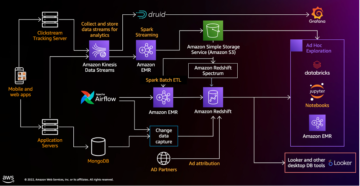
Apaška ledena gora je oblika odprte tabele za zelo velike analitične nabore podatkov, ki zajema informacije metapodatkov o stanju naborov podatkov, ko se razvijajo in spreminjajo skozi čas. Dodaja tabele v računalniške mehanizme, vključno s Spark, Trino, PrestoDB, Flink in Hive, z uporabo visoko zmogljivega formata tabele, ki deluje tako kot tabela SQL. Iceberg je postal zelo priljubljen zaradi svoje podpore za transakcije ACID v podatkovnih jezerih in funkcij, kot so razvoj sheme in particije, potovanje skozi čas in povrnitev nazaj.
Integracijo Apache Iceberg podpirajo analitične storitve AWS, vključno z Amazonski EMR, Amazonska Atenain AWS lepilo. Amazon EMR lahko zagotovi gruče s Spark, Hive, Trino in Flink, ki lahko poganjajo Iceberg. Začenši z različico Amazon EMR 6.5.0, lahko uporabite Iceberg s svojo gručo EMR brez potrebe po zagonskem dejanju. V začetku leta 2022 je AWS objavil splošno razpoložljivost transakcij Athena ACID, ki jih poganja Apache Iceberg. Nedavno izdan Poizvedovalni mehanizem Athena različica 3 zagotavlja boljšo integracijo s formatom tabele Iceberg. AWS Glue 3.0 in novejši podpira ogrodje Apache Iceberg za podatkovna jezera.
V tej objavi razpravljamo o tem, kaj stranke želijo v sodobnih podatkovnih jezerih in kako Apache Iceberg pomaga pri reševanju potreb strank. Nato se sprehodimo skozi rešitev za izgradnjo visoko zmogljivega in razvijajočega se podatkovnega jezera Iceberg Preprosta storitev shranjevanja Amazon (Amazon S3) in obdelujte inkrementalne podatke z izvajanjem stavkov SQL za vstavljanje, posodabljanje in brisanje. Nazadnje vam pokažemo, kako prilagoditi zmogljivost postopka za izboljšanje zmogljivosti branja in pisanja.
Kako Apache Iceberg obravnava tisto, kar stranke želijo v sodobnih podatkovnih jezerih
Vedno več strank gradi podatkovna jezera s strukturiranimi in nestrukturiranimi podatki za podporo številnim uporabnikom, aplikacijam in analitičnim orodjem. Obstaja povečana potreba po podatkovnih jezerih za podporo funkcij, kot so baze podatkov, kot so transakcije ACID, posodobitve in brisanja na ravni zapisov, potovanje skozi čas in povrnitev nazaj. Apache Iceberg je zasnovan tako, da podpira te funkcije na stroškovno učinkovitih petabajtnih podatkovnih jezerih na Amazon S3.
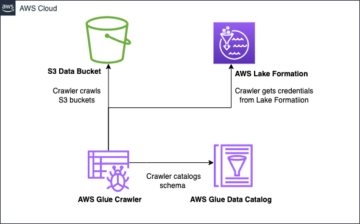
Apache Iceberg obravnava potrebe strank z zajemanjem bogatih metapodatkov o naboru podatkov v času, ko so posamezne podatkovne datoteke ustvarjene. V arhitekturi tabele Iceberg so tri plasti: katalog Iceberg, metapodatkovna plast in podatkovna plast, kot je prikazano na naslednji sliki (vir).

Katalog Iceberg shrani kazalec metapodatkov na datoteko metapodatkov trenutne tabele. Ko izbrana poizvedba bere tabelo Iceberg, gre mehanizem poizvedb najprej v katalog Iceberg, nato pa pridobi lokacijo trenutne datoteke z metapodatki. Kadarkoli pride do posodobitve tabele Iceberg, se ustvari nov posnetek tabele, kazalec metapodatkov pa kaže na trenutno datoteko metapodatkov tabele.
Sledi primer kataloga Iceberg z implementacijo AWS Glue. Ogledate si lahko ime baze podatkov, lokacijo (pot S3) tabele Iceberg in lokacijo metapodatkov.

Metapodatkovna plast ima tri vrste datotek: metapodatkovno datoteko, seznam manifestov in datoteko manifestov v hierarhiji. Na vrhu hierarhije je datoteka z metapodatki, ki shranjuje informacije o shemi tabele, informacije o particiji in posnetke. Posnetek kaže na seznam manifestov. Seznam manifestov vsebuje informacije o vsaki datoteki manifesta, ki sestavlja posnetek, na primer lokacijo datoteke manifesta, particije, ki jim pripada, ter spodnje in zgornje meje za stolpce particij za podatkovne datoteke, ki jim sledi. Datoteka manifesta sledi podatkovnim datotekam in dodatnim podrobnostim o vsaki datoteki, kot je oblika datoteke. Vse tri datoteke delujejo v hierarhiji za sledenje posnetkom, shemi, particioniranju, lastnostim in podatkovnim datotekam v tabeli Iceberg.
Podatkovna plast ima posamezne podatkovne datoteke tabele Iceberg. Iceberg podpira široko paleto formatov datotek, vključno s Parquet, ORC in Avro. Ker tabela Iceberg sledi posameznim podatkovnim datotekam, namesto da kaže le na lokacijo particije s podatkovnimi datotekami, izolira operacije pisanja od operacij branja. Podatkovne datoteke lahko kadar koli zapišete, vendar le izrecno potrdite spremembo, ki ustvari novo različico posnetka in metapodatkovnih datotek.
Pregled rešitev
V tej objavi vas vodimo skozi rešitev za izgradnjo visoko zmogljivega podatkovnega jezera Apache Iceberg na Amazon S3; obdelava inkrementalnih podatkov s stavki SQL za vstavljanje, posodabljanje in brisanje; in nastavite tabelo Iceberg, da izboljšate zmogljivost branja in pisanja. Naslednji diagram ponazarja arhitekturo rešitve.

Za prikaz te rešitve uporabljamo Ocene kupcev Amazon nabor podatkov v vedru S3 (s3://amazon-reviews-pds/parquet/). V primeru resnične uporabe bi bili to neobdelani podatki, shranjeni v vedru S3. Velikost podatkov lahko preverimo z naslednjo kodo v Vmesnik ukazne vrstice AWS (AWS CLI):
Skupno število objektov je 430, skupna velikost pa 47.4 GiB.
Za nastavitev in testiranje te rešitve opravimo naslednje korake na visoki ravni:
- Nastavite vedro S3 v izbranem območju za shranjevanje pretvorjenih podatkov v obliki tabele Iceberg.
- Zaženite gručo EMR z ustreznimi konfiguracijami za Apache Iceberg.
- Ustvarite zvezek v EMR Studio.
- Konfigurirajte sejo Spark za Apache Iceberg.
- Pretvorite podatke v obliko tabele Iceberg in premaknite podatke v kurirano območje.
- Zaženite poizvedbe za vstavljanje, posodabljanje in brisanje v Atheni za obdelavo inkrementalnih podatkov.
- Izvedite nastavitev zmogljivosti.
Predpogoji
Če želite slediti tem navodilom, morate imeti AWS račun s AWS upravljanje identitete in dostopa (IAM), ki ima zadosten dostop za zagotavljanje potrebnih virov.
Nastavite vedro S3 za podatke Iceberg v kuriranem območju v vašem podatkovnem jezeru
Izberite regijo, v kateri želite ustvariti vedro S3, in podajte edinstveno ime:
Zaženite gručo EMR za izvajanje opravil Iceberg z uporabo Spark
Gručo EMR lahko ustvarite iz Konzola za upravljanje AWS, Amazon EMR CLI, oz Komplet za razvoj oblaka AWS (AWS CDK). Za to objavo vas vodimo skozi postopek ustvarjanja gruče EMR iz konzole.
- Na konzoli Amazon EMR izberite Ustvarite gručo.
- Izberite Dodatne možnosti.
- za Konfiguracija programske opreme, izberite najnovejšo izdajo Amazon EMR. Od januarja 2023 je zadnja izdaja 6.9.0. Iceberg zahteva izdajo 6.5.0 in novejše.
- Izberite JupyterEnterpriseGateway in Spark kot programsko opremo za namestitev.
- za Uredite nastavitve programske opremetako, da izberete Vnesite konfiguracijo in vnesite
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - Druge nastavitve pustite privzete in izberite Naslednji.

- za strojna oprema, uporabite privzeto nastavitev.
- Izberite Naslednji.
- za Ime gruče, vnesite ime. Uporabljamo
iceberg-blog-cluster. - Preostale nastavitve pustite nespremenjene in izberite Naslednji.
- Izberite Ustvarite gručo.
Ustvarite zvezek v EMR Studio
Zdaj vam bomo predstavili, kako ustvariti zvezek v programu EMR Studio s konzole.
- Na konzoli IAM, ustvarite storitveno vlogo EMR Studio.
- Na konzoli Amazon EMR izberite Studio EMR.
- Izberite Začnite.
O Začnite stran se prikaže v novem zavihku.
- Izberite Ustvari Studio v novem zavihku.
- Vnesite ime. Uporabljamo iceberg-studio.
- Izberite isti VPC in podomrežje kot za gručo EMR in privzeto varnostno skupino.
- Izberite AWS upravljanje identitete in dostopa (IAM) za preverjanje pristnosti in izberite vlogo storitve EMR Studio, ki ste jo pravkar ustvarili.
- Izberite pot S3 za Varnostno kopiranje delovnih prostorov.
- Izberite Ustvari Studio.
- Ko je Studio ustvarjen, izberite URL za dostop do Studia.
- Na nadzorni plošči EMR Studio izberite Ustvari delovni prostor.
- Vnesite ime za svoj delovni prostor. Uporabljamo
iceberg-workspace. - Razširi Napredna konfiguracija In izberite Priključite delovni prostor gruči EMR.
- Izberite gručo EMR, ki ste jo ustvarili prej.
- Izberite Ustvari delovni prostor.
- Izberite ime delovnega prostora, da odprete nov zavihek.
V podoknu za krmarjenje je zvezek z enakim imenom kot delovni prostor. V našem primeru je to delovni prostor ledene gore.
- Odprite zvezek.
- Ko ste pozvani, da izberete jedro, izberite Spark.
Konfigurirajte sejo Spark za Apache Iceberg
Uporabite naslednjo kodo in navedite svoje ime vedra S3:
To nastavi naslednje konfiguracije sej Spark:
- spark.sql.catalog.demo – Registrira katalog Spark z imenom demo, ki uporablja vtičnik kataloga Iceberg Spark.
- spark.sql.catalog.demo.catalog-impl – Predstavitveni katalog Spark uporablja AWS Glue kot fizični katalog za shranjevanje informacij o bazi podatkov Iceberg in tabelah.
- spark.sql.catalog.demo.warehouse – Demo katalog Spark shranjuje vse metapodatke in podatkovne datoteke Iceberg pod korensko potjo, ki jo definira ta lastnost:
s3://iceberg-curated-blog-data. - spark.sql.extensions – Doda podporo razširitvam Iceberg Spark SQL, ki vam omogočajo izvajanje postopkov Iceberg Spark in nekaterih ukazov SQL samo za Iceberg (to uporabite v kasnejšem koraku).
- spark.sql.catalog.demo.io-impl – Iceberg uporabnikom omogoča pisanje podatkov v Amazon S3 prek S3FileIO. Katalog podatkov AWS Glue privzeto uporablja ta FileIO, drugi katalogi pa lahko naložijo ta FileIO z lastnostjo kataloga io-impl.
Pretvorite podatke v obliko tabele Iceberg
Za nalaganje tabele Iceberg lahko uporabite Spark na Amazon EMR ali Atheno. V seji EMR Studio Workspace notebook Spark zaženite naslednje ukaze za nalaganje podatkov:
Ko zaženete kodo, bi morali najti dve predponi, ustvarjeni na poti S3 vašega podatkovnega skladišča (s3://iceberg-curated-blog-data/reviews.db/all_reviews): podatki in metapodatki.
Obdelajte inkrementalne podatke z uporabo stavkov SQL za vstavljanje, posodabljanje in brisanje v Atheni
Athena je poizvedovalni mehanizem brez strežnika, ki ga lahko uporabite za izvajanje nalog branja, pisanja, posodabljanja in optimizacije za tabele Iceberg. Da bi prikazali, kako format podatkovnega jezera Apache Iceberg podpira inkrementalni vnos podatkov, v podatkovnem jezeru izvajamo stavke SQL za vstavljanje, posodabljanje in brisanje.
Pomaknite se do konzole Athena in izberite Urejevalnik poizvedb. Če prvič uporabljate urejevalnik poizvedb Athena, morate to storiti konfigurirajte lokacijo rezultatov poizvedbe biti vedro S3, ki ste ga ustvarili prej. Morali bi videti, da je tabela reviews.all_reviews na voljo za poizvedovanje. Zaženite naslednjo poizvedbo, da preverite, ali ste uspešno naložili tabelo Iceberg:
Obdelajte inkrementalne podatke z izvajanjem stavkov SQL za vstavljanje, posodabljanje in brisanje:
Nastavitev zmogljivosti
V tem razdelku se sprehodimo skozi različne načine za izboljšanje zmogljivosti branja in pisanja Apache Iceberg.
Konfigurirajte lastnosti tabele Apache Iceberg
Apache Iceberg je oblika tabele in podpira lastnosti tabele za konfiguracijo obnašanja tabele, kot so branje, pisanje in katalogiziranje. Zmogljivost branja in pisanja v tabelah Iceberg lahko izboljšate tako, da prilagodite lastnosti tabele.
Če na primer opazite, da pišete preveč majhnih datotek za tabelo Iceberg, lahko velikost pisalne datoteke konfigurirate tako, da piše manj datotek, a večjih velikosti, da izboljšate učinkovitost poizvedbe.
| Nepremičnine | privzeto | Opis |
| write.target-file-size-bytes | 536870912 (512 MB) | Nadzoruje velikost datotek, ustvarjenih za ciljanje približno toliko bajtov |
Za spremembo oblike tabele uporabite naslednjo kodo:
Razdelitev in razvrščanje
Če želite, da se poizvedba izvaja hitro, manj podatkov preberete, bolje je. Iceberg izkorišča prednosti bogatih metapodatkov, ki jih zajame v času pisanja, in olajša tehnike, kot so načrtovanje skeniranja, particioniranje, obrezovanje in statistike na ravni stolpcev, kot so najmanjše/najvišje vrednosti, da preskočijo podatkovne datoteke, ki nimajo zapisov o ujemanju. Predstavili vam bomo, kako načrtovanje skeniranja poizvedb in particioniranje delujeta v Icebergu in kako ju uporabljamo za izboljšanje učinkovitosti poizvedb.
Načrtovanje pregledovanja poizvedb
Za dano poizvedbo je prvi korak v mehanizmu poizvedb načrtovanje skeniranja, ki je postopek iskanja datotek v tabeli, potrebnih za poizvedbo. Načrtovanje v tabeli Iceberg je zelo učinkovito, saj je mogoče bogate metapodatke Iceberga uporabiti za obrezovanje datotek metapodatkov, ki niso potrebni, poleg filtriranja podatkovnih datotek, ki ne vsebujejo ujemajočih se podatkov. Pri naših preizkusih smo opazili, da je Athena pregledala 50 % ali manj podatkov za dano poizvedbo v tabeli Iceberg v primerjavi z izvirnimi podatki pred pretvorbo v format Iceberg.
Obstajata dve vrsti filtriranja:
- Filtriranje metapodatkov – Iceberg uporablja dve ravni metapodatkov za sledenje datotekam v posnetku: seznam manifestov in datoteke manifestov. Najprej uporabi seznam manifestov, ki deluje kot indeks datotek manifestov. Med načrtovanjem Iceberg filtrira manifeste z uporabo obsega vrednosti particije na seznamu manifestov, ne da bi prebral vse datoteke manifesta. Nato uporabi izbrane datoteke manifesta, da pridobi podatkovne datoteke.
- Filtriranje podatkov – Ko izbere seznam datotek manifesta, Iceberg za filtriranje podatkovnih datotek uporabi particijske podatke in statistiko na ravni stolpca za vsako podatkovno datoteko, shranjeno v datotekah manifesta. Med načrtovanjem se predikati poizvedbe pretvorijo v predikate na particijskih podatkih in najprej uporabijo za filtriranje podatkovnih datotek. Nato se statistični podatki stolpca, kot so štetje vrednosti na ravni stolpca, ničelno štetje, spodnje meje in zgornje meje, uporabijo za filtriranje podatkovnih datotek, ki se ne morejo ujemati s predikatom poizvedbe. Z uporabo zgornjih in spodnjih meja za filtriranje podatkovnih datotek v času načrtovanja Iceberg močno izboljša zmogljivost poizvedb.
Razdelitev in razvrščanje
Particioniranje je način pisnega združevanja zapisov z enakimi vrednostmi ključnih stolpcev. Prednost particioniranja so hitrejše poizvedbe, ki dostopajo le do dela podatkov, kot je bilo razloženo prej pri načrtovanju pregledovanja poizvedb: filtriranje podatkov. Iceberg omogoča preprosto particioniranje s podporo za skrito particioniranje, tako da Iceberg ustvari particijske vrednosti tako, da vzame vrednost stolpca in jo po želji preoblikuje.
V našem primeru uporabe najprej zaženemo naslednjo poizvedbo na tabeli Iceberg, ki ni particionirana. Nato tabelo Iceberg razdelimo po kategoriji pregledov, ki bodo uporabljeni v pogoju poizvedbe WHERE za filtriranje zapisov. S particioniranjem bi lahko poizvedba skenirala veliko manj podatkov. Oglejte si naslednjo kodo:
Zaženite naslednji stavek za izbiro na neparticionirani tabeli all_reviews v primerjavi s particionirano tabelo, da vidite razliko v zmogljivosti:
Naslednja tabela prikazuje izboljšanje zmogljivosti particije podatkov, s približno 50 % izboljšavo zmogljivosti in 70 % manj pregledanih podatkov.
| Ime nabora podatkov | Neparticioniran nabor podatkov | Particioniran nabor podatkov |
| Čas delovanja (sekunde) | 8.20 | 4.25 |
| Skenirani podatki (MB) | 131.55 | 33.79 |
Upoštevajte, da je čas izvajanja povprečni čas izvajanja z več zagoni v našem testu.
Po razdelitvi smo opazili dobro izboljšanje zmogljivosti. Vendar pa je to mogoče še izboljšati z uporabo statističnih podatkov na ravni stolpca iz datotek manifesta Iceberg. Če želite učinkovito uporabiti statistiko na ravni stolpca, želite dodatno razvrstiti svoje zapise na podlagi vzorcev poizvedbe. Razvrščanje celotnega nabora podatkov z uporabo stolpcev, ki se pogosto uporabljajo v poizvedbah, bo prerazporedilo podatke na tak način, da bo vsaka podatkovna datoteka imela edinstven obseg vrednosti za določene stolpce. Če so ti stolpci uporabljeni v pogoju poizvedbe, omogoča poizvedovalnim mehanizmom, da dodatno preskočijo podatkovne datoteke in s tem omogočijo še hitrejše poizvedbe.
Kopiranje ob pisanju v primerjavi z branjem ob spajanju
Pri izvajanju posodabljanja in brisanja tabel Iceberg v podatkovnem jezeru obstajata dva pristopa, opredeljena z lastnostmi tabele Iceberg:
- Kopiraj-zapiši – S tem pristopom se bodo podatkovne datoteke, povezane z zadevnimi zapisi, podvojile in posodobile, ko pride do sprememb tabele Iceberg, bodisi posodobitev bodisi izbrisov. Zapisi bodo posodobljeni ali izbrisani iz podvojenih podatkovnih datotek. Ustvarjen bo nov posnetek tabele Iceberg, ki bo pokazal na novejšo različico podatkovnih datotek. Zaradi tega je splošno pisanje počasnejše. Lahko pride do situacij, ko so potrebna sočasna pisanja s spori, zato je treba znova poskusiti, kar še dodatno podaljša čas pisanja. Po drugi strani pa pri branju podatkov ni potreben noben dodaten postopek. Poizvedba bo pridobila podatke iz najnovejše različice podatkovnih datotek.
- Spoji ob branju – S tem pristopom ob posodobitvah ali izbrisih v tabeli Iceberg obstoječe podatkovne datoteke ne bodo ponovno zapisane; namesto tega bodo ustvarjene nove datoteke za brisanje za sledenje spremembam. Pri izbrisih bo ustvarjena nova datoteka za brisanje z izbrisanimi zapisi. Pri branju tabele Iceberg bo datoteka za brisanje uporabljena za pridobljene podatke, da se izločijo izbrisani zapisi. Za posodobitve bo ustvarjena nova datoteka za brisanje, ki bo posodobljene zapise označila kot izbrisane. Nato bo za te zapise ustvarjena nova datoteka, vendar s posodobljenimi vrednostmi. Ko berete tabelo Iceberg, bosta izbrisani in novi datoteki uporabljeni za pridobljene podatke, da odražata zadnje spremembe in ustvarita pravilne rezultate. Torej se bo za vse nadaljnje poizvedbe zgodil dodaten korak za združitev podatkovnih datotek z brisanjem in novimi datotekami, kar bo običajno podaljšalo čas poizvedbe. Po drugi strani pa je zapisovanje morda hitrejše, ker ni potrebe po prepisovanju obstoječih podatkovnih datotek.
Če želite preizkusiti učinek obeh pristopov, lahko zaženete naslednjo kodo za nastavitev lastnosti tabele Iceberg:
Zaženite stavke SQL za posodobitev, brisanje in izbiro v Atheni, da prikažete razliko v času izvajanja za kopiranje ob pisanju in spajanje ob branju:
Naslednja tabela povzema čas izvajanja poizvedbe.
| Poizvedba | Copy-on-Write | Spoji ob branju | ||||
| POSODOBI | DELETE | IZBIRA | POSODOBI | DELETE | IZBIRA | |
| Čas delovanja (sekunde) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| Skenirani podatki (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
Upoštevajte, da je čas izvajanja povprečni čas izvajanja z več zagoni v našem testu.
Kot kažejo rezultati naših testov, pri obeh pristopih vedno obstajajo kompromisi. Kateri pristop uporabiti, je odvisno od vaših primerov uporabe. Če povzamemo, se premisleki zmanjšajo na zakasnitev pri branju v primerjavi s pisanjem. Oglejte si naslednjo tabelo in se pravilno odločite.
| . | Copy-on-Write | Spoji ob branju |
| Prednosti | Hitrejše branje | Hitreje piše |
| Proti | Drago piše | Višja zakasnitev pri branju |
| Kdaj uporabiti | Dobro za pogosta branja, redke posodobitve in brisanja ali velike paketne posodobitve | Dobro za tabele s pogostim posodabljanjem in brisanjem |
Zgoščevanje podatkov
Če je vaša podatkovna datoteka majhna, boste morda imeli na tisoče ali milijone datotek v tabeli Iceberg. To močno poveča V/I operacijo in upočasni poizvedbe. Poleg tega Iceberg sledi vsaki podatkovni datoteki v naboru podatkov. Več podatkovnih datotek vodi do več metapodatkov. To posledično poveča obremenitev in V/I operacijo pri branju metapodatkovnih datotek. Za izboljšanje zmogljivosti poizvedb je priporočljivo strniti majhne podatkovne datoteke v večje podatkovne datoteke.
Pri posodabljanju in brisanju zapisov v tabeli Iceberg, če je uporabljen pristop branja ob spajanju, lahko na koncu pride do številnih majhnih izbrisov ali novih podatkovnih datotek. Zagon stiskanja bo združil vse te datoteke in ustvaril novejšo različico podatkovne datoteke. To odpravlja potrebo po njihovem usklajevanju med branjem. Priporočljivo je, da imate redna opravila stiskanja, da čim manj vplivate na branje, hkrati pa ohranite večjo hitrost pisanja.
Zaženite naslednji ukaz za stiskanje podatkov, nato zaženite poizvedbo za izbiro iz Athene:
Naslednja tabela primerja čas izvajanja pred in po stiskanju podatkov. Opazite lahko približno 40-odstotno izboljšanje zmogljivosti.
| Poizvedba | Pred stiskanjem podatkov | Po stiskanju podatkov |
| Čas delovanja (sekunde) | 97.75 | 32.676 sekund |
| Skenirani podatki (MB) | 137.16 M | 189.19 M |
Upoštevajte, da so se izbirne poizvedbe izvajale na all_reviews tabela po operacijah posodobitve in brisanja, pred in po stiskanju podatkov. Čas izvajanja je povprečni čas izvajanja z več zagoni v našem testu.
Čiščenje
Ko sledite navodilom za rešitev za izvedbo primerov uporabe, dokončajte naslednje korake, da očistite svoje vire in se izognete nadaljnjim stroškom:
- Spustite tabele in bazo podatkov AWS Glue iz Athene ali zaženite naslednjo kodo v svojem zvezku:
- Na konzoli EMR Studio izberite Delovni prostori v podoknu za krmarjenje.
- Izberite delovni prostor, ki ste ga ustvarili, in izberite Brisanje.
- Na konzoli EMR se pomaknite do Studios stran.
- Izberite Studio, ki ste ga ustvarili, in izberite Brisanje.
- Na konzoli EMR izberite Grozdi v podoknu za krmarjenje.
- Izberite gručo in izberite Prekinite.
- Izbrišite vedro S3 in vse druge vire, ki ste jih ustvarili kot del predpogojev za to objavo.
zaključek
V tej objavi smo predstavili ogrodje Apache Iceberg in kako pomaga pri reševanju nekaterih izzivov, ki jih imamo v sodobnem podatkovnem jezeru. Nato smo vam predstavili rešitev za obdelavo inkrementalnih podatkov v podatkovnem jezeru z uporabo Apache Iceberg. Nazadnje smo se globoko poglobili v prilagajanje zmogljivosti, da bi izboljšali zmogljivost branja in pisanja za naše primere uporabe.
Upamo, da vam ta objava nudi nekaj koristnih informacij, da se boste lahko odločili, ali želite uporabiti Apache Iceberg v svoji rešitvi podatkovnega jezera.
O avtorjih
 Flora Wu je starejši stalni arhitekt pri AWS Data Lab. Podjetniškim strankam pomaga ustvariti strategije za analizo podatkov in zgraditi rešitve za pospešitev njihovih poslovnih rezultatov. V prostem času rada igra tenis, pleše salso in potuje.
Flora Wu je starejši stalni arhitekt pri AWS Data Lab. Podjetniškim strankam pomaga ustvariti strategije za analizo podatkov in zgraditi rešitve za pospešitev njihovih poslovnih rezultatov. V prostem času rada igra tenis, pleše salso in potuje.
 Daniel Li je starejši arhitekt rešitev pri Amazon Web Services. Osredotoča se na pomoč strankam pri razvoju, sprejemanju in izvajanju storitev in strategije v oblaku. Ko ni v službi, rad preživlja čas na prostem z družino.
Daniel Li je starejši arhitekt rešitev pri Amazon Web Services. Osredotoča se na pomoč strankam pri razvoju, sprejemanju in izvajanju storitev in strategije v oblaku. Ko ni v službi, rad preživlja čas na prostem z družino.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- Sposobna
- O meni
- nad
- pospeši
- dostop
- upravljanje dostopa
- Ukrep
- aktov
- Poleg tega
- Dodatne
- Naslov
- naslovi
- Dodaja
- sprejme
- Prednost
- po
- proti
- vsi
- omogoča
- vedno
- Amazon
- Amazonski EMR
- Amazon Web Services
- Analitični
- analitika
- in
- razglasitve
- Apache
- aplikacije
- uporabna
- pristop
- pristopi
- primerno
- Arhitektura
- povezan
- Preverjanje pristnosti
- razpoložljivost
- Na voljo
- povprečno
- izogniti
- AWS
- AWS lepilo
- temeljijo
- ker
- postanejo
- pred
- koristi
- Boljše
- med
- večji
- Bootstrap
- izgradnjo
- Building
- podjetja
- ujame
- Zajemanje
- primeru
- primeri
- Katalog
- kataloge
- Kategorija
- izzivi
- spremenite
- Spremembe
- preveriti
- izbira
- Izberite
- Razvrstitev
- Cloud
- storitev v oblaku
- Grozd
- Koda
- Stolpec
- Stolpci
- združujejo
- kako
- Zavezati
- v primerjavi z letom
- dokončanje
- Izračunajte
- sočasno
- stanje
- konfiguracije
- premislekov
- Konzole
- Pretvorba
- pretvori
- stroškovno učinkovito
- stroški
- bi
- ustvarjajo
- ustvaril
- ustvari
- kurirano
- Trenutna
- stranka
- Stranke, ki so
- ples
- Armaturna plošča
- datum
- Podatkovna analiza
- Data jezero
- obdelava podatkov
- podatkovno skladišče
- Baze podatkov
- nabor podatkov
- globoko
- globok potop
- privzeto
- opredeljen
- Predstavitev
- izkazati
- odvisno
- zasnovan
- Podrobnosti
- Razvoj
- Razvoj
- Razlika
- drugačen
- razpravlja
- dont
- navzdol
- dramatično
- Drop
- med
- vsak
- prej
- Zgodnje
- urednik
- učinkovito
- učinkovite
- bodisi
- odpravlja
- omogočena
- omogočanje
- konča
- Motor
- Motorji
- Vnesite
- Podjetje
- podjetniške stranke
- Eter (ETH)
- Tudi
- evolucija
- razvijajo
- razvija
- Primer
- obstoječih
- obstaja
- razložiti
- razširitve
- dodatna
- olajša
- družina
- FAST
- hitreje
- Lastnosti
- Slika
- file
- datoteke
- filter
- filtriranje
- Filtri
- končno
- Najdi
- prva
- prvič
- Osredotoča
- sledi
- po
- format
- Okvirni
- pogosto
- iz
- nadalje
- Poleg tega
- splošno
- ustvarila
- dobili
- dana
- goes
- dobro
- zelo
- skupina
- strani
- se zgodi
- pomoč
- pomoč
- Pomaga
- skrita
- hierarhija
- na visoki ravni
- visokozmogljivo
- visoko zmogljiv
- Panj
- upam,
- Kako
- Kako
- Vendar
- HTML
- HTTPS
- IAM
- identiteta
- upravljanje identitete in dostopa
- vpliv
- prizadeti
- izvajati
- Izvajanje
- izvajanja
- izboljšanje
- izboljšalo
- Izboljšanje
- izboljšuje
- in
- Vključno
- Povečajte
- povečal
- Poveča
- Indeks
- individualna
- Podatki
- namestitev
- Namesto
- integracija
- Uvedeno
- Izolati
- IT
- januar
- Delovna mesta
- Ključne
- lab
- Jezero
- velika
- večja
- Latenca
- Zadnji
- zadnja izdaja
- plast
- plasti
- vodi
- ravni
- LIMIT
- vrstica
- Seznam
- malo
- obremenitev
- kraj aktivnosti
- Znamka
- IZDELA
- upravljanje
- več
- znamka
- tržnica
- Stave
- ujemanje
- Spoji
- metapodatki
- morda
- milijoni
- sodobna
- več
- premikanje
- več
- Ime
- Imenovan
- Krmarjenje
- ostalo
- Nimate
- potrebna
- potrebe
- Novo
- prenosnik
- predmet
- odprite
- Delovanje
- operacije
- optimizacija
- Optimizirajte
- Da
- izvirno
- Ostalo
- na prostem
- Splošni
- lastne
- podokno
- del
- pot
- vzorci
- opravlja
- performance
- fizično
- načrtovanje
- platon
- Platonova podatkovna inteligenca
- PlatoData
- igranje
- vključiti
- točke
- Popular
- mogoče
- Prispevek
- poganja
- predpogoji
- Postopki
- Postopek
- obravnavati
- proizvodnjo
- Lastnosti
- nepremičnine
- zagotavljajo
- zagotavlja
- zagotavljanje
- zagotavljanje
- območje
- Surovi
- surovi podatki
- Preberi
- reading
- pravo
- Pred kratkim
- priporočeno
- evidence
- odražajo
- okolica
- registri
- redni
- sprostitev
- sprosti
- Preostalih
- obvezna
- zahteva
- viri
- povzroči
- Rezultati
- Mnenja
- Rich
- vloga
- koren
- Run
- tek
- Enako
- skeniranje
- sekund
- Oddelek
- varnost
- izbran
- izbiranje
- Brez strežnika
- Storitev
- Storitve
- Zasedanje
- nastavite
- Kompleti
- nastavitev
- nastavitve
- shouldnt
- Prikaži
- Razstave
- Enostavno
- situacije
- Velikosti
- upočasni
- majhna
- Posnetek
- So
- Software
- Rešitev
- rešitve
- nekaj
- Spark
- specifična
- hitrost
- Poraba
- SQL
- Začetek
- Država
- Izjava
- Izjave
- statistika
- Korak
- Koraki
- Še vedno
- shranjevanje
- trgovina
- shranjeni
- trgovine
- strategije
- Strategija
- strukturirano
- strukturirani in nestrukturirani podatki
- studio
- subnet
- kasneje
- Uspešno
- taka
- dovolj
- POVZETEK
- podpora
- Podprti
- Podpora
- Podpira
- miza
- meni
- ob
- ciljna
- Naloge
- tehnike
- tenis
- Test
- Testiranje
- testi
- O
- informacije
- Država
- njihove
- s tem
- tisoče
- 3
- skozi
- čas
- Čas potovanja
- do
- skupaj
- tudi
- orodja
- vrh
- Skupaj za plačilo
- sledenje
- Transakcije
- preoblikovanje
- potovanja
- Potovanje
- OBRAT
- Vrste
- pod
- edinstven
- Nadgradnja
- posodobljeno
- posodobitve
- posodabljanje
- URL
- uporaba
- primeru uporabe
- Uporabniki
- navadno
- VAL
- vrednost
- Vrednote
- preverjanje
- različica
- hodil
- walkthrough
- Skladišče
- ure
- načini
- web
- spletne storitve
- Kaj
- ali
- ki
- medtem
- široka
- Širok spekter
- bo
- brez
- delo
- deluje
- deluje
- bi
- pisati
- pisanje
- Vaša rutina za
- zefirnet