Novembra 2022 smo razglasitve s katerimi lahko stranke AWS ustvarijo slike iz besedila Stabilna difuzija modeli v Amazon SageMaker JumpStart. Stable Diffusion je model globokega učenja, ki vam omogoča ustvarjanje realističnih, visokokakovostnih slik in osupljive umetnosti v samo nekaj sekundah. Čeprav lahko ustvarjanje impresivnih slik najde uporabo v panogah, ki segajo od umetnosti do NFT-jev in več, danes pričakujemo tudi, da bo umetna inteligenca prilagodljiva. Danes oznanjamo, da lahko model generiranja slik prilagodite svojemu primeru uporabe tako, da ga natančno prilagodite na svojem naboru podatkov po meri v Amazon SageMaker JumpStart. To je lahko uporabno pri ustvarjanju umetnosti, logotipov, dizajnov po meri, NFT-jev itd. ali zabavnih stvari, kot je ustvarjanje slik umetne inteligence po meri vaših hišnih ljubljenčkov ali vaših avatarjev.
V tej objavi ponujamo pregled, kako natančno prilagoditi model stabilne difuzije na dva načina: programsko prek API-ji JumpStart na voljo v SDK SageMaker Pythonin JumpStartov uporabniški vmesnik (UI) v Amazon SageMaker Studio. Razpravljamo tudi o tem, kako narediti načrtovalske odločitve, vključno s kakovostjo nabora podatkov, velikostjo nabora podatkov za usposabljanje, izbiro vrednosti hiperparametrov in uporabnostjo za več naborov podatkov. Na koncu razpravljamo o več kot 80 javno dostopnih natančno nastavljenih modelih z različnimi vnosnimi jeziki in slogi, nedavno dodanimi v JumpStart.
Stabilno difuzijsko in prenosno učenje
Stable Diffusion je model besedila v sliko, ki vam omogoča ustvarjanje fotorealističnih slik samo iz besedilnega poziva. Difuzijski model se uri z učenjem odstranjevanja šuma, ki je bil dodan resnični sliki. Ta postopek odstranjevanja šuma ustvari realistično sliko. Ti modeli lahko ustvarijo slike tudi samo iz besedila, tako da proces generiranja pogojevajo z besedilom. Stabilna difuzija je na primer latentna difuzija, pri kateri se model nauči prepoznati oblike v sliki s čistim šumom in postopoma postavi te oblike v fokus, če se oblike ujemajo z besedami v vhodnem besedilu. Besedilo je treba najprej vdelati v latentni prostor z jezikovnim modelom. Nato se izvede niz operacij dodajanja in odstranjevanja hrupa v latentnem prostoru z arhitekturo U-Net. Končno se izhod brez šuma dekodira v prostor slikovnih pik.
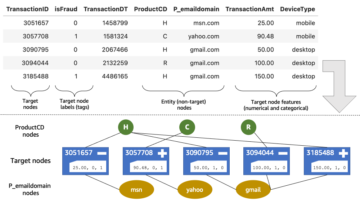
V strojnem učenju (ML) se imenuje zmožnost prenosa znanja, pridobljenega v eni domeni v drugo transferno učenje. Učenje prenosa lahko uporabite za izdelavo natančnih modelov na svojih manjših naborih podatkov z veliko nižjimi stroški usposabljanja kot stroški usposabljanja izvirnega modela. S prenosnim učenjem lahko natančno prilagodite model stabilne difuzije na svojem naboru podatkov s samo petimi slikami. Na primer, na levi so slike treninga psa z imenom Doppler, ki se uporablja za natančno nastavitev modela, na sredini in na desni pa so slike, ki jih je ustvaril natančno nastavljeni model, ko je bil pozvan, da predvidi Dopplerjevo sliko na plaži, in skico s svinčnikom.

Na levi sta sliki belega stola, ki se uporablja za natančno nastavitev modela, in podoba rdečega stola, ki jo ustvari natančno nastavljen model. Na desni strani so slike otomanke, ki se uporablja za natančno nastavitev modela, in podoba mačke, ki sedi na otomanki.

Natančna nastavitev velikih modelov, kot je Stable Diffusion, običajno zahteva, da zagotovite skripte za usposabljanje. Obstaja vrsta težav, vključno s težavami s pomanjkanjem pomnilnika, težavami z velikostjo tovora in drugimi. Poleg tega morate zagnati preskuse od konca do konca, da zagotovite, da skript, model in želeni primerek delujejo skupaj na učinkovit način. JumpStart poenostavlja ta postopek z zagotavljanjem skriptov, pripravljenih za uporabo, ki so bili temeljito preizkušeni. Skript za fino uravnavanje JumpStart za modele stabilne difuzije temelji na skriptu za fino uravnavanje iz dreambooth. Do teh skriptov lahko dostopate z enim klikom prek uporabniškega vmesnika Studio ali z zelo malo vrsticami kode prek API-ji JumpStart.
Upoštevajte, da se z uporabo modela stabilne difuzije strinjate z Licenca CreativeML Open RAIL++-M.
Uporabite JumpStart programsko s SDK SageMaker
Ta razdelek opisuje, kako usposobiti in razmestiti model z SDK SageMaker Python. Izberemo ustrezen vnaprej usposobljen model v JumpStartu, usposobimo ta model z učnim opravilom SageMaker in uvedemo usposobljen model v končno točko SageMaker. Poleg tega izvajamo sklepanje na razporejeni končni točki, vse z uporabo SDK-ja SageMaker Python. Naslednji primeri vsebujejo delčke kode. Za celotno kodo z vsemi koraki v tej predstavitvi glejte Uvod v JumpStart – besedilo v sliko primer zvezka.
Usposobite in natančno prilagodite model stabilne difuzije
Vsak model je označen z edinstveno oznako model_id. Naslednja koda prikazuje, kako natančno prilagoditi osnovni model Stable Diffusion 2.1, ki ga identificira model_id model-txt2img-stabilityai-stable-diffusion-v2-1-base na naboru podatkov za usposabljanje po meri. Za popoln seznam model_id vrednosti in kateri modeli so fino nastavljivi, glejte Vgrajeni algoritmi z vnaprej pripravljeno tabelo modelov. Za vsakogar model_id, da bi prek Ocenjevalnik razreda SDK SageMaker Python, morate pridobiti URI slike Docker, URI skripta za usposabljanje in URI vnaprej usposobljenega modela prek pomožnih funkcij, ki jih ponuja SageMaker. URI skripte za usposabljanje vsebuje vso potrebno kodo za obdelavo podatkov, nalaganje vnaprej usposobljenega modela, usposabljanje modela in shranjevanje usposobljenega modela za sklepanje. URI vnaprej usposobljenega modela vsebuje definicijo vnaprej usposobljene arhitekture modela in parametre modela. Vnaprej usposobljen URI modela je specifičen za določen model. Vnaprej usposobljeni arhivi modelov so bili vnaprej preneseni iz Hugging Face in shranjeni z ustreznim podpisom modela v Preprosta storitev shranjevanja Amazon (Amazon S3), tako da se usposabljanje izvaja v izolaciji omrežja. Oglejte si naslednjo kodo:
S temi vadbenimi artefakti, specifičnimi za model, lahko sestavite predmet Ocenjevalnik razred:
Nabor podatkov o usposabljanju
Sledijo navodila za oblikovanje podatkov o usposabljanju:
- vhod – Imenik, ki vsebuje slike primerkov,
dataset_info.json, z naslednjo konfiguracijo:- Slike so lahko v formatu .png, .jpg ali .jpeg
- O
dataset_info.jsondatoteka mora biti v formatu{'instance_prompt':<<instance_prompt>>}
- izhod – Usposobljen model, ki ga je mogoče uporabiti za sklepanje
Pot S3 bi morala izgledati takole s3://bucket_name/input_directory/. Upoštevajte zaostanek / je potrebno.
Sledi primer oblike podatkov o usposabljanju:
Za navodila o tem, kako formatirati podatke med uporabo predhodnega ohranjanja, glejte razdelek Predhodno ohranjanje v tej objavi.
Ponujamo privzeti nabor podatkov slik mačk. Sestavljen je iz osmih slik (slike primerkov, ki ustrezajo pozivu primerka) ene mačke brez slik razreda. Prenesete ga lahko iz GitHub. Če uporabljate privzeti nabor podatkov, med sklepanjem v predstavitvenem zvezku poskusite uporabiti poziv »fotografija mačke riobugger«.
licenca: MIT.
Hiperparametri
Nato boste za prenos učenja na svojem naboru podatkov po meri morda morali spremeniti privzete vrednosti hiperparametrov usposabljanja. S klicem lahko pridobite slovar Python teh hiperparametrov z njihovimi privzetimi vrednostmi hyperparameters.retrieve_default, jih po potrebi posodobite in jih nato posredujte razredu Estimator. Oglejte si naslednjo kodo:
Algoritem za natančno nastavitev podpira naslednje hiperparametre:
- s_predhodno_ohranjenostjo – Označite za dodajanje predhodne izgube ohranjanja. Predhodno ohranjanje je regulator, ki preprečuje prekomerno opremljanje. (Možnosti:
[“True”,“False”], privzeto:“False”.) - num_class_images – Slike minimalnega razreda za predhodno izgubo ohranjenosti. če
with_prior_preservation = Truein že ni dovolj slikclass_data_dir, dodatne slike bodo vzorčene zclass_prompt. (Vrednosti: pozitivno celo število, privzeto: 100.) - Epohe – Število prehodov, ki jih opravi algoritem za natančno nastavitev skozi nabor podatkov za usposabljanje. (Vrednosti: pozitivno celo število, privzeto: 20.)
- Max_steps – Skupno število vadbenih korakov, ki jih je treba izvesti. Če ne
None, preglasi epohe. (Vrednote:“None”ali niz celega števila, privzeto:“None”.) - Velikost serije –: Število primerov usposabljanja, ki so obdelani, preden se posodobijo uteži modela. Enako kot velikost serije med ustvarjanjem slik razreda, če
with_prior_preservation = True. (Vrednosti: pozitivno celo število, privzeto: 1.) - stopnja učenja – Hitrost, s katero se uteži modela posodabljajo po delu skozi vsako serijo primerov usposabljanja. (Vrednosti: pozitivno plavajoče, privzeto: 2e-06.)
- prejšnja_izguba_teže – Teža izgube predhodnega ohranjanja. (Vrednosti: pozitivno plavajoče, privzeto: 1.0.)
- center_crop – Ali naj se slike obrežejo pred spreminjanjem velikosti na želeno ločljivost. (Možnosti:
[“True”/“False”], privzeto:“False”.) - lr_razporejevalnik – Vrsta urnika hitrosti učenja. (Možnosti:
["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"], privzeto:"constant".) Za več informacij glejte Načrtovalci hitrosti učenja. - adam_weight_decay – Razpad teže, ki se uporabi (če ni nič) za vse plasti, razen za vse pristranskosti in
LayerNormuteži vAdamWoptimizator. (Vrednost: float, privzeto: 1e-2.) - adam_beta1 – Hiperparameter beta1 (eksponentna stopnja upadanja za ocene prvega trenutka) za
AdamWoptimizator. (Vrednost: float, privzeto: 0.9.) - adam_beta2 – Hiperparameter beta2 (eksponentna stopnja upadanja za ocene prvega trenutka) za
AdamWoptimizator. (Vrednost: float, privzeto: 0.999.) - adam_epsilon -
epsilonhiperparameter zaAdamWoptimizator. Običajno je nastavljena na majhno vrednost, da se izognemo deljenju z 0. (Vrednost: float, privzeto: 1e-8.) - gradient_accumulation_steps – Število korakov posodobitev, ki jih je treba zbrati pred izvedbo prehoda nazaj/posodabljanja. (Vrednost: celo število, privzeto: 1.)
- max_grad_norm – Največja norma gradienta (za izrez gradienta). (Vrednost: float, privzeto: 1.0.)
- seme – Popravite naključno stanje, da dosežete ponovljive rezultate pri vadbi. (Vrednost: celo število, privzeto: 0.)
Razmestite natančno usposobljen model
Ko je usposabljanje modela končano, lahko model neposredno uvedete v obstojno končno točko v realnem času. Pridobimo zahtevane URI-je slike Docker in URI-je skriptov ter razmestimo model. Oglejte si naslednjo kodo:
Na levi strani so slike treninga mačke z imenom riobugger, uporabljene za natančno nastavitev modela (privzeti parametri razen max_steps = 400). Na sredini in desno sta sliki, ki ju je ustvaril natančno nastavljen model, ko je bil pozvan, naj napove podobo riobuggerja na plaži in skico s svinčnikom.

Za več podrobnosti o sklepanju, vključno s podprtimi parametri, obliko odziva in tako naprej, glejte Ustvarite slike iz besedila s stabilnim difuzijskim modelom na Amazon SageMaker JumpStart.
Do JumpStart dostopajte prek uporabniškega vmesnika Studio
V tem razdelku prikazujemo, kako učiti in uvajati modele JumpStart prek uporabniškega vmesnika Studio. Naslednji videoposnetek prikazuje, kako poiskati predhodno usposobljen model Stable Diffusion na JumpStart, ga usposobiti in nato razmestiti. Stran z modelom vsebuje dragocene informacije o modelu in o tem, kako ga uporabljati. Ko konfigurirate učni primerek SageMaker, izberite Vlak. Ko je model usposobljen, lahko uvedete učen model tako, da izberete uvajanje. Ko je končna točka v fazi »v uporabi«, je pripravljena odgovoriti na zahteve po sklepanju.
Da bi pospešili čas sklepanja, JumpStart ponuja vzorčni zvezek, ki prikazuje, kako zagnati sklepanje na novo ustvarjeni končni točki. Za dostop do zvezka v Studiu izberite Odprite Beležnico v Uporabite Endpoint iz Studia na strani končne točke modela.
JumpStart ponuja tudi preprost prenosni računalnik, ki ga lahko uporabite za natančno nastavitev stabilnega difuzijskega modela in uvajanje nastalega natančno nastavljenega modela. Uporabite ga lahko za ustvarjanje zabavnih slik svojega psa. Za dostop do zvezka poiščite »Ustvari zabavne slike svojega psa« v iskalni vrstici JumpStart. Za izvedbo zvezka lahko uporabite kar pet slik za usposabljanje in jih naložite v mapo lokalnega studia. Če imate več kot pet slik, jih lahko tudi naložite. Beležnica naloži slike za usposabljanje v S3, usposobi model na vašem naboru podatkov in uvede nastali model. Usposabljanje lahko traja 20 minut. Za pospešitev vadbe lahko spremenite število korakov. Beležnica ponuja nekaj vzorčnih pozivov, ki jih lahko poskusite z razporejenim modelom, vendar lahko poskusite kateri koli poziv, ki vam je všeč. Beležnico lahko prilagodite tudi za ustvarjanje avatarjev sebe ali svojih ljubljenčkov. Na primer, namesto svojega psa lahko v prvem koraku naložite slike svoje mačke in nato spremenite pozive iz psov v mačke in model bo ustvaril slike vaše mačke.
Premisleki o fini nastavitvi
Training Stable Diffusion modeli se nagibajo k temu, da se hitro preveč prilagodijo. Da bi dobili kakovostne slike, moramo najti dobro ravnovesje med razpoložljivimi vadbenimi hiperparametri, kot sta število vadbenih korakov in stopnja učenja. V tem razdelku prikazujemo nekaj eksperimentalnih rezultatov in nudimo smernice o tem, kako nastaviti te parametre.
Priporočila
Upoštevajte naslednja priporočila:
- Začnite z dobro kakovostjo vadbenih slik (4–20). Če trenirate na človeških obrazih, boste morda potrebovali več slik.
- Pri vadbi na psih ali mačkah in drugih nečloveških subjektih vadite 200–400 korakov. Če trenirate na človeških obrazih, boste morda potrebovali več korakov. Če pride do prekomernega opremljanja, zmanjšajte število korakov. Če pride do premajhnega prileganja (natančno nastavljen model ne more ustvariti slike ciljnega subjekta), povečajte število korakov.
- Če trenirate na nečloveških obrazih, lahko nastavite
with_prior_preservation = Falseker ne vpliva bistveno na uspešnost. Na človeških obrazih boste morda morali nastavitiwith_prior_preservation=True. - Če nastavitev
with_prior_preservation=True, uporabite vrsto primerka ml.g5.2xlarge. - Pri zaporednem usposabljanju več subjektov, če so subjekti zelo podobni (na primer vsi psi), model obdrži zadnji subjekt in pozabi prejšnje subjekte. Če sta subjekta različna (na primer najprej mačka, nato pes), model obdrži oba subjekta.
- Priporočamo uporabo nizke stopnje učenja in postopno povečevanje števila korakov, dokler rezultati niso zadovoljivi.
Nabor podatkov o usposabljanju
Na kakovost natančno nastavljenega modela neposredno vpliva kakovost slik za usposabljanje. Zato morate za dobre rezultate zbrati visokokakovostne slike. Zamegljene slike ali slike nizke ločljivosti bodo vplivale na kakovost natančno nastavljenega modela. Upoštevajte naslednje dodatne parametre:
- Število slik za usposabljanje – Model lahko natančno prilagodite na najmanj štirih slikah vadbe. Eksperimentirali smo z nabori podatkov za usposabljanje v velikosti le 4 slik in kar 16 slik. V obeh primerih je s fino nastavitvijo uspelo prilagoditi model subjektu.
- Formati nabora podatkov – Algoritem natančnega prilagajanja smo preizkusili na slikah formata .png, .jpg in .jpeg. Delujejo lahko tudi drugi formati.
- Ločljivost slike – Slike usposabljanja so lahko katere koli ločljivosti. Algoritem natančnega prilagajanja bo spremenil velikost vseh slik vadbe, preden začne natančno prilagajanje. Kot rečeno, če želite imeti večji nadzor nad obrezovanjem in spreminjanjem velikosti vadbenih slik, priporočamo, da sami spremenite velikost slik na osnovno ločljivost modela (v tem primeru 512 × 512 slikovnih pik).
Nastavitve poskusa
V poskusu v tej objavi med natančno nastavitvijo uporabljamo privzete vrednosti hiperparametrov, razen če so določene. Poleg tega uporabljamo enega od štirih naborov podatkov:
- Pes1-8 – Pes 1 z 8 slikami
- Pes1-16 – Pes 1 z 16 slikami
- Pes2-4 – Pes 2 s štirimi slikami
- Mačka-8 – Mačka z 8 slikami
Da bi zmanjšali nered, v vsakem razdelku skupaj z imenom nabora podatkov prikažemo samo eno reprezentativno sliko nabora podatkov. Celoten nabor treningov najdete v razdelku Eksperimentalni nabori podatkov v tej objavi.
Prekomerno opremljanje
Stabilni difuzijski modeli se pri natančnem prilagajanju nekaj slik ponavadi preveč prilegajo. Zato morate izbrati parametre, kot je npr epochs, max_epochs, in učenje ocenite previdno. V tem razdelku smo uporabili nabor podatkov Dog1-16.

Za ovrednotenje delovanja modela ocenimo natančno nastavljen model za štiri naloge:
- Ali lahko natančno nastavljeni model ustvari slike subjekta (psa Doppler) v enakem okolju, kot je bil učen?
- Opazovanje – Da, lahko. Omeniti velja, da se učinkovitost modela povečuje s številom korakov usposabljanja.
- Ali lahko natančno nastavljeni model ustvari slike subjekta v drugačnem okolju, kot je bilo urjeno? Ali lahko na primer ustvari slike Dopplerja na plaži?
- Opazovanje – Da, lahko. Omeniti velja, da se zmogljivost modela povečuje s številom korakov treninga do določene točke. Če pa se model uri predolgo, se zmogljivost modela poslabša, ker se model nagiba k pretiranemu prilagajanju.
- Ali lahko natančno nastavljen model ustvari slike razreda, ki mu pripada predmet usposabljanja? Ali lahko na primer ustvari sliko generičnega psa?
- Opazovanje – Ko povečamo število vadbenih korakov, se model začne pretirano prilagajati. Posledično pozabi na generični razred psa in ustvari samo slike, povezane s predmetom.
- Ali lahko natančno nastavljeni model ustvari slike razreda ali predmeta, ki ni v naboru podatkov o usposabljanju? Ali lahko na primer ustvari sliko mačke?
- Opazovanje – Ko povečamo število vadbenih korakov, se model začne pretirano prilagajati. Posledično bo ustvaril samo slike, povezane s predmetom, ne glede na navedeni razred.
Model fino prilagodimo za različno število korakov (z nastavitvijo max_steps hiperparametri) in za vsak natančno nastavljen model ustvarimo slike na vsakem od naslednjih štirih pozivov (prikazano v naslednjih primerih od leve proti desni:
- “Fotografija Dopplerjevega psa”
- »Fotografija Dopplerjevega psa na plaži«
- “Fotografija psa”
- "Fotografija mačke"
Naslednje slike so iz modela, treniranega s 50 koraki.

Naslednji model je bil treniran s 100 koraki.

Trenirali smo naslednji model z 200 koraki.

Naslednje slike so iz modela, treniranega s 400 koraki.

Nazadnje, naslednje slike so rezultat 800 korakov.

Usposabljajte se na več nizih podatkov
Med natančno nastavitvijo boste morda želeli natančno prilagoditi več subjektov in omogočiti, da natančno nastavljeni model ustvari slike vseh subjektov. Na žalost je JumpStart trenutno omejen na usposabljanje o eni sami temi. Modela ne morete natančno nastaviti na več temah hkrati. Poleg tega zaporedna fina nastavitev modela za različne subjekte povzroči, da model pozabi prvi subjekt, če so subjekti podobni.
V tem razdelku upoštevamo naslednje poskuse:
- Natančno prilagodite model za subjekt A.
- Natančno prilagodite nastali model iz 1. koraka za subjekt B.
- Ustvarite slike Subjekta A in Subjekta B z uporabo izhodnega modela iz 2. koraka.
V naslednjih poskusih opazimo, da:
- Če je A pes 1 in B pes 2, so vse slike, ustvarjene v koraku 3, podobne psu 2
- Če je A pes 2 in B pes 1, so vse slike, ustvarjene v koraku 3, podobne psu 1
- Če je A pes 1 in B je mačka, potem so slike, ustvarjene s pozivi psa, podobne psu 1 in slike, ustvarjene s pozivi mačke, so podobne mački
Vadite psa 1 in nato psa 2
V 1. koraku natančno prilagodimo model za 200 korakov na osmih slikah psa 1. V 2. koraku dodatno natančno prilagodimo model za 200 korakov na štirih slikah psa 2.

Sledijo slike, ki jih ustvari natančno nastavljeni model na koncu 2. koraka za različne pozive.

Vadite psa 2 in nato psa 1
V 1. koraku natančno prilagodimo model za 200 korakov na štirih slikah psa 2. V 2. koraku dodatno natančno prilagodimo model za 200 korakov na osmih slikah psa 1.

Sledijo slike, ki jih ustvari natančno nastavljeni model na koncu 2. koraka z različnimi pozivi.

Usposabljajte pse in mačke
V 1. koraku natančno prilagodimo model za 200 korakov na osmih slikah mačke. Nato dodatno prilagodimo model za 200 korakov na osmih slikah psa 1.

Sledijo slike, ki jih ustvari natančno nastavljeni model na koncu 2. koraka. Slike s pozivi, povezanimi z mačkami, so videti kot mačka v 1. koraku natančnega prilagajanja, slike s pozivi, povezanimi s psom, pa kot pes v 2. korak natančne nastavitve.

Predhodno konzerviranje
Predhodno ohranjanje je tehnika, ki uporablja dodatne slike istega razreda, na katerem poskušamo trenirati. Na primer, če so podatki o usposabljanju sestavljeni iz slik določenega psa, s predhodnim ohranjanjem vključimo slike razreda generičnih psov. Poskuša se izogniti pretiranemu opremljanju s prikazovanjem slik različnih psov med šolanjem za določenega psa. Oznaka, ki označuje določenega psa, prisotnega v pozivu primerka, manjka v pozivu razreda. Na primer, poziv primerka je lahko »fotografija mačke riobugger«, poziv razreda pa je lahko »fotografija mačke«. Predhodno ohranjanje lahko omogočite z nastavitvijo hiperparametra with_prior_preservation = True. Če nastavitev with_prior_preservation = True, morate vključiti class_prompt in dataset_info.json in lahko vključuje vse slike razreda, ki so vam na voljo. Sledi oblika nabora podatkov o usposabljanju pri nastavitvi with_prior_preservation = True:
- vhod – Imenik, ki vsebuje slike primerkov,
dataset_info.jsonin (izbirno) imenikclass_data_dir. Upoštevajte naslednje:- Slike so lahko v formatu .png, .jpg, .jpeg.
- O
dataset_info.jsondatoteka mora biti v formatu{'instance_prompt':<<instance_prompt>>,'class_prompt':<<class_prompt>>}. - O
class_data_dirImenik mora imeti slike razreda. čeclass_data_dirni prisoten ali pa že ni dovolj slikclass_data_dir, dodatne slike bodo vzorčene zclass_prompt.
Pri naborih podatkov, kot so mačke in psi, predhodno ohranjanje ne vpliva bistveno na delovanje natančno nastavljenega modela in se mu je zato mogoče izogniti. Pri treningu na obrazih pa je to nujno. Za več informacij glejte Usposabljanje stabilne difuzije z Dreamboothom z uporabo difuzorjev.
Vrste primerkov
Natančno prilagajanje modelov stabilne difuzije zahteva pospešeno računanje, ki ga zagotavljajo primerki, ki jih podpira GPU. Eksperimentiramo s finim prilagajanjem z instancama ml.g4dn.2xlarge (16 GB pomnilnika CUDA, 1 GPE) in ml.g5.2xlarge (24 GB pomnilnika CUDA, 1 GPE). Pri generiranju slik razreda je zahteva po pomnilniku višja. Zato, če nastavitev with_prior_preservation=True, uporabite vrsto primerka ml.g5.2xlarge, ker usposabljanje naleti na težavo s pomanjkanjem pomnilnika CUDA na primerku ml.g4dn.2xlarge. Skript za natančno nastavitev JumpStart trenutno uporablja en sam GPE, zato natančna nastavitev na primerkih z več GPU ne bo prinesla povečanja zmogljivosti. Za več informacij o različnih vrstah primerkov glejte Vrste primerkov Amazon EC2.
Omejitve in pristranskost
Čeprav ima Stable Diffusion impresivno zmogljivost pri ustvarjanju slik, ima številne omejitve in pristranskosti. Ti vključujejo, vendar niso omejeni na:
- Model morda ne bo ustvaril natančnih obrazov ali udov, ker podatki o vadbi ne vključujejo dovolj slik s temi funkcijami
- Model je bil usposobljen na Nabor podatkov LAION-5B, ki ima vsebino za odrasle in morda ne bo primeren za uporabo v izdelku brez nadaljnjih premislekov
- Model morda ne bo dobro deloval z neangleškimi jeziki, ker je bil model učen z besedilom v angleškem jeziku
- Model ne more ustvariti dobrega besedila v slikah
Za več informacij o omejitvah in pristranskosti glejte Kartica osnovnega modela Stable Diffusion v2-1. Te omejitve za predhodno usposobljen model se lahko prenesejo tudi na natančno nastavljene modele.
Čiščenje
Ko končate z zagonom zvezka, izbrišite vse vire, ustvarjene v procesu, da zagotovite, da je zaračunavanje ustavljeno. Koda za čiščenje končne točke je na voljo v povezanem Uvod v JumpStart – besedilo v sliko primer zvezka.
Javno dostopni natančno nastavljeni modeli v JumpStartu
Čeprav so modeli Stable Diffusion, ki jih je izdal Stabilnost AI imajo impresivno zmogljivost, imajo omejitve glede jezika ali domene, na kateri so bili usposobljeni. Na primer, modeli stabilne difuzije so bili usposobljeni za angleško besedilo, vendar boste morda morali ustvariti slike iz neangleškega besedila. Druga možnost je, da so bili modeli Stable Diffusion usposobljeni za ustvarjanje fotorealističnih slik, vendar boste morda morali ustvariti animirane ali umetniške slike.
JumpStart ponuja več kot 80 javno dostopnih modelov z različnimi jeziki in temami. Ti modeli so pogosto natančno prilagojene različice modelov Stable Diffusion, ki jih je izdal StabilityAI. Če se vaš primer uporabe ujema z enim od natančno nastavljenih modelov, vam ni treba zbirati lastnega nabora podatkov in ga natančno prilagajati. Enega od teh modelov lahko preprosto uvedete prek uporabniškega vmesnika Studio ali z API-ji JumpStart, ki so preprosti za uporabo. Če želite v JumpStart uvesti predhodno usposobljen model stabilne difuzije, glejte Ustvarite slike iz besedila s stabilnim difuzijskim modelom na Amazon SageMaker JumpStart.
Sledi nekaj primerov slik, ustvarjenih z različnimi modeli, ki so na voljo v JumpStartu.


Upoštevajte, da ti modeli niso natančno nastavljeni s skripti JumpStart ali skripti DreamBooth. Celoten seznam javno dostopnih natančno nastavljenih modelov s primeri pozivov lahko prenesete s tukaj.
Za več primerov ustvarjenih slik iz teh modelov glejte razdelek Odprtokodni fino nastavljeni modeli v prilogi.
zaključek
V tej objavi smo pokazali, kako natančno prilagoditi model Stable Diffusion za besedilo v sliko in ga nato razmestiti s pomočjo JumpStart. Poleg tega smo razpravljali o nekaterih premislekih, ki jih morate upoštevati pri natančnem prilagajanju modela, in o tem, kako lahko to vpliva na zmogljivost natančno nastavljenega modela. Razpravljali smo tudi o več kot 80 modelih, pripravljenih za uporabo, ki so na voljo v JumpStartu. V tej objavi smo prikazali delčke kode – za celotno kodo z vsemi koraki v tej predstavitvi glejte Uvod v JumpStart – besedilo v sliko primer zvezka. Preizkusite rešitev sami in nam pošljite svoje komentarje.
Če želite izvedeti več o modelu in natančni nastavitvi DreamBooth, si oglejte naslednje vire:
Če želite izvedeti več o JumpStart, si oglejte naslednje objave v spletnem dnevniku:
O avtorjih
 dr. Vivek Madan je uporabni znanstvenik pri ekipi Amazon SageMaker JumpStart. Doktoriral je na Univerzi Illinois v Urbana-Champaign in bil podoktorski raziskovalec na Georgia Tech. Je aktiven raziskovalec strojnega učenja in oblikovanja algoritmov ter je objavil članke na konferencah EMNLP, ICLR, COLT, FOCS in SODA.
dr. Vivek Madan je uporabni znanstvenik pri ekipi Amazon SageMaker JumpStart. Doktoriral je na Univerzi Illinois v Urbana-Champaign in bil podoktorski raziskovalec na Georgia Tech. Je aktiven raziskovalec strojnega učenja in oblikovanja algoritmov ter je objavil članke na konferencah EMNLP, ICLR, COLT, FOCS in SODA.
 Heiko Hotz je višji arhitekt rešitev za umetno inteligenco in strojno učenje s posebnim poudarkom na obdelavi naravnega jezika (NLP), modelih velikih jezikov (LLM) in generativni umetni inteligenci. Pred to vlogo je bil vodja podatkovne znanosti za Amazonovo službo za stranke v EU. Heiko pomaga našim strankam, da so uspešne na njihovem potovanju AI/ML na AWS in je sodeloval z organizacijami v številnih panogah, vključno z zavarovalništvom, finančnimi storitvami, mediji in zabavo, zdravstvom, komunalnimi storitvami in proizvodnjo. V prostem času Heiko čim več potuje.
Heiko Hotz je višji arhitekt rešitev za umetno inteligenco in strojno učenje s posebnim poudarkom na obdelavi naravnega jezika (NLP), modelih velikih jezikov (LLM) in generativni umetni inteligenci. Pred to vlogo je bil vodja podatkovne znanosti za Amazonovo službo za stranke v EU. Heiko pomaga našim strankam, da so uspešne na njihovem potovanju AI/ML na AWS in je sodeloval z organizacijami v številnih panogah, vključno z zavarovalništvom, finančnimi storitvami, mediji in zabavo, zdravstvom, komunalnimi storitvami in proizvodnjo. V prostem času Heiko čim več potuje.
Dodatek: Eksperimentalni nabori podatkov
Ta razdelek vsebuje nabore podatkov, uporabljene v poskusih v tej objavi.
Pes1-8

Pes1-16

Pes2-4

Pes3-8

Dodatek: Odprtokodni fino nastavljeni modeli
Sledi nekaj primerov slik, ustvarjenih z različnimi modeli, ki so na voljo v JumpStartu. Vsaka slika je označena z a model_id ki se začne s predpono huggingface-txt2img- sledi poziv za ustvarjanje slike v naslednji vrstici.

























- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/fine-tune-text-to-image-stable-diffusion-models-with-amazon-sagemaker-jumpstart/
- 1
- 100
- 11
- 2022
- 9
- a
- sposobnost
- Sposobna
- O meni
- pospeši
- pospešeno
- dostop
- Akumulirajte
- natančna
- Doseči
- aktivna
- prilagodijo
- dodano
- Poleg tega
- Dodatne
- Izobraževanje odraslih
- po
- AI
- AI in strojno učenje
- AI / ML
- algoritem
- algoritmi
- vsi
- omogoča
- sam
- že
- Čeprav
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- in
- Objavi
- Še ena
- API-ji
- uporabna
- Uporabi
- primerno
- Arhitektura
- Umetnost
- umetniško
- povezan
- samodejno
- Na voljo
- avatarji
- izogniti
- izognili
- AWS
- Ravnovesje
- bar
- baza
- Beach
- ker
- pred
- počutje
- med
- Poleg
- pristranskosti
- zaračunavanje
- Blog
- Blog Prispevkov
- Prinaša
- Gradi
- se imenuje
- kliče
- previdno
- opravlja
- primeru
- primeri
- CAT
- Mačke
- nekatere
- Stol
- spremenite
- preveriti
- izbira
- možnosti
- Izberite
- izbiri
- razred
- nered
- Koda
- zbiranje
- komentarji
- računanje
- konference
- konfiguracija
- Razmislite
- premislekov
- stalna
- gradnjo
- Posoda
- Vsebuje
- vsebina
- nadzor
- Ustrezno
- stroški
- ustvarjajo
- ustvaril
- Ustvarjanje
- pridelek
- Trenutno
- po meri
- stranka
- Za stranke
- Stranke, ki so
- datum
- obdelava podatkov
- znanost o podatkih
- nabor podatkov
- globoko
- globoko učenje
- privzeto
- Predstavitev
- izkazati
- razporedi
- razporejeni
- Oblikovanje
- modeli
- Podrobnosti
- drugačen
- Difuzija
- neposredno
- razpravlja
- razpravljali
- delitev
- Lučki delavec
- Kontejner Docker
- Ne
- Pes
- psi
- tem
- domena
- dont
- prenesi
- med
- vsak
- enostaven za uporabo
- učinkovite
- vgrajeni
- omogočajo
- omogoča
- konec koncev
- Končna točka
- Angleščina
- dovolj
- zagotovitev
- Zabava
- Vpis
- epohe
- ocene
- itd
- Eter (ETH)
- EU
- oceniti
- Primer
- Primeri
- Razen
- izvršiti
- pričakovati
- poskus
- eksponentna
- Obraz
- obrazi
- Nekaj
- file
- datoteke
- končno
- finančna
- finančne storitve
- Najdi
- konča
- prva
- fit
- fiksna
- Plavaj
- Osredotočite
- sledili
- po
- format
- iz
- polno
- zabava
- funkcije
- nadalje
- Poleg tega
- Gain
- ustvarjajo
- ustvarila
- ustvarja
- ustvarjajo
- generacija
- generativno
- Generativna AI
- Georgia
- dobili
- GitHub
- dobro
- GPU
- postopoma
- Ravnanje
- se zgodi
- Glava
- zdravstveno varstvo
- Pomaga
- visoka kvaliteta
- več
- gostitelj
- Kako
- Kako
- Vendar
- HTML
- HTTPS
- človeškega
- ICLR
- identificirati
- Illinois
- slika
- generiranje slik
- slike
- vpliv
- prizadeti
- uvoz
- Impresivno
- in
- vključujejo
- vključuje
- Vključno
- vključi
- Povečajte
- Poveča
- narašča
- industrij
- Podatki
- vhod
- primer
- Namesto
- Navodila
- zavarovanje
- vmesnik
- vključeni
- izolacija
- vprašanje
- Vprašanja
- IT
- Job
- Potovanje
- json
- Imejte
- znanje
- jezik
- jeziki
- velika
- Zadnja
- kosilo
- plasti
- UČITE
- naučili
- učenje
- omejitve
- Limited
- vrstica
- linije
- Seznam
- malo
- nalaganje
- lokalna
- Long
- Poglej
- izgleda kot
- off
- nizka
- stroj
- strojno učenje
- Znamka
- Način
- ročno
- proizvodnja
- več
- Stave
- največja
- mediji
- Spomin
- Bližnji
- morda
- moti
- minimalna
- manjka
- ML
- Model
- modeli
- Trenutek
- več
- več
- Ime
- Imenovan
- naravna
- Naravni jezik
- Obdelava Natural Language
- potrebno
- Nimate
- potrebna
- mreža
- Naslednja
- NFT
- nlp
- hrup
- prenosnik
- november
- Številka
- predmet
- opazujejo
- ONE
- odprite
- operacije
- Da
- organizacije
- izvirno
- Ostalo
- pregled
- lastne
- članki
- parametri
- zlasti
- vozovnice
- Podaje
- pot
- opravlja
- performance
- izvajati
- prilagodite
- Hišni ljubljenčki
- Fotorealistično
- pixel
- platon
- Platonova podatkovna inteligenca
- PlatoData
- prosim
- Točka
- pozitiven
- mogoče
- Prispevek
- Prispevkov
- napovedati
- predstaviti
- prejšnja
- Predhodna
- Postopek
- obravnavati
- proizvodnjo
- Izdelek
- postopoma
- zagotavljajo
- če
- zagotavlja
- zagotavljanje
- javno
- objavljeno
- Python
- kakovost
- hitro
- naključno
- obsegu
- Oceniti
- pripravljen
- pravo
- v realnem času
- realistična
- Pred kratkim
- priznajo
- Priporočamo
- Priporočila
- Rdeča
- zmanjša
- Ne glede na to
- povezane
- sprosti
- odstranitev
- odstrani
- predstavnik
- zahteva
- zahteva
- obvezna
- zahteva
- zahteva
- raziskovalec
- Resolucija
- viri
- Odzove
- Odgovor
- povzroči
- rezultat
- Rezultati
- vloga
- Run
- tek
- sagemaker
- Je dejal
- Enako
- shranjevanje
- Znanost
- Znanstvenik
- skripte
- SDK
- Iskalnik
- sekund
- Oddelek
- višji
- Serija
- Storitev
- Storitve
- nastavite
- nastavitev
- več
- Oblike
- shouldnt
- Prikaži
- pokazale
- Razstave
- bistveno
- Podoben
- Enostavno
- preprosto
- sam
- Sedenje
- Velikosti
- majhna
- manj
- So
- Rešitev
- rešitve
- nekaj
- Vesolje
- posebna
- specifična
- določeno
- hitrost
- stabilna
- Stage
- Začetek
- začne
- Država
- Korak
- Koraki
- ustavil
- shranjevanje
- studio
- predmet
- uspešno
- taka
- Trpi
- dovolj
- podpora
- Podprti
- Podpira
- TAG
- Bodite
- meni
- ciljna
- Naloge
- skupina
- tech
- Pogoji
- testi
- O
- njihove
- zato
- skozi
- čas
- do
- danes
- skupaj
- tudi
- Skupaj za plačilo
- Vlak
- usposobljeni
- usposabljanje
- vlaki
- prenos
- potovanja
- Vrste
- ui
- edinstven
- univerza
- Nadgradnja
- posodobljeno
- posodobitve
- URI
- us
- uporaba
- primeru uporabe
- uporabnik
- Uporabniški vmesnik
- navadno
- javne gospodarske službe
- pripomoček
- izkorišča
- dragocene
- Dragocene informacije
- vrednost
- Vrednote
- različnih
- Video
- načini
- teža
- ali
- ki
- medtem
- bele
- bo
- v
- brez
- besede
- delo
- delati skupaj
- delal
- deluje
- vredno
- donos
- Vaša rutina za
- sami
- zefirnet
- nič