Plato Data Intelligence. Vertical Search. Ai
Plato’s Ai and advanced automation curates the latest sector intelligence with insights into the people, companies and culture driving innovation today.
Signup for Free. Get Access Now.
Plato Web3 DefiX Gateway. Access all your dApps in one place.
Connect with the thousands of dApps via a single and secure interface.
Your Gateway to the world of Decentralized Finance.
Plato OpenAi. Driving Smart Search.
By employing a completely new methodology related to search and Intelligence, we enable deep and authentic connectivity to today’s most innovative technology sectors. The platform provides an ultra-secure environment to consume sector-specific real-time data intelligence. Plato is accessible across 23 languages and 27 verticals.


NodeMonkes leads NFT sales with over US$1 million in a day


Bitcoin Mining Decentralization Not Great, Says Ordinals Creator – Unchained

Exness Wins ‘Best Trading Conditions 2024’ at UF Awards LATAM 2024

Stablecoin Bill Could Be Ready for the U.S. House Soon Says Top Democrat Maxine Waters: Bloomberg
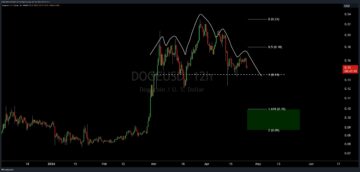
Head & Shoulders Alert: Dogecoin Could See A Price Crash Soon

Liquidations Exceed $200 Million As Bitcoin Falls Below $64K – CryptoInfoNet
BNB Chain to Enable Native Staking on BNB Smart Chain (BSC) following Beacon Chain Sunset

Negative Nirvana? Decoding The First Bitcoin Funding Rate Dip Of 2024

Cointelegraph Reports Meta’s 15% Drop Due To Disappointing Outlook And Increased Investments In AI And Metaverse – CryptoInfoNet

Bitcoin Will Still Hit $150,000 By Year-End Despite ETF Hype Dying Down — Standard Chartered

DogeMob Set to Enhance User Engagement and Utility Within its Ecosystem With Key Developments
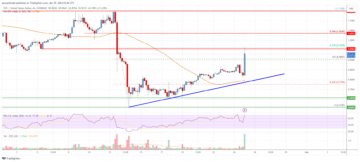
EOS Price Analysis: Gains Could Accelerate Above $1 | Live Bitcoin News

Here’s What Will Drive Bitcoin to $150K After the Halving: Standard Chartered
Litecoin (LTC) Price Analysis: Can Bulls Hold This Key Support? | Live Bitcoin News


Honda Reaches Basic Agreement with Asahi Kasei on Collaboration for Production of Battery Separators for Automotive Batteries in Canada

XRP Ledger’s Decentralized Exchange Sees Total Value Locked Soar Over 7.5 Million $XRP

High Bitcoin fees push active addresses down to 3-year low

Elevate Your Sleep Game This World Health Day with LAC
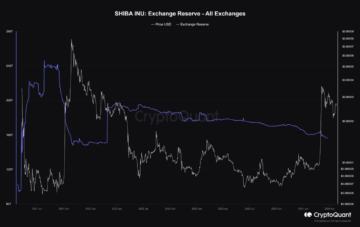
Shiba Inu’s Supply on Exchanges Drops to Two-Year Low as $SHIB Price Surges


TOKEN2049 Dubai 2024: A Resounding Success Despite the Rain

Ex-Binance CEO CZ seeks forgiveness and a fresh start in pre-sentencing apology letter

UNIQLO Sponsors KAWS + Warhol Exhibition Tour, Starting in Pittsburgh

Bitcoin Runes Transactions Are Taking Over the Network—And Dominating BRC-20 – Decrypt

Standard Chartered Remains Bullish on Crypto as Ether ETF Approval Delays are ‘Priced in’

ImmutableX Price Prediction for Today, April 24 – IMX Technical Analysis?

SEC Looking for $5,300,000,000 Penalty Against Terra-Founder Do Kwon, Alleging ‘Brazen Misconduct’: Report – The Daily Hodl
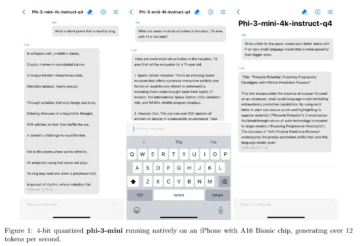
This Ultra Light AI Model Fits on Your Phone and Can Beat ChatGPT – Decrypt

Cardano Price Prediction for Today, April 24 – ADA Technical Analysis

Pyth Network boosts Morph DeFi ecosystem with real-time price feeds


10101.art transforms pieces from famous artists into RWA tokens


Paris Blockchain Week’s ‘Meet the Drapers’ – $10 Million Prize

Users Smitten by Microsoft’s Image to Video Tool – VASA-

Pent-Up Bitcoin Demand Could Come From Morgan Stanley and Other Institutions: Investor Brian Kelly – The Daily Hodl
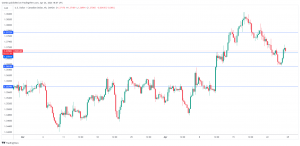
Canadian dollar dips as retail sales fall – MarketPulse

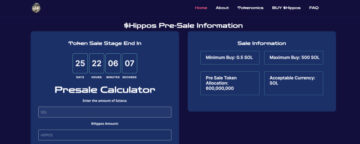
Hipposol, A Solana-based Memecoin Announces $Hippos Token Presale Round

Solana Price Recovers But Encounters Resistance At $159

CoinGecko Reveals Bitcoin Halving Occurred – CryptoCurrencyWire
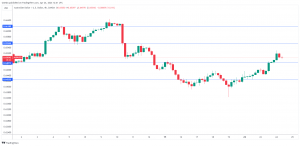
AUD/USD extends gains as inflation higher than expected – MarketPulse

Anticipated Return of $9B Mt. Gox-era Bitcoin May Spur Market Anxiety

Ex-Binance CEO faces 3-years prison and millions in fines

Binance Founder Changpeng Zhao Apologizes Ahead of Sentencing, 161 Others Send Letters of Support

Dogecoin Price Continues Recovery And Finds Support At Over $0.14

Number of Stablecoin Holders Nears 100M Mark, Data Show

Analyst Predicts Bitcoin Is Primed For Last Surge In Parabolic Trend, Shares Outlook – The Daily Hodl – CryptoInfoNet
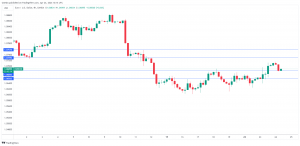
Euro edges lower despite stronger German business confidence – MarketPulse

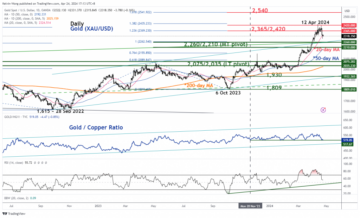
Gold Technical: Is the bull run over after its worst daily decline in 2 years? – MarketPulse
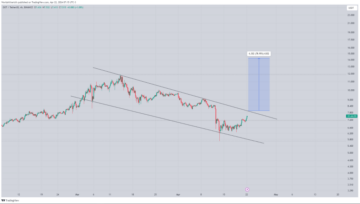
Bullish On Polkadot: Analyst Sees DOT Hitting $15 Soon



Detained Binance Executives’ Bail Hearing in Nigeria Pushed to May 17

Top 10 Crypto Puzzle: BlockDAG Crosses $19.8M, XRP Price Soars While Polygon NFT Sector Thrives | Live Bitcoin News

Ethereum Whales Turn Bullish As Over $92,020,000 in ETH Leaves Binance: Lookonchain – The Daily Hodl


MetaMask and Crypto Tax Calculator Team up to Save Crypto Investors This Tax Season

Worldcoin Announces Circulating Supply Update and Sales to Trading Firms

Mitsubishi Power Begins Commercial Operation of Seventh M701JAC Gas Turbine in Thailand GTCC Project; Achieves 75,000 AOH To-Date

President Joko Widodo Of Indonesia Issues Warning On Cryptocurrencies And NFTs Being Used For Money Laundering – CryptoInfoNet

Win Big with Bitsler’s Jackpot 30% Rakeback | BitcoinChaser


Hong Kong Crypto ETFs Get an April Launch Date – Unchained
How To Outperform In Crypto: Arthur Hayes’ ‘Left Curve’ Strategy

Binance Futures to Introduce USDC-Margined BOME, TIA, and MATIC Perpetual Contracts with Up to 75x Leverage

Harnessing Blockchain to Transform Healthcare Data Management

Coinstore Wraps Up Premiere Brand Conference in Dubai, Showcases New Crypto Initiatives | BitPinas

Block (NYSE: SQ) Making Progress on Development of Its Bitcoin Mining System


Changpeng Zhao could face a 3-year prison term as DOJ seeks to deter crypto crime

Base Chain Welcomes Inaugural Meme Coin Launchpad: A Beacon Against Scams and Rug Pulls

These US Asset Managers Just Bought Bitcoin Through Fidelity’s ETF

Unveiling Dork Lord: Your Path to the True Dark Side of Crypto Meme Tokens
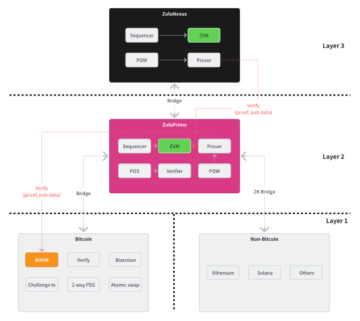
Zulu Network: Moving the Bitcoin Economy Forward With a Two-Tiered Bitcoin Layer 2 Architecture
Binance to Phase Out Deposits on BNB Beacon Chain (BEP2)


Hackers Leak Part of El Salvador’s Chivo Bitcoin ATM Source Code – Unchained

Blockchain Life 2024 thunderstruck in Dubai | Live Bitcoin News

Zircuit Readies for Mainnet Launch with Potential Airdrop for Early Users | BitPinas

Quant Continues Its Upward Trend And Recovers Over $100

Your Next Crypto Breakthrough Might Be a Walk in the Park – Literally – The Daily Hodl

XRP Price Eyes Breakout as Analyst Predicts Potential 150% Surge

Bitcoin Runes made up 57.7% of transactions on halving day

AI Assistant Users Could Develop An ‘Emotional Attachment’ to Them, Google Warns – Decrypt

Dogs Thrive on Vegan Diets, Demonstrates the Most Comprehensive Study So Far

Investors create group to take legal action against ZKasino co-founders

Tether Takes Action: Freezing Assets Amid Venezuela’s Crypto Strategy for Oil Exports


XRP Lawsuit Sees Unexpected Twist as Ripple Opposes SEC’s $2 Billion Fine Demand

Venezuela Turns To Crypto For Oil Sales To Evade Fresh Round Of U.S. Sanctions
Plato Delivers Authenticity in an Ad-Free Environment.
Plato delivers an immersive UI / UX experience via a proprietary Hashtagging algorithm that is optimized for search. Using our technology, we organically generated over 5M users since launching our beta in April of 2020. Plato identifies and organizes both public and private data sources that makes accessing this information faster and more efficient. By layering information with highly contextual and validated data sets, we create an authentic and value driven user experience.
Plato Defi Gateway.
Your Access to the world of Decentralized Finance.
Vertical Specific Search
Your Vertical. Your Edge.
Plato Empowers Discovery
Plato was designed to seamlessly connect users with hundreds of sector specific applications by providing an ultra-safe and secure environment for vertical real-time data intelligence through an intuitive and content-rich user experience.
Intuitive User Friendly UI / UX
While our Ai and machine learning automates and curates both structured and unstructured data, Plato’s modern interface quickly and easily connects users to hundreds of Decentralized Applications and associated data.
The Evolution of Search
Plato identifies and organizes both public and private data sources and makes accessing this information faster and more efficient, while driving open analytics across our entire data ecosystem.
Plato Delivers Contextual Relevancy
Plato was created to change the way business sector information is gathered and processed. By utilizing today’s most innovative technology tools, we connect users to the information that is driving today’s markets into the future.
Smarter Faster Insights
Features and Applications
Plato Data Engine
Our data engine utilizes the latest in machine learning to provide deep sector relevant data through vetted and consensus-driven sources, and our proprietary hash-tagging engine is at the core of a consensus driven search experience that eliminates the need to go to multiple sites and applications.
Plato Framework
The modularity of our framework allows our development team to quickly integrate new data streams and to rapidly develop and deploy plug-in utility applications to drive both user consumption and engagement, creating sector-specific intelligence via an Ai powered Search Engine.
Vertical Search & Ai
Plato is a vertical Search platform with artificial intelligence that optimizes data curation from multiple verified sources that are specific to today’s most active technology sectors like Blockchain, Cyber Security, Fintech and Artificial Intelligence. New sectors are integrated as desired with advanced automation tools.
DaaS / Sectors
-
Plato drives both discovery and connectivity across the following verticals: Aerospace, Ai, AR/VR, Automotive, Aviation, Big Data, Blockchain, Cannabis, Crowdfunding, CyberSecurity, Ecommerce, Edtech, Esports, Fintech, Gaming, IOT, Payments, Private Equity, Quantum, SaaS, SPACs, Startups, Venture Capital.
Multilingual Support
Technology has opened up real-time access to data as it happens anywhere in the world, with the only limitation being linguistic differences in language and culture and unification of messaging. To ensure availability of relevant data for all users, Plato is accessible and indexed across 23 Languages making true conversational search a reality.
PlatoAiStream
Plato delivers custom news streams for access to the information most relevant to you, chosen from hundreds of curated channels and available in 26+ Different Languages. Immediate access to the latest exchange data and pricing. Technical, Fundamental and Social Data. Multi Transitional Indexing. With Plato Ai AudioStream, you create your own broadcast channel.
Modular Integration
Distributed Trainable Ai
Data Ingestion and Analysis
Structured and unstructured data is ingested from a variety of vertically relevant sources through our API appliance.
Data Interpretation
Data is extracted and processed while our engine distills it into reportable and contextually relevant intelligence.
Parsing and Indexing
Vertical Data is indexed via consensus driven algorithms to optimize contextual relevancy, fluency and coherence.
Validation and Formatting
Data is synthesized, validated and formatted for optimal delivery and publishing.
Syndication and Distribution
New Nodes of Data are updated automatically and syndicated globally.
Engagement and Monetization
Engagement is managed in realtime with Freemium to Premium upgrades on the fly.