Amazon Redshift ML omogoča podatkovnim analitikom, razvijalcem in podatkovnim znanstvenikom, da učijo modele strojnega učenja (ML) z uporabo SQL. V prejšnjih objavah smo pokazali, kako lahko za usposabljanje uporabite zmožnost samodejnega usposabljanja modela Redshift ML Razvrstitev in regresija modeli. Redshift ML vam omogoča, da ustvarite model z uporabo SQL in določite svoj algoritem, kot je XGBoost. Redshift ML lahko uporabite za avtomatizacijo priprave podatkov, predprocesiranja in izbire vrste težave (za več informacij glejte Ustvarite, usposobite in uvedite modele strojnega učenja v Amazon Redshift z uporabo SQL z Amazon Redshift ML). Lahko prinesete tudi model, ki je bil predhodno usposobljen Amazon SageMaker v Amazon RedShift prek Redshift ML za lokalno sklepanje. Za lokalno sklepanje o modelih, ustvarjenih v SageMakerju, mora Redshift ML podpirati tip modela ML. vendar daljinsko sklepanje je na voljo za vrste modelov, ki izvorno niso na voljo v Redshift ML.
Sčasoma se modeli ML postarajo in tudi če se ne zgodi nič drastičnega, se kopičijo majhne spremembe. Pogosti razlogi, zakaj je treba modele ML ponovno usposobiti ali revidirati, vključujejo:
- Odmik podatkov – Ker so se vaši podatki sčasoma spremenili, se lahko natančnost napovedi vaših modelov ML začne zmanjševati v primerjavi z natančnostjo, prikazano med testiranjem
- Konceptni drift – Algoritem ML, ki je bil prvotno uporabljen, bo morda treba spremeniti zaradi različnih poslovnih okolij in drugih spreminjajočih se potreb
Morda boste morali redno osveževati model, avtomatizirati postopek in ponovno oceniti izboljšano natančnost modela. Od tega pisanja Amazon Redshift ne podpira različic modelov ML. V tej objavi prikazujemo, kako lahko uporabite funkcijo prinašanja lastnega modela (BYOM) Redshift ML za implementacijo različic modelov Redshift ML.
Lokalno sklepanje uporabljamo za implementacijo različic modelov kot del operacionalizacije modelov ML. Predvidevamo, da dobro razumete svoje podatke in vrsto težave, ki je najbolj uporabna za vaš primer uporabe, ter da ste ustvarili in razmestili modele v produkcijo.
Pregled rešitev
V tej objavi uporabljamo Redshift ML za izgradnjo regresijskega modela, ki napove število ljudi, ki bodo morda uporabljali storitev souporabe koles v mestu Toronto ob kateri koli uri dneva. Model upošteva različne vidike, vključno s prazniki in vremenskimi razmerami, in ker moramo predvideti numerični rezultat, smo uporabili regresijski model. Zamik podatkov uporabljamo kot razlog za ponovno usposabljanje modela, različico modela pa uporabljamo kot del rešitve.
Ko je model preverjen in se redno uporablja za izvajanje napovedi, lahko ustvarite različice modelov, kar zahteva, da znova usposobite model z uporabo posodobljenega nabora za usposabljanje in po možnosti drugačnega algoritma. Različice imajo dva glavna namena:
- Za namene odpravljanja težav ali revizije se lahko sklicujete na prejšnje različice modela. To vam omogoča, da zagotovite, da vaš model še vedno ohranja visoko natančnost, preden preklopite na novejšo različico modela.
- Med procesom usposabljanja modela za novo različico lahko nadaljujete z izvajanjem sklepnih poizvedb na trenutni različici modela.
V času tega pisanja Redshift ML nima izvornih zmogljivosti za ustvarjanje različic, vendar lahko vseeno dosežete različice z implementacijo nekaj preprostih tehnik SQL z uporabo zmogljivosti BYOM. BYOM je bil uveden za podporo vnaprej usposobljenih modelov SageMaker za izvajanje vaših sklepnih poizvedb v Amazon Redshift. V tej objavi uporabljamo isto tehniko BYOM za ustvarjanje različice obstoječega modela, zgrajenega z uporabo Redshift ML.
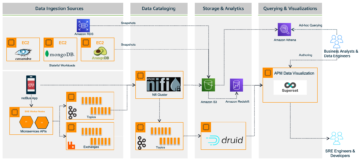
Naslednja slika prikazuje ta potek dela.
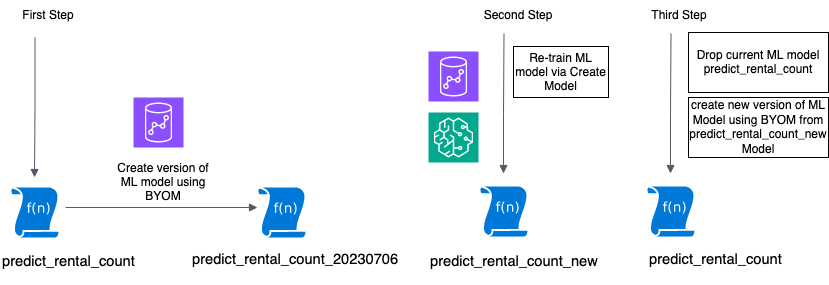
V naslednjih razdelkih vam pokažemo, kako lahko ustvarite različico iz obstoječega modela in nato izvedete ponovno usposabljanje modela.
Predpogoji
Kot predpogoj za implementacijo primera v tej objavi morate nastaviti a Rdeči premik grozda or Amazon Redshift brez strežnika končna točka. Za predhodne korake za začetek in nastavitev vašega okolja glejte Ustvarite, usposobite in uvedite modele strojnega učenja v Amazon Redshift z uporabo SQL z Amazon Redshift ML.
Uporabljamo regresijski model, ustvarjen v objavi Izdelajte regresijske modele z Amazon Redshift ML. Predvidevamo, da je že uveden, in uporabljamo ta model za ustvarjanje novih različic in ponovno usposabljanje modela.
Ustvarite različico iz obstoječega modela
Prvi korak je izdelava različice obstoječega modela (kar pomeni shranjevanje razvojnih sprememb modela), da se ohrani zgodovina in je model na voljo za kasnejšo primerjavo.
Naslednja koda je generična oblika sintakse ukaza CREATE MODEL; v naslednjem koraku dobite informacije, potrebne za uporabo tega ukaza za ustvarjanje nove različice:
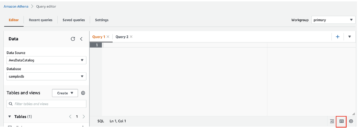
Nato zberemo in uporabimo vhodne parametre za prejšnjo kodo CREATE MODEL za model. Potrebujemo ime opravila in tipe podatkov vhodnih in izhodnih vrednosti modela. Te zbiramo z vodenjem show model ukaz na našem obstoječem modelu. Zaženite naslednji ukaz v Amazon Redshift Query Editor v2:

Upoštevajte vrednosti za Ime opravila AutoML, Vrste parametrov funkcijeIn Ciljni stolpec (trip_count) iz izhoda modela. Te vrednosti uporabimo v ukazu CREATE MODEL za ustvarjanje različice.
Naslednji stavek CREATE MODEL ustvari različico trenutnega modela z uporabo vrednosti, zbranih iz našega show model ukaz. Na konec imena modela in funkcij dodamo datum (primerna oblika je LLLLMMDD), da sledimo, kdaj je bila ta nova različica ustvarjena.
Dokončanje tega ukaza lahko traja nekaj minut. Ko je končano, zaženite naslednji ukaz:

V izhodu lahko opazimo naslednje:
- Ime opravila AutoML je enak originalni različici modela
- Ime funkcije prikazuje novo ime, kot je pričakovano
- Vrsta sklepanja oddaj
Local, ki označuje, da je to BYOM z lokalnim sklepanjem
Poizvedbe po sklepanju lahko zaženete z uporabo obeh različic modela za preverjanje rezultatov sklepanja.
Naslednji posnetek zaslona prikazuje rezultat sklepanja modela z uporabo izvirne različice.

Naslednji posnetek zaslona prikazuje rezultat sklepanja modela z uporabo kopije različice.

Kot lahko vidite, so rezultati sklepanja enaki.
Zdaj ste se naučili ustvariti različico predhodno usposobljenega modela Redshift ML.
Ponovno usposobite svoj model Redshift ML
Ko ustvarite različico obstoječega modela, lahko znova usposobite obstoječi model tako, da preprosto ustvarite nov model.
Nov model lahko ustvarite in učite z istim ukazom CREATE MODEL, vendar z uporabo različnih vhodnih parametrov, naborov podatkov ali tipov težav, kot je primerno. Za to objavo ponovno usposobimo model za novejše nabore podatkov. Prilagamo _new na ime modela, tako da je zaradi identifikacije podoben obstoječemu modelu.
V naslednji kodi uporabimo ukaz CREATE MODEL z novim naborom podatkov, ki je na voljo v training_data miza:
Zaženite naslednji ukaz, da preverite stanje novega modela:
Zamenjajte obstoječi model Redshift ML s ponovno usposobljenim modelom
Zadnji korak je zamenjava obstoječega modela s prešolanim modelom. To naredimo tako, da opustimo izvirno različico modela in ponovno ustvarimo model s tehniko BYOM.
Najprej preverite svoj ponovno usposobljen model, da zagotovite, da rezultati MSE/RMSE ostajajo stabilni med zagonom usposabljanja modela. Če želite preveriti modele, lahko zaženete sklepanje po vsaki funkciji modela v svojem naboru podatkov in primerjate rezultate. Uporabljamo sklepne poizvedbe, navedene v Izdelajte regresijske modele z Amazon Redshift ML.
Po potrditvi lahko zamenjate svoj model.
Začnite z zbiranjem podrobnosti o predict_rental_count_new model.

Upoštevajte Ime opravila AutoML vrednost, Vrste parametrov funkcije vrednote in Ciljni stolpec ime v izhodu modela.
Zamenjajte izvirni model tako, da izpustite izvirni model in nato ustvarite model z izvirnimi imeni modelov in funkcij, da zagotovite, da obstoječe reference na imena modelov in funkcij delujejo:
Izdelava modela naj bi bila končana v nekaj minutah. Stanje modela lahko preverite tako, da zaženete naslednji ukaz:
Ko je status modela ready, novejša različica predict_rental_count vašega obstoječega modela je na voljo za sklepanje in izvirna različica modela ML predict_rental_count_20230706 je na voljo za referenco, če je potrebno.
Prosimo, glejte to GitHub repozitorij za vzorčne skripte za avtomatizacijo različic modela.
zaključek
V tej objavi smo pokazali, kako lahko uporabite funkcijo BYOM programa Redshift ML za ustvarjanje različic modela. To vam omogoča, da imate zgodovino svojih modelov, tako da lahko primerjate rezultate modela skozi čas, se odzovete na zahteve za revizijo in izvedete sklepanje med usposabljanjem novega modela.
Za več informacij o izdelavi različnih modelov z Redshift ML glejte Amazon Redshift ML.
O avtorjih
 Rohit Bansal je strokovnjak za analitične rešitve pri AWS. Specializiran je za Amazon Redshift in sodeluje s strankami pri izgradnji analitičnih rešitev naslednje generacije z uporabo drugih storitev AWS Analytics.
Rohit Bansal je strokovnjak za analitične rešitve pri AWS. Specializiran je za Amazon Redshift in sodeluje s strankami pri izgradnji analitičnih rešitev naslednje generacije z uporabo drugih storitev AWS Analytics.
 Phil Bates je višji arhitekt za rešitve strokovnjaka za analitiko pri AWS. Ima več kot 25 let izkušenj z implementacijo obsežnih rešitev za skladiščenje podatkov. Strastno želi pomagati strankam na njihovem potovanju v oblaku in uporabljati moč ML v njihovem podatkovnem skladišču.
Phil Bates je višji arhitekt za rešitve strokovnjaka za analitiko pri AWS. Ima več kot 25 let izkušenj z implementacijo obsežnih rešitev za skladiščenje podatkov. Strastno želi pomagati strankam na njihovem potovanju v oblaku in uporabljati moč ML v njihovem podatkovnem skladišču.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/implement-model-versioning-with-amazon-redshift-ml/
- :ima
- : je
- :ne
- $GOR
- 100
- 11
- 25
- 5000
- 7
- a
- O meni
- računi
- Akumulirajte
- natančnost
- Doseči
- algoritem
- omogoča
- že
- Prav tako
- Amazon
- Amazon Web Services
- an
- Analitiki
- analitika
- in
- kaj
- primerno
- Uporabi
- SE
- AS
- vidiki
- domnevati
- At
- Revizija
- revidiranih
- avtomatizirati
- Samodejno
- Na voljo
- AWS
- Osnova
- BE
- ker
- bilo
- pred
- začetek
- počutje
- med
- tako
- prinašajo
- izgradnjo
- Building
- zgrajena
- poslovni
- vendar
- by
- CAN
- Zmogljivosti
- zmožnost
- primeru
- spremenilo
- Spremembe
- spreminjanje
- preveriti
- mesto
- Cloud
- Koda
- zbiranje
- Zbiranje
- Stolpec
- Skupno
- primerjate
- v primerjavi z letom
- Primerjava
- dokončanje
- Pogoji
- naprej
- ustvarjajo
- ustvaril
- ustvari
- Ustvarjanje
- Oblikovanje
- Trenutna
- Stranke, ki so
- datum
- Priprava podatkov
- podatkovno skladišče
- nabor podatkov
- Datum
- dan
- zmanjša
- privzeto
- Dokazano
- razporedi
- razporejeni
- Podrobnosti
- Razvijalci
- razvojno
- drugačen
- do
- Ne
- Spuščanje
- 2
- med
- vsak
- urednik
- omogoča
- konec
- Končna točka
- zagotovitev
- okolje
- okolja
- Eter (ETH)
- Tudi
- Primer
- razstavljeno
- obstoječih
- izkušnje
- Feature
- Nekaj
- Slika
- prva
- po
- za
- format
- iz
- funkcija
- funkcionalnost
- funkcije
- dobili
- dana
- dobro
- Grow
- se zgodi
- Imajo
- he
- pomoč
- visoka
- zgodovina
- počitnice
- uro
- Kako
- Kako
- Vendar
- HTML
- http
- HTTPS
- IAM
- Identifikacija
- if
- ponazarja
- izvajati
- izvajanja
- izboljšalo
- in
- vključujejo
- Vključno
- Podatki
- na začetku
- vhod
- v
- Uvedeno
- IT
- Job
- Potovanje
- jpg
- obsežne
- Zadnja
- pozneje
- naučili
- učenje
- lokalna
- stroj
- strojno učenje
- Glavne
- Znamka
- Maj ..
- pomeni
- min
- ML
- Model
- modeli
- več
- Najbolj
- morajo
- Ime
- Imena
- materni
- Nimate
- potrebna
- potrebe
- Novo
- novejši
- Naslednja
- Naslednja generacija
- nič
- zdaj
- Številka
- numerično
- Cilj
- opazujejo
- of
- off
- Staro
- on
- or
- izvirno
- Ostalo
- naši
- Rezultat
- izhod
- izhodi
- več
- lastne
- parameter
- parametri
- del
- strastno
- ljudje
- opravlja
- platon
- Platonova podatkovna inteligenca
- PlatoData
- mogoče
- Prispevek
- Prispevkov
- moč
- napovedati
- napoved
- Napovedi
- Napovedi
- predhodno
- Priprava
- prejšnja
- prej
- Predhodna
- problem
- Postopek
- proizvodnja
- če
- namene
- poizvedbe
- Razlog
- Razlogi
- glejte
- reference
- reference
- regresija
- redni
- zamenjajte
- zahteva
- zahteva
- Odzove
- Rezultati
- ohrani
- preusposabljanje
- vrne
- Run
- tek
- deluje
- sagemaker
- Enako
- shranjevanje
- Znanstveniki
- rezultati
- skripte
- oddelki
- glej
- izbor
- višji
- služi
- Storitev
- Storitve
- nastavite
- nastavitve
- delitev
- shouldnt
- Prikaži
- je pokazala,
- Razstave
- Podoben
- Enostavno
- preprosto
- majhna
- So
- Rešitev
- rešitve
- specialist
- specializirano
- SQL
- stabilna
- začel
- Izjava
- Status
- ostati
- Korak
- Koraki
- Še vedno
- taka
- podpora
- Podprti
- Preverite
- sintaksa
- miza
- Bodite
- ciljna
- tehnika
- tehnike
- kot
- da
- O
- informacije
- njihove
- POTEM
- te
- ta
- skozi
- čas
- do
- sledenje
- Vlak
- usposobljeni
- usposabljanje
- dva
- tip
- Vrste
- razumevanje
- posodobljeno
- uporaba
- primeru uporabe
- Rabljeni
- uporabo
- POTRDI
- potrjeno
- potrjevanje
- vrednost
- Vrednote
- različnih
- različica
- različice
- preko
- Skladišče
- je
- we
- Vreme
- web
- spletne storitve
- kdaj
- ki
- medtem
- zakaj
- z
- v
- delo
- potek dela
- deluje
- pisanje
- XGBoost
- let
- jo
- Vaša rutina za
- zefirnet