Podatki o časovnih vrstah so v našem življenju zelo prisotni. Cene delnic, cene stanovanj, vremenske informacije in podatki o prodaji, zajeti skozi čas, so le nekateri primeri. Ker podjetja vedno bolj iščejo nove načine za pridobitev pomembnih vpogledov iz podatkov časovnih vrst, sta zmožnost vizualizacije podatkov in uporabe želenih transformacij temeljna koraka. Vendar pa imajo podatki časovnih vrst edinstvene značilnosti in nianse v primerjavi z drugimi vrstami tabelarnih podatkov in zahtevajo posebno pozornost. Na primer, standardni tabelarični ali presečni podatki se zbirajo ob določeni časovni točki. V nasprotju s tem se podatki o časovni vrsti zajemajo večkrat skozi čas, pri čemer je vsaka naslednja podatkovna točka odvisna od svojih preteklih vrednosti.
Ker se večina analiz časovnih vrst zanaša na informacije, zbrane v neprekinjenem naboru opazovanj, lahko manjkajoči podatki in inherentna redkost zmanjšajo točnost napovedi in povzročijo pristranskost. Poleg tega se večina pristopov analize časovnih vrst opira na enak razmik med podatkovnimi točkami, z drugimi besedami, periodičnost. Zato je zmožnost popravljanja nepravilnosti v razmiku podatkov ključni predpogoj. Končno analiza časovnih vrst pogosto zahteva ustvarjanje dodatnih funkcij, ki lahko pomagajo razložiti inherentno razmerje med vhodnimi podatki in prihodnjimi napovedmi. Vsi ti dejavniki razlikujejo projekte časovnih vrst od tradicionalnih scenarijev strojnega učenja (ML) in zahtevajo poseben pristop k njegovi analizi.
Ta objava opisuje, kako uporabljati Amazon SageMaker Data Wrangler za uporabo transformacij časovnih vrst in pripravo nabora podatkov za primere uporabe časovnih vrst.
Primeri uporabe za Data Wrangler
Data Wrangler ponuja rešitev brez kode/nizko kodo za analizo časovnih vrst s funkcijami za hitrejše čiščenje, preoblikovanje in pripravo podatkov. Podatkovnim znanstvenikom omogoča tudi, da pripravijo podatke o časovni vrsti v skladu z zahtevami glede vhodnega formata modela napovedovanja. Sledi nekaj načinov, kako lahko uporabite te zmožnosti:
- Opisna analiza– Običajno je prvi korak katerega koli projekta podatkovne znanosti razumevanje podatkov. Ko narišemo podatke o časovni vrsti, dobimo pregled na visoki ravni njihovih vzorcev, kot so trend, sezonskost, cikli in naključne spremembe. Pomaga nam pri odločitvi o pravilni metodologiji napovedovanja za natančno predstavitev teh vzorcev. Risanje lahko pomaga tudi pri prepoznavanju izstopajočih vrednosti, kar preprečuje nerealne in netočne napovedi. Data Wrangler je opremljen z vizualizacija dekompozicije sezonskega trenda za predstavitev komponent časovne vrste in an vizualizacija zaznavanja odstopanj za prepoznavanje izstopajočih vrednosti.
- Razlagalna analiza– Pri večvariantnih časovnih vrstah je zmožnost raziskovanja, prepoznavanja in modeliranja razmerja med dvema ali več časovnimi serijami bistvena za pridobitev smiselnih napovedi. The Skupina z transform v Data Wrangler ustvari več časovnih vrst z združevanjem podatkov za določene celice. Poleg tega pretvorbe časovnih vrst Data Wrangler, kjer je primerno, omogočajo specifikacijo dodatnih stolpcev ID-jev za združevanje, kar omogoča kompleksno analizo časovnih vrst.
- Priprava podatkov in inženiring funkcij– Podatki časovnih vrst so redko v obliki, ki jo pričakujejo modeli časovnih vrst. Pogosto zahteva pripravo podatkov za pretvorbo neobdelanih podatkov v funkcije, specifične za časovno vrsto. Pred analizo boste morda želeli preveriti, ali so podatki o časovni vrsti redno ali enakomerno razporejeni. Za primere uporabe napovedi boste morda želeli vključiti tudi dodatne značilnosti časovnih vrst, kot so avtokorelacija in statistične lastnosti. S programom Data Wrangler lahko hitro ustvarite funkcije časovnih vrst, kot so stolpci zamika za več obdobij zaostankov, ponovno vzorčite podatke na več časovnih razdrobljenosti in samodejno ekstrahirate statistične lastnosti časovne vrste, če naštejemo le nekaj zmogljivosti.
Pregled rešitev
Ta objava pojasnjuje, kako lahko podatkovni znanstveniki in analitiki uporabljajo Data Wrangler za vizualizacijo in pripravo podatkov časovnih vrst. Uporabljamo nabor podatkov o kriptovaluti bitcoin iz cryptodatadownload s podrobnostmi o trgovanju z bitcoini za predstavitev teh zmogljivosti. Očistimo, potrdimo in preoblikujemo neobdelani nabor podatkov s funkcijami časovnih vrst ter ustvarimo napovedi količinskih cen bitcoinov z uporabo preoblikovanega nabora podatkov kot vhodnih podatkov.
Vzorec podatkov o trgovanju z bitcoini je od 1. januarja do 19. novembra 2021 s 464,116 podatkovnimi točkami. Atributi nabora podatkov vključujejo časovni žig zapisa cene, začetno ali prvo ceno, po kateri je bil kovanec zamenjan za določen dan, najvišjo ceno, po kateri je bil kovanec zamenjan na dan, zadnjo ceno, po kateri je bil kovanec zamenjan na dan. dan, količina, izmenjana vrednost kriptovalute na dan v BTC, in ustrezna valuta USD.
Predpogoji
Prenos Bitstamp_BTCUSD_2021_minute.csv datoteka od cryptodatadownload in ga naložite v Preprosta storitev shranjevanja Amazon (Amazon S3).
Uvozite nabor podatkov bitcoin v Data Wrangler
Če želite začeti postopek vnosa v Data Wrangler, dokončajte naslednje korake:
- o Studio SageMaker konzolo na file izberite meni Novo, nato izberite Data Wrangler Flow.
- Po želji preimenujte tok.
- za Uvozi podatke, izberite Amazon S3.
- Naložite
Bitstamp_BTCUSD_2021_minute.csvdatoteko iz vedra S3.
Zdaj si lahko predogledate svoj nabor podatkov.
- v podrobnosti podokno, izberite Napredna konfiguracija in prekliči izbiro Omogoči vzorčenje.
To je razmeroma majhen nabor podatkov, zato ne potrebujemo vzorčenja.
- Izberite uvoz.
Uspešno ste ustvarili diagram poteka in ste pripravljeni na dodajanje korakov transformacije.

Dodajte transformacije
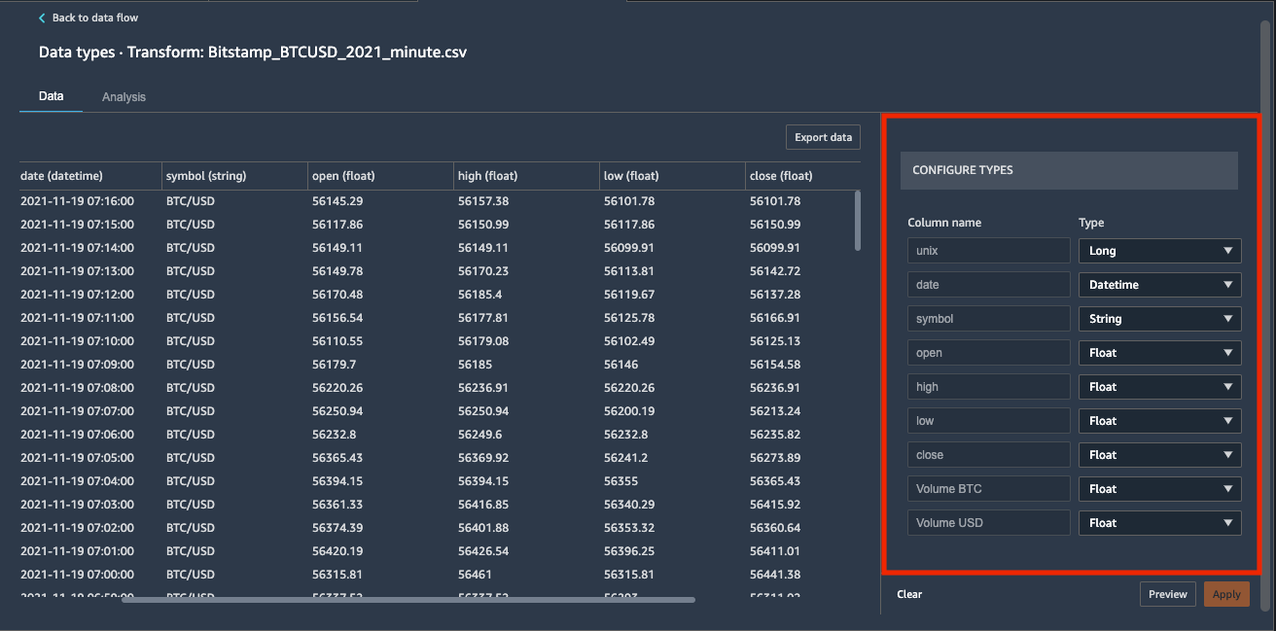
Če želite dodati transformacije podatkov, izberite znak plus zraven Vrste podatkov In izberite Urejanje podatkovnih vrst.

Zagotovite, da je Data Wrangler samodejno ugotovil pravilne vrste podatkov za podatkovne stolpce.
V našem primeru so ugotovljeni tipi podatkov pravilni. Vendar predpostavimo, da je bil en tip podatkov nepravilen. Preprosto jih lahko spremenite prek uporabniškega vmesnika, kot je prikazano na naslednjem posnetku zaslona.
Začnimo z analizo in dodajamo transformacije.
Čiščenje podatkov
Najprej izvedemo več transformacij čiščenja podatkov.
Spustite stolpec
Začnimo s spuščanjem unix stolpec, ker uporabljamo date stolpec kot indeks.
- Izberite Nazaj na pretok podatkov.
- Izberite znak plus poleg Vrste podatkov In izberite Dodaj preoblikovanje.
- Izberite + Dodaj korak v TRANSFORMACIJE okno.
- Izberite Upravljanje stolpcev.
- za Transform, izberite Spustite stolpec.
- za Stolpec spustite, izberite unix.
- Izberite predogled.
- Izberite Dodaj da shranite korak.
Ročaj manjka
Manjkajoči podatki so dobro znana težava v naborih podatkov v resničnem svetu. Zato je najboljša praksa, da preverite prisotnost morebitnih manjkajočih ali ničelnih vrednosti in jih ustrezno obravnavate. Naš nabor podatkov ne vsebuje manjkajočih vrednosti. Če pa bi obstajali, bi uporabili Ročaj manjka preoblikovati časovne vrste, da jih popravimo. Običajno uporabljene strategije za ravnanje z manjkajočimi podatki vključujejo izpuščanje vrstic z manjkajočimi vrednostmi ali zapolnjevanje manjkajočih vrednosti z razumnimi ocenami. Ker se podatki časovnih vrst opirajo na zaporedje podatkovnih točk skozi čas, je zapolnjevanje manjkajočih vrednosti prednostni pristop. Postopek zapolnjevanja manjkajočih vrednosti se imenuje imputacija. Ročaj manjka pretvorba časovnih vrst omogoča izbiro med več strategijami imputiranja.
- Izberite + Dodaj korak v TRANSFORMACIJE okno.
- Izberite Časovne serije preoblikovati.
- za Transform, Izberite Ročaj manjka.
- za Vrsta vnosa časovne vrste, izberite Vzdolž stolpca.
- za Metoda imputiranja vrednosti, izberite Polnjenje naprej.
O Polnjenje naprej metoda nadomesti manjkajoče vrednosti z nemanjkajočimi vrednostmi pred manjkajočimi vrednostmi.
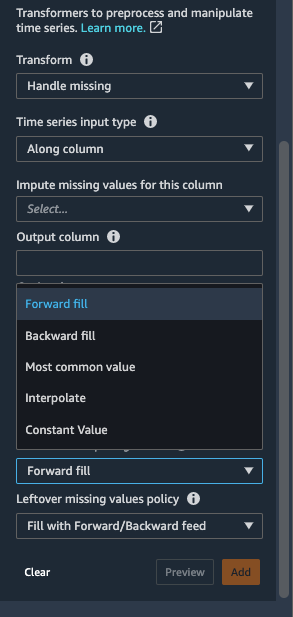
Polnjenje nazaj, Konstantna vrednost, Najpogostejša vrednost in Interpolirajte so druge strategije imputiranja, ki so na voljo v Data Wranglerju. Tehnike interpolacije se za zapolnjevanje manjkajočih vrednosti zanašajo na sosednje vrednosti. Podatki časovnih vrst pogosto kažejo korelacijo med sosednjimi vrednostmi, zaradi česar je interpolacija učinkovita strategija zapolnjevanja. Za dodatne podrobnosti o funkcijah, ki jih lahko uporabite za uporabo interpolacije, glejte pandas.DataFrame.interpolate.
Potrdi časovni žig
Pri analizi časovnih vrst stolpec s časovnim žigom deluje kot indeksni stolpec, okoli katerega se vrti analiza. Zato je nujno zagotoviti, da stolpec časovnega žiga ne vsebuje neveljavnih ali nepravilno oblikovanih vrednosti časovnega žiga. Ker uporabljamo date kot stolpec in indeks časovnega žiga, potrdimo, da so njegove vrednosti pravilno oblikovane.
- Izberite + Dodaj korak v TRANSFORMACIJE okno.
- Izberite Časovne serije preoblikovati.
- za Preoblikovanje, izberite Potrdite časovne žige.
O Potrdite časovne žige transform vam omogoča, da preverite, ali stolpec s časovnim žigom v vašem naboru podatkov nima vrednosti z napačnim časovnim žigom ali manjkajočimi vrednostmi.
- za Stolpec časovnega žiga, izberite Datum.
- za Politika spustni meni, izberite Navedite.
O Navedite možnost pravilnika ustvari logični stolpec, ki označuje, ali je vrednost v stolpcu časovnega žiga veljavna oblika datuma/časa. Druge možnosti za Politika vključujejo:
- napaka – Vrže napako, če stolpec s časovnim žigom manjka ali je neveljaven
- Drop – Izpusti vrstico, če stolpec s časovnim žigom manjka ali je neveljaven
- Izberite predogled.
Nov logični stolpec z imenom date_is_valid je nastala, z true vrednosti, ki označujejo pravilno obliko in neničelne vnose. Naš nabor podatkov ne vsebuje neveljavnih vrednosti časovnih žigov v date stolpec. Če pa bi, bi lahko uporabili nov logični stolpec za prepoznavanje in popravljanje teh vrednosti.
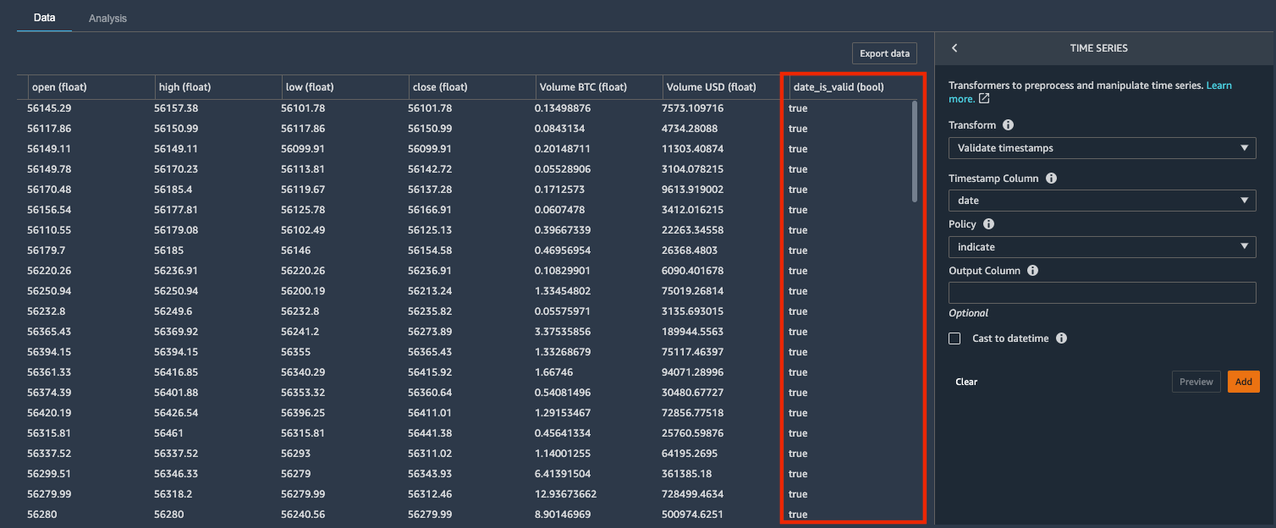
- Izberite Dodaj da shranite ta korak.
Vizualizacija časovnih vrst
Ko očistimo in potrdimo nabor podatkov, si lahko podatke bolje vizualiziramo, da razumemo njihove različne komponente.
Ponovno vzorčenje
Ker nas zanimajo dnevne napovedi, pretvorimo pogostost podatkov v dnevno.
O Ponovno vzorčenje preoblikovanje spremeni pogostost opazovanj časovnih vrst na določeno razdrobljenost in vključuje možnosti povečanja in zmanjšanja vzorčenja. Uporaba povečanega vzorčenja poveča pogostost opazovanj (na primer z dnevnega na vsako uro), medtem ko znižanje vzorčenja zmanjša pogostost opazovanj (na primer z vsakournega na dnevno).
Ker je naš nabor podatkov zelo razdrobljen, uporabimo možnost zmanjšanja vzorčenja.
- Izberite + Dodaj korak.
- Izberite Časovne serije preoblikovati.
- za Transform, izberite Ponovno vzorčenje.
- za Timestamp, izberite Datum.
- za Frekvenčna enota, izberite Koledarski dan.
- za Količina frekvence, vnesite 1.
- za Metoda za združevanje številskih vrednosti, izberite pomeni.
- Izberite predogled.
Pogostost našega nabora podatkov se je spremenila iz na minuto v dnevno.

- Izberite Dodaj da shranite ta korak.
Razčlenitev sezonskega trenda
Po ponovnem vzorčenju lahko vizualiziramo transformirano serijo in z njo povezane komponente STL (Seasonal and Trend decomposition using LOESS) z uporabo Razčlenitev sezonskega trenda vizualizacija. To razčleni prvotno časovno vrsto na različne trende, sezonskost in preostale komponente, kar nam daje dobro razumevanje, kako se vsak vzorec obnaša. Informacije lahko uporabimo tudi pri modeliranju problemov napovedovanja.
Data Wrangler uporablja LOESS, robustno in vsestransko statistično metodo za modeliranje trendov in sezonskih komponent. Njegova osnovna implementacija uporablja polinomsko regresijo za ocenjevanje nelinearnih odnosov, ki so prisotni v komponentah časovne vrste (sezonskost, trend in ostanek).
- Izberite Nazaj na pretok podatkov.
- Izberite znak plus poleg Koraki on Pretok podatkov.
- Izberite Dodaj analizo.
- v Ustvari analizo podokno, za Vrsta analize, izberite Časovne serije.
- za Vizualizacija, izberite Razčlenitev sezonskega trenda.
- za Ime analize, vnesite ime.
- za Stolpec s časovnim žigom, izberite Datum.
- za Stolpec vrednosti, izberite Obseg USD.
- Izberite predogled.
Analiza nam omogoča vizualizacijo vhodne časovne serije in dekomponirane sezonskosti, trenda in reziduala.

- Izberite Shrani da shranite analizo.
Z vizualizacija dekompozicije sezonskega trenda, lahko ustvarimo štiri vzorce, kot je prikazano na prejšnjem posnetku zaslona:
- prvotni – Prvotna časovna serija je ponovno vzorčena na dnevno razdrobljenost.
- Trend – Polinomski trend s splošnim negativnim vzorcem trenda za leto 2021, ki kaže na zmanjšanje
Volume USDvrednost. - Sezona – Multiplikativna sezonskost, ki jo predstavljajo različni vzorci nihanja. Vidimo zmanjšanje sezonskih nihanj, za katere je značilno zmanjšanje amplitude nihanj.
- Preostali – Preostali preostali ali naključni šum. Preostala serija je nastala serija po odstranitvi trendnih in sezonskih komponent. Če natančno pogledamo, opazimo skoke med januarjem in marcem ter med aprilom in junijem, kar kaže na prostor za modeliranje takšnih posebnih dogodkov z uporabo zgodovinskih podatkov.
Te vizualizacije zagotavljajo dragocene napotke podatkovnim znanstvenikom in analitikom v obstoječe vzorce in vam lahko pomagajo pri izbiri strategije modeliranja. Vendar pa je vedno dobra praksa, da izhod razgradnje STL potrdite z informacijami, zbranimi z opisno analizo in strokovnim znanjem o domeni.
Če povzamemo, opažamo padajoči trend, ki je skladen z izvirno vizualizacijo serije, kar povečuje naše zaupanje pri vključevanju informacij, ki jih posreduje vizualizacija trenda, v nadaljnje odločanje. Nasprotno pa vizualizacija sezonskosti pomaga obveščati o prisotnosti sezonskosti in potrebi po njeni odstranitvi z uporabo tehnik, kot je razlikovanje, ne zagotavlja želene ravni podrobnega vpogleda v različne prisotne sezonske vzorce, zato je potrebna globlja analiza.
Feature inženiring
Ko razumemo vzorce, ki so prisotni v našem naboru podatkov, lahko začnemo razvijati nove funkcije, katerih cilj je povečati natančnost modelov napovedovanja.
Predstavite datum in uro
Začnimo proces inženiringa funkcij z enostavnejšimi funkcijami datuma/časa. Funkcije datuma/časa so ustvarjene iz timestamp stolpec in zagotoviti optimalno pot za podatkovne znanstvenike, da začnejo proces inženiringa funkcij. Začnemo z Predstavite datum in uro transformacijo časovne vrste, da v naš nabor podatkov dodamo mesec, dan v mesecu, dan v letu, teden v letu in četrtletje. Ker komponente datuma/časa ponujamo kot ločene funkcije, omogočamo algoritmom ML za zaznavanje signalov in vzorcev za izboljšanje natančnosti predvidevanja.
- Izberite + Dodaj korak.
- Izberite Časovne serije preoblikovati.
- za Preoblikovanje, izberite Predstavite datum in uro.
- za Vnosni stolpec, izberite Datum.
- za Izhodni stolpec, vnesite
date(ta korak ni obvezen). - za izhod, izberite Navadni.
- za Izhodni format, izberite Stolpci.
- Za funkcije datuma/časa, ki jih želite ekstrahirati, izberite mesec, Dan, Teden v letu, Dan v letuin četrtletje.
- Izberite predogled.
Nabor podatkov zdaj vsebuje nove imenovane stolpce date_month, date_day, date_week_of_year, date_day_of_yearin date_quarter. Informacije, pridobljene s temi novimi funkcijami, bi lahko pomagale podatkovnim znanstvenikom pridobiti dodatne vpoglede iz podatkov in v razmerje med vhodnimi in izhodnimi funkcijami.
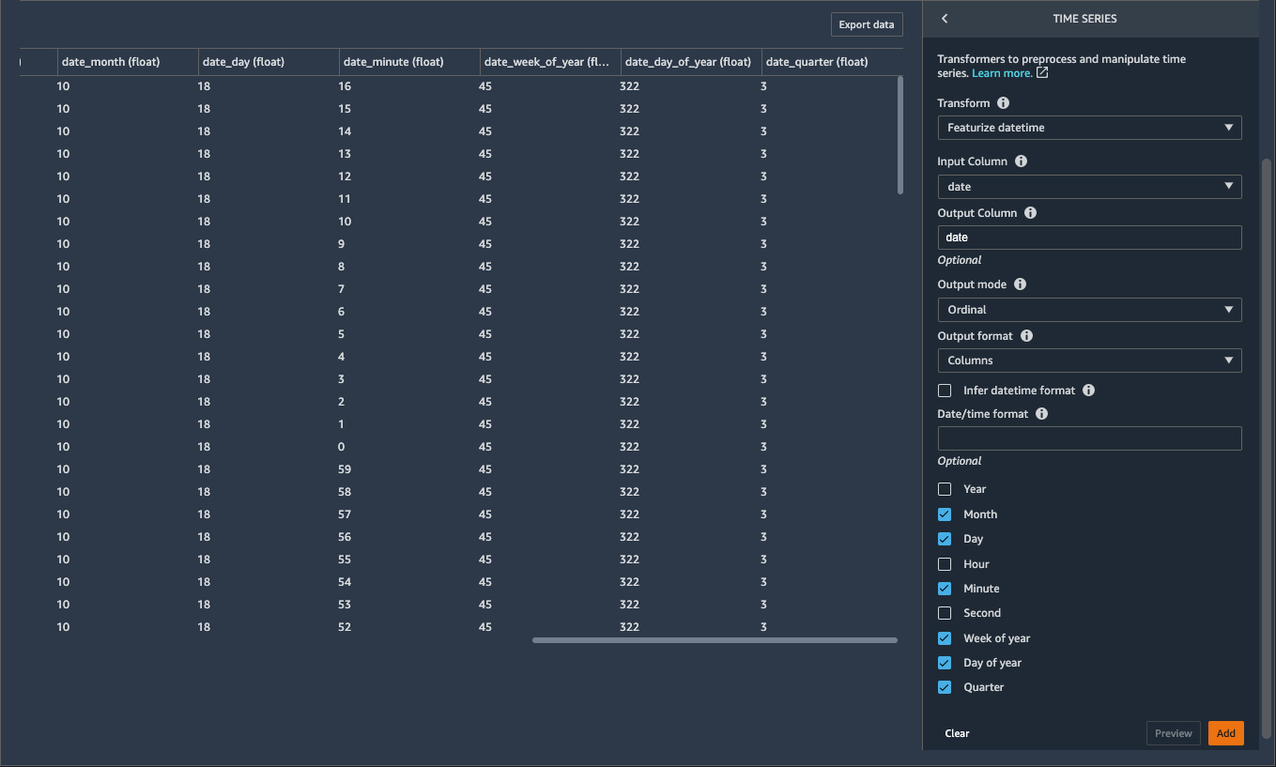
- Izberite Dodaj da shranite ta korak.
Kodiraj kategorično
Funkcije datuma/časa niso omejene na celoštevilske vrednosti. Lahko se tudi odločite, da nekatere ekstrahirane funkcije datuma/časa upoštevate kot kategorične spremenljivke in jih predstavite kot enkratno kodirane funkcije, pri čemer vsak stolpec vsebuje binarne vrednosti. Na novo ustvarjeni date_quarter stolpec vsebuje vrednosti med 0-3 in ga je mogoče enkratno kodirati z uporabo štirih binarnih stolpcev. Ustvarimo štiri nove binarne funkcije, od katerih vsaka predstavlja ustrezno četrtletje v letu.
- Izberite + Dodaj korak.
- Izberite Kodiraj kategorično preoblikovati.
- za Transform, izberite Enkratno kodiranje.
- za Vhodni stolpec, izberite datum_četrtletje.
- za Izhodni slog, izberite Stolpci.
- Izberite predogled.
- Izberite Dodaj , da dodate korak.

Funkcija zamika
Nato ustvarimo funkcije zamika za ciljni stolpec Volume USD. Funkcije zamika v analizi časovnih vrst so vrednosti pri predhodnih časovnih žigih, ki veljajo za koristne pri sklepanju prihodnjih vrednosti. Pomagajo tudi prepoznati avtokorelacijo (znano tudi kot serijska korelacija) vzorcev v rezidualni seriji s kvantificiranjem razmerja opazovanja z opazovanji v prejšnjih časovnih korakih. Avtokorelacija je podobna običajni korelaciji, vendar med vrednostmi v seriji in njenimi preteklimi vrednostmi. Tvori osnovo za avtoregresivne modele napovedovanja v seriji ARIMA.
Z Data Wranglerjem Funkcija zamika transformacijo, lahko preprosto ustvarite funkcije zaostanka v razmiku n obdobij. Poleg tega pogosto želimo ustvariti več funkcij zamika pri različnih zakasnitvah in prepustiti modelu, da določi najbolj pomembne funkcije. Za takšen scenarij je Funkcije zamika transform pomaga ustvariti več stolpcev z zamikom nad določeno velikostjo okna.
- Izberite Nazaj na pretok podatkov.
- Izberite znak plus poleg Koraki on Pretok podatkov.
- Izberite + Dodaj korak.
- Izberite Časovne serije preoblikovati.
- za Transform, izberite Funkcije zamika.
- za Ustvari funkcije zamika za ta stolpec, izberite Obseg USD.
- za Stolpec časovnega žiga, izberite Datum.
- za skupina, vnesite
7. - Ker nas zanima opazovanje do prejšnjih sedmih vrednosti zamika, izberimo Vključite celotno okno zamika.
- Če želite ustvariti nov stolpec za vsako vrednost zamika, izberite Izravnajte izhod.
- Izberite predogled.
Dodanih je sedem novih stolpcev s pripono lag_number ključna beseda za ciljni stolpec Volume USD.
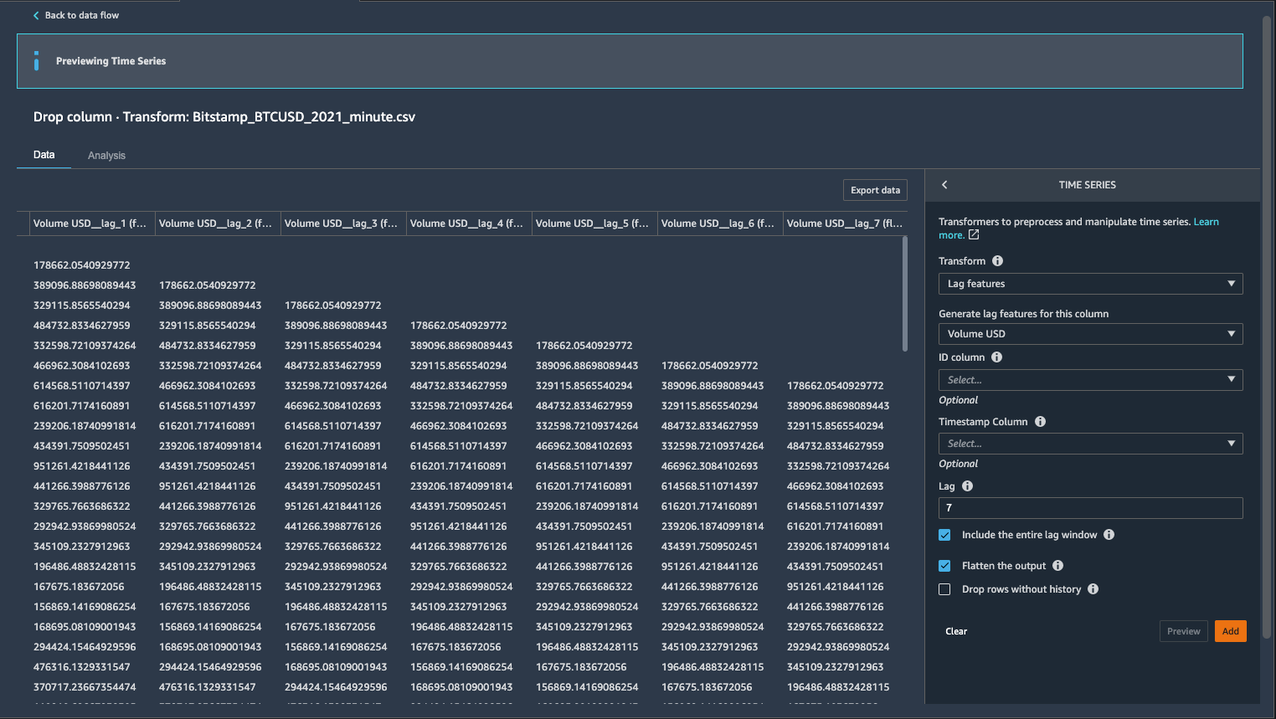
- Izberite Dodaj da shranite korak.
Funkcije drsnega okna
Izračunamo lahko tudi smiselne statistične povzetke v razponu vrednosti in jih vključimo kot vhodne funkcije. Izluščimo pogoste značilnosti statističnih časovnih vrst.
Data Wrangler izvaja zmožnosti samodejnega ekstrahiranja funkcij časovnih vrst z uporabo odprte kode tsfresh paket. S transformacijami ekstrakcije funkcij časovne serije lahko avtomatizirate postopek ekstrakcije funkcij. To odpravlja čas in trud, ki bi ga sicer porabili za ročno implementacijo knjižnic za obdelavo signalov. Za to objavo ekstrahiramo funkcije z uporabo Funkcije drsnega okna transformirati. Ta metoda izračuna statistične lastnosti v nizu opazovanj, ki jih določa velikost okna.
- Izberite + Dodaj korak.
- Izberite Časovne serije preoblikovati.
- za Transform, izberite Funkcije drsnega okna.
- za Ustvari funkcije tekočega okna za ta stolpec, izberite Obseg USD.
- za Stolpec časovnega žiga, izberite Datum.
- za Velikost okna, vnesite
7.
Določitev velikosti okna 7 izračuna funkcije tako, da združi vrednost trenutnega časovnega žiga in vrednosti za prejšnjih sedem časovnih žigov.
- Izberite Sploščite da ustvarite nov stolpec za vsako izračunano funkcijo.
- Izberite svojo strategijo kot Minimalna podmnožica.
Ta strategija izloči osem funkcij, ki so uporabne pri nadaljnjih analizah. Druge strategije vključujejo Učinkovita podmnožica, Podnabor po meriin Vse funkcije. Za celoten seznam funkcij, ki so na voljo za ekstrakcijo, glejte Pregled ekstrahiranih funkcij.
- Izberite predogled.
Vidimo lahko osem novih stolpcev z določeno velikostjo okna 7 v njihovem imenu, priložen našemu naboru podatkov.
- Izberite Dodaj da shranite korak.

Izvozi nabor podatkov
Preoblikovali smo podatkovni niz časovnih vrst in smo pripravljeni uporabiti transformirani niz podatkov kot vhod za algoritem za napovedovanje. Zadnji korak je izvoz preoblikovanega nabora podatkov v Amazon S3. V Data Wranglerju lahko izbirate Korak izvoza za samodejno ustvarjanje prenosnega računalnika Jupyter s kodo Amazon SageMaker Processing za obdelavo in izvoz preoblikovanega nabora podatkov v vedro S3. Ker pa naš nabor podatkov vsebuje nekaj več kot 300 zapisov, izkoristimo prednosti Izvozi podatke možnost v Dodaj preoblikovanje za izvoz preoblikovanega nabora podatkov neposredno v Amazon S3 iz Data Wranglerja.
- Izberite Izvozi podatke.
- za S3 lokacija, izberite brskalnik in izberite svoje vedro S3.
- Izberite Izvozi podatke.

Zdaj, ko smo uspešno preoblikovali nabor podatkov bitcoin, lahko uporabimo Amazonska napoved za ustvarjanje napovedi bitcoinov.
Čiščenje
Če ste končali s tem primerom uporabe, počistite vire, ki ste jih ustvarili, da se izognete dodatnim stroškom. Za Data Wrangler lahko zaustavite osnovni primerek, ko končate. Nanašati se na Zaustavite Data Wrangler dokumentacijo za podrobnosti. Druga možnost je, da nadaljujete Del 2 te serije za uporabo tega nabora podatkov za napovedovanje.
Povzetek
Ta objava je pokazala, kako uporabiti Data Wrangler za poenostavitev in pospešitev analize časovnih vrst z uporabo vgrajenih zmogljivosti časovnih vrst. Raziskali smo, kako lahko podatkovni znanstveniki preprosto in interaktivno očistijo, formatirajo, potrdijo in pretvorijo podatke časovnih vrst v želeno obliko za smiselno analizo. Raziskali smo tudi, kako lahko obogatite svojo analizo časovnih vrst z dodajanjem celovitega nabora statističnih funkcij z uporabo Data Wranglerja. Če želite izvedeti več o transformacijah časovnih vrst v Data Wranglerju, glejte Pretvori podatke.
O Author
 Roop Bains je arhitekt rešitev pri AWS, ki se osredotoča na AI/ML. Strastno želi pomagati strankam pri inovacijah in doseganju njihovih poslovnih ciljev z uporabo umetne inteligence in strojnega učenja. V prostem času Roop uživa v branju in pohodništvu.
Roop Bains je arhitekt rešitev pri AWS, ki se osredotoča na AI/ML. Strastno želi pomagati strankam pri inovacijah in doseganju njihovih poslovnih ciljev z uporabo umetne inteligence in strojnega učenja. V prostem času Roop uživa v branju in pohodništvu.
 Nikita Ivkin je uporabni znanstvenik, Amazon SageMaker Data Wrangler.
Nikita Ivkin je uporabni znanstvenik, Amazon SageMaker Data Wrangler.
- Coinsmart. Najboljša evropska borza bitcoinov in kriptovalut.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. PROST DOSTOP.
- CryptoHawk. Altcoin radar. Brezplačen preizkus.
- Vir: https://aws.amazon.com/blogs/machine-learning/prepare-time-series-data-with-amazon-sagemaker-data-wrangler/
- "
- 100
- 116
- 2021
- 7
- 9
- O meni
- pospeši
- čez
- Dodatne
- Prednost
- algoritem
- algoritmi
- vsi
- Amazon
- Analiza
- primerno
- Uporaba
- pristop
- april
- okoli
- umetni
- Umetna inteligenca
- Umetna inteligenca in strojno učenje
- Na voljo
- AWS
- Osnova
- BEST
- Bitcoin
- bitkoin trgovanje
- meja
- BTC
- vgrajeno
- poslovni
- podjetja
- Zmogljivosti
- primeri
- Stroški
- čiščenje
- Koda
- Coin
- Stolpec
- Skupno
- v primerjavi z letom
- kompleksna
- komponenta
- zaupanje
- Konzole
- Vsebuje
- naprej
- bi
- cryptocurrency
- valuta
- Trenutna
- Stranke, ki so
- datum
- znanost o podatkih
- nabor podatkov
- dan
- globlje
- Povpraševanje
- Odkrivanje
- DID
- drugačen
- Ne
- domena
- navzdol
- enostavno
- Učinkovito
- omogočanje
- inženir
- Inženiring
- bistvena
- ocene
- dogodki
- Primer
- Pričakuje
- strokovno znanje
- Izvlečki
- dejavniki
- hitreje
- Feature
- Lastnosti
- končno
- prva
- fiksna
- Pretok
- po
- format
- Obrazci
- polno
- Prihodnost
- ustvarjajo
- Giving
- dobro
- skupina
- Ravnanje
- pomoč
- pomoč
- Pomaga
- Hiša
- Kako
- Kako
- HTTPS
- identificirati
- V drugi
- vključujejo
- Povečajte
- Indeks
- Podatki
- vpogledi
- Intelligence
- IT
- januar
- znano
- UČITE
- učenje
- Stopnja
- Limited
- Seznam
- si
- stroj
- strojno učenje
- Izdelava
- marec
- ML
- Model
- modeli
- Najbolj
- Nove funkcije
- hrup
- prenosnik
- odprite
- open source
- o odprtju
- Možnost
- možnosti
- Ostalo
- drugače
- Vzorec
- obdobja
- politika
- napoved
- Napovedi
- predstaviti
- preprečevanje
- predogled
- Cena
- problem
- Postopek
- Projekt
- projekti
- zagotavljajo
- zagotavlja
- četrtletje
- hitro
- območje
- Surovi
- reading
- razumno
- zapis
- evidence
- zmanjša
- redni
- Razmerje
- Razmerja
- zahteva
- Zahteve
- viri
- pregleda
- prodaja
- Znanost
- Znanstvenik
- Znanstveniki
- Serija
- Storitev
- nastavite
- shutdown
- Podoben
- Enostavno
- Velikosti
- majhna
- So
- rešitve
- specifikacija
- Začetek
- Statistično
- zaloge
- shranjevanje
- strategije
- Strategija
- Uspešno
- ciljna
- tehnike
- skozi
- čas
- Trgovanje
- tradicionalna
- Transform
- Preoblikovanje
- ui
- razumeli
- edinstven
- us
- ameriški dolar
- uporaba
- navadno
- uporabiti
- vrednost
- Poglej
- vizualizacija
- Obseg
- teden
- besede
- leto