Organisationer använder sina data för att lösa komplexa problem genom att starta små, köra iterativa experiment och förfina lösningen. Även om kraften i experiment inte kan ignoreras, måste organisationer vara försiktiga med kostnadseffektiviteten av sådana experiment. Om tid läggs på att skapa den underliggande infrastrukturen för att möjliggöra experiment ökar det kostnaden ytterligare.
Utvecklare behöver en integrerad utvecklingsmiljö (IDE) för datautforskning och felsökning av arbetsflöden, och olika beräkningsprofiler för att köra dessa arbetsflöden. Om du väljer Amazon EMR för sådana användningsfall kan du använda en IDE som heter Amazon EMR Studio för datautforskning, transformation, versionskontroll och felsökning, och kör Spark-jobb för att bearbeta stora mängder data. Utplacering Amazon EMR på Amazon EKS förenklar hanteringen, minskar kostnaderna och förbättrar prestanda. En dataingenjör eller IT-administratör behöver dock lägga tid på att skapa den underliggande infrastrukturen, konfigurera säkerhet och skapa en hanterad slutpunkt som användare kan ansluta till. Detta innebär att sådana projekt måste vänta tills dessa experter skapar infrastrukturen.
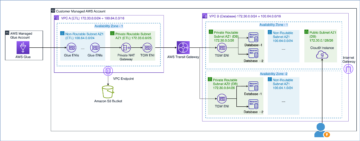
I det här inlägget visar vi hur en dataingenjör eller IT-administratör kan använda AWS Analytics Referensarkitektur (ARA) för att påskynda implementeringen av infrastrukturen, vilket sparar din organisation både tid och pengar som spenderas på dessa dataanalysexperiment. Vi använder biblioteket för att distribuera en Amazon Elastic Kubernetes (Amazon EKS) kluster, konfigurera det att använda Amazon EMR på EKS och distribuera ett virtuellt kluster och hanterade endpoints och EMR Studio. Du kan sedan antingen köra jobb på det virtuella klustret eller köra utforskande dataanalys med Jupyter anteckningsböcker på Amazon EMR Studio och Amazon EMR på EKS. Arkitekturen nedan representerar den infrastruktur du kommer att distribuera med AWS Analytics Reference Architecture.

Förutsättningar
För att följa med behöver du ha ett AWS-konto som är bootstrappat med AWS Cloud Development Kit (AWS CDK). För instruktioner, se Bootstrapping. Följande handledning använder TypeScript och kräver version 2 eller senare av AWS CDK. Om du inte har AWS CDK installerat, se Installera AWS CDK.
Skapa ett AWS CDK-projekt
För att distribuera resurser med hjälp av ARA måste du först ställa in ett AWS CDK-projekt och installera ARA-biblioteket. Slutför följande steg:
- Skapa en mapp som heter emr-eks-app:
- Initiera ett AWS CDK-projekt i en tom katalog och kör följande kommando:
- Installera ARA-biblioteket:
- I lib/emr-eks-app.ts importerar du ARA-biblioteket enligt följande. Den första raden anropar ARA-biblioteket, den andra definierar AWS Identity and Access Management-policyer (IAM):
Skapa och definiera ett EKS-kluster och beräkningskapacitet
För att skapa en EMR på EKS virtuellt klustermåste du först distribuera ett EKS-kluster. ARA-biblioteket definierar en konstruktion som kallas EmrEksCluster. Konstruktionen tillhandahåller ett EKS-kluster, möjliggör IAM -roller för servicekonton, och distribuerar en uppsättning stödjande kontroller som certifikathanterarkontroller (behövs av den hanterade slutpunkten som används av Amazon EMR Studio) samt en automatisk klusterskalare för att ha ett elastiskt kluster och spara kostnader när inget jobb skickas till klustret .
In lib/emr-eks-app.ts, lägg till följande rad:
För att lära dig mer om egenskaperna du kan anpassa, se EmrEksClusterProps. Det finns två obligatoriska parametrar i EmrEksCluster konstruktion: Den första är eksAdminRoleArn roll är obligatorisk och är den roll du använder för att interagera med Kubernetes kontrollplan. Den här rollen måste ha administrativa behörigheter skapa eller uppdatera klustret. Den andra parametern är autoscalingMed den här parametern kan du antingen välja mekanismen för automatisk skalning Snickare or inbyggd Kubernetes Cluster Autoscaler. I den här bloggen kommer vi att använda Karpenter och vi rekommenderar dess användning på grund av snabbare autoskalning, förenklad nodhantering och provisionering. Nu är du redo att definiera beräkningskapaciteten.
Ett sätt att definiera arbetarnoder i Amazon EKS är att använda hanterade nodgrupper. Vi använder en nodgrupp som heter tooling, som är värd för coredns, ingångskontroll, certifikatansvarig, Snickare och alla andra pod som är nödvändiga för att köra EMR på EKS-jobb eller ManagedEndpoint. Vi definierar också standard Karpenter Proviantörer som definierar kapacitet som ska användas för jobb som lämnats in av EMR på EKS. Dessa Provisioners är optimerade för olika användningsfall för Spark (kritiska jobb, icke-kritiskt jobb, experiment och interaktiva sessioner). Konstruktionen låter dig också skicka in din egen provisioner definierad av ett Kubernetes-manifest genom en metod som kallas addKarpenterProvisioner. Låt oss diskutera de fördefinierade Provisioners.
Standardkonfigurationer för Provisioners
Standardförvaltarna är inställda för snabba experiment och är skapas alltid som standard. Men om du inte vill använda dem kan du ställa in defaultNodeGroups parametern till false i EmrEksCluster fastigheter vid skapandet. Provisionerarna definieras enligt följande och skapas i vart och ett av undernäten som används av Amazon EKS:
- Kritisk proviantör – Den är dedikerad till att stödja jobb med aggressiva SLA:er och är tidskänsliga. Provideraren använder On-Demand Instances, som inte stoppas, till skillnad från Spot Instances, och deras livscykel följer genom ett av jobben. Noderna använder instanslager, som är NVMe-diskar som är fysiskt anslutna till värden, som erbjuder en hög I/O-genomströmning som tillåter bättre Spark-prestanda, eftersom den används som tillfällig lagring för diskspill och shuffle. De instanstyper som används i noden är av m6gd-familjen. Förekomsterna använder AWS Graviton processor, som erbjuder bättre pris/prestanda än x86-processorer. För att använda denna provisioner i dina jobb kan du använda följande exempelkonfiguration, som hänvisas till i åsidosätta konfigurationen av EMR om EKS-jobbinlämning.
- Icke-kritisk proviantör – Denna Provisioner utnyttjar Spot Instances för att spara kostnader för jobb som inte är tidskänsliga eller jobb som används för experiment. Den här noden använder Spot Instances eftersom jobben inte är kritiska och kan avbrytas. Dessa instanser kan stoppas om instansen återkrävs. Instanstyperna som används i noden är av m6gd-familjen, drivrutinen är On-Demand och exekutorer finns på platsinstanser.
- Provisionerare för anteckningsbok – Provisionern är till för att köra hanterade slutpunkter som används av Amazon EMR Studio för datautforskning med Amazon EMR på EKS. Förekomsterna är av t3-familjen och är On-Demand för drivrutiner och Spot-instanser för exekutörer för att hålla kostnaden låg. Om exekutörsinstanserna stoppas startas nya av Karpenter. Om exekveringsinstanserna stoppas för ofta kan du definiera dina egna som använder On-Demand-instanser.
Följande länk ger mer information om hur var och en av tillhandahållarna definieras. En importegenskap som är definierad i standardprovisionerarna är att det finns en för varje A-Ö. Detta är viktigt eftersom det låter dig minska överföringskostnaderna mellan AZ-nätverk när Spark kör en shuffle.
För det här inlägget använder vi standardtillhandahållare, så du behöver inte lägga till några rader kod för det här avsnittet. Om du vill lägga till dina egna Provisioners kan du utnyttja metoden addKarpenterProvisioner att tillämpa dina egna manifest. Du kan använda hjälpmetoder i Utils klass som readYamlDocument att läsa YAML-dokument och loadYaml ladda YAML-filer och skicka dem som argument till addKarpenterProvisioner metod.
Distribuera det virtuella klustret och en exekveringsroll
Ett virtuellt kluster är ett Kubernetes-namnområde som Amazon EMR är registrerat med; när du skickar ett jobb körs drivrutin- och executor-podden i det associerade namnområdet. De EmrEksCluster construct erbjuder en metod som kallas addEmrVirtualCluster, som skapar det virtuella klustret åt dig. Metoden tar EmrVirtualClusterOptions som en parameter, som har följande attribut:
- namn – Namnet på ditt virtuella kluster.
- skapa Namnutrymme – Ett valfritt fält som skapar EKS-namnområdet. Detta är av typen Boolean och som standard skapar det inte ett separat EKS-namnutrymme, så ditt virtuella kluster skapas i standardnamnutrymmet.
- eks Namnutrymme – Namnet på EKS-namnområdet som ska länkas till det virtuella EMR-klustret. Om inget namnutrymme tillhandahålls, använder konstruktionen standardnamnutrymmet.
- In
lib/emr-eks-app.ts, lägg till följande rad för att skapa ditt virtuella kluster:Nu skapar vi exekveringsrollen, som är en IAM-roll som används av föraren och executorn för att interagera med AWS-tjänster. Innan vi kan skapa exekveringsrollen för Amazon EMR måste vi först skapa
ManagedPolicy. Observera att i följande kod skapar vi en policy för att tillåta åtkomst till Amazon Simple Storage Service (Amazon S3) hink och Amazon CloudWatch-loggar. - In
lib/emr-eks-app.ts, lägg till följande rad för att skapa policyn:Om du vill använda AWS Glue Data Catalog, lägg till dess behörighet i föregående policy.
Nu skapar vi exekveringsrollen för Amazon EMR på EKS med den policy som definierades i föregående steg med hjälp av
createExecutionRoleinstansmetoden. Drivrutin- och exekutorpodarna kan sedan anta denna roll för att komma åt och bearbeta data. Rollen är avgränsad på ett sådant sätt att endast poddar i det virtuella klustrets namnutrymme kan anta den. För att lära dig mer om villkoret som implementeras av den här metoden för att begränsa åtkomsten till rollen till endast poddar som skapas av Amazon EMR på EKS i namnutrymmet för det virtuella klustret, se Använda jobbexekveringsroller med Amazon EMR på EKS. - In
lib/emr-eks-app.ts, lägg till följande rad för att skapa exekveringsrollen:Den föregående koden producerar en IAM-roll som kallas
execRoleJobmed IAM-policyn definierad iemrekspolicyoch omfattning till namnområdetdataanalysis. - Slutligen matar vi ut parametrar som är viktiga för jobbet:
Distribuera Amazon EMR Studio och tillhandahåll användare
För att distribuera en EMR Studio för datautforskning och jobbförfattande har ARA-biblioteket en konstruktion som heter NotebookPlatform. Denna konstruktion låter dig distribuera så många EMR Studios som du behöver (inom kontogränsen) och ställa in dem med det autentiseringsläge som är lämpligt för dig och tilldela användare till dem. För att lära dig mer om de autentiseringslägen som är tillgängliga i Amazon EMR Studio, se Välj ett autentiseringsläge för Amazon EMR Studio.
Konstruktionen skapar alla nödvändiga IAM-roller och policyer som behövs av Amazon EMR Studio. Det skapar också en S3-hink där alla bärbara datorer lagras av Amazon EMR Studio. Hinken är krypterad med en kundhanterad nyckel (CMK) genererad av AWS CDK-stacken. Följande steg visar dig hur du skapar din egen EMR Studio med konstruktionen.
Konstruktionen av den bärbara plattformen tar NotebookPlatformProps som en egenskap, som låter dig definiera din EMR Studio, ett namnområde, namnet på EMR Studion och dess autentiseringsläge.
- In
lib/emr-eks-app.ts, lägg till följande rad:För det här inlägget använder vi IAM-användare så att du enkelt kan återskapa det på ditt eget konto. Men om du redan har IAM-federation eller enkel inloggning (SSO) på plats kan du använda dem istället för IAM-användare. För att lära dig mer om parametrarna för
NotebookPlatformProps, hänvisa till NotebookPlatformProps.Därefter måste vi skapa och tilldela användare till Amazon EMR Studio. För detta har konstruktionen en metod som kallas
addUsersom tar en lista över användare och antingen tilldelar dem till Amazon EMR Studio vid SSO eller uppdaterar IAM-policyn för att tillåta åtkomst till Amazon EMR Studio för de angivna IAM-användarna. Användaren kan också ha flera hanterade slutpunkter, och varje användare kan ha sin Amazon EMR-version definierad. De kan använda en annan uppsättning Amazon Elastic Compute Cloud (Amazon EC2)-instanser och olika behörigheter med hjälp av jobbexekveringsroller. - In
lib/emr-eks-app.ts, lägg till följande rad:I den föregående koden återanvänder vi för korthetens skull samma IAM-policy som vi skapade i exekveringsrollen.
Observera att konstruktionen optimerar antalet hanterade slutpunkter som skapas. Om två ändpunkter har samma namn skapas bara en.
- Nu när vi har definierat vår implementering kan vi distribuera den:
Du kan hitta ett exempelprojekt som innehåller alla stegen i genomgången i följande GitHub Repository.
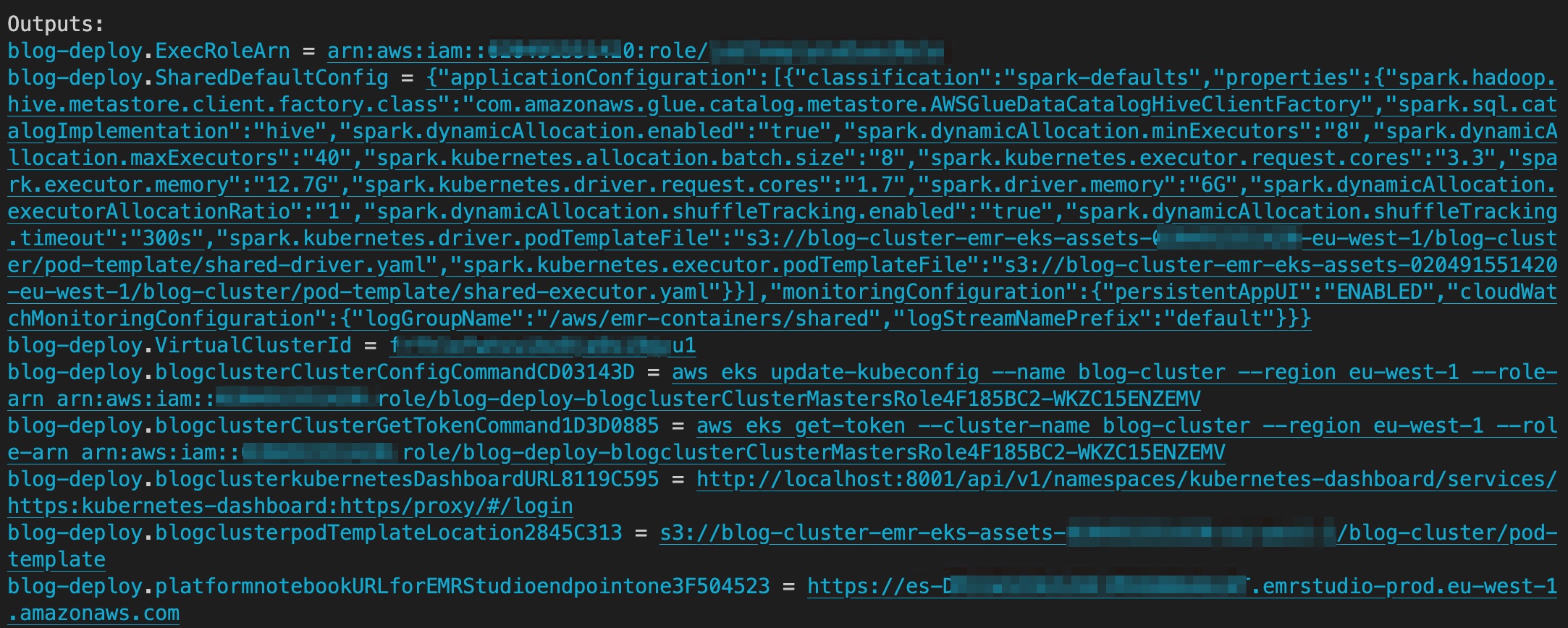
När distributionen är klar innehåller utgången S3-hinken som innehåller tillgångarna för podTemplate, länken till EMR Studio och EMR Studios virtuella kluster-ID. Följande skärmdump visar utdata från AWS CDK efter att distributionen är klar.
Skicka in jobb

Eftersom vi använder standardleverantörerna kommer vi att använda podTemplate som definieras av konstruktionen som är tillgänglig på ARA GitHub-förråd. Dessa laddas upp åt dig av konstruktionen till en S3-hink som heter <clustername>-emr-eks-assets; du behöver bara hänvisa till dem i ditt Spark-jobb. I det här jobbet använder du också jobbparametrarna i utgången i slutet av AWS CDK-distributionen. Dessa parametrar låter dig använda AWS Glue Data Catalog och implementera Spark på Kubernetes bästa praxis som dynamicAllocation och podsamlokalisering. I slutet av cdk deploy ARA kommer att mata ut jobbexempelkonfigurationer med de bästa praxis som listats tidigare som du kan använda för att skicka in ett jobb. Du kan skicka in ett jobb enligt följande.
En jobbkörning är en arbetsenhet som en Spark JAR-fil som skickas till EMR på EKS-klustret. Vi börjar ett jobb med hjälp av start-job-run kommando. Observera att du kan använda SparkSubmitParameters för att ange Amazon S3-sökvägen till podmallen, som visas i följande kommando:
Koden har följande värden:
- – EMR virtuella kluster-ID
- – Namnet på ditt Spark-jobb
- – Utföranderollen du skapade
- – Amazon S3 URI för ditt Spark-jobb
- – Amazon S3 URI för drivrutinspodmallen, som du får från AWS CDK-utgången
- – Amazon S3 URI för executor pod-mallen
- – Ditt CloudWatch-logggruppsnamn
- – Ditt CloudWatch-loggströmsprefix
Du kan gå till Amazon EMR-konsolen för att kontrollera statusen för ditt jobb och för att se loggar. Du kan också kontrollera status genom att köra describe-job-run kommando:
Utforska data med Amazon EMR Studio
I det här avsnittet visar vi hur du kan skapa en arbetsyta i Amazon EMR Studio och ansluta till den Amazon EKS-hanterade slutpunkten från arbetsytan. Från utgången, använd länken till Amazon EMR Studio för att navigera till EMR Studio-distributionen. Du måste logga in med IAM Användarnamn du angav i addUser metod.
Skapa en arbetsyta
Utför följande steg för att skapa en arbetsyta:
- Logga in på EMR Studio skapad av AWS CDK.
- Välja Skapa arbetsyta.
- Ange ett namn på arbetsytan och en valfri beskrivning.
- Välja Tillåt Workspace Collaboration om du vill arbeta med andra Studio-användare i denna arbetsyta i realtid.
- Välja Skapa arbetsyta.

När du har skapat arbetsytan väljer du den från listan med arbetsytor för att öppna JupyterLab-miljön.
Följande skärmdump visar hur terminalen ser ut. För mer information om användargränssnittet, se Förstå Workspace-användargränssnittet.
Anslut till en EMR på EKS-hanterad slutpunkt
Du kan enkelt ansluta till EMR på EKS-hanterad slutpunkt från arbetsytan.
- I navigeringsrutan, på kluster menyn, välj EMR-kluster på EKS för Klustertyp.
De virtuella klustren visas på rullgardinsmenyn EMR-kluster på EKS, och slutpunkten visas på rullgardinsmenyn Endpoint. Om det finns flera slutpunkter visas de här och du kan enkelt växla mellan slutpunkter från arbetsytan. - Välj lämplig slutpunkt och välj Bifoga.

Arbeta med en anteckningsbok
Du kan nu öppna en anteckningsbok och ansluta till en önskad kärna för att utföra dina uppgifter. Du kan till exempel välja en PySpark-kärna, som visas i följande skärmdump.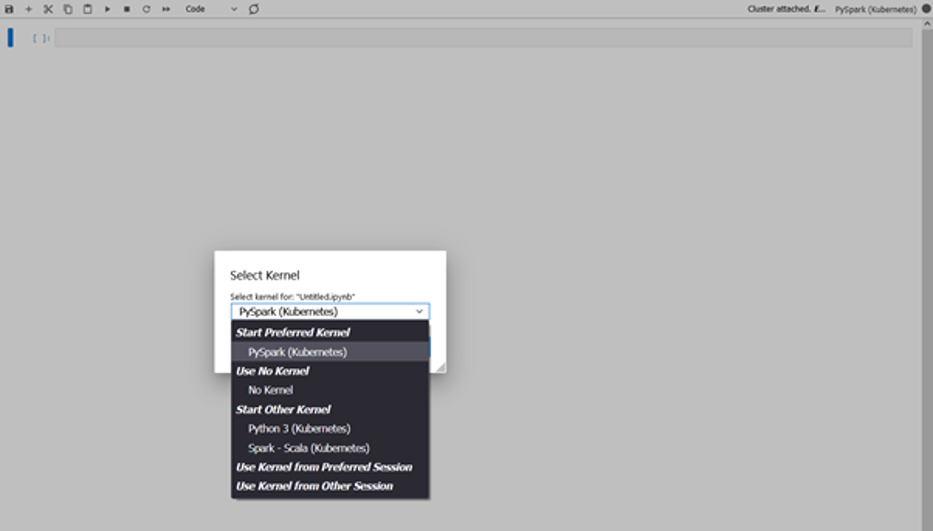
Utforska din data
Det första steget i vår datautforskningsövning är att skapa en Spark-session och sedan ladda New York-taxidataset från S3-skopan till en dataram. Använd följande kodblock för att ladda data till en dataram. Kopiera Amazon S3 URI för platsen där datasetet finns i Amazon S3.
När vi har laddat in data i en dataram, ersätter vi data från current_date kolumn med aktuellt datum, räkna antalet rader och spara data i en parkettfil:
Följande skärmdump visar resultatet av vår anteckningsbok som körs på Amazon EMR Studio och med PySpark som körs på Amazon EMR på EKS.
Städa upp
För att rensa efter det här inlägget, kör cdk destroy.
Slutsats
I det här inlägget visade vi hur du kan använda ARA för att snabbt distribuera en dataanalysinfrastruktur och börja experimentera med dina data. Du kan hitta det fullständiga exemplet som refereras till i det här inlägget i GitHub repository. AWS Analytics Reference Architecture implementerar vanliga Analytics-mönster och AWS bästa praxis för att erbjuda dig färdiga att använda konstruktioner för dina experiment. Ett av mönstren är datanätet, som du kan konsultera hur du använder i detta blogginlägg.
Du kan också utforska andra konstruktioner som erbjuds i detta bibliotek att experimentera med AWS Analytics-tjänster innan du flyttar över din arbetsbelastning för produktion.
Om författarna
 Lotfi Mouhib är en Senior Solutions Architect som arbetar för den offentliga sektorns team med Amazon Web Services. Han hjälper offentliga kunder i hela EMEA att förverkliga sina idéer, bygga nya tjänster och förnya för medborgarna. På fritiden tycker Lotfi om att cykla och springa.
Lotfi Mouhib är en Senior Solutions Architect som arbetar för den offentliga sektorns team med Amazon Web Services. Han hjälper offentliga kunder i hela EMEA att förverkliga sina idéer, bygga nya tjänster och förnya för medborgarna. På fritiden tycker Lotfi om att cykla och springa.
 Sandipan Bhaumik är en Senior Analytics Specialist Solutions Architect baserad i London. Han har arbetat med kunder i olika branscher som bank- och finanstjänster, hälsovård, kraft och energi, tillverkning och detaljhandel och hjälpt dem att lösa komplexa utmaningar med storskaliga dataplattformar. På AWS fokuserar han på strategiska konton i Storbritannien och Irland och hjälper kunder att påskynda sin resa till molnet och förnya sig med hjälp av AWS-analys och maskininlärningstjänster. Han älskar att spela badminton och läsa böcker.
Sandipan Bhaumik är en Senior Analytics Specialist Solutions Architect baserad i London. Han har arbetat med kunder i olika branscher som bank- och finanstjänster, hälsovård, kraft och energi, tillverkning och detaljhandel och hjälpt dem att lösa komplexa utmaningar med storskaliga dataplattformar. På AWS fokuserar han på strategiska konton i Storbritannien och Irland och hjälper kunder att påskynda sin resa till molnet och förnya sig med hjälp av AWS-analys och maskininlärningstjänster. Han älskar att spela badminton och läsa böcker.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/accelerate-your-data-exploration-and-experimentation-with-the-aws-analytics-reference-architecture-library/
- 1
- 10
- 100
- 11
- 6G
- 7
- 9
- a
- Om oss
- accelerera
- tillgång
- Behörighets förvaltning
- Konto
- konton
- tvärs
- åtgärder
- Lägger
- administrativa
- Efter
- aggressiv
- Alla
- fördelning
- tillåter
- redan
- Även
- amason
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- analys
- analytics
- och
- Apache
- app
- visas
- Ansök
- lämpligt
- arkitektur
- argument
- Tillgångar
- associerad
- bifoga
- attribut
- Autentisering
- författarskap
- bil
- tillgänglig
- AWS
- AWS-lim
- AWS Identity and Access Management (IAM)
- Banking
- baserat
- därför att
- innan
- nedan
- BÄST
- bästa praxis
- Bättre
- mellan
- Blockera
- Blogg
- Böcker
- SLUTRESULTAT
- byggare
- kallas
- Samtal
- Kapacitet
- Vid
- fall
- katalog
- försiktig
- CD
- certifikat
- utmaningar
- ta
- Välja
- medborgare
- klass
- klassificering
- klient
- cloud
- kluster
- koda
- Kolumn
- COM
- Gemensam
- fullborda
- komplex
- Compute
- tillstånd
- Kontakta
- Konsol
- konstruera
- innehåller
- kontroll
- styrenhet
- Pris
- Kostar
- skapa
- skapas
- skapar
- Skapa
- skapande
- kritisk
- Aktuella
- Kunder
- skräddarsy
- datum
- dataanalys
- Data Analytics
- dataingenjör
- Datum
- datum Tid
- dedicerad
- Standard
- definierar
- distribuera
- utplacera
- utplacering
- vecklas ut
- beskrivning
- detaljer
- Utveckling
- olika
- diskutera
- dokumentera
- inte
- inte
- chaufför
- varje
- lätt
- effekt
- antingen
- EMEA
- aktiverad
- möjliggör
- möjliggör
- krypterad
- Slutpunkt
- ingenjör
- Miljö
- Eter (ETH)
- exempel
- utförande
- Motionera
- experimentera
- experter
- utforskning
- Utforskande dataanalys
- utforska
- fabrik
- familj
- snabbare
- Federation
- fält
- Fil
- Filer
- finansiella
- finansiella tjänster
- hitta
- Förnamn
- fokuserar
- följer
- efter
- följer
- RAM
- från
- full
- funktioner
- ytterligare
- genereras
- skaffa sig
- GitHub
- Go
- Grupp
- Gruppens
- Hadoop
- hälso-och sjukvård
- hjälpa
- hjälper
- här.
- Hög
- Bikupa
- värd
- Hur ser din drömresa ut
- How To
- Men
- html
- HTTPS
- IAM
- idéer
- Identitet
- identitets- och åtkomsthantering
- Identitets- och åtkomsthantering (IAM)
- genomföra
- genomföras
- redskap
- importera
- med Esport
- förbättrar
- in
- industrier
- informationen
- Infrastruktur
- förnya
- installera
- exempel
- istället
- instruktioner
- integrerade
- interagera
- interaktiva
- Gränssnitt
- avbruten
- irland
- IT
- Jobb
- Lediga jobb
- resa
- json
- Ha kvar
- Kubernetes
- Large
- storskalig
- LÄRA SIG
- inlärning
- Hävstång
- Bibliotek
- BEGRÄNSA
- linje
- rader
- LINK
- kopplade
- Lista
- Noterade
- läsa in
- läge
- london
- UTSEENDE
- Låg
- Maskinen
- maskininlärning
- förvaltade
- ledning
- chef
- obligatoriskt
- Produktion
- många
- betyder
- mekanism
- Minne
- Meny
- metod
- metoder
- Mode
- pengar
- mer
- multipel
- namn
- Som heter
- Navigera
- Navigering
- nödvändigt för
- Behöver
- behövs
- behov
- nät
- Nya
- New York
- nod
- noder
- anteckningsbok
- bärbara datorer
- antal
- erbjudanden
- erbjuds
- Erbjudanden
- ONE
- öppet
- optimerad
- optimerar
- organisation
- organisationer
- Övriga
- egen
- panelen
- parameter
- parametrar
- bana
- Mönster
- mönster
- prestanda
- tillstånd
- behörigheter
- Fysiskt
- Plats
- plattform
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- i
- pods
- Strategier
- policy
- Inlägg
- kraft
- praxis
- föredragen
- föregående
- problem
- process
- Processorn
- Produktion
- Profiler
- projektet
- projekt
- egenskaper
- egenskapen
- förutsatt
- ger
- tillhandahållande
- allmän
- snabbt
- snabb
- Läsa
- Läsning
- redo
- verklig
- realtid
- inser
- rekommenderar
- register
- minska
- minskar
- registrerat
- ersätta
- representerar
- begära
- Kräver
- Resurser
- begränsa
- resultera
- detaljhandeln
- Roll
- roller
- Körning
- rinnande
- skull
- Samma
- Save
- sparande
- Andra
- §
- sektor
- säkerhet
- senior
- känslig
- service
- Tjänster
- session
- in
- show
- visas
- Visar
- blanda
- signera
- Enkelt
- förenklade
- enda
- Storlek
- Small
- So
- lösning
- Lösningar
- LÖSA
- Gnista
- specialist
- spendera
- spent
- Spot
- SQL
- stapel
- starta
- igång
- Starta
- uttalanden
- status
- Steg
- Steg
- slutade
- förvaring
- lagras
- lagrar
- Strategisk
- ström
- studio
- Studios
- underkastelse
- skicka
- lämnats
- subnät
- sådana
- lämplig
- levereras
- Stödjande
- Växla
- tar
- uppgifter
- grupp
- mall
- temporär
- terminal
- Smakämnen
- Storbritannien
- deras
- Genom
- genomströmning
- tid
- till
- alltför
- Totalt
- överföring
- Transformation
- transitio
- sann
- handledning
- typer
- skrivmaskin
- Uk
- underliggande
- enhet
- Uppdatering
- Uppdateringar
- uppladdad
- URI
- användning
- Användare
- Användargränssnitt
- användare
- verktyg
- värde
- Värden
- version
- versionskontroll
- utsikt
- Virtuell
- volym
- vänta
- webb
- webbservice
- Vad
- som
- kommer
- inom
- Arbete
- arbetade
- arbetstagaren
- arbetsflöden
- arbetssätt
- skriva
- jaml
- Din
- zephyrnet