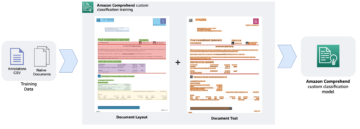
V računalniškem vidu je semantična segmentacija naloga razvrščanja vsake slikovne pike na sliki z razredom iz znanega nabora oznak, tako da si piksli z isto oznako delijo določene značilnosti. Ustvari segmentacijsko masko vhodnih slik. Naslednje slike na primer prikazujejo segmentacijsko masko cat nalepka.
 |
 |
Novembra 2018, Amazon SageMaker napovedal lansiranje algoritma semantične segmentacije SageMaker. S tem algoritmom lahko učite svoje modele z javnim naborom podatkov ali svojim naborom podatkov. Priljubljeni nabori podatkov za segmentacijo slik vključujejo nabor podatkov Common Objects in Context (COCO) in PASCAL Visual Object Classes (PASCAL VOC), vendar so razredi njihovih oznak omejeni in morda boste želeli učiti model na ciljnih objektih, ki niso vključeni v javne zbirke podatkov. V tem primeru lahko uporabite Amazon SageMaker Ground Truth za označevanje lastnega nabora podatkov.
V tej objavi prikazujem naslednje rešitve:
- Uporaba Ground Truth za označevanje nabora podatkov semantične segmentacije
- Pretvorba rezultatov iz Ground Truth v zahtevano obliko vnosa za algoritem semantične segmentacije, vgrajen v SageMaker
- Uporaba algoritma semantične segmentacije za usposabljanje modela in izvajanje sklepanja
Označevanje podatkov semantične segmentacije
Če želimo zgraditi model strojnega učenja za semantično segmentacijo, moramo nabor podatkov označiti na ravni slikovnih pik. Ground Truth vam daje možnost uporabe človeških označevalcev Amazon Mehanični Turk, prodajalci tretjih oseb ali vaša zasebna delovna sila. Če želite izvedeti več o delovni sili, glejte Ustvarjanje in upravljanje delovne sile. Če ne želite sami upravljati delovne sile za etiketiranje, Amazon SageMaker Ground Truth Plus je še ena odlična možnost kot nova storitev označevanja podatkov na ključ, ki vam omogoča hitro ustvarjanje visokokakovostnih naborov podatkov o usposabljanju in zniža stroške do 40 %. Za to objavo vam pokažem, kako ročno označite nabor podatkov s funkcijo samodejnega segmentiranja Ground Truth in množičnim označevanjem z delovno silo Mechanical Turk.
Ročno označevanje z Ground Truth
Decembra 2019 je Ground Truth uporabniškemu vmesniku za označevanje s semantično segmentacijo dodal funkcijo samodejnega segmentiranja, da bi povečal prepustnost označevanja in izboljšal natančnost. Za več informacij glejte Samodejno segmentiranje predmetov pri izvajanju semantičnega segmentacijskega označevanja z Amazon SageMaker Ground Truth. S to novo funkcijo lahko pospešite postopek označevanja pri nalogah segmentacije. Namesto risanja tesno prilegajočega se mnogokotnika ali uporabe orodja za čopič za zajemanje predmeta na sliki, narišete samo štiri točke: na skrajni zgornji, skrajni spodnji, skrajno levi in skrajno desni točki predmeta. Ground Truth vzame te štiri točke kot vhodne podatke in uporablja algoritem Deep Extreme Cut (DEXTR), da ustvari tesno prilegajočo masko okoli predmeta. Za vadnico o uporabi Ground Truth za označevanje semantične segmentacije slike glejte Semantična segmentacija slike. Sledi primer, kako orodje za samodejno segmentacijo samodejno ustvari segmentacijsko masko, potem ko izberete štiri skrajne točke predmeta.


Crowdsourcing označevanje z delovno silo Mechanical Turk
Če imate velik nabor podatkov in ne želite sami ročno označiti na stotine ali tisoče slik, lahko uporabite Mechanical Turk, ki na zahtevo zagotavlja razširljivo človeško delovno silo za dokončanje nalog, ki jih lahko ljudje opravijo bolje kot računalniki. Programska oprema Mechanical Turk formalizira ponudbe za delo za tisoče delavcev, ki so pripravljeni opravljati delo po delih, ko jim ustreza. Programska oprema tudi pridobi opravljeno delo in ga sestavi za vas, vlagatelja zahtevka, ki delavce plača (samo) za zadovoljivo delo. Če želite začeti uporabljati Mechanical Turk, glejte Uvod v Amazon Mechanical Turk.
Ustvarite nalog za označevanje
Sledi primer opravila označevanja Mechanical Turk za nabor podatkov o morski želvi. Nabor podatkov o morskih želvah je iz tekmovanja Kaggle Zaznavanje obraza morske želve, in izbral sem 300 slik nabora podatkov za namene predstavitve. Morska želva ni običajen razred v javnih naborih podatkov, zato lahko predstavlja situacijo, ki zahteva označevanje ogromnega nabora podatkov.
- Na konzoli SageMaker izberite Označevanje delovnih mest v podoknu za krmarjenje.
- Izberite Ustvari nalogo za označevanje.
- Vnesite ime za svoje delovno mesto.
- za Nastavitev vhodnih podatkovtako, da izberete Samodejna nastavitev podatkov.
To ustvari manifest vhodnih podatkov. - za Lokacija S3 za vhodne nize podatkov, vnesite pot za nabor podatkov.

- za Kategorija nalog, izberite Image.
- za Izbor nalogtako, da izberete Semantična segmentacija.

- za Vrste delavcevtako, da izberete Amazon Mehanični Turk.
- Konfigurirajte svoje nastavitve za časovno omejitev opravila, čas poteka opravila in ceno na opravilo.

- Dodajte oznako (za to objavo,
sea turtle) in zagotovite navodila za označevanje. - Izberite ustvarjanje.

Ko nastavite opravilo označevanja, lahko preverite napredek označevanja na konzoli SageMaker. Ko je označeno kot dokončano, lahko izberete opravilo, da preverite rezultate in jih uporabite za naslednje korake.

Transformacija nabora podatkov
Ko dobite rezultate iz Ground Truth, lahko uporabite vgrajene algoritme SageMaker za usposabljanje modela na tem naboru podatkov. Najprej morate pripraviti označeni nabor podatkov kot zahtevani vhodni vmesnik za algoritem semantične segmentacije SageMaker.
Zahtevani vhodni podatkovni kanali
Semantična segmentacija SageMaker pričakuje, da bo vaš nabor podatkov o usposabljanju shranjen Preprosta storitev shranjevanja Amazon (Amazon S3). Nabor podatkov v Amazon S3 naj bi bil predstavljen v dveh kanalih, eden za train in enega za validation, z uporabo štirih imenikov, dveh za slike in dveh za opombe. Pričakuje se, da bodo opombe nestisnjene slike PNG. Nabor podatkov ima lahko tudi preslikavo oznak, ki opisuje, kako so vzpostavljene preslikave opomb. Če ne, algoritem uporabi privzeto. Za sklepanje končna točka sprejema slike z image/jpeg vrsto vsebine. Zahtevana struktura podatkovnih kanalov je naslednja:
Vsaka slika JPG v imeniku za vlak in validacijo ima ustrezno sliko oznake PNG z enakim imenom v train_annotation in validation_annotation imeniki. Ta konvencija poimenovanja pomaga algoritmu, da med usposabljanjem poveže oznako z ustrezno sliko. Vlak, train_annotation, validacija in validation_annotation kanali so obvezni. Opombe so enokanalne slike PNG. Format deluje, dokler metapodatki (načini) na sliki pomagajo algoritmu prebrati slike pripisov v enokanalno 8-bitno nepredznačeno celo število.
Izhod iz opravila označevanja Ground Truth
Izhodi, ustvarjeni iz opravila označevanja Ground Truth, imajo naslednjo strukturo map:
Segmentacijske maske so shranjene v s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Vsaka slika opombe je datoteka .png, poimenovana po indeksu izvorne slike in času, ko je bilo to označevanje slike dokončano. Sledi na primer izvorna slika (Image_1.jpg) in njena segmentacijska maska, ki ju je ustvarila delovna sila Mechanical Turk (0_2022-02-10T17:41:04.724225.png). Opazite, da se indeks maske razlikuje od številke v imenu izvorne slike.
 |
 |
Izhodni manifest opravila označevanja je v /manifests/output/output.manifest mapa. To je datoteka JSON in vsaka vrstica beleži preslikavo med izvorno sliko in njeno oznako ter drugimi metapodatki. Naslednja vrstica JSON beleži preslikavo med prikazano izvorno sliko in njeno opombo:
Izvorna slika se imenuje Image_1.jpg, ime opombe pa je 0_2022-02-10T17:41: 04.724225.png. Za pripravo podatkov kot zahtevanih formatov podatkovnih kanalov algoritma semantične segmentacije SageMaker, moramo spremeniti ime opombe, tako da bo imelo isto ime kot izvorne slike JPG. Prav tako moramo nabor podatkov razdeliti na train in validation imenike za izvorne slike in opombe.
Pretvorite izhod iz opravila označevanja Ground Truth v zahtevano vhodno obliko
Če želite preoblikovati izhod, dokončajte naslednje korake:
- Prenesite vse datoteke iz opravila označevanja iz Amazon S3 v lokalni imenik:
- Preberite datoteko manifesta in spremenite imena pripisov v ista imena kot izvorne slike:
- Razdelite nabor podatkov vlaka in validacije:
- Ustvarite imenik v zahtevani obliki za podatkovne kanale algoritma semantične segmentacije:
- Premaknite slike vlaka in potrditve ter njihove opombe v ustvarjene imenike.
- Za slike uporabite naslednjo kodo:
- Za opombe uporabite naslednjo kodo:
- Naložite nabore podatkov o vlaku in validaciji ter njihove nabore podatkov opomb v Amazon S3:
Usposabljanje modela semantične segmentacije SageMaker
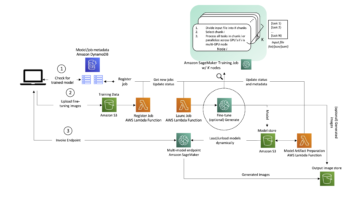
V tem razdelku se sprehodimo skozi korake za usposabljanje vašega modela semantične segmentacije.
Sledite vzorčnemu zvezku in nastavite podatkovne kanale
Sledite lahko navodilom v Algoritem semantične segmentacije je zdaj na voljo v Amazon SageMaker za implementacijo algoritma semantične segmentacije v vaš označeni nabor podatkov. Ta vzorec prenosnik prikazuje primer od konca do konca, ki predstavlja algoritem. V zvezku se naučite, kako usposobiti in gostiti model semantične segmentacije z uporabo popolnoma konvolucijskega omrežja (FCN) algoritem z uporabo Nabor podatkov Pascal VOC za trening. Ker ne nameravam usposobiti modela iz nabora podatkov Pascal VOC, sem preskočil 3. korak (priprava podatkov) v tem zvezku. Namesto tega sem neposredno ustvarjal train_channel, train_annotation_channe, validation_channelin validation_annotation_channel z uporabo lokacij S3, kjer sem shranil svoje slike in opombe:
Prilagodite hiperparametre za svoj nabor podatkov v ocenjevalcu SageMaker
Sledil sem zvezku in ustvaril objekt ocenjevalca SageMaker (ss_estimator), da usposobim svoj algoritem za segmentacijo. Ena stvar, ki jo moramo prilagoditi za nov nabor podatkov, je notri ss_estimator.set_hyperparameters: spremeniti se moramo num_classes=21 do num_classes=2 (turtle in background), pa tudi spremenila sem se epochs=10 do epochs=30 ker je 10 samo za demo namene. Nato sem uporabil primerek p3.2xlarge za usposabljanje modela z nastavitvijo instance_type="ml.p3.2xlarge". Usposabljanje je bilo zaključeno v 8 minutah. Najboljši MIoU (Mean Intersection over Union) 0.846 je dosežen v epohi 11 z pix_acc (odstotek slikovnih pik na vaši sliki, ki so pravilno razvrščene) 0.925, kar je precej dober rezultat za ta majhen nabor podatkov.
Rezultati sklepanja modela
Model sem gostil na nizkocenovnem primerku ml.c5.xlarge:
Nazadnje sem pripravil testni niz 10 slik želve, da vidim rezultat sklepanja usposobljenega modela segmentacije:
Naslednje slike prikazujejo rezultate.

Segmentacijske maske morskih želv so videti natančne in zadovoljen sem s tem rezultatom, usposobljenim na naboru podatkov s 300 slikami, ki so ga označili delavci Mechanical Turk. Raziskujete lahko tudi druga razpoložljiva omrežja, kot je npr omrežje za razčlenjevanje piramidne scene (PSP) or DeepLab-V3 v vzorčnem zvezku z vašim naborom podatkov.
Čiščenje
Izbrišite končno točko, ko končate z njo, da se izognete nadaljnjim stroškom:
zaključek
V tej objavi sem pokazal, kako prilagoditi označevanje podatkov semantične segmentacije in usposabljanje modela z uporabo SageMakerja. Najprej lahko nastavite opravilo označevanja z orodjem za samodejno segmentiranje ali uporabite delovno silo Mechanical Turk (kot tudi druge možnosti). Če imate več kot 5,000 objektov, lahko uporabite tudi samodejno označevanje podatkov. Nato pretvorite izhode vašega opravila označevanja Ground Truth v zahtevane vhodne formate za usposabljanje semantične segmentacije, vgrajeno v SageMaker. Po tem lahko uporabite pospešeno računalniško instanco (kot je p2 ali p3) za usposabljanje modela semantične segmentacije z naslednjim prenosnik in razmestite model na stroškovno učinkovitejši primerek (kot je ml.c5.xlarge). Nazadnje lahko z nekaj vrsticami kode pregledate rezultate sklepanja na svojem testnem naboru podatkov.
Začnite s semantično segmentacijo SageMaker označevanje podatkov in usposabljanje za modele s svojim najljubšim naborom podatkov!
O Author
 Kara Yang je podatkovni znanstvenik v AWS Professional Services. Strastno želi pomagati strankam pri doseganju njihovih poslovnih ciljev s storitvami v oblaku AWS. Organizacijam je pomagala zgraditi rešitve ML v številnih panogah, kot so proizvodnja, avtomobilska industrija, okoljska trajnost in vesoljska industrija.
Kara Yang je podatkovni znanstvenik v AWS Professional Services. Strastno želi pomagati strankam pri doseganju njihovih poslovnih ciljev s storitvami v oblaku AWS. Organizacijam je pomagala zgraditi rešitve ML v številnih panogah, kot so proizvodnja, avtomobilska industrija, okoljska trajnost in vesoljska industrija.
- Coinsmart. Najboljša evropska borza bitcoinov in kriptovalut.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. PROST DOSTOP.
- CryptoHawk. Altcoin radar. Brezplačen preizkus.
- Vir: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- O meni
- pospeši
- pospešeno
- natančna
- Doseči
- doseže
- čez
- dodano
- Aerospace
- algoritem
- algoritmi
- vsi
- Amazon
- razglasitve
- Še ena
- okoli
- Sodelavec
- Avtomatizirano
- samodejno
- avtomobilska
- Na voljo
- AWS
- ozadje
- ker
- BEST
- Boljše
- med
- izgradnjo
- vgrajeno
- poslovni
- zajemanje
- primeru
- nekatere
- spremenite
- kanali
- Izberite
- razred
- razredi
- razvrščeni
- Cloud
- storitev v oblaku
- Koda
- Skupno
- Tekmovanje
- dokončanje
- računalnik
- računalniki
- računalništvo
- zaupanje
- Konzole
- vsebina
- udobje
- Ustrezno
- stroškovno učinkovito
- stroški
- ustvarjajo
- ustvaril
- Stranke, ki so
- prilagodite
- datum
- podatkovni znanstvenik
- globoko
- izkazati
- razporedi
- drugačen
- neposredno
- risanje
- med
- vsak
- omogoča
- konec koncev
- Končna točka
- Vnesite
- okolja
- ustanovljena
- Primer
- Razen
- Pričakuje
- pričakuje
- raziskuje
- ekstremna
- Obraz
- Feature
- prva
- sledi
- po
- format
- iz
- ustvarila
- Cilji
- dobro
- siva
- veliko
- srečna
- pomagal
- pomoč
- Pomaga
- visoka kvaliteta
- gostila
- Kako
- Kako
- HTTPS
- človeškega
- Ljudje
- Stotine
- slika
- slike
- izvajati
- izboljšanje
- vključujejo
- vključeno
- Povečajte
- Indeks
- industrij
- Podatki
- vhod
- primer
- vmesnik
- križišče
- Predstavljamo
- IT
- Job
- Delovna mesta
- znano
- label
- označevanje
- Oznake
- velika
- kosilo
- UČITE
- učenje
- Stopnja
- Limited
- vrstica
- linije
- Seznam
- lokalna
- kraj aktivnosti
- Lokacije
- Long
- Poglej
- stroj
- strojno učenje
- upravljanje
- obvezna
- ročno
- proizvodnja
- map
- kartiranje
- Maska
- Maske
- ogromen
- mehanska
- morda
- ML
- Model
- modeli
- več
- več
- Imena
- poimenovanje
- ostalo
- mreža
- omrežij
- Naslednja
- prenosnik
- Številka
- Ponudbe
- Možnost
- možnosti
- organizacije
- Ostalo
- lastne
- strastno
- odstotkov
- izvajati
- točke
- poligon
- Popular
- Pripravimo
- precej
- Cena
- zasebna
- Postopek
- proizvodnjo
- strokovni
- zagotavljajo
- zagotavlja
- javnega
- namene
- hitro
- RE
- evidence
- predstavljajo
- obvezna
- zahteva
- Rezultati
- pregleda
- Enako
- razširljive
- Znanstvenik
- MORJE
- segmentacija
- izbran
- Storitev
- Storitve
- nastavite
- nastavitev
- Delite s prijatelji, znanci, družino in partnerji :-)
- Prikaži
- pokazale
- Enostavno
- Razmere
- majhna
- So
- Software
- rešitve
- po delih
- začel
- shranjevanje
- Trajnostni razvoj
- ciljna
- Naloge
- skupina
- Test
- O
- Vir
- stvar
- tretjih oseb
- tisoče
- skozi
- pretočnost
- čas
- orodje
- Vlak
- usposabljanje
- Transform
- unija
- uporaba
- potrjevanje
- prodajalci
- Vizija
- WHO
- delo
- delavci
- Delovna sila
- deluje
- Vaša rutina za