Naredite Pande 3-krat hitrejše s PyPolarji
Naučite se, kako pospešiti potek dela Pandas s knjižnico PyPolars.
By Satyam Kumar, navdušenec in programer strojnega učenja

Foto: Tim Gouw on Unsplash
Pandas je eden najpomembnejših paketov Python med podatkovnimi znanstveniki za igranje s podatki. Knjižnica Pandas se večinoma uporablja za raziskovanje podatkov in vizualizacije, saj ima ogromno vgrajenih funkcij. Pandas ne uspe obdelati podatkovnih nizov velike velikosti, ker ne prilagaja ali porazdeli svojega procesa po vseh jedrih CPE.
Če želite pospešiti izračune, lahko uporabite vsa jedra CPE in pospešite potek dela. Obstajajo različne odprtokodne knjižnice, vključno z Dask, Vaex, Modin, Pandarallel, PyPolars itd., ki vzporedno izvajajo izračune v več jedrih CPE. V tem članku bomo razpravljali o implementaciji in uporabi knjižnice PyPolars ter primerjali njeno delovanje s knjižnico Pandas.
Kaj je PyPolars?
PyPolars je odprtokodna knjižnica podatkovnih okvirov Python, podobna Pandas. PyPolars uporablja vsa razpoložljiva jedra CPU in zato izvaja izračune hitreje kot Pandas. PyPolars ima API, podoben API-ju Pandas. Napisano je v rji z ovoji Python.
V idealnem primeru se PyPolars uporablja, ko so podatki preveliki za Pandas in premajhni za Spark
Kako deluje PyPolars?
Knjižnica PyPolars ima dva API-ja, eden je Eager API, drugi pa Lazy API. API Eager je zelo podoben API-ju Pandas, rezultati pa se ustvarijo takoj po zaključku izvajanja, podobno kot Pandas. Lazy API je zelo podoben Sparku, kjer se zemljevid ali načrt oblikuje ob izvedbi poizvedbe. Nato se izvedba izvede vzporedno v vseh jedrih CPE.

(Slika avtorja), API-ji PyPolars
PyPolars je v bistvu vezava pythona na knjižnico Polars. Najboljši del knjižnice PyPolars je podobnost API-ja s programom Pandas, kar razvijalcem olajša delo.
namestitev:
PyPolars lahko namestite iz PyPl z naslednjim ukazom:
pip install py-polarsin uvozite knjižnico z uporabo
import pypolars as plPrimerjalne časovne omejitve:
Za predstavitve sem uporabil nabor podatkov velike velikosti (~6.4 Gb), ki ima 25 milijonov primerkov.

(Slika avtorja), merilno časovno število za osnovne operacije Pandas in Py-Polars
Za zgornje referenčne časovne številke za nekatere osnovne operacije z uporabo Pandas in knjižnice PyPolars lahko opazimo, da je PyPolars skoraj 2x do 3x hitrejši od Pandas.
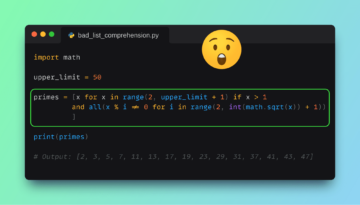
Zdaj vemo, da ima PyPolars API, ki je zelo podoben API-ju Pandas, vendar še vedno ne pokriva vseh funkcij Pandas. Na primer, nimamo .describe() namesto tega lahko uporabimo funkcijo v PyPolars df_pypolars.to_pandas().describe()
Uporaba:
(Koda avtorja)
ugotovitev:
V tem članku smo predstavili majhen uvod v knjižnico PyPolars, vključno z njeno implementacijo, uporabo in primerjavo njenih referenčnih časovnih številk s Pandami za nekatere osnovne operacije. Upoštevajte, da PyPolars deluje zelo podobno kot Pandas in da je PyPolars pomnilniško učinkovita knjižnica, saj je pomnilnik, ki ga podpira, nespremenljiv.
Lahko gre skozi Dokumentacija da bi podrobno razumeli knjižnico. Obstajajo različne druge odprtokodne knjižnice, ki lahko vzporedijo operacije Pandas in pospešijo proces. Preberi spodaj omenjeni članek poznati 4 take knjižnice:
4 knjižnice, ki lahko vzporedijo obstoječi ekosistem Pandas
Porazdelite delovno obremenitev Pythona z vzporedno obdelavo z uporabo teh ogrodij
Reference:
[1] Dokumentacija Polars in repozitorij GitHub: https://github.com/ritchie46/polars
Hvala za branje
Bio: Satyam Kumar je navdušenec in programer strojnega učenja. Satyam piše o podatkovni znanosti in je najboljši pisec na področju umetne inteligence. Išče zahtevno kariero v organizaciji, ki ponuja priložnost, da izkoristi svoje tehnične spretnosti in sposobnosti.
prvotni. Poročeno z dovoljenjem.
Povezano:
Najboljše zgodbe preteklih 30 dni
Vir: https://www.kdnuggets.com/2021/05/pandas-faster-pypolars.html
- "
- &
- AI
- algoritmi
- vsi
- med
- API
- API-ji
- okoli
- članek
- avto
- merilo
- BEST
- knjige
- Kariera
- kariere
- Koda
- datum
- znanost o podatkih
- podatkovni znanstvenik
- vizualizacija podatkov
- ponudba
- Razvijalci
- inženir
- itd
- izvedba
- GitHub
- vodi
- Kako
- Kako
- HTTPS
- slika
- Vključno
- IT
- velika
- UČITE
- učenje
- Knjižnica
- strojno učenje
- map
- srednje
- Microsoft
- Microsoft Research
- milijonov
- Model
- številke
- operacije
- Priložnost
- Ostalo
- performance
- Proizvedeno
- Python
- reading
- Raziskave
- Rezultati
- Rust
- Lestvica
- Znanost
- Velikosti
- spretnosti
- majhna
- hitrost
- SQL
- Začetek
- zgodbe
- tehnični
- čas
- Tone
- vrh
- vizualizacija
- potek dela
- deluje
- Pisatelj
- X