NLP z več oznakami se nanaša na nalogo dodeljevanja več oznak danemu vnosu besedila namesto le ene oznake. Pri tradicionalnih nalogah NLP, kot je razvrščanje besedila ali analiza razpoloženja, je vsakemu vnosu običajno dodeljena ena oznaka glede na njegovo vsebino. Vendar pa lahko v mnogih scenarijih iz resničnega sveta del besedila pripada več kategorijam ali izraža več čustev hkrati.
NLP z več oznakami je pomemben, ker nam omogoča, da iz besedilnih podatkov zajamemo bolj niansirane in kompleksne informacije. Na primer, na področju analize povratnih informacij strank lahko ocena stranke izraža tako pozitivne kot negativne občutke hkrati ali pa se dotika več vidikov izdelka ali storitve. Z dodelitvijo več oznak takšnim vnosom lahko pridobimo celovitejše razumevanje povratnih informacij strank in sprejmemo bolj ciljno usmerjene ukrepe za obravnavo njihovih skrbi.
Ta članek obravnava omembe vreden primer Provectusove uporabe multi-label NLP.
Kontekst:
Na nas se je obrnila stranka s prošnjo za pomoč avtomatsko označevanje dokumentov določene vrste. Na prvi pogled je bila naloga enostavna in enostavno rešljiva. Vendar smo med delom na primeru naleteli na nabor podatkov z nedoslednimi opombami. Čeprav se je naša stranka sčasoma soočila z izzivi z različnimi številkami razredov in spremembami v svoji skupini za pregledovanje, je vložila veliko truda v ustvarjanje raznolikega nabora podatkov z vrsto opomb. Čeprav je bilo v oznakah nekaj neravnovesij in negotovosti, je ta nabor podatkov zagotovil dragoceno priložnost za analizo in nadaljnje raziskovanje.
Oglejmo si podrobneje nabor podatkov, raziščimo metrike in naš pristop ter povzamemo, kako je Provectus rešil problem klasifikacije besedila z več oznakami.
Nabor podatkov ima 14,354 opazovanj s 124 edinstvenimi razredi (oznakami). Naša naloga je, da vsakemu opazovanju dodelimo enega ali več razredov.
Tabela 1 ponuja opisno statistiko za nabor podatkov.
V povprečju imamo približno dva razreda na opazovanje, s povprečno 261 različnimi besedili, ki opisujejo posamezen razred.

Tabela 1: Statistika nabora podatkov
Na sliki 1 vidimo porazdelitev razredov na zgornjem grafu in imamo določeno število oznak HEAD z največjo pogostostjo pojavljanja v naboru podatkov. Upoštevajte tudi, da ima večina razredov nizko pogostost pojavljanja.
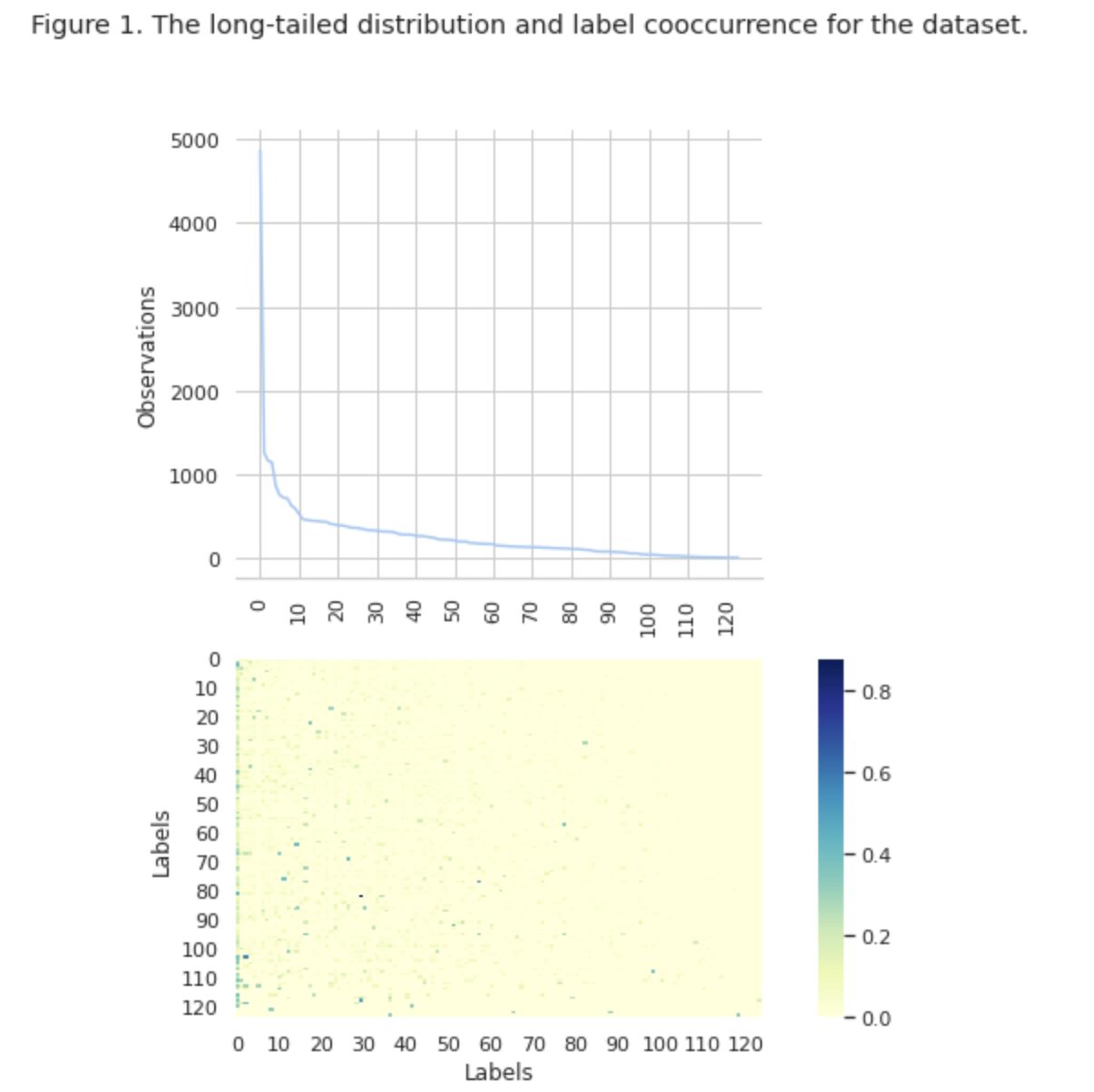
Na spodnjem grafu vidimo, da je pogosto prekrivanje med razredi, ki so najbolje predstavljeni v naboru podatkov, in razredi, ki imajo nizko pomembnost.
Spremenili smo postopek razdelitve nabora podatkov v nabore train/val/test. Namesto tradicionalne metode smo uporabili iterativno stratifikacijo, da bi zagotovili dobro uravnoteženo porazdelitev dokazov o odnosih oznak. Za to smo uporabili Scikit Multi-learn
from skmultilearn.model_selection import iterative_train_test_split mlb = MultiLabelBinarizer() def balanced_split(df, mlb, test_size=0.5): ind = np.expand_dims(np.arange(len(df)), axis=1) mlb.fit_transform(df["tag"]) labels = mlb.transform(df["tag"]) ind_train, _, ind_test, _ = iterative_train_test_split( ind, labels, test_size ) return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]] df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
Dobili smo naslednjo porazdelitev:
- Nabor podatkov za usposabljanje vsebuje 60 % podatkov in zajema vseh 124 oznak
- Nabor validacijskih podatkov vsebuje 20 % podatkov in zajema vseh 124 oznak
- Testni nabor podatkov vsebuje 20 % podatkov in zajema vseh 124 oznak
Klasifikacija z več oznakami je vrsta nadzorovanega algoritma strojnega učenja, ki nam omogoča, da enemu vzorcu podatkov dodelimo več oznak. Razlikuje se od binarne klasifikacije, kjer model napove le dve kategoriji, in večrazredne klasifikacije, kjer model napove le enega od več razredov za vzorec.
Meritve vrednotenja za uspešnost razvrščanja z več oznakami so same po sebi drugačne od tistih, ki se uporabljajo pri razvrščanju po več razredih (ali binarni) zaradi inherentnih razlik problema razvrščanja. Podrobnejše informacije najdete na Wikipediji.
Izbrali smo metrike, ki nam najbolj ustrezajo:
- Precision meri delež resničnih pozitivnih napovedi med skupnimi pozitivnimi napovedmi modela.
- Recall meri delež resničnih pozitivnih napovedi med vsemi dejanskimi pozitivnimi vzorci.
- F1-ocena je harmonično povprečje natančnosti in priklica, ki pomaga vzpostaviti ravnovesje med obema.
- Hammingova izguba je delež oznak, ki so nepravilno predvidene
Tudi sledimo število predvidenih oznak v nizu { definiran kot štetje za oznake, za katere dosežemo rezultat F1 > 0}.
Klasifikacija z več oznakami je vrsta težave z nadzorovanim učenjem, pri kateri je en primerek ali primer mogoče povezati z več oznakami ali klasifikacijami, v nasprotju s tradicionalno klasifikacijo z eno oznako, kjer je vsak primer povezan samo z eno oznako razreda.
Za reševanje problemov klasifikacije z več oznakami obstajata dve glavni kategoriji tehnik:
- Metode transformacije problema
- Metode prilagajanja algoritmov
Metode transformacije problemov nam omogočajo, da naloge klasifikacije z več oznakami pretvorimo v naloge klasifikacije z več oznakami. Na primer, osnovni pristop binarne ustreznosti (BR) obravnava vsako oznako kot ločen problem binarne klasifikacije. V tem primeru se problem z več oznakami spremeni v problem z več oznakami.
Metode prilagajanja algoritmov spremenijo same algoritme, da izvorno obravnavajo podatke z več oznakami, ne da bi opravilo preoblikovali v več nalog razvrščanja z eno oznako. Primer tega pristopa je model BERT, ki je vnaprej usposobljen jezikovni model na osnovi transformatorja, ki ga je mogoče natančno prilagoditi za različne naloge NLP, vključno s klasifikacijo besedila z več oznakami. BERT je zasnovan za neposredno obdelavo podatkov z več oznakami, brez potrebe po preoblikovanju težav.
V kontekstu uporabe BERT za klasifikacijo besedila z več oznakami je standardni pristop uporaba izgube binarne navzkrižne entropije (BCE) kot funkcije izgube. Izguba BCE je pogosto uporabljena funkcija izgube za težave z binarnim razvrščanjem in jo je mogoče enostavno razširiti za obravnavo težav s klasifikacijo z več oznakami tako, da izračunate izgubo za vsako oznako neodvisno in nato seštejete izgube. V tem primeru funkcija izgube BCE meri napako med predvidenimi verjetnostmi in resničnimi oznakami, kjer so predvidene verjetnosti pridobljene iz končne sigmoidne aktivacijske plasti v modelu BERT.
Zdaj pa si podrobneje oglejmo spodnjo sliko 2.
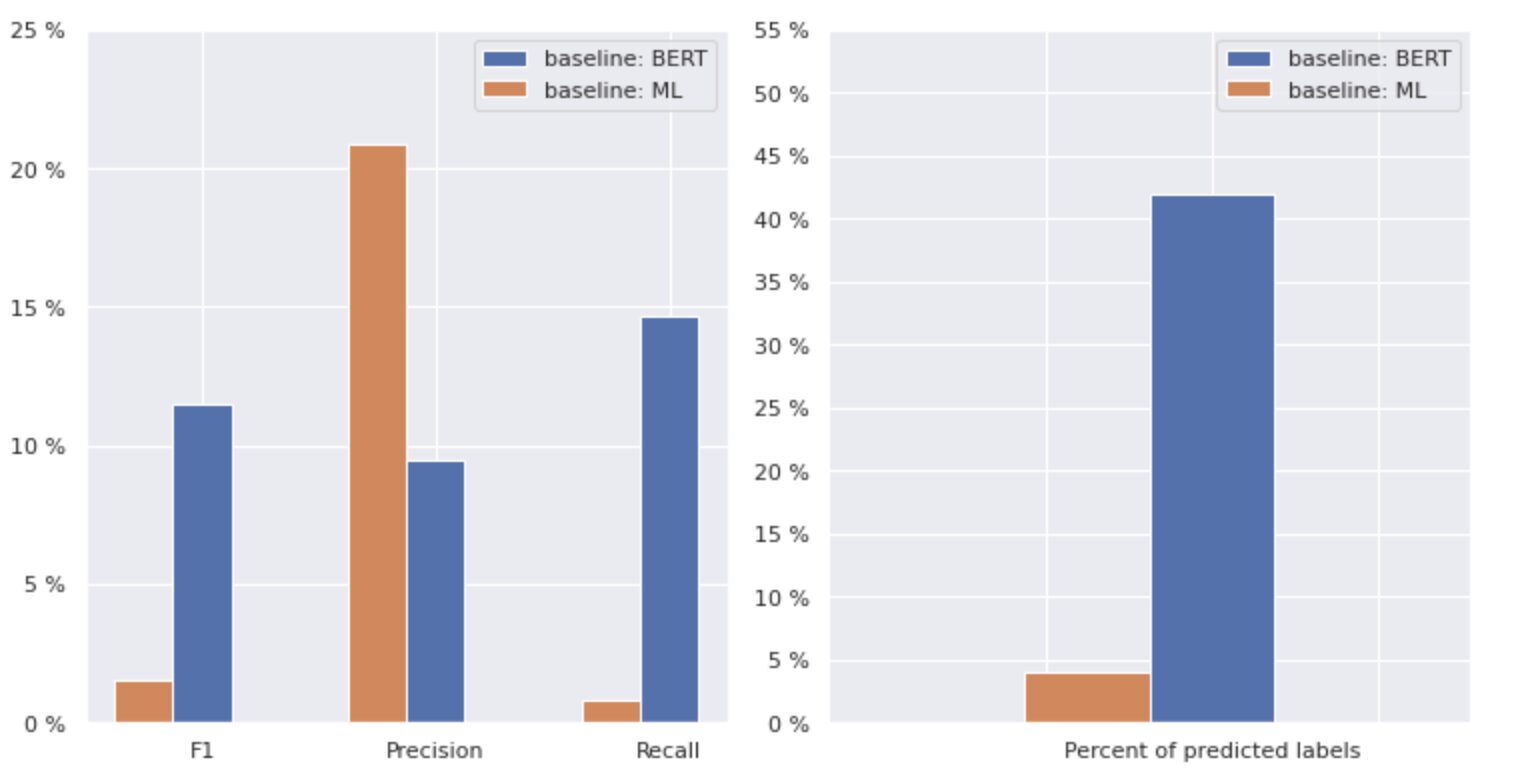
Slika 2. Meritve za osnovne modele
Graf na levi prikazuje primerjavo meritev za »izhodišče: BERT« in »izhodišče: ML«. Tako je razvidno, da sta za »osnovno vrednost: BERT« rezultati F1 in Recall približno 1.5-krat višji, medtem ko je natančnost za »osnovno vrednost: ML« 2-krat višja kot pri modelu 1. Z analizo skupnega odstotka predvidenih razredov, prikazanih na desni, vidimo, da je »osnovna linija: BERT« predvidela razrede več kot 10-krat več kot »osnovna linija: ML«.
Ker je najvišji rezultat za "osnovno vrednost: BERT" manj kot 50 % vseh razredov, so rezultati precej odvračajoči. Ugotovimo, kako izboljšati te rezultate.
Na podlagi izjemnega članka »Metode uravnoteženja za razvrščanje besedila z več oznakami z dolgorepo porazdelitvijo razredov«, smo izvedeli, da je distribucijsko uravnotežena izguba morda najprimernejši pristop za nas.
Distribucijsko uravnotežena izguba
Distribucijsko uravnotežena izguba je tehnika, ki se uporablja pri problemih klasifikacije besedila z več oznakami za odpravljanje neravnovesij v porazdelitvi razredov. Pri teh težavah imajo nekateri razredi veliko večjo pogostost pojavljanja v primerjavi z drugimi, kar povzroči pristranskost modela proti tem pogostejšim razredom.
Da bi rešili to težavo, je namen distribucijsko uravnotežene izgube uravnotežiti prispevek vsakega vzorca v funkciji izgube. To se doseže s ponovnim ponderiranjem izgube vsakega vzorca na podlagi obratne vrednosti njegove pogostosti pojavljanja v naboru podatkov. S tem se poveča prispevek redkejših poukov in zmanjša prispevek pogostejših poukov, s čimer se uravnoteži skupna porazdelitev po razredih.
Ta tehnika se je izkazala za učinkovito pri izboljšanju učinkovitosti modelov pri težavah porazdelitve razredov z dolgim repom. Z zmanjšanjem vpliva pogostih razredov in povečanjem vpliva redkih razredov lahko model bolje zajame vzorce v podatkih in ustvari bolj uravnotežene napovedi.

Implementacija razreda Resample
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np class ResampleLoss(nn.Module): def __init__( self, use_sigmoid=True, partial=False, loss_weight=1.0, reduction="mean", reweight_func=None, weight_norm=None, focal=dict(focal=True, alpha=0.5, gamma=2), map_param=dict(alpha=10.0, beta=0.2, gamma=0.1), CB_loss=dict(CB_beta=0.9, CB_mode="average_w"), logit_reg=dict(neg_scale=5.0, init_bias=0.1), class_freq=None, train_num=None, ): super(ResampleLoss, self).__init__() assert (use_sigmoid is True) or (partial is False) self.use_sigmoid = use_sigmoid self.partial = partial self.loss_weight = loss_weight self.reduction = reduction if self.use_sigmoid: if self.partial: self.cls_criterion = partial_cross_entropy else: self.cls_criterion = binary_cross_entropy else: self.cls_criterion = cross_entropy # reweighting function self.reweight_func = reweight_func # normalization (optional) self.weight_norm = weight_norm # focal loss params self.focal = focal["focal"] self.gamma = focal["gamma"] self.alpha = focal["alpha"] # mapping function params self.map_alpha = map_param["alpha"] self.map_beta = map_param["beta"] self.map_gamma = map_param["gamma"] # CB loss params (optional) self.CB_beta = CB_loss["CB_beta"] self.CB_mode = CB_loss["CB_mode"] self.class_freq = ( torch.from_numpy(np.asarray(class_freq)).float().cuda() ) self.num_classes = self.class_freq.shape[0] self.train_num = train_num # only used to be divided by class_freq # regularization params self.logit_reg = logit_reg self.neg_scale = ( logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0 ) init_bias = ( logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0 ) self.init_bias = ( -torch.log(self.train_num / self.class_freq - 1) * init_bias ) self.freq_inv = ( torch.ones(self.class_freq.shape).cuda() / self.class_freq ) self.propotion_inv = self.train_num / self.class_freq def forward( self, cls_score, label, weight=None, avg_factor=None, reduction_override=None, **kwargs ): assert reduction_override in (None, "none", "mean", "sum") reduction = ( reduction_override if reduction_override else self.reduction ) weight = self.reweight_functions(label) cls_score, weight = self.logit_reg_functions( label.float(), cls_score, weight ) if self.focal: logpt = self.cls_criterion( cls_score.clone(), label, weight=None, reduction="none", avg_factor=avg_factor, ) # pt is sigmoid(logit) for pos or sigmoid(-logit) for neg pt = torch.exp(-logpt) wtloss = self.cls_criterion( cls_score, label.float(), weight=weight, reduction="none" ) alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha) loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss loss = reduce_loss(loss, reduction) else: loss = self.cls_criterion( cls_score, label.float(), weight, reduction=reduction ) loss = self.loss_weight * loss return loss def reweight_functions(self, label): if self.reweight_func is None: return None elif self.reweight_func in ["inv", "sqrt_inv"]: weight = self.RW_weight(label.float()) elif self.reweight_func in "rebalance": weight = self.rebalance_weight(label.float()) elif self.reweight_func in "CB": weight = self.CB_weight(label.float()) else: return None if self.weight_norm is not None: if "by_instance" in self.weight_norm: max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True) weight = weight / max_by_instance elif "by_batch" in self.weight_norm: weight = weight / torch.max(weight) return weight def logit_reg_functions(self, labels, logits, weight=None): if not self.logit_reg: return logits, weight if "init_bias" in self.logit_reg: logits += self.init_bias if "neg_scale" in self.logit_reg: logits = logits * (1 - labels) * self.neg_scale + logits * labels if weight is not None: weight = ( weight / self.neg_scale * (1 - labels) + weight * labels ) return logits, weight def rebalance_weight(self, gt_labels): repeat_rate = torch.sum( gt_labels.float() * self.freq_inv, dim=1, keepdim=True ) pos_weight = ( self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate ) # pos and neg are equally treated weight = ( torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma)) + self.map_alpha ) return weight def CB_weight(self, gt_labels): if "by_class" in self.CB_mode: weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) elif "average_n" in self.CB_mode: avg_n = torch.sum( gt_labels * self.class_freq, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, avg_n)).cuda() ) elif "average_w" in self.CB_mode: weight_ = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) weight = torch.sum( gt_labels * weight_, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) elif "min_n" in self.CB_mode: min_n, _ = torch.min( gt_labels * self.class_freq + (1 - gt_labels) * 100000, dim=1, keepdim=True, ) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, min_n)).cuda() ) else: raise NameError return weight def RW_weight(self, gt_labels, by_class=True): if "sqrt" in self.reweight_func: weight = torch.sqrt(self.propotion_inv) else: weight = self.propotion_inv if not by_class: sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True) weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True) return weight def reduce_loss(loss, reduction): """Reduce loss as specified. Args: loss (Tensor): Elementwise loss tensor. reduction (str): Options are "none", "mean" and "sum". Return: Tensor: Reduced loss tensor. """ reduction_enum = F._Reduction.get_enum(reduction) # none: 0, elementwise_mean:1, sum: 2 if reduction_enum == 0: return loss elif reduction_enum == 1: return loss.mean() elif reduction_enum == 2: return loss.sum() def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None): """Apply element-wise weight and reduce loss. Args: loss (Tensor): Element-wise loss. weight (Tensor): Element-wise weights. reduction (str): Same as built-in losses of PyTorch. avg_factor (float): Avarage factor when computing the mean of losses. Returns: Tensor: Processed loss values. """ # if weight is specified, apply element-wise weight if weight is not None: loss = loss * weight # if avg_factor is not specified, just reduce the loss if avg_factor is None: loss = reduce_loss(loss, reduction) else: # if reduction is mean, then average the loss by avg_factor if reduction == "mean": loss = loss.sum() / avg_factor # if reduction is 'none', then do nothing, otherwise raise an error elif reduction != "none": raise ValueError( 'avg_factor can not be used with reduction="sum"' ) return loss def binary_cross_entropy( pred, label, weight=None, reduction="mean", avg_factor=None
): # weighted element-wise losses if weight is not None: weight = weight.float() loss = F.binary_cross_entropy_with_logits( pred, label.float(), weight, reduction="none" ) loss = weight_reduce_loss( loss, reduction=reduction, avg_factor=avg_factor ) return loss
DBLoss
loss_func = ResampleLoss( reweight_func="rebalance", loss_weight=1.0, focal=dict(focal=True, alpha=0.5, gamma=2), logit_reg=dict(init_bias=0.05, neg_scale=2.0), map_param=dict(alpha=0.1, beta=10.0, gamma=0.405), class_freq=class_freq, train_num=train_num,
) """
class_freq - list of frequencies for each class,
train_num - size of train dataset """
Z natančno preiskavo nabora podatkov smo ugotovili, da parameter
= 0.405.
Nastavitev praga
Še en korak pri izboljšavi našega modela je bil postopek prilagajanja praga, tako v fazi usposabljanja kot v stopnjah validacije in testiranja. Izračunali smo odvisnosti metrik, kot so f1-rezultat, natančnost in priklic, od ravni praga, prag pa smo izbrali na podlagi najvišjega rezultata metrike. Spodaj si lahko ogledate izvajanje funkcije tega procesa.
Optimizacija rezultata F1 s prilagajanjem praga:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray): best_med_th = 0.5 true_bools = [tl == 1 for tl in true_labels] micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th f1_results, pre_results, recall_results = [], [], [] for th in micro_thresholds: pred_bools = [pl > th for pl in pred_labels] test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0) test_precision = precision_score( true_bools, pred_bools, average="micro", zero_division=0 ) test_recall = recall_score( true_bools, pred_bools, average="micro", zero_division=0 ) f1_results.append(test_f1) prec_results.append(test_precision) recall_results.append(test_recall) best_f1_idx = np.argmax(f1_results) return micro_thresholds[best_f1_idx]Vrednotenje in primerjava z izhodiščem
Ti pristopi so nam omogočili usposobiti nov model in pridobiti naslednji rezultat, ki je v primerjavi z izhodiščem: BERT na sliki 3 spodaj.

Slika 3. Primerjalne metrike po izhodišču in novejšem pristopu.
S primerjavo meritev, ki so pomembne za klasifikacijo, opazimo znatno povečanje meritev uspešnosti za skoraj 5-6-krat:
Rezultat F1 se je povečal z 12 % → 55 %, medtem ko se je natančnost povečala z 9 % → 59 %, priklic pa s 15 % → 51 %.
S spremembami, prikazanimi v desnem grafu na sliki 3, lahko zdaj predvidimo 80 % razredov.
Rezine razredov
Naše oznake smo razdelili v štiri skupine: HEAD, MEDIUM, TAIL in ZERO. Vsaka skupina vsebuje oznake s podobno količino podpornih opazovanj podatkov.
Kot je prikazano na sliki 4, so porazdelitve skupin različne. Rožnato polje (HEAD) ima negativno poševno porazdelitev, srednje polje (MEDIUM) ima pozitivno poševno porazdelitev, zeleno polje (REP) pa ima normalno porazdelitev.
Vse skupine imajo tudi izstopajoče vrednosti, ki so točke zunaj brkov v škatlastem prikazu. Skupina HEAD ima velik vpliv na razred MAJOR.
Poleg tega smo identificirali ločeno skupino z imenom »ZERO«, ki vsebuje oznake, ki se jih model ni mogel naučiti in jih ne more prepoznati zaradi minimalnega števila pojavitev v naboru podatkov (manj kot 3 % vseh opazovanj).
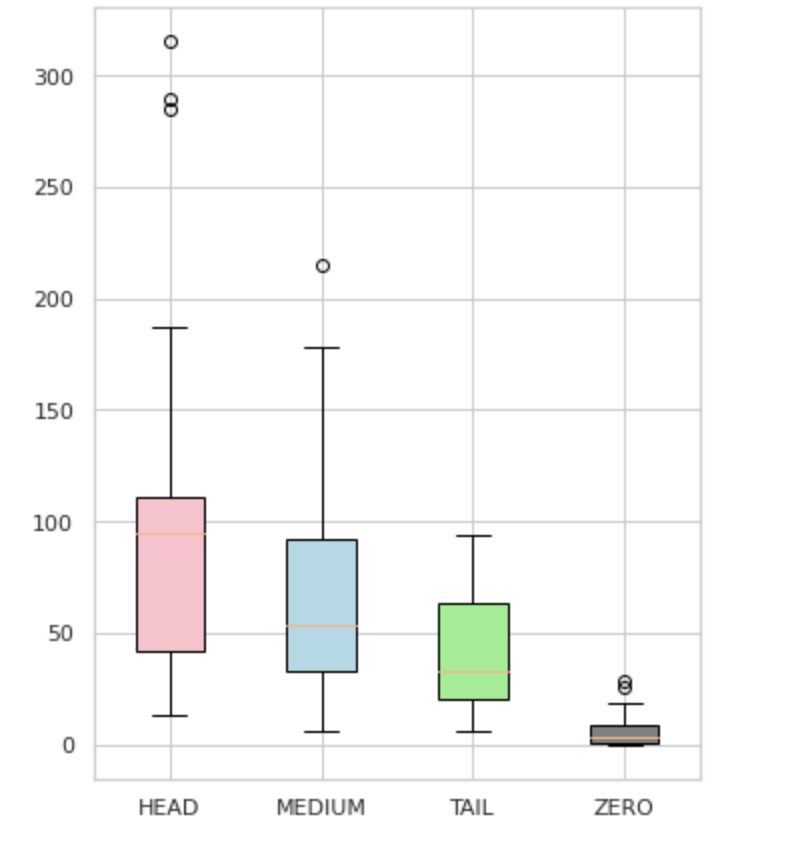
Slika 4. Število oznak v primerjavi s skupinami
Tabela 2 vsebuje informacije o metrikah za vsako skupino oznak za testni podnabor podatkov.
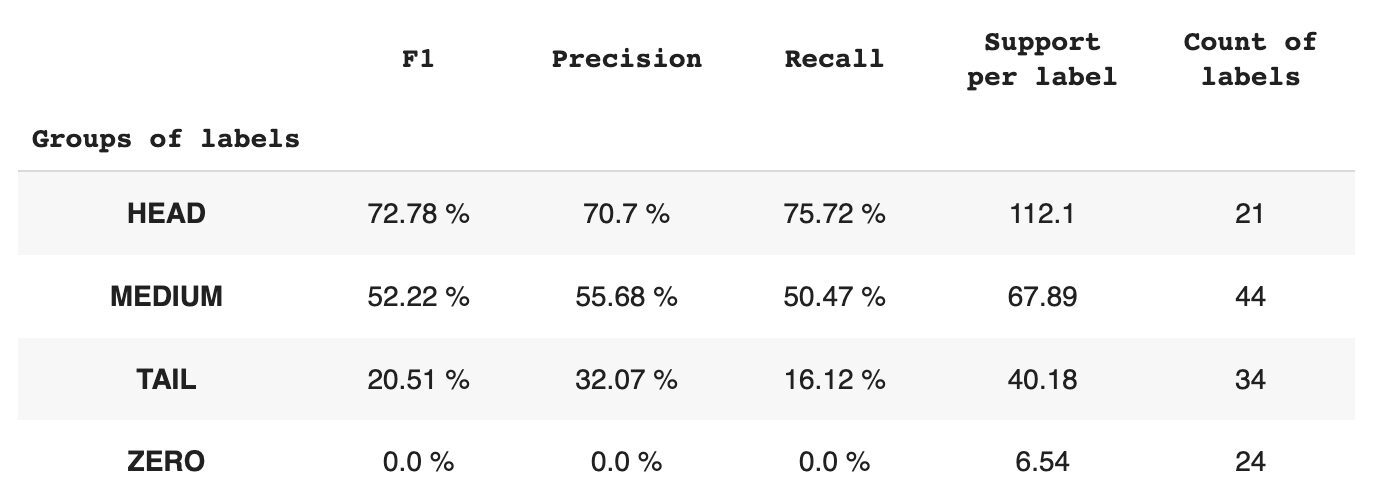
Tabela 2. Meritve na skupino.
- Skupina HEAD vsebuje 21 oznak s povprečno 112 podpornimi opazovanji na oznako. Na to skupino vplivajo odstopanja in zaradi visoke zastopanosti v naboru podatkov so njene meritve visoke: F1 – 73 %, natančnost – 71 %, priklic – 75 %.
- Skupino MEDIUM sestavlja 44 oznak s povprečno podporo 67 opazovanj, kar je približno dvakrat manj kot skupina HEAD. Meritve za to skupino naj bi se zmanjšale za 50 %: F1 – 52 %, Natančnost – 56 %, Priklic – 51 %.
- Skupina TAIL ima največje število razredov, vendar so vsi slabo zastopani v naboru podatkov, s povprečno 40 podpornimi opazovanji na oznako. Posledično se meritve znatno zmanjšajo: F1 – 21 %, Natančnost – 32 %, Priklic – 16 %.
- Skupina ZERO vključuje razrede, ki jih model sploh ne more prepoznati, morda zaradi njihove redke pojavnosti v naboru podatkov. Vsaka od 24 oznak v tej skupini ima povprečno 7 podpornih opazovanj.
Slika 5 vizualizira informacije, predstavljene v tabeli 2, ki zagotavlja vizualno predstavitev meritev na skupino oznak.
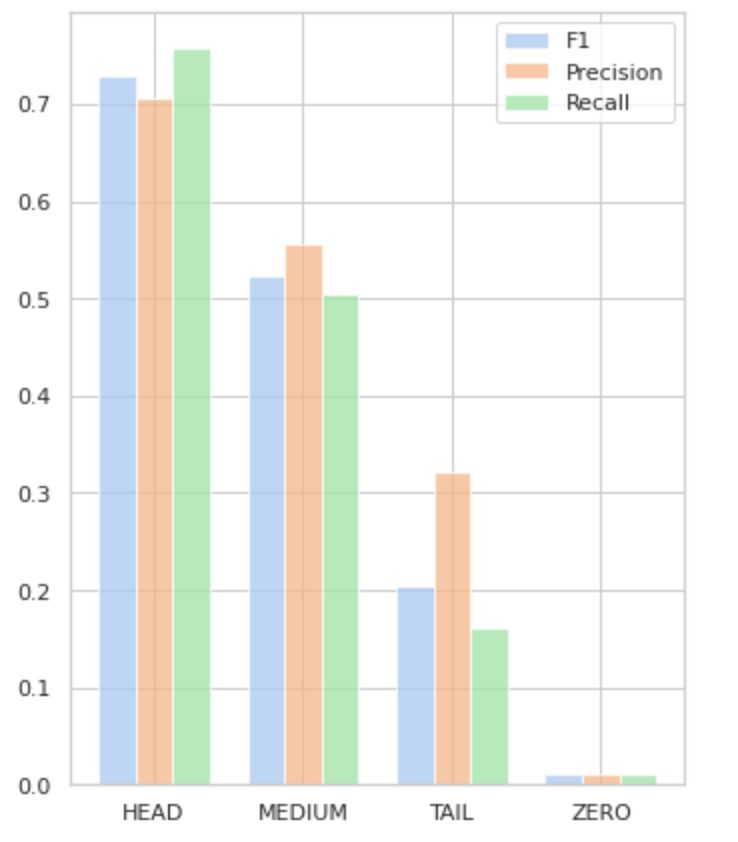
Slika 5. Metrike v primerjavi s skupinami oznak. Vse vrednosti NIČ = 0.
V tem obsežnem članku smo pokazali, da je na videz preprosta naloga razvrščanja besedila z več oznakami lahko zahtevna, če uporabimo tradicionalne metode. Predlagali smo uporabo porazdelitvenih izravnalnih izgubnih funkcij za reševanje vprašanja razrednega neravnovesja.
Uspešnost našega predlaganega pristopa smo primerjali s klasično metodo in jo ovrednotili z uporabo poslovnih meritev iz resničnega sveta. Rezultati kažejo, da uporaba izgubnih funkcij za obravnavo razrednih neravnovesij in sočasnih pojavov oznak nudi izvedljivo rešitev za klasifikacijo besedila z več oznakami.
Predlagani primer uporabe poudarja pomen upoštevanja različnih pristopov in tehnik pri razvrščanju besedila z več oznakami ter potencialne koristi porazdelitvenih izravnalnih funkcij izgube pri obravnavanju razrednih neravnovesij.
Če se soočate s podobno težavo in jo želite poenostaviti proces obdelave dokumentov znotraj vaše organizacije se obrnite name ali na ekipo Provectus. Z veseljem vam bomo pomagali pri iskanju učinkovitejših metod za avtomatizacijo vaših procesov.
Oleksij Babič je inženir strojnega učenja pri Provectusu. Z izkušnjami iz fizike ima odlične analitične in matematične sposobnosti ter je pridobil dragocene izkušnje z znanstvenimi raziskavami in predstavitvami na mednarodnih konferencah, vključno s SPIE Photonics West. Oleksii je specializiran za ustvarjanje obsežnih rešitev AI/ML od konca do konca za zdravstveno varstvo in fintech industrijo. Vključen je v vse faze življenjskega cikla razvoja ML, od prepoznavanja poslovnih težav do uvajanja in izvajanja produkcijskih modelov ML.
Rinat Akhmetov je arhitekt rešitev ML pri Provectusu. S trdnim praktičnim ozadjem na področju strojnega učenja (zlasti na področju računalniškega vida) je Rinat piflar, podatkovni navdušenec, programski inženir in deloholik, čigar druga največja strast je programiranje. Pri Provectusu je Rinat zadolžen za faze odkrivanja in dokazovanja koncepta ter vodi izvedbo kompleksnih projektov AI.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-label-nlp-an-analysis-of-class-imbalance-and-loss-function-approaches
- : je
- 1
- 10
- 100
- 15%
- 67
- 7
- 9
- a
- Sposobna
- O meni
- Doseči
- doseže
- dejavnosti
- Aktiviranje
- prilagoditev
- Naslov
- naslavljanje
- AI
- AI / ML
- Cilje
- algoritem
- algoritmi
- vsi
- omogoča
- Alpha
- med
- znesek
- Analiza
- Analitično
- analiziranje
- in
- pojavil
- uporabna
- Uporabi
- pristop
- pristopi
- približno
- SE
- članek
- AS
- vidiki
- dodeljena
- pomoč
- povezan
- At
- avtomatizacija
- povprečno
- ozadje
- Ravnovesje
- temeljijo
- Izhodišče
- BE
- ker
- spodaj
- Prednosti
- BEST
- beta
- Boljše
- med
- pristranskosti
- največji
- Bottom
- Pasovi
- vgrajeno
- poslovni
- by
- izračuna
- CAN
- ne more
- zajemanje
- primeru
- kategorije
- CB
- nekatere
- izzivi
- izziv
- Spremembe
- naboj
- razred
- razredi
- klasična
- Razvrstitev
- stranke
- tesno
- bližje
- pogosto
- v primerjavi z letom
- primerjavo
- Primerjava
- kompleksna
- celovito
- računalnik
- Računalniška vizija
- računalništvo
- Koncept
- Skrbi
- sklenjene
- Konferenca
- upoštevamo
- kontakt
- Vsebuje
- vsebina
- ozadje
- Prispevek
- prevleke
- Ustvarjanje
- stranka
- cikel
- datum
- deliti
- zmanjša
- opredeljen
- izkazati
- Dokazano
- uvajanja
- zasnovan
- podrobno
- Razvoj
- razlike
- drugačen
- neposredno
- Odkritje
- izrazit
- distribucija
- Distribucije
- razne
- deljeno
- dokument
- Dokumenti
- tem
- domena
- Drop
- vsak
- enostavno
- Učinkovito
- učinkovite
- prizadevanja
- omogočajo
- konec koncev
- inženir
- navdušenec
- enako
- Napaka
- zlasti
- Eter (ETH)
- ocenili
- Tudi vsak
- dokazi
- Primer
- odlično
- izvedba
- Pričakuje
- izkušnje
- raziskovanje
- raziskuje
- express
- f1
- soočen
- s katerimi se sooča
- povratne informacije
- Slika
- končna
- iskanje
- FINTECH
- prva
- Plavaj
- po
- za
- je pokazala,
- ulomek
- frekvenca
- pogosto
- iz
- funkcija
- funkcionalno
- funkcije
- nadalje
- Gain
- dana
- Pogled
- graf
- Zelen
- skupina
- Skupine
- ročaj
- srečna
- Imajo
- Glava
- zdravstveno varstvo
- pomoč
- Pomaga
- visoka
- več
- najvišja
- Poudarki
- Kako
- Kako
- Vendar
- HTML
- http
- HTTPS
- identificirati
- identifikacijo
- neravnovesje
- vpliv
- prizadeti
- Izvajanje
- uvoz
- Pomembnost
- Pomembno
- izboljšanje
- izboljšanju
- in
- vključuje
- Vključno
- nepravilno
- Povečajte
- povečal
- narašča
- neodvisno
- industrij
- Podatki
- inherentno
- vhod
- primer
- Namesto
- Facebook Global
- investirali
- vključeni
- vprašanje
- IT
- ITS
- jpg
- samo en
- KDnuggets
- label
- označevanje
- Oznake
- jezik
- obsežne
- Največji
- plast
- Interesenti
- UČITE
- naučili
- učenje
- Stopnja
- življenje
- Seznam
- Poglej
- off
- izgube
- nizka
- stroj
- strojno učenje
- je
- Glavne
- velika
- Večina
- več
- kartiranje
- math
- največja
- ukrepe
- srednje
- Metoda
- Metode
- meritev
- Meritve
- minimalna
- ML
- MLB
- Model
- modeli
- spremenite
- modul
- več
- učinkovitejše
- Najbolj
- več
- Imenovan
- Nimate
- negativna
- negativno
- Novo
- nlp
- normalno
- vredno omeniti
- Številka
- številke
- otopeli
- pridobi
- pridobljeni
- of
- ponudba
- on
- ONE
- Priložnost
- nasprotuje
- možnosti
- Organizacija
- drugi
- drugače
- zunaj
- Neporavnani
- Splošni
- parameter
- strast
- vzorci
- odstotek
- performance
- Fizika
- kos
- platon
- Platonova podatkovna inteligenca
- PlatoData
- prosim
- točke
- PoS
- pozitiven
- potencial
- potencialno
- Praktično
- Precision
- napovedati
- napovedano
- Napovedi
- Napovedi
- Predstavitve
- predstavljeni
- problem
- Težave
- Postopek
- Procesi
- obravnavati
- proizvodnjo
- Izdelek
- proizvodnja
- Programiranje
- projekti
- dokazilo
- dokaz koncepta
- predlagano
- zagotavljajo
- če
- zagotavlja
- zagotavljanje
- pitorha
- dvigniti
- območje
- precej
- resnični svet
- rebalans
- Rekapitulacija
- priznajo
- zmanjša
- Zmanjšana
- zmanjšanje
- nanaša
- Odnosi
- ustreznost
- pomembno
- zastopanje
- zastopan
- zahteva
- Raziskave
- povzroči
- rezultat
- Rezultati
- vrnitev
- vrne
- pregleda
- ROSE
- tek
- s
- Enako
- scenariji
- Znanstvena raziskava
- drugi
- iskanju
- izbran
- SAMO
- sentiment
- ločena
- Storitev
- nastavite
- Kompleti
- Oblikujte
- pokazale
- Razstave
- Pomen
- pomemben
- bistveno
- Podoben
- Enostavno
- hkrati
- sam
- Velikosti
- spretnosti
- So
- Software
- Software Engineer
- trdna
- Rešitev
- rešitve
- SOLVE
- nekaj
- specializirano
- določeno
- Stage
- postopka
- standardna
- Statistika
- Korak
- naravnost
- taka
- primerna
- nadzorovano učenje
- podpora
- Podpora
- miza
- TAG
- Bodite
- ciljno
- Naloga
- Naloge
- skupina
- tehnike
- Test
- Testiranje
- Razvrstitev besedil
- da
- O
- informacije
- njihove
- Njih
- sami
- te
- Prag
- skozi
- čas
- krat
- do
- vrh
- baklo
- Skupaj za plačilo
- na dotik
- proti
- sledenje
- tradicionalna
- Vlak
- usposabljanje
- Transform
- Preoblikovanje
- preoblikovati
- preoblikovanje
- zdravi
- Res
- tipično
- negotovosti
- razumevanje
- edinstven
- us
- uporaba
- primeru uporabe
- Uporaben
- potrjevanje
- dragocene
- Vrednote
- različnih
- preživetja
- Vizija
- vs
- teža
- West
- ki
- medtem
- Wikipedia
- bo
- z
- v
- brez
- delal
- Vaša rutina za
- zefirnet
- nič