V tem članku boste izvedeli različne načine za pretvorbo PDF v Google Preglednice.
Izvedeli boste tudi, kako lahko Nanonets avtomatizirajte celoten potek dela pretvorbe PDF v Google Preglednice na spletu.
Preden pogledamo, kako pretvoriti PDF v Google Preglednice, si poglejmo, zakaj je to pomembno.
Zakaj pretvoriti PDF v Google Preglednice?
Glede na to Googlov blog objave na uradni Googlovi spletni strani, več kot 5 milijonov podjetij uporablja njihovo rešitev G Suite. Hkrati je veliko podjetij začelo uporabljati integracije Google Preglednic za avtomatizacijo opravil.
Razmislimo o tipičnem primeru uporabe. Vaša skupina za plačljive račune prejme račun v standardni obliki PDF. Nekdo ročno pregleda račun in vnese zahtevane podatke v dokument Google Preglednice, preden ga posreduje razdelku Finance. Oddelek za finance plača vašemu dobavitelju in vnese v knjigo podjetja.
Poleg tega, da je to dolgotrajen postopek, je nagnjen k napakam in bi bilo veliko bolj smiselno, da bi ga preprosto avtomatizirali.
Zdaj, ko je potreba po pretvorbi PDF-jev v obrazec Google List jasna, si poglejmo, kako so dokumenti PDF strukturirani in kakšni so izzivi pri njihovem razčlenjevanju.
Želite spremeniti PDF datoteke za Google Preglednice ? Preveri Nanonets ' brezplačno Pretvornik PDF v CSV. Ali ugotovite, kako avtomatizirajte celoten potek dela PDF v Google Preglednice z Nanonets.
Izzivi pri razčlenjevanju dokumenta PDF
Prenosni format dokumenta je bil format datoteke, ki ga je prvotno razvil Adobe in je bil kasneje izdan kot odprti standard. Od takrat je bil široko sprejet, saj je agnostičen glede na osnovni operacijski sistem.
Zakaj je torej tako težko razčleniti PDF in pretvoriti njegovo vsebino v drugo obliko? Naslednje slike povedo več kot tisoč besed in bodo pripeljale do bistva.
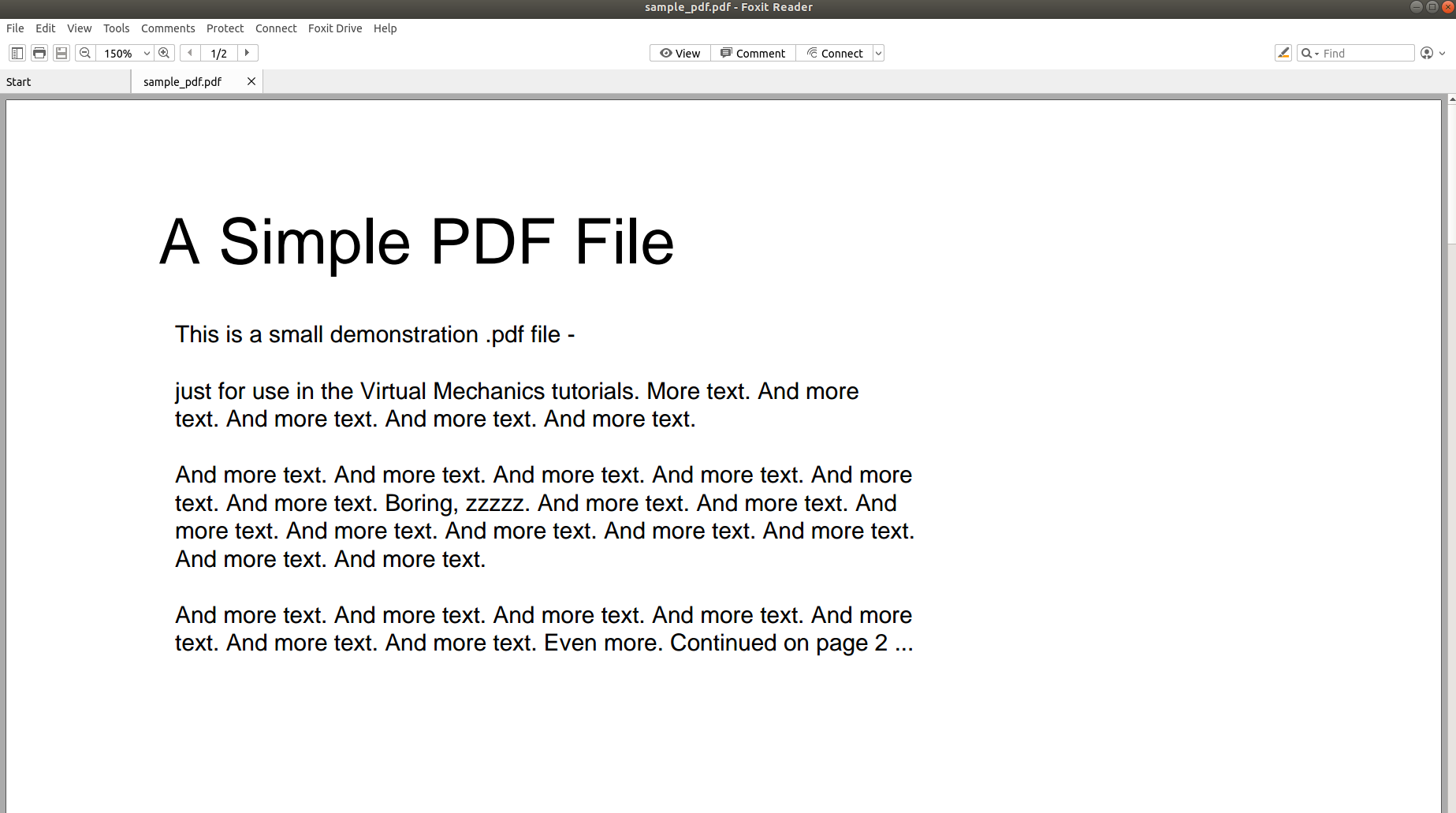
Zgornja slika prikazuje posnetek zaslona dokumenta PDF, ki se odpre z bralnikom PDF. Poskusimo odpreti isti dokument PDF z urejevalnikom besedil.
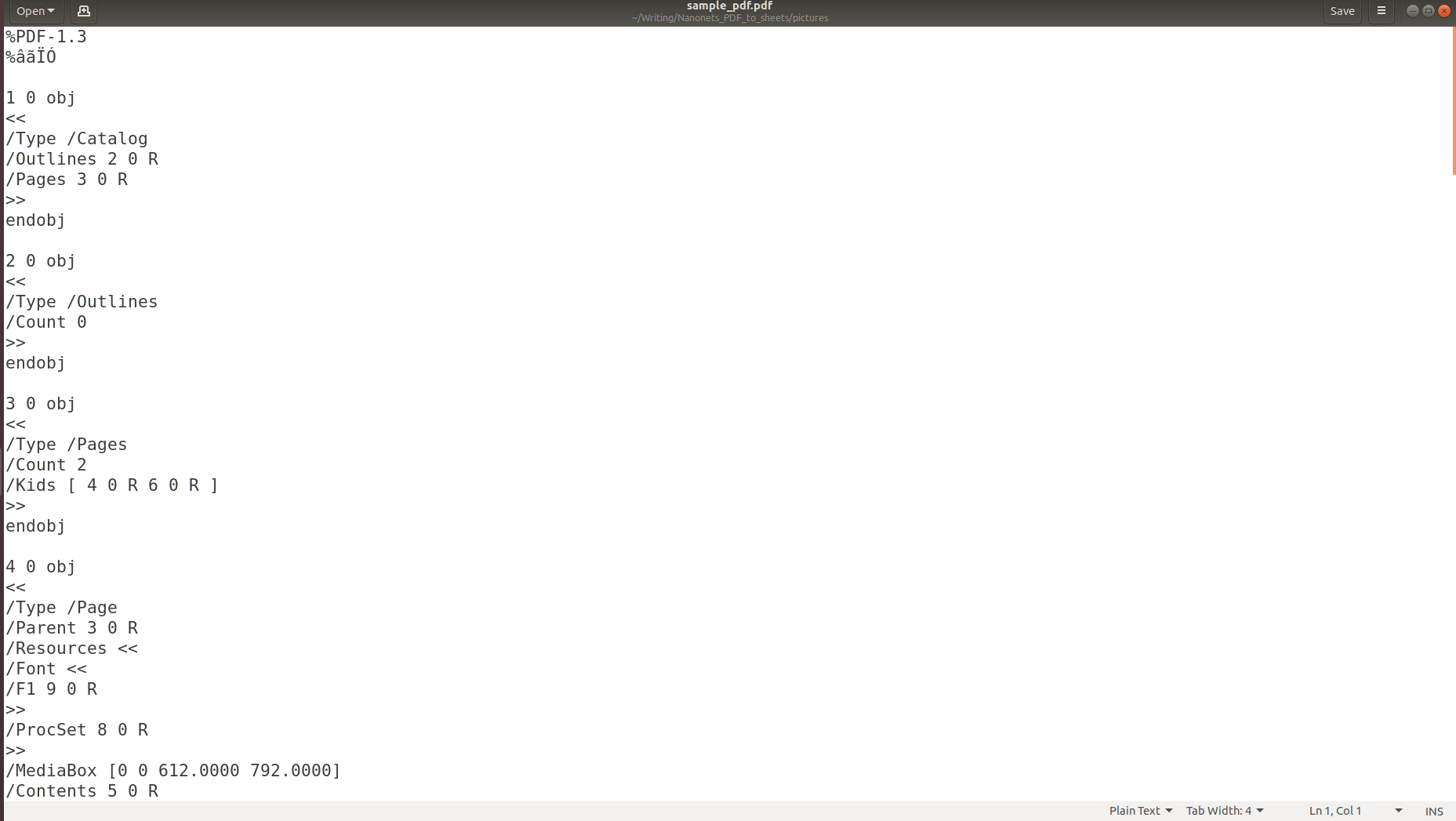
Zgornje slike jasno kažejo, da se pri shranjevanju informacij v PDF-ju njihova prvotna struktura popolnoma izgubi. To je zato, ker format PDF preprosto vsebuje navodila, kako natisniti/risati zaporedje znakov na strani.
Če menite, da je ekstrahiranje besedila težko, je ekstrahiranje podatkov v tabelah še večji izziv zaradi zelo različnih tabelarnih formatov, ki se uporabljajo.
Upajmo, da ste prepričani, da pretvorba dokumenta PDF v obrazec Google Preglednice ni sprehod po parku. Naslednji razdelek govori o pristopu, ki ga uporablja večina sodobnih razčlenjevalcev PDF za prepoznavanje/razčlenjevanje informacij iz dokumenta PDF.
Sodoben pristop k razčlenjevanju dokumentov PDF
Večina sodobnih razčlenjevalcev PDF uporablja spodaj opisani tok za razčlenjevanje nestrukturiranih podatkov iz dokumentov PDF.
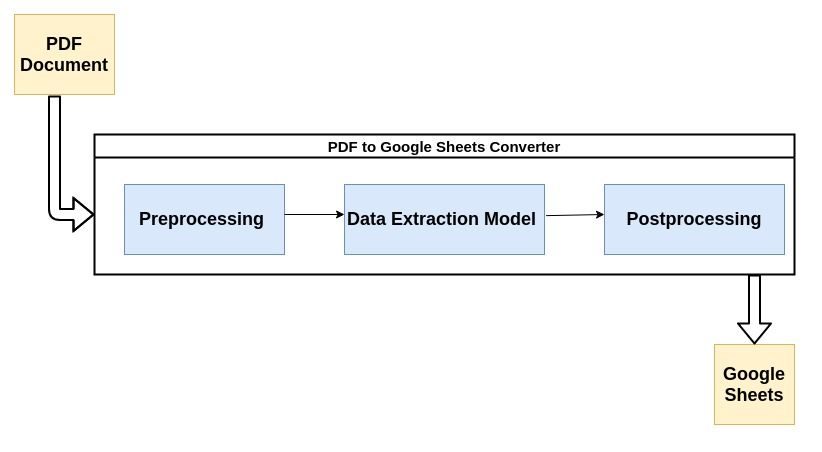
Na kratko si oglejmo vsak korak postopka:
1. Predhodna obdelava ali čiščenje podatkov:
Bolje ko je videti vaš PDF, lažje ga bo vaš model strojnega učenja izvlekel oz zajemanje podatkov iz tega. Na primer, če je bil dokument PDF optično prebran, bo zagotovo vseboval nekaj artefaktov optičnega branja, ki bi lahko vplivali na delovanje pretvornika.
Odstranjevanje hrupa z uporabo ustreznih filtrov, binarizacija, korekcija poševnosti itd. so nekateri najpogostejši koraki predprocesiranja. Naslednja objava Nanonets Nanonets Tesseract Post vsebuje nekaj odličnih primerov, kako je mogoče predhodno obdelati dokumente Optično prepoznavanje znakov(OCR) se izvaja na njih.
Tu se zgodi največ čarovnije. Ekstrakcija podatkov se običajno izvaja z modelom strojnega učenja (ML). Večina modelov ML, ki se uporabljajo za pridobivanje podatkov iz datotek PDF, vsebuje kombinacijo orodij za optično prepoznavanje znakov, orodij za prepoznavanje besedila in vzorcev itd.
Za namen te objave lahko model obravnavamo kot črno skrinjico, ki sprejme vaš dokument PDF kot vhod in izpljune razčlenjene informacije. Poleg tega, ker v svojem jedru uporablja ML, ga je mogoče prekvalificirati s podatki po meri, da ustreza primeru uporabe vašega podjetja.
3. Naknadna obdelava:
V tem koraku se ekstrahirani podatki pretvorijo v zahtevano obliko, kot je CSV, XML, JSON itd. Dodatna pravila, ki jih določi uporabnik, so dodana poleg napovedi, ki jih naredi AI. To bi lahko vključevalo pravila za oblikovanje izpisa, dodatne omejitve za ekstrahirane informacije itd.
Naslednji razdelek obravnava nekatere meritve, ki jih lahko uporabimo za merjenje učinkovitosti razčlenjevalnika PDF.
Želite spremeniti PDF datoteke za Google Preglednice ? Preveri Nanonets ' brezplačno Pretvornik PDF v CSV. Ugotovite, kako z Nanonets avtomatizirati celoten potek dela PDF v Google Preglednice.

Meritve za merjenje zmogljivosti pretvornika PDF
Ker se bo večina pretvornikov PDF uporabljala za obdelavo računov ali sorodna opravila, sta natančnost in hitrost izvlečka tabele iz dokumenta PDF ključni dejavnik pri ocenjevanju učinkovitosti pretvornika PDF.
2. Večjezična zmogljivost:
Večina velikih podjetij mora prejemati račune v več različnih jezikih. Razčlenjevalnik PDF bi moral podpirati večjezično razčlenjevanje takoj po namestitvi ali pa bi moral ponuditi možnost, s katero lahko uporabniki učijo model z uporabo podatkov po meri.
3. Integracija z računovodsko programsko opremo:
Idealen pretvornik PDF bi moral biti plug and play modul, ki ga je mogoče preprosto dodati obstoječemu potek dela dokumentov. Podpirati mora integracijo s priljubljeno računovodsko programsko opremo, kot so QuickBooks, Xero, Wave itd.
4. Enostavno in intuitivno:
Orodje bodo najverjetneje uporabljali netehnični uporabniki. Ugodno bi bilo, če bi ga lahko upravljali z minimalnim tehničnim znanjem.
Različni načini pretvorbe datotek PDF v Google Preglednice
1. Uporaba Google Dokumentov za pretvorbo PDF v Google Preglednice
Google Drive ima vgrajeno zmožnost prepoznavanja tabel in besedila v preprostih dokumentih PDF. Preprosto morate:
-
Naložite datoteko PDF v Google Drive
-
Kliknite »Odpri z Google Dokumenti«
-
Kopirajte želene podatke in jih prilepite v Google Preglednice
Čeprav se zdi, da to dobro deluje, poskusimo nekaj bolj praktičnega. Razmislite o tem preprostem računu.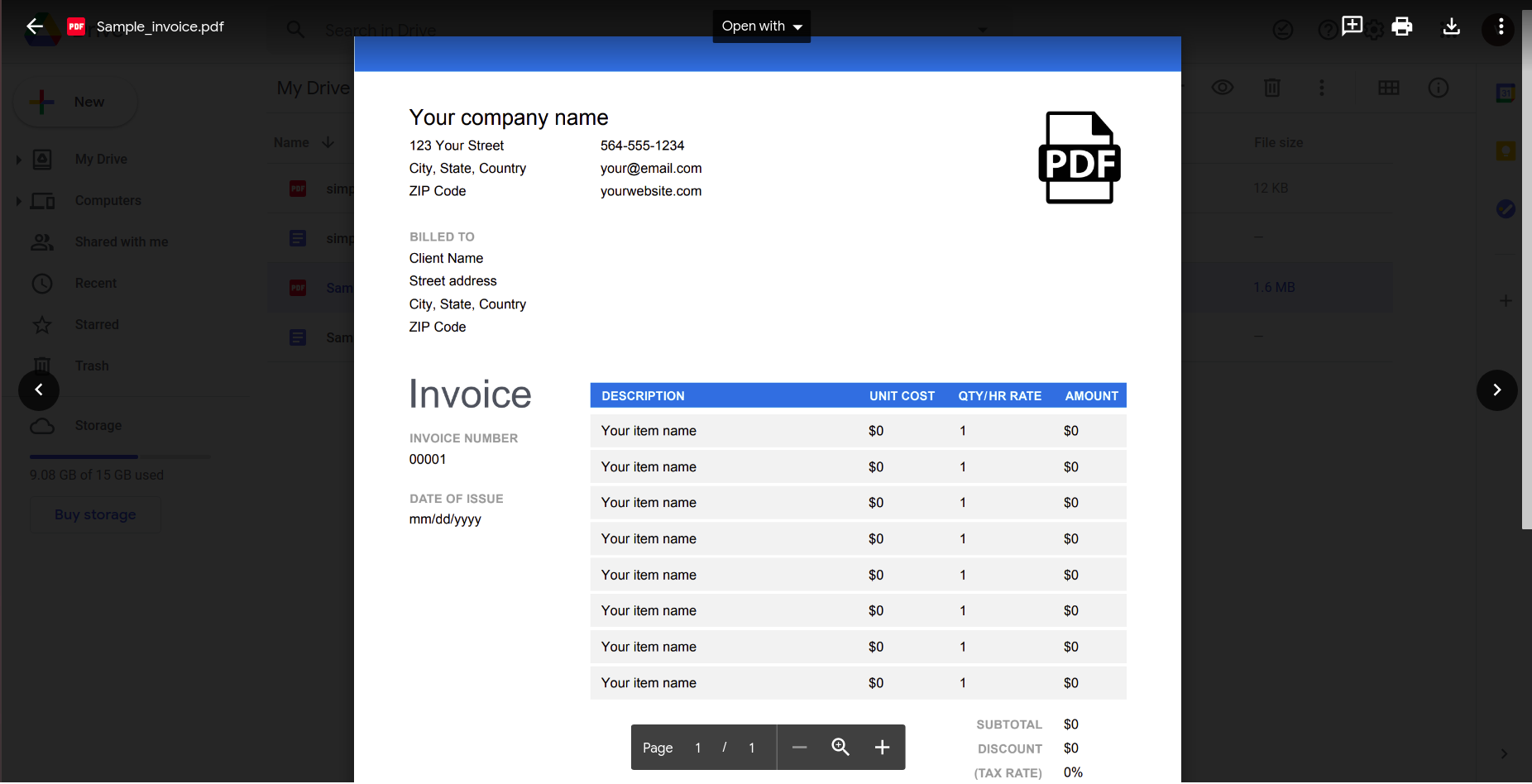
Če to odprete z aplikacijo Google Dokumenti, dobite naslednji rezultat.
Jasno je, da se moramo z večanjem kompleksnosti dokumenta zanesti na bolj sofisticirana orodja za prepoznavanje podatkov.
2. Uporaba spletnih orodij:
Več spletnih orodij, kot je ekstraktor tabel PDF, Online2PDF itd., se neposredno integrirajo z Google Drive in nudijo takojšnjo zmožnost pretvorbe dokumentov PDF v Google Preglednice.
Ko pa so bila ta orodja preizkušena z zgoraj prikazanim vzorčnim računom PDF, tabele v večini primerov niso bile zaznane.
Želite spremeniti PDF datoteke za Google Preglednice ? Preveri Nanonets ' brezplačno Pretvornik PDF v CSV. Ugotovite, kako avtomatizirati celoten potek dela PDF v Google Preglednice z Nanoneti, kot je prikazano spodaj.
Avtomatizacija postopka pretvorbe PDF v Google Preglednice
Z naslednjimi orodji lahko popolnoma avtomatiziramo postopek razčlenjevanja PDF-ja in ekstrahiranja podatkov v obrazec Google Preglednice.
1. Uporaba Webhookov:
Webhooki so po meri definirane zahteve HTTP. Običajno se sprožijo ob dogodku, tj. ko pride do dogodka, aplikacija pošlje informacije na vnaprej določen URL.
Kako lahko to uporabite za avtomatizacijo svojega poteka dela? Oglejmo si tipičen primer uporabe obdelave računov. Od dobaviteljev prejmete številne račune in jih vnesete v pretvornik PDF v Google Preglednice, ki je v oblaku. Kako veste, kdaj je model končal obdelavo dokumentov?
Namesto ročnega preverjanja, ali je bila pretvorba dokončana, lahko preprosto uporabite webhook, ki vas obvesti, ko so bili podatki v PDF ekstrahirani v dokument Google Preglednic.
2. Uporaba API-jev
API pomeni vmesnik za programiranje aplikacij. Z uporabo ustreznih klicev API-ja se lahko izkaže, da je pretvorba dokumentov PDF v Google Preglednice tako enostavna kot pisanje naslednjih vrstic kode:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Če je vaše podjetje že nastavilo integracijo z Webhooks, boste prejeli obvestilo, ko bodo vaši dokumenti PDF uspešno pretvorjeni. Nato lahko prenesete obrazec Google Preglednice s pomočjo API-ja, prikazanega spodaj.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF v Google Preglednice z Nanoneti
Razčlenjevalnik PDF Nanonets omogoča enostavno in natančno razčlenjevanje in pretvorbo. Razčlenjevalnik PDF je bil uporabljen za razčlenjevanje vzorčnega računa. Ta razdelek prikazuje enostavno uporabo in natančnost orodja. Namesto da bi govorili o tem, kako super je, naslednje slike primerno ponazorijo bistvo.
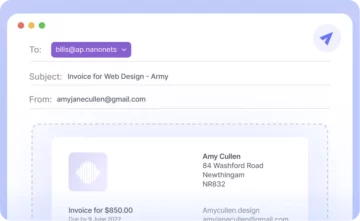
Spodnja slika je posnetek zaslona vzorca računa, ki je bil posredovan razčlenjevalniku PDF Nanonets.
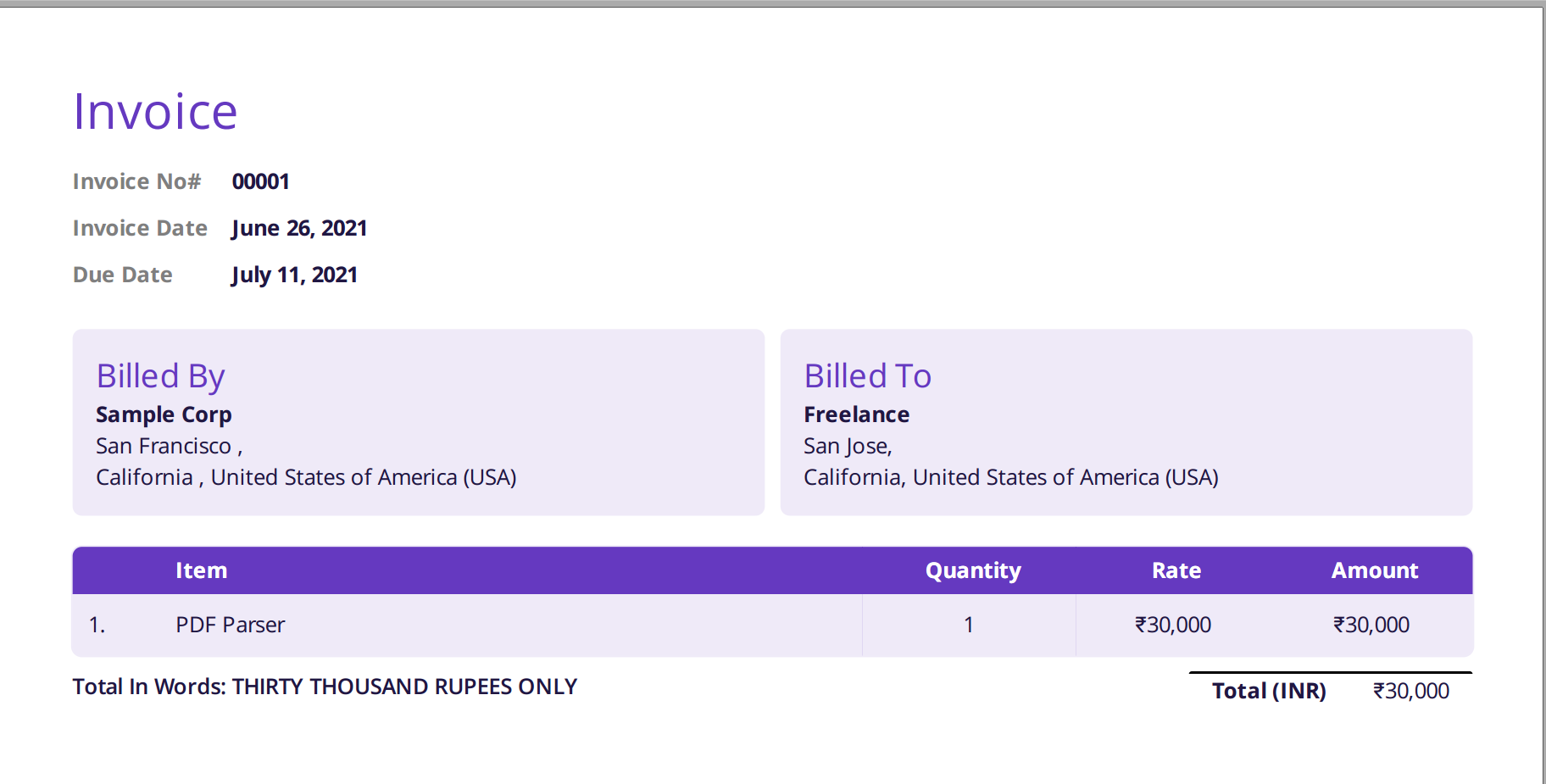
Preprosto pojdite na spletno mesto Nanonets in naložite račun. Pretvorba traja le nekaj sekund, nato pa je mogoče razčlenjene podatke prenesti v različnih formatih, kot je npr CSV, XLSX itd. (preverite Nanonets' Pretvornik PDF v CSV)
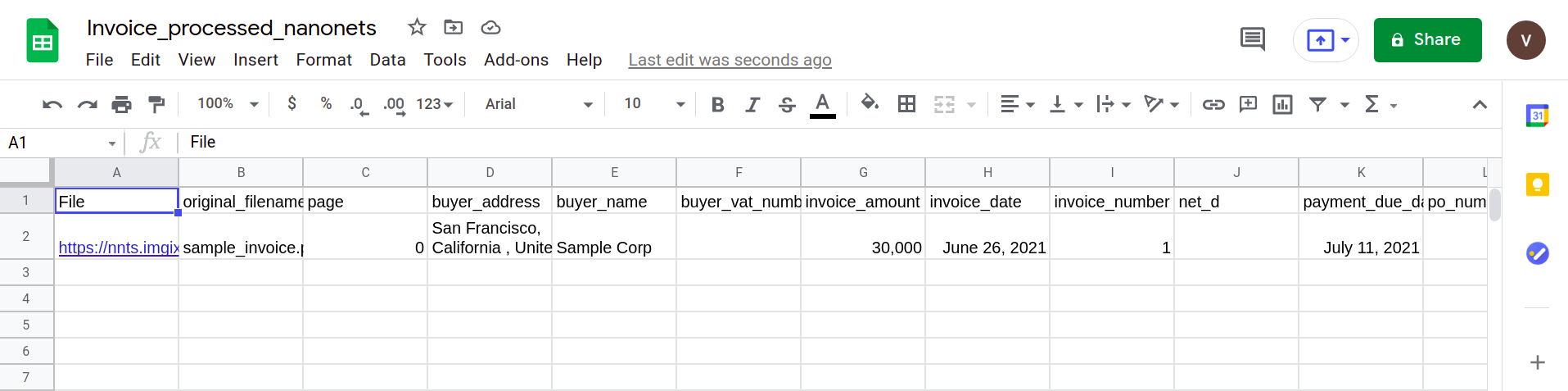
Naslednja slika prikazuje posnetek zaslona datoteke CSV, ki vsebuje razčlenjene podatke iz dokumenta PDF.

Nazadnje, če želite datoteko CSV pretvoriti v obrazec Google Preglednic, preprosto naložite datoteko XLSX/CSV v svoj Google Drive. Ta korak je mogoče avtomatizirati z uporabo API-jev Google Drive.
Naslednji razdelek prikazuje, kako je mogoče ustvariti preprost cevovod z uporabo razčlenjevalnika PDF Nanonets.
Ali želite pridobiti informacije iz dokumentov PDF in jih pretvoriti/dodati v dokument Google Preglednice? Oglejte si Nanonets™ za avtomatiziran izvoz vseh informacij iz katerega koli dokumenta PDF v Google Preglednice!
Ustvarjanje preprostega cevovoda
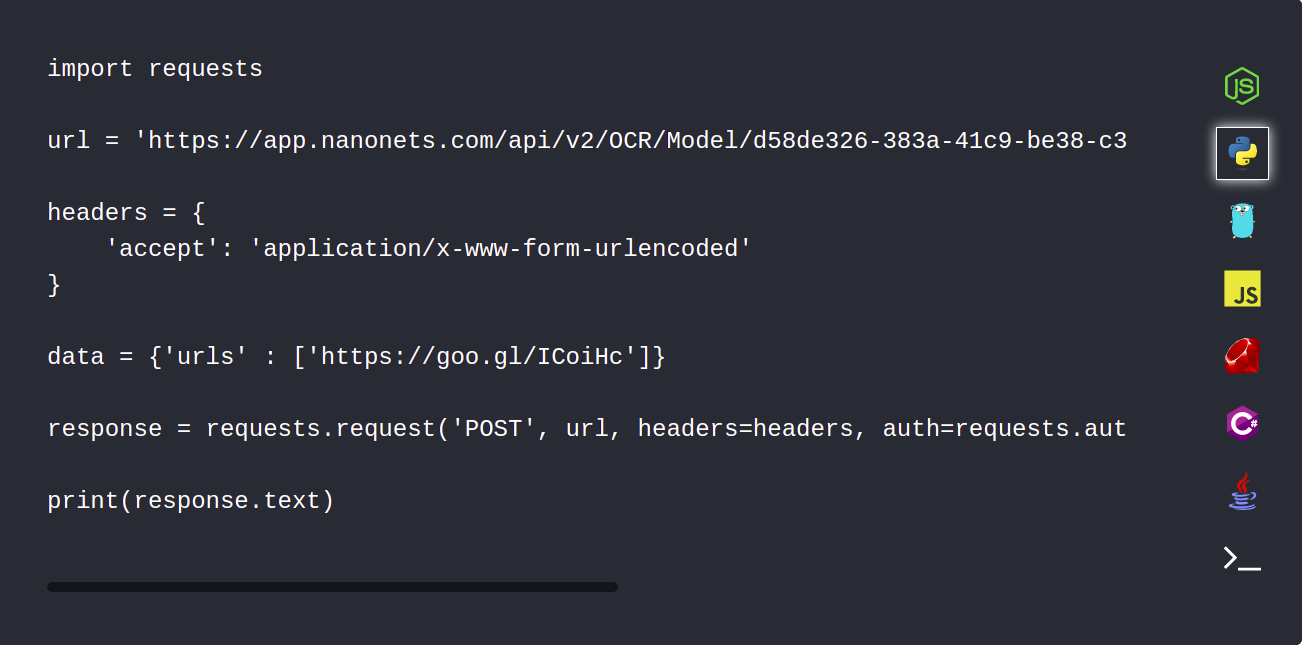
1. Samodejno naložite svoje dokumente PDF z API-jem Nanonets
Nanonets API vam omogoča samodejno nalaganje dokumentov, ki jih je treba razčleniti. Naslednji delček kode prikazuje, kako je to mogoče storiti s pythonom.
2. Uporabite integracijo webhooks, da prejmete obvestilo po zaključku razčlenjevanja
Webhooke je mogoče konfigurirati tako, da vas samodejno obvestijo, ko so dokumenti razčlenjeni.
3. Preglejte in naložite v Google Preglednice
Prenesite in preglejte datoteke CSV, da se prepričate, da je vse v redu, in naložite podatke v Google Preglednice z uporabo API-ja Google Drive.
Nanonet Edge
Tukaj je nekaj funkcij Nanonets PDF Parser, zaradi katerih je idealno orodje za vaše podjetje.
1. Zunanje integracije:
Model nanonetov je mogoče preprosto integrirati z MySql, Quickbooks, Salesforce itd. To pomeni, da vaš trenutni delovni tok ostane nemoten, pretvornik nanonetov pa lahko preprosto priključite kot dodaten modul.
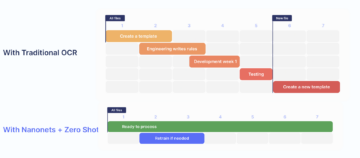
2. Visoka natančnost in nizki časi obdelave:
Orodje za razčlenjevanje PDF Nanonets ima natančnost nad 95 %, kar je veliko več v primerjavi s konkurenti.
3. Cool funkcije naknadne obdelave:
Predpostavimo, da je vaša zbirka podatkov integrirana z modelom nanonetov. Model samodejno izpolni nekatera polja (s podatki iz vaše zbirke podatkov) na podlagi podatkov, pridobljenih iz dokumenta. Na primer:
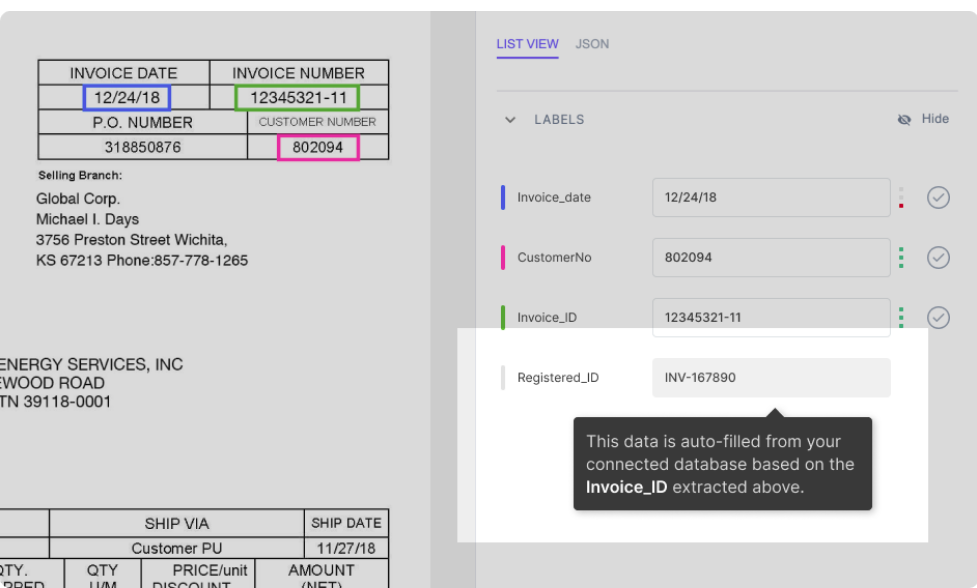
Kot je prikazano na sliki, se polje Registered_ID izpolni samodejno (z iskanjem v zbirki podatkov) na podlagi Invoice_ID, ki je izvlečen iz PDF-ja.
4. Preprost in intuitiven vmesnik
Čeprav je ta funkcija podcenjena, sem ugotovil, da sta uporabniški vmesnik in UX na mestu. Celoten postopek prijave, nalaganja dokumenta in razčlenjevanja podatkov je trajal manj kot 5 minut. To je skoraj enako času, ki ga potrebuje moj prenosnik, da se zažene!
5. Ogromna baza strank
Če imate še vedno zadržke glede uporabe Nanonetov za avtomatizacijo delovnega toka, si oglejte nekaj podjetij, ki uporabljajo njihove storitve.
- Deloitte
- Sherwin Williams
- DoorDash
- P&G
Ali želite pridobiti informacije iz dokumentov PDF in jih pretvoriti/dodati v dokument Google Preglednice? Oglejte si Nanonets™ za avtomatiziran izvoz vseh informacij iz katerega koli dokumenta PDF v Google Preglednice!
zaključek
V tej objavi smo si ogledali, kako lahko avtomatizirate potek dela s pretvornikom PDF v Google Preglednice. Sprva smo izvedeli za potrebo po pretvorbi dokumentov PDF v Google Preglednice, čemur so sledili izzivi, s katerimi se srečujemo med tem postopkom. Nato smo se poglobili v pristope, ki jih uporabljajo sodobni razčlenjevalniki za razčlenjevanje dokumentov PDF, in uvedli tudi nekatere običajne pristope. Naučili smo se tudi, kako lahko popolnoma avtomatiziramo pretvorbo z uporabo zunanjih integracij, kot so webhooks in API-ji. Nazadnje smo uporabili orodje Nanonets za razčlenjevanje vzorčnega računa, ekstrahiranje podatkov v obrazec Google Preglednice in raziskali tudi nekaj njegovih odličnih funkcij naknadne obdelave.
Ste že preizkusili model Nanonets? Če je tako, spodaj pustite komentar o svojih izkušnjah z orodjem. Če ne, ga preizkusite. Morda vam le polepša dan!
- AI
- AI in strojno učenje
- ai art
- ai art generator
- imajo robota
- Umetna inteligenca
- certificiranje umetne inteligence
- umetna inteligenca v bančništvu
- robot z umetno inteligenco
- roboti z umetno inteligenco
- programska oprema za umetno inteligenco
- blockchain
- blockchain konferenca ai
- coingenius
- pogovorna umetna inteligenca
- kripto konferenca ai
- dall's
- globoko učenje
- strojno učenje
- pdf v google preglednice
- platon
- platon ai
- Platonova podatkovna inteligenca
- Igra Platon
- PlatoData
- platogaming
- lestvica ai
- sintaksa
- zefirnet