Ta članek je bil objavljen kot del Blogathon o znanosti o podatkih
Predstavitev
glede na njihove želje. Te tehnike lahko uporabniku omogočijo sprejemanje odločitev. Predmeti se nanašajo na kateri koli izdelek, ki ga sistem priporočanja predlaga svojemu uporabniku, kot so filmi, glasba, novice, potovalni paketi, izdelki e-trgovine itd.
Sistem Recommender je zgrajen za določeno vrsto aplikacije glede na elemente, ki jih priporoča, in temu primerno sta prilagojena njegov grafični uporabniški vmesnik in oblika. Razvoj sistema priporočil je izhajal iz splošne ideje, da se posamezniki zanašajo na druge pri sprejemanju rednih odločitev v svojem življenju. Eksplozivna rast obsega in raznolikosti informacij, ki so na voljo na spletu, je prispevala k razvoju priporočljivih sistemov, kar je posledično privedlo do njihovega uporabnika.
Vrste sistemov priporočil
Obstajajo tri široke kategorije sistemov priporočil:

Izvirni naslov: Google slike
1. Sistemi, ki temeljijo na sodelovalnem filtriranju:
Ti sistemi priporočajo elemente uporabnikom na podlagi izračuna podobnosti teh uporabnikov s podobnimi uporabniki v sistemu ali na podlagi elementov, podobnih elementom, ki so bili uporabniku všeč v preteklosti. Sodelovalno filtriranje lahko torej nadalje razdelimo v dve kategoriji –
- i) temelji na uporabniku sodelovalno filtriranje– Priporočljiv sistem poskuša najti uporabnike, ki so podobni ciljnemu uporabniku, tako da izračuna določene mere podobnosti in nato ciljnemu uporabniku predlaga elemente na podlagi podobnih uporabniških preferenc. Izračun podobnosti je tukaj pomembna naloga.
- ii.) sodelovalno filtriranje na podlagi predmetov– Priporočljiv sistem poskuša najti elemente na podlagi
na prejšnjih uporabniških nastavitvah uporabnika in nato priporočite podobne elemente
uporabnik. Ti predmeti bi lahko bili zanimivi za uporabnika.
2. Sistemi za priporočanje na podlagi vsebine:
Sistem se osredotoča na lastnosti elementov, ki jih predlaga uporabnikom. Na primer, če je uporabnik YouTuba gledal komične videoposnetke, mu bo sistem priporočil videoposnetke žanra komedije. Podobno, če je uporabnik Netflixa gledal filme določenega režiserja, mu bo sistem te filme priporočil.
3. Hibridni sistemi: Ti sistemi so kombinacija sistemov za sodelovanje in sistemov, ki temeljijo na vsebini.
Izgradnja sistema za priporočanje tečajev
Korak 1: Branje nabora podatkov.
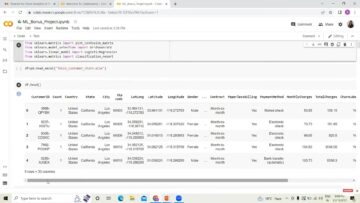
#uvoz potrebnih knjižnic. uvozi pande kot pd data = pd.read_csv(r"C:UsersDellDesktopDatasetdataset.csv") data.head()

O naboru podatkov:
Vključuje podatke dijakov, vpisanih v srednjo šolo, z njihovimi ID-ji, tokovi, najljubšim predmetom in ocenami, pridobljenimi v 12. razredu. Vključuje tudi stolpce z rezultati predmeta in specializacije, ki so jo opravljali ob diplomi.
Tečaje želimo priporočiti študentom s podobnimi ocenami, smermi in najljubšimi predmeti.
Zdaj bomo zgradili priporočljiv sistem, ki temelji na vsebini, ki bi lahko študentom priporočal tečaje na podlagi njihovih osnovnih informacij.
2. korak: Ustvarjanje kombiniranega opisa vsakega študenta v naboru podatkov.
descriptions =data['gender'] +' '+ data['subject'] + ' ' + data['stream'] +' '+ data['marks'].apply(str) #Tiskanje prvih opisov opisa[ 0]

3. korak: Ustvarjanje matrike podobnosti med učenci.
# uvozi TfidfVector iz sklearn. from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import linear_kernel def create_similarity_matrix(new_description, general_descriptions): #Dodaj nov opis celotnemu nizu. total_descriptions.append(new_description) # Definirajte vektorizator tfidf in odstranite vse zaustavitvene besede. tfidf = TfidfVectorizer(stop_words="english") #Pretvori matriko tfidf s prilagajanjem in transformacijo podatkov. tfidf_matrix = tfidf.fit_transform(overall_descriptions) # izpis oblike matrike. tfidf_matrix.shape # izračun kosinusne matrike podobnosti. kosinus_sim = linearno_kernel (tfidf_matrix, tfidf_matrix) vrni kosinus_sim
Funkcija create_similarity_matrix() se uporablja za generiranje kosinusne matrike podobnosti opisov učencev.
Splošnim opisom najprej doda nov opis študenta, za katerega so bila dana priporočila.
Nato je bilo treba opise študentov pretvoriti v besedne vektorje (vektorizirana predstavitev besed). Zato bomo za njihovo pretvorbo uporabili TFIDF (Term Frequency Inverse document frequency). ocena TF-IDF je pogostost pojavljanja besede v dokumentu, ponderirana s številom dokumentov, v katerih se pojavi. To se naredi, da se zmanjša pomen besed, ki se pogosto pojavljajo v opisih, in s tem njihov pomen pri izračunu končne ocene podobnosti.
Zgornja funkcija nato končno izda matriko podobnosti kosinusa.
4. korak: Definirajte funkcijo get_recommendations().
def get_recommendations(new_description,overall_descriptions): # ustvarite matriko podobnosti cosine_sim = create_similarity_matrix(new_description,overall_descriptions) # Pridobite rezultate podobnosti po parih vseh študentov z novim študentom. sim_scores = list(enumerate(cosine_sim[-1])) # Razvrsti opise glede na oceno podobnosti. sim_scores = sorted(sim_scores,key =lambda x:x[1],reverse= True ) # Pridobite rezultate 10 najboljših opisov. sim_scores = sim_scores[1:10] # Pridobite indekse študentov. indeksi = [i[0]za i v sim_scores] vrni podatke.iloc[indeksi]
5. korak: Priporočite tečaj novemu tečajniku.
new_description = pd.Series('male physics science 78') get_recommendations(new_description,descriptions)

Prikazana sta zgornji dve priporočili.
Težave v sistemih priporočil:
1. Težava s hladnim zagonom:
Vsakič, ko nov uporabnik vstopi v sistem priporočanja, se pojavi vprašanje, kaj mu priporočiti in na podlagi česa, saj predhodni podatki niso na voljo in izračuna podobnosti ni bilo mogoče izvesti. Ena od rešitev tega problema je, da novi uporabniki vnesejo majhen uvodni obrazec, ki vsebuje osnovne informacije o posameznikovih interesih, hobijih, poklicu, ter ustvarijo osnovni uporabniški profil in nato priporočijo predmete novemu uporabniku. To bi v veliki meri rešilo problem hladnega zagona.
2. Problem redkosti podatkov:
Glavna težava v sistemu priporočil je nedostopnost ustreznih podatkov, kar je glavna zahteva za postopek priporočanja. Mnogi uporabniki se ne trudijo pregledati kupljenih izdelkov. Posledično ima matrika ocenjevanja uporabniških elementov veliko redkih vnosov, ki poslabšajo delovanje algoritma za izračun podobnosti. Ena od rešitev je torej napovedovanje redkih vnosov in številni raziskovalci so dali algoritme za napovedovanje teh ocen, kot je negativno utežen algoritem z enim nagibom.
3. Spreminjanje nabora podatkov:
Z vsakodnevnim povečanjem količine podatkov se poveča tudi vključitev podatkov v prejšnji nabor podatkov priporočljivega sistema, kar lahko spremeni celotno strukturo in sestavo nabora podatkov. V nabor podatkov so morali biti vključeni novi uporabniki in novi elementi. Zato je bilo treba to spremembo vključiti v nabor podatkov.
4. Težava razširljivosti:
V praktičnem scenariju ni vedno mogoče vsakič najti podobnih uporabnikov in podobnih elementov ter preprečiti odpoved sistema. Zato je izgradnja razširljivega sistema priporočil velika skrb.
5. Napad šilinga:
Napad na šiling je opredeljen kot postopek vključevanja lažnih profilov ter pristranskih pregledov in ocen za pristranskost celotnega postopka priporočanja. Zlonamerni napadalec lahko te profile vstavi, da poveča/zmanjša priporočeno pogostost ciljnih elementov.
Prednosti sistema priporočil:
1. Povečanje dobička s povečanjem števila prodanih artiklov: Eden glavnih ciljev gradnje komercialnih sistemov priporočil je izboljšanje poslovanja in povečanje dobička. To bi lahko storili tako, da bi uporabnikom predlagali nove artikle, ki bi lahko pritegnili uporabnike in bi lahko kupili več artiklov v primerjavi s tistimi brez sistemov priporočanja.
2. Izboljšano zadovoljstvo uporabnikov: Glavni motiv vsake poslovne aplikacije bi moralo biti zadovoljstvo uporabnikov, saj povečuje splošno poslovno rast in zdravo preživetje podjetja. Dobro zasnovan sistem priporočil izboljša uporabnikovo splošno izkušnjo pri uporabi te aplikacije. Morda se jim bodo zdela priporočila koristna in ustrezna potrebam uporabnikov. Glavni namen RS je torej zadovoljiti in osrečiti uporabnike.
3. Ekstrakcija uporabnih vzorcev: Priporočilo sistem ponuja način pridobivanja uporabnih vzorcev potreb in preferenc uporabnikov, ki bi lahko služili kot strateške informacije za podjetje. Na primer, če bi podjetje lahko dobilo vpogled v to, kateri izdelek je njegovim strankam zelo všeč in kateri izdelek ni všeč, bi lahko spremenilo svoj seznam izdelkov.
4. Uporabnikom zagotovite več raznolikih predmetov: Včasih
nemogoče je osebno najti predmete, ki bi jih lahko sistem priporočil
zagotoviti. To poveča raznolikost predmetov, ki jih uporabniki dobijo
priporočila.
Končne opombe
Dandanes so sistemi Recommender postali izjemno priljubljeni. Številna priljubljena spletna mesta za e-trgovino, kot je Amazon, so uporabila prilagojene sisteme priporočil za svoje uporabnike, da predlagajo predmete, ki bi jih lahko kupili na podlagi njihovega preteklega vedenja. RS so povečali dobiček. Spletna mesta, kot sta YouTube in Netflix, uporabnikom predlagajo filme in glasbo glede na žanre, igralce, izvajalce filmov, ki so si jih stranke že ogledale. Potovalna spletna mesta, kot je MakeMyTrip, strankam ponujajo prilagojene potovalne pakete glede na njihove želje in se prek sistemov priporočil ukvarjajo z različnimi uporabniki.
In končno, ni samoumevno.
Hvala za branje!
Mediji, prikazani v tem članku, niso v lasti Analytics Vidhya in se uporabljajo po presoji avtorja.
Podobni
- '
- algoritem
- algoritmi
- vsi
- Amazon
- analitika
- uporaba
- članek
- Izvajalci
- izgradnjo
- Building
- poslovni
- nakup
- spremenite
- Komedija
- komercialna
- podjetje
- računalništvo
- prispevali
- Ustvarjanje
- Stranke, ki so
- datum
- dan
- ponudba
- Oblikovanje
- Razvoj
- Direktor
- Dokumenti
- e-trgovina
- Angleščina
- Vstopi
- itd
- izkušnje
- Napaka
- ponaredek
- končno
- prva
- obrazec
- funkcija
- Spol
- splošno
- veliko
- Rast
- tukaj
- visoka
- Prosti čas
- HTTPS
- Hybrid
- Ideja
- vključitev
- Povečajte
- Podatki
- vpogledi
- obresti
- IT
- Ključne
- naučili
- Led
- Seznam
- velika
- mediji
- Meritve
- filmi
- Glasba
- Netflix
- novice
- drugi
- performance
- Fizika
- Popular
- Izdelek
- Izdelki
- profil
- Profili
- Dobiček
- Python
- ocen
- zmanjša
- pregleda
- Mnenja
- Prilagodljivost
- <span style="color: #f7f7f7;">Šola</span>
- Znanost
- nastavite
- majhna
- So
- prodaja
- SOLVE
- Začetek
- Strateško
- študent
- sistem
- sistemi
- ciljna
- čas
- vrh
- preoblikovanje
- potovanja
- Uporabniki
- Video posnetki
- Obseg
- web
- spletne strani
- besede
- X
- youtube