Plato Data Intelligence. Vertical Search. Ai
Plato’s Ai and advanced automation curates the latest sector intelligence with insights into the people, companies and culture driving innovation today.
Signup for Free. Get Access Now.
Plato Web3 DefiX Gateway. Access all your dApps in one place.
Connect with the thousands of dApps via a single and secure interface.
Your Gateway to the world of Decentralized Finance.
Plato OpenAi. Driving Smart Search.
By employing a completely new methodology related to search and Intelligence, we enable deep and authentic connectivity to today’s most innovative technology sectors. The platform provides an ultra-secure environment to consume sector-specific real-time data intelligence. Plato is accessible across 23 languages and 27 verticals.


Should You Sell Ether Ahead of the SEC’s Expected Rejection of a Spot Ether ETF on May 23? – Unchained

P2 Ventures Commits $50M Via Hadron FC to Startup Founders in Polygon Ecosystem

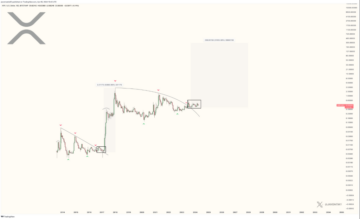
Analyst Keeps Faith In XRP, Targets $288 Despite Price Retreat

Web3 Hackers Target Big Fish, But Sector’s Recovery Hits 54%: Hacken

Deutsche Börse’s Clearstream Unit Invests in This European Fintech

Bitcoin Halving Google Searches Soar To New ATH As Bitwise Says Markets Underestimate Its Impact On The BTC Price
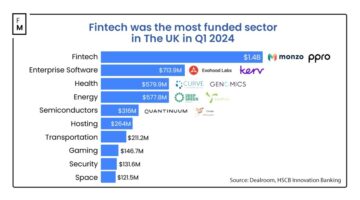
The UK Fintech Startups Raise $1.4B, Reclaim Throne as Top VC Destination
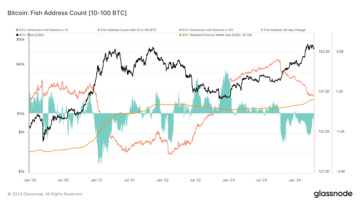
OG Bitcoin holders or ‘King’ Fish retain $15k cost basis after buying the dip
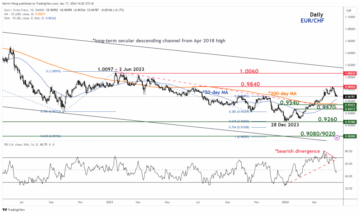
EUR/CHF Technical: Bullish exhaustion condition detected after 2-month of rallies – MarketPulse

Former Goldman Sachs Executive Says 80% of His Crypto Portfolio Allocated to One Ethereum Rival – The Daily Hodl
Pepe Price Prediction: PEPE Pumps 9% As This Multi-Chain Dogecoin Derivative Charges Towards $6 Million
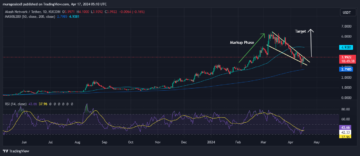
Akash Network Price Prediction: Top-Performing AKT Surges 12% As This Green AI Presale Blasts Past $3 Million
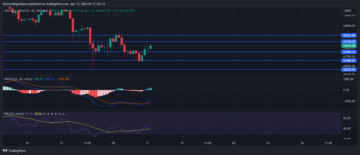
Bitcoin Price Prediction: Bybit Says BTC Exchange’s Supply Will Run Out In 9 Months As Traders Turn To This Learn-To-Earn ICO For 10X Gains

NatWest Collaborates with StoneX to Expand Cross-Border FX Capabilities
Fortex Unveiled 4 Features in Their Platform: See What’s New

HashKey Global Announces Listing of MERL Token with 200,000 MERL Prize Pool Campaign

UAE’s Klickl Secures ADGM Financial Services Permission, Revolutionizing Finance with Integrated Tradefi and Web 3.0

Liquid Mercury Partners with GFO-X to Provide RFQ Platform for Trading Crypto Derivatives

Navigating Digital Assets In 2024: Understanding The Regulatory Landscape For Banking Bitcoin – CryptoInfoNet

South Korean Won Overtakes U.S. Dollar As The Dominant Currency In Crypto Trading, Reports News Explorer – CryptoInfoNet
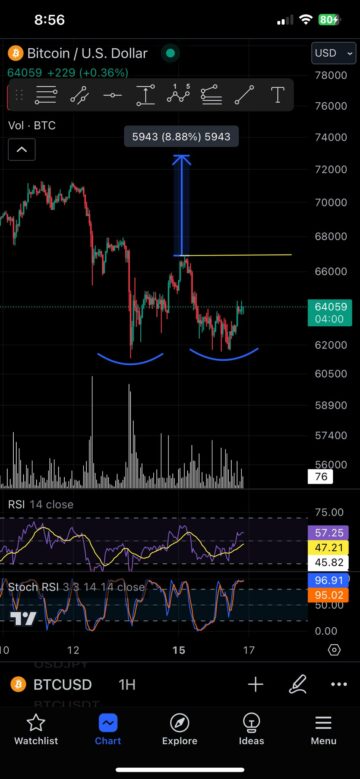

Ethereum Risk Reversals Sink Deeper as Crypto Markets Turn Nervous: QCP – Unchained

SEC Commissioner Peirce’s Vision for Modernizing U.S. Crypto Regulations

Eisai’s Antiepileptic Drug Fycompa Injection Formulation Launched In Japan

TRON DAO at Harvard Blockchain Conference and New TRON Builder Tour Stop


Macro Guru Lyn Alden Says Bitcoin Hitting Six Figures Wouldn’t Be Surprising Amid Rising Liquidity – Here’s the Timeline – The Daily Hodl
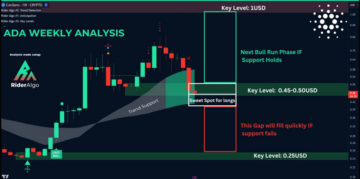
Cardano’s Dark Hour: Panic Grips Investors As ADA Drops 20%




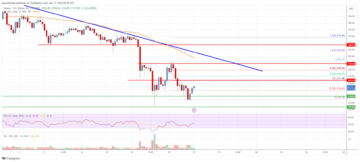
Solana (SOL) Price Analysis: Price Dips 50%, Can It Recover? | Live Bitcoin News

Condo, the world’s first meme token based on Real-World Asset (RWA), launches on Base Chain with innovative treasury investment strategy | Live Bitcoin News
XRP Price Recovery Could Soon Fade, These Are Key Levels To Watch

Over 1,000 Attendees: YGG Pilipinas Kickstarts Roadtrip in Lipa | BitPinas


Cryptocurrency Whales Have Over $1.2 Billion They Can’t Access

Bitcoin spot ETFs ready for Hong Kong debut with restrained expectations

$120,000 Bitcoin Price Incoming? Crypto Analyst Predicts Doomsday Surge Amid Rising Geopolitical Tensions

This Altcoin Group Will Run First After Market Wipeout As Capital Takes Flight to Quality, Says Crypto Strategist – The Daily Hodl

These AI Tokens Are Set to Merge—Here’s How It Will Work – Decrypt

Bitcoin Traders Brace for Runes Launch by Setting Up Their Own Nodes—Why? – Decrypt

PSG fan token jumps 23% during the match against Barcelona

Ethereum Gaming Network Xai Expands Staking Rewards – Decrypt

Senators Elizabeth Warren and Charles Grassley Probe CFTC Chair About Alleged Ties With Sam Bankman-Fried – The Daily Hodl

Forge teams up with Xterio to boost Web3 Gaming with rewards

Ripple’s XRP Price to $20? — Devs Unveil Super Bullish Proposal That Could Massively Advance XRPL


Hong Kong’s Bitcoin and Ethereum ETFs Could Fetch $25 Billion—If China Plays Nice – Decrypt

Pundit Declares Bitcoin’s Trillion-Dollar Crown Is Here To Stay Amid Deepening Market Rout


Fetch.ai, SingularityNET, and Ocean Protocol’s planned $7.5 billion ASI token to launch in May
NZ dollar slips ahead of New Zealand inflation – MarketPulse

Quant Reaches Bearish Exhaustion As It Recovers Over $100

New legislation in Arkansas singles out Bitcoin miners introducing targeted state fee


The Winning Strategy: BRISE, BEFE, and CENX Lead Crypto Success | Live Bitcoin News

Top Trader Unveils Crypto Holdings Following Last Week’s Crash, Says Altcoin Recovery Now on Accelerated Timeline – The Daily Hodl

Overview Of UEX.Finance Cryptocurrency Exchange – CryptoInfoNet
Canadian dollar extends losses as Canada’s inflation rises – MarketPulse


Trust Wallet Warning: High-Risk Zero-Day iMessage Exploit Targeting iOS Users

XRP About to Face Huge Selling Pressure? — These 3 Warning Signs Could Send Ripple’s XRP Crashing

Acuity Trading and Excent Capital Partner for Market Analytics Integration

Polkadot eyes $8.8 million sponsorship deal with Lionel Messi’s Inter Miami




FMAS:24 Session Spotlight – Gold, South African Rand & The 2024 Financial Markets Outlook

Binance Academy Introduces University-Accredited Programs with Discount and Rewards

Exploding Gold Sales at Pawnshops Offers Lesson for Bitcoin Bulls

Saakuru Labs Secures $2.4 Million in Funding to Fuel the Adoption of the Saakuru Protocol

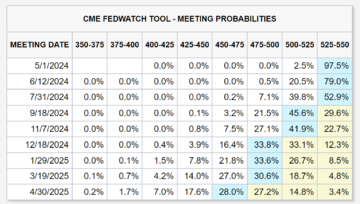
‘We Sold Everything Last Night’, Reveals Crypto Research Firm
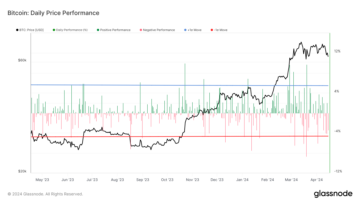
Bitcoin’s April plunge: On track for worst month since August down 11%
Vara Network’s Actor Model to Turbocharge Adoption of Blockchain Applications | Live Bitcoin News

How Soon Could Chiliz (CHZ) Hit the $1 Mark Amid Market Trends?

DWF Labs Renews Collaboration with DMCC to Propel MENA Blockchain Ecosystem Forward

Gold’s Outlook: Goldman Says $2,700 by Year End, Citi Says $3,000 Within 6-18 Months

‘A Masterpiece’ – Tether CEO Hints at New Fully Non-Custodial Tokenization Platform From Top Stablecoin Issuer – The Daily Hodl
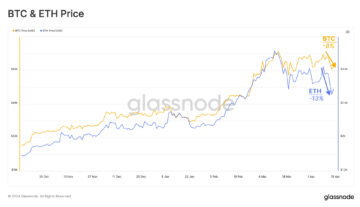

Bitcoin Price Slips Below $62,000 as Pre-Halving Momentum Stalls – Decrypt
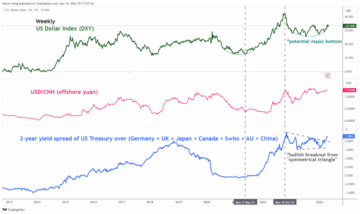
Currency war and geopolitical risk are deadly concoctions for risk assets – MarketPulse
Cashing In on Memes: Top Meme Coin Pick for April 2024
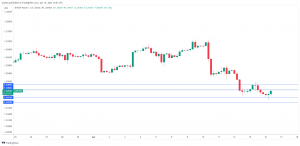



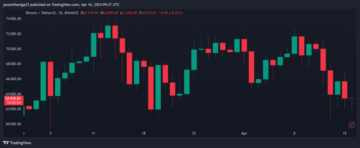
What Lies Ahead For Bitcoin As Halving Approaches in 3 Days?

P2E Space Nation Introduces ‘Cosmorathon’ for $OIK Airdrop | BitPinas

Major Crypto Exchange CEO Predicts Impact of Bitcoin Halving 2024


Trust Wallet releases advisory on zero-day exploit exposing iOS users

Solana Renaissance Hackathon PH: Local Demo Day Winners | BitPinas
Bitcoin Investors In The Red: Losses Trump Profits As Ratio Dips Below 1

Bitcoin Funds Saw $110 Million Weekly Outflows – Unchained
Plato Delivers Authenticity in an Ad-Free Environment.
Plato delivers an immersive UI / UX experience via a proprietary Hashtagging algorithm that is optimized for search. Using our technology, we organically generated over 5M users since launching our beta in April of 2020. Plato identifies and organizes both public and private data sources that makes accessing this information faster and more efficient. By layering information with highly contextual and validated data sets, we create an authentic and value driven user experience.
Plato Defi Gateway.
Your Access to the world of Decentralized Finance.
Vertical Specific Search
Your Vertical. Your Edge.
Plato Empowers Discovery
Plato was designed to seamlessly connect users with hundreds of sector specific applications by providing an ultra-safe and secure environment for vertical real-time data intelligence through an intuitive and content-rich user experience.
Intuitive User Friendly UI / UX
While our Ai and machine learning automates and curates both structured and unstructured data, Plato’s modern interface quickly and easily connects users to hundreds of Decentralized Applications and associated data.
The Evolution of Search
Plato identifies and organizes both public and private data sources and makes accessing this information faster and more efficient, while driving open analytics across our entire data ecosystem.
Plato Delivers Contextual Relevancy
Plato was created to change the way business sector information is gathered and processed. By utilizing today’s most innovative technology tools, we connect users to the information that is driving today’s markets into the future.
Smarter Faster Insights
Features and Applications
Plato Data Engine
Our data engine utilizes the latest in machine learning to provide deep sector relevant data through vetted and consensus-driven sources, and our proprietary hash-tagging engine is at the core of a consensus driven search experience that eliminates the need to go to multiple sites and applications.
Plato Framework
The modularity of our framework allows our development team to quickly integrate new data streams and to rapidly develop and deploy plug-in utility applications to drive both user consumption and engagement, creating sector-specific intelligence via an Ai powered Search Engine.
Vertical Search & Ai
Plato is a vertical Search platform with artificial intelligence that optimizes data curation from multiple verified sources that are specific to today’s most active technology sectors like Blockchain, Cyber Security, Fintech and Artificial Intelligence. New sectors are integrated as desired with advanced automation tools.
DaaS / Sectors
-
Plato drives both discovery and connectivity across the following verticals: Aerospace, Ai, AR/VR, Automotive, Aviation, Big Data, Blockchain, Cannabis, Crowdfunding, CyberSecurity, Ecommerce, Edtech, Esports, Fintech, Gaming, IOT, Payments, Private Equity, Quantum, SaaS, SPACs, Startups, Venture Capital.
Multilingual Support
Technology has opened up real-time access to data as it happens anywhere in the world, with the only limitation being linguistic differences in language and culture and unification of messaging. To ensure availability of relevant data for all users, Plato is accessible and indexed across 23 Languages making true conversational search a reality.
PlatoAiStream
Plato delivers custom news streams for access to the information most relevant to you, chosen from hundreds of curated channels and available in 26+ Different Languages. Immediate access to the latest exchange data and pricing. Technical, Fundamental and Social Data. Multi Transitional Indexing. With Plato Ai AudioStream, you create your own broadcast channel.
Modular Integration
Distributed Trainable Ai
Data Ingestion and Analysis
Structured and unstructured data is ingested from a variety of vertically relevant sources through our API appliance.
Data Interpretation
Data is extracted and processed while our engine distills it into reportable and contextually relevant intelligence.
Parsing and Indexing
Vertical Data is indexed via consensus driven algorithms to optimize contextual relevancy, fluency and coherence.
Validation and Formatting
Data is synthesized, validated and formatted for optimal delivery and publishing.
Syndication and Distribution
New Nodes of Data are updated automatically and syndicated globally.
Engagement and Monetization
Engagement is managed in realtime with Freemium to Premium upgrades on the fly.