Učenje podatkovne znanosti in strojno učenje: prvi koraki
Samo vstop v učenje znanosti o podatkih se morda zdi tako zastrašujoč kot (če ne več kot) poskus iskanja prve zaposlitve na tem področju. S toliko možnostmi in viri na spletu in v tradicionalnih akademskih krogih, ki jih je treba upoštevati, priporočamo te predpogoje in pripravo, preden se poglobite v podatkovno znanost in AI/ML.
By Harshit Tyagi, inštruktor znanosti o podatkih | Mentor | YouTuber.

vir: https://www.wiplane.com/p/foundations-for-data-science-ml
V začetku tega leta sem objavil miselni zemljevid na Učni načrt podatkovne znanosti (prikazan spodaj). Načrt je bil široko sprejet, ta članek je bil preveden v različne jezike in veliko ljudi se mi je zahvalilo za objavo.
Vse je bilo dobro, dokler nekaj kandidatov ni opozorilo, da je virov preveč in da so številni med njimi dragi. Programiranje v Pythonu je bilo edina veja, ki je imela številne res dobre tečaje, vendar se za začetnike tu konča.
Zadelo se mi je nekaj pomembnih vprašanj o temeljni znanosti o podatkih:
- Kaj storiti, potem ko se nauči kodirati? Ali obstajajo teme, ki vam pomagajo okrepiti temelje podatkovne znanosti?
- Sovražim matematiko in obstajajo zelo osnovne vaje ali pregloboke zame. Ali lahko priporočite kompakten, a obsežen tečaj matematike in statistike?
- Koliko matematike je dovolj, da se začnete učiti, kako delujejo algoritmi ML?
- Katere so nekatere bistvene statistične teme za začetek analize podatkov ali znanosti o podatkih?
Odgovore na veliko teh vprašanj najdete v knjigi Globoko učenje avtorja Ian Goodfellow in Yoshua Bengio. Toda ta knjiga je za mnoge preveč tehnična in matematična.
Tukaj je torej bistvo tega članka, prvi koraki k učenju podatkovne znanosti ali ML.
Trije stebri podatkovne znanosti in strojnega učenja

vir: https://wiplane.com
Če pregledate predpogoje ali pripravo katerega koli tečaja ML/DS, boste našli kombinacijo programiranja, matematike in statistike.
Za zdaj pozabite na druge, to je tisto Google priporoča ki jih naredite pred tečajem ML:

https://developers.google.com/machine-learning/crash-course/prereqs-and-prework (CC BY 4.0)
1. Bistveno programiranje
Večina podatkovnih vlog temelji na programiranju, razen nekaj vlog, kot so poslovna inteligenca, analiza trga, analitik izdelkov itd.
Osredotočil se bom na delovna mesta s tehničnimi podatki, ki zahtevajo strokovno znanje vsaj enega programskega jezika. Osebno imam Python raje pred katerim koli drugim jezikom zaradi njegove vsestranskosti in enostavnosti učenja – kar je dobra izbira za razvoj projektov od konca do konca.
Kratek vpogled v teme/knjižnice, ki jih morate obvladati za podatkovno znanost:
- Pogoste podatkovne strukture (podatkovni tipi, seznami, slovarji, nizi, tuple), zapisovalne funkcije, logika, kontrolni tok, algoritmi iskanja in razvrščanja, objektno orientirano programiranje in delo z zunanjimi knjižnicami.
- Pisanje skriptov python za ekstrahiranje, formatiranje in shranjevanje podatkov v datoteke ali nazaj v zbirke podatkov.
- Upravljanje z večdimenzionalnimi nizi, indeksiranje, rezanje, prenos, oddajanje in generiranje psevdonaključnih števil z uporabo NumPy.
- Izvajanje vektoriziranih operacij z uporabo znanstvenih računalniških knjižnic, kot je NumPy.
- Manipulirajte s podatki s Pandas— serije, podatkovni okvir, indeksiranje v podatkovnem okvirju, primerjalni operaterji, združevanje podatkovnih okvirov, preslikava in uporaba funkcij.
- Prerekanje podatkov z uporabo Pand— preverjanje ničelnih vrednosti, imputiranje, združevanje podatkov, njihovo opisovanje, izvajanje raziskovalne analize itd.
- Vizualizacija podatkov z uporabo Matplotliba— hierarhija API-ja, dodajanje slogov, barv in oznak na risbo, poznavanje različnih grafov in kdaj jih uporabiti, črtni risbi, palični ploskvi, razpršeni ploskvi, histogrami, škatlasti ploskvi in seaborn za naprednejše izrisovanje.
2. Bistvena matematika
obstajajo praktičnih razlogov, zakaj je matematika bistvena za ljudi, ki želijo kariero strokovnjaka za strojno učenje, podatkovnega znanstvenika ali inženirja globokega učenja.
#1 Linearna algebra za predstavitev podatkov
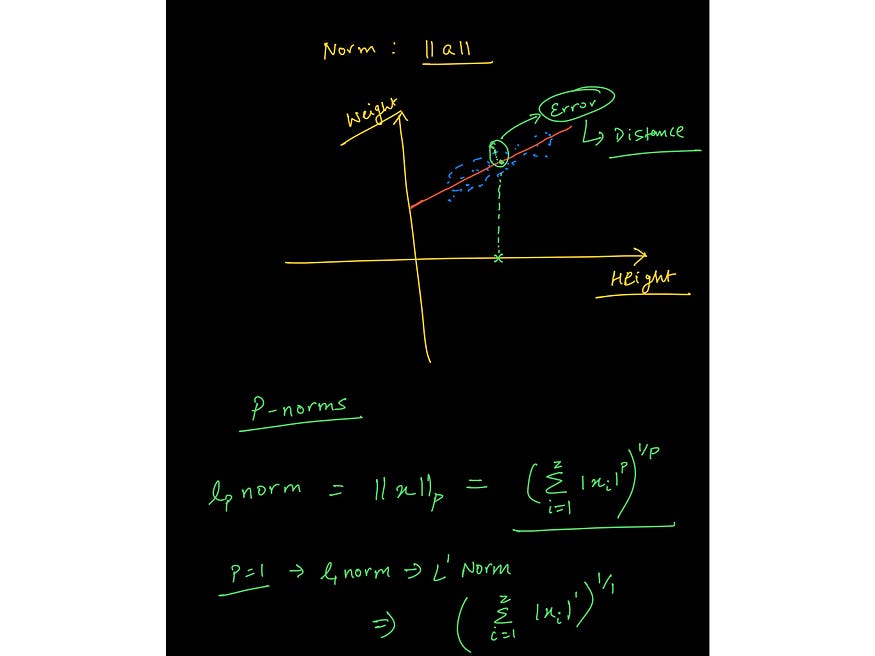
Slika iz predavanja Vektorske norme iz predmeta: https://www.wiplane.com/p/foundations-for-data-science-ml
ML sam po sebi temelji na podatkih, ker so podatki v središču strojnega učenja. Podatke si lahko predstavljamo kot vektorji — predmet, ki se drži aritmetičnih pravil. To nas vodi do razumevanja, kako pravila linearne algebre delujejo nad nizi podatkov.
#2 Račun za usposabljanje modelov ML

Slika iz predavanja o gradientnem spustu iz predmeta: https://www.wiplane.com/p/foundations-for-data-science-ml
Če imate vtis, da se usposabljanje modela zgodi "samodejno", potem se motite. Računstvo je tisto, kar spodbuja učenje večine algoritmov ML in DL.
Eden najpogosteje uporabljenih optimizacijskih algoritmov –gradientni spust— je uporaba delnih izpeljank.
Model je matematična predstavitev določenih prepričanj in predpostavk. Rečeno je, da se nauči (približno) postopka (linearnega, polinomskega itd.) tega, kako so bili podatki zagotovljeni, sploh ustvarjenega, in nato naredi napovedi na podlagi tega naučenega procesa.
Pomembne teme vključujejo:
- Osnovna algebra — spremenljivke, koeficienti, enačbe ter linearne, eksponentne, logaritemske funkcije itd.
- Linearna algebra — skalarji, vektorji, tenzorji, norme (L1 in L2), pikčasti produkt, vrste matrik, linearna transformacija, predstavitev linearnih enačb v matričnem zapisu, reševanje problema linearne regresije z vektorji in matrikami.
- Račun — odvodi in meje, pravila odvajanja, verižno pravilo (za algoritem širjenja nazaj), delni odvodi (za izračun gradientov), konveksnost funkcij, lokalni/globalni minimumi, matematika za regresijskim modelom, uporabna matematika za usposabljanje modela iz nič .
#3 Bistvena statistika
Vsaka današnja organizacija si prizadeva postati podatkovno vodena. Da bi to dosegli, morajo analitiki in znanstveniki uporabiti prodajne podatke na različne načine, da bi spodbudili odločanje.
Opisovanje podatkov — od podatkov do vpogledov
Podatki so vedno surovi in grdi. Začetno raziskovanje vam pove, kaj manjka, kako so podatki porazdeljeni in kakšen je najboljši način za njihovo čiščenje, da dosežete končni cilj.
Da bi odgovorili na definirana vprašanja, vam deskriptivna statistika omogoča, da vsako opazovanje v svojih podatkih pretvorite v smiselne vpoglede.
Kvantificiranje negotovosti
Poleg tega je sposobnost kvantificiranja negotovosti najdragocenejša veščina, ki je zelo cenjena v vsakem podatkovnem podjetju. Poznavanje možnosti za uspeh v katerem koli poskusu/odločitvi je zelo pomembno za vsa podjetja.
Tukaj je nekaj glavnih sponk statistike, ki predstavljajo najmanjši minimum:

Slika s predavanja o Poissonovi porazdelitvi — https://www.wiplane.com/p/foundations-for-data-science-ml
- Ocene lokacije — povprečje, mediana in druge njihove različice.
- Ocene variabilnosti
- Korelacija in kovarianca
- Naključne spremenljivke — diskretne in zvezne
- Distribucija podatkov— PMF, PDF, CDF
- Pogojna verjetnost — Bayesova statistika
- Običajno uporabljene statistične porazdelitve — Gaussova, binomska, Poissonova, eksponentna
- Pomembni izreki — Zakon velikih števil in Centralni mejni izrek.

Slika s predavanja o Poissonovi porazdelitvi — https://www.wiplane.com/p/foundations-for-data-science-ml
- Referenčna statistika - Bolj praktična in napredna veja statistike, ki pomaga pri načrtovanju eksperimentov za preizkušanje hipotez, nas spodbuja, da poglobljeno razumemo pomen meritev in nam hkrati pomaga kvantificirati pomembnost rezultatov.
- Pomembni testi - Studentov t-test, hi-kvadrat test, ANOVA test itd.
Vsak začetni navdušenec nad podatkovno znanostjo bi se moral osredotočiti na te tri stebre, preden se poglobi v kateri koli osnovni tečaj podatkovne znanosti ali osnovnega tečaja strojnega učenja.
Viri za učenje zgoraj navedenega — v iskanju kompaktnega, celovitega, a cenovno dostopnega tečaja

https://www.freecodecamp.org/news/data-science-learning-roadmap/
Moj učni načrt vam je tudi povedal, kaj se morate naučiti, poleg tega pa je bil poln virov, tečajev in programov, v katere se lahko vpišete sami.
Toda v priporočenih virih in načrtu, ki sem ga začrtal, je nekaj nedoslednosti.
Težave s tečaji Data Science ali ML
- Vsak tečaj podatkovne znanosti, ki sem ga tam vpisal, je od študentov zahteval dostojno razumevanje programiranja, matematike ali statistike. na primer najbolj znan tečaj o strojnem jeziku Andrewa Nga se močno opira tudi na razumevanje vektorske algebre in računa.
- Večina tečajev, ki pokrivajo matematiko in statistiko za podatkovno znanost, je le kontrolni seznam konceptov, potrebnih za DS/ML, brez razlage, kako se uporabljajo in kako so programirani v stroj.
- Obstajajo izjemni viri, s katerimi se lahko poglobite v matematiko, vendar večina od nas ni ustvarjena za to in ni treba biti dobitnik zlate medalje, da se naučite znanosti o podatkih.
Bottom line: Manjka vir, ki bi pokrival ravno toliko uporabne matematike, statistike ali programiranja, da bi lahko začeli z znanostjo o podatkih ali strojnim učenjem.
Akademija Wiplane — wiplane.com
Tako sem se odločil, da bom popustil in vse naredil sam. Zadnje 3 mesece sem razvijal učni načrt, ki bo zagotovil trdne temelje za vašo kariero kot ...
- Analitik podatkov
- Data Scientist
- Ali praktik/inženir ML
Tukaj vam predstavljam Osnove podatkovne znanosti ali ML - Prvi koraki za učenje podatkovne znanosti in strojnega učenja

Takrat sem se odločil za lansiranje!
Obsežen, a kompakten in cenovno dostopen tečaj, ki ne zajema le vse bistvene stvari, predpogoji in preddelo ampak tudi pojasnjuje, kako se vsak koncept uporablja računalniško in programsko (Python).
In to še ni vse. Vsebino tečaja bom vsak mesec posodabljal na podlagi vaših prispevkov. Nauči se več tukaj.
Zgodnja ponudba!
Vesel sem, da lahko začnem s predprodajo tega tečaja, saj sem trenutno v procesu snemanja in urejanja zadnjih delov 2–3 modulov, ki bodo prav tako objavljeni v prvem tednu septembra.
Izkoristite zgodnjo ponudbo, ki velja le do 30. avgusta 2021.
prvotni. Poročeno z dovoljenjem.
Bio: Harshit Tyagi je inženir z združenimi izkušnjami na področju spletnih tehnologij in podatkovne znanosti (tudi full-stack data science), ki je bil mentor več kot 1000 kandidatom za AI/Web/Data Science, medtem ko je oblikoval podatkovno znanost in inženirske učne poti ML. Pred tem je Harshit razvil algoritme za obdelavo podatkov z raziskovalci na Yalu, MIT in UCLA.
Povezano:
Vir: https://www.kdnuggets.com/2021/08/learn-data-science-machine-learning.html
- "
- &
- 2021
- AI
- algoritem
- algoritmi
- vsi
- Analiza
- Analitik
- API
- uporaba
- članek
- Avgust
- BEST
- ptica
- Bit
- poslovni
- Poslovna inteligenca
- podjetja
- Kariera
- kvote
- preverjanje
- Koda
- Skupno
- podjetje
- Izračunajte
- računalništvo
- vsebina
- datum
- Analiza podatkov
- obdelava podatkov
- znanost o podatkih
- podatkovni znanstvenik
- baze podatkov
- Odločanje
- globoko učenje
- Izvedeni finančni instrumenti
- Razvojni
- Direktor
- Zgodnje
- konča
- inženir
- Inženiring
- Osnove
- itd
- izkušnje
- raziskovanje
- prva
- Pretok
- Osredotočite
- format
- Gold
- dobro
- Grafične kartice
- tukaj
- Kako
- Kako
- HTTPS
- slika
- vpogledi
- Intelligence
- Intervju
- IT
- Job
- Delovna mesta
- znanje
- jezik
- jeziki
- velika
- kosilo
- zakon
- UČITE
- naučili
- učenje
- vrstica
- seznami
- kraj aktivnosti
- strojno učenje
- Izdelava
- map
- Tržna
- Analiza trga
- math
- srednje
- Meritve
- MIT
- ML
- ML algoritmi
- Model
- mesecev
- Naravni jezik
- Obdelava Natural Language
- Nevronski
- nlp
- številke
- ponudba
- na spletu
- odprite
- open source
- operacije
- možnosti
- Da
- Ostalo
- drugi
- Napovedi
- predstaviti
- Izdelek
- Programiranje
- programi
- projekti
- Založništvo
- Python
- Surovi
- Razlogi
- regresija
- Raziskave
- vir
- viri
- Rezultati
- pravila
- Znanost
- Znanstveniki
- Iskalnik
- Občutek
- Serija
- So
- Začetek
- začel
- Statistika
- trgovina
- zgodbe
- uspeh
- tehnični
- Tehnologije
- pove
- Test
- Testiranje
- čas
- vrh
- Teme
- usposabljanje
- Preoblikovanje
- vaje
- UCLA
- us
- vizualizacija
- web
- teden
- WHO
- delo
- pisanje
- X
- leto
- youtube