Введение
Музыкальная индустрия стала более популярной, и то, как люди слушают музыку, меняется со скоростью лесного пожара. Развитие сервисов потоковой передачи музыки увеличило спрос на системы автоматической классификации музыки и рекомендаций. Spotify, один из ведущих мировых сайтов потоковой передачи музыки, имеет миллионы подписчиков и огромный каталог песен. Тем не менее, чтобы у клиентов был персонализированный музыкальный опыт, Spotify должен рекомендовать треки, которые соответствуют их предпочтениям. Spotify использует алгоритмы машинного обучения, чтобы направлять музыку и классифицировать ее по жанру.

Источник: www.analyticsvidhya.com
Этот проект будет посвящен проблеме классификации жанров Spotify Multiclass, где мы загружаем набор данных из Kaggle.
Цель – Этот проект направлен на разработку модели, которая классифицирует жанр и может точно предсказать жанр музыкального трека на Spotify.
Цели обучения
- Исследовать связь между музыкальными жанрами на Spotify и их акустическими характеристиками.
- Создать классификационную модель на основе слуховых характеристик для предсказания жанра данной песни.
- Исследовать распределение различных музыкальных жанров Spotify в наборе данных.
- Очистить и предварительно обработать данные, чтобы подготовить их к моделированию.
- Оценить эффективность модели категоризации и повысить ее точность.
Эта статья была опубликована в рамках Блогатон по Data Science.
Содержание
Предпосылки
Прежде чем мы начнем реализацию, мы должны установить и импортировать некоторые библиотеки. Перечисленные ниже библиотеки являются обязательными:
Панды: библиотека для обработки и анализа данных.
NumPy: пакет научных вычислений, используемый для матричных вычислений.
Матплотлиб: библиотека построения графиков для языка программирования Python.
Sурожденный: библиотека визуализации данных на основе matplotlib.
Склеарн: библиотека машинного обучения для построения моделей для классификации.
TensorFlow: популярная библиотека с открытым исходным кодом для создания и обучения моделей глубокого обучения.
Чтобы установить их, мы запускаем эту команду.
!pip install pandas !pip install numpy
!pip install matplotlib
!pip install seaborn
!pip install sklearn
!pip install tensorflowПроектный трубопровод
Предварительная обработка данных: очистить и предварительно обработать набор данных «genres_v2», чтобы подготовить его к машинному обучению.
Техническая инженерия: извлечение значимых функций из аудиофайлов, которые помогут нам обучить нашу модель.
Выбор модели: оцените несколько алгоритмов машинного обучения, чтобы найти наиболее эффективную модель.
Модельное обучение: обучите выбранную модель предварительно обработанному набору данных и оцените ее производительность.
Развертывание модели: Разверните обученную модель в онлайн-приложении, которое может рекомендовать музыкальные треки в Spotify на основе предпочтений пользователя.
Итак, давайте начнем делать код.
Проект
Во-первых, нам нужно загрузить набор данных. Вы можете скачать набор данных с Kaggle. Нам нужно импортировать необходимые библиотеки для выполнения наших задач.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn import preprocessing
from sklearn import metrics
import numpy as np
import tensorflow as tf
from tensorflow import keras
from sklearn.decomposition import PCA, KernelPCA, TruncatedSVD
from sklearn.manifold import Isomap, TSNE, MDS
import random
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
import warnings warnings.simplefilter("ignore")Загрузите набор данных
Мы загружаем набор данных с помощью pandas read_csv, и набор данных содержит 42305 строк и 22 столбца и состоит из более чем 18000 дорожек.
data = pd.read_csv("Desktop/genres_v2.csv")
data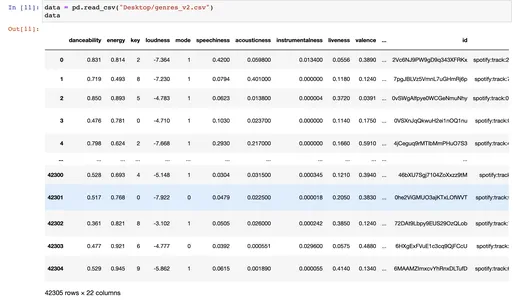
Изучение данных
Я использую метод iloc для выбора строк и столбцов, формирующих фрейм данных, по позициям их целочисленных индексов. Я выбираю первые 20 столбцов df.
data.iloc[:,:20] # this is for the first 20 columns data.iloc[:,20:] # this is for the 21st column data.info()Когда вы вызываете data.info(), он выводит следующую информацию:
- Количество строк и столбцов во фрейме данных.
- Имя каждого столбца, его тип данных и количество ненулевых значений в этом столбце.
- Общее количество ненулевых значений во фрейме данных.
- Использование памяти DataFrame.
data.nunique() # number of unique values in our data set.Очистка данных
Здесь мы хотим очистить наши данные, удалив ненужные столбцы, которые не добавляют ценности прогнозу.
df = data.drop(["type","type","id","uri","track_href","analysis_url","song_name", "Unnamed: 0","title", "duration_ms", "time_signature"], axis =1)
df
Мы удалили некоторые столбцы, которые не добавляют ценности этой конкретной проблеме, и установили ось = 1, где удаляются столбцы, а не строки. Мы снова вызываем фрейм данных, чтобы увидеть новый фрейм данных с полезной информацией.
дф. Метод description() генерирует описательную статистику фрейма данных Pandas. Он дает сводную информацию о центральной тенденции и дисперсии, а также о форме распределения набора данных.
После запуска этой команды вы можете увидеть всю описательную статистику фрейма данных, такую как стандартное значение, среднее значение, медиана, процентиль, минимум и максимум.
df.describe()Чтобы отобразить сводку Pandas DataFrame или Series, используйте функцию df.info(). Он предоставляет информацию о наборе данных, такую как количество строк и столбцов, типы данных каждого столбца, количество ненулевых значений в каждом столбце и использование памяти набора данных.
df.info()
df["genre"].value_counts()
ax = sns.histplot(df[«жанр»]) генерирует гистограмму распределения значений в Pandas DataFrame с именем столбца «жанр» df. Этот код можно использовать для визуализации частотности некоторых жанров Spotify в наборе музыкальных данных.
ax = sns.histplot(df["genre"])
_ = plt.xticks(rotation=90)
_ = plt.title("Genres")Следующий код исключает или удаляет все строки в Pandas DataFrame, где значение в столбце «жанр» равно «Поп». Затем индекс DataFrame сбрасывается до диапазона, в котором он начинается с 0. Наконец, он вычисляет корреляционную матрицу оставшихся столбцов DataFrame.
Этот код помогает изучить набор данных, удаляя ненужные строки и находя корреляции между оставшимися переменными.
df.drop(df.loc[df['genre']=="Pop"].index, inplace=True)
df = df.reset_index(drop = True)
df = df.corr()Следующий код sns. тепловая карта (df, cmap='coolwarm, annot=True) plt. show() генерирует тепловую карту, изображающую корреляционную матрицу Pandas DataFrame df.
Этот код помогает найти и отобразить силу и направление корреляции между переменными в наборе данных. Цветовое кодирование тепловой карты позволяет легко увидеть, какие пары переменных сильно коррелированы, а какие нет.
sns.heatmap(df, cmap='coolwarm', annot=True ) plt.show()12pythonСледующий код выбирает подмножество столбцов в Pandas DataFrame df с именем x, которое содержит все столбцы с начала DataFrame, включая столбец «tempo». Затем он выбирает «жанр» DataFrame в качестве целевой переменной и присваивает его y.
Переменная x представляет Pandas DataFrame с подмножеством исходных столбцов, а переменная y представляет серию Pandas со значениями столбца «жанр».
Методы x.unique() и y.unique() извлекают уникальные значения переменных x и y соответственно. Эти подпрограммы могут быть полезны для определения количества уникальных значений в переменных набора данных.
x = df.loc[:,:"tempo"]
y = df["genre"]
x y
x.unique()
y.unique()Я не даю все изображения. Вы можете проверить блокнот внизу.
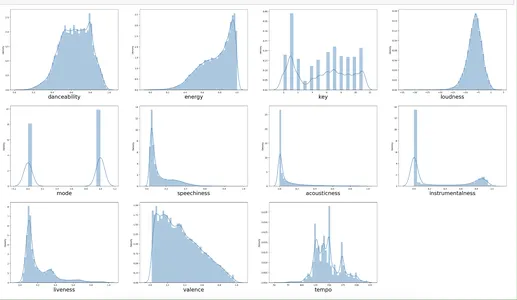
Данный код создает сетку графиков распределения, которые позволяют пользователям просматривать распределение значений по нескольким столбцам в наборе данных. Обнаружение закономерностей, тенденций и выбросов в данных путем отображения распределения значений в каждом столбце. Они полезны и полезны для исследовательского анализа данных и поиска ценных и потенциальных ошибок или неточностей в наборе данных.
k=0
plt.figure(figsize = (40,30))
for i in x.columns: plt.subplot(4,4, k + 1) sns.distplot(x[i]) plt.xlabel(i, fontsize=24) k +=1Здесь мы строим график для каждого x_columns, используя цикл for.
Модельное обучение
Следующий код делит набор данных на подмножества обучения и тестирования. Он случайным образом делит входные переменные и целевые переменные на 80% обучающих и 20% тестовых групп. Затем выводятся описательные статистические данные обучающих данных, чтобы помочь в исследовании данных и выявлении возможных проблем.
xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size= 0.2, random_state=42, shuffle = True)
xtrain.columns
xtrain.describe()Здесь мы разделяем данные на обучение и тестирование (размер = 20%), и мы используем функцию описания, чтобы увидеть описательную статистику.
Функция MinMaxScaler() из модуля sklearn.preprocessing используется для масштабирования функций. Он хранит имена столбцов обучающих данных в переменной ol. Затем объект масштабирования используется для подгонки и преобразования данных xtrain при изменении данных xtest.
Наконец, альтернативные данные xtrain и xtest преобразуются в кадры данных pandas с исходными именами столбцов (col). Это важный шаг в предварительной обработке и стандартизации данных для моделей машинного обучения.
ol = xtrain.columns scalerx = MinMaxScaler() xtrain = scalerx.fit_transform(xtrain)
xtest = scalerx.transform(xtest) xtrain = pd.DataFrame(xtrain, columns = col)
xtest = pd.DataFrame(xtest, columns = col)Здесь мы используем MinMaxScaler, в основном для масштабирования и нормализации данных.
Следующее позволяет нам увидеть описательную статистику xtrain и xtest.
xtrain.describe() xtest.describe()Функция LabelEncoder() из пакета sklearn.preprocessing используется для кодирования меток. Он использует подпрограммы fit transform() и transform() для кодирования целевых переменных категории (ytrain и ytest) в числовые значения.
Затем данные обучения и тестирования для входных (x) и целевых (y) переменных объединяются. Затем числовые метки обратно преобразуются в исходные значения категорий (y train, y test и y org).
Далее мы используем метод np.unique(), который возвращает отдельные категории в обучающих данных.
Наконец, с помощью библиотеки seaborn создается тепловая карта, иллюстрирующая взаимосвязь между входными характеристиками. Это критический этап, когда мы изучаем и подготавливаем данные для моделей машинного обучения.
le = preprocessing.LabelEncoder()
ytrain = le.fit_transform(ytrain)
ytest = le.transform(ytest) x = pd.concat([xtrain, xtest], axis = 0)
y = pd.concat([pd.DataFrame(ytrain), pd.DataFrame(ytest)], axis = 0) y_train = le.inverse_transform(ytrain)
y_test = le.inverse_transform(ytest)
y_org = pd.concat([pd.DataFrame(y_train), pd.DataFrame(y_test)], axis = 0) np.unique(y_train) csvax = sns.heatmap(xtrain.corr()).set(title = "Correlation between Features")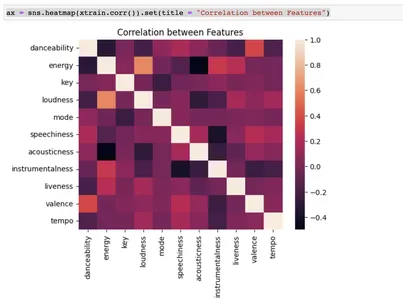
PCA — это популярный подход к уменьшению размерности, который может помочь уменьшить сложность больших наборов данных и повысить производительность моделей машинного обучения.
С входными данными x алгоритм использует PCA, чтобы минимизировать количество признаков до двух частей, которые объясняют вариацию. Уменьшенный набор данных показан на двумерной диаграмме рассеивания с точками, окрашенными метками классов в y. Это помогает визуализировать разделение некоторых классов в сокращенном пространстве признаков.
pca = PCA(n_components=2)
x_pca = pca.fit_transform(x, y)
plot_pca = plt.scatter(x_pca[:,0], x_pca[:,1], c=y)
handles, labels = plot_pca.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
_ = plt.title("PCA")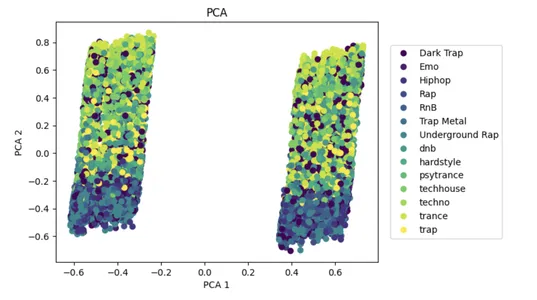
t-SNE — это популярный подход к нелинейному уменьшению размерности, который может помочь уменьшить сложность больших наборов данных и повысить производительность моделей машинного обучения.
Использование t-распределенного стохастического встраивания соседей (t-SNE) во входных данных x уменьшает количество признаков в многомерном пространстве до 2D, сохраняя при этом сходство между точками данных.
Двухмерный точечный график показывает уменьшенный набор данных с точками, окрашенными в соответствии с их метками y-класса. Это помогает визуализировать разделение некоторых классов в сокращенном пространстве признаков.
tsne = TSNE(n_components=2)
x_tsne = tsne.fit_transform(x, y)
plot_tsne = plt.scatter(x_tsne[:,0], x_tsne[:,1], c=y)
handles, labels = plot_tsne.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("T-SNE 1")
plt.ylabel("T-SNE 2")
_ = plt.title("T-SNE")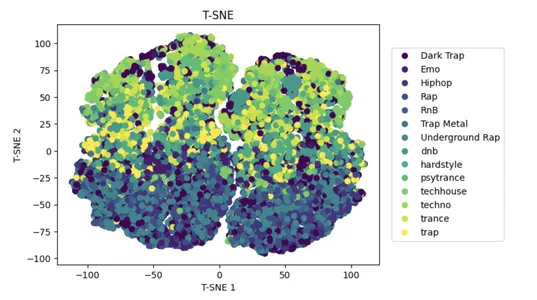
SVD — это популярный подход к уменьшению размерности, который может помочь уменьшить сложность больших наборов данных и повысить производительность моделей машинного обучения.
Следующий код применяет разложение по сингулярным значениям (SVD) к входным данным x с n компонентами = 2, уменьшая количество входных признаков до двух, которые объясняют наибольшую дисперсию данных. Уменьшенный набор данных затем отображается на 2D-диаграмме рассеяния с точками, окрашенными в соответствии с их метками y-класса.
Это облегчает визуализацию разделения нескольких классов в сокращенном пространстве признаков, а точечная диаграмма создается с помощью инструмента matplotlib.
svd = TruncatedSVD(n_components=2)
x_svd = svd.fit_transform(x, y)
plot_svd = plt.scatter(x_svd[:,0], x_svd[:,1], c=y)
handles, labels = plot_svd.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("Truncated SVD 1")
plt.ylabel("Truncated SVD 2")
_ = plt.title("Truncated SVD")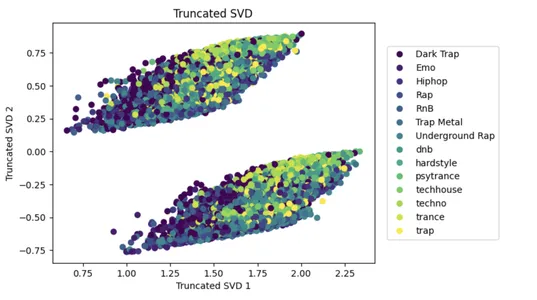
LDA — это популярный подход к уменьшению размерности, который может повысить производительность модели машинного обучения за счет уменьшения влияния нерелевантной информации.
Следующий код выполняет линейный дискриминантный анализ (LDA) для входных данных x с n компонентами = 2, что уменьшает количество входных признаков до двух линейных дискриминантов, которые максимизируют разделение между различными классами в данных.
Уменьшенный набор данных затем отображается на 2D-диаграмме рассеяния с точками, окрашенными в соответствии с их метками y-класса. Это помогает визуализировать разделение некоторых классов в сокращенном пространстве признаков.
lda = LinearDiscriminantAnalysis(n_components=2)
x_lda = lda.fit_transform(x, y.values.ravel())
plot_lda = plt.scatter(x_lda[:,0], x_lda[:,1], c=y)
handles, labels = plot_lda.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("LDA 1")
plt.ylabel("LDA 2")
_ = plt.title("Linear Discriminant Analysis")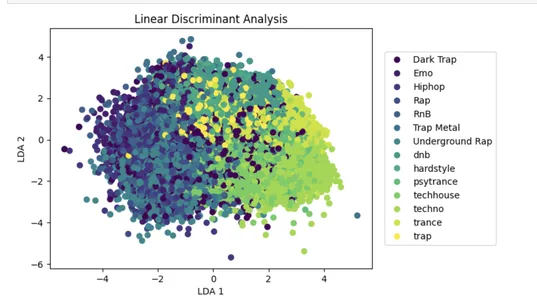
Следующий код заменяет некоторые значения в столбце фрейма данных под названием «жанр» новой сделкой «Рэп». В частности, он заменяет значения «Trap Metal», «Underground Rap», «Emo», «RnB» и т. д. на «Rap». Это полезно для группировки жанров под одним именем для анализа или моделирования.
df = df.replace("Trap Metal", "Rap")
df = df.replace("Underground Rap", "Rap")
df = df.replace("Emo", "Rap")
df = df.replace("RnB", "Rap")
df = df.replace("Hiphop", "Rap")
df = df.replace("Dark Trap", "Rap")Приведенный ниже код создает гистограмму с использованием библиотеки seaborn, чтобы проиллюстрировать распределение переменной «жанр» во входном наборе данных df. Фигура повернута на 80 градусов, чтобы улучшить видимость меток оси x. «Жанры» — это название.
ax = sns.histplot(df["genre"])
_ = plt.xticks(rotation=80)
_ = plt.title("Genres")Предоставленный код удаляет строки из фрейма данных. В частности, он удаляет строки с частотой 0.85, где значением столбца жанра является «Рэп», с помощью генератора случайных чисел.
Строки, подлежащие отбрасыванию, сохраняются в списке отброшенных строк перед удалением из фрейма данных с помощью функции отбрасывания. Затем код печатает гистограмму оставшихся значений жанра с помощью функции seaborn plot и изменяет заголовок и поворот меток по оси x с помощью методов matplotlib title и xticks.
rows_drop = []
for i in range(len(df)): if df.iloc[i]['genre'] == 'Rap': if random.random()<0.85: rows_drop.append(i)
df.drop(index = rows_drop, inplace=True) ax = sns.histplot(df["genre"])
_ = plt.xticks(rotation=80)
_ = plt.title("Genres")Предоставленный код выполняет предварительную обработку данных. Первым шагом является разделение входных данных на обучающие и тестовые наборы с использованием функции разделения тестов обучения библиотеки Sklearn.
Затем он корректирует числовые характеристики предоставленных данных с помощью функции MinMaxScaler из того же пакета. Код кодирует целевую переменную категории с помощью функции LabelEncoder модуля предварительной обработки.
В результате предварительно обработанные наборы данных для обучения и тестирования объединяются в единый набор данных, который может обрабатывать алгоритм машинного обучения.
x = df.loc[:,:"tempo"]
y = df["genre"] xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size= 0.2, random_state=42, shuffle = True) col = xtrain.columns
scalerx = MinMaxScaler() xtrain = scalerx.fit_transform(xtrain)
xtest = scalerx.transform(xtest) xtrain = pd.DataFrame(xtrain, columns = col)
xtest = pd.DataFrame(xtest, columns = col)
le = preprocessing.LabelEncoder()
ytrain = le.fit_transform(ytrain)
ytest = le.transform(ytest) x = pd.concat([xtrain, xtest], axis = 0)
y = pd.concat([pd.DataFrame(ytrain), pd.DataFrame(ytest)], axis = 0) y_train = le.inverse_transform(ytrain)
y_test = le.inverse_transform(ytest)
y_org = pd.concat([pd.DataFrame(y_train), pd.DataFrame(y_test)], axis = 0) Этот код создает два обратных вызова с ранней остановкой для обучения модели, один из которых основан на потере проверки, а другой — на точности проверки. Последовательный API Keras создает модель NN с различными связанными слоями, используя функцию активации ReLU, пакетную нормализацию и регуляризацию отсева. Краткое описание модели напечатано на консоли.
Последний выходной слой выводит вероятности классов, используя функцию активации softmax. Краткое описание модели напечатано на консоли.
early_stopping1 = keras.callbacks.EarlyStopping(monitor = "val_loss", patience = 10, restore_best_weights = True)
early_stopping2 = keras.callbacks.EarlyStopping(monitor = "val_accuracy", patience = 10, restore_best_weights = True) model = keras.Sequential([ keras.layers.Input(name = "input", shape = (xtrain.shape[1])), keras.layers.Dense(256, activation = "relu"), keras.layers.BatchNormalization(), keras.layers.Dropout(0.2), keras.layers.Dense(128, activation = "relu"), keras.layers.Dense(128, activation = "relu"), keras.layers.BatchNormalization(), keras.layers.Dropout(0.2), keras.layers.Dense(64, activation = "relu"), keras.layers.Dense(max(ytrain)+1, activation = "softmax")
]) model.summary()Следующий блок кода использует Keras для компиляции и обучения модели нейронной сети. Модель представляет собой последовательную модель с несколькими плотными слоями с функцией активации relu, пакетной нормализацией и регуляризацией отсева. «разреженная категориальная перекрестная энтропия» — это используемая функция потерь. В то же время «Адам» является оптимизатором. Модель обучается в течение 100 эпох с обратными вызовами, которые заканчиваются раньше, в зависимости от потери проверки и точности.
model.compile(optimizer = keras.optimizers.Adam(), loss = "sparse_categorical_crossentropy", metrics = ["accuracy"]) model_history = model.fit(xtrain, ytrain, epochs = 100, verbose = 1, batch_size = 128, validation_data = (xtest, ytest), callbacks = [early_stopping1, early_stopping2])Данные обучения отправляются как xtrain и ytrain, тогда как данные проверки отправляются как xtest и ytest. История обучения модели сохраняется в переменной истории модели.
print(model.evaluate(xtrain, ytrain)) print(model.evaluate(xtest, ytest))Следующий код создает график, используя matplotlib; на оси x у нас есть эпоха, а на оси y у нас есть разреженная категориальная перекрестная энтропия.
plt.plot(model_history.history["loss"])
plt.plot(model_history.history["val_loss"])
plt.legend(["loss", "validation loss"], loc ="upper right")
plt.title("Train and Validation Loss")
plt.xlabel("epoch")
plt.ylabel("Sparse Categorical Cross Entropy")
plt.show()То же, что и выше, но здесь мы строим график между эпохой и точностью.
plt.plot(model_history.history["accuracy"])
plt.plot(model_history.history["val_accuracy"])
plt.legend(["accuracy", "validation accuracy"], loc ="upper right")
plt.title("Train and Validation Accuracy")
plt.xlabel("epoch")
plt.ylabel("Accuracy")
plt.show()Следующий код ypred, который предсказывает xtest.
ypred = model.predict(xtest).argmax(axis=1)Следующий код оценивает метрики классификации в тесте и ypred, где мы можем видеть точность, отзыв и F1score. Основываясь на значениях, мы можем продолжить нашу модель.
cf_matrix = metrics.confusion_matrix(ytest, ypred) _ = sns.heatmap(cf_matrix, fmt=".0f", annot=True) _ = plt.title("Confusion Matrix")Наконец, мы делаем оценку модели.
Оценка модели
Следующий код оценивает метрики классификации в тесте и ypred, где мы можем указать точность, отзыв, F1score. Основываясь на значениях, мы можем продолжить нашу модель.
print(metrics.classification_report(ytest, ypred))Заключение
В заключение, мы можем классифицировать музыкальные жанры Spotify с точностью 88%, используя анализ и моделирование, проведенные в этом исследовании. Учитывая сложность и субъективность определения музыкальных жанров, это разумный уровень точности. Тем не менее, всегда есть возможность для улучшения, и наш анализ имеет несколько ограничений.
Одним из недостатков является необходимость большего разнообразия в нашем наборе данных, в первую очередь рэп и хип-хоп музыки на Spotify. Это повлияло на наши исследования и моделирование в пользу конкретных жанров. Мы должны включить в набор данных более широкий спектр музыкальных жанров, чтобы улучшить нашу модель.
Еще одним ограничением является вероятность человеческих ошибок при классификации данных, что могло привести к расхождениям в жанровой категоризации. Мы можем использовать более сложные подходы, такие как модели глубокого обучения, для автоматической маркировки музыки на основе слуховых атрибутов, чтобы решить эту проблему.
Наш анализ и моделирование дают прочную основу для классификации музыкальных жанров Spotify, но для повышения точности и устойчивости модели требуются дополнительные исследования и улучшения.
Основные выводы
- Слуховые характеристики, такие как темп, танцевальность, энергия и валентность, можно различать в музыкальных жанрах Spotify.
- Очистка и предварительная обработка данных являются важными процессами подготовки данных для моделирования и могут существенно повлиять на производительность модели.
- Подходы к ранней остановке, такие как мониторинг потерь и точности при проверке, могут помочь предотвратить переоснащение модели.
- Увеличивайте размер набора данных, добавляйте функции и экспериментируйте с альтернативными методами и гиперпараметрами, чтобы повысить производительность модели классификации.
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2023/03/solving-spotify-multiclass-genre-classification-problem/
- 1
- 10
- 100
- 2D
- a
- выше
- По
- точность
- точно
- через
- Активация
- адрес
- помощь
- пособие
- Цель
- алгоритм
- алгоритмы
- Все
- позволяет
- альтернатива
- всегда
- анализ
- аналитика
- Аналитика Видхья
- и
- API
- Применение
- подхода
- подходы
- гайд
- помощь
- Атрибуты
- аудио
- Автоматический
- автоматически
- Ось
- основанный
- становиться
- до
- начало
- не являетесь
- ниже
- полезный
- между
- Заблокировать
- Строительство
- строительные модели
- призывают
- под названием
- вызова
- каталог
- категории
- категоризации
- Категории
- Центр
- центральный
- изменения
- изменения
- характеристика
- проверка
- Выбирая
- класс
- классов
- классификация
- Уборка
- код
- Кодирование
- цвет
- Column
- Колонки
- сложность
- расчеты
- вычисление
- заключение
- замешательство
- подключенный
- Консоли
- содержит
- конвертировать
- переделанный
- Корреляция
- корреляции
- может
- Создайте
- создает
- критической
- Пересекать
- Клиенты
- темно
- данным
- анализ данных
- точки данных
- набор данных
- визуализация данных
- Наборы данных
- сделка
- глубоко
- глубокое обучение
- определяющий
- Спрос
- изображающая
- развертывание
- описывать
- определения
- развивать
- Развитие
- различный
- направление
- Недостаток
- обнаружение
- усмотрение
- Дисплей
- Выдающийся
- распределение
- Разнообразие
- Разделение
- дело
- вниз
- скачать
- Падение
- упал
- Капли
- каждый
- Рано
- легко
- ликвидирует
- энергетика
- эпоха
- эпохи
- и т.д
- оценивать
- оценка
- опыт
- эксперимент
- Объяснять
- исследование
- Исследовательский анализ данных
- извлечение
- облегчает
- в пользу
- Особенность
- Особенности
- несколько
- фигура
- Файлы
- окончательный
- Найдите
- обнаружение
- First
- соответствовать
- Фокус
- после
- форма
- Год основания
- КАДР
- частота
- от
- функция
- генерирует
- генератор
- получить
- Дайте
- данный
- дает
- Отдаете
- сетка
- Группы
- инструкция
- Ручки
- помощь
- полезный
- помогает
- здесь
- очень
- история
- Как
- HTTPS
- человек
- Идентификация
- изображений
- реализация
- Импортировать
- улучшать
- улучшение
- улучшение
- in
- В том числе
- включать
- Увеличение
- расширились
- повышение
- индекс
- individual
- промышленность
- повлиять
- влияние
- информация
- вход
- устанавливать
- Введение
- исследовать
- IT
- keras
- этикетка
- Этикетки
- язык
- большой
- слой
- слоев
- ведущий
- изучение
- уровень
- LG
- библиотеки
- Библиотека
- недостатки
- LINK
- Список
- Включенный в список
- загрузка
- от
- машина
- обучение с помощью машины
- сделанный
- ДЕЛАЕТ
- Манипуляция
- массивный
- Matplotlib
- матрица
- Макс
- Максимизировать
- значимым
- Медиа
- Память
- металл
- метод
- методы
- Метрика
- может быть
- миллионы
- минимизировать
- ошибки
- модель
- моделирование
- Модели
- модуль
- монитор
- Мониторинг
- БОЛЕЕ
- самых
- с разными
- Музыка
- музыкальная индустрия
- потоковое воспроизведение музыки
- имя
- Названный
- имена
- навигационный
- необходимо
- Необходимость
- сеть
- нервный
- нейронной сети
- Новые
- ноутбук
- номер
- NumPy
- объект
- ONE
- онлайн
- с открытым исходным кодом
- Возможность
- заказ
- оригинал
- Другое
- принадлежащих
- Темп
- пакет
- пар
- панд
- часть
- особый
- части
- Терпение
- паттеранами
- Люди
- выполнять
- производительность
- Персонализированные
- Выборы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- пунктов
- поп
- Популярное
- позиции
- возможное
- потенциал
- Точность
- предсказывать
- прогноз
- предсказывает
- предпочтения
- Подготовить
- подготовка
- предпосылки
- предотвращать
- предварительно
- в первую очередь
- Печать / PDF
- печать
- Проблема
- проблемам
- процесс
- Процессы
- Программирование
- Проект
- при условии
- приводит
- опубликованный
- положил
- Питон
- случайный
- ассортимент
- рэп
- скорее
- разумный
- рекомендовать
- Рекомендация
- Цена снижена
- снижает
- снижение
- отношения
- осталось
- удален
- удаление
- представляет
- обязательный
- исследованиям
- упругость
- ограничение
- результат
- Возвращает
- процедуры
- Run
- Бег
- то же
- масштабирование
- Наука
- рожденное море
- выбранный
- Серии
- Услуги
- набор
- Наборы
- несколько
- Форма
- показанный
- Шоу
- перемешивание
- существенно
- одинарной
- единственное число
- Сайтов
- Размер
- твердый
- Решение
- некоторые
- сложный
- Space
- конкретный
- конкретно
- раскол
- Spotify
- Этап
- стандартизации
- и политические лидеры
- начинается
- статистика
- Шаг
- остановка
- магазины
- потоковый
- Потоковые службы
- прочность
- Кабинет
- Абоненты
- такие
- РЕЗЮМЕ
- поставляется
- системы
- цель
- задачи
- Время
- tensorflow
- тестXNUMX
- Тестирование
- Ассоциация
- их
- время
- Название
- в
- инструментом
- Всего
- трек
- Train
- специалистов
- Обучение
- преобразован
- Тенденции
- правда
- Типы
- под
- созданного
- UNNAMED
- URI
- us
- Применение
- использование
- пользователей
- использовать
- использовать
- Проверка
- ценный
- ценностное
- Наши ценности
- переменные
- разнообразие
- различный
- Вид
- видимость
- визуализация
- визуализации
- который
- в то время как
- Шире
- будете
- мире
- X
- зефирнет