Predstavitev
Vsak podatkovni znanstvenik potrebuje učinkovito in zanesljivo orodje za obdelavo teh velikih neustavljivih podatkov. Danes razpravljamo o enem takem orodju, imenovanem Delta Lake, ki ga ljubitelji podatkov uporabljajo za učinkovitejše in zanesljivejše procese obdelave podatkov.
V bistvu je Delta Lake odprtokodna plast za shranjevanje, ki leži na naši obstoječi infrastrukturi za shranjevanje podatkov in omogoča uveljavljanje sheme, različice in transakcije ACID (atomičnost, doslednost, izolacija in trajnost) za naše podatke. Delta Lake ponuja številne prednosti, kot je upravljanje ogromne količine podatkov, možnost enostavnega povrnitve sprememb in zagotavljanje doslednosti podatkov v več sejah Spark.
Če se pripravljate na intervju za Delta Lake, ste pristali na pravem blogu. Tukaj razpravljamo o najpogosteje zastavljenih vprašanjih za razgovor o Delta Lakeu.
Učni cilji
Spodaj je tisto, kar se bomo naučili po natančnem branju tega spletnega dnevnika:
- Razumevanje, kaj je Delta Lake in kakšno vlogo igra v tehnični dobi.
- Poznavanje njegovega odnosa z Apache Spark.
- Razumevanje postopka vstavljanja ali nalaganja podatkov v Delta Lake.
- Razumevanje komponent Delta Lake in njihovih lastnosti, skladnih s standardom ACID.
- Vpogled v koncepte, kot so Upserts, načini branja podatkov ter operacije Batch in Streaming v Delta Lake.
Na splošno bomo z branjem tega vodnika pridobili celovito razumevanje Delta Lake za shranjevanje podatkov. Ko končamo ta spletni dnevnik, imamo dovolj znanja in sposobnosti za učinkovito uporabo te tehnike in odgovarjanje na pogosta poizvedbe na srednji ravni, vi pa boste lahko opravili svoj intervju z delta jezerom.
.
Ta članek je bil objavljen kot del Blogaton podatkovne znanosti.
Kazalo
Q1. Kako se Delta Lake razlikuje od drugih slojev transakcijskega shranjevanja?
Čeprav Delta Lake rešuje enake izzive, kot jih rešujejo druge transakcijske plasti, to ni to; ima širšo pokritost primerov uporabe v podatkovnem ekosistemu, kar mu zagotavlja slavo. Delta Lake zagotavlja varnost podatkov, zanesljivost in boljšo zmogljivost ter ponuja enoten okvir za paketne in pretočne delovne obremenitve. Izboljša učinkovitost različnih nadaljnjih dejavnosti, kot so BI, ML, podatkovna znanost in cevovodi za pretvorbo podatkov.
Vir: kpipartners
Poleg tega lahko za več koristi uporabimo Delta Lake Podatkovne palice; zagotavlja širšo ekosistemsko podporo s hitrejšimi izvornimi priključki za najbolj priljubljena orodja poslovne inteligence, omogoča boljšo zmogljivost z Delta Engine ter nudi boljšo varnost in upravljanje z natančnimi kontrolami dostopa.
Končno, pri statističnih podatkih, jezera Delta vsak dan zaužijejo približno 3 petabajte podatkov, ki so bili v proizvodnji več kot 3 leta; na tisoče uporabnikov uporablja Delta Lake na Databricks.
Q2. Pojasnite, kako so Delta Lakes skladna s standardom ACID.
Delta Lakes so KISLINA skladen, ker:
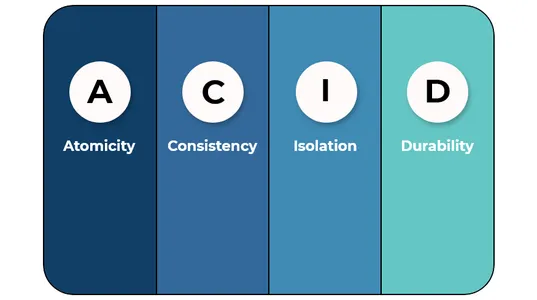
A (Atomičnost)- Delta Lake ponuja atomske transakcije, kar pomeni, da so vse spremembe podatkov v tabeli Delta bodisi odobrene bodisi vse povrnjene.
C (doslednost)- Delta Lake ponuja konsistentnost podatkov, kar pomeni, da bodo čitalniki podatkov vedno brali iste podatke ob začetku transakcije.
jaz (izolacija)- Podatkovna jezera s pomočjo funkcije potovanja skozi čas podpirajo izolacijo in uporabnikom omogočajo, da si kadar koli ogledajo podatke, kakršni obstajajo.
D (trpežnost)- Data Lake podpira vzdržljivost s prikazom vseh transakcijskih sprememb kljub okvaram sistema.
Q3. Pojasnite razmerje Delta Lake in Apache Spark.
Delta Lake je orodje, zgrajeno na vrhu Apache Spark in ponuja pot za upravljanje shranjevanja in izboljšanje zmogljivosti za aplikacije Spark. Delta Lake izboljša zmogljivost, ko Spark bere in piše podatke s shranjevanjem podatkov v datoteke Parquet. Uporablja stolpčni format in za zagotavljanje doslednosti podatkov ponuja način za upravljanje transakcij in spremljanje sprememb podatkov.
Q4. Zakaj uporabljati Delta Lake, če lahko shranjujemo podatke v obliki parketa na S3 ali HDFS?
Delta Lake je dobra izbira namesto Parquet, ko moramo izvesti obsežno obdelavo podatkov, saj ponuja visoko razširljivost in boljšo zmogljivost. Tudi kljub izpadom električne energije ali okvaram strojne opreme bodo podatki ostali varni pred poškodbami zaradi ACID-združljive zasnove Delta Lakes.
V5. Pojasnite postopek uvoza podatkov v Delta Lake.
Podatke lahko uvozimo v Delta Lake samo z uporabo Podatkovne palice orodje Auto Loader ali ukaz COPY INTO s SQL; samodejno sprejme nove podatkovne datoteke v Delta Lake, ker pridejo v naše podatkovno jezero (tj. na S3 ali ADLS). Poleg tega lahko uporabimo Apache SparkTM za paketno branje naših podatkov tako, da izvedemo potrebne spremembe in shranimo rezultat v Delta Lake.
V6. Pojasnite glavne sestavne dele jezera Delta.
Delta Lake sestavljajo tri pomembne komponente tabela Delta, dnevnik Delta in predpomnilnik Delta.
Delta tabela: To je osrednji del za shranjevanje, ki nosi vse podatke za Delta Lake.
Delta Log: Dnevnik transakcij se uporablja za sledenje ali spremljanje vseh sprememb tabele Delta.
Delta predpomnilnik: Je stolpčni predpomnilnik in tako kot običajni predpomnilnik shranjuje trenutno različico podatkov v tabeli Delta.
V7. Kako izvajamo Upserts v Delta Lake?
Upsert je kombinacija dveh besed/operacij, tj. Posodobi in Vstavi. Upsert v delta lake lahko izvajamo z ukazoma MERGE in INSERT INTO:
Spajanje: S pomočjo ukaza MERGE lahko posodobimo ali vstavimo poljubne podatke v Delta tabelo, odvisno od danega stanja. S klavzulo WHERE postavimo pogoj za kateri koli ukaz in če je pogoj resničen, se izvede dejanje UPDATE; če je rezultat pogoja false, se izvede dejanje INSERT.
Vstavi:S pomočjo ukaza INSERT INTO lahko vnesemo podatke v tabelo Delta, vendar bo ta ukaz v tabelo vstavil le nove vrstice, brez operacije posodabljanja obstoječih vrstic.
V8. Pojasnite različne načine, ki so na voljo za branje podatkov iz tabele Delta Lake.
Za branje podatkov iz tabele Delta Lake imamo na voljo dva načina:
1. Način popolnega skeniranja: Ta način se uporablja za branje celotne vsebine tabele Delta Lake.
2. Način postopnega skeniranja: Ta način se uporablja samo za branje podatkov, vstavljenih ali spremenjenih od zadnjega branja tabele Delta.
V9. Pojasnite pomen paketnih in pretočnih operacij v jezeru Delta.
Z Delta Lake lahko izvajamo paketne in pretočne operacije na eni sami poenostavljeni arhitekturi, s čimer se izognemo zapletenim, redundantnim sistemom in operativnim izzivom. V Delta Lake je tabela hkrati paketna tabela in pretočni vir.
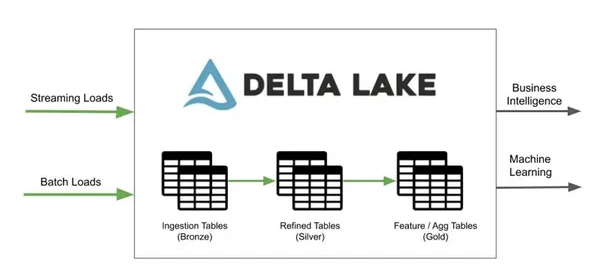
Vir: hevodata.com
Kar zadeva pomembnost, interaktivne poizvedbe, pretočni vnos podatkov in paketno zgodovinsko zapolnjevanje delujejo takoj po namestitvi in se neposredno integrirajo s Spark Structured Streaming.
V10. Kako lahko naložimo podatke v tabelo iz drugega datotečnega sistema v Delta Lake?
Za izvedbo operacije nalaganja Delta Lake podpira postopek, imenovan »upserts«. Naloži podatke v tabelo Delta iz drugega obstoječega datotečnega sistema. V tem procesu najprej preverimo, ali vrstica z istim primarnim ključem že obstaja v tabeli ali ne. Če vrstica obstaja, se posodobi z novimi podatki; sicer se vstavi v tabelo.
zaključek
Ta blog pokriva nekatera pogosto zastavljena vprašanja o intervjuju Delta Lake, ki bi jih lahko postavili v intervjujih o podatkovni znanosti in intervjujih z razvijalci velikih podatkov. Če uporabite ta vprašanja za razgovor o jezeru delta kot referenco, lahko bolje razumete koncepte in oblikujete učinkovite odgovore za prihajajoče intervjuje. Ključni povzetki tega bloga Delta Lake so:-
- Delta Lake je odprtokodna plast za shranjevanje, skladna z ACID, ki leži na vrhu naše obstoječe infrastrukture za shranjevanje podatkov.
- Delta Lake nam olajša upravljanje ogromne količine podatkov in ohranjanje doslednosti podatkov v več sejah Spark.
- Delta Lake je boljši od različnih slojev za shranjevanje transakcij v smislu
- Razpravljali smo o upsertih, načinu nalaganja podatkov v tabele Data Lake.
- V tem blogu smo razpravljali tudi o komponentah Delta Lake, vključno s tabelo, dnevnikom in predpomnilnikom Delta.
Mediji, prikazani v tem članku, niso v lasti Analytics Vidhya in se uporabljajo po lastni presoji avtorja.
Podobni
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://www.analyticsvidhya.com/blog/2023/02/ace-your-interview-with-top-10-interview-questions-on-delta-lake/
- 10
- 11
- a
- sposobnost
- Sposobna
- dostop
- čez
- Ukrep
- dejavnosti
- po
- vsi
- že
- vedno
- analitika
- Analitika Vidhya
- in
- Še ena
- odgovori
- Apache
- Apache Spark
- aplikacije
- Arhitektura
- okoli
- članek
- avto
- samodejno
- Na voljo
- izogibanje
- nazaj
- Osnova
- ker
- počutje
- Prednosti
- Boljše
- Big
- Big Podatki
- Blog
- blogaton
- Pasovi
- širši
- zgrajena
- poslovni
- Poslovna inteligenca
- predpomnilnik
- se imenuje
- previdno
- primeru
- Osrednji
- izzivi
- Spremembe
- preveriti
- izbira
- kombinacija
- kako
- prihajajo
- storjeno
- Skupno
- dokončanje
- kompleksna
- skladno
- deli
- celovito
- koncepti
- Sklenitev
- stanje
- Vsebina
- Nadzor
- Korupcija
- bi
- pokritost
- prevleke
- Trenutna
- vsak dan
- datum
- Data jezero
- obdelava podatkov
- znanost o podatkih
- podatkovni znanstvenik
- Varovanje podatkov
- shranjevanje podatkov
- Podatkovne palice
- Delta
- zahteve
- Odvisno
- Oblikovanje
- Kljub
- Razvojni
- se razlikujejo
- drugačen
- neposredno
- diskretnost
- razpravlja
- razpravljali
- trajnost
- enostavno
- ekosistem
- Učinkovito
- učinkovito
- učinkovitosti
- učinkovite
- bodisi
- omogoča
- izvršba
- Motor
- Izboljša
- dovolj
- zagotovitev
- Ljubitelji
- Celotna
- Era
- obstoječih
- obstaja
- Pojasnite
- olajša
- GLAD
- hitreje
- Feature
- file
- datoteke
- prva
- format
- Okvirni
- pogosto
- iz
- polno
- Gain
- dobili
- dana
- dobro
- upravljanje
- vodi
- strojna oprema
- pomoč
- tukaj
- visoka
- Zgodovinski
- Kako
- HTTPS
- velika
- uvoz
- Pomembno
- uvoz
- izboljšuje
- in
- Vključno
- Infrastruktura
- integrirati
- Intelligence
- interaktivno
- Intervju
- vprašanja za intervju
- Intervjuji
- Predstavitev
- izolacija
- IT
- Imejte
- Ključne
- znanje
- Jezero
- obsežne
- Zadnja
- plast
- plasti
- UČITE
- obremenitev
- nakladač
- nalaganje
- obremenitve
- je
- Glavne
- Znamka
- upravljanje
- upravljanje
- upravljanje
- mediji
- Spoji
- ML
- način
- načini
- spremembe
- spremembe
- monitor
- več
- učinkovitejše
- Najbolj
- Najbolj popularni
- več
- materni
- nav
- potrebno
- Novo
- normalno
- Ponudbe
- ONE
- open source
- Delovanje
- operativno
- operacije
- Ostalo
- drugače
- Izpusti
- Rezultat
- v lasti
- del
- pot
- opravlja
- performance
- izvajati
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Popular
- moč
- priprava
- primarni
- Postopek
- obravnavati
- proizvodnja
- Lastnosti
- zagotavlja
- zagotavljanje
- objavljeno
- dal
- Q1
- Q2
- Q3
- vprašanja
- Preberi
- bralci
- reading
- Razmerje
- zanesljivost
- zanesljiv
- ostajajo
- Odzove
- Rezultati
- vloga
- Roll
- Valjani
- ROW
- Run
- varna
- Enako
- Prilagodljivost
- skeniranje
- Znanost
- Znanstvenik
- varnost
- sej
- več
- pokazale
- Pomen
- poenostavljeno
- saj
- sam
- Rešuje
- nekaj
- vir
- Spark
- SQL
- začel
- statistika
- shranjevanje
- trgovina
- Shranite podatke
- trgovine
- pretakanje
- strukturirano
- taka
- podpora
- Podpira
- sistem
- sistemi
- miza
- Takeaways
- tehnični
- Pogoji
- O
- Združitev
- njihove
- tisoče
- 3
- čas
- Čas potovanja
- do
- danes
- orodje
- orodja
- vrh
- Top 10
- sledenje
- transakcija
- transakcijski
- Transakcije
- Preoblikovanje
- potovanja
- Res
- razumeli
- razumevanje
- poenoteno
- neustavljivo.
- prihajajoče
- Nadgradnja
- posodobljeno
- us
- uporaba
- primeru uporabe
- Uporabniki
- različnih
- različica
- Poglej
- Obseg
- Kaj
- ali
- ki
- bo
- delo
- telovaditi
- let
- Vaša rutina za
- zefirnet