Ta objava je napisana skupaj z Mahimo Agarwalom, inženirjem strojnega učenja, in Deepakom Mettemom, višjim vodjem inženiringa pri VMware Carbon Black
VMware Carbon Black je priznana varnostna rešitev, ki nudi zaščito pred celotnim spektrom sodobnih kibernetskih napadov. S terabajti podatkov, ki jih ustvari izdelek, se skupina za varnostno analitiko osredotoča na gradnjo rešitev strojnega učenja (ML) za odkrivanje kritičnih napadov in opozarjanje na nastajajoče grožnje zaradi hrupa.
Za ekipo VMware Carbon Black je ključnega pomena, da oblikuje in zgradi prilagojen cevovod MLOps od konca do konca, ki usmerja in avtomatizira poteke dela v življenjskem ciklu ML ter omogoča usposabljanje za modele, ocene in uvajanja.
Obstajata dva glavna namena za izgradnjo tega cevovoda: podpora podatkovnim znanstvenikom za razvoj modelov v pozni fazi in napovedi površinskih modelov v izdelku s streženjem modelov v velikem obsegu in v prometu proizvodnje v realnem času. Zato sta se VMware Carbon Black in AWS odločila zgraditi cevovod MLOps po meri z uporabo Amazon SageMaker zaradi svoje enostavne uporabe, vsestranskosti in popolnoma upravljane infrastrukture. Usklajujemo svoje cevovode za usposabljanje in uvajanje ML z uporabo Delovni tokovi, ki jih upravlja Amazon za Apache Airflow (Amazon MWAA), ki nam omogoča, da se bolj osredotočimo na programsko ustvarjanje potekov dela in cevovodov, ne da bi morali skrbeti za samodejno skaliranje ali vzdrževanje infrastrukture.
S tem cevovodom je tisto, kar je nekoč bilo raziskovanje ML, ki ga je vodil prenosnik Jupyter, zdaj avtomatiziran proces, ki uvaja modele v proizvodnjo z malo ročnega posredovanja podatkovnih znanstvenikov. Prej je lahko proces usposabljanja, ocenjevanja in uvajanja modela trajal en dan; s to izvedbo je vse oddaljeno le en sprožilec in je skrajšalo skupni čas na nekaj minut.
V tej objavi arhitekti VMware Carbon Black in AWS razpravljajo o tem, kako smo zgradili in upravljali poteke dela ML po meri z uporabo gitlab, Amazon MWAA in SageMaker. Razpravljamo o tem, kaj smo dosegli do zdaj, o nadaljnjih izboljšavah v pripravi in izkušnjah, pridobljenih na poti.
Pregled rešitev
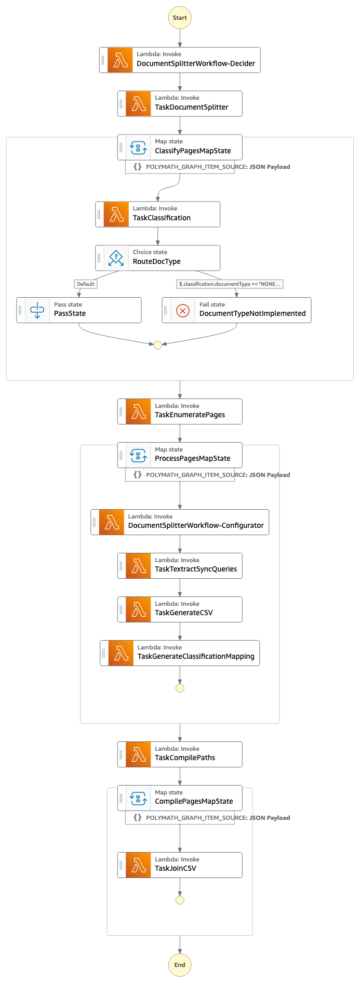
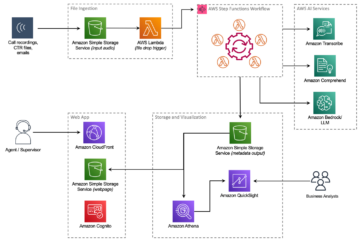
Naslednji diagram ponazarja arhitekturo platforme ML.

Oblikovanje rešitve na visoki ravni
Ta platforma ML je bila zasnovana in zasnovana tako, da jo uporabljajo različni modeli v različnih repozitorijih kode. Naša ekipa uporablja GitLab kot orodje za upravljanje izvorne kode za vzdrževanje vseh repozitorijev kode. Vse spremembe v izvorni kodi repozitorija modela se nenehno integrirajo z uporabo Gitlab CI, ki prikliče nadaljnje poteke dela v cevovodu (usposabljanje modela, vrednotenje in uvajanje).
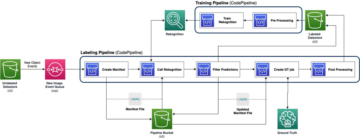
Naslednji diagram arhitekture prikazuje potek dela od konca do konca in komponente, vključene v naš cevovod MLOps.

Potek dela od konca do konca
Cevovodi za usposabljanje, vrednotenje in uvajanje modela ML so orkestrirani z uporabo Amazon MWAA, imenovanega Usmerjeni aciklični graf (DAG). DAG je skupek opravil, organiziranih z odvisnostmi in odnosi, ki določajo, kako naj se izvajajo.
Na visoki ravni vključuje arhitektura rešitve tri glavne komponente:
- Repozitorij cevovodne kode ML
- Usposabljanje in ocenjevanje modela ML
- Cevovod za uvajanje modela ML
Pogovorimo se o tem, kako se te različne komponente upravljajo in kako medsebojno delujejo.
Repozitorij cevovodne kode ML
Potem ko repo model integrira repo MLOps kot njihov nadaljnji cevovod in podatkovni znanstvenik potrdi kodo v svojem repo modelu, izvajalec GitLab izvede standardno preverjanje kode in testiranje, definirano v tem repoju, ter sproži cevovod MLOps na podlagi sprememb kode. Uporabljamo Gitlabov cevovod za več projektov, da omogočimo ta sprožilec v različnih skladiščih.
Cevovod MLOps GitLab poteka v določenem nizu stopenj. Izvaja osnovno preverjanje veljavnosti kode z uporabo pylinta, pakira kodo za usposabljanje in sklepanje modela v sliko Docker in objavi sliko vsebnika v Registar elastičnih zabojnikov Amazon (Amazon ECR). Amazon ECR je popolnoma upravljan register vsebnikov, ki ponuja visoko zmogljivo gostovanje, tako da lahko zanesljivo namestite slike aplikacij in artefakte kjer koli.
Usposabljanje in ocenjevanje modela ML
Ko je slika objavljena, sproži usposabljanje in vrednotenje pretok zraka apache cevovod skozi AWS Lambda funkcijo. Lambda je brezstrežniška računalniška storitev, ki temelji na dogodkih in vam omogoča zagon kode za skoraj vse vrste aplikacij ali zalednih storitev brez zagotavljanja ali upravljanja strežnikov.
Ko je cevovod uspešno sprožen, zažene DAG za usposabljanje in ocenjevanje, ki nato zažene usposabljanje modela v SageMakerju. Na koncu tega cevovoda usposabljanja identificirana skupina uporabnikov prejme obvestilo z rezultati usposabljanja in vrednotenja modela po e-pošti prek Amazon Simple notification Service (Amazon SNS) in Slack. Amazon SNS je v celoti upravljana pub/sub storitev za sporočanje A2A in A2P.
Po natančni analizi rezultatov vrednotenja lahko podatkovni znanstvenik ali inženir ML uvede nov model, če je zmogljivost na novo usposobljenega modela boljša v primerjavi s prejšnjo različico. Delovanje modelov je ovrednoteno na podlagi metrik, specifičnih za model (kot je rezultat F1, MSE ali matrika zmede).
Cevovod za uvajanje modela ML
Za začetek uvajanja uporabnik zažene opravilo GitLab, ki sproži DAG za uvajanje prek iste funkcije Lambda. Ko cevovod uspešno teče, ustvari ali posodobi končno točko SageMaker z novim modelom. To tudi pošlje obvestilo s podrobnostmi o končni točki po e-pošti z uporabo Amazon SNS in Slack.
V primeru okvare v enem od cevovodov so uporabniki obveščeni po istih komunikacijskih kanalih.
SageMaker ponuja sklepanje v realnem času, ki je idealno za delovne obremenitve sklepanja z nizko zakasnitvijo in zahtevami po visoki prepustnosti. Te končne točke so v celoti upravljane, uravnotežene obremenitve in samodejno prilagojene ter jih je mogoče razmestiti v več območjih razpoložljivosti za visoko razpoložljivost. Naš cevovod ustvari takšno končno točko za model, potem ko ta uspešno deluje.
V naslednjih razdelkih podrobneje opisujemo različne komponente in se poglobimo v podrobnosti.
GitLab: Pakirajte modele in prožilne cevovodi
GitLab uporabljamo kot naš repozitorij kode in za cevovod za pakiranje modelne kode in sprožitev nižjih DAG-jev Airflow.
Večprojektni cevovod
Funkcija cevovoda GitLab za več projektov se uporablja, kjer je nadrejeni cevovod (navzgor) repo model, podrejeni cevovod (navzdol) pa repo MLOps. Vsak repo vzdržuje .gitlab-ci.yml in naslednji blok kode, omogočen v cevovodu navzgor, sproži cevovod MLOps navzgor.
Gornji cevovod pošlje kodo modela v spodnji cevovod, kjer se sprožijo opravila CI pakiranja in objavljanja. Kodo za shranjevanje kode modela in njeno objavo v Amazon ECR vzdržuje in upravlja cevovod MLOps. Pošilja spremenljivke, kot je ACCESS_TOKEN (lahko se ustvari pod Nastavitve, dostop), spremenljivk JOB_ID (za dostop do artefaktov navzgor) in $CI_PROJECT_ID (ID projekta repo modela), tako da lahko cevovod MLOps dostopa do datotek kode modela. z delovnih artefaktov funkcija iz Gitlaba, spodnji repo dostopa do oddaljenih artefaktov z naslednjim ukazom:
Repo modela lahko porabi nadaljnje cevovode za več modelov iz istega repoja tako, da razširi stopnjo, ki ga sproži z uporabo Se razširi ključno besedo iz GitLaba, ki vam omogoča ponovno uporabo iste konfiguracije na različnih stopnjah.
Po objavi slike modela v Amazon ECR cevovod MLOps sproži cevovod Amazon MWAA za usposabljanje z uporabo Lambda. Po odobritvi uporabnika sproži tudi cevovod Amazon MWAA za uvedbo modela z uporabo iste funkcije Lambda.
Semantična različica in prenos različic navzdol
Razvili smo kodo po meri za različico slik ECR in modelov SageMaker. Cevovod MLOps upravlja semantično logiko različic za slike in modele kot del stopnje, kjer se koda modela pospravi v vsebnike, in posreduje različice na kasnejše stopnje kot artefakte.
Prekvalifikacija
Ker je preusposabljanje ključni vidik življenjskega cikla ML, smo uvedli zmogljivosti preusposabljanja kot del našega načrta. Uporabljamo API seznama modelov SageMaker, da ugotovimo, ali gre za ponovno usposabljanje na podlagi številke različice za ponovno usposabljanje modela in časovnega žiga.
Dnevni urnik poteka prekvalifikacije vodimo z uporabo GitLabovi razporedi.
Terraform: Nastavitev infrastrukture
Ta rešitev poleg gruče Amazon MWAA, repozitorijev ECR, funkcij Lambda in teme SNS uporablja tudi AWS upravljanje identitete in dostopa (IAM) vloge, uporabniki in politike; Preprosta storitev shranjevanja Amazon (Amazon S3) vedra in an amazoncloudwatch odpremnik hlodov.
Za poenostavitev postavitve in vzdrževanja infrastrukture za storitve, ki so vključene v naš cevovod, uporabljamo Terraform implementirati infrastrukturo kot kodo. Kadarkoli so potrebne infra posodobitve, spremembe kode sprožijo cevovod GitLab CI, ki smo ga nastavili, ki potrdi in uvede spremembe v različna okolja (na primer dodajanje dovoljenja pravilniku IAM v računih razvijalcev, stopenj in proizvodov).
Amazon ECR, Amazon S3 in Lambda: olajšanje cevovoda
Za olajšanje našega cevovoda uporabljamo naslednje ključne storitve:
- Amazon ECR – Za vzdrževanje in omogočanje priročnega pridobivanja slik modelnega vsebnika jih označimo s semantičnimi različicami in jih naložimo v repozitorije ECR, nastavljene po
${project_name}/${model_name}prek Terraforma. To omogoča dobro plast izolacije med različnimi modeli in nam omogoča uporabo algoritmov po meri ter oblikovanje zahtev in odgovorov za sklepanje tako, da vključujejo želene informacije o manifestu modela (ime modela, različica, pot podatkov o usposabljanju itd.). - Amazon S3 – Vedra S3 uporabljamo za ohranjanje podatkov o usposabljanju modela, artefaktov usposobljenega modela na model, DAG-jev zračnega toka in drugih dodatnih informacij, ki jih zahtevajo cevovodi.
- Lambda – Ker je naša gruča Airflow zaradi varnostnih razlogov nameščena v ločenem VPC, do DAG ni mogoče dostopati neposredno. Zato uporabljamo funkcijo Lambda, ki jo vzdržuje tudi Terraform, da sproži vse DAG-je, ki jih določa ime DAG. S pravilno nastavitvijo IAM opravilo GitLab CI sproži funkcijo Lambda, ki prehaja skozi konfiguracije do zahtevanega DAG-ja za usposabljanje ali uvajanje.
Amazon MWAA: Cevovodi za usposabljanje in uvajanje
Kot smo že omenili, uporabljamo Amazon MWAA za usmerjanje cevovodov za usposabljanje in uvajanje. Uporabljamo operaterje SageMaker, ki so na voljo v Paket ponudnika Amazon za Airflow za integracijo s SageMakerjem (da bi se izognili predlogam jinja).
V tem procesu usposabljanja uporabljamo naslednje operaterje (prikazane v naslednjem diagramu poteka dela):

MWAA Training Pipeline
V cevovodu za uvajanje uporabljamo naslednje operaterje (prikazano v naslednjem diagramu poteka dela):

Cevovod za uvajanje modela
Za objavo sporočil o napakah/uspehu in rezultatov vrednotenja v obeh cevovodih uporabljamo Slack in Amazon SNS. Slack ponuja široko paleto možnosti za prilagajanje sporočil, vključno z naslednjimi:
- SnsPublishOperator - Uporabljamo SnsPublishOperator za pošiljanje obvestil o uspehu/neuspehu na e-pošto uporabnikov
- Slack API – Ustvarili smo dohodni URL webhook da dobite cevovodna obvestila na želeni kanal
CloudWatch in VMware Wavefront: spremljanje in beleženje
Za konfiguracijo spremljanja in beleženja končne točke uporabljamo nadzorno ploščo CloudWatch. Pomaga vizualizirati in spremljati različne operativne in modelne meritve uspešnosti, specifične za vsak projekt. Poleg pravilnikov o samodejnem skaliranju, nastavljenih za sledenje nekaterim od njih, nenehno spremljamo spremembe v uporabi procesorja in pomnilnika, zahtevah na sekundo, zakasnitvah odziva in meritvah modela.
CloudWatch je celo integriran z nadzorno ploščo VMware Tanzu Wavefront, tako da lahko vizualizira metrike za končne točke modela kot tudi druge storitve na ravni projekta.
Poslovne koristi in kaj sledi
Cevovodi ML so zelo pomembni za storitve in funkcije ML. V tej objavi smo razpravljali o primeru uporabe ML od konca do konca z uporabo zmogljivosti AWS. Z uporabo SageMaker in Amazon MWAA smo zgradili cevovod po meri, ki ga lahko ponovno uporabimo v projektih in modelih, in avtomatizirali življenjski cikel ML, kar je skrajšalo čas od usposabljanja modela do uvedbe v proizvodnjo na vsega 10 minut.
S prenosom bremena življenjskega cikla ML na SageMaker je zagotovil optimizirano in razširljivo infrastrukturo za usposabljanje in uvajanje modela. Storitev modela s SageMakerjem nam je pomagala narediti napovedi v realnem času z milisekundnimi zakasnitvami in zmožnostmi spremljanja. Terraform smo uporabili za enostavno nastavitev in upravljanje infrastrukture.
Naslednji koraki v zvezi s tem cevovodom bi bili izboljšanje cevovoda za usposabljanje modela z zmožnostmi preusposabljanja, ne glede na to, ali je načrtovano ali temelji na zaznavanju premikanja modela, podpori uvajanja v senci ali testiranja A/B za hitrejšo in kvalificirano uvajanje modela ter sledenja rodu ML. Načrtujemo tudi ocenjevanje Amazonski cevovodi SageMaker ker je zdaj podprta integracija GitLab.
Nova spoznanja
Kot del gradnje te rešitve smo se naučili, da bi morali posploševati zgodaj, vendar ne posplošujte pretirano. Ko smo prvič končali načrtovanje arhitekture, smo poskušali ustvariti in uveljaviti predloge kode za kodo modela kot najboljšo prakso. Vendar pa je bilo tako zgodaj v razvojnem procesu, da so bile predloge preveč posplošene ali preveč podrobne, da bi jih bilo mogoče ponovno uporabiti za prihodnje modele.
Po dobavi prvega modela v nastajanju so predloge nastale naravno na podlagi vpogledov iz našega prejšnjega dela. Plinovod ne zmore vsega od prvega dne.
Eksperimentiranje z modelom in proizvodnja imata pogosto zelo različne (ali včasih celo nasprotujoče si) zahteve. Ključnega pomena je, da te zahteve že od začetka kot ekipa uravnotežite in temu primerno določite prednostne naloge.
Poleg tega morda ne boste potrebovali vseh funkcij storitve. Uporaba bistvenih funkcij storitve in modularna zasnova sta ključa do učinkovitejšega razvoja in prilagodljivega cevovoda.
zaključek
V tej objavi smo pokazali, kako smo z uporabo SageMaker in Amazon MWAA zgradili rešitev MLOps, ki je avtomatizirala postopek uvajanja modelov v proizvodnjo z malo ročnega posredovanja podatkovnih znanstvenikov. Spodbujamo vas, da ocenite različne storitve AWS, kot so SageMaker, Amazon MWAA, Amazon S3 in Amazon ECR, da zgradite popolno rešitev MLOps.
*Apache, Apache Airflow in Airflow so registrirane blagovne znamke ali blagovne znamke družbe Apache Software Foundation v ZDA in / ali drugih državah.
O avtorjih
 Deepak Mettem je višji vodja inženiringa v VMware, enoti za saje. On in njegova ekipa delajo na izdelavi aplikacij in storitev, ki temeljijo na pretakanju in so zelo razpoložljive, razširljive in odporne, da strankam v realnem času zagotovijo rešitve, ki temeljijo na strojnem učenju. On in njegova ekipa sta odgovorna tudi za ustvarjanje orodij, potrebnih podatkovnim znanstvenikom za izdelavo, usposabljanje, uvajanje in potrjevanje njihovih modelov ML v proizvodnji.
Deepak Mettem je višji vodja inženiringa v VMware, enoti za saje. On in njegova ekipa delajo na izdelavi aplikacij in storitev, ki temeljijo na pretakanju in so zelo razpoložljive, razširljive in odporne, da strankam v realnem času zagotovijo rešitve, ki temeljijo na strojnem učenju. On in njegova ekipa sta odgovorna tudi za ustvarjanje orodij, potrebnih podatkovnim znanstvenikom za izdelavo, usposabljanje, uvajanje in potrjevanje njihovih modelov ML v proizvodnji.
 Mahima Agarwal je inženir strojnega učenja v VMware, enoti za črne saje.
Mahima Agarwal je inženir strojnega učenja v VMware, enoti za črne saje.
Dela na načrtovanju, gradnji in razvoju osrednjih komponent in arhitekture platforme za strojno učenje za VMware CB SBU.
 Vamshi Krishna Enabothala je starejši arhitekt specialist za umetno inteligenco pri AWS. Sodeluje s strankami iz različnih sektorjev, da bi pospešil pobude za podatke, analitiko in strojno učenje z velikim vplivom. Navdušen je nad sistemi priporočil, NLP in področji računalniškega vida v AI in ML. Zunaj službe je Vamshi navdušenec nad RC, sestavlja RC opremo (letala, avtomobile in brezpilotna letala), uživa pa tudi v vrtnarjenju.
Vamshi Krishna Enabothala je starejši arhitekt specialist za umetno inteligenco pri AWS. Sodeluje s strankami iz različnih sektorjev, da bi pospešil pobude za podatke, analitiko in strojno učenje z velikim vplivom. Navdušen je nad sistemi priporočil, NLP in področji računalniškega vida v AI in ML. Zunaj službe je Vamshi navdušenec nad RC, sestavlja RC opremo (letala, avtomobile in brezpilotna letala), uživa pa tudi v vrtnarjenju.
 Sahil Thapar je arhitekt za podjetniške rešitve. Sodeluje s strankami, da bi jim pomagal zgraditi zelo razpoložljive, razširljive in odporne aplikacije v oblaku AWS. Trenutno se osredotoča na vsebnike in rešitve strojnega učenja.
Sahil Thapar je arhitekt za podjetniške rešitve. Sodeluje s strankami, da bi jim pomagal zgraditi zelo razpoložljive, razširljive in odporne aplikacije v oblaku AWS. Trenutno se osredotoča na vsebnike in rešitve strojnega učenja.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- : je
- $GOR
- 1
- 10
- 100
- 7
- 8
- a
- O meni
- pospeši
- dostop
- dostopna
- ustrezno
- računi
- doseže
- čez
- aciklični
- Poleg tega
- Dodatne
- Dodatne informacije
- po
- proti
- AI
- algoritmi
- vsi
- omogoča
- Amazon
- Amazon SageMaker
- Analiza
- analitika
- in
- kjerkoli
- Apache
- API
- uporaba
- aplikacije
- uporabna
- Uporabljena AI
- odobritev
- Arhitektura
- SE
- območja
- AS
- vidik
- At
- Napadi
- avtorstvo
- avto
- Avtomatizirano
- avtomatizira
- razpoložljivost
- Na voljo
- izogniti
- AWS
- Backend
- Ravnovesje
- temeljijo
- Osnovni
- BE
- ker
- Začetek
- Prednosti
- BEST
- Boljše
- med
- črna
- Block
- Branch
- prinašajo
- izgradnjo
- Building
- zgrajena
- obremenitev
- by
- CAN
- ne more
- Zmogljivosti
- ogljika
- avtomobili
- primeru
- CB
- nekatere
- Spremembe
- kanali
- otrok
- izbral
- Cloud
- Grozd
- Koda
- zbirka
- Komunikacija
- v primerjavi z letom
- dokončanje
- deli
- Izračunajte
- računalnik
- Računalniška vizija
- dirigira
- konfiguracija
- konfiguracije
- V nasprotju
- zmeda
- premislekov
- porabijo
- porabi
- Posoda
- Zabojniki
- stalno
- Priročen
- Core
- bi
- države
- CPU
- ustvarjajo
- ustvaril
- ustvari
- Ustvarjanje
- kritično
- ključnega pomena
- Trenutno
- po meri
- Stranke, ki so
- prilagodite
- kibernetski napadi
- DAG
- vsak dan
- Armaturna plošča
- datum
- podatkovni znanstvenik
- dan
- opredeljen
- dostavo
- razporedi
- razporejeni
- uvajanja
- uvajanje
- razmestitve
- razpolaga
- Oblikovanje
- zasnovan
- oblikovanje
- podrobno
- Podrobnosti
- Odkrivanje
- dev
- razvili
- razvoju
- Razvoj
- drugačen
- neposredno
- razpravlja
- razpravljali
- Lučki delavec
- dont
- navzdol
- Brezpilotna letala
- vsak
- prej
- Zgodnje
- Enostavnost uporabe
- učinkovite
- bodisi
- E-naslov
- smirkovim
- omogočajo
- omogočena
- omogoča
- spodbujanje
- konec koncev
- Končna točka
- inženir
- Inženiring
- Podjetje
- Rešitve za podjetja
- navdušenec
- okolja
- oprema
- bistvena
- Eter (ETH)
- oceniti
- ocenili
- ocenjevanje
- Ocena
- vrednotenja
- Tudi
- Event
- Tudi vsak
- vse
- Primer
- Razširi
- razširitev
- f1
- olajšati
- Napaka
- daleč
- hitreje
- Feature
- Lastnosti
- Nekaj
- datoteke
- prva
- prilagodljiv
- Osredotočite
- osredotočena
- Osredotoča
- po
- za
- format
- iz
- polno
- celoten spekter
- v celoti
- funkcija
- funkcije
- nadalje
- Prihodnost
- ustvarila
- dobili
- dobro
- skupina
- Imajo
- ob
- pomoč
- pomagal
- Pomaga
- visoka
- visokozmogljivo
- zelo
- gostovanje
- Kako
- Vendar
- HTML
- http
- HTTPS
- IAM
- ID
- idealen
- identificirati
- identificirati
- identiteta
- slika
- slike
- izvajati
- Izvajanje
- izvajali
- in
- vključujejo
- vključuje
- Vključno
- Podatki
- Infrastruktura
- pobud
- vpogledi
- integrirati
- integrirana
- Integrira
- integracija
- interakcijo
- intervencije
- prikliče
- vključeni
- izolacija
- IT
- ITS
- Job
- Delovna mesta
- jpg
- Imejte
- Ključne
- tipke
- Latenca
- plast
- naučili
- učenje
- Spoznanja
- Pridobljena spoznanja
- Lets
- Stopnja
- življenski krog
- kot
- malo
- obremenitev
- nizka
- stroj
- strojno učenje
- Glavne
- vzdrževati
- vzdržuje
- vzdrževanje
- Znamka
- upravljanje
- upravlja
- upravljanje
- upravitelj
- upravlja
- upravljanje
- Navodilo
- Matrix
- Spomin
- omenjeno
- sporočil
- sporočanje
- Meritve
- morda
- milisekunde
- min
- ML
- MLOps
- Model
- modeli
- sodobna
- monitor
- spremljanje
- več
- učinkovitejše
- več
- Ime
- seveda
- potrebno
- Nimate
- Novo
- Naslednja
- nlp
- hrup
- Obvestilo
- Obvestila
- Številka
- of
- ponujanje
- Ponudbe
- on
- ONE
- operativno
- operaterji
- optimizirana
- možnosti
- orkestrirana
- Organizirano
- Ostalo
- zunaj
- Splošni
- paket
- pakete
- embalaža
- del
- vozovnice
- Podaje
- strastno
- pot
- performance
- Dovoljenje
- plinovod
- Načrt
- Letala
- platforma
- platon
- Platonova podatkovna inteligenca
- PlatoData
- politike
- politika
- Prispevek
- praksa
- Napovedi
- prejšnja
- Prednost
- Postopek
- Izdelek
- proizvodnja
- Projekt
- projekti
- pravilno
- zaščita
- če
- Ponudnik
- zagotavlja
- objavijo
- objavljeno
- Objavlja
- Založništvo
- namene
- kvalificirano
- območje
- v realnem času
- Priporočilo
- Zmanjšana
- besedilu
- registriranih
- registra
- Razmerja
- daljinsko
- Priznan
- Skladišče
- zahtevano
- zahteva
- obvezna
- Zahteve
- Raziskave
- odporno
- Odgovor
- odgovorna
- Rezultati
- preusposabljanje
- za večkratno uporabo
- vloge
- Run
- runner
- sagemaker
- Enako
- razširljive
- skaliranje
- urnik
- načrtovano
- Znanstvenik
- Znanstveniki
- drugi
- oddelki
- Sektorji
- varnost
- višji
- ločena
- Brez strežnika
- Strežniki
- Storitev
- Storitve
- služijo
- nastavite
- nastavitev
- Shadow
- PREMIKANJE
- shouldnt
- pokazale
- Enostavno
- Slack
- So
- doslej
- Software
- Rešitev
- rešitve
- nekaj
- vir
- Izvorna koda
- specialist
- specifična
- določeno
- Spectrum
- Spotlight
- Stage
- postopka
- standardna
- Začetek
- začne
- Države
- Koraki
- shranjevanje
- Strategija
- pretakanje
- racionalizirati
- kasneje
- Uspešno
- taka
- podpora
- Podprti
- Površina
- sistemi
- TAG
- Bodite
- Naloge
- skupina
- predloge
- Terraform
- Testiranje
- da
- O
- njihove
- Njih
- zato
- te
- grožnje
- 3
- skozi
- vsej
- pretočnost
- čas
- Časovni žig
- do
- skupaj
- tudi
- orodje
- orodja
- vrh
- temo
- sledenje
- Sledenje
- blagovne znamke
- Prometa
- Vlak
- usposobljeni
- usposabljanje
- sprožijo
- sprožilo
- OBRAT
- pod
- Enota
- Velika
- Združene države Amerike
- posodobitve
- us
- Uporaba
- uporaba
- primeru uporabe
- uporabnik
- Uporabniki
- POTRDI
- potrjevanje
- spremenljivke
- različnih
- različica
- praktično
- Vizija
- vizualizirati
- VMware
- Obseg
- način..
- Dobro
- Kaj
- ali
- ki
- široka
- Širok spekter
- z
- v
- brez
- delo
- potek dela
- delovnih tokov
- deluje
- bi
- zefirnet
- Zip
- cone