Ta objava v spletnem dnevniku je napisana skupaj s Chaoyang He in Salmanom Avestimehrom iz FedML.
Analiziranje podatkov iz resničnega sveta zdravstvenega varstva in znanosti o življenju (HCLS) predstavlja več praktičnih izzivov, kot so porazdeljeni podatkovni silosi, pomanjkanje dovolj podatkov na enem mestu za redke dogodke, regulativne smernice, ki prepovedujejo skupno rabo podatkov, infrastrukturne zahteve in stroški, nastali pri ustvarjanju centralizirano skladišče podatkov. Ker so v zelo regulirani domeni, partnerji in stranke HCLS iščejo mehanizme za ohranjanje zasebnosti za upravljanje in analizo obsežnih, porazdeljenih in občutljivih podatkov.
Za ublažitev teh izzivov predlagamo okvir zveznega učenja (FL), ki temelji na odprtokodnem FedML na AWS, ki omogoča analizo občutljivih podatkov HCLS. Vključuje usposabljanje modela globalnega strojnega učenja (ML) iz porazdeljenih zdravstvenih podatkov, ki se hranijo lokalno na različnih mestih. Ne zahteva premikanja ali deljenja podatkov med spletnimi mesti ali s centraliziranim strežnikom med procesom usposabljanja modela.
Namestitev ogrodja FL v oblaku ima več izzivov. Avtomatizacija infrastrukture odjemalec-strežnik za podporo več računov ali navideznih zasebnih oblakov (VPC) zahteva enakovredno VPC in učinkovito komunikacijo med VPC in primerki. Pri produkcijski delovni obremenitvi je potreben stabilen cevovod za uvajanje za nemoteno dodajanje in odstranjevanje strank ter posodabljanje njihovih konfiguracij brez večjih stroškov. Poleg tega imajo lahko odjemalci v heterogeni postavitvi različne zahteve glede računalništva, omrežja in shranjevanja. V tej decentralizirani arhitekturi je lahko beleženje in odpravljanje napak pri odjemalcih težavno. Končno je določitev optimalnega pristopa k skupnim parametrom modela, vzdrževanju zmogljivosti modela, zagotavljanju zasebnosti podatkov in izboljšanju učinkovitosti komunikacije težka naloga. V tem prispevku obravnavamo te izzive z zagotavljanjem predloge operacij zveznega učenja (FLOps), ki gosti rešitev HCLS. Rešitev je agnostična za primere uporabe, kar pomeni, da jo lahko prilagodite svojim primerom uporabe, tako da spremenite model in podatke.
V tej dvodelni seriji prikazujemo, kako lahko namestite ogrodje FL v oblaku na AWS. V prva objava, smo opisali koncepte FL in ogrodje FedML. V tem drugem delu predstavljamo primer uporabe dokazanega koncepta v zdravstvu in znanostih o življenju iz nabora podatkov resničnega sveta eICU. Ta nabor podatkov obsega večcentrično zbirko podatkov o intenzivni negi, zbrano iz več kot 200 bolnišnic, zaradi česar je idealen za testiranje naših poskusov FL.
Primer uporabe HCLS
Za namene predstavitve smo zgradili model FL na javno dostopnem naboru podatkov za vodenje kritično bolnih bolnikov. Uporabili smo eICU zbirka podatkov o skupnih raziskavah, multicentrična baza podatkov enote intenzivne nege (ICU), ki obsega 200,859 srečanj enot za bolnike za 139,367 edinstvenih bolnikov. Med letoma 335 in 208 so bili sprejeti v eno od 2014 enot v 2015 bolnišnicah po ZDA. Zaradi osnovne heterogenosti in porazdeljene narave podatkov zagotavlja idealen primer iz resničnega sveta za testiranje tega okvira FL. Nabor podatkov vključuje laboratorijske meritve, vitalne znake, informacije o načrtu oskrbe, zdravila, bolnikovo anamnezo, sprejemno diagnozo, diagnoze s časovnim žigom s strukturiranega seznama težav in podobno izbrana zdravljenja. Na voljo je kot niz datotek CSV, ki jih je mogoče naložiti v kateri koli sistem relacijske baze podatkov. Tabele so deidentificirane zaradi izpolnjevanja zakonskih zahtev ameriškega zakona o prenosljivosti in odgovornosti zdravstvenega zavarovanja (HIPAA). Do podatkov je mogoče dostopati prek repozitorija PhysioNet, podrobnosti o postopku dostopa do podatkov pa najdete tukaj [1].
Podatki eICU so idealni za razvoj algoritmov ML, orodij za podporo odločanju in napredovanje kliničnih raziskav. Za primerjalno analizo smo upoštevali nalogo napovedovanja umrljivosti bolnikov v bolnišnici [2]. Opredelili smo ga kot binarno klasifikacijsko nalogo, kjer vsak vzorec podatkov obsega 1-urno okno. Da bi ustvarili kohorto za to nalogo, smo izbrali bolnike s statusom odpusta iz bolnišnice v pacientovi kartoteki in dolžino bivanja vsaj 48 ur, ker se osredotočamo na napoved umrljivosti v prvih 24 in 48 urah. To je ustvarilo kohorto 30,680 bolnikov, ki je vsebovala 1,164,966 zapisov. Za napoved umrljivosti smo sprejeli domensko specifično predobdelavo podatkov in metode, opisane v [3]. Posledica tega je združeni nabor podatkov, ki obsega več stolpcev na bolnika na zapis, kot je prikazano na naslednji sliki. Naslednja tabela ponuja zapis o bolniku v tabelarnem vmesniku s časom v stolpcih (5 intervalov v 48 urah) in opazovanjem vitalnih znakov v vrsticah. Vsaka vrstica predstavlja fiziološko spremenljivko, vsak stolpec pa njeno vrednost, zabeleženo v časovnem oknu 48 ur za bolnika.
| Fiziološki parameter | Chart_Time_0 | Chart_Time_1 | Chart_Time_2 | Chart_Time_3 | Chart_Time_4 |
| Glasgow Coma Score Eyes | 4 | 4 | 4 | 4 | 4 |
| FiO2 | 15 | 15 | 15 | 15 | 15 |
| Glasgow Coma Score Eyes | 15 | 15 | 15 | 15 | 15 |
| Srčni utrip | 101 | 100 | 98 | 99 | 94 |
| Invazivni diastolični krvni tlak | 73 | 68 | 60 | 64 | 61 |
| Invazivni sistolični krvni tlak | 124 | 122 | 111 | 105 | 116 |
| Povprečni arterijski tlak (mmHg) | 77 | 77 | 77 | 77 | 77 |
| Glasgow Coma Score Motor | 6 | 6 | 6 | 6 | 6 |
| 02 Nasičenost | 97 | 97 | 97 | 97 | 97 |
| Stopnja dihanja | 19 | 19 | 19 | 19 | 19 |
| Temperatura (C) | 36 | 36 | 36 | 36 | 36 |
| Verbalni rezultat Glasgow Coma | 5 | 5 | 5 | 5 | 5 |
| vstopna višina | 162 | 162 | 162 | 162 | 162 |
| sprejemna teža | 96 | 96 | 96 | 96 | 96 |
| starost | 72 | 72 | 72 | 72 | 72 |
| apacheadmissiondx | 143 | 143 | 143 | 143 | 143 |
| narodnost | 3 | 3 | 3 | 3 | 3 |
| spol | 1 | 1 | 1 | 1 | 1 |
| glukoze | 128 | 128 | 128 | 128 | 128 |
| hospitalacmitoffset | -436 | -436 | -436 | -436 | -436 |
| odpust iz bolnišnice | 0 | 0 | 0 | 0 | 0 |
| itemoffset | -6 | -1 | 0 | 1 | 2 |
| pH | 7 | 7 | 7 | 7 | 7 |
| pacientunitstayid | 2918620 | 2918620 | 2918620 | 2918620 | 2918620 |
| enotadischargeoffset | 1466 | 1466 | 1466 | 1466 | 1466 |
| stanje praznjenja enote | 0 | 0 | 0 | 0 | 0 |
Uporabili smo tako numerične kot kategorične značilnosti in združili vse zapise vsakega bolnika, da bi jih združili v časovno vrsto z enim zapisom. Sedem kategoričnih značilnosti (Diagnoza ob sprejemu, Etnična pripadnost, Spol, Skupni rezultat Glasgow Coma Score, oči Glasgow Coma Score, Motor Glasgow Coma Score in Verbalni rezultat Glasgow Coma Score so bili pretvorjeni v enkratne vektorje kodiranja) je vsebovalo 429 edinstvenih vrednosti in so bile pretvorjene v eno - vroče vgradnje. Da bi preprečili uhajanje podatkov prek strežnikov vozlišč za usposabljanje, smo podatke razdelili po ID-jih bolnišnic in hranili vse zapise o bolnišnici v enem samem vozlišču.
Pregled rešitev
Naslednji diagram prikazuje arhitekturo uvedbe FedML z več računi na AWS. To vključuje dva odjemalca (udeleženca A in udeleženca B) in zbiralnik modelov.
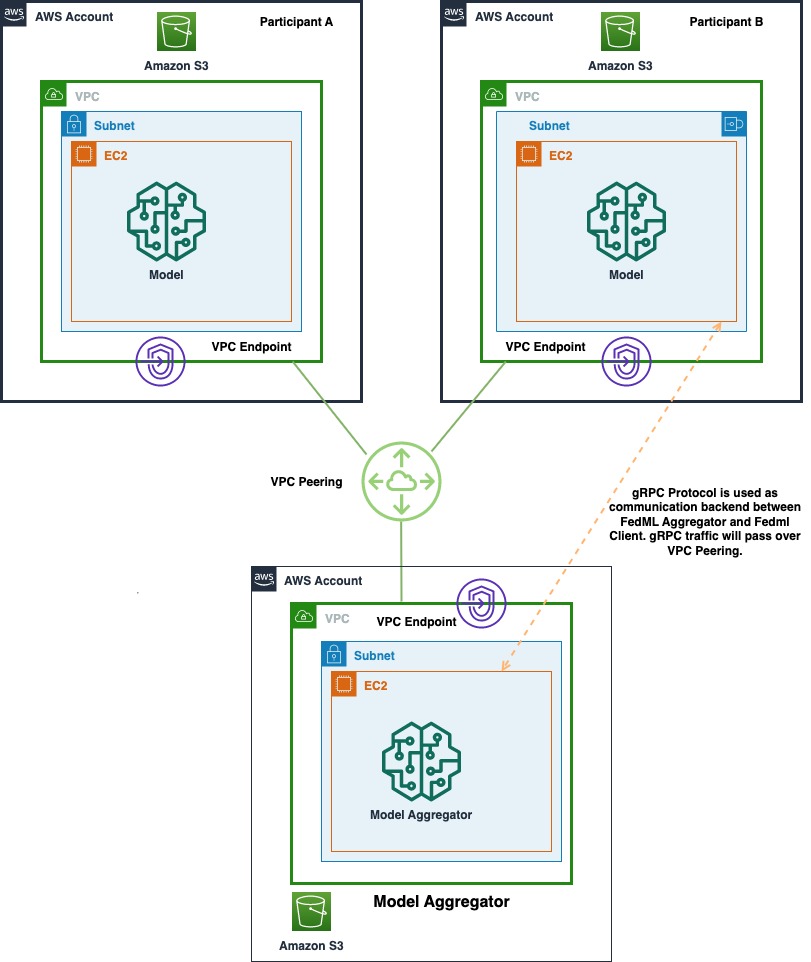
Arhitektura je sestavljena iz treh ločenih Amazonski elastični računalniški oblak (Amazon EC2), ki se izvajajo v lastnem računu AWS. Vsak od prvih dveh primerkov je v lasti stranke, tretji primerek pa je v lasti zbiralnika modelov. Računi so povezani prek VPC peeringa, da se omogoči izmenjava modelov in uteži ML med strankami in zbiralnikom. gRPC se uporablja kot komunikacijsko zaledje za komunikacijo med zbiralnikom modelov in odjemalci. Preizkusili smo porazdeljeno računalniško nastavitev, ki temelji na enem računu, z enim strežnikom in dvema vozliščema odjemalca. Vsak od teh primerkov je bil ustvarjen z uporabo prilagojenega Amazon EC2 AMI z odvisnostmi FedML, nameščenimi v skladu z Navodila za namestitev FedML.ai.
Nastavite peering VPC
Ko zaženete tri primerke v njihovih ustreznih računih AWS, vzpostavite VPC peering med računi prek Navidezni zasebni oblak Amazon (Amazon VPC). Če želite nastaviti enakovredno povezavo VPC, najprej ustvarite zahtevo za enakovredno povezovanje z drugim VPC. Zahtevate lahko vzporedno povezavo VPC z drugim VPC v svojem računu ali z VPC v drugem računu AWS. Za aktiviranje zahteve mora lastnik VPC sprejeti zahtevo. Za namen te predstavitve smo vzpostavili enakovredno povezavo med VPC-ji v različnih računih, vendar v isti regiji. Za druge konfiguracije peeringa VPC glejte Ustvarite vzporedno povezavo VPC.
Preden začnete, se prepričajte, da imate številko računa AWS in ID VPC VPC-ja, s katerima boste sodelovali.
Zahtevajte vzporedno povezavo VPC
Če želite ustvariti vzporedno povezavo VPC, izvedite naslednje korake:
- Na konzoli Amazon VPC v podoknu za krmarjenje izberite Peering povezave.
- Izberite Ustvari peering povezavo.
- za Imenska oznaka peering povezave, lahko po želji poimenujete svojo vzporedno povezavo VPC. S tem ustvarite oznako s ključem imena in vrednostjo, ki jo določite. Ta oznaka je vidna samo vam; lastnik enakovrednega VPC lahko ustvari lastne oznake za enakovredno povezavo VPC.
- za VPC (vlagatelj zahteve), izberite VPC v svojem računu, da ustvarite vzporedno povezavo.
- za Račun, izberite Še en račun.
- za ID računa, vnesite ID računa AWS lastnika sprejemnika VPC.
- za VPC (sprejemnik), vnesite ID VPC, s katerim želite ustvariti vzporedno povezavo VPC.
- V potrditvenem pogovornem oknu izberite OK.
- Izberite Ustvari peering povezavo.
Sprejmite vzporedno povezavo VPC
Kot smo že omenili, mora vzporedno povezavo VPC sprejeti lastnik VPC, ki mu je bila poslana zahteva za povezavo. Izvedite naslednje korake, da sprejmete zahtevo za enakovredno povezavo:
- Na konzoli Amazon VPC uporabite izbirnik regije, da izberete regijo prejemnika VPC.
- V podoknu za krmarjenje izberite Peering povezave.
- Izberite čakajočo vzporedno povezavo VPC (stanje je
pending-acceptance), in na Proces izberite meni Sprejmi zahtevo. - V potrditvenem pogovornem oknu izberite Da, Sprejmi.
- V drugem potrditvenem pogovornem oknu izberite Zdaj spremeni moje tabele poti da greste neposredno na stran s tabelami poti, ali izberite Zapri da to storite pozneje.
Posodobite tabele poti
Če želite omogočiti zasebni promet IPv4 med primerki v enakovrednih VPC-jih, dodajte pot v tabele poti, povezane s podomrežji za oba primerka. Cilj poti je blok CIDR (ali del bloka CIDR) enakovrednega VPC, cilj pa je ID enakovredne povezave VPC. Za več informacij glejte Konfigurirajte tabele poti.
Posodobite svoje varnostne skupine, da se bodo sklicevale na enakovredne skupine VPC
Posodobite vhodna ali izhodna pravila za vaše varnostne skupine VPC, da se bodo sklicevale na varnostne skupine v enakovrednem VPC. To omogoča pretok prometa prek primerkov, ki so povezani z referenčno varnostno skupino v enakovrednem VPC. Za več podrobnosti o nastavitvi varnostnih skupin glejte Posodobite svoje varnostne skupine, da se bodo sklicevale na enakovredne varnostne skupine.
Konfigurirajte FedML
Ko zaženete tri primerke EC2, se povežite z vsakim od njih in izvedite naslednje korake:
- Kloniraj Repozitorij FedML.
- V konfiguracijsko datoteko vnesite podatke o topologiji vašega omrežja
grpc_ipconfig.csv.
To datoteko lahko najdete na FedML/fedml_experiments/distributed/fedavg v skladišču FedML. Datoteka vključuje podatke o strežniku in odjemalcih ter njihovo določeno preslikavo vozlišč, kot je FL Server – vozlišče 0, FL Client 1 – Node 1 in FL Client 2 – Node2.
- Določite konfiguracijsko datoteko za preslikavo GPU.
To datoteko lahko najdete na FedML/fedml_experiments/distributed/fedavg v skladišču FedML. Datoteka gpu_mapping.yaml je sestavljen iz konfiguracijskih podatkov za preslikavo odjemalskega strežnika v ustrezen GPE, kot je prikazano v naslednjem delčku.
Ko definirate te konfiguracije, ste pripravljeni na zagon odjemalcev. Upoštevajte, da je treba odjemalce zagnati, preden zaženete strežnik. Preden to naredimo, nastavimo nalagalnike podatkov za poskuse.
Prilagodite FedML za eICU
Če želite prilagoditi repozitorij FedML za nabor podatkov eICU, izvedite naslednje spremembe podatkov in nalagalnika podatkov.
datum
Dodajte podatke v vnaprej dodeljeno podatkovno mapo, kot je prikazano na naslednjem posnetku zaslona. Podatke lahko postavite v katero koli mapo po vaši izbiri, če je pot dosledno navedena v skriptu za usposabljanje in ima omogočen dostop. Če želite slediti scenariju HCLS v resničnem svetu, kjer lokalni podatki niso v skupni rabi med spletnimi mesti, razdelite in vzorčite podatke, tako da ne pride do prekrivanja ID-jev bolnišnic pri obeh odjemalcih. To zagotavlja, da podatki bolnišnice gostujejo na njenem lastnem strežniku. Enako omejitev smo uveljavili tudi za razdelitev podatkov v nize usposabljanja/testiranja znotraj vsakega odjemalca. Vsak od nizov vlakov/testov pri strankah je imel razmerje med pozitivnimi in negativnimi oznakami 1:10, s približno 27,000 vzorci v usposabljanju in 3,000 vzorcev v testu. Neuravnoteženost podatkov pri usposabljanju modelov obravnavamo s funkcijo utežene izgube.
Nalagalnik podatkov
Vsak odjemalec FedML naloži podatke in jih pretvori v tenzorje PyTorch za učinkovito usposabljanje na GPU. Razširite obstoječo nomenklaturo FedML, da dodate mapo za podatke eICU v data_processing mapa.

Naslednji delček kode naloži podatke iz vira podatkov. Predobdela podatke in vrne en element naenkrat prek __getitem__ Funkcija.
Usposabljanje modelov ML z eno podatkovno točko naenkrat je dolgočasno in dolgotrajno. Usposabljanje modela se običajno izvaja na seriji podatkovnih točk pri vsaki stranki. Za izvedbo tega je nalagalnik podatkov v data_loader.py skript pretvori nize NumPy v tenzorje Torch, kot je prikazano v naslednjem delčku kode. Upoštevajte, da FedML zagotavlja dataset.py in data_loader.py skripte za strukturirane in nestrukturirane podatke, ki jih lahko uporabite za spremembe, specifične za podatke, kot v katerem koli projektu PyTorch.
Uvozite nalagalnik podatkov v skript za usposabljanje
Ko ustvarite nalagalnik podatkov, ga uvozite v kodo FedML za usposabljanje modela ML. Kot kateri koli drug nabor podatkov (na primer CIFAR-10 in CIFAR-100), naložite podatke eICU v main_fedavg.py skript na poti FedML/fedml_experiments/distributed/fedavg/. Tukaj smo uporabili zvezno povprečje (fedavg) agregacijsko funkcijo. Za nastavitev lahko sledite podobni metodi main datoteko za katero koli drugo funkcijo združevanja.
Funkcijo nalagalnika podatkov za podatke eICU pokličemo z naslednjo kodo:
Določite model
FedML podpira več vnaprej pripravljenih algoritmov globokega učenja za različne tipe podatkov, kot so tabelarični, besedilni, slikovni, grafi in podatki interneta stvari (IoT). Naložite model, specifičen za eICU, z vhodnimi in izhodnimi dimenzijami, definiranimi na podlagi nabora podatkov. Za ta dokaz razvoja koncepta smo uporabili logistični regresijski model za usposabljanje in napovedovanje stopnje umrljivosti bolnikov s privzetimi konfiguracijami. Naslednji delček kode prikazuje posodobitve, ki smo jih naredili za main_fedavg.py scenarij. Upoštevajte, da lahko s FedML uporabite tudi prilagojene modele PyTorch in jih uvozite v main_fedavg.py skripta.
Zaženite in spremljajte usposabljanje FedML na AWS
Naslednji videoposnetek prikazuje inicializacijo procesa usposabljanja v vsaki od strank. Ko sta oba odjemalca navedena za strežnik, ustvarite proces usposabljanja strežnika, ki izvaja zvezno združevanje modelov.
Če želite konfigurirati strežnik FL in odjemalce, dokončajte naslednje korake:
- Zaženite odjemalca 1 in odjemalca 2.
Če želite zagnati odjemalca, vnesite naslednji ukaz z ustreznim ID-jem vozlišča. Če želite na primer zagnati odjemalca 1 z ID-jem vozlišča 1, zaženite iz ukazne vrstice:
- Ko sta zagnana oba primerka odjemalca, zaženite primerek strežnika z istim ukazom in ustreznim ID-jem vozlišča glede na vašo konfiguracijo v
grpc_ipconfig.csv file. Vidite lahko uteži modela, ki se posredujejo strežniku iz instanc odjemalca.
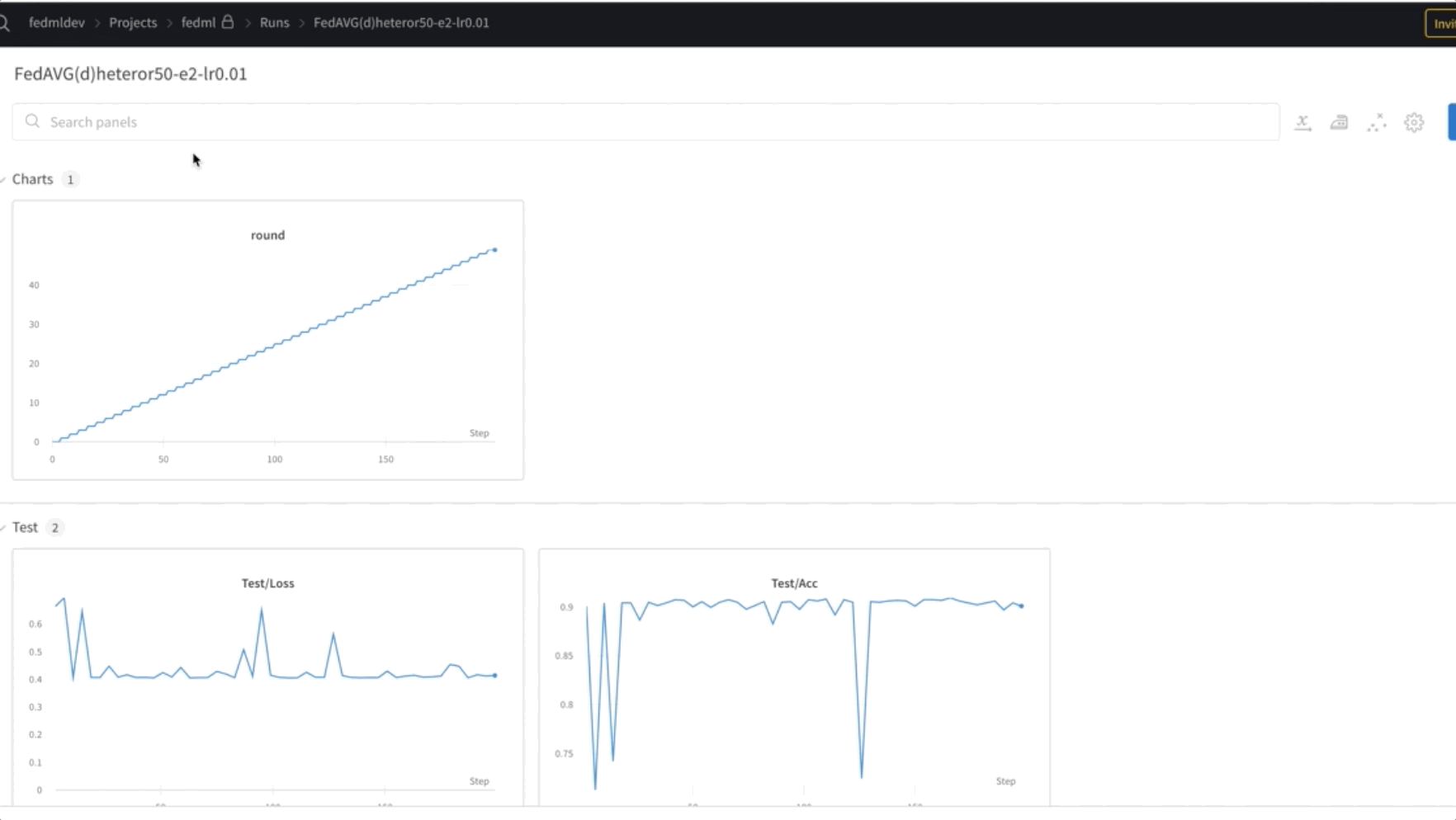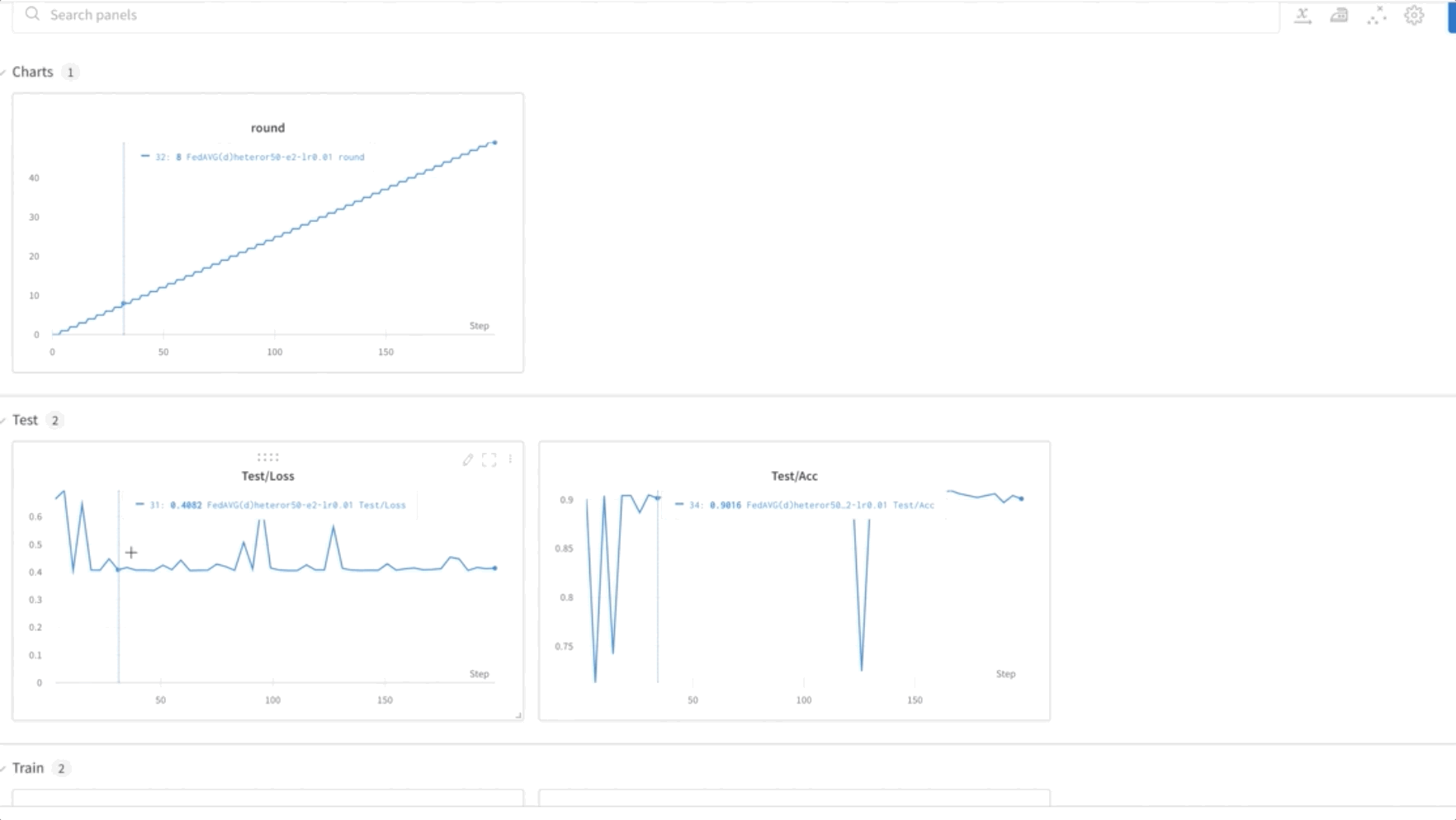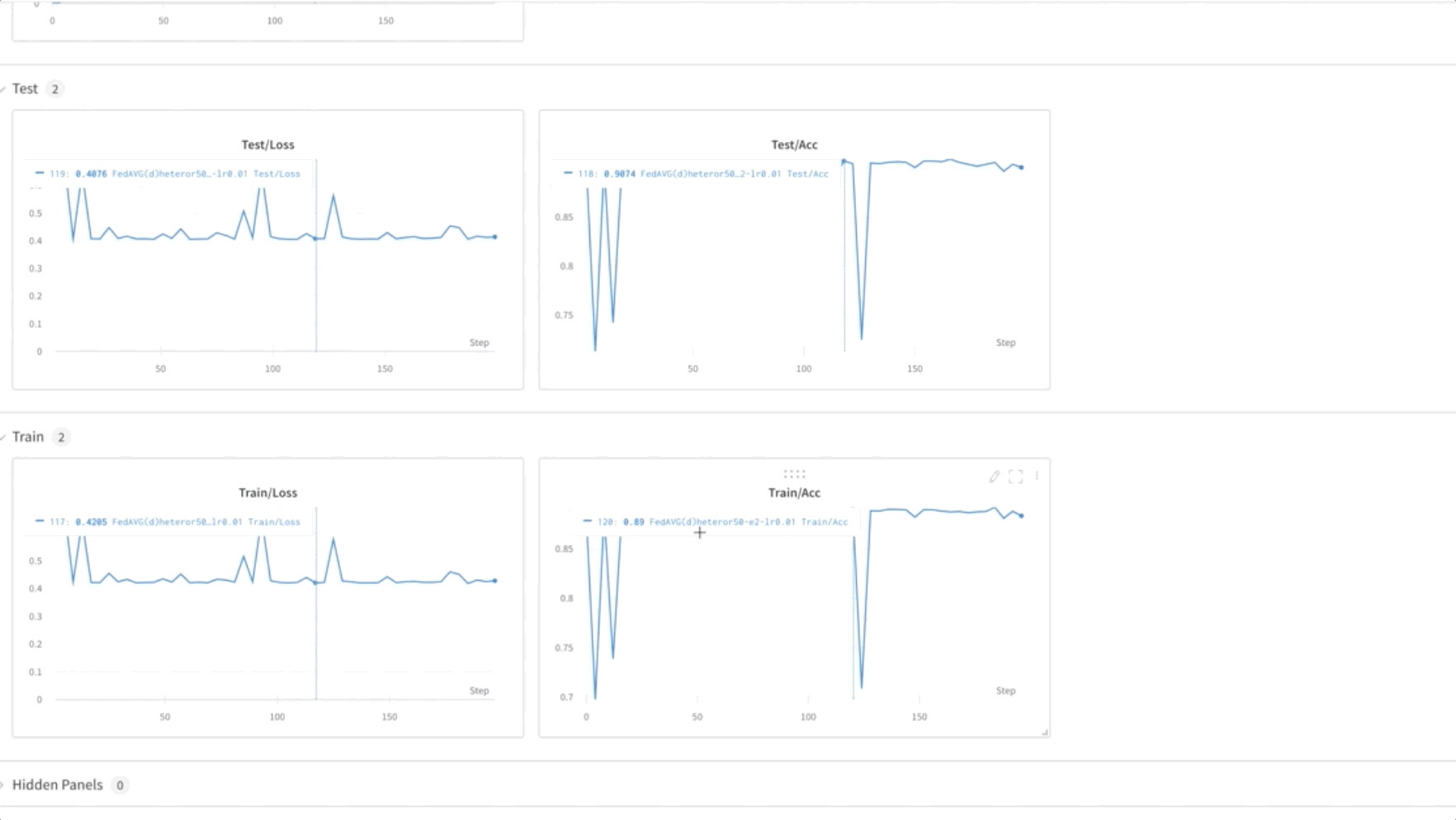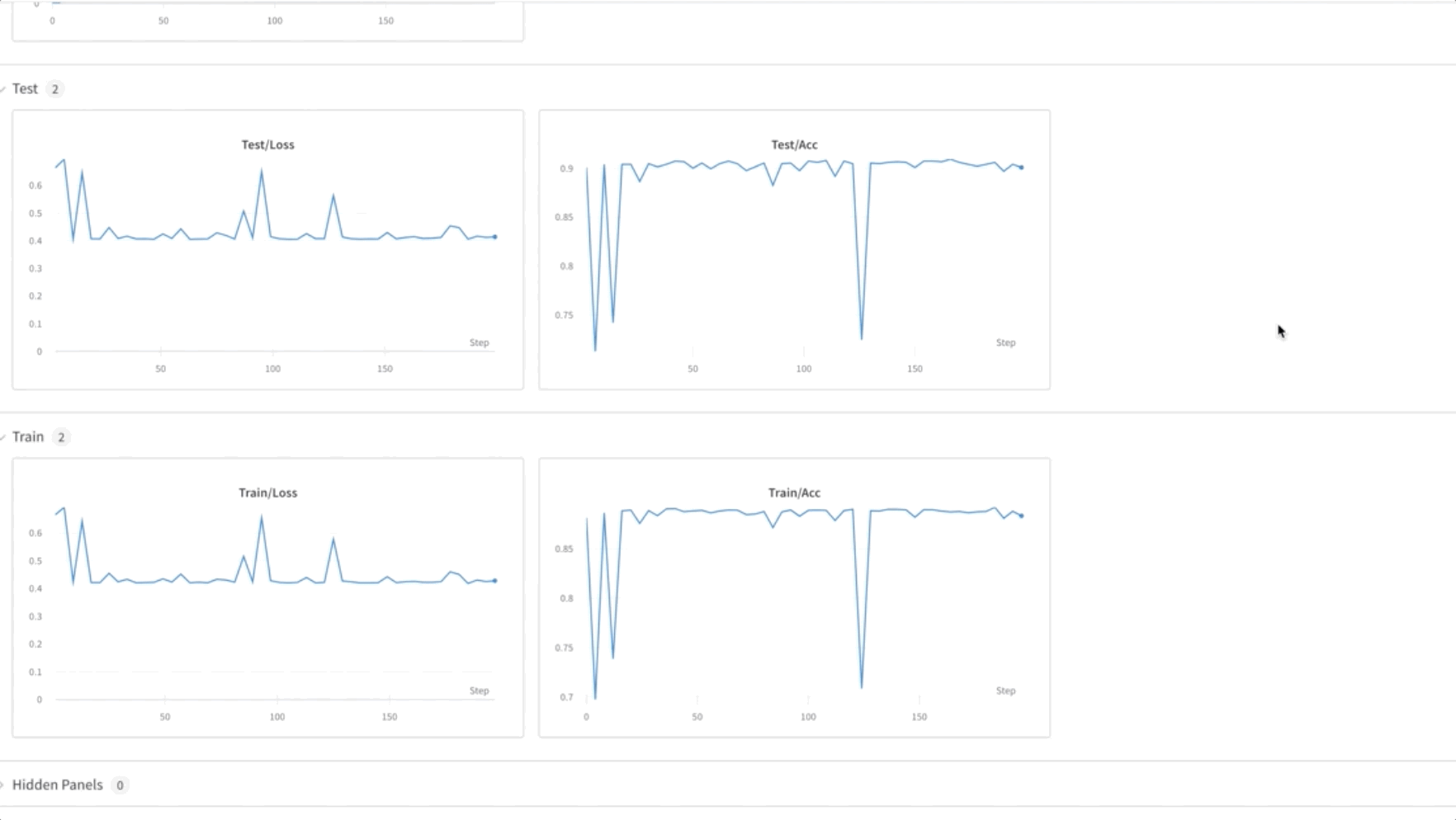
- Model FL usposabljamo za 50 epoh. Kot lahko vidite v spodnjem videoposnetku, se uteži prenašajo med vozlišči 0, 1 in 2, kar kaže, da usposabljanje napreduje, kot je pričakovano, na združen način.
- Na koncu spremljajte in sledite napredovanju usposabljanja modela FL v različnih vozliščih v gruči z uporabo uteži in pristranskosti (wandb), kot je prikazano na naslednjem posnetku zaslona. Sledite navedenim korakom tukaj za namestitev wandb in nastavitev nadzora za to rešitev.
Naslednji video zajema vse te korake za zagotovitev celovite predstavitve FL na AWS z uporabo FedML:
zaključek
V tej objavi smo pokazali, kako lahko namestite ogrodje FL, ki temelji na odprtokodnem FedML, na AWS. Omogoča vam, da usposobite model ML na porazdeljenih podatkih, ne da bi jih morali deliti ali premikati. Vzpostavili smo arhitekturo z več računi, kjer se lahko v resničnem scenariju bolnišnice ali zdravstvene organizacije pridružijo ekosistemu in izkoristijo sodelovalno učenje ob ohranjanju upravljanja podatkov. Za testiranje te uvedbe smo uporabili nabor podatkov eICU za več bolnišnic. Ta okvir je mogoče uporabiti tudi za druge primere uporabe in domene. To delo bomo še naprej širili z avtomatizacijo uvajanja prek infrastrukture kot kode (z uporabo Oblikovanje oblaka AWS), ki dodatno vključuje mehanizme za ohranjanje zasebnosti ter izboljšuje interpretabilnost in poštenost modelov FL.
Oglejte si predstavitev na re:MARS 2022, ki se osredotoča na »Upravljano zvezno učenje na AWS: študija primera za zdravstveno varstvo” za podroben potek te rešitve.
Reference
[1] Pollard, Tom J., et al. »Zbirka podatkov eICU Collaborative Research Database, prosto dostopna multicentrična baza podatkov za raziskave intenzivne nege.« Znanstveni podatki 5.1 (2018): 1-13.
[2] Yin, X., Zhu, Y. in Hu, J., 2021. Obsežna raziskava zveznega učenja, ki ohranja zasebnost: taksonomija, pregled in prihodnje smernice. ACM Computing Surveys (CSUR), 54(6), pp.1-36.
[3] Sheikhalishahi, Seyedmostafa, Vevake Balaraman in Venet Osmani. "Primerjalna analiza modelov strojnega učenja na naboru podatkov o intenzivni negi multicentričnega eICU." Plos ena 15.7 (2020): e0235424.
O avtorjih
 Vidya Sagar Ravipati je vodja pri Amazon ML Solutions Lab, kjer izkorišča svoje bogate izkušnje v obsežnih porazdeljenih sistemih in svojo strast do strojnega učenja, ki strankam AWS v različnih panogah industrije pomaga pospešiti njihovo uvajanje umetne inteligence in oblakov. Prej je bil inženir strojnega učenja v storitvah povezljivosti pri Amazonu, ki je pomagal zgraditi platforme za personalizacijo in predvidevanje vzdrževanja.
Vidya Sagar Ravipati je vodja pri Amazon ML Solutions Lab, kjer izkorišča svoje bogate izkušnje v obsežnih porazdeljenih sistemih in svojo strast do strojnega učenja, ki strankam AWS v različnih panogah industrije pomaga pospešiti njihovo uvajanje umetne inteligence in oblakov. Prej je bil inženir strojnega učenja v storitvah povezljivosti pri Amazonu, ki je pomagal zgraditi platforme za personalizacijo in predvidevanje vzdrževanja.
 Olivia Choudhury, PhD, je višji partnerski arhitekt rešitev pri AWS. Pomaga partnerjem na področju zdravstva in bioloških ved pri načrtovanju, razvoju in prilagajanju najsodobnejših rešitev, ki uporabljajo AWS. Ima izkušnje z genomiko, zdravstveno analitiko, zveznim učenjem in strojnim učenjem, ki varuje zasebnost. Zunaj službe igra družabne igre, slika pokrajine in zbira mange.
Olivia Choudhury, PhD, je višji partnerski arhitekt rešitev pri AWS. Pomaga partnerjem na področju zdravstva in bioloških ved pri načrtovanju, razvoju in prilagajanju najsodobnejših rešitev, ki uporabljajo AWS. Ima izkušnje z genomiko, zdravstveno analitiko, zveznim učenjem in strojnim učenjem, ki varuje zasebnost. Zunaj službe igra družabne igre, slika pokrajine in zbira mange.
 Wajahat Aziz je glavni arhitekt za strojno učenje in rešitve HPC pri AWS, kjer se osredotoča na pomoč strankam v zdravstvu in znanosti o življenju pri uporabi tehnologij AWS za razvoj najsodobnejših rešitev ML in HPC za najrazličnejše primere uporabe, kot je razvoj zdravil, Klinična preskušanja in strojno učenje, ki ohranja zasebnost. Zunaj službe Wajahat rad raziskuje naravo, pohodništvo in branje.
Wajahat Aziz je glavni arhitekt za strojno učenje in rešitve HPC pri AWS, kjer se osredotoča na pomoč strankam v zdravstvu in znanosti o življenju pri uporabi tehnologij AWS za razvoj najsodobnejših rešitev ML in HPC za najrazličnejše primere uporabe, kot je razvoj zdravil, Klinična preskušanja in strojno učenje, ki ohranja zasebnost. Zunaj službe Wajahat rad raziskuje naravo, pohodništvo in branje.
 Divya Bhargavi je podatkovni znanstvenik in vertikalni vodja medijev in zabave pri Amazon ML Solutions Lab, kjer rešuje pomembne poslovne probleme za stranke AWS z uporabo strojnega učenja. Ukvarja se z razumevanjem slik/videoposnetkov, priporočilnimi sistemi grafov znanja, primeri uporabe napovednega oglaševanja.
Divya Bhargavi je podatkovni znanstvenik in vertikalni vodja medijev in zabave pri Amazon ML Solutions Lab, kjer rešuje pomembne poslovne probleme za stranke AWS z uporabo strojnega učenja. Ukvarja se z razumevanjem slik/videoposnetkov, priporočilnimi sistemi grafov znanja, primeri uporabe napovednega oglaševanja.
 Ujjwal Ratan je vodja za AI/ML in Data Science v poslovni enoti AWS Healthcare and Life Science in je tudi glavni arhitekt rešitev AI/ML. V preteklih letih je bil Ujjwal vodilni v industriji zdravstva in znanosti o življenju, saj je številnim organizacijam s seznama Global Fortune 500 pomagal doseči njihove inovacijske cilje s sprejetjem strojnega učenja. Njegovo delo, ki je vključevalo analizo medicinskega slikanja, nestrukturiranega kliničnega besedila in genomike, je AWS pomagalo zgraditi izdelke in storitve, ki zagotavljajo visoko personalizirano in natančno usmerjeno diagnostiko in terapevtiko. V prostem času rad posluša (in predvaja) glasbo in se z družino odpravi na nenačrtovane izlete.
Ujjwal Ratan je vodja za AI/ML in Data Science v poslovni enoti AWS Healthcare and Life Science in je tudi glavni arhitekt rešitev AI/ML. V preteklih letih je bil Ujjwal vodilni v industriji zdravstva in znanosti o življenju, saj je številnim organizacijam s seznama Global Fortune 500 pomagal doseči njihove inovacijske cilje s sprejetjem strojnega učenja. Njegovo delo, ki je vključevalo analizo medicinskega slikanja, nestrukturiranega kliničnega besedila in genomike, je AWS pomagalo zgraditi izdelke in storitve, ki zagotavljajo visoko personalizirano in natančno usmerjeno diagnostiko in terapevtiko. V prostem času rad posluša (in predvaja) glasbo in se z družino odpravi na nenačrtovane izlete.
 Chaoyang He je soustanovitelj in tehnični direktor FedML, Inc., zagonskega podjetja, ki se zavzema za skupnost, ki gradi odprto in sodelovalno umetno inteligenco od koder koli in v katerem koli obsegu. Njegove raziskave se osredotočajo na algoritme, sisteme in aplikacije porazdeljenega/zveznega strojnega učenja. Doktoriral je. iz računalništva iz University of Southern California, Los Angeles, ZDA.
Chaoyang He je soustanovitelj in tehnični direktor FedML, Inc., zagonskega podjetja, ki se zavzema za skupnost, ki gradi odprto in sodelovalno umetno inteligenco od koder koli in v katerem koli obsegu. Njegove raziskave se osredotočajo na algoritme, sisteme in aplikacije porazdeljenega/zveznega strojnega učenja. Doktoriral je. iz računalništva iz University of Southern California, Los Angeles, ZDA.
 Salman Avestimehr je soustanovitelj in izvršni direktor FedML, Inc., zagonskega podjetja, ki se zavzema za skupnost, ki gradi odprto in sodelovalno umetno inteligenco od koder koli in v katerem koli obsegu. Salman Avestimehr je svetovno znani strokovnjak za zvezno učenje z več kot 20-letnim vodstvom na področju raziskav in razvoja v akademskem svetu in industriji. Je dekanski profesor in uvodni direktor Centra USC-Amazon za zanesljivo strojno učenje na Univerzi Južne Kalifornije. Bil je tudi Amazon Scholar v Amazonu. Je dobitnik predsedniške nagrade Združenih držav Amerike za svoje globoke prispevke na področju informacijske tehnologije in član IEEE.
Salman Avestimehr je soustanovitelj in izvršni direktor FedML, Inc., zagonskega podjetja, ki se zavzema za skupnost, ki gradi odprto in sodelovalno umetno inteligenco od koder koli in v katerem koli obsegu. Salman Avestimehr je svetovno znani strokovnjak za zvezno učenje z več kot 20-letnim vodstvom na področju raziskav in razvoja v akademskem svetu in industriji. Je dekanski profesor in uvodni direktor Centra USC-Amazon za zanesljivo strojno učenje na Univerzi Južne Kalifornije. Bil je tudi Amazon Scholar v Amazonu. Je dobitnik predsedniške nagrade Združenih držav Amerike za svoje globoke prispevke na področju informacijske tehnologije in član IEEE.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/part-2-federated-learning-on-aws-with-fedml-health-analytics-without-sharing-sensitive-data/
- 000
- 1
- 10
- 100
- 20 let
- 2018
- 2020
- 2021
- 2022
- 28
- 7
- 9
- a
- O meni
- nad
- Akademija
- pospeši
- Sprejmi
- dostop
- dostopna
- Račun
- odgovornost
- računi
- Doseči
- čez
- Zakon
- prilagodijo
- Naslov
- priznal
- sprejet
- Sprejem
- Sprejetje
- Oglaševanje
- po
- združevanje
- Združevalec
- AI
- AI / ML
- algoritmi
- vsi
- omogoča
- Amazon
- Amazon EC2
- Analiza
- analitika
- analizirati
- analiziranje
- in
- Angeles
- Še ena
- kjerkoli
- aplikacije
- uporabna
- pristop
- primerno
- Arhitektura
- povezan
- avtomatizacija
- Na voljo
- Nagrada
- AWS
- Backend
- ozadje
- temeljijo
- ker
- pred
- počutje
- spodaj
- merilo
- koristi
- med
- Block
- Blog
- svet
- Namizne igre
- Pasovi
- BP
- izgradnjo
- Building
- zgrajena
- poslovni
- california
- klic
- ujame
- ki
- primeru
- diplomsko delo
- primeri
- center
- centralizirano
- ceo
- izzivi
- Spremembe
- spreminjanje
- izbira
- Izberite
- izbran
- razred
- Razvrstitev
- stranke
- stranke
- klinični
- kliničnih preskušanj
- Cloud
- sprejem v oblak
- Grozd
- So-ustanovitelj
- Koda
- Kohorta
- sodelovanje
- zbira
- Stolpec
- Stolpci
- Koma
- Komunikacija
- skupnost
- stavba skupnosti
- dokončanje
- celovito
- Izračunajte
- računalnik
- Računalništvo
- računalništvo
- Koncept
- koncepti
- konfiguracija
- Connect
- povezane
- povezava
- Povezovanje
- šteje
- Konzole
- naprej
- prispevkov
- pretvori
- Ustrezno
- strošek
- ustvarjajo
- ustvaril
- ustvari
- Ustvarjanje
- kritično
- CTO
- po meri
- Stranke, ki so
- prilagodite
- datum
- dostop do podatkov
- uhajanje podatkov
- podatkovne točke
- zasebnost podatkov
- znanost o podatkih
- podatkovni znanstvenik
- izmenjavo podatkov
- Baze podatkov
- Decentralizirano
- Odločitev
- globoko
- globoko učenje
- privzeto
- izkazati
- razporedi
- uvajanje
- opisano
- Oblikovanje
- destinacija
- podrobno
- Podrobnosti
- določanje
- Razvoj
- razvoju
- Razvoj
- Dialog
- drugačen
- težko
- dimenzije
- neposredno
- Direktor
- porazdeljena
- porazdeljeno računalništvo
- porazdeljeni sistemi
- distribucija
- Ne
- tem
- domena
- domen
- drog
- razvoj zdravil
- med
- vsak
- prej
- ekosistem
- učinkovitosti
- učinkovite
- omogočajo
- omogočena
- omogoča
- konec koncev
- inženir
- zagotovitev
- zagotavlja
- Vnesite
- Zabava
- epohe
- napake
- vzpostaviti
- Eter (ETH)
- dogodki
- Primer
- obstoječih
- Pričakuje
- izkušnje
- strokovnjak
- raziskuje
- razširiti
- oči
- pravičnost
- družina
- Lastnosti
- kolega
- Slika
- file
- datoteke
- končno
- prva
- Pretok
- Osredotočite
- osredotočena
- Osredotoča
- sledi
- po
- Fortune
- je pokazala,
- Okvirni
- brezplačno
- iz
- funkcija
- funkcije
- nadalje
- Poleg tega
- Prihodnost
- Games
- Spol
- genomika
- gif
- Globalno
- Go
- Cilji
- upravljanje
- GPU
- graf
- grafi
- skupina
- Skupine
- Smernice
- ročaj
- Zdravje
- zdravstveno zavarovanje
- zdravstveno varstvo
- Hero
- pomoč
- pomagal
- pomoč
- Pomaga
- tukaj
- zelo
- pohodništvo
- zgodovina
- Bolnišnica
- bolnišnice
- gostila
- URE
- Kako
- hpc
- HTML
- HTTPS
- idealen
- IEEE
- slika
- slikanje
- neravnovesje
- izvajati
- uvoz
- izboljšanje
- izboljšanju
- in
- Otvoritveni
- Inc
- vključuje
- vključujoč
- Indeks
- Industrija
- Podatki
- Infrastruktura
- Inovacije
- vhod
- namestitev
- primer
- zavarovanje
- vmesnik
- Internet
- Internet stvari
- Internet stvari
- IT
- pridružite
- Ključne
- znanje
- Oznake
- Laboratorij
- Pomanjkanje
- obsežne
- kosilo
- vodi
- Vodja
- Vodstvo
- učenje
- dolžina
- Vzvod
- Leverages
- vzvod
- življenje
- Znanost o življenju
- Life Sciences
- vrstica
- Seznam
- Navedeno
- Poslušanje
- obremenitev
- nakladač
- obremenitve
- lokalna
- lokalno
- nahaja
- Long
- jih
- Los Angeles
- off
- stroj
- strojno učenje
- je
- vzdrževati
- vzdrževanje
- Znamka
- IZDELA
- upravljanje
- upravitelj
- Način
- kartiranje
- marec
- pomeni
- meritve
- mediji
- medicinski
- medicinsko slikanje
- Srečati
- omenjeno
- Metoda
- Metode
- MIT
- Omiliti
- ML
- ML algoritmi
- Model
- modeli
- monitor
- spremljanje
- več
- Motor
- premikanje
- premikanje
- več
- Glasba
- Ime
- Narava
- ostalo
- Nimate
- potrebna
- potrebe
- negativna
- mreža
- Vozel
- vozlišča
- Številka
- otopeli
- ONE
- odprite
- open source
- operacije
- optimalna
- organizacije
- Ostalo
- zunaj
- lastne
- v lasti
- Lastnik
- podokno
- parametri
- del
- partner
- partnerji
- opravil
- strast
- pot
- Bolnik
- bolniki
- peer
- opravlja
- performance
- opravlja
- personalizacija
- Prilagojene
- plinovod
- Kraj
- Načrt
- Platforme
- platon
- Platonova podatkovna inteligenca
- PlatoData
- igranje
- prosim
- Točka
- točke
- pozira
- pozitiven
- Prispevek
- Praktično
- Ravno
- napovedati
- napovedovanje
- napoved
- predstaviti
- predstavitev
- predsedniški
- tlak
- preprečiti
- prej
- , ravnateljica
- zasebnost
- zasebna
- problem
- Težave
- Postopek
- proizvodnja
- Izdelki
- Izdelki in storitve
- Učitelj
- napreduje
- napredovanje
- prepovedati
- Projekt
- dokazilo
- dokaz koncepta
- predlaga
- zagotavljajo
- zagotavlja
- zagotavljanje
- javno
- Namen
- pitorha
- R & D
- naključno
- REDKO
- Oceniti
- razmerje
- RE
- reading
- pripravljen
- resnični svet
- prejetih
- Priporočilo
- zapis
- Zabeležena
- evidence
- okolica
- regresija
- urejeno
- regulatorni
- odstrani
- Skladišče
- predstavlja
- zahteva
- zahteva
- zahteva
- Zahteve
- zahteva
- Raziskave
- tisti,
- vrnitev
- vrne
- pregleda
- cesta
- grobo
- Pot
- ROW
- pravila
- Run
- tek
- Enako
- Lestvica
- Znanost
- ZNANOSTI
- Znanstvenik
- skripte
- brez težav
- drugi
- varnost
- Seek
- izbran
- SAMO
- višji
- občutljiva
- Serija
- Storitve
- nastavite
- Kompleti
- nastavitev
- nastavitev
- sedem
- več
- Delite s prijatelji, znanci, družino in partnerji :-)
- deli
- delitev
- pokazale
- Razstave
- podpisati
- Znaki
- Podoben
- podobno
- sam
- spletna stran
- Spletna mesta
- So
- Rešitev
- rešitve
- Rešuje
- vir
- Južna
- razponi
- specifična
- po delih
- stabilna
- standardna
- Začetek
- začel
- zagon
- state-of-the-art
- Države
- Status
- bivanje
- Koraki
- shranjevanje
- strukturirano
- strukturirani in nestrukturirani podatki
- študija
- slog
- podomrežja
- taka
- dovolj
- podpora
- Podpira
- Anketa
- sistem
- sistemi
- miza
- TAG
- ob
- ciljna
- ciljno
- Naloga
- taksonomija
- Tehnologije
- Tehnologija
- Predloga
- Test
- O
- njihove
- terapevtiki
- stvari
- tretja
- mislil
- 3
- skozi
- vsej
- čas
- Časovne serije
- zamudno
- do
- orodje
- orodja
- baklo
- Torchvision
- Skupaj za plačilo
- sledenje
- Prometa
- Vlak
- usposabljanje
- prenese
- poskusi
- zaupanja
- Vrste
- tipično
- osnovni
- razumevanje
- edinstven
- Enota
- Velika
- Združene države Amerike
- enote
- univerza
- University of Southern California
- Nadgradnja
- posodobitve
- us
- ZDA
- uporaba
- primeru uporabe
- vrednost
- Vrednote
- raznolikost
- različnih
- Popravljeno
- vertikale
- preko
- Video
- Virtual
- vidna
- ključnega pomena
- walkthrough
- ki
- medtem
- WHO
- široka
- bo
- v
- brez
- delo
- deluje
- svetovno znani
- X
- let
- Vaša rutina za
- zefirnet