Plato Data Intelligence. Vertical Search. Ai
Plato’s Ai and advanced automation curates the latest sector intelligence with insights into the people, companies and culture driving innovation today.
Signup for Free. Get Access Now.
Plato Web3 DefiX Gateway. Access all your dApps in one place.
Connect with the thousands of dApps via a single and secure interface.
Your Gateway to the world of Decentralized Finance.
Plato OpenAi. Driving Smart Search.
By employing a completely new methodology related to search and Intelligence, we enable deep and authentic connectivity to today’s most innovative technology sectors. The platform provides an ultra-secure environment to consume sector-specific real-time data intelligence. Plato is accessible across 23 languages and 27 verticals.


TSMC Sees AI Accelerator Sales Soaring by 50% Annually

Spectacular 350% Explosion Predicted For Shiba Inu, XRP, Solana, Cardano, Avalanche, DOT

RoboHero’s Compromised Twitter Account Sounds Alarm on Web3 Projects Cybersecurity Vulnerabilities

Your Reliable Source For Impartial Analysis On Cryptocurrency And Forex Trading – CryptoInfoNet

Warren Buffett Warns Of Negative Outcome For Bitcoin – Is It A Risky Investment? – CryptoInfoNet

Democratizing access to AI development: Partnering with Prime Intellect


Blockchain Association Sues SEC Over Dealer Rule – Unchained

Crypto.com Postpones South Korea Launch After Reports of Money Laundering Probe

Ethereum On-Chain Health Holds Strong Amidst OI Plunge

FMAS:24 Speaker Spotlight – ‘FX and CFDs in Africa: Key Industry Trends’

XRP’s Price Plunge Spurs Whale Buying Frenzy Amidst Ripple Vs. SEC Saga

GuildFi Rebrands to Zentry, Launching a ‘Game of Games’ to Reward Players – Decrypt

Could Esienberg commodities conviction be smoking gun for Coinbase against SEC?


Fiserv’s Net Profits Increased by Over 30% in Early 2024

Ripple contests SEC’s US$2 bln fine, suggests US$10 mln

Akash (AKT) Leads Crypto Top 100 With 46% Rise: Here’s Why


Philippine SEC orders removal of Binance from Google and Apple app stores

Panda Swap Price Prediction: PANDA Skyrockets 28% As Traders Rush To Buy New SOL Meme Coin Slothana With Just Six Days Left

Venezuela turns to crypto for oil trades under renewed US sanctions: Reuters

Akash Network Price Prediction: AKT Is Top Gainer With 45% Surge As The World’s First AR/VR Crypto Rockets Towards $6M

Bitget Wallet’s Chief Operating Officer Presents Web3 Wallet Security Strategies at Blockchain Life Dubai

Why Two DePIN Projects Are Dominating the Top 100 With Double-Digit Gains – Decrypt

Ripple challenges SEC’s $2 billion fine, proposes $10 million settlement instead

Ray Dalio on Debt, Inflation, and the Role of Gold and Crypto


Venezuela Accelerates Shift to Tether (USDT) Amidst Tightening US Sanctions

BolsaDX: Your Secure, Simple, and Trusted Gateway to Digital Finance

Fidelity Digital Assets Q1 2024 Signals Report on Bitcoin Halving and Ethereum Upgrade Impact


Memecoin Mania Onboarding ‘Thousands and Thousands’ of People Into Base’s Economy, Says Creator Jesse Pollak – The Daily Hodl

analytica Convention 2024 Focuses on Vietnam’s Laboratory Needs

Just In: SEC Seeks Google, Apple Assistance to Ban Binance App | BitPinas

Tether Launches USDT on Telegram’s TON Blockchain; Expands Global Reach | BitPinas

SEC Seeks $5.3 Billion From Do Kwon and Terraform Labs – Unchained

Ethereum Struggles To Reach A High Of $3,239 And Is Stuck In A Range
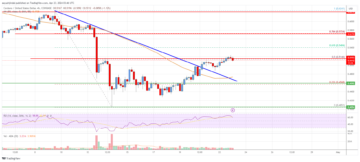
Cardano (ADA) Price Analysis: Bulls Aim Steady Increase | Live Bitcoin News
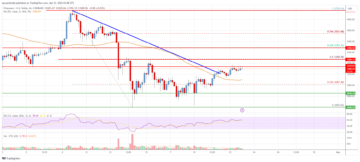
Ethereum Price Analysis: ETH Could Revisit $3,500 | Live Bitcoin News

Market Insights Podcast – BOJ, AU inflation, US PCE and US Magnificent 7 stocks earnings in the focus – MarketPulse

Fujitsu SX Survey reveals key success factors for sustainability

Blockchain Life 2024 thunderstruck in Dubai – CryptoCurrencyWire
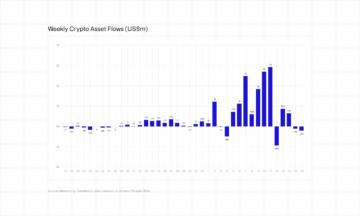
US Institutions Take $206,000,000 out of Crypto Investment Products Amid Interest Rate Worries: CoinShares – The Daily Hodl

Weekly Cryptocurrency Market Analysis: Altcoins Are In Free Fall After Losing Previous Gains



The Sandbox Partners With Hanjin Tan For Groundbreaking Metaverse Collaboration – CryptoInfoNet

Binance Executive’s Wife Refutes Extradition Claim; Thailand Strengthens Cryptocurrency Regulations – CryptoInfoNet

$0.001 SHIB Price Earthquake Looks Nigh As Shiba Inu Secures $12 Million For Its New Blockchain

Bitcoin Network Fees Stabilize After Unprecedented Chaos On Halving Day
New IRS Draft Tax Form Proposes Tracking of Certain Crypto Transactions – The Daily Hodl

Sam Bankman-Fried Agrees to Help FTX Investors Go After Celeb Promoters

MAS Markets Welcomes Gold-i’s Chris James as Chief Technology Officer


Stablecoins: The Federal Reserve’s Path to Taming Crypto’s Wild West

NYSE Asks Market Participants About 24/7 Trading for Stocks

Why the ‘Notcoin’ Token Launch Was Delayed—And When It’s Coming – Decrypt


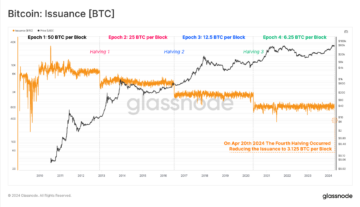
$BTC: Tezos Co-Founder on What’s Next for Bitcoin Post Its Fourth Halving
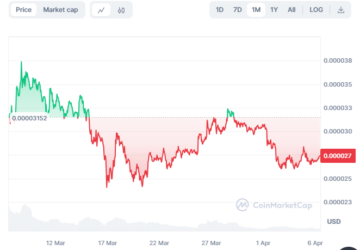
Shiba Inu Price Prediction: Can SHIB Hit $0.000129 by 2029?

FTX creditors invited to bid on Solana tokens in new auction format

BlackRock’s IBIT only 1 day away from top 10 status with unbroken inflow streak




Bitcoin miner earnings soar on halving day due to Runes

Over $500M Ethereum (ETH) Left CEXs as Market Prepares for Impulsive Move: Data

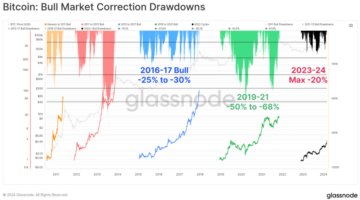

Bitcoin miners might pivot to AI after the halving — CoinShares

Google Nigeria Launches AI Training for Journalists in Lagos

Arkham Data Suggests US Government Has Significant BTC Holdings – CryptoCurrencyWire

Bitcoin Leads as Crypto Products See Second Week of Outflows, Totaling $206M

Bitcoin Technical Analysis: BTC Bulls Attempt to Push Prices Higher Post-Halving

Riding the Bitgert Coin Rally: Post-Halving Momentum | Live Bitcoin News

Molecular Farming Company to Achieve USDA Approval for Plant-Grown Animal Proteins

Bitcoin Price Prediction: BTC Fees Plunge Despite Runes Debut As This Bitcoin ICO Offers Last Chance To Buy After $13M Raise


Here’s Why Today is Important in the SEC v. Ripple Case

Unknown Shiba Inu Wallet Reactivated After 528 Days to Burn 372M+ SHIB
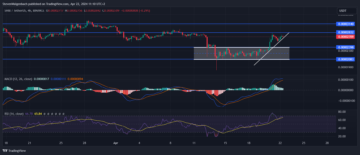
Shiba Inu Price Prediction: SHIB Soars 15% In A Week As It Raises $12 Million Via TREAT Token, And This Dogecoin Derivative Rockets Towards $10M
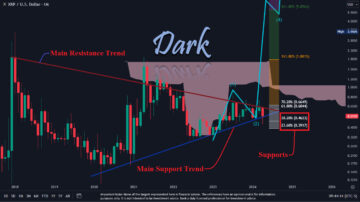
XRP Price Scenarios Ahead Of Ripple-SEC Case Update: Analyst

Why liquidity is an important metric in crypto markets

Bitget Featured at Token2049 Dubai with Panels and Key Side Events

Bitcoin Transaction Fees Experience Significant Drop Following Record High

Woo X Introduces Tokenized US Treasury Bills for Retail Investors


Binance Futures Introduces Updates to Taker Program, Offering Fee Discounts

Coins.ph, XD Academy Partner for Crypto Courses, Certifications | BitPinas

Ripple Price Oscillates Above $0.46 In Anticipation Of An Uptrend

slashing energy costs, boosting productivity with new manufacturing industry solutions

Bitcoin Will Shatter $16 Trillion Market Cap of Gold, Says SkyBridge Capital’s Anthony Scaramucci – Here’s How – The Daily Hodl

USD Deposits and Withdrawals Via Wire Transfer Now Available

NEC Strengthens Commitment to Space Industry with Investment in Seraphim Space Venture Fund II
Plato Delivers Authenticity in an Ad-Free Environment.
Plato delivers an immersive UI / UX experience via a proprietary Hashtagging algorithm that is optimized for search. Using our technology, we organically generated over 5M users since launching our beta in April of 2020. Plato identifies and organizes both public and private data sources that makes accessing this information faster and more efficient. By layering information with highly contextual and validated data sets, we create an authentic and value driven user experience.
Plato Defi Gateway.
Your Access to the world of Decentralized Finance.
Vertical Specific Search
Your Vertical. Your Edge.
Plato Empowers Discovery
Plato was designed to seamlessly connect users with hundreds of sector specific applications by providing an ultra-safe and secure environment for vertical real-time data intelligence through an intuitive and content-rich user experience.
Intuitive User Friendly UI / UX
While our Ai and machine learning automates and curates both structured and unstructured data, Plato’s modern interface quickly and easily connects users to hundreds of Decentralized Applications and associated data.
The Evolution of Search
Plato identifies and organizes both public and private data sources and makes accessing this information faster and more efficient, while driving open analytics across our entire data ecosystem.
Plato Delivers Contextual Relevancy
Plato was created to change the way business sector information is gathered and processed. By utilizing today’s most innovative technology tools, we connect users to the information that is driving today’s markets into the future.
Smarter Faster Insights
Features and Applications
Plato Data Engine
Our data engine utilizes the latest in machine learning to provide deep sector relevant data through vetted and consensus-driven sources, and our proprietary hash-tagging engine is at the core of a consensus driven search experience that eliminates the need to go to multiple sites and applications.
Plato Framework
The modularity of our framework allows our development team to quickly integrate new data streams and to rapidly develop and deploy plug-in utility applications to drive both user consumption and engagement, creating sector-specific intelligence via an Ai powered Search Engine.
Vertical Search & Ai
Plato is a vertical Search platform with artificial intelligence that optimizes data curation from multiple verified sources that are specific to today’s most active technology sectors like Blockchain, Cyber Security, Fintech and Artificial Intelligence. New sectors are integrated as desired with advanced automation tools.
DaaS / Sectors
-
Plato drives both discovery and connectivity across the following verticals: Aerospace, Ai, AR/VR, Automotive, Aviation, Big Data, Blockchain, Cannabis, Crowdfunding, CyberSecurity, Ecommerce, Edtech, Esports, Fintech, Gaming, IOT, Payments, Private Equity, Quantum, SaaS, SPACs, Startups, Venture Capital.
Multilingual Support
Technology has opened up real-time access to data as it happens anywhere in the world, with the only limitation being linguistic differences in language and culture and unification of messaging. To ensure availability of relevant data for all users, Plato is accessible and indexed across 23 Languages making true conversational search a reality.
PlatoAiStream
Plato delivers custom news streams for access to the information most relevant to you, chosen from hundreds of curated channels and available in 26+ Different Languages. Immediate access to the latest exchange data and pricing. Technical, Fundamental and Social Data. Multi Transitional Indexing. With Plato Ai AudioStream, you create your own broadcast channel.
Modular Integration
Distributed Trainable Ai
Data Ingestion and Analysis
Structured and unstructured data is ingested from a variety of vertically relevant sources through our API appliance.
Data Interpretation
Data is extracted and processed while our engine distills it into reportable and contextually relevant intelligence.
Parsing and Indexing
Vertical Data is indexed via consensus driven algorithms to optimize contextual relevancy, fluency and coherence.
Validation and Formatting
Data is synthesized, validated and formatted for optimal delivery and publishing.
Syndication and Distribution
New Nodes of Data are updated automatically and syndicated globally.
Engagement and Monetization
Engagement is managed in realtime with Freemium to Premium upgrades on the fly.