Amazon SageMaker je popolnoma upravljana storitev strojnega učenja (ML). S SageMakerjem lahko podatkovni znanstveniki in razvijalci hitro in preprosto zgradijo in učijo modele ML ter jih nato neposredno uvedejo v gostujoče okolje, pripravljeno za proizvodnjo. Zagotavlja integriran primerek Jupyter avtorskega beležnika za preprost dostop do vaših virov podatkov za raziskovanje in analizo, tako da vam ni treba upravljati strežnikov. Zagotavlja tudi skupno ML algoritmi ki so optimizirani za učinkovito delovanje z izjemno velikimi podatki v porazdeljenem okolju.
Sklepanje v realnem času SageMaker je idealno za delovne obremenitve, ki imajo zahteve glede realnega časa, interaktivnosti in nizke zakasnitve. S sklepanjem v realnem času SageMaker lahko uvedete končne točke REST, ki so podprte z določeno vrsto primerka z določeno količino računalništva in pomnilnika. Uvedba končne točke SageMaker v realnem času je za mnoge stranke le prvi korak na poti do proizvodnje. Želimo, da bi lahko povečali zmogljivost končne točke, da bi dosegli ciljno število transakcij na sekundo (TPS), pri tem pa upoštevali zahteve glede zakasnitve. Velik del optimizacije zmogljivosti za sklepanje je zagotavljanje, da izberete ustrezno vrsto primerka in štejete nazaj do končne točke.
Ta objava opisuje najboljše prakse za obremenitveno testiranje končne točke SageMaker za iskanje prave konfiguracije za število primerkov in velikost. To nam lahko pomaga razumeti minimalne zahteve glede primerkov, da bi izpolnili naše zahteve glede zakasnitve in TPS. Od tam se poglobimo v to, kako lahko sledite in razumete meritve in zmogljivost končne točke SageMaker z uporabo amazoncloudwatch meritve.
Najprej primerjamo zmogljivost našega modela na enem primerku, da identificiramo TPS, ki ga lahko obravnava glede na naše sprejemljive zahteve glede zakasnitve. Nato ekstrapoliramo ugotovitve, da se odločimo o številu primerkov, ki jih potrebujemo za obvladovanje našega produkcijskega prometa. Na koncu simuliramo promet na ravni proizvodnje in nastavimo teste obremenitve za končno točko SageMaker v realnem času, da potrdimo, da naša končna točka zmore obremenitev na ravni proizvodnje. Celoten nabor kode za primer je na voljo v nadaljevanju GitHub repozitorij.
Pregled rešitve
Za to delovno mesto namestimo vnaprej usposobljeno osebo Hugging Face DistilBERT model Iz Hugging Face Hub. Ta model lahko izvaja številne naloge, vendar pošljemo koristni tovor posebej za analizo razpoloženja in klasifikacijo besedila. S tem vzorčnim tovorom si prizadevamo doseči 1000 TPS.
Namestite končno točko v realnem času
Ta objava predvideva, da ste seznanjeni s tem, kako uvesti model. Nanašati se na Ustvarite svojo končno točko in uvedite svoj model razumeti notranjost za gostovanje končne točke. Za zdaj lahko hitro pokažemo na ta model v Hugging Face Hub in uvedemo končno točko v realnem času z naslednjim izrezkom kode:
Hitro preizkusimo našo končno točko z vzorčno koristno obremenitvijo, ki jo želimo uporabiti za testiranje obremenitve:

Upoštevajte, da podpiramo končno točko z uporabo enega Amazonski elastični računalniški oblak (Amazon EC2) primerek tipa ml.m5.12xlarge, ki vsebuje 48 vCPU in 192 GiB pomnilnika. Število vCPE-jev je dober pokazatelj sočasnosti, ki jo primerek lahko obravnava. Na splošno je priporočljivo preizkusiti različne vrste primerkov, da se prepričamo, da imamo primerek, ki ima vire, ki so pravilno uporabljeni. Če si želite ogledati celoten seznam primerkov SageMaker in njihove ustrezne računske moči za sklepanje v realnem času, glejte Cene Amazon SageMaker.
Meritve za sledenje
Preden se lahko lotimo testiranja obremenitve, je bistveno razumeti, katerim metrikam slediti, da bi razumeli razčlenitev zmogljivosti vaše končne točke SageMaker. CloudWatch je primarno orodje za beleženje, ki ga SageMaker uporablja za pomoč pri razumevanju različnih meritev, ki opisujejo delovanje vaše končne točke. Dnevnike CloudWatch lahko uporabite za odpravljanje napak pri priklicih končne točke; tukaj so zajeti vsi stavki za beleženje in tiskanje, ki jih imate v sklepni kodi. Za več informacij glejte Kako deluje Amazon CloudWatch.
Obstajata dve različni vrsti meritev, ki jih CloudWatch pokriva za SageMaker: meritve na ravni primerka in meritve priklica.
Meritve na ravni primerka
Prvi niz parametrov, ki jih je treba upoštevati, je metrika na ravni primerka: CPUUtilization in MemoryUtilization (za primerke, ki temeljijo na GPU, GPUUtilization). Za CPUUtilization, boste morda v CloudWatchu najprej videli odstotke nad 100 %. Pomembno se je zavedati, CPUUtilization, se prikaže vsota vseh jeder CPU. Na primer, če instanca za vašo končno točko vsebuje 4 vCPU-je, to pomeni, da je obseg uporabe do 400 %. MemoryUtilization, po drugi strani pa je v območju 0–100 %.
Natančneje, lahko uporabite CPUUtilization da bi globlje razumeli, ali imate dovolj ali celo preveč strojne opreme. Če imate premalo izkoriščen primerek (manj kot 30 %), lahko potencialno zmanjšate vrsto svojega primerka. Nasprotno, če imate približno 80–90-odstotno izkoriščenost, bi bilo koristno izbrati primerek z večjo računalniško zmogljivostjo/pomnilnikom. Iz naših testov predlagamo približno 60–70-odstotno izkoriščenost vaše strojne opreme.
Meritve priklica
Kot nakazuje že ime, lahko meritve klicev spremljamo zakasnitev od konca do konca vseh klicev do vaše končne točke. Uporabite lahko metrike priklica, da zajamete število napak in vrste napak (5xx, 4xx itd.), ki jih morda doživlja vaša končna točka. Še pomembneje je, da lahko razumete razčlenitev zakasnitev vaših klicev končne točke. Veliko tega je mogoče zajeti z ModelLatency in OverheadLatency metrike, kot je prikazano v naslednjem diagramu.

O ModelLatency metrika zajema čas, ki traja sklepanje znotraj vsebnika modela za končno točko SageMaker. Upoštevajte, da vsebnik modela vključuje tudi katero koli kodo sklepanja po meri ali skripte, ki ste jih posredovali za sklepanje. Ta enota je zajeta v mikrosekundah kot metrika priklica in na splošno lahko narišete graf percentila v CloudWatch (p99, p90 itd.), da vidite, ali dosegate ciljno zakasnitev. Upoštevajte, da lahko več dejavnikov vpliva na zakasnitev modela in vsebnika, na primer naslednje:
- Sklepni skript po meri – Ne glede na to, ali ste implementirali svoj vsebnik ali ste uporabili vsebnik, ki temelji na SageMakerju, z obdelovalniki sklepanja po meri, je najboljša praksa, da profilirate svoj skript, da ujamete vse operacije, ki posebej dodajajo veliko časa vaši zakasnitvi.
- Komunikacijski protokol – Razmislite o povezavah REST in gRPC s strežnikom modela znotraj vsebnika modela.
- Optimizacije ogrodja modela – To je specifično za okvir, na primer z TensorFlowobstaja več spremenljivk okolja, ki jih lahko nastavite in so specifične za TF Serving. Prepričajte se, da preverite, kateri vsebnik uporabljate in ali obstajajo kakršne koli optimizacije, specifične za ogrodje, ki jih lahko dodate znotraj skripta ali kot spremenljivke okolja za vbrizgavanje v vsebnik.
OverheadLatency se meri od časa, ko SageMaker prejme zahtevo, dokler ne vrne odgovora stranki, minus zakasnitev modela. Ta del je večinoma izven vašega nadzora in spada pod čas, ki ga vzamejo režijski stroški SageMakerja.
Zakasnitev od konca do konca je kot celota odvisna od različnih dejavnikov in ni nujno vsota ModelLatency plus OverheadLatency. Na primer, če vaša stranka izdeluje InvokeEndpoint Klic API prek interneta, z vidika odjemalca bi bila zakasnitev od konca do konca internet + ModelLatency + OverheadLatency. Zato je pri obremenitvenem testiranju vaše končne točke, da bi natančno primerjali samo končno točko, priporočljivo, da se osredotočite na meritve končne točke (ModelLatency, OverheadLatencyin InvocationsPerInstance) za natančno primerjavo končne točke SageMaker. Vse težave, povezane z zakasnitvijo od konca do konca, je mogoče nato ločeno izolirati.
Nekaj vprašanj, ki jih je treba upoštevati pri zakasnitvi od konca do konca:
- Kje je odjemalec, ki kliče vašo končno točko?
- Ali obstajajo vmesne plasti med vašo stranko in izvajalnim okoljem SageMaker?
Samodejno skaliranje
V tem prispevku ne obravnavamo posebej samodejnega skaliranja, vendar je to pomemben dejavnik pri zagotavljanju pravilnega števila primerkov glede na delovno obremenitev. Glede na vzorce prometa lahko priložite pravilnik o samodejnem skaliranju na vašo končno točko SageMaker. Obstajajo različne možnosti skaliranja, kot npr TargetTrackingScaling, SimpleScalingin StepScaling. To omogoča vaši končni točki, da se samodejno poveča in zmanjša glede na vaš prometni vzorec.
Običajna možnost je sledenje cilju, kjer lahko določite meritev CloudWatch ali meritev po meri, ki ste jo definirali, in na podlagi tega povečate. Pogosta uporaba samodejnega skaliranja je sledenje InvocationsPerInstance metrika. Ko ugotovite ozko grlo pri določenem TPS, lahko to pogosto uporabite kot meritev za razširitev na večje število primerkov, da boste lahko obvladovali največje obremenitve prometa. Za podrobnejšo razčlenitev končnih točk SageMaker za samodejno skaliranje glejte Konfiguriranje končnih točk sklepanja samodejnega skaliranja v Amazon SageMaker.
Testiranje obremenitve
Čeprav uporabljamo Locust, da prikažemo, kako lahko naložimo test v velikem obsegu, če poskušate ustrezno velikost primerka za vašo končno točko, SageMaker Inference Recommender je bolj učinkovita možnost. Z orodji drugih proizvajalcev za testiranje obremenitve morate ročno razmestiti končne točke v različnih instancah. Z Inference Recommender lahko preprosto posredujete matriko vrst primerkov, za katere želite naložiti test, in SageMaker se bo začel delovna mesta za vsakega od teh primerov.
Locust
Za ta primer uporabljamo Locust, odprtokodno orodje za testiranje obremenitve, ki ga lahko implementirate s Pythonom. Locust je podoben mnogim drugim odprtokodnim orodjem za testiranje obremenitve, vendar ima nekaj posebnih prednosti:
- Enostavno vzpostaviti – Kot prikazujemo v tej objavi, bomo posredovali preprost skript Python, ki ga je mogoče zlahka preoblikovati za vašo specifično končno točko in obremenitev.
- Distribuirano in razširljivo – Locust temelji na dogodkih in uporablja gevent pod pokrovom. To je zelo uporabno za preizkušanje zelo sočasnih delovnih obremenitev in simulacijo na tisoče sočasnih uporabnikov. Visok TPS lahko dosežete z enim postopkom, ki izvaja Locust, vendar ima tudi porazdeljeno ustvarjanje obremenitve funkcija, ki vam omogoča razširitev na več procesov in odjemalskih strojev, kot bomo raziskali v tej objavi.
- Locust meritve in uporabniški vmesnik – Locust zajame tudi zakasnitev od konca do konca kot meritev. To vam lahko pomaga dopolniti meritve CloudWatch, da ustvarite popolno sliko svojih testov. Vse to je zajeto v uporabniškem vmesniku Locust, kjer lahko spremljate sočasne uporabnike, delavce in drugo.
Če želite bolje razumeti Locust, si oglejte njihov Dokumentacija.
Nastavitev Amazon EC2
Locust lahko nastavite v poljubnem okolju, ki je za vas združljivo. Za to objavo smo postavili instanco EC2 in vanjo namestili Locust za izvajanje naših testov. Uporabljamo primerek c5.18xlarge EC2. Upoštevati je treba tudi računalniško moč na strani odjemalca. V trenutkih, ko vam zmanjka računalniške moči na strani odjemalca, to pogosto ni zajeto in se napačno razume kot napaka končne točke SageMaker. Pomembno je, da svojo stranko postavite na lokacijo z zadostno računalniško močjo, ki lahko prenese obremenitev, na kateri preskušate. Za naš primer EC2 uporabljamo Ubuntu Deep Learning AMI, vendar lahko uporabite kateri koli AMI, če lahko pravilno nastavite Locust na računalniku. Če želite razumeti, kako zagnati vaš primerek EC2 in se povezati z njim, glejte vadnico Začnite uporabljati primerke Amazon EC2 Linux.
Uporabniški vmesnik Locust je dostopen prek vrat 8089. To lahko odpremo tako, da prilagodimo pravila vhodne varnostne skupine za primerek EC2. Odpremo tudi vrata 22, tako da lahko SSH v primerek EC2. Razmislite o obsegu vira do določenega naslova IP, s katerega dostopate do primerka EC2.

Ko ste povezani s svojo instanco EC2, nastavimo virtualno okolje Python in namestimo odprtokodni API Locust prek CLI:
Zdaj smo pripravljeni na delo z Locust za obremenitveno testiranje naše končne točke.
Testiranje kobilic
Vsi preskusi obremenitve Locust se izvajajo na podlagi a Datoteka kobilica ki jih zagotavljate. Ta datoteka Locust definira nalogo za obremenitveni test; tukaj definiramo naš Boto3 klic API-ja invoke_endpoint. Glej naslednjo kodo:
V prejšnji kodi prilagodite svoje parametre klica končne točke za priklic, da bodo ustrezali vašemu specifičnemu priklicu modela. Uporabljamo InvokeEndpoint API z uporabo naslednjega dela kode v datoteki Locust; to je naša točka izvajanja preizkusa obremenitve. Datoteka Locust, ki jo uporabljamo, je locust_script.py.
Zdaj, ko imamo naš skript Locust pripravljen, želimo zagnati porazdeljene teste Locust za stresni test našega posameznega primerka, da ugotovimo, koliko prometa zmore naš primerek.
Locust porazdeljeni način je nekoliko bolj niansiran kot enoprocesni Locust test. V porazdeljenem načinu imamo enega primarnega in več delavcev. Primarni delavec delavcem daje navodila, kako ustvariti in nadzorovati sočasne uporabnike, ki pošiljajo zahtevo. V našem porazdeljeno.sh skripta, privzeto vidimo, da bo 240 uporabnikov porazdeljenih med 60 delavcev. Upoštevajte, da je --headless zastavica v Locust CLI odstrani funkcijo uporabniškega vmesnika Locusta.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
Najprej zaženemo porazdeljeni test na enem primerku, ki podpira končno točko. Ideja tukaj je, da želimo v celoti maksimizirati en primerek, da bi razumeli število primerkov, ki jih potrebujemo za dosego ciljnega TPS, pri tem pa ostajamo znotraj naših zahtev glede zakasnitve. Upoštevajte, da če želite dostopati do uporabniškega vmesnika, spremenite Locust_UI spremenljivko okolja na True in prenesite javni IP vašega primerka EC2 ter preslikajte vrata 8089 v URL.
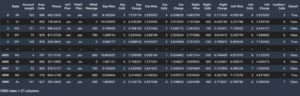
Naslednji posnetek zaslona prikazuje naše meritve CloudWatch.

Sčasoma opazimo, da čeprav na začetku dosežemo TPS 200, začnemo opažati napake 5xx v naših dnevnikih na strani odjemalca EC2, kot je prikazano na naslednjem posnetku zaslona.
To lahko preverimo tudi tako, da posebej pogledamo naše meritve na ravni primerka CPUUtilization.
 Tukaj opazimo
Tukaj opazimo CPUUtilization pri skoraj 4,800 %. Naš primerek ml.m5.12x.large ima 48 vCPE (48 * 100 = 4800~). To nasiči celoten primerek, kar tudi pomaga razložiti naše napake 5xx. Opažamo tudi porast pri ModelLatency.
Zdi se, kot da se naš posamezen primerek sesuva in nima računalnika, da bi vzdržal obremenitev nad 200 TPS, ki jih opazujemo. Naš ciljni TPS je 1000, zato poskusimo povečati število primerkov na 5. V produkcijski nastavitvi bo to morda moralo biti še več, ker smo po določeni točki opazili napake pri 200 TPS.

V uporabniškem vmesniku Locust in dnevnikih CloudWatch vidimo, da imamo TPS skoraj 1000 s petimi primerki, ki podpirajo končno točko.

 Če se začnejo pojavljati napake tudi pri tej nastavitvi strojne opreme, poskrbite za nadzor
Če se začnejo pojavljati napake tudi pri tej nastavitvi strojne opreme, poskrbite za nadzor CPUUtilization da razumete celotno sliko za gostovanjem končne točke. Ključnega pomena je, da razumete svojo uporabo strojne opreme, da ugotovite, ali morate povečati ali celo zmanjšati. Včasih težave na ravni vsebnika povzročijo napake 5xx, toda če CPUUtilization je nizka, pomeni, da do teh težav morda ne povzroča vaša strojna oprema, ampak nekaj na ravni vsebnika ali modela (na primer ni nastavljena ustrezna spremenljivka okolja za število delavcev). Po drugi strani pa, če opazite, da vaš primerek postaja popolnoma zasičen, je to znak, da morate povečati trenutno floto instanc ali preizkusiti večjo instanco z manjšo floto.
Čeprav smo povečali število primerkov na 5 za obdelavo 100 TPS, lahko vidimo, da je ModelLatency metrika je še vedno visoka. To je posledica nasičenosti primerkov. Na splošno predlagamo, da si prizadevate za uporabo virov instance med 60–70 %.
Čiščenje
Po obremenitvenem testiranju počistite vse vire, ki jih ne boste uporabili prek konzole SageMaker ali prek delete_endpoint Klic API-ja Boto3. Poleg tega se prepričajte, da ste ustavili svoj primerek EC2 ali katero koli nastavitev odjemalca, ki jo imate, da tudi tam ne boste imeli dodatnih stroškov.
Povzetek
V tej objavi smo opisali, kako lahko naložite test svoje končne točke SageMaker v realnem času. Razpravljali smo tudi o tem, katere meritve bi morali oceniti pri obremenitvenem testiranju končne točke, da bi razumeli razčlenitev učinkovitosti. Ne pozabite odjaviti SageMaker Inference Recommender za nadaljnje razumevanje pravilne velikosti primerka in več tehnik za optimizacijo delovanja.
O avtorjih
 Marc Karp je ML arhitekt pri ekipi SageMaker Service. Osredotoča se na pomoč strankam pri načrtovanju, uvajanju in upravljanju delovnih obremenitev ML v velikem obsegu. V prostem času rad potuje in raziskuje nove kraje.
Marc Karp je ML arhitekt pri ekipi SageMaker Service. Osredotoča se na pomoč strankam pri načrtovanju, uvajanju in upravljanju delovnih obremenitev ML v velikem obsegu. V prostem času rad potuje in raziskuje nove kraje.
 Ram Vegiraju je ML arhitekt pri ekipi SageMaker Service. Osredotoča se na pomoč strankam pri izgradnji in optimizaciji njihovih rešitev AI/ML na Amazon SageMaker. V prostem času rad potuje in piše.
Ram Vegiraju je ML arhitekt pri ekipi SageMaker Service. Osredotoča se na pomoč strankam pri izgradnji in optimizaciji njihovih rešitev AI/ML na Amazon SageMaker. V prostem času rad potuje in piše.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- Sposobna
- nad
- sprejemljiv
- dostop
- dostopen
- Dostop
- natančno
- Doseči
- čez
- Poleg tega
- Naslov
- po
- proti
- AI / ML
- Usmerjanje
- vsi
- omogoča
- Čeprav
- Amazon
- Amazon EC2
- Amazon SageMaker
- znesek
- Analiza
- in
- API
- okoli
- Array
- pripisujejo
- avtorstvo
- avto
- samodejno
- Na voljo
- AWS
- nazaj
- Backed
- podloga
- temeljijo
- ker
- zadaj
- počutje
- merilo
- koristi
- Prednosti
- BEST
- najboljše prakse
- med
- telo
- Razčlenitev
- izgradnjo
- C + +
- klic
- poziva
- Lahko dobiš
- zajemanje
- ujame
- wrestling
- nekatere
- spremenite
- Stroški
- preveriti
- razred
- Razvrstitev
- stranke
- Koda
- Skupno
- združljiv
- Izračunajte
- sočasno
- Ravnanje
- konfiguracija
- Potrdi
- Connect
- povezane
- povezave
- Razmislite
- premislek
- Konzole
- Posoda
- Vsebuje
- ozadje
- nadzor
- Ustrezno
- bi
- pokrov
- prevleke
- CPU
- ustvarjajo
- ključnega pomena
- Trenutna
- po meri
- Stranke, ki so
- datum
- globoko
- globoko učenje
- globlje
- privzeto
- Določa
- izkazati
- Odvisno
- odvisno
- razporedi
- uvajanja
- opisati
- opisano
- Oblikovanje
- Razvijalci
- drugačen
- neposredno
- razpravljali
- zaslon
- porazdeljena
- Ne
- dont
- navzdol
- vsak
- enostavno
- učinkovite
- učinkovito
- bodisi
- omogoča
- konec koncev
- Končna točka
- Celotna
- okolje
- Napaka
- napake
- bistvena
- Eter (ETH)
- Tudi
- Primer
- izjema
- izvršiti
- doživlja
- Pojasnite
- raziskovanje
- raziskuje
- Raziskovati
- izvoz
- izredno
- Obraz
- dejavniki
- Falls
- seznanjeni
- Feature
- Nekaj
- file
- končno
- Najdi
- prva
- FLET
- Osredotočite
- Osredotoča
- po
- format
- Okvirni
- pogosto
- iz
- polno
- v celoti
- nadalje
- splošno
- splošno
- dobili
- pridobivanje
- dobro
- graf
- več
- skupina
- Skupine
- ročaj
- srečna
- strojna oprema
- pomoč
- pomoč
- Pomaga
- tukaj
- visoka
- zelo
- napa
- gostitelj
- gostila
- gostovanje
- Kako
- Kako
- HTML
- HTTPS
- Hub
- Ideja
- idealen
- identificirati
- identificirati
- vpliv
- izvajati
- izvajali
- uvoz
- Pomembno
- in
- vključuje
- Povečajte
- povečal
- označuje
- indikacija
- Podatki
- na začetku
- namestitev
- primer
- integrirana
- interaktivno
- Internet
- prikliče
- IP
- IP naslov
- izolirani
- Vprašanja
- IT
- sam
- json
- velika
- v veliki meri
- večja
- Latenca
- kosilo
- plasti
- vodi
- vodi
- učenje
- Stopnja
- linux
- Seznam
- malo
- obremenitev
- obremenitve
- kraj aktivnosti
- Long
- si
- Sklop
- nizka
- stroj
- strojno učenje
- Stroji
- Znamka
- Izdelava
- upravljanje
- upravlja
- ročno
- več
- map
- Povečajte
- pomeni
- Srečati
- srečanja
- Spomin
- meritev
- Meritve
- morda
- minimalna
- ML
- način
- Model
- modeli
- monitor
- več
- učinkovitejše
- več
- Ime
- skoraj
- nujno
- Nimate
- Novo
- prenosnik
- Številka
- ONE
- odprite
- open source
- operacije
- optimizacija
- Optimizirajte
- optimizirana
- Možnost
- možnosti
- Da
- Ostalo
- zunaj
- lastne
- barve
- parametri
- del
- opravil
- preteklosti
- pot
- Vzorec
- vzorci
- Peak
- opravlja
- performance
- perspektiva
- kramp
- slika
- kos
- Kraj
- Mesta
- platon
- Platonova podatkovna inteligenca
- PlatoData
- plus
- Točka
- Prispevek
- potencialno
- moč
- praksa
- vaje
- Predictor
- primarni
- Tiskanje
- Težave
- Postopek
- Procesi
- proizvodnja
- profil
- pravilno
- pravilno
- zagotavljajo
- zagotavlja
- zagotavljanje
- javnega
- Python
- vprašanja
- hitro
- območje
- pripravljen
- v realnem času
- uresničitev
- prejme
- priporočeno
- okolica
- povezane
- zahteva
- Zahteve
- viri
- Odgovor
- REST
- povzroči
- Rezultati
- vrne
- pravila
- Run
- tek
- sagemaker
- Sklep SageMaker
- Lestvica
- skaliranje
- Znanstveniki
- Področje uporabe
- skripte
- drugi
- varnost
- Zdi se,
- SAMO
- pošiljanja
- sentiment
- Storitev
- služijo
- nastavite
- nastavitev
- nastavitve
- nastavitev
- več
- shouldnt
- pokazale
- Razstave
- podpisati
- Podoben
- Enostavno
- preprosto
- sam
- Velikosti
- manj
- So
- rešitve
- Nekaj
- vir
- Viri
- Spawn
- specifična
- posebej
- Spin
- standardna
- Začetek
- začel
- Izjave
- Korak
- Še vedno
- stop
- stres
- stremiti
- taka
- dovolj
- Suit
- Super
- dopolnjujejo
- Bodite
- meni
- ciljna
- Naloga
- Naloge
- skupina
- tehnike
- Test
- Testiranje
- Testiranje
- testi
- Razvrstitev besedil
- O
- Vir
- njihove
- tretjih oseb
- tisoče
- skozi
- čas
- krat
- do
- orodje
- orodja
- tps
- sledenje
- Sledenje
- Prometa
- Vlak
- Transakcije
- Potovanje
- Res
- Navodila
- Vrste
- Ubuntu
- ui
- pod
- razumeli
- razumevanje
- Enota
- URL
- us
- uporaba
- Uporabniki
- uporabiti
- uporablja
- izkorišča
- Uporaben
- raznolikost
- preverjanje
- preko
- Virtual
- Kaj
- ali
- ki
- medtem
- bo
- v
- delo
- delavec
- delavci
- bi
- pisanje
- Vaša rutina za
- zefirnet