Ta članek je bil prvotno objavljen na MontažaAI in ponovno objavljeno na TOPBOTS z dovoljenjem avtorja.
Difuzijski modeli so generativni modeli, ki v zadnjih nekaj letih postajajo zelo priljubljeni, in to z dobrim razlogom. Nekaj temeljnih člankov, objavljenih v 2020-ih sam so svetu pokazali, česa so zmožni difuzijski modeli, na primer premagati GAN-je[6] o sintezi slike. V zadnjem času bodo praktiki videli uporabo difuzijskih modelov v DALL-E2, model generiranja slik OpenAI, ki je bil izdan prejšnji mesec.

Glede na nedavni val uspeha difuzijskih modelov mnoge praktike strojnega učenja zagotovo zanima njihovo notranje delovanje. V tem članku bomo preučili teoretične osnove za difuzijske modelein nato pokažite, kako ustvariti slike z a Difuzijski model v PyTorchu. Potopimo se!
Če je ta poglobljena izobraževalna vsebina koristna za vas, naročite se na naš poštni seznam AI na katerega bomo opozorili, ko bomo izdali novo gradivo.
Difuzijski modeli – Uvod
Difuzijski modeli so generativno modelov, kar pomeni, da se uporabljajo za ustvarjanje podatkov, podobnih podatkom, na katerih se usposabljajo. V bistvu difuzijski modeli delujejo po uničenje podatkov o usposabljanju z zaporednim dodajanjem Gaussovega šuma in nato učenje okrevanja podatke po vzvratno ta hrupni proces. Po usposabljanju lahko uporabimo difuzijski model za preprosto ustvarjanje podatkov prenašanje naključno vzorčenega hrupa skozi naučen postopek odstranjevanja hrupa.

Natančneje, difuzijski model je model latentne spremenljivke, ki se preslika v latentni prostor z uporabo fiksne Markovljeve verige. Ta veriga podatkom postopoma dodaja šum, da dobi približen posteriorni q(x1: T|x0), kjer je x1,…, XT so latentne spremenljivke z enako dimenzijo kot x0. Na spodnji sliki vidimo takšno Markovljevo verigo, prikazano za slikovne podatke.
Na koncu se slika asimptotično pretvori v čisti Gaussov šum. The Cilj usposabljanja difuzijskega modela je učenje nazaj proces – torej usposabljanje strθ(xt−1|xt). S prečkanjem te verige nazaj lahko ustvarimo nove podatke.
Prednosti difuzijskih modelov
Kot je navedeno zgoraj, so raziskave difuzijskih modelov v zadnjih letih eksplodirale. Po navdihu neravnovesne termodinamike[1], Difuzijski modeli trenutno proizvajajo Vrhunska kakovost slike, katerih primere si lahko ogledate spodaj:
Poleg vrhunske kakovosti slike imajo difuzijski modeli številne druge prednosti, vključno z ne potrebujejo kontradiktornega usposabljanja. Težave adversarnega usposabljanja so dobro dokumentirane; in v primerih, ko obstajajo nekontradiktorne alternative s primerljivo uspešnostjo in učinkovitostjo usposabljanja, jih je običajno najbolje uporabiti. Na temo učinkovitosti usposabljanja imajo difuzijski modeli tudi dodatne prednosti razširljivost in vzporednost.
Čeprav se zdi, da difuzijski modeli dajejo rezultate skoraj iz nič, obstaja veliko previdnih in zanimivih matematičnih odločitev in podrobnosti, ki zagotavljajo osnovo za te rezultate, najboljše prakse pa se v literaturi še razvijajo. Zdaj pa si podrobneje oglejmo matematično teorijo, na kateri temeljijo difuzijski modeli.
Difuzijski modeli – globok potop
Kot je navedeno zgoraj, je difuzijski model sestavljen iz a postopek naprej (ali difuzijski proces), v kateri je podatek (na splošno slika) postopoma šumen, in a obratni proces (ali proces povratne difuzije), v katerem se hrup pretvori nazaj v vzorec iz ciljne porazdelitve.
Prehode verige vzorčenja v procesu naprej lahko nastavite na pogojne Gaussove, ko je raven hrupa dovolj nizka. Kombinacija tega dejstva z Markovo predpostavko vodi do preproste parametrizacije naprednega procesa:

Matematična opomba
Govorili smo o poškodovanju podatkov s dodajanje Gaussov šum, vendar bo morda sprva nejasno, kje izvajamo ta dodatek. V skladu z zgornjo enačbo na vsakem koraku v verigi preprosto vzorčimo iz Gaussove porazdelitve, katere povprečje je prejšnja vrednost (tj. slika) v verigi.
Ti dve izjavi sta enakovredni. To je

Da bi razumeli, zakaj, bomo uporabili rahlo zlorabo notacije s trditvijo


Kjer končna implikacija izhaja iz matematične enakovrednosti med vsoto naključnih spremenljivk in konvolucijo njihovih porazdelitev – glej to stran Wikipedije za več informacij.
Z drugimi besedami, pokazali smo, da je trditev o porazdelitvi časovnega koraka, pogojenega s prejšnjim prek povprečja Gaussove porazdelitve, enakovredna trditvi, da je porazdelitev danega časovnega koraka enaka porazdelitvi prejšnjega z dodatkom Gaussovega šuma. Izpustili smo skalarje, ki jih je uvedel razpored variance, in to zaradi poenostavitve prikazali za eno dimenzijo, vendar podoben dokaz velja za multivariatne Gaussove.
Kjer je β1,…,βT je razpored odstopanj (naučen ali fiksen), ki, če se pravilno obnaša, zagotavlja, da xT je skoraj izotropni Gaussov za dovolj velik T.

Kot smo že omenili, prihaja do "čarovnije" difuzijskih modelov obratni proces. Med usposabljanjem se model nauči obrniti ta proces difuzije, da ustvari nove podatke. Začenši s čistim Gaussovim šumom p(xT):=N(xT,0,I) se model nauči skupne porazdelitve pθ(x0: T) kot

kjer se naučijo časovno odvisni parametri Gaussovih prehodov. Upoštevajte zlasti, da Markovljeva formulacija trdi, da je dana porazdelitev prehoda povratne difuzije odvisna samo od prejšnjega časovnega koraka (ali naslednjega časovnega koraka, odvisno od tega, kako na to gledate):

usposabljanje
Difuzijski model usposablja iskanje obratnih Markovljevih prehodov, ki povečajo verjetnost podatkov o usposabljanju. V praksi je usposabljanje enakovredno sestavljeno iz minimiziranja variacijske zgornje meje verjetnosti negativnega dnevnika.

Notacija Podrobnosti
Upoštevajte, da je Litd je tehnično an Zgornji vezan (negativ ELBO), ki ga poskušamo minimizirati, vendar ga imenujemo Litd zaradi skladnosti z literaturo.
Prizadevamo si prepisati Litd v smislu Razhajanja Kullback-Leibler (KL). Divergenca KL je asimetrična statistična mera razdalje, ki določa, koliko ena porazdelitev verjetnosti P razlikuje od referenčne porazdelitve Q. Zanima nas formulacija Litd v smislu razhajanj KL, ker so prehodne porazdelitve v naši Markovljevi verigi Gaussove, in divergenca KL med Gaussovi ima zaprto obliko.
Kaj je KL divergenca?
Matematična oblika divergence KL za zvezne porazdelitve je

Spodaj lahko vidite razhajanje KL spremenljive porazdelitve P (modra) iz referenčne distribucije Q (rdeča). Zelena krivulja označuje funkcijo znotraj integrala v zgornji definiciji za divergenco KL, skupna površina pod krivuljo pa predstavlja vrednost divergence KL P iz Q v danem trenutku vrednost, ki je tudi številčno prikazana.
Casting  v smislu razhajanj KL
v smislu razhajanj KL
Kot je bilo že omenjeno, je možno [1] prepisati Litd skoraj popolnoma v smislu razhajanj KL:

Kje

Podrobnosti izpeljave
Variacijska meja je enaka

Če porazdelitve zamenjamo z njihovimi definicijami glede na predpostavko Markova, dobimo

Za pretvorbo izraza v vsoto dnevnikov uporabimo pravila dnevnika, nato pa izvlečemo prvi člen

Z uporabo Bayesovega izreka in naše Markove predpostavke ta izraz postane

Nato razdelimo srednji izraz z uporabo pravil dnevnika
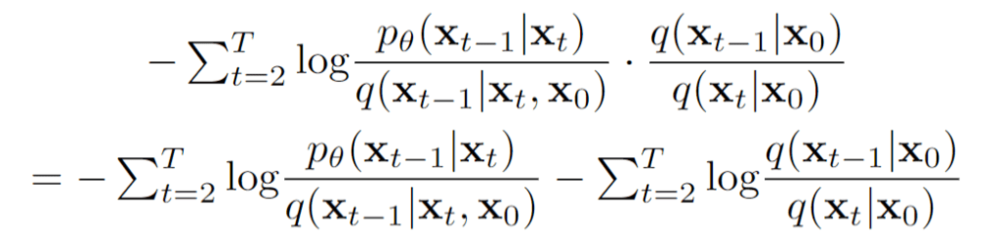
Vidimo, da izoliramo drugi izraz

Če to vključimo nazaj v našo enačbo za Litd, imamo

Z uporabo pravil dnevnika preuredimo

Nato opazimo naslednjo enakovrednost za divergenco KL za kateri koli dve porazdelitvi:

Končno z uporabo te enakovrednosti prejšnjega izraza pridemo do

Pogojovanje naprednega procesa posteriorno na x0 v Lt−1 rezultatov v poslušni obliki, ki vodi do vse KL divergence so primerjave med Gaussovi. To pomeni, da je mogoče razlike natančno izračunati z izrazi zaprte oblike in ne z ocenami Monte Carlo[3].
Izbira modela
Z vzpostavljeno matematično osnovo za našo ciljno funkcijo moramo zdaj sprejeti več odločitev glede tega, kako bo implementiran naš difuzijski model. Za postopek posredovanja je edina zahtevana izbira definiranje urnika odstopanja, katerega vrednosti med postopkom posredovanja običajno naraščajo.
Za obratni proces izberemo arhitekturo(-e) parametrizacije/modela Gaussove porazdelitve. Upoštevajte visoka stopnja fleksibilnosti ki ga omogočajo difuzijski modeli – samo Zahteva za našo arhitekturo je, da imata njen vhod in izhod enako dimenzionalnost.
Spodaj bomo podrobneje raziskali podrobnosti teh izbir.
Forward Process in LT
Kot je navedeno zgoraj, moramo v zvezi s postopkom naprej opredeliti razpored odstopanj. Še posebej smo jih postavili časovno odvisne konstante, zanemarjajoč dejstvo, da se jih je mogoče naučiti. Na primer[3], linearni razpored iz β1= 10-4 do βTUporabite lahko =0.2 ali morda geometrijsko vrsto.
Ne glede na določene izbrane vrednosti dejstvo, da je razpored variance fiksen, povzroči LT postane stalnica glede na naš nabor učljivih parametrov, kar nam omogoča, da ga zanemarimo, kar zadeva usposabljanje.

Obratni proces in L1:T−1
Zdaj razpravljamo o izbirah, ki so potrebne pri definiranju obratnega procesa. Spomnimo se, da smo zgoraj definirali obratne Markovljeve prehode kot Gaussov:

Zdaj moramo definirati funkcionalne oblike μθ ali Σθ. Medtem ko obstajajo bolj zapleteni načini za parametrizacijo Σθ[5], preprosto nastavimo

To pomeni, da predpostavljamo, da je multivariatni Gaussian produkt neodvisnih Gaussianov z enako varianco, vrednost variance, ki se lahko s časom spreminja. mi nastavite te razlike tako, da bodo enakovredne našemu razporedu odstopanj v naprej.
Glede na to novo formulacijo Σθ, imamo

ki nam omogoča transformacijo

do

kjer je prvi člen v razliki linearna kombinacija xt in x0 ki je odvisen od razporeda variance βt. Natančna oblika te funkcije ni pomembna za naše namene, vendar jo je mogoče najti v [3].
Pomen zgornjega deleža je v tem najbolj enostavna parametrizacija μθ preprosto napove posteriorno povprečje difuzije. Pomembno je, da avtorji [3] je dejansko ugotovil, da je usposabljanje μθ napovedati hrupa komponenta v katerem koli danem časovnem koraku daje boljše rezultate. Zlasti naj

Kje

To vodi do naslednje alternativne funkcije izgube, ki so ga avtorji [3] vodi do stabilnejšega treninga in boljših rezultatov:

Avtorji [3] upoštevajte tudi povezave te formulacije difuzijskih modelov z generativnimi modeli za ujemanje točk, ki temeljijo na Langevinovi dinamiki. Dejansko se zdi, da sta lahko difuzijski modeli in modeli, ki temeljijo na rezultatih, dve plati istega kovanca, podobno neodvisnemu in sočasnemu razvoju kvantne mehanike, ki temelji na valovih, in kvantne mehanike, ki temelji na matriki, ki razkrivata dve enakovredni formulaciji istih pojavov.[2].
Arhitektura omrežja
Medtem ko naša poenostavljena funkcija izgube poskuša usposobiti model ϵθ, še vedno nismo definirali arhitekture tega modela. Upoštevajte, da je samo Zahteva za model je, da sta njegova vhodna in izhodna dimenzija enaki.
Glede na to omejitev morda ni presenetljivo, da se modeli difuzije slike običajno izvajajo z arhitekturami, podobnimi U-Netu.

Dekoder povratnega procesa in L0
Pot vzdolž obratnega procesa je sestavljena iz številnih transformacij pod zveznimi pogojnimi Gaussovimi porazdelitvami. Na koncu obratnega procesa se spomnite, da poskušamo ustvariti slika, ki je sestavljen iz celih vrednosti slikovnih pik. Zato moramo izmisliti način za pridobitev diskretne (log) verjetnosti za vsako možno vrednost slikovne pike v vseh slikovnih pikah.
To se naredi tako, da se zadnji prehod v verigi povratne difuzije nastavi na an neodvisni diskretni dekoder. Za določitev verjetnosti dane slike x0 glede na x1, najprej vsilimo neodvisnost med dimenzijami podatkov:

kjer je D dimenzionalnost podatkov in nadnapis i označuje ekstrakcijo ene koordinate. Zdaj je cilj ugotoviti, kako verjetna je posamezna cela vrednost za dano slikovno piko dana porazdelitev po možnih vrednostih za ustrezno slikovno piko na sliki z rahlim šumom v času t=1:

kjer so porazdelitve slikovnih pik za t=1 izpeljane iz spodnjega multivariantnega Gaussova, katerega diagonalna kovariančna matrika nam omogoča razdelitev porazdelitve na produkt univariantnih Gaussovih, enega za vsako dimenzijo podatkov:

Predvidevamo, da so slike sestavljene iz celih števil v 0,1,…,255 (kot standardne RGB slike), ki so bile linearno pomanjšane na [-1,1]. Nato realno črto razčlenimo na majhne »vedra«, kjer za dano pomanjšano vrednost slikovnih pik x, je vedro za ta obseg [x−1/255, x+1/255]. Verjetnost vrednosti slikovne pike x, glede na univariatno Gaussovo porazdelitev ustrezne piksle v x1, ali je območje pod to univariatno Gaussovo porazdelitvijo znotraj vedra s središčem na x.
Spodaj si lahko ogledate območje za vsako od teh veder z njihovimi verjetnostmi za Gaussovo srednjo vrednost 0, ki v tem kontekstu ustreza porazdelitvi s povprečno vrednostjo pikslov 255/2 (polovična svetlost). Rdeča krivulja predstavlja porazdelitev določene piksle v t = 1 sliko, območja pa podajajo verjetnost ustrezne vrednosti pikslov v t = 0 sliko.
Tehnična opomba
Prvo in zadnje vedro se razširita na -inf in +inf, da ohranita skupno verjetnost.
Glede na a t = 0 vrednost pikslov za vsako slikovno piko, vrednost pθ(x0|x1) je preprosto njihov izdelek. Ta proces je na kratko opisan z naslednjo enačbo:

Kje

in

Glede na to enačbo za pθ(x0|x1), lahko izračunamo končni člen Litd ki ni formuliran kot KL divergenca:

Končni cilj
Kot je bilo omenjeno v zadnjem razdelku, so avtorji [3] je ugotovil, da napovedovanje komponente hrupa slike v danem časovnem koraku daje najboljše rezultate. Navsezadnje uporabljajo naslednji cilj:

Algoritme za usposabljanje in vzorčenje za naš model difuzije je torej mogoče na kratko zajeti na spodnji sliki:
Povzetek teorije difuzijskega modela
V tem razdelku smo se podrobno poglobili v teorijo difuzijskih modelov. Lahko se zlahka ujamete v matematične podrobnosti, zato si v tem razdelku spodaj zapomnimo najpomembnejše točke, da se bomo orientirali s ptičje perspektive:
- Naš difuzijski model je parametriran kot a Markova veriga, kar pomeni, da naše latentne spremenljivke x1,…, XT odvisno samo od prejšnjega (ali naslednjega) časovnega koraka.
- O prehodne porazdelitve v markovski verigi so Gaussian, kjer napredni proces zahteva razpored odstopanj, parametri obratnega procesa pa so naučeni.
- Postopek difuzije zagotavlja, da xT is asimptotično porazdeljen kot izotropni Gaussov za dovolj velik T.
- V našem primeru je razpored odstopanj je bil popravljen, vendar se ga da tudi naučiti. Za fiksne razporede lahko sledenje geometrijskemu napredovanju zagotovi boljše rezultate kot linearno napredovanje. V obeh primerih se variance na splošno povečujejo s časom v seriji (tj. βi<βj za i
- Difuzijski modeli so zelo prilagodljiv in omogočiti kaj arhitektura, katere vhodna in izhodna dimenzija sta enaki za uporabo. Številne izvedbe uporabljajo Podobno U-Netu arhitekture.
- O cilj usposabljanja je povečati verjetnost podatkov o usposabljanju. To se kaže kot nastavitev parametrov modela na minimizirajte variacijsko zgornjo mejo negativne log verjetnosti podatkov.
- Skoraj vse člene v ciljni funkciji je mogoče prenesti kot Razhajanja KL kot rezultat naše Markove predpostavke. Te vrednote postanejo sposobni izračunati glede na to, da uporabljamo Gaussove vrednosti, zato ni potrebe po izvajanju aproksimacije Monte Carlo.
- Navsezadnje z uporabo a poenostavljen cilj usposabljanja usposabljanje funkcije, ki napoveduje komponento šuma dane latentne spremenljivke, daje najboljše in najbolj stabilne rezultate.
- A diskretni dekoder se uporablja za pridobitev log verjetnosti v vrednostih slikovnih pik kot zadnji korak v procesu povratne difuzije.
S tem pregledom difuzijskih modelov na visoki ravni v mislih, pojdimo naprej, da vidimo, kako uporabiti difuzijske modele v PyTorchu.
Difuzijski modeli v PyTorchu
Čeprav difuzijski modeli še niso bili demokratizirani do enake stopnje kot druge starejše arhitekture/pristopi v strojnem učenju, še vedno obstajajo izvedbe, ki so na voljo za uporabo. Najlažji način za uporabo difuzijskega modela v PyTorchu je uporaba denoising-diffusion-pytorch paket, ki izvaja model difuzije slike, kot je ta, obravnavan v tem članku. Če želite namestiti paket, preprosto vnesite naslednji ukaz v terminal:
pip install denoising_diffusion_pytorch
Minimalni primer
Za usposabljanje modela in ustvarjanje slik najprej uvozimo potrebne pakete:
import torch
from denoising_diffusion_pytorch import Unet, GaussianDiffusion
Nato definiramo našo omrežno arhitekturo, v tem primeru U-Net. The dim parameter določa število zemljevidov značilnosti pred prvim vzorčenjem navzdol in dim_mults parameter zagotavlja množitelje za to vrednost in zaporedna znižanja vzorčenja:
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
)
Zdaj, ko je naša omrežna arhitektura definirana, moramo definirati sam model difuzije. Posredujemo model U-Net, ki smo ga pravkar definirali, skupaj z več parametri – velikostjo slik za generiranje, številom časovnih korakov v procesu difuzije in izbiro med normama L1 in L2.
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000, # number of steps
loss_type = 'l1' # L1 or L2
)
Zdaj, ko je model difuzije definiran, je čas za usposabljanje. Ustvarimo naključne podatke za urjenje, nato pa urimo model difuzije na običajen način:
training_images = torch.randn(8, 3, 128, 128)
loss = diffusion(training_images)
loss.backward()
Ko je model usposobljen, lahko končno ustvarimo slike z uporabo sample() metoda diffusion predmet. Tukaj ustvarimo 4 slike, ki so le šum glede na to, da so bili naši podatki o usposabljanju naključni:
sampled_images = diffusion.sample(batch_size = 4)

Usposabljanje o podatkih po meri
O denoising-diffusion-pytorch vam omogoča tudi urjenje difuzijskega modela na določenem naboru podatkov. Preprosto zamenjajte 'path/to/your/images' niz s potjo imenika nabora podatkov v Trainer() predmet spodaj in spremenite image_size na ustrezno vrednost. Po tem preprosto zaženite kodo za usposabljanje modela in nato vzorčite kot prej. Upoštevajte, da mora biti PyTorch preveden z omogočeno CUDA, če želite uporabiti Trainer razred:
from denoising_diffusion_pytorch import Unet, GaussianDiffusion, Trainer
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
).cuda()
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000, # number of steps
loss_type = 'l1' # L1 or L2
).cuda()
trainer = Trainer(
diffusion,
'path/to/your/images',
train_batch_size = 32,
train_lr = 2e-5,
train_num_steps = 700000, # total training steps
gradient_accumulate_every = 2, # gradient accumulation steps
ema_decay = 0.995, # exponential moving average decay
amp = True # turn on mixed precision
)
trainer.train()
Spodaj si lahko ogledate progresivno odstranjevanje hrupa od multivariantnega Gaussovega šuma do števk MNIST, ki je podobno obratni difuziji:

Končne besede
Difuzijski modeli so konceptualno preprost in eleganten pristop k problemu generiranja podatkov. Njihovi najsodobnejši rezultati v kombinaciji z nenadpornim usposabljanjem so jih popeljali v velike višine in glede na njihov nastajajoči status lahko v prihodnjih letih pričakujemo nadaljnje izboljšave. Zlasti je bilo ugotovljeno, da so difuzijski modeli bistveni za delovanje najsodobnejših modelov, kot je DALL-E2.
Reference
[1] Globoko nenadzorovano učenje z uporabo neravnotežne termodinamike
[2] Generativno modeliranje z ocenjevanjem gradientov porazdelitve podatkov
[3] Verjetnotni modeli difuzijskega odpravljanja hrupa
[4] Izboljšane tehnike za usposabljanje generativnih modelov na podlagi rezultatov
[5] Izboljšani verjetnostni modeli difuzijskega odpravljanja hrupa
[6] Difuzijski modeli premagajo GAN pri sintezi slike
[7] GLIDE: Proti fotorealističnemu ustvarjanju in urejanju slik z besedilno vodenimi difuzijskimi modeli
[8] Hierarhično besedilno pogojno generiranje slik s CLIP Latents
Uživate v tem članku? Prijavite se za več posodobitev raziskav AI.
Obvestili vas bomo, ko bomo objavili več povzetkov, kot je ta.
Podobni
- AI
- ai art
- ai art generator
- imajo robota
- Umetna inteligenca
- certificiranje umetne inteligence
- umetna inteligenca v bančništvu
- robot z umetno inteligenco
- roboti z umetno inteligenco
- blockchain
- blockchain konferenca ai
- coingenius
- Računalniška vizija
- pogovorna umetna inteligenca
- kripto konferenca ai
- dall's
- globoko učenje
- Gost
- strojno učenje
- Glavna značilnost
- platon
- platon ai
- Platonova podatkovna inteligenca
- Igra Platon
- PlatoData
- platogaming
- lestvica ai
- sintaksa
- Tehnična navodila
- TOPBOTI
- zefirnet