Kdaj OpenAI julija 2020 izdal tretjo generacijo svojega modela strojnega učenja (ML), ki je specializiran za ustvarjanje besedila, sem vedel, da je nekaj drugače. Ta model je zadel živce kot noben pred njim. Nenadoma sem slišal prijatelje in kolege, ki jih tehnologija morda zanima, a jim najnovejši napredek na področju umetne inteligence/ML običajno ne zanima veliko, govoriti o tem. Tudi Guardian je pisal članek o tem. Ali, če smo natančni, Model napisal članek, Guardian pa ga je uredil in objavil. Tega ni bilo mogoče zanikati – GPT-3 je spremenil igro.
Ko je bil model izdan, so ljudje takoj začeli prihajati do možnih aplikacij zanj. V nekaj tednih je bilo ustvarjenih veliko impresivnih predstavitev, ki jih lahko najdete na Spletno mesto GPT-3. Ena posebna aplikacija, ki mi je padla v oči, je bila povzemanje besedila – zmožnost računalnika, da prebere določeno besedilo in povzame njegovo vsebino. Gre za eno najtežjih nalog za računalnik, saj združuje dve področji znotraj polja obdelave naravnega jezika (NLP): bralno razumevanje in generiranje besedila. Zato sem bil tako navdušen nad predstavitvami GPT-3 za povzemanje besedila.
Lahko jih preizkusite Spletno mesto Hugging Face Spaces. Moja najljubša trenutno je an uporaba ki ustvarja povzetke novičarskih člankov s samo URL-jem članka kot vnosom.
V tej dvodelni seriji predlagam praktični vodnik za organizacije, da lahko ocenite kakovost modelov povzemanja besedila za svojo domeno.
Pregled vadnice
Številne organizacije, s katerimi sodelujem (dobrodelne ustanove, podjetja, nevladne organizacije), imajo ogromne količine besedil, ki jih morajo prebrati in povzeti – finančna poročila ali članke z novicami, znanstvenoraziskovalne članke, patentne prijave, pravne pogodbe in drugo. Seveda so te organizacije zainteresirane za avtomatizacijo teh nalog s tehnologijo NLP. Za prikaz umetnosti mogočega pogosto uporabljam demo posnetke povzemanja besedila, ki skoraj nikoli ne naredijo vtisa.
Ampak kaj zdaj?
Izziv za te organizacije je, da želijo oceniti modele povzemanja besedil na podlagi povzetkov za veliko, veliko dokumentov – ne enega za drugim. Nočejo zaposliti pripravnika, katerega edina naloga je odpreti aplikacijo, prilepiti dokument, klikniti Povzemajo gumb, počakajte na izpis, ocenite, ali je povzetek dober, in to ponovite za tisoče dokumentov.
To vadnico sem napisal z mislijo na sebe izpred štirih tednov – to je vadnica, ki sem si jo želel imeti takrat, ko sem začel to potovanje. V tem smislu je ciljna publika te vadnice nekdo, ki pozna AI/ML in je že uporabljal modele Transformer, vendar je na začetku svoje poti povzemanja besedila in se želi vanj poglobiti. Ker jo je napisal »začetnik« in je za začetnike, želim poudariti dejstvo, da je ta vadnica a praktični vodnik – ne o praktični vodnik. Prosim, ravnajte s tem, kot da George EP Box je rekel:
![]()
Glede na to, koliko tehničnega znanja je potrebno v tej vadnici: Resda vključuje nekaj kodiranja v Pythonu, vendar večino časa uporabljamo kodo samo za klic API-jev, tako da tudi poglobljeno znanje kodiranja ni potrebno. Koristno je, če ste seznanjeni z nekaterimi koncepti strojnega upravljanja, na primer, kaj to pomeni vlak in razporedi model, koncepti trening, potrjevanjein testni nizi podatkov, in tako naprej. Prav tako se je ukvarjal z Knjižnica transformatorjev pred bi lahko bilo koristno, ker to knjižnico v veliki meri uporabljamo v tej vadnici. Vključujem tudi uporabne povezave za nadaljnje branje teh pojmov.
Ker je to vadnico napisal začetnik, ne pričakujem, da bodo strokovnjaki za NLP in napredni praktiki globokega učenja dobili veliko od te vadnice. Vsaj ne s tehničnega vidika – morda boste še vedno uživali v branju, zato vas prosimo, da še ne odidete! Vendar boste morali biti potrpežljivi glede mojih poenostavitev – poskušal sem živeti v skladu s konceptom, da bi bilo vse v tej vadnici čim bolj preprosto, vendar ne preprostejše.
Struktura te vadnice
Ta serija obsega štiri dele, razdeljene na dve objavi, v katerih gremo skozi različne stopnje projekta povzemanja besedila. V prvi objavi (1. razdelek) začnemo z uvedbo metrike za naloge povzemanja besedila – merilo uspešnosti, ki nam omogoča, da ocenimo, ali je povzetek dober ali slab. Predstavimo tudi nabor podatkov, ki ga želimo povzeti, in ustvarimo izhodišče z uporabo modela brez ML – uporabimo preprosto hevristiko za ustvarjanje povzetka iz danega besedila. Ustvarjanje tega izhodišča je ključnega pomena pri vsakem projektu ML, saj nam omogoča, da kvantificiramo, koliko napredka dosežemo z uporabo umetne inteligence v prihodnosti. Omogoča nam odgovor na vprašanje "Ali se res splača vlagati v tehnologijo AI?"
V drugem prispevku uporabljamo model, ki je bil že vnaprej usposobljen za ustvarjanje povzetkov (razdelek 2). To je mogoče s sodobnim pristopom v ML, imenovanim transferno učenje. To je še en koristen korak, ker v bistvu vzamemo že pripravljen model in ga preizkusimo na našem naboru podatkov. To nam omogoča, da ustvarimo drugo osnovno linijo, ki nam pomaga videti, kaj se zgodi, ko dejansko urimo model na našem naboru podatkov. Pristop se imenuje zero-shot povzemanje, ker model ni bil izpostavljen našemu naboru podatkov.
Po tem je čas, da uporabimo predhodno usposobljen model in ga usposobimo na lastnem naboru podatkov (razdelek 3). To se tudi imenuje fina nastavitev. Modelu omogoča, da se uči iz vzorcev in posebnosti naših podatkov ter se jim počasi prilagaja. Ko usposobimo model, ga uporabimo za ustvarjanje povzetkov (razdelek 4).
Če povzamemo:
- Del 1:
- Oddelek 1: Uporabite model brez ML za določitev izhodišča
- Del 2:
- 2. razdelek: Ustvarjanje povzetkov z modelom zero-shot
- 3. razdelek: Usposobite model povzemanja
- Razdelek 4: Ocenite usposobljeni model
Celotna koda za to vadnico je na voljo v nadaljevanju GitHub repo.
Kaj bomo dosegli do konca te vadnice?
Do konca te vadnice smo ne bo imeti model povzemanja besedila, ki se lahko uporablja v produkciji. Sploh ne bomo imeli dobro model povzemanja (sem vstavite emoji krik)!
Namesto tega bomo imeli izhodišče za naslednjo fazo projekta, ki je eksperimentalna faza. Tu nastopi »znanost« v znanosti o podatkih, saj je zdaj vse v eksperimentiranju z različnimi modeli in različnimi nastavitvami, da bi razumeli, ali je dovolj dober model povzemanja mogoče usposobiti z razpoložljivimi podatki za usposabljanje.
In, če smo povsem transparentni, obstaja velika verjetnost, da se bo ugotovilo, da tehnologija preprosto še ni zrela in da projekt ne bo uresničen. In svoje poslovne deležnike morate pripraviti na to možnost. Ampak to je tema za drugo objavo.
Oddelek 1: Uporabite model brez ML za določitev izhodišča
To je prvi del naše vadnice o nastavitvi projekta povzemanja besedila. V tem razdelku vzpostavimo izhodišče z zelo preprostim modelom, ne da bi dejansko uporabili ML. To je zelo pomemben korak v vsakem projektu ML, saj nam omogoča, da razumemo, koliko vrednosti ML doda v času projekta in ali je vredno vlagati vanj.
Kodo za vadnico najdete v nadaljevanju GitHub repo.
Podatki, podatki, podatki
Vsak projekt ML se začne s podatki! Če je mogoče, moramo vedno uporabiti podatke, povezane s tem, kar želimo doseči s projektom povzemanja besedila. Na primer, če je naš cilj povzeti patentne prijave, bi morali patentne prijave uporabiti tudi za usposabljanje modela. Veliko opozorilo za projekt ML je, da morajo biti podatki o usposabljanju običajno označeni. V kontekstu povzemanja besedila to pomeni, da moramo zagotoviti besedilo, ki ga želimo povzemati, in povzetek (oznako). Le če zagotovite oboje, se lahko model nauči, kako izgleda dober povzetek.
V tej vadnici uporabljamo javno dostopen nabor podatkov, vendar ostanejo koraki in koda popolnoma enaki, če uporabimo nabor podatkov po meri ali zasebni nabor podatkov. In še enkrat, če imate v mislih cilj za svoj model povzemanja besedila in imate ustrezne podatke, raje uporabite svoje podatke, da kar najbolje izkoristite to.
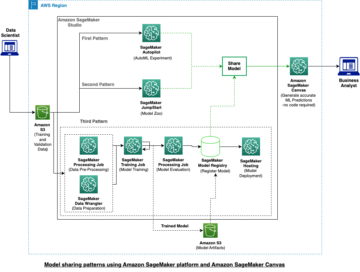
Podatki, ki jih uporabljamo, so nabor podatkov arXiv, ki vsebuje povzetke člankov arXiv in njihove naslove. Za naš namen uporabimo povzetek kot besedilo, ki ga želimo povzeti, naslov pa kot referenčni povzetek. Vsi koraki prenosa in predhodne obdelave podatkov so na voljo v nadaljevanju prenosnik. Potrebujemo an AWS upravljanje identitete in dostopa (IAM), ki dovoljuje nalaganje podatkov v in iz Preprosta storitev shranjevanja Amazon (Amazon S3), da lahko uspešno zaženete ta prenosnik. Nabor podatkov je bil razvit kot del prispevka O uporabi ArXiv kot nabora podatkov in je licenciran pod Creative Commons CC0 1.0 Univerzalna javna domena.
Podatki so razdeljeni v tri nabore podatkov: podatki o usposabljanju, validaciji in preskusu. Če želite uporabiti svoje podatke, se prepričajte, da je tudi to. Naslednji diagram prikazuje, kako uporabljamo različne nabore podatkov.
![]()
Seveda je pogosto vprašanje na tej točki: Koliko podatkov potrebujemo? Kot verjetno že ugibate, je odgovor: odvisno. Odvisno je od tega, kako specializirano je področje (povzemanje patentnih prijav se precej razlikuje od povzemanja novic), kako natančen mora biti model, da je uporaben, koliko naj stane usposabljanje modela itd. K temu vprašanju se bomo vrnili pozneje, ko bomo model dejansko usposobili, vendar je kratko to, da moramo preizkusiti različne velikosti nabora podatkov, ko smo v eksperimentalni fazi projekta.
Kaj naredi dober model?
V mnogih projektih ML je precej preprosto izmeriti zmogljivost modela. To je zato, ker je običajno malo dvoumnosti glede tega, ali je rezultat modela pravilen. Oznake v naboru podatkov so pogosto binarne (True/False, Da/Ne) ali kategorične. V vsakem primeru je v tem scenariju enostavno primerjati izhod modela z oznako in ga označiti kot pravilnega ali nepravilnega.
Pri generiranju besedila postane to bolj zahtevno. Povzetki (oznake), ki jih zagotovimo v našem naboru podatkov, so samo en način za povzemanje besedila. Obstaja pa veliko možnosti za povzetek danega besedila. Torej, tudi če se model ne ujema z našo oznako 1:1, je lahko rezultat še vedno veljaven in uporaben povzetek. Kako torej primerjamo povzetek modela s tistim, ki ga nudimo? Merilo, ki se najpogosteje uporablja pri povzemanju besedila za merjenje kakovosti modela, je ROUGE rezultat. Če želite razumeti mehaniko te metrike, glejte Ultimate Performance Metric v NLP. Če povzamemo, ocena ROUGE meri prekrivanje n-gramov (neprekinjeno zaporedje n postavke) med povzetkom modela (povzetek kandidata) in referenčnim povzetkom (oznaka, ki jo zagotovimo v našem naboru podatkov). A to seveda ni popoln ukrep. Če želite razumeti njegove omejitve, preverite V ROUGE ali ne v ROUGE?
Torej, kako izračunamo rezultat ROUGE? Obstaja kar nekaj paketov Python za izračun te metrike. Da zagotovimo doslednost, moramo v celotnem projektu uporabljati isto metodo. Ker bomo pozneje v tej vadnici uporabili skript za usposabljanje iz knjižnice Transformers, namesto da bi napisali svojega, lahko samo pokukamo v Izvorna koda skripta in kopirajte kodo, ki izračuna rezultat ROUGE:
Z uporabo te metode za izračun ocene zagotovimo, da skozi projekt vedno primerjamo jabolka z jabolki.
Ta funkcija izračuna več rezultatov ROUGE: rouge1, rouge2, rougeLin rougeLsum. "Vsota" v rougeLsum se nanaša na dejstvo, da je ta metrika izračunana za celoten povzetek, medtem ko rougeL se izračuna kot povprečje posameznih stavkov. Torej, kateri rezultat ROUGE naj uporabimo za naš projekt? Spet moramo poskusiti različne pristope v eksperimentalni fazi. Kolikor je vredno, original papir ROUGE navaja, da sta "ROUGE-2 in ROUGE-L dobro delovala pri nalogah povzemanja enega dokumenta", medtem ko sta "ROUGE-1 in ROUGE-L odlična pri ocenjevanju kratkih povzetkov."
Ustvarite osnovno črto
Nato želimo ustvariti osnovno linijo z uporabo preprostega modela brez ML. Kaj to pomeni? Na področju povzemanja besedila številne študije uporabljajo zelo preprost pristop: vzamejo prvo n stavkov besedila in ga razglasite za povzetek kandidata. Nato primerjajo povzetek kandidata z referenčnim povzetkom in izračunajo oceno ROUGE. To je preprost, a zmogljiv pristop, ki ga lahko implementiramo v nekaj vrsticah kode (celotna koda za ta del je v nadaljevanju prenosnik):
Za to oceno uporabljamo testni nabor podatkov. To je smiselno, ker potem, ko usposobimo model, uporabimo isti testni nabor podatkov tudi za končno oceno. Poskušamo tudi različne številke za n: začnemo samo s prvim stavkom kot povzetkom kandidata, nato s prvima dvema stavkoma in na koncu s prvimi tremi stavki.
Naslednji posnetek zaslona prikazuje rezultate za naš prvi model.
![]()
Rezultati ROUGE so najvišji, le prvi stavek je povzetek kandidata. To pomeni, da če vzamete več kot en stavek, postane povzetek preveč podroben in vodi do nižje ocene. To torej pomeni, da bomo kot izhodišče uporabili rezultate za povzetke v enem stavku.
Pomembno je omeniti, da so za tako preprost pristop te številke dejansko precej dobre, zlasti za rouge1 rezultat. Da bi te številke postavili v kontekst, se lahko sklicujemo na Modeli Pegasus, ki prikazuje rezultate najsodobnejšega modela za različne nabore podatkov.
Zaključek in kaj sledi
V 1. delu naše serije smo predstavili nabor podatkov, ki ga uporabljamo v celotnem projektu povzemanja, in metriko za ocenjevanje povzetkov. Nato smo ustvarili naslednjo osnovo s preprostim modelom brez ML.
![]()
v Naslednja objava, uporabljamo model zero-shot – natančneje, model, ki je bil posebej usposobljen za povzemanje besedila v člankih javnih novic. Vendar se ta model sploh ne bo uril na našem naboru podatkov (od tod tudi ime »ničelni strel«).
Kot domačo nalogo prepuščam vam, da ugibate, kako se bo ta model z ničelnim strelom obnesel v primerjavi z našo zelo preprosto osnovo. Po eni strani bo to veliko bolj sofisticiran model (gre dejansko za nevronsko mrežo). Po drugi strani pa se uporablja samo za povzemanje člankov z novicami, zato se lahko bori z vzorci, ki so neločljivo povezani z naborom podatkov arXiv.
O Author
![]() Heiko Hotz je višji arhitekt rešitev za umetno inteligenco in strojno učenje ter vodi skupnost za obdelavo naravnega jezika (NLP) znotraj AWS. Pred to vlogo je bil vodja podatkovne znanosti za Amazonovo službo za stranke v EU. Heiko pomaga našim strankam, da so uspešne na njihovi poti AI/ML na AWS, in je sodeloval z organizacijami v številnih panogah, vključno z zavarovalništvom, finančnimi storitvami, mediji in zabavo, zdravstvom, komunalnimi storitvami in proizvodnjo. V prostem času Heiko čim več potuje.
Heiko Hotz je višji arhitekt rešitev za umetno inteligenco in strojno učenje ter vodi skupnost za obdelavo naravnega jezika (NLP) znotraj AWS. Pred to vlogo je bil vodja podatkovne znanosti za Amazonovo službo za stranke v EU. Heiko pomaga našim strankam, da so uspešne na njihovi poti AI/ML na AWS, in je sodeloval z organizacijami v številnih panogah, vključno z zavarovalništvom, finančnimi storitvami, mediji in zabavo, zdravstvom, komunalnimi storitvami in proizvodnjo. V prostem času Heiko čim več potuje.
- Coinsmart. Najboljša evropska borza bitcoinov in kriptovalut.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. PROST DOSTOP.
- CryptoHawk. Altcoin radar. Brezplačen preizkus.
- Vir: https://aws.amazon.com/blogs/machine-learning/part-1-set-up-a-text-summarization-project-with-hugging-face-transformers/
- '
- "
- &
- 100
- 2020
- O meni
- POVZETEK
- dostop
- natančna
- doseže
- napredno
- napredek
- AI
- vsi
- že
- Amazon
- Dvoumnost
- zneski
- Še ena
- API-ji
- uporaba
- aplikacije
- pristop
- okoli
- Umetnost
- članek
- članki
- Občinstvo
- Na voljo
- povprečno
- AWS
- Izhodišče
- V bistvu
- Začetek
- počutje
- poslovni
- klic
- ki
- ujete
- izziv
- Koda
- Kodiranje
- Skupno
- skupnost
- Podjetja
- v primerjavi z letom
- popolnoma
- Izračunajte
- Koncept
- Vsebuje
- vsebina
- pogodbe
- Ustvarjanje
- po meri
- Za stranke
- Stranke, ki so
- datum
- znanost o podatkih
- globlje
- razvili
- drugačen
- Dokumenti
- Ne
- domena
- Zabava
- zlasti
- vzpostaviti
- EU
- vse
- Primer
- pričakovati
- Strokovnjaki
- oči
- Obraz
- Področja
- končno
- finančna
- finančne storitve
- prva
- po
- Naprej
- je pokazala,
- funkcija
- nadalje
- igra
- ustvarjajo
- generacija
- Cilj
- dogaja
- dobro
- veliko
- Skrbnik
- vodi
- ob
- Glava
- zdravstveno varstvo
- pomoč
- Pomaga
- tukaj
- najem
- Kako
- HTTPS
- velika
- identiteta
- izvajati
- izvajali
- Pomembno
- vključujejo
- Vključno
- individualna
- industrij
- zavarovanje
- Predstavljamo
- vlaganjem
- IT
- Job
- julij
- Ključne
- znanje
- Oznake
- jezik
- Zadnji
- Interesenti
- UČITE
- učenje
- pustite
- Pravne informacije
- Knjižnica
- Licencirano
- Povezave
- malo
- stroj
- strojno učenje
- IZDELA
- Izdelava
- proizvodnja
- znamka
- Stave
- merjenje
- mediji
- moti
- ML
- Model
- modeli
- več
- Najbolj
- naravna
- mreža
- novice
- prenosnik
- številke
- odprite
- Da
- organizacije
- Ostalo
- Papir
- patent
- ljudje
- performance
- perspektiva
- faza
- Točka
- možnosti
- možnost
- mogoče
- Prispevkov
- potencial
- močan
- zasebna
- proizvodnja
- Projekt
- projekti
- predlaga
- zagotavljajo
- zagotavljanje
- javnega
- Namen
- kakovost
- vprašanje
- območje
- RE
- reading
- Poročila
- zahteva
- obvezna
- Raziskave
- Rezultati
- Run
- Je dejal
- Znanost
- Občutek
- Serija
- Storitev
- Storitve
- nastavite
- nastavitev
- Kratke Hlače
- Enostavno
- So
- rešitve
- nekdo
- Nekaj
- prefinjeno
- Vesolje
- prostori
- specializirani
- specializirano
- posebej
- po delih
- Začetek
- začel
- začne
- state-of-the-art
- Države
- shranjevanje
- stres
- Študije
- uspešno
- Uspešno
- Pogovor
- ciljna
- Naloge
- tehnični
- Tehnologija
- Test
- tisoče
- skozi
- vsej
- čas
- Naslov
- usposabljanje
- pregleden
- zdravljenje
- Končni
- razumeli
- Universal
- us
- uporaba
- navadno
- vrednost
- Počakaj
- Kaj
- ali
- WHO
- Wikipedia
- v
- brez
- delo
- delal
- vredno
- pisanje
- X
- nič