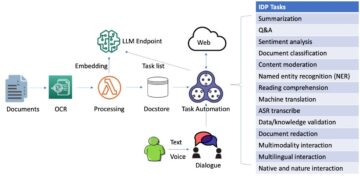
Ta tridelna serija prikazuje, kako uporabljati grafične nevronske mreže (GNN) in Amazonski Neptun za ustvarjanje filmskih priporočil z uporabo IMDb in Box Office Mojo Movies/TV/OTT licenčni podatkovni paket, ki zagotavlja široko paleto zabavnih metapodatkov, vključno z več kot milijardo uporabniških ocen; zasluge za več kot 1 milijonov igralcev in članov ekipe; 11 milijonov filmov, TV in razvedrilnih naslovov; in podatki o svetovnih blagajnah iz več kot 9 držav. Številne stranke medijev in zabave AWS licencirajo podatke IMDb Izmenjava podatkov AWS izboljšati odkrivanje vsebine ter povečati sodelovanje in zadrževanje strank.
In Del 1, smo razpravljali o aplikacijah GNN in o tem, kako preoblikovati in pripraviti naše podatke IMDb za poizvedovanje. V tej objavi razpravljamo o postopku uporabe Neptuna za ustvarjanje vdelav, ki se uporabljajo za izvajanje našega iskanja izven kataloga v 3. delu. Gremo tudi čez Amazon Neptune ML, funkcija strojnega učenja (ML) Neptuna in koda, ki jo uporabljamo v našem razvojnem procesu. V 3. delu se sprehodimo skozi uporabo naših vdelav grafa znanja v primeru uporabe iskanja zunaj kataloga.
Pregled rešitev
Veliki povezani nabori podatkov pogosto vsebujejo dragocene informacije, ki jih je težko izluščiti s poizvedbami, ki temeljijo samo na človeški intuiciji. Tehnike ML lahko pomagajo najti skrite korelacije v grafih z milijardami odnosov. Te korelacije so lahko v pomoč pri priporočanju izdelkov, napovedovanju kreditne sposobnosti, prepoznavanju goljufij in številnih drugih primerih uporabe.
Neptune ML omogoča izdelavo in usposabljanje uporabnih modelov ML na velikih grafih v urah namesto v tednih. Da bi to dosegel, Neptune ML uporablja tehnologijo GNN, ki jo poganja Amazon SageMaker in Knjižnica globokih grafov (DGL) (kateri je open-source). GNN so nastajajoče področje umetne inteligence (za primer glejte Obsežna raziskava o grafičnih nevronskih mrežah). Za praktično vadnico o uporabi GNN-jev z DGL glejte Učenje grafičnih nevronskih mrež s knjižnico Deep Graph Library.
V tej objavi pokažemo, kako uporabiti Neptune v našem cevovodu za ustvarjanje vdelav.
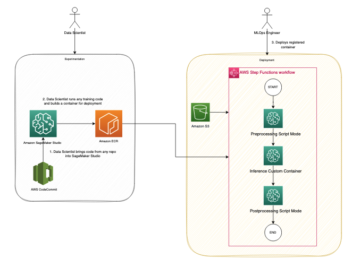
Naslednji diagram prikazuje celoten tok podatkov IMDb od prenosa do ustvarjanja vdelave.
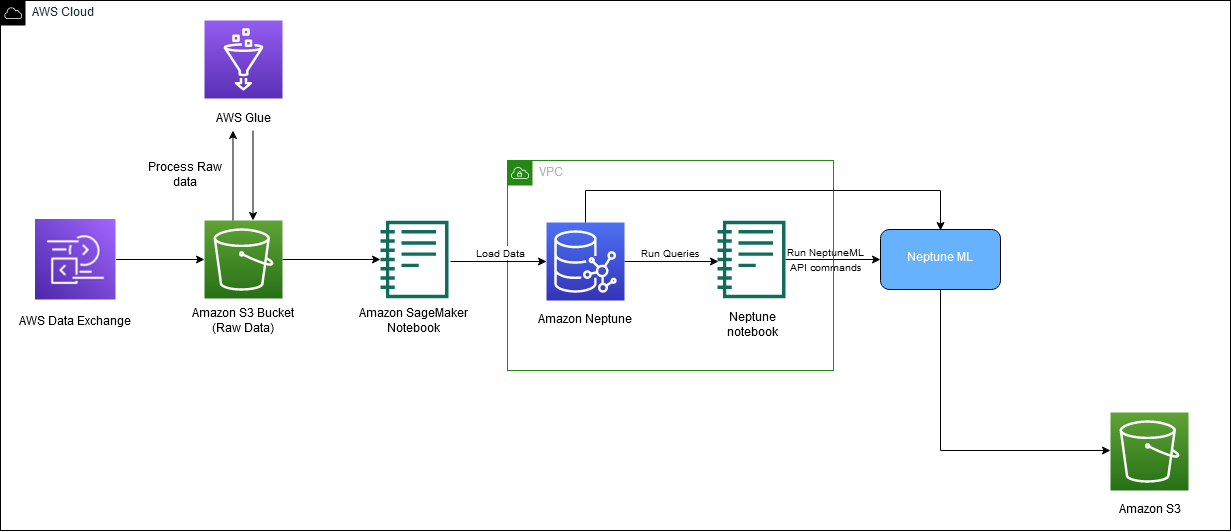
Za implementacijo rešitve uporabljamo naslednje storitve AWS:
V tej objavi vas vodimo skozi naslednje korake na visoki ravni:
- Nastavite spremenljivke okolja
- Ustvarite izvozno opravilo.
- Ustvarite opravilo za obdelavo podatkov.
- Oddajte delovno mesto za usposabljanje.
- Prenesite vdelave.
Koda za ukaze Neptune ML
Kot del izvajanja te rešitve uporabljamo naslednje ukaze:
Mi uporabljamo neptune_ml export da preverite stanje ali začnete postopek izvoza Neptune ML in neptune_ml training za začetek in preverjanje statusa delovnega mesta usposabljanja modela Neptune ML.
Za več informacij o teh in drugih ukazih glejte Uporaba Neptunove magije delovne mize v vaših zvezkih.
Predpogoji
Če želite slediti tej objavi, morate imeti naslednje:
- An AWS račun
- Poznavanje SageMaker, Amazon S3 in AWS CloudFormation
- Podatki grafov, naloženi v gručo Neptun (glejte Del 1 za več informacij)
Nastavite spremenljivke okolja
Preden začnemo, boste morali nastaviti svoje okolje z nastavitvijo naslednjih spremenljivk: s3_bucket_uri in processed_folder. s3_bucket_uri je ime vedra, uporabljenega v 1. delu in processed_folder je lokacija Amazon S3 za izhod iz izvoznega posla.
Ustvarite izvozno opravilo
V 1. delu smo ustvarili prenosnik SageMaker in izvozno storitev za izvoz naših podatkov iz gruče Neptune DB v Amazon S3 v zahtevanem formatu.
Zdaj, ko so naši podatki naloženi in je izvozna storitev ustvarjena, moramo ustvariti izvozno opravilo, ki ga zažene. Da bi to naredili, uporabljamo NeptuneExportApiUri in ustvarite parametre za izvozno opravilo. V naslednji kodi uporabljamo spremenljivke expo in export_params. Nastavite expo do vašega NeptuneExportApiUri vrednost, ki jo najdete na Izhodi zavihek vašega sklada CloudFormation. Za export_params, uporabimo končno točko vaše gruče Neptun in zagotovimo vrednost za outputS3path, ki je lokacija Amazon S3 za izhod iz izvoznega posla.
Če želite oddati izvozno opravilo, uporabite naslednji ukaz:
Če želite preveriti status izvoznega posla, uporabite naslednji ukaz:
Ko je delo končano, nastavite processed_folder spremenljivka za zagotavljanje lokacije Amazon S3 obdelanih rezultatov:
Ustvarite opravilo za obdelavo podatkov
Zdaj, ko je izvoz končan, ustvarimo opravilo za obdelavo podatkov za pripravo podatkov za proces usposabljanja Neptune ML. To je mogoče storiti na več različnih načinov. Za ta korak lahko spremenite job_name in modelType spremenljivke, vsi drugi parametri pa morajo ostati enaki. Glavni del te kode je modelType parameter, ki so lahko heterogeni modeli grafov (heterogeneous) ali grafe znanja (kge).
Izvozno delo vključuje tudi training-data-configuration.json. S to datoteko dodajte ali odstranite vozlišča ali robove, ki jih ne želite zagotoviti za usposabljanje (če na primer želite predvideti povezavo med dvema vozliščema, lahko to povezavo odstranite v tej konfiguracijski datoteki). Za to objavo v spletnem dnevniku uporabljamo izvirno konfiguracijsko datoteko. Za dodatne informacije glejte Urejanje konfiguracijske datoteke za usposabljanje.
Ustvarite svoje opravilo obdelave podatkov z naslednjo kodo:
Če želite preveriti status izvoznega posla, uporabite naslednji ukaz:
Oddajte delovno mesto za usposabljanje
Ko je delo obdelave končano, lahko začnemo z našim delom usposabljanja, kjer ustvarimo naše vdelave. Priporočamo vrsto primerka ml.m5.24xlarge, vendar ga lahko spremenite tako, da ustreza vašim računalniškim potrebam. Oglejte si naslednjo kodo:
Natisnemo spremenljivko training_results, da dobimo ID za opravilo usposabljanja. Za preverjanje statusa vašega opravila uporabite naslednji ukaz:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Prenesite vdelave
Ko je vaše usposabljanje končano, je zadnji korak prenos neobdelanih vdelav. Naslednji koraki vam pokažejo, kako prenesete vdelave, ustvarjene s KGE (isti postopek lahko uporabite za RGCN).
V naslednji kodi uporabljamo neptune_ml.get_mapping() in get_embeddings() za prenos datoteke za preslikavo (mapping.info) in surovo vdelano datoteko (entity.npy). Nato moramo ustrezne vdelave preslikati v njihove ustrezne ID-je.
Če želite prenesti RGCN, sledite istemu postopku z novim imenom opravila usposabljanja, tako da obdelate podatke s parametrom modelType, nastavljenim na heterogeneous, nato usposobite svoj model s parametrom modelName, nastavljenim na rgcn glej tukaj za več podrobnosti. Ko je to končano, pokličite get_mapping in get_embeddings funkcije za prenos vašega novega preslikava.info in entiteta.npy datoteke. Ko imate datoteko entitete in preslikavo, je postopek ustvarjanja datoteke CSV enak.
Na koncu naložite svoje vdelave na želeno lokacijo Amazon S3:
Zapomnite si to lokacijo S3, uporabiti jo boste morali v 3. delu.
Čiščenje
Ko končate z uporabo rešitve, ne pozabite počistiti vseh virov, da se izognete nenehnim bremenitvam.
zaključek
V tej objavi smo razpravljali o tem, kako uporabiti Neptune ML za usposabljanje vdelav GNN iz podatkov IMDb.
Nekatere povezane aplikacije vdelav grafov znanja so koncepti, kot so iskanje izven kataloga, priporočila vsebine, ciljano oglaševanje, predvidevanje manjkajočih povezav, splošno iskanje in kohortna analiza. Iskanje izven kataloga je postopek iskanja vsebine, ki je vaša last, in iskanje ali priporočanje vsebine v vašem katalogu, ki je čim bližje tistemu, kar je uporabnik iskal. V 3. delu se poglobimo v iskanje zunaj kataloga.
O avtorjih
 Matthew Rhodes je podatkovni znanstvenik, ki dela v Amazon ML Solutions Lab. Specializiran je za gradnjo cevovodov strojnega učenja, ki vključujejo koncepte, kot sta obdelava naravnega jezika in računalniški vid.
Matthew Rhodes je podatkovni znanstvenik, ki dela v Amazon ML Solutions Lab. Specializiran je za gradnjo cevovodov strojnega učenja, ki vključujejo koncepte, kot sta obdelava naravnega jezika in računalniški vid.
 Divya Bhargavi je podatkovna znanstvenica in vodja vertikale za medije in razvedrilo v Amazon ML Solutions Lab, kjer rešuje pomembne poslovne probleme za stranke AWS s pomočjo strojnega učenja. Ukvarja se z razumevanjem slik/videoposnetkov, priporočilnimi sistemi grafov znanja, primeri uporabe napovednega oglaševanja.
Divya Bhargavi je podatkovna znanstvenica in vodja vertikale za medije in razvedrilo v Amazon ML Solutions Lab, kjer rešuje pomembne poslovne probleme za stranke AWS s pomočjo strojnega učenja. Ukvarja se z razumevanjem slik/videoposnetkov, priporočilnimi sistemi grafov znanja, primeri uporabe napovednega oglaševanja.
 Gaurav Rele je Data Scientist v Amazon ML Solution Lab, kjer sodeluje s strankami AWS v različnih vertikalah, da pospeši njihovo uporabo strojnega učenja in storitev AWS Cloud za reševanje njihovih poslovnih izzivov.
Gaurav Rele je Data Scientist v Amazon ML Solution Lab, kjer sodeluje s strankami AWS v različnih vertikalah, da pospeši njihovo uporabo strojnega učenja in storitev AWS Cloud za reševanje njihovih poslovnih izzivov.
 Karan Sindwani je podatkovni znanstvenik pri Amazon ML Solutions Lab, kjer gradi in uvaja modele globokega učenja. Specializiran je za področje računalniškega vida. V prostem času se rad pohodi.
Karan Sindwani je podatkovni znanstvenik pri Amazon ML Solutions Lab, kjer gradi in uvaja modele globokega učenja. Specializiran je za področje računalniškega vida. V prostem času se rad pohodi.
 Soji Adeshina je uporabni znanstvenik pri AWS, kjer razvija modele, ki temeljijo na grafičnih nevronskih mrežah, za strojno učenje na grafičnih nalogah z aplikacijami za goljufije in zlorabe, grafe znanja, sisteme priporočil in znanosti o življenju. V prostem času rada bere in kuha.
Soji Adeshina je uporabni znanstvenik pri AWS, kjer razvija modele, ki temeljijo na grafičnih nevronskih mrežah, za strojno učenje na grafičnih nalogah z aplikacijami za goljufije in zlorabe, grafe znanja, sisteme priporočil in znanosti o življenju. V prostem času rada bere in kuha.
 Vidya Sagar Ravipati je vodja v Amazon ML Solutions Lab, kjer izkorišča svoje bogate izkušnje v obsežnih porazdeljenih sistemih in svojo strast do strojnega učenja, da strankam AWS v različnih industrijskih vertikalah pomaga pri pospeševanju umetne inteligence in sprejemanja oblaka.
Vidya Sagar Ravipati je vodja v Amazon ML Solutions Lab, kjer izkorišča svoje bogate izkušnje v obsežnih porazdeljenih sistemih in svojo strast do strojnega učenja, da strankam AWS v različnih industrijskih vertikalah pomaga pri pospeševanju umetne inteligence in sprejemanja oblaka.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- O meni
- zloraba
- pospeši
- čez
- Dodatne
- Dodatne informacije
- Sprejetje
- Oglaševanje
- po
- AI
- vsi
- sam
- Amazon
- Amazon ML Solutions Lab
- Analiza
- in
- aplikacije
- uporabna
- Uporabi
- primerno
- OBMOČJE
- umetni
- Umetna inteligenca
- AWS
- temeljijo
- med
- Billion
- milijardah
- Blog
- Pasovi
- blagajna
- izgradnjo
- Building
- Gradi
- poslovni
- klic
- primeru
- primeri
- Katalog
- izzivi
- spremenite
- Stroški
- preveriti
- Zapri
- Cloud
- sprejem v oblak
- storitev v oblaku
- Grozd
- Koda
- Kohorta
- dokončanje
- celovito
- računalnik
- Računalniška vizija
- računalništvo
- koncepti
- Ravnanje
- konfiguracija
- povezane
- vsebina
- Ustrezno
- države
- ustvarjajo
- ustvaril
- kredit
- krediti
- stranka
- Angažiranje strank
- Stranke, ki so
- datum
- obdelava podatkov
- podatkovni znanstvenik
- nabor podatkov
- globoko
- globoko učenje
- globlje
- razpolaga
- Podrobnosti
- Razvoj
- razvija
- dgl
- drugačen
- Odkritje
- razpravlja
- razpravljali
- porazdeljena
- porazdeljeni sistemi
- dont
- prenesi
- bodisi
- smirkovim
- Končna točka
- sodelovanje
- Zabava
- entiteta
- okolje
- Eter (ETH)
- Primer
- izkušnje
- izvoz
- ekstrakt
- Feature
- Nekaj
- Polje
- file
- datoteke
- Najdi
- iskanje
- Pretok
- sledi
- po
- format
- goljufija
- iz
- polno
- funkcije
- splošno
- ustvarjajo
- generacija
- dobili
- Globalno
- Go
- graf
- grafi
- hands-on
- Trdi
- pomoč
- pomoč
- skrita
- na visoki ravni
- URE
- Kako
- Kako
- HTML
- HTTPS
- človeškega
- enako
- identifikacijo
- izvajati
- izvajanja
- izboljšanje
- in
- vključuje
- Vključno
- Povečajte
- Indeks
- Industrija
- info
- Podatki
- primer
- Namesto
- Intelligence
- vključujejo
- IT
- Job
- json
- Ključne
- znanje
- lab
- jezik
- velika
- obsežne
- Zadnja
- vodi
- učenje
- Leverages
- Knjižnica
- Licenca
- življenje
- Life Sciences
- LINK
- Povezave
- kraj aktivnosti
- stroj
- strojno učenje
- Glavne
- IZDELA
- upravitelj
- več
- map
- kartiranje
- mediji
- srednje
- člani
- metapodatki
- milijonov
- manjka
- ML
- Model
- modeli
- več
- Film
- Ime
- naravna
- Obdelava Natural Language
- Nimate
- potrebe
- Neptun
- omrežno
- omrežij
- nevronske mreže
- Novo
- vozlišča
- prenosnik
- Office
- v teku
- izvirno
- Ostalo
- Splošni
- lastne
- paket
- parameter
- parametri
- del
- strast
- plinovod
- platon
- Platonova podatkovna inteligenca
- PlatoData
- mogoče
- Prispevek
- moč
- poganja
- napovedati
- napovedovanje
- Pripravimo
- Tiskanje
- Težave
- Postopek
- obravnavati
- Izdelki
- profil
- zagotavljajo
- zagotavlja
- območje
- ocen
- Surovi
- reading
- Priporočamo
- Priporočilo
- Priporočila
- priporočilo
- povezane
- Razmerja
- ostajajo
- ne pozabite
- odstrani
- Poročanje
- obvezna
- viri
- Rezultati
- zadrževanje
- sagemaker
- Enako
- ZNANOSTI
- Znanstvenik
- Iskalnik
- iskanje
- Serija
- Storitev
- Storitve
- nastavite
- nastavitev
- shouldnt
- Prikaži
- Rešitev
- rešitve
- SOLVE
- Rešuje
- specializirano
- sveženj
- Začetek
- Status
- Korak
- Koraki
- trgovina
- predloži
- taka
- Suit
- Anketa
- sistemi
- ciljno
- Naloge
- tehnike
- Tehnologija
- O
- Območje
- njihove
- skozi
- čas
- naslove
- do
- Vlak
- usposabljanje
- Transform
- Res
- Navodila
- tv
- razumevanje
- uporaba
- primeru uporabe
- uporabnik
- dragocene
- vrednost
- Popravljeno
- različica
- vertikale
- Vizija
- načini
- Weeks
- Kaj
- ki
- široka
- Širok spekter
- bo
- deluje
- deluje
- Vaša rutina za
- zefirnet