Хотите извлечь данные с веб-страницы?
Отправляйтесь в Нанонец парсер веб-сайтов, Добавьте URL-адрес и нажмите «Очистить», чтобы мгновенно загрузить текст веб-страницы в виде файла. Попробуйте бесплатно прямо сейчас.
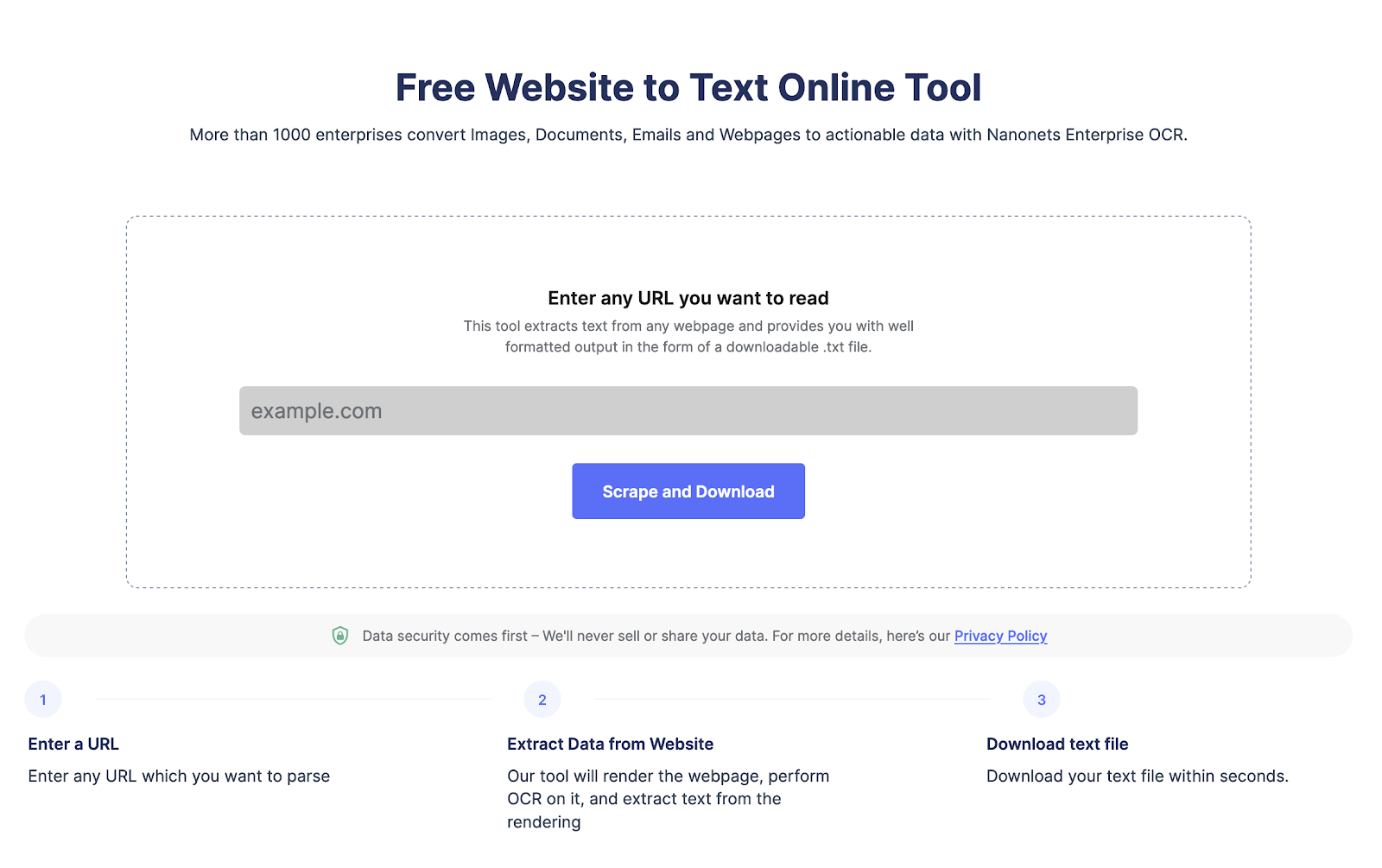
Что такое веб-скрапинг и его преимущества?
Веб-скрапинг используется для автоматического извлечения данных с веб-страниц в больших масштабах. Очистка веб-страниц выполняется для преобразования данных в сложных структурах HTML в структурированный формат, такой как электронная таблица или база данных, и используется для различных целей, таких как исследования, анализ и автоматизация.
Вот некоторые из причин, по которым люди используют веб-скрапинг:
- Эффективно извлекайте данные веб-страницы для расширенного анализа.
- Следите за развитием веб-сайтов конкурентов и следите за изменениями в их предложениях продуктов, тактике или ценах.
- Извлеките лиды или данные электронной почты из LinkedIn или другого каталога.
- Автоматизируйте такие задачи, как ввод данных, заполнение форм и другие повторяющиеся задачи, экономя ваше время и повышая эффективность.
Почему вам следует использовать Node.js для парсинга веб-страниц?
Node.js широко используется, поскольку это легкая, высокопроизводительная и эффективная платформа. Вот несколько причин, по которым node.js — отличный выбор для парсинга веб-страниц:
- Node.js может обрабатывать несколько запросов на парсинг веб-страниц параллельно.
- Он имеет большое сообщество, которое обеспечивает поддержку и создает значимые библиотеки веб-скрейпинга.
- Node.js является кроссплатформенным, что делает его универсальным выбором для проектов веб-скрейпинга.
- Node.js легко освоить, особенно если вы уже знаете JavaScript.
- Node.js имеет встроенную поддержку HTTP-запросов, что упрощает получение и анализ HTML-страниц с веб-сайтов.
- Node.js обладает высокой масштабируемостью, что важно для парсинга веб-страниц при обработке большого объема данных.
Хотите извлечь данные с веб-страницы?
Отправляйтесь в Нанонец парсер веб-сайтов, Добавьте URL-адрес и нажмите «Очистить», чтобы мгновенно загрузить текст веб-страницы в виде файла. Попробуйте бесплатно прямо сейчас.
Как очистить веб-страницы с помощью Node JS?
Шаг 1 Настройка вашей среды:
Вы должны установить node.js, если вы еще этого не сделали. Скачать его можно с официального сайта.
Шаг 2 Установка необходимых пакетов для парсинга веб-страниц с помощью Node.js:
Node.js имеет несколько вариантов парсинга веб-страниц, таких как Cheerio, Puppeteer и request. Вы можете легко установить их, используя следующую команду.
npm install cheerio
npm install puppeteer
npm install requestШаг 3 Настройка каталога вашего проекта:
Вам нужно создать новый каталог для нового проекта. А затем перейдите в командную строку, чтобы создать новый файл для хранения вашего кода парсинга веб-страниц NodeJS.
Вы можете создать новый каталог и новый файл, используя следующую команду:
mkdir my-web-scraper
cd my-web-scraper
touch scraper.jsШаг 4. Выполнение HTTP-запросов с помощью Node.js:
Чтобы парсить веб-страницы, вам нужно делать HTTP-запросы. Теперь Node.js имеет встроенный модуль http. Это упрощает выполнение запросов. Вы также можете использовать аксиомы или запросы, чтобы сделать запрос.
Вот код для выполнения http-запросов с помощью node.js
const http = require('http');
const url = 'http://example.com';
http.get(url, (res) => {
let data = '';
res.on('data', (chunk) => {
data += chunk;
});
res.on('end', () => {
console.log(data);
});
});Замените http.//example.com URL-адресом по вашему выбору, чтобы очистить веб-страницы,
Шаг 5. Очистка HTML с помощью Node.js:
Когда у вас есть HTML-контент веб-страницы, вам нужно проанализировать его, чтобы извлечь нужные данные. Для анализа HTML в Node.js доступно несколько сторонних библиотек, таких как Cheerio и JSDOM.
Вот пример фрагмента кода, использующего Cheerio для анализа HTML и извлечения данных:
const cheerio = require('cheerio');
const request = require('request');
const url = 'https://example.com';
request(url, (error, response, html) => {
if (!error && response.statusCode == 200) {
const $ = cheerio.load(html);
const title = $('title').text();
const firstParagraph = $('p').first().text();
console.log(title);
console.log(firstParagraph);
}
});Этот код использует библиотеку запросов для получения HTML-содержимого веб-страницы по URL-адресу, а затем использует Cheerio для анализа HTML и извлечения заголовка и первого абзаца.
Как обрабатывать javascript и динамический контент с помощью Node.js?
Многие современные веб-страницы используют JavaScript для отображения динамического содержимого, что затрудняет его очистку. Для обработки JavaScript-рендеринга вы можете использовать безголовые браузеры, такие как Puppeteer и Playwright, которые позволяют имитировать среду браузера и очищать динамический контент.
Вот пример фрагмента кода, использующего Puppeteer для очистки веб-страницы, которая отображает контент с помощью JavaScript:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('title', el => el.textContent);
const firstParagraph = await page.$eval('p', el => el.textContent);
console.log(title);
console.log(firstParagraph);
await browser.close();
})();Этот код использует Puppeteer для запуска безголового браузера, перехода на веб-страницу по URL-адресу и извлечения заголовка и первого абзаца. Метод page.$eval() выбирает и извлекает данные из элементов HTML.
Вот несколько библиотек, которые вы можете использовать для простого парсинга веб-страниц с помощью NodeJS:
Приветствую: — это быстрая, гибкая и легкая реализация ядра jQuery, разработанная для серверной части.
JSDOM: — это реализация модели DOM для Node.js на чистом JavaScript. Он предоставляет способ создать среду DOM в Node.js и управлять ею с помощью стандартного API.
Кукольник: — это библиотека Node.js, предоставляющая высокоуровневый API для управления безголовым Chrome или Chromium. Его можно использовать для просмотра веб-страниц, автоматического тестирования, сканирования и рендеринга.
Лучшие практики для парсинга веб-страниц с помощью Node.js
Вот несколько рекомендаций, которым следует следовать при использовании Node.js для парсинга веб-страниц:
- Перед парсингом веб-сайта ознакомьтесь с их условиями использования. Убедитесь, что веб-страница не имеет ограничений на парсинг или частоту парсинга веб-страниц.
- Ограничьте количество HTTP-запросов, чтобы предотвратить перегрузку веб-сайта, контролируя частоту запросов.
- Установите соответствующие заголовки в ваших HTTP-запросах, чтобы имитировать поведение обычного пользователя.
- Кэшируйте веб-страницы и извлеченные данные, чтобы снизить нагрузку на сайт.
- Веб-скрапинг может быть подвержен ошибкам из-за сложности и изменчивости веб-сайтов.
- Отслеживайте и корректируйте свою активность по скрейпингу, а также корректируйте ограничение скорости, заголовки и другие параметры по мере необходимости.
Хотите извлечь данные с веб-страницы?
Отправляйтесь в Нанонец парсер веб-сайтов, Добавьте URL-адрес и нажмите «Очистить», чтобы мгновенно загрузить текст веб-страницы в виде файла. Попробуйте бесплатно прямо сейчас.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://nanonets.com/blog/web-scraping-with-node-js/
- :является
- ][п
- $UP
- 1
- 2023
- a
- деятельность
- продвинутый
- уже
- анализ
- и
- API
- соответствующий
- МЫ
- AS
- At
- Автоматизированный
- автоматически
- автоматизация
- доступен
- Ждите
- Вардар
- BE
- Преимущества
- ЛУЧШЕЕ
- лучшие практики
- браузер
- браузеры
- встроенный
- by
- CAN
- CD
- изменение
- проверка
- выбор
- Chrome
- хром
- нажмите на
- код
- COM
- сообщество
- конкурент
- комплекс
- сложность
- Консоли
- содержание
- контроль
- управление
- конвертировать
- Основные
- Создайте
- создает
- кросс-платформенной
- данным
- ввод данных
- База данных
- предназначенный
- события
- трудный
- не
- DOM
- скачать
- динамический
- легко
- легко
- затрат
- эффективный
- эффективно
- элементы
- обеспечивать
- запись
- Окружающая среда
- ошибка
- особенно
- Эфир (ETH)
- пример
- извлечение
- извлечь данные
- Экстракты
- Глаза
- БЫСТРО
- Файл
- First
- гибкого
- следовать
- после
- Что касается
- форма
- формат
- Бесплатно
- частота
- от
- большой
- обрабатывать
- Есть
- Заголовки
- здесь
- на высшем уровне
- высокая производительность
- очень
- HTML
- HTTP
- HTTPS
- реализация
- важную
- улучшение
- in
- устанавливать
- IT
- ЕГО
- JavaScript
- JQuery
- Сохранить
- Знать
- большой
- большое сообщество
- запуск
- Лиды
- УЧИТЬСЯ
- библиотеки
- Библиотека
- легкий
- такое как
- загрузка
- сделать
- ДЕЛАЕТ
- Создание
- значимым
- метод
- Модерн
- модуль
- с разными
- Откройте
- необходимо
- Необходимость
- необходимый
- Новые
- узел
- Node.js
- номер
- of
- Предложения
- Официальный представитель в Грузии
- Официальный веб-сайт
- on
- Опции
- заказ
- Другое
- пакеты
- страница
- Люди
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- практиками
- предотвращать
- цены
- обработка
- Продукт
- Проект
- приводит
- целей
- Обменный курс
- Читать
- причины
- уменьшить
- регулярный
- оказание
- оказывает
- повторяющийся
- запросить
- Запросы
- исследованиям
- ответ
- Ограничения
- экономия
- масштабируемые
- Шкала
- выскабливание
- установка
- настройки
- несколько
- должен
- некоторые
- Таблица
- стандарт
- магазин
- структурированный
- такие
- поддержка
- тактика
- задачи
- terms
- Тестирование
- который
- Ассоциация
- их
- Их
- сторонние
- время
- Название
- в
- трогать
- URL
- использование
- Информация о пользователе
- различный
- разносторонний
- объем
- Путь..
- Web
- соскоб
- Вебсайт
- веб-сайты
- который
- ВАШЕ
- зефирнет