Исследовательский анализ данных (EDA) — это обычная задача, выполняемая бизнес-аналитиками для выявления закономерностей, понимания взаимосвязей, проверки предположений и выявления аномалий в своих данных. В машинном обучении (ML) важно сначала понять данные и их отношения, прежде чем приступать к построению модели. Традиционные циклы разработки машинного обучения иногда могут занимать месяцы и требовать передовых знаний в области обработки данных и инженерных навыков машинного обучения, в то время как решения машинного обучения без кода могут помочь компаниям ускорить разработку решений машинного обучения до нескольких дней или даже часов.
Холст Amazon SageMaker — это инструмент машинного обучения без кода, который помогает бизнес-аналитикам создавать точные прогнозы машинного обучения без необходимости писать код или без какого-либо опыта машинного обучения. Canvas предоставляет простой в использовании визуальный интерфейс для загрузки, очистки и преобразования наборов данных с последующим построением моделей машинного обучения и созданием точных прогнозов.
В этом посте мы рассмотрим, как выполнить EDA, чтобы лучше понять ваши данные перед созданием модели ML, благодаря встроенным в Canvas расширенным визуализациям. Эти визуализации помогут вам проанализировать отношения между объектами в ваших наборах данных и лучше понять ваши данные. Это делается интуитивно, с возможностью взаимодействия с данными и обнаружения идей, которые могут остаться незамеченными при специальных запросах. Их можно быстро создать с помощью «визуализатора данных» в Canvas перед созданием и обучением моделей машинного обучения.
Обзор решения
Эти визуализации дополняют ряд возможностей подготовки и исследования данных, уже предлагаемых Canvas, включая возможность исправления отсутствующих значений и замены выбросов; фильтровать, объединять и изменять наборы данных; и извлекать определенные значения времени из временных меток. Чтобы узнать больше о том, как Canvas может помочь вам очистить, преобразовать и подготовить набор данных, ознакомьтесь с Подготовка данных с расширенными преобразованиями.
Для нашего варианта использования мы рассмотрим, почему в любом бизнесе уходят клиенты, и продемонстрируем, как EDA может помочь с точки зрения аналитика. Набор данных, который мы используем в этом посте, представляет собой синтетический набор данных от оператора мобильной связи для прогнозирования оттока клиентов, который вы можете скачать (отток.csv), или вы приносите свой собственный набор данных для экспериментов. Инструкции по импорту собственного набора данных см. Импорт данных в Amazon SageMaker Canvas.
Предпосылки
Следуйте инструкциям в Предварительные условия для настройки Amazon SageMaker Canvas прежде чем продолжить.
Импортируйте свой набор данных в Canvas
Чтобы импортировать образец набора данных в Canvas, выполните следующие шаги:
- Войдите в Canvas как бизнес-пользователь. Сначала мы загружаем набор данных, упомянутый ранее, с нашего локального компьютера в Canvas. Если вы хотите использовать другие источники, такие как Амазонка Redshift, Ссылаться на Подключиться к внешнему источнику данных.
- Выберите Импортировать.

- Выберите Загрузите, а затем выберите Выберите файлы на вашем компьютере.
- Выберите свой набор данных (churn.csv) и выберите Даты импорта.

- Выберите набор данных и выберите Создать модель.

- Что касается Название модели, введите имя (для этого поста мы дали название Прогноз оттока).
- Выберите Создавай.

Как только вы выберете свой набор данных, вам будет представлен обзор, в котором описаны типы данных, отсутствующие значения, несоответствующие значения, уникальные значения, а также средние или модальные значения соответствующих столбцов.
С точки зрения EDA вы можете заметить, что в наборе данных нет отсутствующих или несовпадающих значений. Как бизнес-аналитик, вы можете захотеть получить начальное представление о построении модели еще до начала исследования данных, чтобы определить, как модель будет работать и какие факторы влияют на производительность модели. Canvas дает вам возможность получить представление о ваших данных, прежде чем строить модель, предварительно просмотрев модель. - Прежде чем приступить к исследованию данных, выберите Предварительная версия модели.

- Выберите столбец для прогнозирования (оттока). Canvas автоматически определяет, что это прогноз с двумя категориями.
- Выберите Предварительная версия модели. SageMaker Canvas использует подмножество ваших данных для быстрого построения модели, чтобы проверить, готовы ли ваши данные для создания точного прогноза. Используя этот пример модели, вы можете понять точность текущей модели и относительное влияние каждого столбца на прогнозы.
На следующем снимке экрана показан наш предварительный просмотр.

Предварительный просмотр модели показывает, что модель предсказывает правильную цель (отток?) в 95.6% случаев. Вы также можете увидеть начальное влияние столбца (влияние каждого столбца на целевой столбец). Давайте проведем исследование, визуализацию и преобразование данных, а затем приступим к построению модели.
Исследование данных
Canvas уже предоставляет некоторые общие базовые визуализации, такие как распределение данных в виде сетки на строить вкладка Они отлично подходят для получения общего обзора данных, понимания того, как данные распределяются, и получения сводного обзора набора данных.
Как бизнес-аналитику вам, возможно, потребуется получить общее представление о том, как распределяются данные, а также о том, как распределение отражается в целевом столбце (отток), чтобы легко понять взаимосвязь данных перед построением модели. Теперь вы можете выбрать Вид сетки чтобы получить представление о распределении данных.
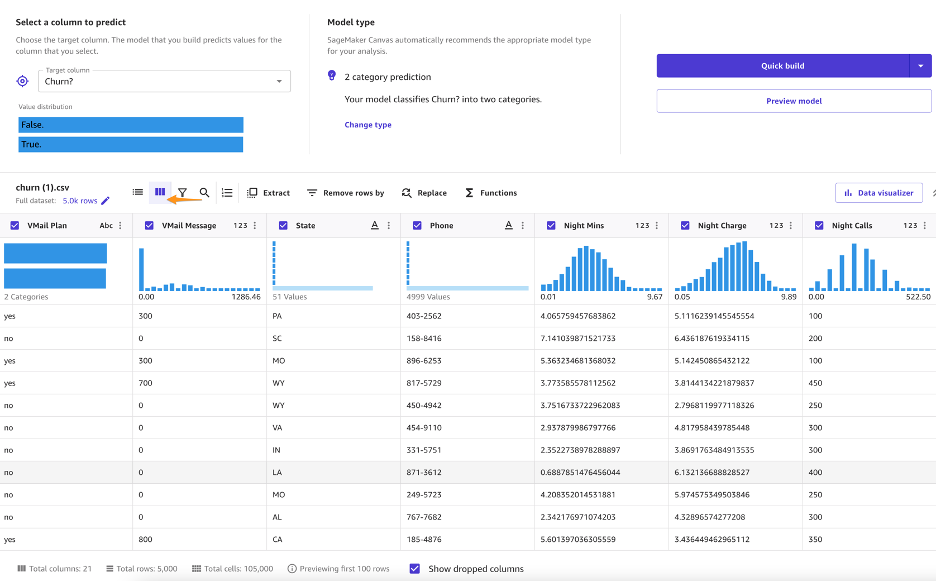
На следующем снимке экрана показан обзор распределения набора данных.

Мы можем сделать следующие наблюдения:
- Телефон принимает слишком много уникальных значений, чтобы иметь какое-либо практическое применение. Мы знаем, что телефон — это идентификатор клиента, и не хотим строить модель, учитывающую конкретных клиентов, а скорее изучаем в более общем смысле, что может привести к оттоку. Вы можете удалить эту переменную.
- Большинство числовых функций хорошо распределены после Гауссовым кривая колокола. В ML вы хотите, чтобы данные распределялись нормально, потому что любую переменную, которая демонстрирует нормальное распределение, можно прогнозировать с более высокой точностью.
Давайте углубимся и рассмотрим расширенные визуализации, доступные в Canvas.
Визуализация данных
Как бизнес-аналитик, вы хотите увидеть, есть ли отношения между элементами данных и как они связаны с оттоком. С Canvas вы можете исследовать и визуализировать свои данные, что поможет вам получить более глубокое представление о ваших данных перед созданием моделей машинного обучения. Вы можете визуализировать с помощью точечных диаграмм, гистограмм и коробчатых диаграмм, которые могут помочь вам понять ваши данные и обнаружить взаимосвязи между функциями, которые могут повлиять на точность модели.
Чтобы приступить к созданию визуализаций, выполните следующие шаги:
- На строить вкладке приложения Canvas выберите Визуализатор данных.

Ключевым ускорителем визуализации в Canvas является Визуализатор данных. Давайте изменим размер выборки, чтобы получить лучшую перспективу.
- Выберите количество строк рядом с Образец визуализации.
- С помощью ползунка выберите нужный размер выборки.

- Выберите Обновление ПО чтобы подтвердить изменение размера выборки.
Вы можете изменить размер выборки на основе вашего набора данных. В некоторых случаях у вас может быть от нескольких сотен до нескольких тысяч строк, в которых вы можете выбрать весь набор данных. В некоторых случаях у вас может быть несколько тысяч строк, и в этом случае вы можете выбрать несколько сотен или несколько тысяч строк в зависимости от вашего варианта использования.

Точечная диаграмма показывает взаимосвязь между двумя количественными переменными, измеренными для одних и тех же людей. В нашем случае важно понять взаимосвязь между значениями, чтобы проверить корреляцию.
Поскольку у нас есть звонки, минуты и расходы, мы построим корреляцию между ними для дня, вечера и ночи.
Во-первых, давайте создадим точечный график между дневной зарядкой и дневными минутами.

Мы можем наблюдать, что по мере увеличения Day Mins, Day Charge также увеличивается.
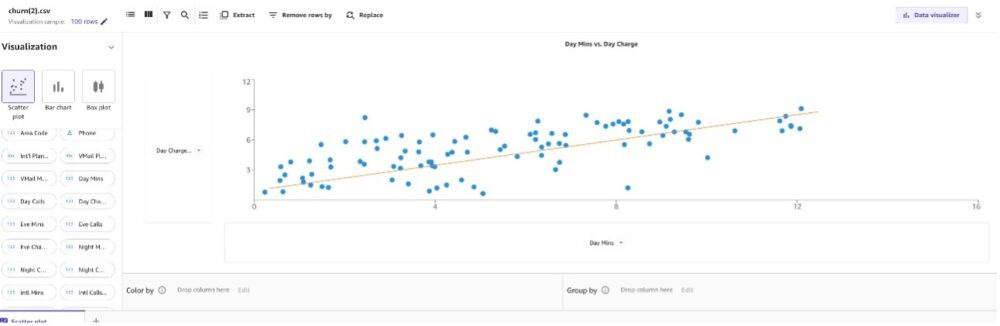
То же самое относится и к вечерним звонкам.

Ночные звонки также имеют ту же закономерность.

Поскольку количество минут и заряд, кажется, увеличиваются линейно, вы можете заметить, что они имеют высокую корреляцию друг с другом. Включение этих пар признаков в некоторые алгоритмы машинного обучения может занять дополнительное место в памяти и снизить скорость обучения, а наличие схожей информации в нескольких столбцах может привести к тому, что модель переоценит влияние и приведет к нежелательной систематической ошибке в модели. Удалим по одному признаку из каждой пары с высокой корреляцией: дневная оплата из пары с дневными минутами, ночная оплата из пары с ночными минутами и международная оплата из пары с международными минутами.
Баланс и вариация данных
Гистограмма — это график между категориальной переменной по оси x и числовой переменной по оси y для изучения взаимосвязи между обеими переменными. Давайте создадим гистограмму, чтобы увидеть, как вызовы распределяются по нашему целевому столбцу Отток для True и False. Выбирать гистограмма и перетащите дневные вызовы и оттоки на ось Y и ось X соответственно.
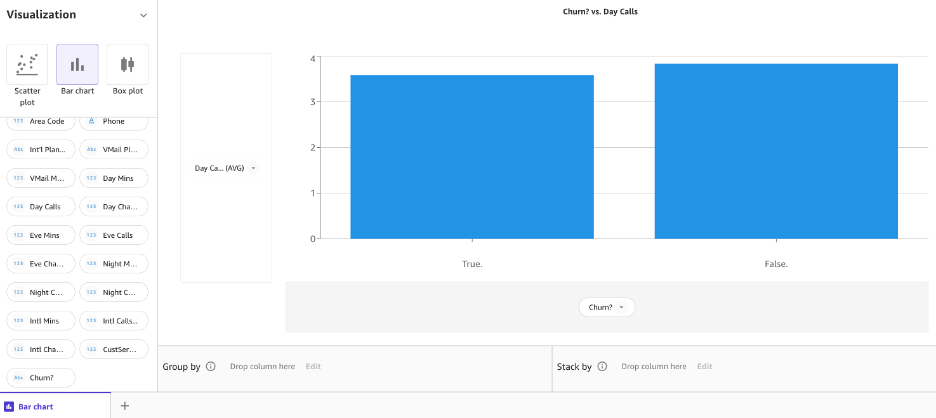
Теперь давайте создадим такую же гистограмму для вечерних звонков и оттока.
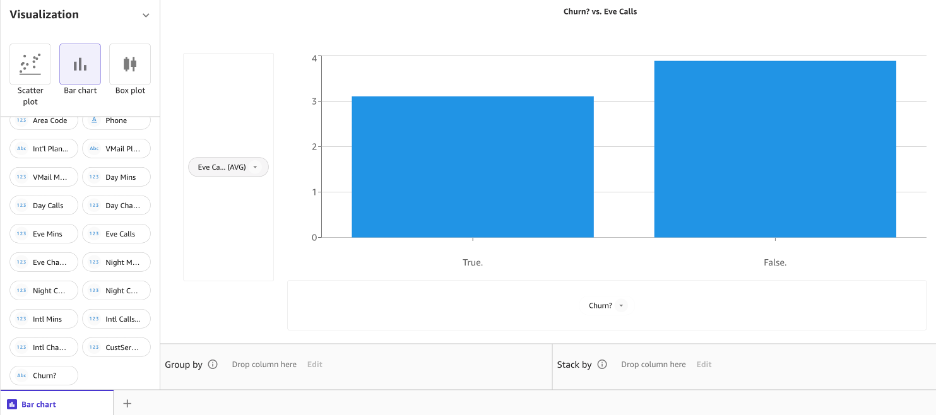
Далее давайте создадим гистограмму ночных звонков и оттока.

Похоже, что есть разница в поведении клиентов, которые ушли, и тех, кто этого не сделал.
Блочные диаграммы полезны, поскольку они показывают различия в поведении данных по классам (отток или нет). Поскольку мы собираемся прогнозировать отток (целевой столбец), давайте создадим ящичковую диаграмму некоторых функций по нашему целевому столбцу, чтобы вывести описательную статистику по набору данных, такую как среднее, максимальное, минимальное, медиана и выбросы.
Выберите Коробочный сюжет и перетащите Day mins и Churn на оси Y и X соответственно.

Вы также можете попробовать тот же подход к другим столбцам против нашего целевого столбца (отток).
Теперь давайте создадим ящичковую диаграмму количества минут в день по сравнению со звонками в службу поддержки, чтобы понять, как количество звонков в службу поддержки распределяется между значениями минут в день. Вы можете видеть, что звонки в службу поддержки не имеют зависимости или корреляции со значением дневных минут.

Из наших наблюдений мы можем определить, что набор данных достаточно сбалансирован. Мы хотим, чтобы данные были равномерно распределены между истинными и ложными значениями, чтобы модель не была смещена в сторону одного значения.
Преобразования
Основываясь на наших наблюдениях, мы удаляем столбец «Телефон», потому что это просто номер счета, а столбцы «Дневная оплата», «Накануне оплаты», «Ночная оплата», поскольку они содержат перекрывающуюся информацию, например столбцы минут, но мы можем снова запустить предварительный просмотр для подтверждения.

После анализа и преобразования данных давайте снова просмотрим модель.

Вы можете заметить, что оценочная точность модели изменилась с 95.6% до 93.6% (это может варьироваться), однако влияние столбца (важность функции) для определенных столбцов значительно изменилось, что повышает скорость обучения, а также влияние столбцов на прогноз, когда мы переходим к следующим шагам построения модели. Наш набор данных не требует дополнительной трансформации, но при необходимости вы можете воспользоваться Преобразование данных машинного обучения для очистки, преобразования и подготовки данных для построения модели.
Построить модель
Теперь вы можете приступить к построению модели и анализу результатов. Для получения дополнительной информации см. Прогнозируйте отток клиентов с помощью машинного обучения без кода с помощью Amazon SageMaker Canvas.
Убирать
Чтобы избежать будущих плата за сеанс, выйти из системы холста.

Заключение
В этом посте мы показали, как вы можете использовать возможности визуализации Canvas для EDA, чтобы лучше понимать свои данные перед построением модели, создавать точные модели машинного обучения и генерировать прогнозы, используя визуальный интерфейс без кода, с интерфейсом «укажи и щелкни».
Об авторах
 Раджакумар Сампаткумар является главным техническим менеджером по работе с клиентами в AWS, предоставляя клиентам рекомендации по согласованию бизнес-технологий и поддерживая переосмысление их моделей облачных операций и процессов. Он увлечен облачными технологиями и машинным обучением. Радж также является специалистом по машинному обучению и работает с клиентами AWS над проектированием, развертыванием и управлением их рабочими нагрузками и архитектурами AWS.
Раджакумар Сампаткумар является главным техническим менеджером по работе с клиентами в AWS, предоставляя клиентам рекомендации по согласованию бизнес-технологий и поддерживая переосмысление их моделей облачных операций и процессов. Он увлечен облачными технологиями и машинным обучением. Радж также является специалистом по машинному обучению и работает с клиентами AWS над проектированием, развертыванием и управлением их рабочими нагрузками и архитектурами AWS.
 Рахул Набера является консультантом по аналитике данных в AWS Professional Services. Его текущая работа сосредоточена на предоставлении клиентам возможности создавать свои рабочие нагрузки данных и машинного обучения на AWS. В свободное время любит играть в крикет и волейбол.
Рахул Набера является консультантом по аналитике данных в AWS Professional Services. Его текущая работа сосредоточена на предоставлении клиентам возможности создавать свои рабочие нагрузки данных и машинного обучения на AWS. В свободное время любит играть в крикет и волейбол.
 Равитея Еламанчили работает архитектором корпоративных решений в Amazon Web Services в Нью-Йорке. Он работает с крупными корпоративными клиентами, предоставляющими финансовые услуги, над разработкой и развертыванием в облаке высокозащищенных, масштабируемых, надежных и экономичных приложений. Он обладает более чем 11-летним опытом управления рисками, технологического консалтинга, анализа данных и машинного обучения. Когда он не помогает клиентам, ему нравится путешествовать и играть на PS5.
Равитея Еламанчили работает архитектором корпоративных решений в Amazon Web Services в Нью-Йорке. Он работает с крупными корпоративными клиентами, предоставляющими финансовые услуги, над разработкой и развертыванием в облаке высокозащищенных, масштабируемых, надежных и экономичных приложений. Он обладает более чем 11-летним опытом управления рисками, технологического консалтинга, анализа данных и машинного обучения. Когда он не помогает клиентам, ему нравится путешествовать и играть на PS5.
- Продвинутый (300)
- AI
- ай искусство
- генератор искусств ай
- искусственный интеллект
- Создатель мудреца Амазонки
- Холст Amazon SageMaker
- искусственный интеллект
- сертификация искусственного интеллекта
- искусственный интеллект в банковском деле
- робот с искусственным интеллектом
- роботы с искусственным интеллектом
- программное обеспечение искусственного интеллекта
- Машинное обучение AWS
- блокчейн
- конференция по блокчейну
- Coingenius
- разговорный искусственный интеллект
- криптоконференция ИИ
- дал-и
- глубокое обучение
- google ai
- обучение с помощью машины
- Платон
- Платон Ай
- Платон Интеллектуальные данные
- Платон игра
- ПлатонДанные
- платогейминг
- масштаб ай
- синтаксис
- Технические инструкции
- зефирнет