Letos mi ni uspelo v Punta Cano  sem pa vesel (na daljavo) za ljudi, ki so uspeli priti tja kljub vsem omejitvam potovanja! Premium vsebina znotraj.
sem pa vesel (na daljavo) za ljudi, ki so uspeli priti tja kljub vsem omejitvam potovanja! Premium vsebina znotraj.
Jesen je bila zelo naporna in rad bi poskusil s krajšim formatom: vsaka velika tema ima enega »reflektorja«  delo v glavnem bloku, ki se mi zdi še posebej zanimivo, in več relevantnih del, ki imajo nekoliko krajši opis.
delo v glavnem bloku, ki se mi zdi še posebej zanimivo, in več relevantnih del, ki imajo nekoliko krajši opis.
Plan za danes:
- KG-razširjeni jezikovni modeli: Kategorizacija
- Pogovorni AI: Nehaj halucinirati, brat
- Povezovanje entitet: V senci kolosa (Entitete)
- KG Gradbeništvo
- KG Odgovor na vprašanje: Dodajte nekaj
 SPARQL
SPARQL
Če je ta poglobljena izobraževalna vsebina koristna za vas, se naročite na naš seznam raziskav AI za raziskave na katerega bomo opozorili, ko bomo izdali novo gradivo.
KG-razširjeni jezikovni modeli: Kategorizacija
Relacijska predstavitev svetovnega znanja v kontekstualnih jezikovnih modelih: pregled avtorja Tara Safavi in Danai Koutra
Če ste izkušen bralec takšnih povzetkov (ali prejšnjih objav), potem precej dobro poznate obilico LM-jev, razširjenih s KG, objavljenih na vsaki konferenci in tedensko naloženih v arxiv. Če se počutiš izgubljeno  — Lahko vam zagotovim, da niste edini.
— Lahko vam zagotovim, da niste edini.
Letos imamo končno a zvočni okvir in taksonomija različnih pristopov KG+LM! Avtorji opredeljujejo 3 velike družine: 1⃣ brez nadzora KG, preizkušanje znanja, kodiranega v parametrih LM s pozivi v slogu cloze; 2⃣ Nadzor KG s subjekti in ID-ji; 3⃣ Nadzor KG z relacijskimi predlogami in površinskimi oblikami.
Vsaka družina ima nekaj vej  Oglejmo si na primer 4 modele, ki se zavedajo entitet, prikazane spodaj. Različno od "manj simbolično" do “bolj simbolično”, nekateri LM-ji izvajajo maskiranje obsega omembe ali kontrastno učenje ali fuzijo vdelav entitet iz znanega besedišča. Avtorji so opravili odlično delo pri razvrščanju na desetine obstoječih arhitektur glede na okvir in zdaj je videti veliko bolje organizirano. Zelo potrebno delo!
Oglejmo si na primer 4 modele, ki se zavedajo entitet, prikazane spodaj. Različno od "manj simbolično" do “bolj simbolično”, nekateri LM-ji izvajajo maskiranje obsega omembe ali kontrastno učenje ali fuzijo vdelav entitet iz znanega besedišča. Avtorji so opravili odlično delo pri razvrščanju na desetine obstoječih arhitektur glede na okvir in zdaj je videti veliko bolje organizirano. Zelo potrebno delo! 

Nekaj kratkih prispevkov se osredotoča na obogatitev LM z biomedicinskimi KG, dolgotrajno prizadevanje, da bi LM naučili biomedicine, specifične za domeno. sleng. Meng et al predlaga Mešanica pregrad (MoP), LM, ki temelji na AdapterFusion tehnika, ki zmanjša potrebo po predhodnem treningu LM od začetka. MoP je bil usposobljen s splošnimi biomedicinskimi besednjaki in ontologijama UMLS in SNOMED CT. Sung et al vprašati "Ali so lahko jezikovni modeli baze biomedicinskega znanja?" nanašajoč se na slavni članek EMNLP'19 Petronija et al. Odgovor je v veliki meri NE. Avtorji oblikujejo BioLAMA, merilo uspešnosti za preizkušanje biomedicinskega znanja, zgrajeno iz UMLS, CTD in Wikidata. Ugotovijo, da imajo sodobni LM-ji <10-odstotno natančnost na teh sondah, zato skupnost zagotovo potrebuje nekaj bolj zanesljivega
Meng et al predlaga Mešanica pregrad (MoP), LM, ki temelji na AdapterFusion tehnika, ki zmanjša potrebo po predhodnem treningu LM od začetka. MoP je bil usposobljen s splošnimi biomedicinskimi besednjaki in ontologijama UMLS in SNOMED CT. Sung et al vprašati "Ali so lahko jezikovni modeli baze biomedicinskega znanja?" nanašajoč se na slavni članek EMNLP'19 Petronija et al. Odgovor je v veliki meri NE. Avtorji oblikujejo BioLAMA, merilo uspešnosti za preizkušanje biomedicinskega znanja, zgrajeno iz UMLS, CTD in Wikidata. Ugotovijo, da imajo sodobni LM-ji <10-odstotno natančnost na teh sondah, zato skupnost zagotovo potrebuje nekaj bolj zanesljivega  .
.
Pogovorni AI: Nehaj halucinirati, brat
Neural Path Hunter: Zmanjšanje halucinacij v sistemih dialoga prek ozemljitve poti od Nouha Dziri, Andrea Madotto, Osmar Zaiane, Avishek Joey Bose
Ustvarjanje odgovorov s sistemom ConvAI z ozadjem KG je težavno. V cevovodnih sistemih s številnimi komponentami strogo uporabljate površinske oblike (imena entitet) in se večinoma zatekate k predlogam ter predloge so dolgočasne in težko vzdrževana. Po drugi strani pa generativni modeli e2e, kot sta GPT-2 in GPT-3, proizvajajo veliko bolj edinstvene odgovore, vendar pogosto halucinirajo, to je vstavljanje napačnih imen entitet, ko tega ne pričakujete.
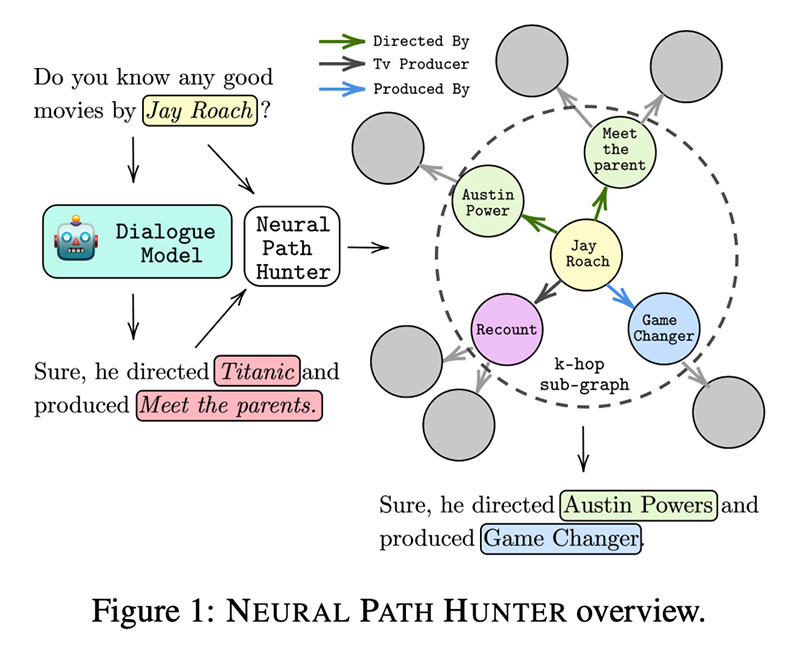
Avtorji tega dela so se lotili a Lov  za zmanjšanje halucinacij s predlaganjem nadzora KG Lovec na nevronske poti. Najprej preučijo več vrste halucinacij , od kod prihajajo (večinoma iz vzorčenja top-k) in kako jih kvantificirati.
za zmanjšanje halucinacij s predlaganjem nadzora KG Lovec na nevronske poti. Najprej preučijo več vrste halucinacij , od kod prihajajo (večinoma iz vzorčenja top-k) in kako jih kvantificirati.
Sam NPH je sestavljen iz dveh modulov: 1⃣ kritik (neavtoregresivni LM), ki izvaja binarno klasifikacijo nad žetoni; 2⃣ pridobivalnik entitet za popravljanje napak entitet: to je v bistvu pomnilnik entitet, kjer vdelave entitet prihajajo iz GPT in se posodabljajo s CompGCN z uporabo strukture grafa. Najbolj verjetni kandidati prihajajo z uporabo funkcije točkovanja DistMult. Voila!
NPH se lahko seznani s katerim koli vnaprej usposobljenim LM, poskusi na OpenDialKG merilo z GPT2-KG, GPT2-KEin AdapterBot kažejo znatno zmanjšanje  halucinacij in povečanja
halucinacij in povečanja  v zvestobi. Uporabniška študija poroča, da so halucinacije, izmerjene pri ljudeh, zmanjšane približno 2x v modelih NPH
v zvestobi. Uporabniška študija poroča, da so halucinacije, izmerjene pri ljudeh, zmanjšane približno 2x v modelih NPH
Še eno relevantno delo v tem kontekstu: Honovich et al preučiti isto težavo v sistemih za dialog, vendar brez KG ozadja, in predlagati novo merilo uspešnosti Q² za merjenje dejanske skladnosti ustvarjanja vprašanj in odgovarjanja na vprašanja (od koder prihajata oba Q, če vprašate).
Če vas zanimajo ConvAI in zdravorazumski KG – obvezno preverite CLUE (Conversational Multi-Hop Reasoner) do Arabshahi, Lee, et alki vključuje pojem če-(stanje), potem-(dejanje), ker-(cilj) vzorci logičnih pravil in simboličnega sklepanja.
Povezovanje entitet: V senci kolosa
Vrednotenje robustnosti razdvoumljanja entitete z uporabo predhodnih sond: primer zasenčenja entitete by Vera Provatorova, Svitlana Vakulenko, Samarth Bhargav, Evangelos Kanoulas
Ko priključite KG iz resničnega sveta za jezikovne naloge, s katerimi se boste neizogibno srečali različne entitete ki imajo točno isto ime  . Na žalost človeštvo ne uporablja edinstvenih zgoščenih vrednosti za vse entitete na svetu, zato ostaja razločevanje entitet pomemben korak pri povezovanju entitet.
. Na žalost človeštvo ne uporablja edinstvenih zgoščenih vrednosti za vse entitete na svetu, zato ostaja razločevanje entitet pomemben korak pri povezovanju entitet.

Wikidata ima na primer vsaj 18 subjektov z imenom "Michael Jordan". Sistemi EL se pogosto zanašajo na osnovne statistike in rezultate priljubljenosti, tako da bi najbolj priljubljen »košarkar Michael Jordan« zasenčil manj ugledne (vsaj v pop kulturi) ljudi.
 Avtorji se lotevajo tega problema in predstavljajo nov nabor podatkov, ShadowLink, za merjenje stopnje zmedenosti sodobnih EL sistemov. Izkazalo se je, da najvišja ocena F1 komaj doseže 0.35 (nedavni generativni ŽANR daje 0.26) na najtršem delu. Vsi sistemi nasičijo svoje rezultate na redkih entitetah z dolgim repom in se spopadejo tudi z pogostejšimi entitetami. Glavni izziv je formuliran kot "tisto, zaradi česar je naloga zahtevna, je kombinacija dvoumnosti in nenavadnosti”. Avtorjem priporočam, da naložijo nabor podatkov v Nabori podatkov HuggingFace povečati prepoznavnost njihovega kul projekta
Avtorji se lotevajo tega problema in predstavljajo nov nabor podatkov, ShadowLink, za merjenje stopnje zmedenosti sodobnih EL sistemov. Izkazalo se je, da najvišja ocena F1 komaj doseže 0.35 (nedavni generativni ŽANR daje 0.26) na najtršem delu. Vsi sistemi nasičijo svoje rezultate na redkih entitetah z dolgim repom in se spopadejo tudi z pogostejšimi entitetami. Glavni izziv je formuliran kot "tisto, zaradi česar je naloga zahtevna, je kombinacija dvoumnosti in nenavadnosti”. Avtorjem priporočam, da naložijo nabor podatkov v Nabori podatkov HuggingFace povečati prepoznavnost njihovega kul projekta  .
.
Arora idr pristopite k problemu povezovanja entitet iz druge smeri. Glavna ideja je, da Res imenovan subjekti v dokumentu (obdelano skupaj, ne posamezno) span nizkega ranga podprostor  v prostoru vseh entitet, vključno s kandidati (preverite vizualni primer spodaj). The Eingenthemes pristop je nenadzorovan, če imate vnaprej usposobljene vdelave entitet — avtorji uporabljajo DeepWalk nad angleško podmnožico Wikipodatkov (alternativno poskusijo z vdelavami besed, vendar ne deluje tako dobro).
v prostoru vseh entitet, vključno s kandidati (preverite vizualni primer spodaj). The Eingenthemes pristop je nenadzorovan, če imate vnaprej usposobljene vdelave entitet — avtorji uporabljajo DeepWalk nad angleško podmnožico Wikipodatkov (alternativno poskusijo z vdelavami besed, vendar ne deluje tako dobro).

Konceptualno podoben problem konfliktov na podlagi entitet preučuje Longpre et al, in sicer zamenjava znanja – če pravo entiteto v odstavku obrnete v naključno (ali protislovno), ali bi model spremenil odgovor? Z drugimi besedami, ali bi se modeli zagotavljanja kakovosti zanašali na branje konteksta ali zapomnitev znanja? Izkazalo se je, da lahko pri usposabljanju QA modelov s takšnimi zamenjavami povečate generalizacijo OOD z dobro mejo!
Za konec si oglejte anketo o Tedeschi et al on »NER za povezovanje entitet: kaj deluje in kaj je naslednje«. Avtorji identificirajo ključne izzive EL in poskušajo obravnavati tiste, ki so pomembni za NER NER4EL katerega namen je zmanjšati vrzel v zmogljivosti med velikimi vnaprej usposobljenimi LM in manjšimi modeli, kar je še posebej pomembno v scenarijih z nizkimi viri .

KG Gradbeništvo
Tukaj mi ni uspelo najti privlačne vrstice :/ Če se ukvarjate z OpenIE in KG Construction, so naslednji članki morda pomembni.
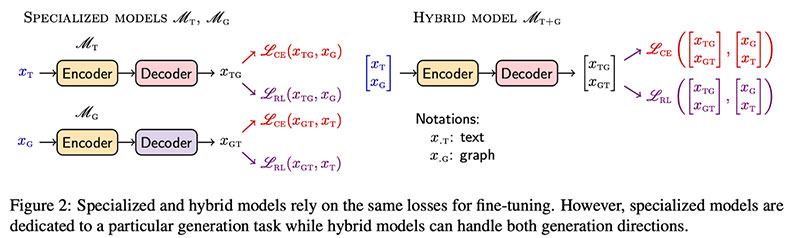
Dognin idr predlaga ReGen, pristop za natančno nastavitev LM-jev za izvajanje nalog Text2Graph in Graph2Text (ali natančno nastavitev specializiranih modelov). Ključna sestavina  dodaja izgubo RL (Self-Critical Sequence Training) poleg standardne navzkrižne entropije (CE). Z lahkoto ga je mogoče dodati kateremu koli vnaprej usposobljenemu LM - avtorji ga preizkusijo s T5-Large (770M paramov) in T5-base (220M paramov).
dodaja izgubo RL (Self-Critical Sequence Training) poleg standardne navzkrižne entropije (CE). Z lahkoto ga je mogoče dodati kateremu koli vnaprej usposobljenemu LM - avtorji ga preizkusijo s T5-Large (770M paramov) in T5-base (220M paramov).  Eksperimentalno, ReGen znatno izboljša osnovne črte Text2Graph WebNLG (3–10 abs. točk, odvisno od metrike) in deluje na veliko večja Nabor podatkov TekGen (6M vadbenih parov).
Eksperimentalno, ReGen znatno izboljša osnovne črte Text2Graph WebNLG (3–10 abs. točk, odvisno od metrike) in deluje na veliko večja Nabor podatkov TekGen (6M vadbenih parov).
Dash et al preučiti kanonikalizacija problem v OpenIE — ko entitete z različnimi površinskimi oblikami, kot so (NYC, New York City) nanašajo na isti prototip. Na nenadzorovan način želimo, da sistemi IE samodejno združijo te omembe skupaj. metoda, BOBEN, uporablja variacijske samodejne kodirnike (VAE) za identifikacijo grozdov (entitete in relacije so parametrirane z Gaussovi). Poleg standarda za VAE izguba obnove, CUVA zaposluje dodatne napoved povezave off temelji na funkciji točkovanja lukenj.  Poleg tega avtorja uvajata roman CanonicNELL nabor podatkov!
Poleg tega avtorja uvajata roman CanonicNELL nabor podatkov!

KG Odgovor na vprašanje: Dodajte nekaj SPARQL
Poizvedbe po bazi podatkov SPARQLing iz vmesnih dekompozicij vprašanj by Irina Saparina in Anton Osokin
V domeni *CL žal ni toliko aplikacij SPARQL. Mislim, da si zasluži veliko širšo sprejetost v NLP. Ko ga podpira kul aplikacija — sem za  .
.
Večina strukturiranih naborov podatkov QA ali tistih, ki uporabljajo semantično razčlenjevanje, ciljajo na SQL kot glavni izhodni format. Ali obstaja življenje onkraj cevovodov SQL?
Saparina in Osokina predlagajte nov pogled na to težavo tako, da 1⃣ najprej uporabite a Predstavitev pomena razčlenitve vprašanja (QDMR) okvir, ki prevede vprašanje v logično obliko, neodvisno od sintakse; 2⃣ ta obrazec je mogoče prevesti v kateri koli strukturiran format in tukaj se avtorji zatečejo k SPARQL, ki kaže, da je veliko lažje poizvedovati po bazah podatkov v formatu grafa. Zahteva preoblikovanje vhodne tabele v RDF, vendar za nize podatkov Spider obsega je to mogoče narediti zelo enostavno.
Moduli, ki jih je mogoče učiti, vključujejo RAT transformator kodirnik z dekoderjem LSTM, ki proizvaja žetone QDMR. QDMR -> SPARQL je ravna transpilacija, ki temelji na nekaj pravilih. Rezultati v primerjavi s SOTA; koda je na voljo ; SPARQL deluje bolje kot SQL;
Rezultati v primerjavi s SOTA; koda je na voljo ; SPARQL deluje bolje kot SQL;
kaj še rabiš za dober papir?

Še eno razburljivo delo »Razmišljanje na podlagi primerov za poizvedbe v naravnem jeziku prek baz znanja« Dasa et al. združuje SPARQL z sklepanje na podlagi primerov (CBR). CBR ima globoke korenine v ekspertnih sistemih že v 80-ih letih prejšnjega stoletja, vendar je bil nedavno oživljen z močjo predstavitvenega učenja. Razlaga TLDR za CBR leta 2021: konceptualno je blizu posplošitvi kompozicije, tj. ko si ogledate nekaj osnovnih primerov, lahko sestavite bolj zapleteno poizvedbo o prej nevidenih entitetah.
Oglejte si spodnji primer. Imamo vnosno poizvedbo "Kdo je brat in sestra Gimlijevega očeta v Hobitu?". V podatkih o usposabljanju morda nimamo ničesar o Gimliju ali Hobitu, lahko pa imamo "relativno podobno" primeri nad odnosi, ki bi se nam lahko zdeli koristni za našo poizvedbo, npr. "Kdo je oče Charlieja Sheena?" z relacijo Freebase people.person_parents in "Kdo so Rihannini bratje in sestre?" z razmerjem people.person.sibling_s . Ko jih sestavimo za naše vprašanje, sestavimo poizvedbo SPARQL v bazo podatkov.
Predlagani CBR-KBQA pristop združuje 1⃣ nevronskega prenašalca, ki ga je mogoče učiti, v slogu DPR (nadzor temelji na prekrivajočih se odnosih), 2⃣ linearni transformator (uporabljajo BigBird), saj so povezana ustrezna vprašanja in poizvedbe precej dolga, 3⃣ več mehanizmov za ponovno razvrščanje za čiščenje napovedi. Uporabljajo že pripravljene module NER in Entity Linking ter uporabljajo tudi vnaprej usposobljene vdelave odnosov TransE za ponovno razvrščanje. CBR-KBQA dokazuje impresivno zmogljivost na več naborih podatkov KBQA, vključno z CFQ. Majhna opomba: nekoliko dvomim, da je najboljši razpoložljivi model SOTA (67.3 MCD-Mean) boljši od takšne marže na 78.1 in ni predložen v merilo uspešnosti, tudi koda še ni na voljo.

Shi et al preučiti zagotavljanje kakovosti z več skoki in predlagati integracijo ID-jev entitet/relacije (obrazec oznake) in njihovih opisov v naravnem jeziku (oblika besedila) v njihov okvir za širjenje sporočil TransferNet. Vrednotenje poteka na standardnih zbirkah podatkov MetaQA, WebQuestionsSP in kompleksnih spletnih vprašanj.
V isti nalogi (isti nabori podatkov kot v prejšnjem delu), Oliya idr opazil, da večina modelov SOTA QA zahteva besedilne razpone, ki so že povezani z entitetami KG, in poskušal to zahtevo zaobiti z dinamičnim ponovnim razvrščanjem entitet z uporabo funkcij soseščine vozlišč entitet KG in funkcij besedilnih razponov.
To so vsi ljudje
Povejte mi, če vam je všeč ta krajši "premum"  oblika boljša od dolgih sten besedila kot v prejšnjih ocenah! Hvala, ker ste vložili svoj čas tukaj, upam, da ste domov odnesli kaj koristnega
oblika boljša od dolgih sten besedila kot v prejšnjih ocenah! Hvala, ker ste vložili svoj čas tukaj, upam, da ste domov odnesli kaj koristnega

Ta članek je bil prvotno objavljen na srednje in z dovoljenjem avtorja ponovno objavljen v TOPBOTS.
Uživate v tem članku? Prijavite se za več posodobitev AI.
Obvestili vas bomo, ko bomo izdali več tehničnega izobraževanja.
Pošta Grafi znanja na EMNLP 2021 pojavil prvi na TOPBOTI.
- '
- "
- 10
- 11
- 2021
- 67
- 7
- 9
- a
- O meni
- obilje
- Po
- Ukrep
- dodano
- Poleg tega
- Naslov
- uprava
- Sprejetje
- AI
- ai raziskave
- Usmerjanje
- vsi
- že
- Dvoumnost
- analitika
- Še ena
- odgovor
- uporaba
- aplikacije
- uporabna
- Uporaba
- pristop
- članek
- Avtorji
- samodejno
- Na voljo
- ozadje
- Košarka
- spodaj
- merilo
- BEST
- med
- Poleg
- največji
- Bit
- Block
- poslovni
- klic
- kandidati
- primeru
- primeri
- izziv
- izzivi
- izziv
- spremenite
- mesto
- Razvrstitev
- Koda
- kombinacija
- kako
- Skupno
- skupnost
- kompleksna
- deli
- Konferenca
- zmeda
- Gradbeništvo
- vsebina
- bi
- Kultura
- stranka
- Pomoč strankam
- datum
- Baze podatkov
- baze podatkov
- globoko
- izkazati
- Odvisno
- opisati
- DID
- drugačen
- Ne
- domena
- dinamično
- vsak
- enostavno
- Izobraževanje
- izobraževalne
- prizadevanje
- zaposluje
- Angleščina
- subjekti
- entiteta
- zlasti
- v bistvu
- Ocena
- Event
- Primer
- Primeri
- zanimivo
- obstoječih
- pričakovati
- strokovnjak
- družine
- družina
- Lastnosti
- končno
- financiranje
- prva
- Osredotočite
- po
- obrazec
- format
- Obrazci
- Okvirni
- iz
- funkcija
- vrzel
- generacija
- generativno
- GitHub
- Cilj
- dobro
- veliko
- srečna
- ob
- višina
- tukaj
- Domov
- upam,
- Kako
- Kako
- hr
- HTTPS
- Človeštvo
- Ideja
- identificirati
- Pomembno
- Impresivno
- V drugi
- Vključno
- Povečajte
- vhod
- primer
- integrirati
- vlaganjem
- IT
- sam
- Job
- Ključne
- Vedite
- znanje
- znano
- label
- jezik
- velika
- učenje
- Pravne informacije
- vrstica
- povezovanje
- London
- Long
- Poglej
- Večina
- Znamka
- IZDELA
- upravljanje
- upravlja
- Način
- Trženje
- Material
- kar pomeni,
- merjenje
- srednje
- Spomin
- omenja
- morda
- Model
- modeli
- več
- Najbolj
- Najbolj popularni
- in sicer
- Imena
- naravna
- potrebe
- NY
- New York City
- Pojem
- NYC
- Ontario
- operacije
- Organizirano
- Ostalo
- Papir
- del
- zlasti
- performance
- oseba
- prosim
- točke
- Popular
- Priljubljenost
- Prispevkov
- moč
- Napovedi
- Premium
- precej
- prejšnja
- problem
- proizvodnjo
- Izdelek
- Projekt
- ugledni
- predlaga
- vprašanje
- Bralec
- reading
- nedavno
- Pred kratkim
- Priporočamo
- zmanjša
- Zmanjšana
- zmanjšanje
- Odnosi
- sprostitev
- pomembno
- zanesljiv
- ostanki
- Poročila
- zastopanje
- zahteva
- Raziskave
- Resort
- Rezultati
- pravila
- prodaja
- Enako
- Lestvica
- točkovanje
- več
- Shadow
- Kratke Hlače
- podpisati
- pomemben
- majhna
- So
- nekaj
- Nekaj
- Vesolje
- specializirani
- standardna
- Država
- statistika
- strukturirano
- študija
- predložen
- nadzor
- podpora
- Podprti
- Površina
- Anketa
- sistem
- sistemi
- ciljna
- Naloge
- tehnični
- predloge
- O
- svet
- čas
- danes
- skupaj
- Boni
- temo
- usposabljanje
- preoblikovanje
- Potovanje
- Uk
- edinstven
- posodobitve
- uporaba
- različnih
- vidljivost
- W
- web
- Tedenski
- Kaj
- WHO
- širše
- besede
- delo
- deluje
- svet
- bi
- leto
- Vaša rutina za




