Predstavitev
Svet revizijskih podatkov je lahko zapleten, s številnimi izzivi, ki jih je treba premagati. Eden največjih izzivov je ravnanje s kategoričnimi atributi pri delu z nizi podatkov. V tem članku se bomo poglobili v svet revizijskih podatkov, odkrivanja anomalij in vpliva kodiranja kategoričnih atributov na modele.
Eden od glavnih izzivov, povezanih z odkrivanjem anomalij za revidiranje podatkov, je ravnanje s kategoričnimi atributi. Kodiranje kategoričnih atributov je obvezno, ker modeli ne morejo interpretirati vnosa besedila. Običajno se to izvede s kodiranjem Label ali One Hot encoding. Vendar lahko v velikem naboru podatkov kodiranje One-hot povzroči slabo delovanje modela zaradi prekletstva dimenzionalnosti.
Učni cilji
-
Razumeti koncept revizijskih podatkov in izziv
- Oceniti različne metode globokega nenadzorovanega odkrivanja anomalij.
- Razumeti vpliv kodiranja kategoričnih atributov na modele, ki se uporabljajo za odkrivanje nepravilnosti v revizijskih podatkih.
Ta članek je bil objavljen kot del Blogathon o znanosti o podatkih.
Kazalo
- Kaj je Auata?
- Kaj je odkrivanje anomalij?
- Glavni izzivi pri revidiranju podatkov
- Revizija naborov podatkov za odkrivanje nepravilnosti
- Kodiranje kategorialnih atributov
- Kategorična kodiranja
- Nenadzorovani modeli za odkrivanje nepravilnosti
- Kako kodiranje kategoričnih atributov vpliva na modele?
8.1 t-SNE predstavitev nabora podatkov o avtomobilskem zavarovanju
8.2 t-SNE predstavitev nabora podatkov o zavarovanju vozil
8.3 t-SNE predstavitev nabora podatkov o zahtevkih za vozila - zaključek
pri je Revizijski podatki?
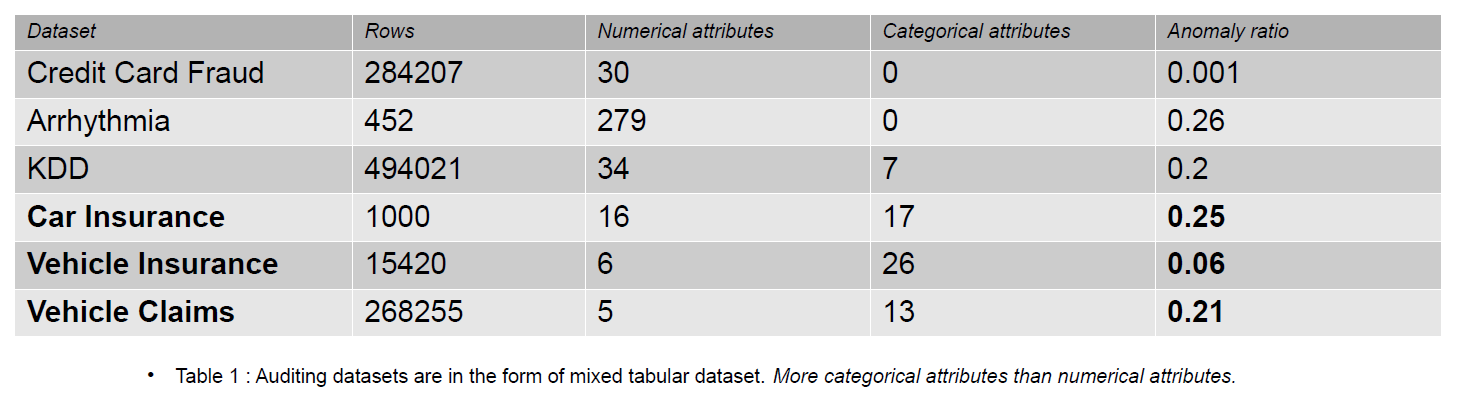
Revizijski podatki lahko vključujejo dnevnike, zavarovalne zahtevke in podatke o vdorih za informacijske sisteme; v tem članku so navedeni primeri zavarovalnih zahtevkov za vozila. Zavarovalni zahtevki se od naborov podatkov za odkrivanje nepravilnosti, npr. KDD, razlikujejo po večjem številu kategoričnih značilnosti.
Kategorične značilnosti so razprave v naših podatkih, ki so lahko celega ali znakovnega tipa. Številske značilnosti so stalni atributi v naših podatkih, ki so vedno realno ovrednoteni. Nabori podatkov s številčnimi značilnostmi so priljubljeni v skupnosti za odkrivanje nepravilnosti, kot so podatki o goljufijah s kreditnimi karticami. Večina javno dostopnih naborov podatkov vsebuje manj kategoričnih značilnosti kot podatki o zavarovalnih zahtevkih. Kategoričnih značilnosti je v naborih podatkov o zavarovalnih zahtevkih več kot številčnih.
Zavarovalni zahtevek vključuje značilnosti, kot so model, blagovna znamka, dohodek, stroški, izdaja, barva itd. Število kategoričnih značilnosti je večje pri revizijskih podatkih kot pri naborih podatkov o kreditni kartici in KDD. Ti nabori podatkov so merila uspešnosti pri nenadzorovanih metodah odkrivanja nepravilnosti. Kot je razvidno iz spodnje tabele, imajo nabori podatkov o zavarovalnih zahtevkih več kategoričnih značilnosti, ki so pomembne za razumevanje vedenja goljufivih podatkov.
Revizijski nizi podatkov, ki se uporabljajo za ovrednotenje vpliva kategoričnega kodiranja, so avtomobilsko zavarovanje, zavarovanje vozil in zahtevki za vozila.
Kaj je odkrivanje anomalij?
Anomalija je opazovanje, ki je oddaljeno od običajnih podatkov v naboru podatkov za določeno razdaljo (prag). Pri revizijskih podatkih raje uporabljamo izraz goljufivi podatki. Zaznavanje anomalij razlikuje med običajnimi in lažnimi podatki z uporabo strojnega učenja ali modela globokega učenja. Različne metode se lahko uporablja za odkrivanje anomalij, kot je ocena gostote, napaka rekonstrukcije in metode razvrščanja.
- Ocena gostote – Te metode ocenjujejo normalno porazdelitev podatkov in razvrščajo nenormalne podatke, če niso bili vzorčeni iz naučene porazdelitve.
- Napaka pri rekonstrukciji – Metode rekonstrukcije, ki temeljijo na napakah, temeljijo na načelu, da je mogoče običajne podatke rekonstruirati z manjšimi izgubami kot nepravilne podatke. Večja kot je izguba pri rekonstrukciji, poveča možnosti, da so podatki anomalija.
- Metode razvrščanja - Metode razvrščanja, kot so Naključni gozd, izolacijski gozd, enotni razred – podporni vektorski stroji in lokalni izstopajoči faktorji se lahko uporabljajo za odkrivanje anomalij. Razvrstitev pri odkrivanju anomalij vključuje identifikacijo enega od razredov kot anomalije. Kljub temu so razredi razdeljeni v dve skupini (0 in 1) v večrazrednem scenariju, razred z manj podatki pa je nepravilen razred.
Rezultat zgornjih metod so rezultati anomalij ali napake rekonstrukcije. Nato se moramo odločiti za prag, po katerem razvrstimo nenormalne podatke.
Glavni izzivi pri revidiranju podatkov
- Ravnanje s kategoričnimi atributi: Kodiranje kategoričnih atributov je obvezno, ker model ne more interpretirati vnosa besedila. Torej so vrednosti kodirane s kodiranjem Label ali One Hot kodiranjem. Toda v velikem naboru podatkov One hot encoding pretvori podatke v visokodimenzionalni prostor s povečanjem števila atributov. Model deluje slabo zaradi prekletstvo dimenzij.
- Izbira praga za razvrstitev: Če podatki niso označeni, je težko oceniti delovanje modela, ker ne poznamo števila anomalij, prisotnih v naboru podatkov. Predhodno znanje o naboru podatkov olajša določitev praga. Recimo, da imamo v svojih podatkih 5 od 10 nepravilnih vzorcev. Torej lahko izberemo prag pri rezultatu 50 percentilov.
- Javni nabori podatkov: Večina naborov revizijskih podatkov je zaupnih, ker pripadajo podjetjem in vsebujejo občutljive in osebne podatke. Eden od možnih načinov za ublažitev težav z zaupnostjo je usposabljanje z uporabo sintetičnih naborov podatkov (zahtevci vozil).
Revizija naborov podatkov za odkrivanje nepravilnosti
Zavarovalni zahtevki za vozila vključujejo podatke o lastnostih vozila, kot so model, znamka, cena, letnik in vrsta goriva. Vsebuje podatke o vozniku, datum rojstva, spol in poklic. Poleg tega lahko zahtevek vključuje informacije o skupnih stroških popravila. Vsi nabori podatkov, uporabljeni v tem članku, so iz ene same domene, vendar se razlikujejo po številu atributov in številu primerkov.
-
Nabor podatkov o zahtevkih za vozila je velik in vsebuje več kot 250,000 vrstic, njegovi kategorični atributi pa imajo kardinalnost 1171. Zaradi velike velikosti ta nabor podatkov trpi zaradi prekletstva dimenzionalnosti.
- Nabor podatkov o zavarovanju vozil je srednje velik, s 15,420 vrsticami in 151 edinstvenimi kategoričnimi vrednostmi. Zaradi tega je manj nagnjen k prekletstvu dimenzionalnosti.
- Nabor podatkov o avtomobilskem zavarovanju je majhen, z oznakami in 25 % nenormalnimi vzorci ter vsebuje podobno število numeričnih in kategoričnih značilnosti. S 169 edinstvenimi kategorijami ne trpi zaradi prekletstva dimenzionalnosti.
Kodiranje kategoričnih atributov
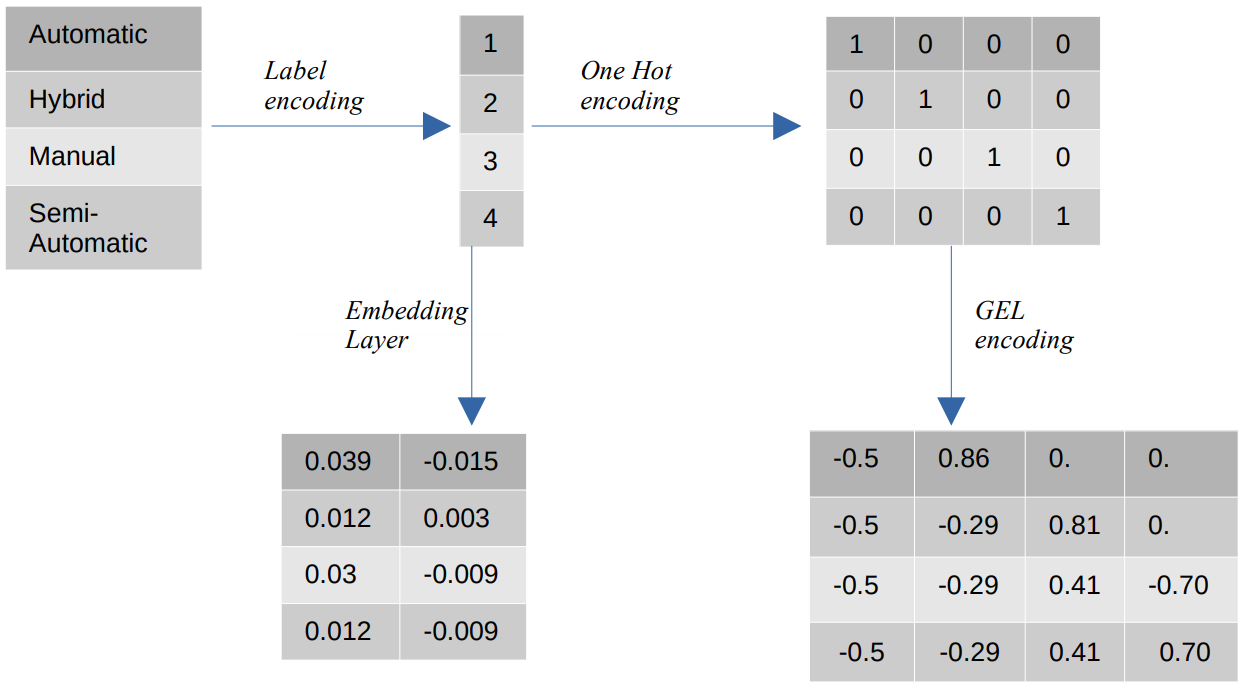
Različna kodiranja kategoričnih vrednosti
- Kodiranje nalepk – Pri kodiranju oznak so kategorične vrednosti nadomeščene s številskimi celimi vrednostmi med 1 in številom kategorij. Kodiranje oznak predstavlja kategorije na predviden način za ordinalne vrednosti. Kljub temu, ko so lastnosti nominalne, je predstavitev nepravilna, saj kategorične vrednosti niso v skladu z določenim vrstnim redom.
Na primer, če imamo v funkciji kategorije, kot so Samodejno, Hibridno, Ročno in Polsamodejno, kodiranje oznak pretvori te vrednosti v {1: Samodejno, 2: Hibridno, 3: Ročno, 4: Polsamodejno}. Ta predstavitev ne zagotavlja informacij o kategoričnih vrednostih, vendar predstavitev, kot je {0: Nizka, 1: Srednja, 2: Visoka}, zagotavlja jasno predstavitev, ker je spremenljivki funkcije Nizka dodeljena nižja številčna vrednost. Zato je kodiranje oznake boljše za ordinalne vrednosti, vendar neugodno za nominalne vrednosti. - En vroči kodiranje – Eno vroče kodiranje se uporablja za reševanje problema nominalnih vrednosti kodiranja, ki pretvori vsako kategorično vrednost v ločeno značilnost v nizu podatkov, sestavljenem iz binarnih vrednosti. Na primer, v primeru štirih različnih kategorij, kodiranih kot {1, 2, 3, 4}, bi One Hot kodiranje ustvarilo nove funkcije, kot so {Samodejno: [1,0,0,0], Hibridno: [0,1,0,0 ,0,0,1,0], ročno: [0,0,0,1], polavtomatsko: [XNUMX]}.
Razsežnost nabora podatkov je nato neposredno odvisna od števila kategorij, prisotnih v naboru podatkov. Posledično lahko kodiranje One Hot povzroči prekletstvo dimenzionalnosti, kar je pomanjkljivost tega načina kodiranja. - GEL kodiranje – Kodiranje GEL je tehnika vdelave, ki se lahko uporablja v nadzorovanih in nenadzorovanih učnih metodah. Temelji na načelu kodiranja One Hot in se lahko uporablja za zmanjšanje dimenzionalnosti kategoričnih značilnosti, ki so bile kodirane z uporabo kodiranja One Hot.
- Vdelana plast - Vdelave besed omogočajo uporabo kompaktne in goste predstavitve, v kateri imajo podobne besede podobno kodiranje. Vdelava je zgoščen vektor vrednosti s plavajočo vejico, ki so parametri, ki jih je mogoče učiti. Vdelave besed se lahko gibljejo od 8-dimenzionalnih (za majhne nabore podatkov) do 1024-dimenzionalnih (za velike nabore podatkov).
Večdimenzionalna vdelava lahko zajame podrobnejše odnose med besedami, vendar zahteva več podatkov za učenje. Vdelana plast je iskalna tabela, ki pretvori vsako besedo, prisotno v matriki, v vektor določene velikosti.
Nenadzorovani modeli za odkrivanje nepravilnosti
V resničnem svetu podatki v večini primerov niso označeni, označevanje podatkov pa je drago in dolgotrajno. Zato bomo za naše ocene uporabili nenadzorovane modele.
- SOM - Samoorganizirajoča se karta (SOM) je konkurenčna učna metoda, pri kateri se uteži nevronov posodabljajo tekmovalno in ne z uporabo učenja širjenja nazaj. SOM je sestavljen iz zemljevida nevronov, od katerih ima vsak utežni vektor enake velikosti kot vhodni vektor. Vektor teže se inicializira z naključnimi utežmi pred začetkom vadbe. Med usposabljanjem se vsak vhod primerja z nevroni zemljevida na podlagi metrike razdalje (npr. evklidske razdalje) in se preslika v enoto najboljšega ujemanja (BMU), ki je nevron z najmanjšo razdaljo do vhodnega vektorja.
Uteži BMU se posodobijo z utežmi vhodnega vektorja, sosednji nevroni pa se posodobijo na podlagi radija soseske (sigma). Ker nevroni tekmujejo med seboj, da bodo enota, ki se najbolje ujema, je ta proces znan kot tekmovalno učenje. Na koncu so nevroni normalnih vzorcev bližje kot nenormalni. Rezultati anomalij so opredeljeni z napako kvantizacije, ki je razlika med vhodnim vzorcem in utežmi enote, ki se najbolje ujema. Večja napaka kvantizacije pomeni večjo verjetnost, da je vzorec anomalija. - DAGMM – Model globoke avtokodirane Gaussove mešanice (DAGMM) je metoda ocenjevanja gostote, ki predpostavlja, da so anomalije v območju z nizko verjetnostjo. Omrežje je razdeljeno na dva dela: kompresijsko omrežje, ki se uporablja za projiciranje podatkov v nižje dimenzije z uporabo samodejnega kodirnika, in ocenjevalno omrežje, ki se uporablja za oceno parametrov modela Gaussove mešanice. DAGMM oceni k število Gaussovih zmesi, kjer je k lahko poljubno število od 1 do N (število podatkovnih točk), pri čemer se predpostavlja, da normalne točke ležijo v območju z visoko gostoto, kar pomeni, da je verjetnost vzorčenja iz Gaussova mešanica je višja za normalne točke kot za nepravilne vzorce. Rezultati anomalij so opredeljeni z ocenjeno energijo vzorca.
- RSRAE – Sloj Robust Surface Recovery Layer za nenadzorovano odkrivanje nepravilnosti je metoda napake pri rekonstrukciji, ki podatke najprej projicira v nižjo dimenzijo z uporabo samodejnega kodirnika. Latentna predstavitev je nato podvržena pravokotni projekciji na linearni podprostor, ki je robusten do izstopajočih vrednosti. Dekoder nato rekonstruira izhod iz linearnega podprostora. Pri tej metodi večja napaka rekonstrukcije kaže večjo verjetnost, da je vzorec anomalija.
- SOM-DAGMM- Self-organizing Map (SOM) – Deep Autoencoding Gaussian Mixture Model (DAGMM) je tudi model ocenjevanja gostote. Tako kot DAGMM tudi oceni verjetnostno porazdelitev normalnih podatkovnih točk in podatkovno točko razvrsti kot anomalijo, če je zanjo majhna verjetnost vzorčenja iz naučene porazdelitve. Glavna razlika med SOM-DAGMM in DAGMM je v tem, da SOM-DAGMM vključuje normalizirane koordinate SOM za vhodni vzorec, ki omrežju ocenjevanja zagotavlja manjkajoče topološke informacije v primeru DAGMM. Cilj je podoben tudi DAGMM, saj so rezultati anomalije opredeljeni z ocenjeno energijo vzorca, nizka energija pa kaže večjo verjetnost, da je vzorec anomalija.
Nato se bomo posvetili izzivu ravnanja s kategoričnimi atributi.
Kako kodiranje kategoričnih atributov vpliva na modele?
Da bi razumeli vpliv različnih kodiranj na nabore podatkov, bomo uporabili t-SNE za vizualizacijo nizkodimenzionalnih predstavitev podatkov za različna kodiranja. t-SNE projicira visokodimenzionalne podatke v nižjedimenzionalni prostor, kar olajša vizualizacijo. S primerjavo vizualizacij t-SNE in numeričnih rezultatov različnih kodiranj istega nabora podatkov se opazi razlika v dobljenih predstavitvah in razumevanju vpliva kodiranja na nabor podatkov.
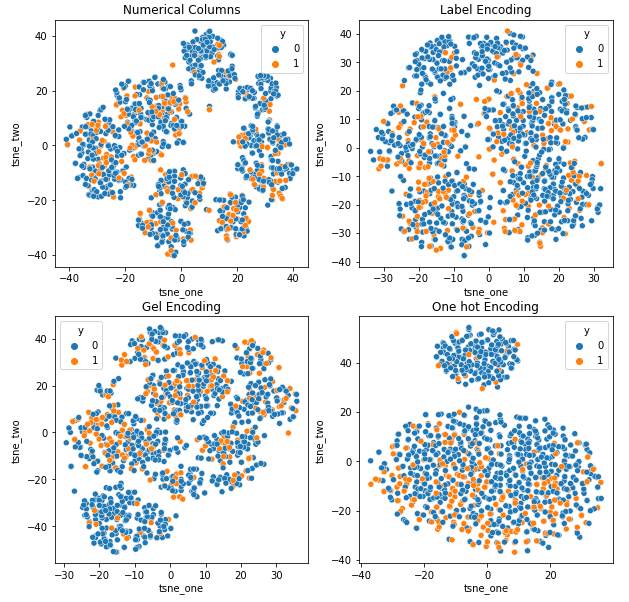
t-SNE predstavitev nabora podatkov o avtomobilskem zavarovanju
t-SNE predstavitev nabora podatkov o zavarovanju vozil
-
Podatki so bližje drug drugemu, ker je število vrstic večje kot v naboru podatkov Car Insurance. S povečano dimenzionalnostjo v kodiranju One Hot postane težko ločiti.
-
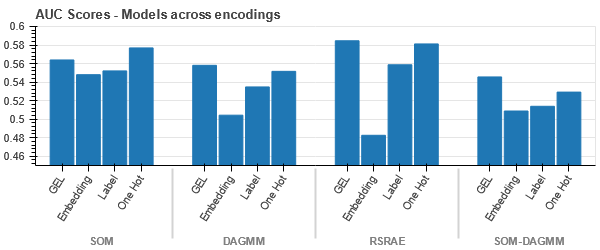
Kodiranje GEL je boljše od kodiranja One Hot v vseh primerih razen DAGMM.
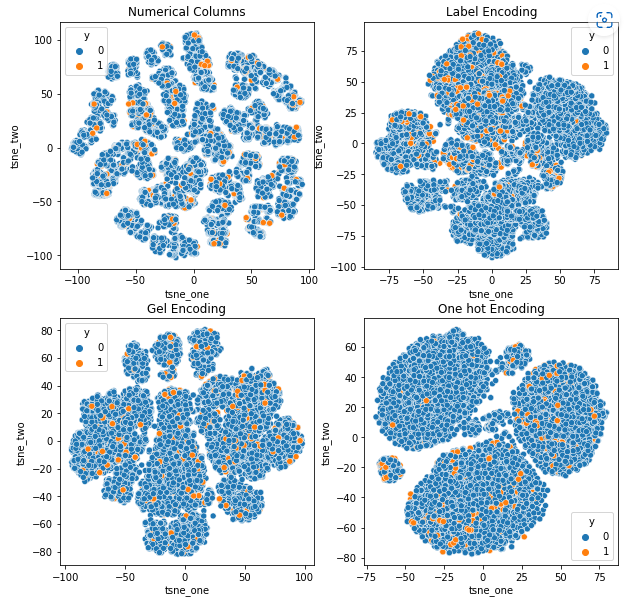
t-SNE predstavitev nabora podatkov o zahtevkih za vozila
-
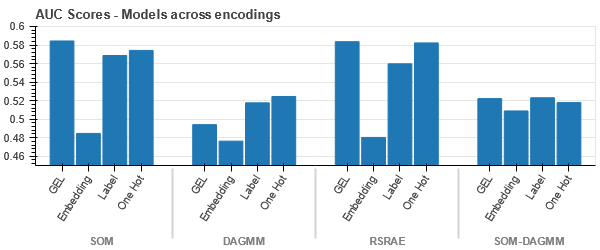
Podatki so v vseh primerih tesno vezani, kar otežuje ločevanje zaradi povečane dimenzionalnosti. To je eden od razlogov za slabo delovanje modelov zaradi povečane dimenzionalnosti.
- SOM prekaša vse druge modele za ta nabor podatkov. Kljub temu je v večini primerov primernejša vdelana plast, ki nam omogoča alternativo kodiranju kategorični atributi za odkrivanje nepravilnosti.
zaključek
Ta članek predstavlja kratek pregled revizijskih podatkov, odkrivanja nepravilnosti in kategoričnega kodiranja. Pomembno je razumeti, da je ravnanje s kategoričnimi atributi v revizijskih podatkih zahtevno. Z razumevanjem vpliva kodiranja atributov na modele lahko izboljšamo natančnost zaznavanja nepravilnosti v naborih podatkov. Ključni izsledki tega članka so:
- Ker se velikost podatkov povečuje, je pomembno uporabiti alternativne pristope kodiranja za kategorične atribute, kot sta kodiranje GEL in plasti vdelave, ker kodiranje One Hot ni primerno.
- En model ne deluje za vse nize podatkov. Za tabelarične podatkovne nize je poznavanje domene izjemno pomembno.
- Izbira metode kodiranja je odvisna od izbire modela.
Koda za ocenjevanje modelov je na voljo na GitHub.
Mediji, prikazani v tem članku, niso v lasti Analytics Vidhya in se uporabljajo po lastni presoji avtorja.
Podobni
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- O meni
- nad
- Po
- natančnost
- Poleg tega
- Naslov
- vsi
- omogoča
- alternativa
- vedno
- analitika
- Analitika Vidhya
- in
- odkrivanje anomalije
- pristopi
- članek
- dodeljena
- povezan
- domnevajo
- lastnosti
- revidiranje
- Samodejno
- Na voljo
- temeljijo
- ker
- postane
- pred
- počutje
- spodaj
- meril
- BEST
- Boljše
- med
- največji
- zavezuje
- blagovne znamke
- ne more
- zajemanje
- voziček
- avtomobilsko zavarovanje
- kartice
- primeru
- primeri
- kategorije
- izziv
- izzivi
- izziv
- kvote
- značaja
- izbira
- trdijo
- terjatve
- razred
- razredi
- Razvrstitev
- Razvrsti
- jasno
- bližje
- Koda
- barva
- pogosto
- skupnost
- Podjetja
- v primerjavi z letom
- primerjavo
- tekmujejo
- konkurenčno
- kompleksna
- Koncept
- zaupnost
- Sestavljeno
- Vsebuje
- neprekinjeno
- Corporate
- strošek
- ustvarjajo
- kredit
- kreditne kartice
- datum
- podatkovne točke
- nabor podatkov
- Datum
- deliti
- zmanjša
- globoko
- globoko učenje
- odvisno
- podrobno
- Odkrivanje
- Ugotovite,
- Razlika
- drugačen
- težko
- Dimenzije
- dimenzije
- neposredno
- diskretnost
- razdalja
- izrazit
- distribucija
- deljeno
- domena
- voznik
- med
- vsak
- lažje
- bodisi
- energija
- Napaka
- napake
- oceniti
- ocenjeni
- ocene
- itd
- oceniti
- Ocena
- vrednotenja
- Primer
- Primeri
- Razen
- drago
- izredno
- soočen
- dejavniki
- Feature
- Lastnosti
- prva
- gozd
- goljufija
- goljufiva
- iz
- gorivo
- Spol
- Skupine
- Ravnanje
- visoka
- več
- HOT
- Vendar
- HTTPS
- Hybrid
- identifikacijo
- vpliv
- Pomembno
- izboljšanje
- in
- vključujejo
- vključuje
- prihodki
- povečal
- Poveča
- narašča
- označuje
- Podatki
- Informacijski sistemi
- vhod
- zavarovanje
- izolacija
- vprašanje
- Vprašanja
- IT
- Ključne
- Vedite
- znanje
- znano
- label
- označevanje
- Oznake
- velika
- večja
- plast
- plasti
- vodi
- UČITE
- naučili
- učenje
- lokalna
- nahaja
- iskanje
- off
- izgube
- nizka
- stroj
- strojno učenje
- Stroji
- Glavne
- IZDELA
- Izdelava
- obvezna
- Navodilo
- več
- map
- ujemanje
- Matrix
- kar pomeni,
- mediji
- srednje
- Metoda
- Metode
- meritev
- minimalna
- manjka
- Omiliti
- mešanico
- Model
- modeli
- več
- Najbolj
- mreža
- Neuroni
- Novo
- Nove funkcije
- normalno
- Številka
- Cilj
- ONE
- Da
- Ostalo
- Presega
- Premagajte
- pregled
- v lasti
- parametri
- del
- deli
- performance
- opravlja
- Osebni
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Točka
- točke
- slaba
- Popular
- mogoče
- raje
- predstaviti
- darila
- Cena
- Načelo
- Predhodna
- verjetnost
- problem
- Postopek
- poklic
- Projekt
- podatke o projektu
- Projekcija
- projekti
- Lastnosti
- zagotavljajo
- če
- zagotavlja
- objavljeno
- naključno
- območje
- pravo
- resnični svet
- Razlogi
- okrevanje
- okolica
- Razmerja
- popravilo
- nadomesti
- zastopanje
- predstavlja
- zahteva
- povzroči
- rezultat
- Rezultati
- robusten
- Enako
- Znanost
- občutljiva
- ločena
- pokazale
- Sigma
- Podoben
- saj
- sam
- Velikosti
- majhna
- manj
- So
- Vesolje
- specifična
- začne
- Še vedno
- taka
- Trpi
- primerna
- podpora
- Površina
- sintetična
- sistemi
- miza
- Takeaways
- Pogoji
- O
- svet
- zato
- Prag
- tesno
- zamudno
- do
- Skupaj za plačilo
- Vlak
- usposabljanje
- razumeli
- razumevanje
- edinstven
- Enota
- nenadzorovano učenje
- posodobljeno
- us
- uporaba
- vrednost
- Vrednote
- vozilo
- Vozila
- teža
- Kaj
- Kaj je
- ki
- medtem
- bo
- beseda
- besede
- delo
- svet
- bi
- leto
- zefirnet