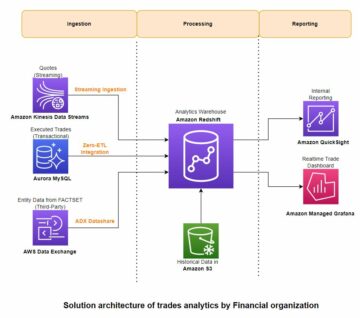
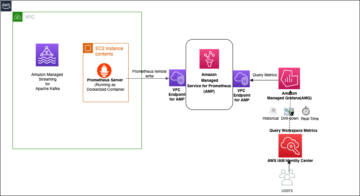
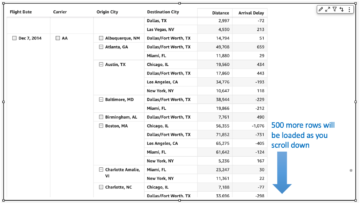
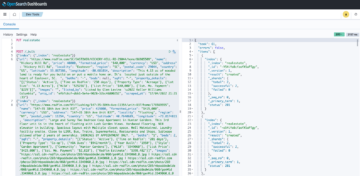
Pri vklopu aplikacij Apache Flink Amazonova upravljana storitev za Apache Flink, imate edinstveno prednost, da izkoristite njegovo naravo brez strežnika. To pomeni, da se vaje za optimizacijo stroškov lahko izvajajo kadar koli – ni jih več treba izvesti v fazi načrtovanja. Z upravljano storitvijo za Apache Flink lahko dodajate in odstranjujete računalništvo s klikom gumba.
Apache Flink je odprtokodno ogrodje za obdelavo toka, ki ga uporablja na stotine podjetij v kritičnih poslovnih aplikacijah in na tisoče razvijalcev, ki imajo za svoje delovne obremenitve potrebe po obdelavi toka. Je zelo razpoložljiv in razširljiv ter ponuja visoko prepustnost in nizko zakasnitev za najzahtevnejše aplikacije za obdelavo toka. Te razširljive lastnosti Apache Flink so lahko ključne za optimizacijo vaših stroškov v oblaku.
Upravljana storitev za Apache Flink je popolnoma upravljana storitev, ki zmanjša kompleksnost gradnje in upravljanja aplikacij Apache Flink. Upravljana storitev za Apache Flink upravlja osnovno infrastrukturo in komponente Apache Flink, ki zagotavljajo trajno stanje aplikacije, meritve, dnevnike in drugo.
V tej objavi lahko izveste o stroškovnem modelu upravljane storitve za Apache Flink, področjih, kjer lahko prihranite pri stroških v svojih aplikacijah Apache Flink, in na splošno pridobite boljše razumevanje vaših cevovodov za obdelavo podatkov. Poglobili smo se v razumevanje vaših stroškov, razumevanje, ali je vaša aplikacija preveč opremljena, kako razmišljati o samodejnem prilagajanju velikosti in načine za optimizacijo vaših aplikacij Apache Flink, da prihranite pri stroških. Nazadnje postavljamo pomembna vprašanja o vaši delovni obremenitvi, da ugotovimo, ali je Apache Flink prava tehnologija za vaš primer uporabe.
Kako se izračunajo stroški v upravljani storitvi za Apache Flink
Če želite optimizirati stroške v zvezi z vašo upravljano storitvijo za aplikacijo Apache Flink, vam lahko pomaga imeti dobro predstavo o tem, kaj je vključeno v cene za upravljano storitev.
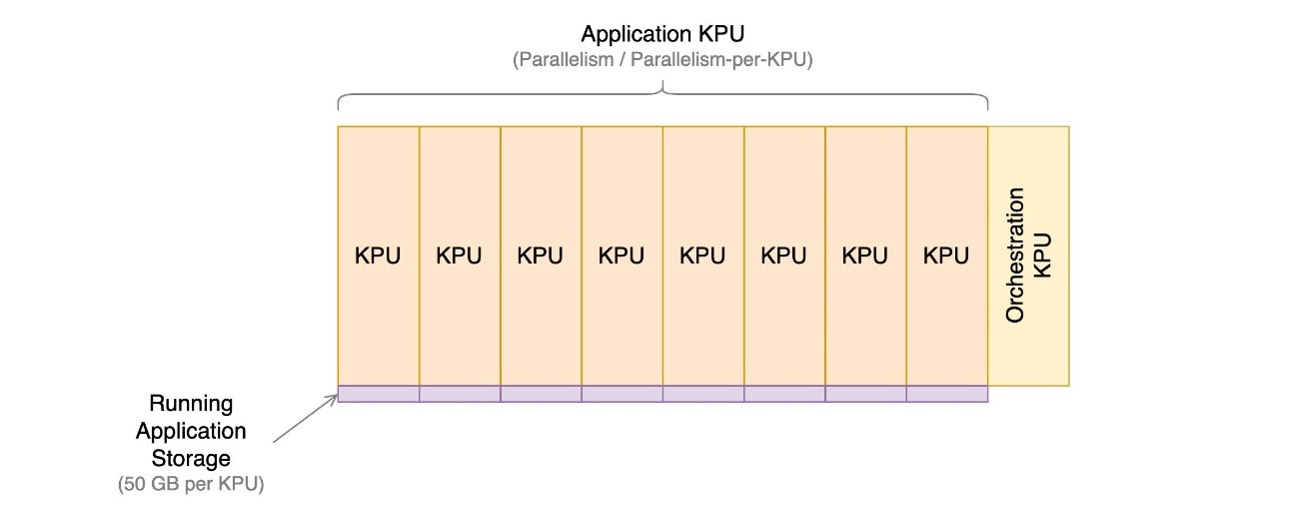
Upravljana storitev za aplikacije Apache Flink je sestavljena iz procesorskih enot Kinesis (KPU), ki so računske instance, sestavljene iz 1 navideznega CPE in 4 GB pomnilnika. Skupno število KPE, dodeljenih aplikaciji, se določi z množenjem dveh parametrov, ki ju neposredno nadzirate:
- Vzporednost – Raven vzporedne obdelave v aplikaciji Apache Flink
- Paralelizem na KPU – Število virov, namenjenih vsakemu paralelizmu
Število KPE je določeno s preprosto formulo: KPU = Parallelism / ParallelismPerKPU, zaokroženo navzgor na naslednje celo število.
Dodaten KPU na aplikacijo se zaračuna tudi za orkestracijo in se ne uporablja neposredno za obdelavo podatkov.
Skupno število KPU-jev določa število virov, CPE-ja, pomnilnika in prostora za shranjevanje aplikacij, dodeljenih aplikaciji. Za vsako KPU aplikacija prejme 1 vCPU in 4 GB pomnilnika, od katerih je 3 GB privzeto dodeljenih delujoči aplikaciji, preostali 1 GB pa se uporablja za upravljanje shrambe stanja aplikacije. Vsak KPU ima tudi 50 GB prostora za shranjevanje, ki je priložen aplikaciji. Apache Flink ohrani stanje aplikacije v pomnilniku do meje, ki jo je mogoče konfigurirati, in prelivanje v priključeni pomnilnik.
Tretja stroškovna komponenta so trajne varnostne kopije aplikacij oz posnetki. To je povsem neobvezno in njegov vpliv na skupne stroške je majhen, razen če obdržite zelo veliko število posnetkov.
V času pisanja stane vsak KPU v regiji AWS vzhod ZDA (Ohio) 0.11 USD na uro, shramba priloženih aplikacij pa stane 0.10 USD na GB na mesec. Cena trajne varnostne kopije aplikacij (posnetki) je 0.023 USD na GB na mesec. Nanašati se na Cene storitve Amazon Managed Service za Apache Flink za najnovejše cene in različne regije.
Naslednji diagram prikazuje relativne deleže stroškovnih komponent za delujočo aplikacijo v upravljani storitvi za Apache Flink. Število KPU nadzirate prek parametrov vzporednosti in vzporednosti na KPU. Trajno shranjevanje varnostnih kopij aplikacij ni predstavljeno.
V naslednjih razdelkih preučujemo, kako spremljati vaše stroške, optimizirati uporabo aplikacijskih virov in poiskati zahtevano število KPE za obravnavo vašega profila prepustnosti.
AWS Cost Explorer in razumevanje vašega računa
Če želite videti, kakšna je vaša trenutna poraba upravljane storitve za Apache Flink, lahko uporabite Raziskovalec stroškov AWS.
Na konzoli Cost Explorer lahko filtrirate glede na časovno obdobje, vrsto uporabe in storitev, da izločite svojo porabo za upravljane storitve za aplikacije Apache Flink. Naslednji posnetek zaslona prikazuje stroške zadnjih 12 mesecev, razčlenjene v cenovne kategorije, opisane v prejšnjem razdelku. Večina porabe v mnogih od teh mesecev je bila iz interaktivnih KPU iz Amazonova upravljana storitev za Apache Flink Studio.
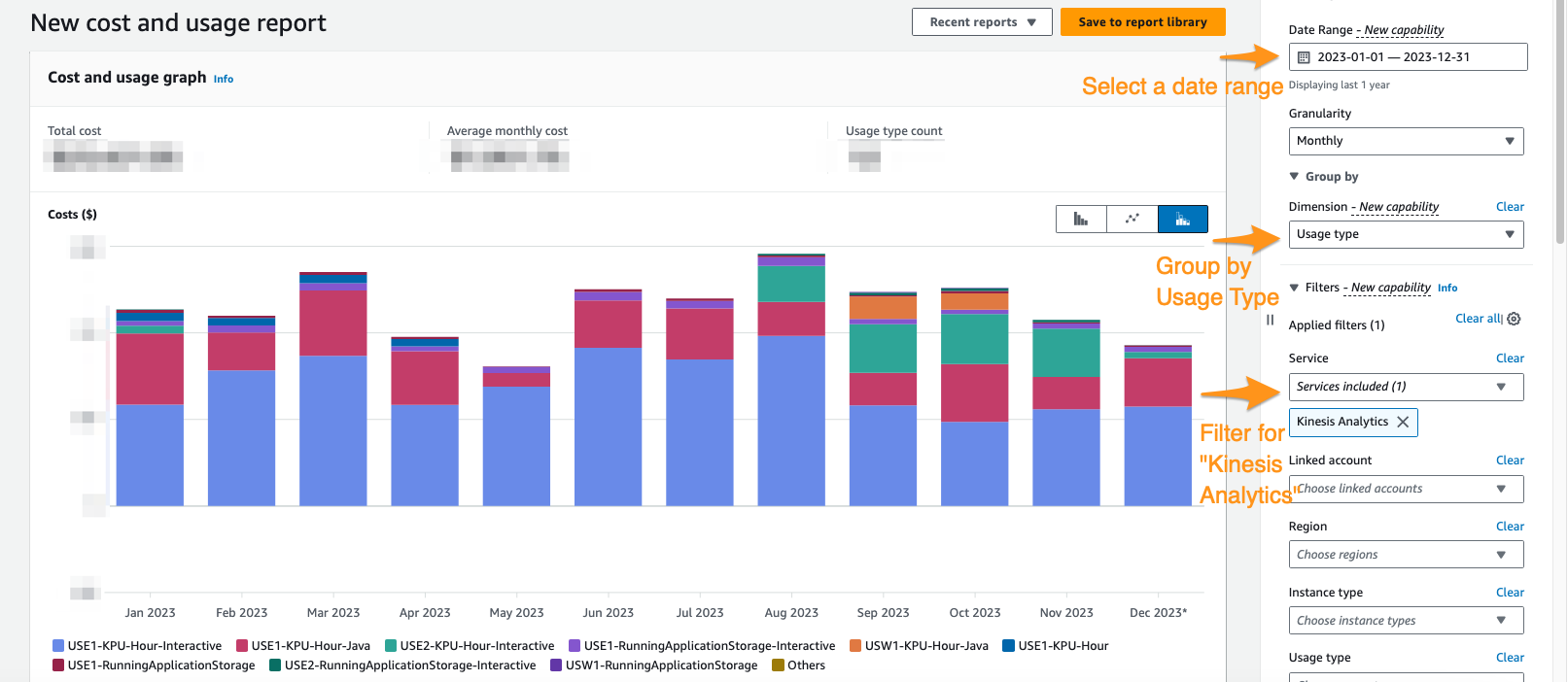
Uporaba Cost Explorerja vam lahko ne le pomaga razumeti vaš račun, ampak pomaga dodatno optimizirati določene aplikacije, ki so morda samodejno ali zaradi zahtev glede prepustnosti presegle pričakovanja. S pravilnim označevanjem aplikacij lahko to porabo razčlenite tudi po aplikacijah, da vidite, katere aplikacije predstavljajo stroške.
Znaki prekomernega zagotavljanja ali neučinkovite uporabe virov
Za zmanjšanje stroškov, povezanih z upravljano storitvijo za aplikacije Apache Flink, preprost pristop vključuje zmanjšanje števila KPU-jev, ki jih uporabljajo vaše aplikacije. Vendar je ključnega pomena zavedanje, da lahko to zmanjšanje negativno vpliva na uspešnost, če ni temeljito ocenjeno in testirano. Če želite hitro oceniti, ali so vaše aplikacije preveč oskrbljene, preglejte ključne indikatorje, kot so poraba procesorja in pomnilnika, funkcionalnost aplikacije in distribucija podatkov. Kljub temu, da lahko ti indikatorji nakazujejo morebitno prekomerno zagotavljanje, je bistvenega pomena, da izvedete testiranje zmogljivosti in potrdite svoje vzorce skaliranja, preden izvedete kakršne koli prilagoditve števila KPU.
Meritve
Analiza meritve za vašo aplikacijo on amazoncloudwatch lahko razkrije jasne signale prekomerne oskrbe. Če je containerCPUUtilization in containerMemoryUtilization meritve dosledno ostajajo pod 20 % v statistično pomembnem obdobju za prometne vzorce vaše aplikacije, bi bilo morda smiselno zmanjšati obseg in dodeliti več podatkov manjšemu številu naprav. Na splošno menimo, da so aplikacije primerno velike, ko containerCPUUtilization giblje med 50–75 %. čeprav containerMemoryUtilization lahko niha čez dan in nanj vpliva optimizacija kode, lahko dosledno nizka vrednost za daljše trajanje kaže na morebitno prekomerno zagotavljanje.
Paralelizem na KPE premalo izkoriščen
Še en subtilen znak, da je vaša aplikacija preveč oskrbljena, je, če je vaša aplikacija izključno vezana na V/I ali izvaja samo preproste klice v baze podatkov in operacije, ki ne zahtevajo CPE. V tem primeru lahko uporabite vzporednost na parameter KPU znotraj upravljane storitve za Apache Flink, da naložite več opravil v eno procesno enoto.
Paralelizem na parameter KPE si lahko ogledate kot merilo gostote delovne obremenitve na enoto računalniških in pomnilniških virov (KPU). Če povečate vzporednost na KPE nad privzeto vrednost 1, postane obdelava bolj gosta, kar eni KPU dodeli več vzporednih procesov.
Naslednji diagram ponazarja, kako z ohranjanjem vzporednosti aplikacije konstantno (na primer 4) in povečanjem vzporednosti na KPE (na primer z 1 na 2) vaša aplikacija uporablja manj virov z isto stopnjo vzporednih izvajanj.
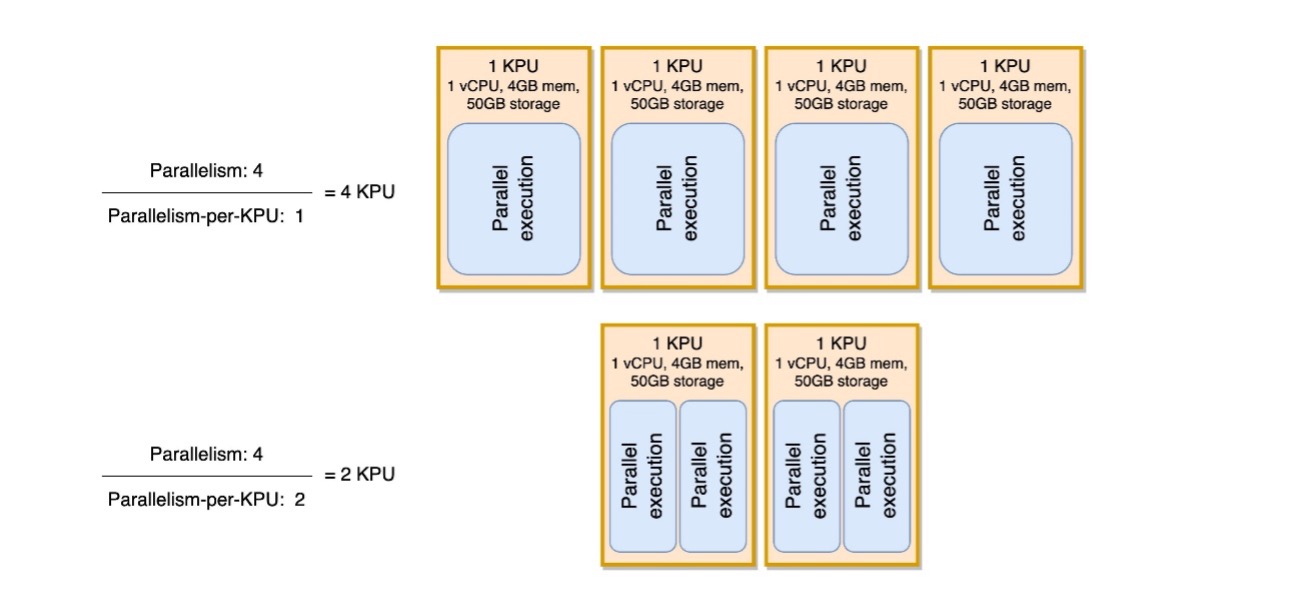
Odločitev o povečanju vzporednosti na KPU, tako kot vsa priporočila v tej objavi, je treba sprejeti zelo previdno. Povečanje vzporednosti na vrednost KPE lahko dodatno obremeni posamezen KPE in mora biti pripravljen tolerirati to obremenitev. Operacije, vezane na V/I, ne bodo bistveno povečale izkoriščenosti procesorja ali pomnilnika, vendar procesna funkcija, ki izračuna številne zapletene operacije glede na podatke, ne bi bila idealna operacija za zbiranje na enem samem KPU, ker bi lahko preobremenila vire. Preizkusite zmogljivost in ocenite, ali je to dobra možnost za vaše aplikacije.
Kako pristopiti k določanju velikosti
Preden vzpostavite upravljano storitev za aplikacijo Apache Flink, je lahko težko oceniti število KPU-jev, ki bi jih morali dodeliti svoji aplikaciji. Na splošno bi morali imeti pred ocenjevanjem dober občutek vzorcev prometa. Razumevanje vaših prometnih vzorcev na podlagi stopnje vnosa megabajtov na sekundo vam lahko pomaga približati začetno točko.
Splošno pravilo je, da lahko začnete z enim KPU na 1 MB/s, ki ga bo obdelala vaša aplikacija. Na primer, če vaša aplikacija procesira 10 MB/s (v povprečju), bi dodelili 10 KPE kot izhodišče za svojo aplikacijo. Upoštevajte, da je to približek na zelo visoki ravni, za katerega menimo, da je učinkovit za splošno oceno. Vendar pa morate na podlagi meritev (CPE, pomnilnik, zakasnitev, splošna uspešnost dela) v daljšem časovnem obdobju tudi preizkusiti zmogljivost in oceniti, ali je to dolgoročno ustrezna velikost ali ne.
Če želite najti ustrezno velikost za vašo aplikacijo, morate aplikacijo Apache Flink povečati in zmanjšati. Kot že omenjeno, imate v upravljani storitvi za Apache Flink dva ločena nadzora: vzporednost in vzporednost na KPU. Ti parametri skupaj določajo raven vzporedne obdelave v aplikaciji in skupne vire računalništva, pomnilnika in pomnilnika, ki so na voljo.
Priporočena metodologija testiranja je spreminjanje vzporednosti ali vzporednosti na KPE ločeno, medtem ko eksperimentirate, da bi našli pravo velikost. Na splošno spremenite samo vzporednost na KPU, da povečate število vzporednih V/I-vezanih operacij, ne da bi povečali skupne vire. Za vse druge primere spremenite samo vzporednost – KPU se bo posledično spremenil – da poiščete pravo velikost za svojo delovno obremenitev.
Lahko tudi nastavite paralelizem na ravni operaterja za omejevanje virov, ponorov ali katerega koli drugega operaterja, ki ga je morda treba omejiti in je neodvisen od mehanizmov skaliranja. To lahko uporabite za aplikacijo Apache Flink, ki bere iz teme Apache Kafka, ki ima 10 particij. z setParallelism() lahko KafkaSource omejite na 10, vendar upravljano storitev za aplikacijo Apache Flink prilagodite na paralelizem, višji od 10, ne da bi za izvor Kafka ustvarili nedejavne naloge. Za druge primere obdelave podatkov je priporočljivo, da vzporednosti operaterja ne nastavite statično na statično vrednost, temveč funkcijo vzporednosti aplikacije, tako da se spreminja, ko se spreminja celotna aplikacija.
Skaliranje in samodejno skaliranje
V upravljani storitvi za Apache Flink je spreminjanje vzporednosti ali vzporednosti na KPU posodobitev konfiguracije aplikacije. Povzroči, da aplikacija samodejno sprejme a Posnetek (razen če je onemogočeno), zaustavite aplikacijo in jo znova zaženite z novo velikostjo ter obnovite stanje iz posnetka. Operacije skaliranja ne povzročijo izgube podatkov ali nedoslednosti, vendar za kratek čas zaustavijo obdelavo podatkov, medtem ko je infrastruktura dodana ali odstranjena. To je nekaj, kar morate upoštevati pri spreminjanju velikosti v produkcijskem okolju.
Med postopkom testiranja in optimizacije priporočamo onemogočanje samodejno skaliranje in spreminjanje vzporednosti in vzporednosti na KPU za iskanje optimalnih vrednosti. Kot že omenjeno, je ročno skaliranje le posodobitev konfiguracije aplikacije in ga je mogoče zagnati prek Konzola za upravljanje AWS ali API z Dejanje UpdateApplication.
Ko najdete optimalno velikost in pričakujete, da se bo vaš vneseni pretok precej razlikoval, se lahko odločite, da omogočite samodejno skaliranje.
V upravljani storitvi za Apache Flink lahko uporabite več vrst samodejnega skaliranja:
- Pripravljeno samodejno skaliranje – To lahko omogočite, da samodejno prilagodite vzporednost aplikacij glede na
containerCPUUtilizationmetrika. Samodejno skaliranje je v novih aplikacijah privzeto omogočeno. Za podrobnosti o algoritmu samodejnega skaliranja glejte Samodejno skaliranje. - Drobnozrnato samodejno skaliranje na osnovi metrike – To je enostavno izvesti. Avtomatizacija lahko temelji na skoraj vseh metrikah, vključno z meritve po meri vaša aplikacija izpostavlja.
- Načrtovano skaliranje – To je lahko koristno, če pričakujete največje delovne obremenitve ob določenih urah dneva ali dnevih v tednu.
Pripravljeno samodejno skaliranje in natančno skaliranje na podlagi metrike se medsebojno izključujeta. Za več podrobnosti o natančnem samodejnem skaliranju na podlagi metrike in načrtovanem skaliranju ter popolnoma delujoč primer kode glejte Omogočite skaliranje na podlagi metrike in načrtovano skaliranje za Amazon Managed Service za Apache Flink.
Optimizacije kode
Drug način za prihranek stroškov za vašo upravljano storitev za aplikacije Apache Flink je optimizacija kode. Neoptimizirana koda bo za izvajanje istih izračunov zahtevala več strojev. Optimiziranje kode bi lahko omogočilo nižjo skupno uporabo virov, kar bi posledično lahko omogočilo zmanjšanje obsega in ustrezno prihranek stroškov.
Prvi korak k razumevanju učinkovitosti kode je prek vgrajenega pripomočka znotraj Apache Flink, imenovanega Grafi plamena.
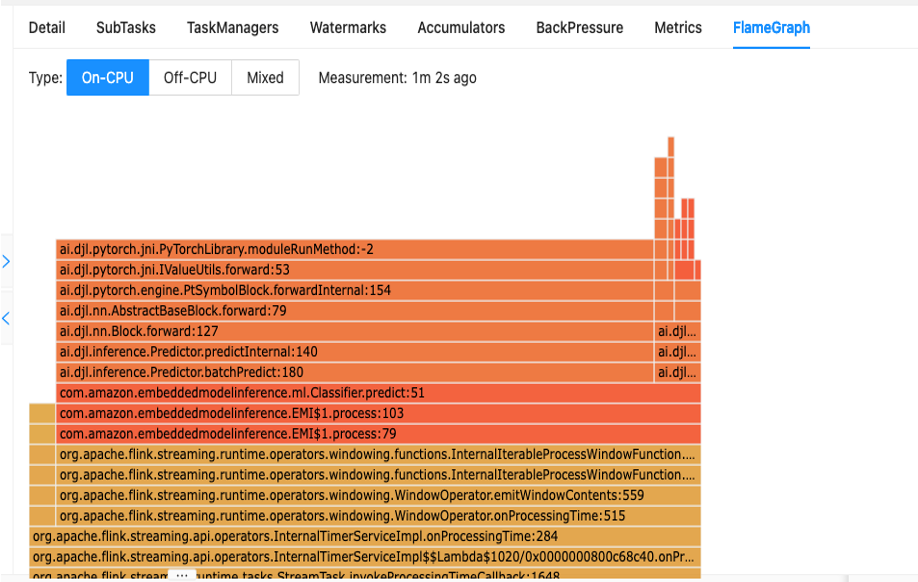
Grafi Flame, ki so dostopni prek nadzorne plošče Apache Flink, vam nudijo vizualno predstavitev sledi vašega sklada. Vsakič, ko se pokliče metoda, se stolpec, ki predstavlja ta klic metode v sledenju sklada, poveča sorazmerno s skupnim številom vzorcev. To pomeni, da če imate neučinkovit kos kode z zelo dolgim stolpcem v grafu plamena, je to lahko razlog za preiskavo, kako narediti to kodo učinkovitejšo. Poleg tega lahko uporabite Profiler Amazon CodeGuru do spremljajte in optimizirajte svoje aplikacije Apache Flink, ki se izvajajo v upravljani storitvi za Apache Flink.
Pri načrtovanju vaših aplikacij je priporočljivo, da uporabite API najvišje ravni, ki je potreben za določeno operacijo v danem trenutku. Apache Flink ponuja štiri ravni podpore za API: Flink SQL, API za tabele, Datastream API in ProcessFunction API-ji z vedno večjo stopnjo kompleksnosti in odgovornosti. Če je vašo aplikacijo mogoče v celoti napisati v API-ju Flink SQL ali Table, lahko uporaba tega pomaga izkoristiti okvir Apache Flink namesto ročnega upravljanja stanja in izračunov.
Izkrivljenost podatkov
Na nadzorni plošči Apache Flink lahko zberete druge koristne informacije o svojih upravljanih storitvah za opravila Apache Flink.
Na nadzorni plošči lahko pregledujete posamezna opravila znotraj grafa vaše prijave za delo. Vsako modro polje predstavlja opravilo, vsako opravilo pa je sestavljeno iz podopravil ali porazdeljenih enot dela za to opravilo. Na ta način lahko prepoznate odstopanje podatkov med podopravili.
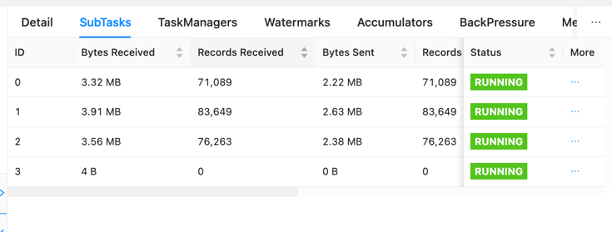
Izkrivljenost podatkov je pokazatelj, da se enemu podopravilu pošlje več podatkov kot drugemu in da podopravilo, ki prejme več podatkov, opravi več dela kot drugo. Če imate takšne simptome izkrivljenosti podatkov, jih lahko odpravite tako, da identificirate vir. Na primer, a GroupBy or KeyedStream lahko ima zakrivljen ključ. To bi pomenilo, da podatki niso enakomerno razporejeni med ključi, kar ima za posledico neenakomerno porazdelitev dela med računalniškimi instancami Apache Flink. Predstavljajte si scenarij, po katerem se razvrščate v skupine userId, vendar vaša aplikacija prejema podatke od enega uporabnika bistveno več kot ostali. To lahko povzroči izkrivljenost podatkov. Če želite to odpraviti, lahko izberete drug ključ združevanja, da enakomerno porazdelite podatke po podopravilih. Upoštevajte, da bo to zahtevalo spremembo kode, da izberete drug ključ.
Ko je odstopanje podatkov odpravljeno, se lahko vrnete na containerCPUUtilization in containerMemoryUtilization metrike za zmanjšanje števila KPE.
Druga področja za optimizacijo kode vključujejo zagotavljanje, da dostopate do zunanjih sistemov prek Async I/O API ali prek združitve podatkovnega toka, ker lahko sinhrona poizvedba v shrambo podatkov povzroči upočasnitve in težave pri preverjanju točk. Poleg tega se obrnite na Odpravljanje težav z delovanjem za težave, ki se lahko pojavijo pri počasnih kontrolnih točkah ali beleženju, kar lahko povzroči povratni pritisk aplikacije.
Kako ugotoviti, ali je Apache Flink prava tehnologija
Če vaša aplikacija ne uporablja nobene zmogljive zmožnosti ogrodja Apache Flink in upravljane storitve za Apache Flink, lahko potencialno prihranite pri stroških z uporabo nečesa preprostejšega.
Slogan Apache Flink je »Stateful Computations over Data Streams«. Stanje v tem kontekstu pomeni, da uporabljate konstrukt stanja Apache Flink. Stanje v Apache Flinku vam omogoča, da si za daljša časovna obdobja zapomnite sporočila, ki ste jih videli v preteklosti, kar omogoča stvari, kot so pretočna združevanja, deduplikacija, obdelava točno enkrat, okno in obdelava poznih podatkov. To stori z uporabo shrambe stanja v pomnilniku. V upravljani storitvi za Apache Flink uporablja RocksDB ohraniti svoje stanje.
Če vaša aplikacija ne vključuje operacij stanja, lahko razmislite o alternativah, kot je npr AWS Lambda, kontejnerske aplikacije ali an Amazonski elastični računalniški oblak (Amazon EC2) primerek, ki izvaja vašo aplikacijo. Kompleksnost Apache Flink v takih primerih morda ni potrebna. Izračuni s stanjem, vključno s predpomnjenimi podatki ali postopki obogatitve, ki zahtevajo neodvisen pomnilnik položaja toka, lahko upravičujejo zmožnosti Apache Flink za spremljanje stanja. Če obstaja možnost, da vaša aplikacija v prihodnosti postane statusna, bodisi zaradi podaljšane hrambe podatkov ali drugih zahtev glede stanja, bi lahko bila nadaljnja uporaba Apache Flink enostavnejša. Organizacije, ki poudarjajo Apache Flink za zmožnosti obdelave toka, se bodo morda raje držale Apache Flink za aplikacije s stanjem in brez stanja, tako da vse njihove aplikacije obdelujejo podatke na enak način. Pred prehodom z Apache Flink na alternative morate upoštevati tudi njegove funkcije orkestracije, kot so natanko enkratna obdelava, zmožnosti razpršitve in porazdeljeno računanje.
Drug dejavnik so vaše zahteve glede zakasnitve. Ker je Apache Flink odličen pri obdelavi podatkov v realnem času, njegova uporaba za aplikacijo s 6-urno ali 1-dnevno zakasnitvijo ni smiselna. Prihranki pri stroških s prehodom na začasni serijski proces izven Preprosta storitev shranjevanja Amazon (Amazon S3), na primer, bi bil pomemben.
zaključek
V tej objavi smo pokrili nekatere vidike, ki jih je treba upoštevati pri poskusih varčevanja stroškov za upravljano storitev za Apache Flink. Razpravljali smo o tem, kako ugotoviti vašo skupno porabo za upravljano storitev, o nekaterih uporabnih meritvah za spremljanje pri zmanjševanju velikosti vaših KPE, o tem, kako optimizirati kodo za pomanjšanje in o tem, kako ugotoviti, ali je Apache Flink pravi za vaš primer uporabe.
Implementacija teh strategij varčevanja s stroški ne samo poveča vašo stroškovno učinkovitost, temveč zagotavlja tudi poenostavljeno in dobro optimizirano uvedbo Apache Flink. Če upoštevate svojo skupno porabo, uporabljate ključne meritve in sprejemate premišljene odločitve o zmanjševanju virov, lahko dosežete stroškovno učinkovito delovanje brez ogrožanja učinkovitosti. Ko krmarite po pokrajini Apache Flink, postane ključnega pomena nenehno ocenjevanje, ali se sklada z vašim posebnim primerom uporabe, tako da lahko dosežete prilagojeno in učinkovito rešitev za vaše potrebe obdelave podatkov.
Če katero od priporočil, obravnavanih v tej objavi, ustreza vašim delovnim obremenitvam, vam priporočamo, da jih preizkusite. Z navedenimi metrikami in nasveti o tem, kako bolje razumeti svoje delovne obremenitve, bi zdaj morali imeti vse, kar potrebujete za učinkovito optimizacijo delovnih obremenitev Apache Flink v upravljani storitvi za Apache Flink. Sledi nekaj koristnih virov, ki jih lahko uporabite za dopolnitev te objave:
O avtorjih
 Jeremy Ber zadnjih 10 let dela v prostoru telemetričnih podatkov kot programski inženir, inženir strojnega učenja in nazadnje podatkovni inženir. Pri AWS je strokovnjak za rešitve za pretakanje, ki podpira Amazonovo upravljano pretakanje za Apache Kafka (Amazon MSK) in Amazonovo upravljano storitev za Apache Flink.
Jeremy Ber zadnjih 10 let dela v prostoru telemetričnih podatkov kot programski inženir, inženir strojnega učenja in nazadnje podatkovni inženir. Pri AWS je strokovnjak za rešitve za pretakanje, ki podpira Amazonovo upravljano pretakanje za Apache Kafka (Amazon MSK) in Amazonovo upravljano storitev za Apache Flink.
 Lorenzo Nicora dela kot višji arhitekt za pretočne rešitve pri AWS in pomaga strankam po EMEA. Že več kot 25 let gradi podatkovno intenzivne sisteme, ki izvirajo iz oblaka, pri čemer dela v finančni industriji prek svetovalnih storitev in za produktna podjetja FinTech. Obširno je izkoristil odprtokodne tehnologije in prispeval k več projektom, vključno z Apache Flink.
Lorenzo Nicora dela kot višji arhitekt za pretočne rešitve pri AWS in pomaga strankam po EMEA. Že več kot 25 let gradi podatkovno intenzivne sisteme, ki izvirajo iz oblaka, pri čemer dela v finančni industriji prek svetovalnih storitev in za produktna podjetja FinTech. Obširno je izkoristil odprtokodne tehnologije in prispeval k več projektom, vključno z Apache Flink.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/real-time-cost-savings-for-amazon-managed-service-for-apache-flink/
- :ima
- : je
- :ne
- :kje
- $GOR
- 1
- 10
- 100
- 11
- 12
- 12 mesecev
- 2%
- 25
- 4
- 50
- a
- O meni
- nad
- dostopen
- Dostop
- ustrezno
- Račun
- Doseči
- čez
- dodajte
- dodano
- Dodatne
- Poleg tega
- prilagodite
- Popravki
- Prednost
- negativno
- vplivajo
- proti
- algoritem
- Poravnava
- vsi
- dodeliti
- dodeljenih
- omogočajo
- omogoča
- Prav tako
- alternative
- Čeprav
- Amazon
- Amazon EC2
- Amazon Web Services
- med
- an
- analizirati
- in
- Še ena
- kaj
- Apache
- Apache Kafka
- API
- API-ji
- uporaba
- aplikacije
- pristop
- primerno
- ustrezno
- približno
- SE
- območja
- AS
- vprašati
- vidiki
- ocenili
- dodeljena
- povezan
- At
- priložen
- poskus
- avto
- Samodejno
- samodejno
- Avtomatizacija
- Na voljo
- povprečno
- AWS
- backup
- varnostne kopije
- bar
- temeljijo
- Osnova
- BE
- ker
- postanejo
- postane
- bilo
- pred
- zadaj
- počutje
- spodaj
- koristi
- Boljše
- med
- Poleg
- Bill
- Modra
- tako
- zavezuje
- Pasovi
- Break
- Broken
- Building
- vgrajeno
- poslovni
- Poslovne aplikacije
- vendar
- Gumb
- by
- izračuna
- izračuna
- klic
- se imenuje
- CAN
- Zmogljivosti
- ki
- primeru
- primeri
- kategorije
- Vzrok
- vzroki
- spremenite
- zaračuna
- Izberite
- jasno
- klik
- Cloud
- Koda
- prihaja
- Podjetja
- kompleksna
- kompleksnost
- komponenta
- deli
- sestavljajo
- Sestavljeno
- ogrozili
- računanje
- izračuni
- Izračunajte
- Ravnanje
- konfiguracija
- Razmislite
- znatno
- premislek
- dosledno
- Konzole
- stalna
- nenehno
- gradnjo
- ozadje
- nadaljevati
- prispevali
- nadzor
- Nadzor
- strošek
- prihranki pri stroških
- stroškovno učinkovito
- stroški
- bi
- štetje
- zajeti
- CPU
- ustvarjajo
- Ustvarjanje
- kritično
- ključnega pomena
- Trenutna
- Stranke, ki so
- Armaturna plošča
- datum
- podatkovni inženir
- izguba podatkov
- obdelava podatkov
- baze podatkov
- Datum
- dan
- Dnevi
- odloča
- Odločitev
- odločitve
- namenjen
- globoko
- privzeto
- zahtevno
- gosto
- Gostota
- uvajanje
- opisano
- oblikovanje
- Podrobnosti
- Ugotovite,
- določi
- določa
- Razvijalci
- diagram
- drugačen
- težko
- neposredno
- onemogočena
- razpravljali
- distribuirati
- porazdeljena
- distribucija
- potop
- ne
- Ne
- tem
- dont
- navzdol
- 2
- trajanje
- vsak
- East
- Učinkovito
- učinkovitosti
- učinkovite
- učinkovito
- odpravo
- odpraviti
- EMEA
- poudarjajo
- omogočajo
- omogočena
- spodbujanje
- inženir
- Izboljša
- obogatitev
- popolnoma
- okolje
- bistvena
- oceniti
- Eter (ETH)
- oceniti
- ocenjevanje
- enakomerno
- preučiti
- Primer
- Ekskluzivno
- vaje
- pričakovati
- pričakovanja
- izkušnje
- eksperimentiranje
- raziskovalec
- obširno
- zunanja
- Faktor
- Lastnosti
- manj
- filter
- financiranje
- Najdi
- FINTECH
- prva
- nihati
- po
- za
- Formula
- je pokazala,
- štiri
- Okvirni
- iz
- v celoti
- funkcija
- funkcionalnost
- nadalje
- Prihodnost
- Gain
- zbiranje
- merilnik
- splošno
- splošno
- dobi
- Daj
- dana
- goes
- dobro
- graf
- grafi
- veliko
- ročaj
- Ravnanje
- se zgodi
- Imajo
- he
- pomoč
- pomoč
- pomoč
- visoka
- na visoki ravni
- več
- zelo
- uro
- Kako
- Kako
- Vendar
- HTML
- http
- HTTPS
- Stotine
- Ideja
- idealen
- identificirati
- identifikacijo
- Mirovanje
- if
- ponazarja
- slika
- vpliv
- izvajati
- Pomembno
- in
- vključujejo
- Vključno
- neskladja
- Povečajte
- narašča
- Neodvisni
- Navedite
- Kazalec
- kazalniki
- individualna
- Industrija
- neučinkovit
- vplivali
- Podatki
- obvestila
- Infrastruktura
- primer
- primerov
- celo
- intenzivno
- interaktivno
- v
- preiskava
- vključujejo
- vključuje
- Vprašanja
- IT
- ITS
- Jeremy
- Job
- Delovna mesta
- pridružite
- Pridružuje
- jpeg
- jpg
- samo
- kafka
- Imejte
- vzdrževanje
- Ključne
- tipke
- Pokrajina
- velika
- večja
- nazadnje
- Latenca
- UČITE
- učenje
- Stopnja
- ravni
- finančni vzvod
- kot
- LIMIT
- obremenitev
- sečnja
- Long
- več
- off
- nizka
- nižje
- stroj
- strojno učenje
- Stroji
- vzdrževati
- Večina
- Znamka
- IZDELA
- Izdelava
- upravlja
- upravljanje
- upravlja
- upravljanje
- Navodilo
- ročno
- več
- Maj ..
- pomeni
- smiselna
- pomeni
- merjenje
- ukrepe
- Mehanizmi
- Spomin
- omenjeno
- sporočil
- Metoda
- Metodologija
- meritev
- Meritve
- morda
- moti
- zmanjšajo
- Model
- monitor
- mesec
- mesecev
- več
- učinkovitejše
- Najbolj
- več
- množenje
- morajo
- vzajemno
- Narava
- Krmarjenje
- potrebno
- Nimate
- potrebe
- Novo
- Naslednja
- št
- zdaj
- Številka
- of
- ponujanje
- Ponudbe
- Ohio
- on
- ONE
- samo
- na
- odprite
- open source
- Delovanje
- operacije
- operater
- optimalna
- optimizacija
- Optimizirajte
- optimizacijo
- Možnost
- or
- orkestracijo
- organizacije
- Ostalo
- ven
- več
- Splošni
- vzporedno
- parameter
- parametri
- zlasti
- preteklosti
- vzorci
- pavza
- za
- opravlja
- performance
- Obdobje
- obdobja
- faza
- kos
- ključno
- načrtovanje
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Točka
- Stališče
- mogoče
- Prispevek
- potencial
- potencialno
- močan
- raje
- prejšnja
- Cena
- cenitev
- model določanja cen
- Postopki
- Postopek
- Procesi
- obravnavati
- Izdelek
- proizvodnja
- profil
- projekti
- pravilno
- Lastnosti
- sorazmerna
- zagotavljajo
- zagotavlja
- izključno
- dal
- poizvedba
- vprašanja
- hitro
- območje
- Oceniti
- precej
- v realnem času
- podatki v realnem času
- prejme
- prejema
- Pred kratkim
- priznajo
- Priporočamo
- Priporočila
- priporočeno
- zmanjša
- zmanjšuje
- zmanjšanje
- Zmanjšanje
- glejte
- pozdrav
- okolica
- regije
- relativna
- ostajajo
- Preostalih
- ne pozabite
- odstrani
- Odstranjeno
- zastopanje
- zastopan
- predstavlja
- zahteva
- obvezna
- zahteva
- Zahteve
- resonator
- vir
- viri
- Odgovornost
- REST
- obnavljanje
- omejiti
- omejeno
- povzroči
- rezultat
- ohranijo
- ohrani
- zadrževanje
- vrnitev
- razkrivajo
- Pravica
- Pravilo
- Run
- tek
- deluje
- Enako
- Vzorec
- Shrani
- Prihranki
- razširljive
- Lestvica
- pomanjšana
- luske
- skaliranje
- Scenarij
- načrtovano
- Oddelek
- oddelki
- glej
- videl
- višji
- Občutek
- poslan
- ločena
- ločeno
- Brez strežnika
- Storitev
- Storitve
- nastavite
- več
- Kratke Hlače
- shouldnt
- Razstave
- podpisati
- signali
- pomemben
- bistveno
- Enostavno
- enostavnejši
- sam
- velikosti
- nagniti
- počasi
- upočasnitve
- majhna
- Posnetek
- So
- Software
- Software Engineer
- Rešitev
- rešitve
- nekaj
- Nekaj
- vir
- Viri
- Vesolje
- specialist
- specifična
- določeno
- preživeti
- prelivanje
- namaz
- SQL
- sveženj
- stati
- Začetek
- Začetek
- Država
- statična
- statistično
- ostati
- Korak
- Držijo
- stop
- shranjevanje
- trgovina
- naravnost
- strategije
- tok
- pretakanje
- racionaliziran
- tokovi
- precejšen
- subtilna
- taka
- predlagajte
- dopolnjujejo
- podpora
- Podpora
- Preverite
- Simptomi
- sistemi
- miza
- prilagojene
- Bodite
- sprejeti
- ob
- Naloga
- Naloge
- Tehnologije
- Tehnologija
- Izraz
- Test
- Testiran
- Testiranje
- kot
- da
- O
- Prihodnost
- Pokrajina
- Vir
- Država
- njihove
- Njih
- te
- stvari
- Pomislite
- tretja
- ta
- temeljito
- tisoče
- skozi
- vsej
- pretočnost
- čas
- krat
- nasveti
- do
- skupaj
- temo
- Skupaj za plačilo
- sledenje
- Prometa
- prehod
- poskusite
- OBRAT
- dva
- tip
- Vrste
- osnovni
- razumeli
- razumevanje
- edinstven
- Enota
- enote
- če
- up-to-date
- Nadgradnja
- us
- Uporaba
- uporaba
- primeru uporabe
- Rabljeni
- koristno
- uporabnik
- uporablja
- uporabo
- pripomoček
- uporaba
- POTRDI
- vrednost
- Vrednote
- razlikujejo
- zelo
- preko
- preživetja
- Poglej
- Virtual
- praktično
- vizualna
- Nalog
- je
- način..
- načini
- we
- web
- spletne storitve
- teden
- Kaj
- kdaj
- ali
- ki
- medtem
- WHO
- bo
- pripravljeni
- z
- v
- brez
- delo
- deluje
- deluje
- bi
- pisanje
- pisni
- let
- jo
- Vaša rutina za
- zefirnet