Slika ustvarjena z Ideogram.ai
Prepričan sem, da je večina od nas uporabljala iskalnike.
Obstaja celo stavek, kot je "Just Google it." Besedna zveza pomeni, da bi morali odgovor poiskati z Googlovim iskalnikom. Tako lahko univerzalni Google zdaj prepoznamo kot iskalnik.
Zakaj je iskalnik tako dragocen? Iskalniki uporabnikom omogočajo enostavno pridobivanje informacij na internetu z omejenim vnosom poizvedb in organiziranje teh informacij glede na ustreznost in kakovost. Po drugi strani pa iskanje omogoča dostop do ogromnega znanja, ki je bilo prej nedostopno.
Tradicionalno pristop iskalnika k iskanju informacij temelji na leksikalnih ujemanjih ali ujemanju besed. Deluje dobro, včasih pa je lahko rezultat natančnejši, ker se namen uporabnika razlikuje od vnesenega besedila.
Na primer, vnos »Red Dress Shot in the Dark« ima lahko dvojni pomen, zlasti z besedo »Shot«. Bolj verjeten pomen je, da je slika rdeče obleke posneta v temi, vendar tradicionalni iskalniki tega ne bi razumeli. Zato se pojavlja semantično iskanje.
Semantično iskanje bi lahko opredelili kot iskalnik, ki upošteva pomen besed in stavkov. Izhod semantičnega iskanja bi bil podatek, ki se ujema s pomenom poizvedbe, kar je v nasprotju s tradicionalnim iskanjem, ki poizvedbo ujema z besedami.
Na področju NLP (Obdelava naravnega jezika) so vektorske zbirke podatkov znatno izboljšale zmožnosti semantičnega iskanja z uporabo shranjevanja, indeksiranja in priklica visokodimenzionalnih vektorjev, ki predstavljajo pomen besedila. Semantično iskanje in vektorske baze podatkov so torej tesno povezani področji.
Ta članek bo razpravljal o semantičnem iskanju in o tem, kako uporabljati vektorsko bazo podatkov. S tem v mislih se lotimo tega.
Razpravljajmo o semantičnem iskanju v kontekstu vektorskih baz podatkov.
Ideje za semantično iskanje temeljijo na pomenih besedila, toda kako bi lahko zajeli te informacije? Računalnik ne more imeti občutka ali znanja kot ljudje, kar pomeni, da se mora beseda »pomeni« nanašati na nekaj drugega. Pri semantičnem iskanju bi beseda »pomen« postala predstavitev znanja, ki je primerno za smiselno iskanje.
Predstavitev pomena pride kot vdelava, proces pretvorbe besedila v vektor z numeričnimi informacijami. Na primer, lahko preoblikujemo stavek "Želim izvedeti več o semantičnem iskanju" z uporabo modela vdelave OpenAI.
[-0.027598874643445015, 0.005403674207627773, -0.03200408071279526, -0.0026835924945771694, -0.01792600005865097,...]
Kako lahko potem ta numerični vektor zajame pomene? Stopimo korak nazaj. Rezultat, ki ga vidite zgoraj, je rezultat vdelave stavka. Izhod vdelave bi bil drugačen, če bi zamenjali samo eno besedo v zgornjem stavku. Celo ena sama beseda bi imela tudi drugačen izhod vdelave.
Če pogledamo celotno sliko, se bodo vdelave posamezne besede v primerjavi s celotnim stavkom bistveno razlikovale, ker stavčne vdelave upoštevajo razmerja med besedami in splošnim pomenom stavka, ki ni zajet v posameznih vdelavah besed. To pomeni, da je vsaka beseda, stavek in besedilo edinstveno v rezultatu vdelave. Tako bi lahko vdelava zajela pomen namesto leksikalnega ujemanja.
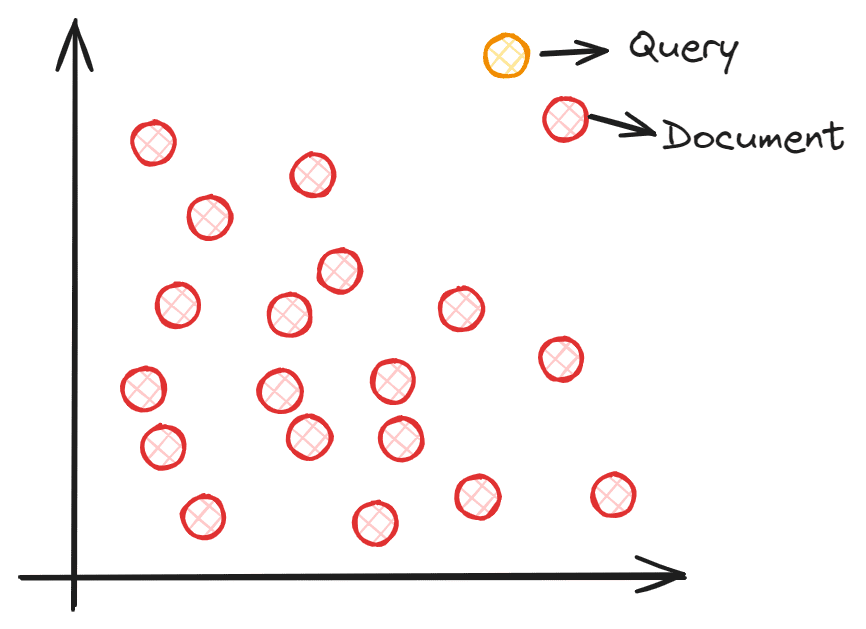
Kako torej semantično iskanje deluje z vektorji? Namen semantičnega iskanja je vdelati vaš korpus v vektorski prostor. To omogoča, da vsaka podatkovna točka zagotovi informacije (besedilo, stavek, dokumente itd.) in postane koordinatna točka. Vnos poizvedbe se med časom iskanja obdela v vektor z vdelavo v isti vektorski prostor. Našli bi najbližjo vdelavo iz našega korpusa v vnos poizvedbe z uporabo mer vektorske podobnosti, kot je podobnost kosinusa. Za boljše razumevanje si lahko ogledate spodnjo sliko.
Slika avtorja
Vsaka koordinata vdelave dokumenta je postavljena v vektorski prostor in vdelava poizvedbe je postavljena v vektorski prostor. Izbran bi bil dokument, ki je najbližji poizvedbi, saj ima teoretično najbližji semantični pomen vnosu.
Vendar pa bi bilo vzdrževanje vektorskega prostora, ki vsebuje vse koordinate, obsežna naloga, zlasti pri večjem korpusu. Baza podatkov Vector je boljša za shranjevanje vektorja namesto celotnega vektorskega prostora, saj omogoča boljši vektorski izračun in lahko ohranja učinkovitost, ko podatki rastejo.
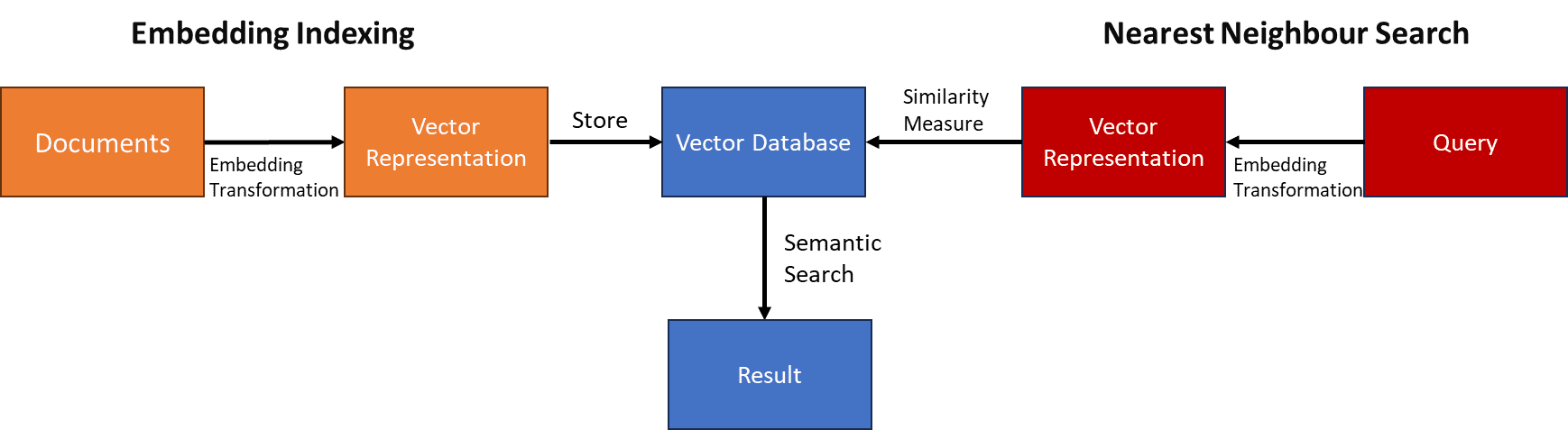
Proces semantičnega iskanja z vektorskimi zbirkami podatkov na visoki ravni je prikazan na spodnji sliki.
Slika avtorja
V naslednjem razdelku bomo izvedli semantično iskanje s primerom Python.
V tem članku bomo uporabili odprtokodno vektorsko bazo podatkov Tkajte. Za namene vadnice uporabljamo tudi Weaviate Cloud Service (WCS) za shranjevanje našega vektorja.
Najprej moramo namestiti paket Weavieate Python.
pip install weaviate-client
Nato se registrirajte za njihov brezplačni grozd prek Konzola Weaviate in zaščitite URL gruče in ključ API.
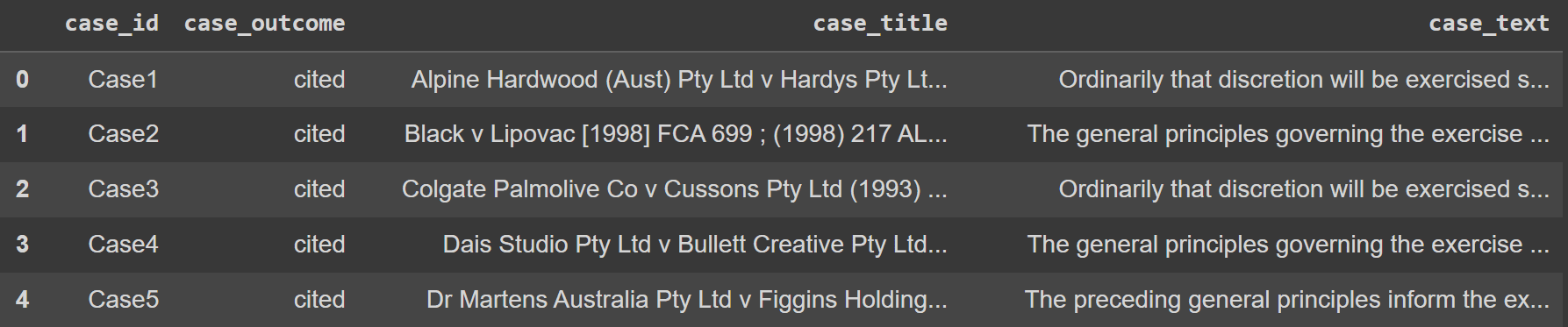
Kar zadeva primer nabora podatkov, bi uporabili Pravni besedilni podatki od Kaggle. Da bi stvari olajšali, bi uporabili tudi samo zgornjih 100 vrstic podatkov.
import pandas as pd
data = pd.read_csv('legal_text_classification.csv', nrows = 100)
Slika avtorja
Nato bi vse podatke shranili v vektorske baze podatkov v storitvi Weaviate Cloud Service. Za to moramo nastaviti povezavo z bazo podatkov.
import weaviate
import os
import requests
import json
cluster_url = "YOUR_CLUSTER_URL"
wcs_api_key = "YOUR_WCS_API_KEY"
Openai_api_key ="YOUR_OPENAI_API_KEY"
client = weaviate.connect_to_wcs(
cluster_url=cluster_url,
auth_credentials=weaviate.auth.AuthApiKey(wcs_api_key),
headers={
"X-OpenAI-Api-Key": openai_api_key
}
)
Naslednja stvar, ki jo moramo storiti, je, da se povežemo s storitvijo Weaviate Cloud Service in ustvarimo razred (kot je tabela v SQL) za shranjevanje vseh besedilnih podatkov.
import weaviate.classes as wvc
client.connect()
legal_cases = client.collections.create(
name="LegalCases",
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(),
generative_config=wvc.config.Configure.Generative.openai()
)
V zgornji kodi ustvarimo razred LegalCases, ki uporablja model vdelave OpenAI. V ozadju bi kateri koli besedilni objekt, ki bi ga shranili v razredu LegalCases, šel skozi model vdelave OpenAI in bil shranjen kot vdelani vektor.
Poskusimo shraniti podatke o pravnem besedilu v vektorsko bazo podatkov. Če želite to narediti, lahko uporabite naslednjo kodo.
sent_to_vdb = data.to_dict(orient='records')
legal_cases.data.insert_many(sent_to_vdb)
V gruči Weaviate bi morali videti, da je vaše pravno besedilo tam že shranjeno.
Ko je vektorska zbirka podatkov pripravljena, poskusimo semantično iskanje. Weaviate API olajša, kot je prikazano v spodnji kodi. V spodnjem primeru bomo poskušali najti primere, ki se zgodijo v Avstraliji.
response = legal_cases.query.near_text(
query="Cases in Australia",
limit=2
)
for i in range(len(response.objects)):
print(response.objects[i].properties)
Rezultat je prikazan spodaj.
{'case_title': 'Castlemaine Tooheys Ltd v South Australia [1986] HCA 58 ; (1986) 161 CLR 148', 'case_id': 'Case11', 'case_text': 'Hexal Australia Pty Ltd v Roche Therapeutics Inc (2005) 66 IPR 325, the likelihood of irreparable harm was regarded by Stone J as, indeed, a separate element that had to be established by an applicant for an interlocutory injunction. Her Honour cited the well-known passage from the judgment of Mason ACJ in Castlemaine Tooheys Ltd v South Australia [1986] HCA 58 ; (1986) 161 CLR 148 (at 153) as support for that proposition.', 'case_outcome': 'cited'}
{'case_title': 'Deputy Commissioner of Taxation v ACN 080 122 587 Pty Ltd [2005] NSWSC 1247', 'case_id': 'Case97', 'case_text': 'both propositions are of some novelty in circumstances such as the present, counsel is correct in submitting that there is some support to be derived from the decisions of Young CJ in Eq in Deputy Commissioner of Taxation v ACN 080 122 587 Pty Ltd [2005] NSWSC 1247 and Austin J in Re Currabubula Holdings Pty Ltd (in liq); Ex parte Lord (2004) 48 ACSR 734; (2004) 22 ACLC 858, at least so far as standing is concerned.', 'case_outcome': 'cited'}
Kot lahko vidite, imamo dva različna rezultata. V prvem primeru je bila beseda »Avstralija« neposredno omenjena v dokumentu, tako da jo je lažje najti. Vendar drugi rezultat nikjer ni imel besede "Avstralija". Semantično iskanje pa ga lahko najde, ker obstajajo besede, povezane z besedo »Avstralija«, na primer »NSWSC«, ki pomeni vrhovno sodišče Novega Južnega Walesa, ali beseda »Currabubula«, ki je vas v Avstraliji.
Tradicionalno leksikalno ujemanje lahko zgreši drugi zapis, vendar je semantično iskanje veliko bolj natančno, saj upošteva pomene dokumenta.
To je vsa implementacija preprostega semantičnega iskanja z vektorsko bazo podatkov.
Iskalniki prevladujejo pri pridobivanju informacij na internetu, čeprav ima tradicionalna metoda z leksikalnim ujemanjem pomanjkljivost, in sicer, da ne zajame namena uporabnika. Ta omejitev povzroči semantično iskanje, metodo iskalnika, ki lahko interpretira pomen poizvedb po dokumentih. Izboljšana z vektorskimi zbirkami podatkov je zmožnost semantičnega iskanja še učinkovitejša.
V tem članku smo raziskali, kako deluje semantično iskanje, in praktično implementacijo Pythona z odprtokodnimi vektorskimi bazami podatkov Weaviate. Upam, da pomaga!
Cornellius Yudha Wijaya je vodja podatkovne znanosti in pisec podatkov. Medtem ko dela s polnim delovnim časom pri Allianz Indonesia, rad deli nasvete o Pythonu in podatkih prek družbenih medijev in pisnih medijev. Cornellius piše o različnih temah umetne inteligence in strojnega učenja.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.kdnuggets.com/semantic-search-with-vector-databases?utm_source=rss&utm_medium=rss&utm_campaign=semantic-search-with-vector-databases
- :ima
- : je
- :ne
- 100
- 11
- 12
- 13
- 2005
- 21
- 22
- 325
- 48
- 58
- 66
- 7
- 8
- 9
- a
- Sposobna
- O meni
- nad
- dostopnost
- Račun
- natančna
- ACN
- pridobiti
- pridobitev
- AI
- Cilje
- vsi
- Allianz
- omogočajo
- omogoča
- že
- Prav tako
- Čeprav
- am
- an
- in
- odgovor
- kaj
- kjerkoli
- API
- pristop
- SE
- članek
- AS
- Pomočnik
- At
- Austin
- Avstralija
- Auth
- nazaj
- ozadje
- temeljijo
- BE
- ker
- postanejo
- spodaj
- Boljše
- med
- tako
- vendar
- by
- izračun
- CAN
- Zmogljivosti
- zmožnost
- zajemanje
- Zajeto
- primeru
- primeri
- okoliščinah
- praksa
- razred
- razredi
- stranke
- tesno
- Najbližje
- Cloud
- Grozd
- Koda
- Zbirke
- prihaja
- komisar
- dokončanje
- računalnik
- zaskrbljen
- Connect
- povezava
- meni
- Vsebuje
- ozadje
- kontrasti
- koordinate
- koordinate
- popravi
- bi
- svetovalec
- Sodišče
- ustvarjajo
- Temnomodra
- datum
- znanost o podatkih
- Baze podatkov
- baze podatkov
- odločitve
- opredeljen
- namestnik
- Izpeljano
- DID
- se razlikujejo
- drugačen
- neposredno
- razpravlja
- do
- dokument
- Dokumenti
- ne
- prevladujejo
- podvojila
- med
- vsak
- lažje
- enostavno
- učinkovitosti
- učinkovite
- element
- ostalo
- Embed
- vdelava
- smirkovim
- omogoča
- Motor
- Motorji
- okrepljeno
- zlasti
- ustanovljena
- itd
- Eter (ETH)
- Tudi
- Primer
- Raziskano
- ne uspe
- daleč
- občutek
- Polje
- Področja
- Najdi
- iskanje
- prva
- napaka
- po
- za
- brezplačno
- iz
- ustvarila
- generativno
- dobili
- daje
- Go
- raste
- imel
- hands-on
- se zgodi
- škodovalo
- Imajo
- ob
- he
- jo
- na visoki ravni
- Holdings
- čast
- upam,
- Kako
- Kako
- Vendar
- http
- HTTPS
- Ljudje
- i
- Ideje
- identificirati
- if
- slika
- Izvajanje
- uvoz
- izboljšalo
- in
- nedostopna
- prav zares
- individualna
- Indonezija
- Podatki
- vhod
- namestitev
- Namesto
- namen
- Namen
- Internet
- razlagajo
- v
- IT
- ITS
- json
- samo
- samo en
- KDnuggets
- Ključne
- znanje
- jezik
- večja
- UČITE
- učenje
- vsaj
- Pravne informacije
- kot
- verjetnost
- Omejitev
- Limited
- Poglej
- gospodar
- ljubi
- Ltd
- stroj
- strojno učenje
- vzdrževati
- vzdrževanje
- Znamka
- IZDELA
- upravitelj
- Mason
- ogromen
- Stave
- tekme
- ujemanje
- kar pomeni,
- smiselna
- pomene
- pomeni
- ukrepe
- mediji
- omenjeno
- Metoda
- morda
- moti
- pogrešam
- Model
- več
- učinkovitejše
- Najbolj
- veliko
- naravna
- Naravni jezik
- Obdelava Natural Language
- Nimate
- potrebe
- Novo
- New South Wales
- Naslednja
- nlp
- Novost
- zdaj
- numerično
- predmet
- predmeti
- of
- on
- ONE
- samo
- open source
- OpenAI
- or
- OS
- naši
- izhod
- Splošni
- paket
- pand
- Prehod
- opravlja
- slika
- postavi
- platon
- Platonova podatkovna inteligenca
- PlatoData
- prosim
- Točka
- raje
- predstaviti
- prej
- Postopek
- obdelani
- obravnavati
- Lastnosti
- predlog
- predlogi
- zagotavljajo
- namene
- Python
- kakovost
- poizvedbe
- poizvedba
- RE
- pripravljen
- zapis
- evidence
- Rdeča
- glejte
- upoštevati
- Registracija
- povezane
- Razmerja
- ustreznost
- nadomesti
- zastopanje
- predstavlja
- zahteva
- Odgovor
- povzroči
- Rezultati
- iskanje
- Rise
- skala
- vrstic
- s
- Enako
- Znanost
- Iskalnik
- iskalnik
- Iskalniki
- drugi
- Oddelek
- zavarovanje
- glej
- videl
- izbran
- pomensko
- stavek
- ločena
- Storitev
- nastavite
- Delite s prijatelji, znanci, družino in partnerji :-)
- shot
- shouldnt
- pokazale
- bistveno
- podobnosti
- Enostavno
- sam
- So
- doslej
- socialna
- družbeni mediji
- nekaj
- Nekaj
- Včasih
- South
- Vesolje
- SQL
- stoječa
- stojala
- Korak
- STONE
- shranjevanje
- trgovina
- shranjeni
- shranjevanje
- oddaja
- taka
- primerna
- podpora
- Vrhovno
- Vrhovno sodišče
- Preverite
- miza
- Bodite
- sprejeti
- meni
- Naloga
- Obdavčitev
- besedilo
- da
- O
- njihove
- POTEM
- teoretično
- terapevtiki
- Tukaj.
- stvar
- stvari
- ta
- skozi
- čas
- nasveti
- do
- vrh
- Teme
- tradicionalna
- Transform
- Preoblikovanje
- poskusite
- OBRAT
- Navodila
- dva
- razumeli
- edinstven
- Universal
- URL
- us
- uporaba
- Rabljeni
- uporabnik
- Uporabniki
- uporablja
- uporabo
- Uporaben
- dragocene
- raznolikost
- vektor
- vektorji
- Proti
- preko
- Vas
- želeli
- je
- we
- Dobro
- dobro znana
- so bili
- karkoli
- ki
- medtem
- celoti
- zakaj
- bo
- z
- beseda
- besede
- delo
- deluje
- deluje
- bi
- Pisatelj
- pisanje
- jo
- mladi
- Vaša rutina za
- zefirnet