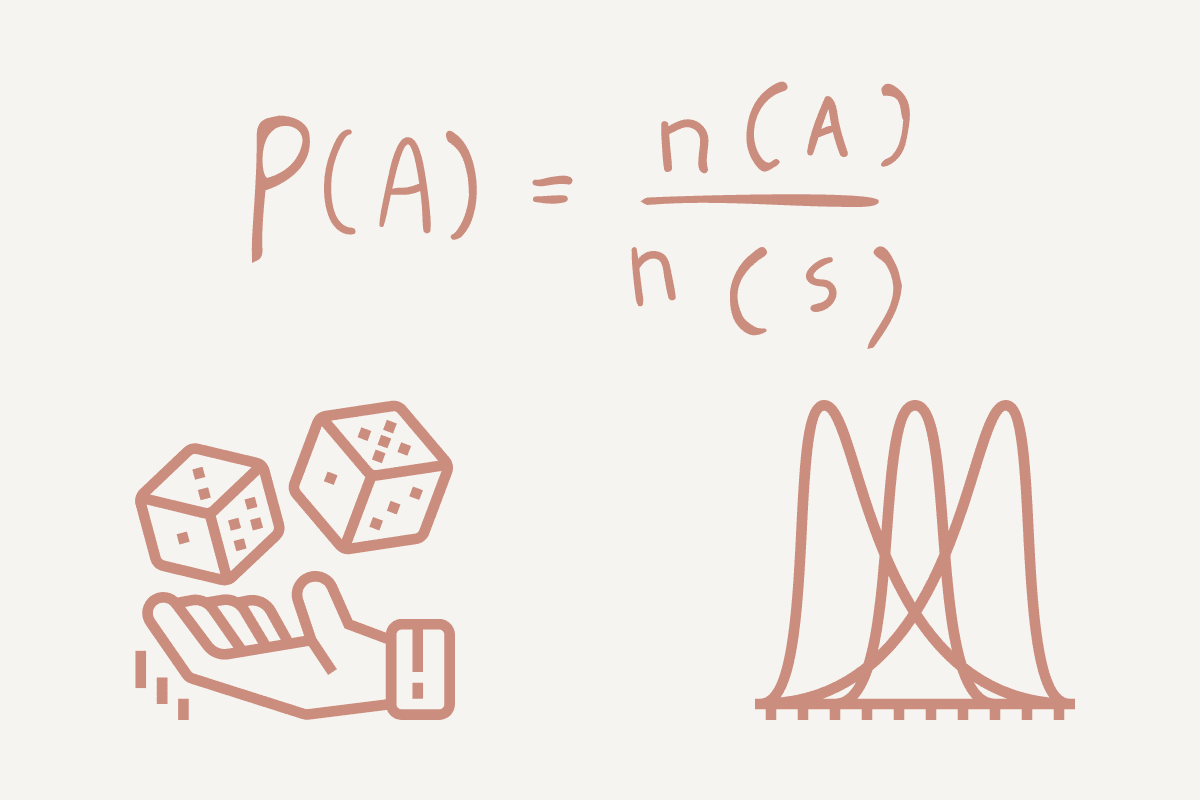
Slika avtorja
Kot podatkovni znanstvenik boste želeli vedeti točnost svojih rezultatov, da zagotovite veljavnost. Potek dela podatkovne znanosti je načrtovan projekt z nadzorovanimi pogoji. Omogoča vam, da ocenite vsako stopnjo in kako je prispevala k vašemu rezultatu.
Verjetnost je merilo verjetnosti, da se dogodek/nekaj zgodi. Je pomemben element v napovedni analizi, ki vam omogoča, da raziščete računalniško matematiko, ki stoji za vašim rezultatom.
Na preprostem primeru si oglejmo met kovanca: z glavami (H) ali z repi (T). Vaša verjetnost bo število načinov, na katere se lahko zgodi dogodek, deljeno s skupnim številom možnih rezultatov.
- Če želimo ugotoviti verjetnost glav, bi bila ta 1 (glava) / 2 (glava in rep) = 0.5.
- Če želimo ugotoviti verjetnost repov, bi bila 1 (repi) / 2 (glave in repi) = 0.5.
Vendar ne želimo, da bi se verjetnost in verjetnost mešali – obstaja razlika. Verjetnost je merilo za pojav določenega dogodka ali izida. Verjetnost se uporabi, ko želite povečati možnosti za pojav določenega dogodka ali izida.
Če razčlenimo – verjetnost se nanaša na možne rezultate, medtem ko se verjetnost nanaša na hipoteze.
Drug izraz, ki ga je treba poznati, so "medsebojno izključujoči se dogodki". To so dogodki, ki se ne zgodijo istočasno. Na primer, ne morete iti desno in levo hkrati. Ali če vržemo kovanec, lahko dobimo glavo ali rep, ne obojega.
Vrste verjetnosti
- Teoretična verjetnost: to se osredotoča na to, kako verjetno je, da se dogodek zgodi, in temelji na temelju sklepanja. Če uporabimo teorijo, je rezultat pričakovana vrednost. Na primeru glave in repa je teoretična verjetnost pristanka na glavi 0.5 ali 50 %.
- Eksperimentalna verjetnost: to se osredotoča na to, kako pogosto se dogodek zgodi med trajanjem preizkusa. Če uporabimo primer glave in repa – če bi kovanec vrgli 10-krat in bi 6-krat pristal na glavi, bi bila eksperimentalna verjetnost, da bi kovanec pristal na glavi, 6/10 ali 60 %.
Pogojna verjetnost je možnost, da se dogodek/izid pojavi na podlagi obstoječega dogodka/izida. Na primer, če delate za zavarovalnico, boste morda želeli ugotoviti verjetnost, da bi oseba lahko plačala svoje zavarovanje na podlagi pogoja, da je vzela stanovanjsko posojilo.
Pogojna verjetnost pomaga Data Scientistom izdelati natančnejše modele in rezultate z uporabo drugih spremenljivk v naboru podatkov.
Porazdelitev verjetnosti je statistična funkcija, ki pomaga opisati možne vrednosti in verjetnosti za naključno spremenljivko znotraj danega obsega. Obseg bo imel možne najmanjše in največje vrednosti, kje so narisane na porazdelitvenem grafu, pa je odvisno od statističnih testov.
Glede na vrsto podatkov, uporabljenih v projektu, lahko ugotovite, katero vrsto distribucije uporabljate. Razdelil jih bom v dve kategoriji: diskretna distribucija in kontinuirana distribucija.
Diskretna distribucija
Diskretna porazdelitev je, ko lahko podatki zavzamejo samo določene vrednosti ali imajo omejeno število rezultatov. Na primer, če bi metali kocko, so vaše omejene vrednosti 1, 2, 3, 4, 5 in 6.
Obstajajo različne vrste diskretne distribucije. Na primer:
- Diskretna enakomerna porazdelitev ko so vsi izidi enako verjetni. Če uporabimo primer metanja šeststrane kocke, obstaja enaka verjetnost, da lahko pristane na 1, 2, 3, 4, 5 ali 6 – ⅙. Vendar pa je težava z diskretno enakomerno distribucijo v tem, da nam ne zagotavlja ustreznih informacij, ki bi jih podatkovni znanstveniki lahko uporabili in uporabili.
- Bernoullijeva distribucija je druga vrsta diskretne porazdelitve, kjer ima poskus samo dva možna izida, ali da ali ne, 1 ali 2, res ali ne. To lahko uporabite, ko vržete kovanec z glavo ali repom. Pri uporabi Bernoullijeve porazdelitve imamo verjetnost enega od izidov (p) in jo lahko odštejemo od skupne verjetnosti (1), predstavljene kot (1-p).
- Binomna porazdelitev je zaporedje Bernoullijevih dogodkov in je diskretna verjetnostna porazdelitev, ki lahko povzroči samo dva možna rezultata v poskusu, bodisi uspeh ali neuspeh. Ko vržete kovanec, bo verjetnost, da vržete kovanec, vedno 1.5 ali ½ v vsakem izvedenem poskusu.
- Poissonova porazdelitev je porazdelitev tega, kolikokrat je verjetno, da se bo dogodek zgodil v določenem obdobju ali razdalji. Namesto da bi se osredotočil na dogodek, se osredotoča na pogostost dogodka, ki se zgodi v določenem intervalu. Na primer, če gre 12 avtomobilov po določeni cesti ob 11. uri vsak dan, lahko uporabimo Poissonovo porazdelitev, da ugotovimo, koliko avtomobilov gre po tej cesti ob 11. uri v enem mesecu.
Kontinuirana distribucija
Za razliko od diskretnih porazdelitev, ki imajo končne rezultate, imajo zvezne porazdelitve kontinualne rezultate. Te porazdelitve so običajno prikazane kot krivulja ali črta na grafu, saj so podatki zvezni.
- Običajna porazdelitev je tisti, za katerega ste morda že slišali, saj se najpogosteje uporablja. Gre za simetrično porazdelitev vrednosti okoli povprečja, brez poševnosti. Podatki sledijo obliki zvona, ko so narisani, kjer je srednji obseg povprečje. Na primer, značilnosti, kot so višina in rezultati IQ, sledijo normalni porazdelitvi.
- T-Distribucija je vrsta zvezne porazdelitve, ki se uporablja, kadar standardna deviacija populacije (σ) ni znana in je velikost vzorca majhna (n<30). Sledi enaki obliki kot normalna porazdelitev, zvonasta krivulja. Na primer, če gledamo, koliko čokoladnih tablic je bilo prodanih na dan, bi uporabili običajno porazdelitev. Če pa želimo preveriti, koliko je bilo prodanih v določeni uri, bomo uporabili t-distribucijo.
- Eksponentna porazdelitev je vrsta zvezne porazdelitve verjetnosti, ki se osredotoča na količino časa, preden se zgodi dogodek. Na primer, morda želimo preučiti potrese in lahko uporabimo eksponentno porazdelitev. Količina časa od te točke do trenutka, ko pride do potresa. Eksponentna porazdelitev je narisana kot ukrivljena črta in eksponentno predstavlja verjetnosti.
Iz zgoraj navedenega lahko vidite, kako lahko podatkovni znanstveniki uporabijo verjetnost, da bi razumeli več podatkov in odgovorili na vprašanja. Za podatkovne znanstvenike je zelo koristno, da poznajo in razumejo možnosti, da se dogodek zgodi, in so lahko zelo učinkoviti v procesu odločanja.
Nenehno boste delali s podatki in o njih se morate naučiti več, preden izvedete kakršno koli analizo. Če si ogledate distribucijo podatkov, lahko dobite veliko informacij, ki jih lahko uporabite za prilagoditev svoje naloge, procesa in modela, da bodo zadostili distribuciji podatkov.
To skrajša vaš čas, ki ga porabite za razumevanje podatkov, zagotavlja učinkovitejši potek dela in ustvari natančnejše rezultate.
Veliko konceptov znanosti o podatkih temelji na osnovah verjetnosti.
Nisha Arya je podatkovni znanstvenik in samostojni tehnični pisec. Še posebej jo zanima zagotavljanje kariernih nasvetov ali vadnic o podatkovni znanosti in na teoriji temelječega znanja o podatkovni znanosti. Prav tako želi raziskati različne načine, na katere umetna inteligenca koristi/lahko prispeva k dolgoživosti človeškega življenja. Zavzeta učenka, ki želi razširiti svoje tehnično znanje in pisne sposobnosti, hkrati pa pomaga usmerjati druge.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://www.kdnuggets.com/2023/02/importance-probability-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-importance-of-probability-in-data-science
- 1
- 10
- 11
- a
- Sposobna
- O meni
- o IT
- nad
- natančnost
- natančna
- nasveti
- vsi
- Dovoli
- vedno
- znesek
- Analiza
- in
- Še ena
- odgovor
- zdi
- uporabna
- Uporabi
- okoli
- umetni
- Umetna inteligenca
- bari
- temeljijo
- pred
- zadaj
- počutje
- Bell
- koristi
- Break
- razširiti
- ne more
- Kariera
- avtomobili
- kategorije
- nekatere
- kvote
- lastnosti
- čokolada
- Coin
- podjetje
- koncepti
- stanje
- Pogoji
- zmeden
- nenehno
- neprekinjeno
- Continuum
- nadzorom
- krivulja
- datum
- znanost o podatkih
- podatkovni znanstvenik
- dan
- Odločanje
- opisati
- odstopanje
- Polnilna postaja
- Razlika
- drugačen
- razdalja
- distribucija
- Distribucije
- deljeno
- dont
- navzdol
- med
- vsak
- potres
- Učinkovito
- bodisi
- zagotovitev
- enako
- Event
- dogodki
- Tudi vsak
- vsak dan
- Primer
- Ekskluzivno
- obstoječih
- Pričakuje
- poskus
- raziskuje
- eksponentna
- eksponentno
- Napaka
- Slika
- Najdi
- Osredotoča
- osredotoča
- sledi
- sledi
- obrazec
- Fundacija
- svobodni
- frekvenca
- pogosto
- iz
- funkcija
- Osnove
- dobili
- Daj
- dana
- Go
- graf
- vodi
- Zgodi se
- Glava
- glave
- Slišal
- višina
- pomoč
- Pomaga
- Hiša
- Kako
- Vendar
- HTTPS
- človeškega
- Pomembnost
- Pomembno
- in
- Povečajte
- Podatki
- zavarovanje
- Intelligence
- zainteresirani
- IT
- KDnuggets
- Keen
- Vedite
- znanje
- Država
- pristanek
- UČITE
- učenec
- življenje
- Verjeten
- Limited
- vrstica
- posojila
- dolgoživost
- Poglej
- si
- Sklop
- več
- math
- največja
- merjenje
- Bližnji
- minimalna
- Model
- modeli
- mesec
- več
- Najbolj
- Nimate
- normalno
- Številka
- ONE
- Ostalo
- drugi
- Rezultat
- zlasti
- zlasti
- Plačajte
- izvajati
- Obdobje
- oseba
- načrtovano
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Točka
- prebivalstvo
- možnost
- mogoče
- Napovedna analiza
- verjetnost
- problem
- Postopek
- proizvodnjo
- Projekt
- zagotavljajo
- zagotavlja
- zagotavljanje
- vprašanja
- naključno
- območje
- zmanjšuje
- pomembno
- zastopan
- predstavlja
- Rezultati
- cesta
- Roll
- Valjanje
- Enako
- Znanost
- Znanstvenik
- Znanstveniki
- iskanju
- Zaporedje
- Oblikujte
- Enostavno
- Velikosti
- nagniti
- spretnosti
- majhna
- prodaja
- specifična
- določeno
- porabljen
- Stage
- standardna
- Začetek
- Statistično
- uspeh
- taka
- Bodite
- Naloga
- tech
- tehnični
- testi
- O
- Teoretični
- čas
- krat
- do
- metati
- Skupaj za plačilo
- proti
- Res
- vaje
- Vrste
- tipično
- razumeli
- razumevanje
- us
- uporaba
- veljavnost
- vrednost
- Vrednote
- spremenljivke
- načini
- Kaj
- ki
- Medtem ko
- bo
- želje
- v
- potek dela
- deluje
- bi
- Pisatelj
- pisanje
- Vaša rutina za
- zefirnet








