Апач Айсберг — это формат открытой таблицы для очень больших аналитических наборов данных, который фиксирует метаданные о состоянии наборов данных по мере их развития и изменения с течением времени. Он добавляет таблицы в вычислительные механизмы, включая Spark, Trino, PrestoDB, Flink и Hive, используя высокопроизводительный формат таблицы, который работает так же, как таблица SQL. Iceberg стал очень популярным благодаря своей поддержке транзакций ACID в озерах данных и таких функций, как эволюция схемы и раздела, путешествие во времени и откат.
Интеграция с Apache Iceberg поддерживается аналитическими сервисами AWS, включая Амазонка ЭМИ, Амазонка Афинакачества Клей AWS. Amazon EMR может выделять кластеры с помощью Spark, Hive, Trino и Flink, на которых может работать Iceberg. Начиная с Amazon EMR версии 6.5.0, вы можете используйте Iceberg с вашим кластером EMR не требуя действия начальной загрузки. В начале 2022 года AWS объявила об общедоступности транзакций Athena ACID на базе Apache Iceberg. Недавно выпущенный Механизм запросов Athena версии 3 обеспечивает лучшую интеграцию с форматом таблицы Iceberg. AWS Glue 3.0 и более поздние версии поддерживает инфраструктуру Apache Iceberg для озер данных.
В этом посте мы обсудим, чего хотят клиенты от современных озер данных, и как Apache Iceberg помогает удовлетворять потребности клиентов. Затем мы рассмотрим решение для создания высокопроизводительного и развивающегося озера данных Iceberg на Простой сервис хранения Amazon (Amazon S3) и обрабатывать добавочные данные, выполняя операторы вставки, обновления и удаления SQL. Наконец, мы покажем вам, как настроить производительность процесса, чтобы улучшить производительность чтения и записи.
Как Apache Iceberg удовлетворяет потребности клиентов в современных озерах данных
Все больше и больше клиентов создают озера данных со структурированными и неструктурированными данными для поддержки множества пользователей, приложений и инструментов аналитики. Возрастает потребность в озерах данных для поддержки таких функций баз данных, как ACID-транзакции, обновления и удаления на уровне записей, путешествия во времени и откат. Apache Iceberg поддерживает эти функции в экономичных петабайтных озерах данных в Amazon S3.
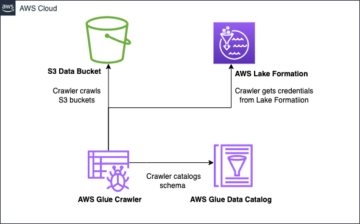
Apache Iceberg удовлетворяет потребности клиентов, собирая подробные метаданные о наборе данных во время создания отдельных файлов данных. В архитектуре таблицы Iceberg есть три уровня: каталог Iceberg, уровень метаданных и уровень данных, как показано на следующем рисунке (источник).

Каталог Iceberg хранит указатель метаданных на текущий файл метаданных таблицы. Когда запрос на выборку считывает таблицу Iceberg, обработчик запросов сначала обращается к каталогу Iceberg, а затем извлекает расположение текущего файла метаданных. При каждом обновлении таблицы Iceberg создается новый снимок таблицы, а указатель метаданных указывает на текущий файл метаданных таблицы.
Ниже приведен пример каталога Iceberg с реализацией AWS Glue. Вы можете увидеть имя базы данных, расположение (путь S3) таблицы Iceberg и расположение метаданных.

Уровень метаданных имеет три типа файлов: файл метаданных, список манифеста и файл манифеста в иерархии. На вершине иерархии находится файл метаданных, в котором хранится информация о схеме таблицы, информация о разделах и моментальные снимки. Снимок указывает на список манифестов. Список манифестов содержит информацию о каждом файле манифеста, из которого состоит моментальный снимок, например расположение файла манифеста, разделы, которым он принадлежит, а также нижние и верхние границы столбцов разделов для файлов данных, которые он отслеживает. Файл манифеста отслеживает файлы данных, а также дополнительные сведения о каждом файле, такие как формат файла. Все три файла работают в иерархии для отслеживания моментальных снимков, схемы, секционирования, свойств и файлов данных в таблице Iceberg.
Слой данных содержит отдельные файлы данных таблицы Iceberg. Iceberg поддерживает широкий спектр форматов файлов, включая Parquet, ORC и Avro. Поскольку таблица Iceberg отслеживает отдельные файлы данных, а не указывает только расположение раздела с файлами данных, она изолирует операции записи от операций чтения. Вы можете записать файлы данных в любое время, но только явно зафиксировать изменение, что создаст новую версию файлов моментальных снимков и метаданных.
Обзор решения
В этом посте мы познакомим вас с решением для создания высокопроизводительного озера данных Apache Iceberg на Amazon S3; обрабатывать добавочные данные с помощью операторов вставки, обновления и удаления SQL; и настройте таблицу Iceberg, чтобы улучшить производительность чтения и записи. Следующая диаграмма иллюстрирует архитектуру решения.

Чтобы продемонстрировать это решение, мы используем Amazon Отзывы клиентов набор данных в корзине S3 (s3://amazon-reviews-pds/parquet/). В реальном случае это будут необработанные данные, хранящиеся в вашей корзине S3. Мы можем проверить размер данных с помощью следующего кода в Интерфейс командной строки AWS (интерфейс командной строки AWS):
Общее количество объектов — 430, а общий размер — 47.4 ГиБ.
Чтобы настроить и протестировать это решение, мы выполняем следующие высокоуровневые шаги:
- Настройте корзину S3 в курируемой зоне для хранения преобразованных данных в формате таблицы Iceberg.
- Запустите кластер EMR с соответствующими конфигурациями для Apache Iceberg.
- Создайте блокнот в EMR Studio.
- Настройте сеанс Spark для Apache Iceberg.
- Преобразуйте данные в формат таблицы Iceberg и переместите данные в курируемую зону.
- Запускайте запросы на вставку, обновление и удаление в Athena для обработки добавочных данных.
- Проведите настройку производительности.
Предпосылки
Чтобы следовать этому пошаговому руководству, у вас должен быть Аккаунт AWS с Управление идентификацией и доступом AWS (IAM), которая имеет достаточный доступ для предоставления необходимых ресурсов.
Настройте корзину S3 для данных Iceberg в курируемой зоне вашего озера данных.
Выберите регион, в котором вы хотите создать корзину S3, и укажите уникальное имя:
Запустите кластер EMR для запуска заданий Iceberg с помощью Spark.
Вы можете создать кластер EMR из Консоль управления AWS, интерфейс командной строки Amazon EMR или Комплект для разработки облачных сервисов AWS (АВС ЦДК). В этом посте мы расскажем, как создать кластер EMR из консоли.
- В консоли Amazon EMR выберите Создать кластер.
- Выберите Дополнительные параметры.
- Что касается Конфигурация программного обеспечения, выберите последнюю версию Amazon EMR. По состоянию на январь 2023 года последней версией является 6.9.0. Iceberg требует версии 6.5.0 и выше.
- Выберите JupyterEnterpriseGateway и Искриться как программное обеспечение для установки.
- Что касается Изменить настройки программного обеспечения, наведите на Введите конфигурацию и введите
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - Оставьте другие настройки по умолчанию и выберите Следующая.

- Что касается Аппаратные средства, используйте настройку по умолчанию.
- Выберите Следующая.
- Что касается Имя кластера, введите имя. Мы используем
iceberg-blog-cluster. - Оставьте остальные настройки без изменений и выберите Следующая.
- Выберите Создать кластер.
Создайте блокнот в EMR Studio
Теперь мы покажем вам, как создать блокнот в EMR Studio из консоли.
- На консоли IAM создать роль службы EMR Studio.
- В консоли Amazon EMR выберите Студия ЭМР.
- Выберите Начать.
Ассоциация Начать страница появится в новой вкладке.
- Выберите Создать студию в новой вкладке.
- Введите имя. Мы используем айсберг-студию.
- Выберите тот же VPC и подсеть, что и для кластера EMR, и группу безопасности по умолчанию.
- Выберите Управление идентификацией и доступом AWS (IAM) для аутентификации и выберите только что созданную роль службы EMR Studio.
- Выберите путь S3 для Резервное копирование рабочих мест.
- Выберите Создать студию.
- После создания Studio выберите URL-адрес доступа к Studio.
- На панели инструментов EMR Studio выберите Создать рабочее пространство.
- Введите имя для вашего рабочего пространства. Мы используем
iceberg-workspace. - Расширьте Расширенная конфигурация , а затем выбрать Присоединение рабочей области к кластеру EMR.
- Выберите созданный ранее кластер EMR.
- Выберите Создать рабочее пространство.
- Выберите имя рабочей области, чтобы открыть новую вкладку.
На панели навигации есть записная книжка с тем же именем, что и рабочая область. В нашем случае это айсберг-рабочее пространство.
- Откройте блокнот.
- Когда будет предложено выбрать ядро, выберите Искриться.
Настройка сеанса Spark для Apache Iceberg
Используйте следующий код, указав собственное имя корзины S3:
Это устанавливает следующие конфигурации сеанса Spark:
- spark.sql.catalog.demo – Регистрирует каталог Spark с именем demo, в котором используется подключаемый модуль каталога Iceberg Spark.
- spark.sql.catalog.demo.catalog-импл – Демонстрационный каталог Spark использует AWS Glue в качестве физического каталога для хранения данных базы данных и таблиц Iceberg.
- spark.sql.catalog.demo.warehouse – Демонстрационный каталог Spark хранит все метаданные и файлы данных Iceberg по корневому пути, определенному этим свойством:
s3://iceberg-curated-blog-data. - искра.sql.extensions – Добавлена поддержка расширений Iceberg Spark SQL, что позволяет запускать процедуры Iceberg Spark и некоторые команды SQL только для Iceberg (вы используете это на более позднем этапе).
- spark.sql.catalog.demo.io-impl – Iceberg позволяет пользователям записывать данные в Amazon S3 через S3FileIO. Каталог данных AWS Glue по умолчанию использует этот FileIO, и другие каталоги могут загружать этот FileIO с помощью свойства каталога io-impl.
Преобразование данных в формат таблицы Iceberg
Вы можете использовать Spark на Amazon EMR или Athena для загрузки таблицы Iceberg. В сеансе Spark записной книжки EMR Studio Workspace выполните следующие команды для загрузки данных:
После запуска кода вы должны найти два префикса, созданные в пути к хранилищу данных S3 (s3://iceberg-curated-blog-data/reviews.db/all_reviews): данные и метаданные.
Обработка добавочных данных с помощью инструкций SQL вставки, обновления и удаления в Athena.
Athena — это бессерверный механизм запросов, который можно использовать для выполнения задач чтения, записи, обновления и оптимизации таблиц Iceberg. Чтобы продемонстрировать, как формат озера данных Apache Iceberg поддерживает добавочный прием данных, мы запускаем инструкции SQL вставки, обновления и удаления в озере данных.
Перейдите к консоли Athena и выберите Редактор запросов. Если вы впервые используете редактор запросов Athena, вам необходимо настроить местоположение результата запроса в качестве корзины S3, которую вы создали ранее. Вы должны увидеть, что таблица review.all_reviews доступна для запросов. Выполните следующий запрос, чтобы убедиться, что вы успешно загрузили таблицу Iceberg:
Обработайте добавочные данные, выполнив инструкции SQL вставки, обновления и удаления:
Настройка производительности
В этом разделе мы рассмотрим различные способы повышения производительности чтения и записи Apache Iceberg.
Настройка свойств таблицы Apache Iceberg
Apache Iceberg — это формат таблицы, который поддерживает свойства таблицы для настройки поведения таблицы, например чтение, запись и каталог. Вы можете повысить производительность чтения и записи в таблицах Iceberg, изменив свойства таблицы.
Например, если вы заметили, что записываете слишком много маленьких файлов для таблицы Iceberg, вы можете настроить размер записываемого файла, чтобы записывать меньше файлов большего размера, чтобы повысить производительность запросов.
| Объект | По умолчанию | Описание |
| write.target-file-size-bytes | 536870912 (512 MB) | Контролирует размер файлов, созданных для таргетинга на это количество байтов. |
Используйте следующий код, чтобы изменить формат таблицы:
Разделение и сортировка
Чтобы запрос выполнялся быстро, чем меньше данных считывается, тем лучше. Iceberg использует преимущества богатых метаданных, которые он собирает во время записи, и упрощает такие методы, как планирование сканирования, секционирование, сокращение и статистику на уровне столбца, такую как минимальные и максимальные значения, для пропуска файлов данных, которые не имеют соответствующих записей. Мы познакомим вас с тем, как планирование сканирования запросов и секционирование работают в Iceberg, и как мы используем их для повышения производительности запросов.
Планирование сканирования запросов
Для заданного запроса первым шагом в обработчике запросов является планирование сканирования, т. е. процесс поиска файлов в таблице, необходимых для запроса. Планирование в таблице Iceberg очень эффективно, поскольку богатые метаданные Iceberg можно использовать для удаления ненужных файлов метаданных, а также для фильтрации файлов данных, не содержащих совпадающих данных. В наших тестах мы наблюдали, как Athena просматривала 50 % или меньше данных для заданного запроса в таблице Iceberg по сравнению с исходными данными до преобразования в формат Iceberg.
Существует два типа фильтрации:
- Фильтрация метаданных – Iceberg использует два уровня метаданных для отслеживания файлов в моментальном снимке: список манифеста и файлы манифеста. Сначала он использует список манифестов, который действует как индекс файлов манифеста. Во время планирования Iceberg фильтрует манифесты, используя диапазон значений раздела в списке манифестов, не читая все файлы манифеста. Затем он использует выбранные файлы манифеста для получения файлов данных.
- Фильтрация данных – После выбора списка файлов манифеста Iceberg использует данные раздела и статистику на уровне столбца для каждого файла данных, хранящегося в файлах манифеста, для фильтрации файлов данных. Во время планирования предикаты запроса преобразуются в предикаты для данных раздела и сначала применяются для фильтрации файлов данных. Затем статистика столбца, такая как количество значений на уровне столбца, количество нулей, нижние и верхние границы, используются для фильтрации файлов данных, которые не могут соответствовать предикату запроса. Используя верхнюю и нижнюю границы для фильтрации файлов данных во время планирования, Iceberg значительно повышает производительность запросов.
Разделение и сортировка
Разделение — это способ сгруппировать записи с одинаковыми значениями ключевого столбца вместе в письменной форме. Преимущество секционирования заключается в более быстрых запросах, которые обращаются только к части данных, как объяснялось ранее при планировании сканирования запросов: фильтрация данных. Iceberg делает секционирование простым, поддерживая скрытое секционирование таким же образом, как Iceberg создает значения секционирования, беря значение столбца и при необходимости преобразовывая его.
В нашем случае мы сначала запускаем следующий запрос к неразделенной таблице Iceberg. Затем разбиваем таблицу Iceberg по категориям отзывов, которые будут использоваться в условии запроса WHERE для фильтрации записей. При секционировании запрос может сканировать гораздо меньше данных. См. следующий код:
Запустите следующую инструкцию select для неразделенной таблицы all_reviews и для многораздельной таблицы, чтобы увидеть разницу в производительности:
В следующей таблице показано повышение производительности при секционировании данных: повышение производительности примерно на 50 % и уменьшение количества сканируемых данных на 70 %.
| Название набора данных | Неразделенный набор данных | Секционированный набор данных |
| Время выполнения (секунды) | 8.20 | 4.25 |
| Просканировано данных (МБ) | 131.55 | 33.79 |
Обратите внимание, что время выполнения — это среднее время выполнения с несколькими запусками в нашем тесте.
Мы увидели хорошее улучшение производительности после разделения. Однако это можно улучшить, используя статистику на уровне столбцов из файлов манифеста Iceberg. Чтобы эффективно использовать статистику на уровне столбцов, вы хотите дополнительно отсортировать записи на основе шаблонов запросов. Сортировка всего набора данных с использованием столбцов, которые часто используются в запросах, приведет к переупорядочению данных таким образом, что каждый файл данных будет иметь уникальный диапазон значений для определенных столбцов. Если эти столбцы используются в условии запроса, это позволяет механизмам запросов дополнительно пропускать файлы данных, тем самым обеспечивая еще более быстрые запросы.
Копирование при записи против чтения при объединении
При реализации обновления и удаления таблиц Iceberg в озере данных существует два подхода, определяемых свойствами таблицы Iceberg:
- Копирование при записи – При таком подходе при внесении изменений в таблицу Iceberg, будь то обновление или удаление, файлы данных, связанные с затронутыми записями, будут продублированы и обновлены. Записи будут либо обновлены, либо удалены из дублированных файлов данных. Будет создан новый снимок таблицы Iceberg, указывающий на более новую версию файлов данных. Это замедляет общую запись. Могут быть ситуации, когда одновременная запись необходима с конфликтами, поэтому должна произойти повторная попытка, что еще больше увеличивает время записи. С другой стороны, при чтении данных дополнительный процесс не требуется. Запрос извлечет данные из последней версии файлов данных.
- Слияние при чтении – При таком подходе при обновлении или удалении таблицы Iceberg существующие файлы данных не будут перезаписываться; вместо этого будут созданы новые файлы удаления для отслеживания изменений. Для удалений будет создан новый файл удаления с удаленными записями. При чтении таблицы Iceberg файл удаления будет применен к извлеченным данным, чтобы отфильтровать удаляемые записи. Для обновлений будет создан новый файл удаления, чтобы пометить обновленные записи как удаленные. Затем для этих записей будет создан новый файл, но с обновленными значениями. При чтении таблицы Iceberg к полученным данным будут применены как файлы удаления, так и новые файлы, чтобы отразить последние изменения и получить правильные результаты. Таким образом, для любых последующих запросов произойдет дополнительный шаг для объединения файлов данных с удалением и новыми файлами, что обычно увеличивает время запроса. С другой стороны, запись может выполняться быстрее, поскольку нет необходимости перезаписывать существующие файлы данных.
Чтобы проверить влияние двух подходов, вы можете запустить следующий код, чтобы задать свойства таблицы Iceberg:
Запустите SQL-операторы обновления, удаления и выбора в Athena, чтобы показать разницу во времени выполнения для копирования при записи и слияния при чтении:
В следующей таблице приведены сведения о времени выполнения запросов.
| запрос | Копирование при записи | Слияние при чтении | ||||
| ОБНОВЛЕНИЕ ПО | УДАЛИТЬ | ВЫБОР | ОБНОВЛЕНИЕ ПО | УДАЛИТЬ | ВЫБОР | |
| Время выполнения (секунды) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| Просканировано данных (МБ) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
Обратите внимание, что время выполнения — это среднее время выполнения с несколькими запусками в нашем тесте.
Как показывают результаты наших тестов, в обоих подходах всегда есть компромиссы. Какой подход использовать, зависит от ваших вариантов использования. Таким образом, соображения сводятся к задержке чтения и записи. Вы можете обратиться к следующей таблице и сделать правильный выбор.
| . | Копирование при записи | Слияние при чтении |
| Плюсы | Быстрее читает | Быстрее пишет |
| Минусы | Дорого пишет | Более высокая задержка при чтении |
| Когда использовать | Подходит для частых чтений, нечастых обновлений и удалений или больших пакетных обновлений. | Подходит для таблиц с частыми обновлениями и удалениями |
Сжатие данных
Если размер вашего файла данных невелик, вы можете получить тысячи или миллионы файлов в таблице Iceberg. Это резко увеличивает количество операций ввода-вывода и замедляет запросы. Более того, Iceberg отслеживает каждый файл данных в наборе данных. Чем больше файлов данных, тем больше метаданных. Это, в свою очередь, увеличивает накладные расходы и операции ввода-вывода при чтении файлов метаданных. Чтобы повысить производительность запросов, рекомендуется сжимать небольшие файлы данных в файлы большего размера.
При обновлении и удалении записей в таблице Iceberg, если используется подход чтения при слиянии, вы можете получить множество небольших удалений или новых файлов данных. Запуск сжатия объединит все эти файлы и создаст более новую версию файла данных. Это избавляет от необходимости согласовывать их во время чтения. Рекомендуется выполнять регулярные задания сжатия, чтобы как можно меньше влиять на чтение, сохраняя при этом более высокую скорость записи.
Запустите следующую команду сжатия данных, затем запустите запрос выбора из Athena:
В следующей таблице сравнивается время выполнения до и после сжатия данных. Вы можете увидеть улучшение производительности примерно на 40%.
| запрос | Перед сжатием данных | После сжатия данных |
| Время выполнения (секунды) | 97.75 | 32.676 секунд |
| Просканировано данных (МБ) | 137.16 M | 189.19 M |
Обратите внимание, что запросы на выборку выполнялись на all_reviews таблица после операций обновления и удаления, до и после сжатия данных. Время выполнения — это среднее время выполнения с несколькими запусками в нашем тесте.
Убирать
Выполнив пошаговое руководство по решению для выполнения вариантов использования, выполните следующие действия, чтобы очистить ресурсы и избежать дополнительных затрат.
- Перетащите таблицы и базу данных AWS Glue из Athena или выполните следующий код в своей записной книжке:
- На консоли EMR Studio выберите Workspaces в навигационной панели.
- Выберите созданное вами рабочее пространство и выберите Удалить.
- На консоли EMR перейдите к Студии стр.
- Выберите созданную вами студию и выберите Удалить.
- В консоли EMR выберите Кластеры в навигационной панели.
- Выберите кластер и выберите прекратить.
- Удалите корзину S3 и любые другие ресурсы, которые вы создали в рамках предварительных условий для этого сообщения.
Заключение
В этом посте мы представили платформу Apache Iceberg и то, как она помогает решить некоторые проблемы, с которыми мы сталкиваемся в современном озере данных. Затем мы познакомили вас с решением для обработки добавочных данных в озере данных с помощью Apache Iceberg. Наконец, мы глубоко погрузились в настройку производительности, чтобы улучшить производительность чтения и записи для наших вариантов использования.
Мы надеемся, что этот пост содержит полезную информацию, которая поможет вам решить, хотите ли вы использовать Apache Iceberg в своем решении для озера данных.
Об авторах
 Флора Ву является старшим архитектором-резидентом в AWS Data Lab. Она помогает корпоративным клиентам создавать стратегии анализа данных и создавать решения для ускорения результатов их бизнеса. В свободное время она любит играть в теннис, танцевать сальсу и путешествовать.
Флора Ву является старшим архитектором-резидентом в AWS Data Lab. Она помогает корпоративным клиентам создавать стратегии анализа данных и создавать решения для ускорения результатов их бизнеса. В свободное время она любит играть в теннис, танцевать сальсу и путешествовать.
 Даниэль Ли является старшим архитектором решений в Amazon Web Services. Он фокусируется на помощи клиентам в разработке, внедрении и внедрении облачных услуг и стратегии. Когда он не работает, он любит проводить время на свежем воздухе со своей семьей.
Даниэль Ли является старшим архитектором решений в Amazon Web Services. Он фокусируется на помощи клиентам в разработке, внедрении и внедрении облачных услуг и стратегии. Когда он не работает, он любит проводить время на свежем воздухе со своей семьей.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- в состоянии
- О нас
- выше
- ускорять
- доступ
- управление доступом
- Действие
- акты
- дополнение
- дополнительный
- адрес
- адреса
- Добавляет
- принять
- плюс
- После
- против
- Все
- позволяет
- всегда
- Amazon
- Амазонка ЭМИ
- Amazon Web Services
- аналитический
- аналитика
- и
- объявило
- апаш
- Приложения
- прикладной
- подхода
- подходы
- соответствующий
- архитектура
- связанный
- Аутентификация
- свободных мест
- доступен
- в среднем
- избежать
- AWS
- Клей AWS
- основанный
- , так как:
- становиться
- до
- польза
- Лучшая
- между
- больший
- Начальная загрузка
- строить
- Строительство
- бизнес
- перехватывает
- Захват
- случаев
- случаев
- каталог
- каталоги
- Категории
- проблемы
- изменение
- изменения
- проверка
- выбор
- Выберите
- классификация
- облако
- облачные сервисы
- Кластер
- код
- Column
- Колонки
- объединять
- как
- совершать
- сравненный
- полный
- Вычисление
- параллельный
- состояние
- Конфигурации
- соображения
- Консоли
- Конверсия
- переделанный
- рентабельным
- Расходы
- может
- Создайте
- создали
- создает
- Куратор
- Текущий
- клиент
- Клиенты
- танцы
- приборная панель
- данным
- Анализ данных
- Озеро данных
- обработка данных
- информационное хранилище
- База данных
- Наборы данных
- глубоко
- глубокое погружение
- По умолчанию
- определенный
- Демо
- демонстрировать
- зависит
- предназначенный
- подробнее
- развивать
- Разработка
- разница
- различный
- обсуждать
- Dont
- вниз
- драматично
- Падение
- в течение
- каждый
- Ранее
- Рано
- редактор
- фактически
- эффективный
- или
- ликвидирует
- включен
- позволяет
- окончания поездки
- Двигатель
- Двигатели
- Enter
- Предприятие
- корпоративные клиенты
- Эфир (ETH)
- Даже
- эволюция
- развивается
- развивается
- пример
- существующий
- существует
- объяснены
- расширения
- дополнительно
- облегчает
- семья
- БЫСТРО
- быстрее
- Особенности
- фигура
- Файл
- Файлы
- фильтр
- фильтрация
- фильтры
- в заключение
- Найдите
- First
- Впервые
- фокусируется
- следовать
- после
- формат
- Рамки
- частое
- от
- далее
- Более того
- Общие
- генерируется
- получить
- данный
- идет
- хорошо
- значительно
- группы
- рука
- происходить
- помощь
- помощь
- помогает
- Скрытый
- иерархия
- на высшем уровне
- высокая производительность
- высокопроизводительный
- Hive
- надежды
- Как
- How To
- Однако
- HTML
- HTTPS
- IAM
- Личность
- управление идентификацией и доступом
- Влияние
- влияние
- осуществлять
- реализация
- Осуществляющий
- улучшать
- улучшенный
- улучшение
- улучшается
- in
- В том числе
- Увеличение
- расширились
- Увеличивает
- индекс
- individual
- информация
- устанавливать
- вместо
- интеграции.
- выпустили
- изоляты
- IT
- январь
- Джобс
- Основные
- лаборатория
- озеро
- большой
- больше
- Задержка
- последний
- последний релиз
- слой
- слоев
- вести
- уровни
- ОГРАНИЧЕНИЯ
- линия
- Список
- мало
- загрузка
- расположение
- сделать
- ДЕЛАЕТ
- управление
- многих
- отметка
- рынка
- Совпадение
- согласование
- идти
- Метаданные
- может быть
- миллионы
- Модерн
- БОЛЕЕ
- двигаться
- с разными
- имя
- Названный
- Откройте
- Навигация
- Необходимость
- необходимый
- потребности
- Новые
- ноутбук
- объект
- открытый
- операция
- Операционный отдел
- оптимизация
- Оптимизировать
- заказ
- оригинал
- Другие контрактные услуги
- на открытом воздухе
- общий
- собственный
- хлеб
- часть
- путь
- паттеранами
- выполнять
- производительность
- физический
- планирование
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- игры
- плагин
- пунктов
- Популярное
- возможное
- После
- Питание
- предпосылки
- Процедуры
- процесс
- обработка
- производит
- свойства
- собственность
- обеспечивать
- приводит
- обеспечение
- обеспечение
- ассортимент
- Сырье
- необработанные данные
- Читать
- Reading
- реальные
- недавно
- Управление по борьбе с наркотиками (DEA)
- учет
- отражать
- область
- регистры
- регулярный
- освободить
- выпустил
- осталось
- обязательный
- требуется
- Полезные ресурсы
- результат
- Итоги
- Отзывы
- Богатые
- Роли
- корень
- Run
- Бег
- то же
- сканирование
- секунды
- Раздел
- безопасность
- выбранный
- выбор
- Serverless
- обслуживание
- Услуги
- Сессия
- набор
- Наборы
- установка
- настройки
- должен
- показывать
- Шоу
- просто
- обстоятельства
- Размер
- замедляет
- небольшой
- Снимок
- So
- Software
- Решение
- Решения
- некоторые
- Искриться
- конкретный
- скорость
- Расходы
- SQL
- Начало
- Область
- заявление
- отчетность
- Статистика
- Шаг
- Шаги
- По-прежнему
- диск
- магазин
- хранить
- магазины
- стратегий
- Стратегия
- структурированный
- структурированные и неструктурированные данные
- студия
- подсети
- последующее
- Успешно
- такие
- достаточный
- РЕЗЮМЕ
- поддержка
- Поддержанный
- поддержки
- Поддержка
- ТАБЛИЦЫ
- принимает
- с
- цель
- задачи
- снижения вреда
- теннис
- тестXNUMX
- Тестирование
- тестов
- Ассоциация
- информация
- Государство
- их
- тем самым
- тысячи
- три
- Через
- время
- путешествие во времени
- в
- вместе
- слишком
- инструменты
- топ
- Всего
- трек
- Сделки
- превращение
- путешествовать
- Путешествие
- ОЧЕРЕДЬ
- Типы
- под
- созданного
- Обновление ПО
- обновление
- Updates
- обновление
- URL
- использование
- прецедент
- пользователей
- обычно
- VAL
- ценностное
- Наши ценности
- проверить
- версия
- ходил
- прохождение
- Склады
- часы
- способы
- Web
- веб-сервисы
- Что
- будь то
- который
- в то время как
- широкий
- Широкий диапазон
- будете
- без
- Работа
- работает
- работает
- бы
- записывать
- письмо
- ВАШЕ
- зефирнет