Amazon EMR-serverlös låter dig köra stordataramverk med öppen källkod som Apache Spark och Apache Hive utan att hantera kluster och servrar. Med EMR Serverless kan du köra analytiska arbetsbelastningar i vilken skala som helst med automatisk skalning som ändrar storlek på resurser på några sekunder för att möta ändrade datavolymer och bearbetningskrav. EMR Serverless skalar automatiskt resurser upp och ner för att ge precis rätt mängd kapacitet för din applikation.
Vi är glada att kunna meddela att EMR Serverless nu erbjuder arbetarkonfigurationer med 8 vCPU:er med upp till 60 GB minne och 16 vCPU:er med upp till 120 GB minne, vilket gör att du kan köra mer beräknings- och minnesintensiva arbetsbelastningar på EMR Serverless. En EMR Serverless-applikation använder internt arbetare för att utföra arbetsbelastningar. och du kan konfigurera olika arbetarkonfigurationer baserat på dina arbetsbelastningskrav. Tidigare var den största arbetarkonfigurationen tillgänglig på EMR Serverless 4 vCPU:er med upp till 30 GB minne. Denna funktion är särskilt fördelaktig för följande vanliga scenarier:
- Blandade tunga arbetsbelastningar
- Minnesintensiva arbetsbelastningar
Låt oss titta på vart och ett av dessa användningsfall och fördelarna med att ha större arbetarstorlekar.
Fördelar med att använda stora arbetare för blandningsintensiva arbetsbelastningar
I Spark and Hive sker shuffle när data behöver omfördelas över klustret under en beräkning. När din applikation utför breda transformationer eller reducerar operationer som t.ex join, groupBy, sortBy, eller repartition, Spark and Hive utlöser en shuffle. Dessutom begränsas varje Spark-steg och Tez-vertex av en shuffle-operation. Med Spark som ett exempel, som standard finns det 200 partitioner för varje Spark-jobb som definieras av spark.sql.shuffle.partitions. Däremot kommer Spark att beräkna antalet uppgifter i farten baserat på datastorleken och operationen som utförs. När en bred transformation utförs ovanpå en stor datamängd kan det finnas GB eller till och med TB data som måste hämtas av alla uppgifter.
Blandningar är vanligtvis dyra i termer av både tid och resurser och kan leda till prestandaflaskhalsar. Därför kan optimering av shufflar ha en betydande inverkan på prestandan och kostnaden för ett Spark-jobb. Med stora arbetare kan mer data allokeras till varje exekutors minne, vilket minimerar data som blandas över executors. Detta leder i sin tur till ökad shuffle-läsprestanda eftersom mer data kommer att hämtas lokalt från samma arbetare och mindre data kommer att hämtas på distans från andra arbetare.
Experiment
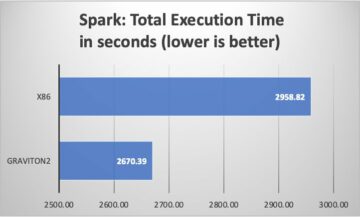
För att visa fördelarna med att använda stora arbetare för blandningsintensiva frågor, låt oss använda q78 från TPC-DS, som är en shuffle-tung Spark-fråga som blandar 167 GB data över 12 Spark-steg. Låt oss utföra två iterationer av samma fråga med olika konfigurationer.
Konfigurationerna för Test 1 är följande:
- Storlek på exekutor som begärdes när EMR Serverless-applikation skapades = 4 vCPU:er, 8 GB minne, 200 GB disk
- Spark job-konfiguration:
spark.executor.cores= 4spark.executor.memory= 8spark.executor.instances= 48- Parallellism = 192 (
spark.executor.instances*spark.executor.cores)
Konfigurationerna för Test 2 är följande:
- Storlek på exekutor som begärdes när EMR Serverless-applikation skapades = 8 vCPU:er, 16 GB minne, 200 GB disk
- Spark job-konfiguration:
spark.executor.cores= 8spark.executor.memory= 16spark.executor.instances= 24- Parallellism = 192 (
spark.executor.instances*spark.executor.cores)
Låt oss också inaktivera dynamisk allokering genom att ställa in spark.dynamicAllocation.enabled till false för båda testerna för att undvika eventuellt brus på grund av varierande starttider för executor och hålla resursutnyttjandet konsekvent för båda testerna. Vi använder Gnistmått, som är ett verktyg med öppen källkod som förenklar insamlingen och analysen av Spark-prestandamått. Eftersom vi använder ett fast antal executorer är det totala antalet vCPU:er och minne som begärs detsamma för båda testerna. Följande tabell sammanfattar observationerna från de mätvärden som samlats in med Spark Measure.
| . | Total tid som tagits för fråga i millisekunder | shuffleLocalBlocksHämtade | shuffleRemoteBlocksHämtade | shuffleLocalBytesRead | shuffleRemoteBytesRead | shuffleFetchWaitTime | shuffleWriteTime |
| Test 1 | 153244 | 114175 | 5291825 | 3.5 GB | 163.1 GB | 1.9 hr | 4.7 min |
| Test 2 | 108136 | 225448 | 5185552 | 6.9 GB | 159.7 GB | 3.2 min | 5.2 min |
Som framgår av tabellen är det en betydande skillnad i prestanda på grund av förbättringar av shuffle. Test 2, med hälften så många exekverare som är dubbelt så stora som test 1, körde 29.44 % snabbare, med 1.97 gånger mer shuffle-data hämtade lokalt jämfört med test 1 för samma fråga, samma parallellitet och samma aggregerade vCPU- och minnesresurser . Därför kan du dra nytta av förbättrad prestanda utan att kompromissa med kostnader eller jobbparallellitet med hjälp av stora utförare. Vi har observerat liknande prestandafördelar för andra blandningsintensiva TPC-DS-frågor som t.ex Q23A och q23b.
Rekommendationer
För att avgöra om de stora arbetarna kommer att gynna dina shuffle-intensiva Spark-applikationer, överväg följande:
- Kontrollera praktik fliken från Spark History Server UI för din EMR Serverless-applikation. Till exempel, från följande skärmdump av Spark History Server, kan vi fastställa att det här Spark-jobbet skrev och läste 167 GB shuffle-data samlat över 12 steg, tittar på Blanda Läs och Blanda Skriv kolumner. Om dina jobb blandar över 50 GB data kan du eventuellt dra nytta av att använda större arbetare med 8 eller 16 vCPU:er eller
spark.executor.cores.

- Kontrollera SQL / DataFrame fliken från Spark History Server UI för din EMR Serverless-applikation (endast för Dataframe och Dataset APIs). När du väljer den Spark-åtgärd som utförs, såsom samla in, ta, visa String eller spara, kommer du att se en aggregerad DAG för alla stadier åtskilda av utbytena. Varje utbyte i DAG motsvarar en shuffle-operation, och den kommer att innehålla de lokala och avlägsna byten och blocken blandade, som visas i följande skärmdump. Om de lokala shuffle-blocken eller byten som hämtas är mycket mindre jämfört med fjärrblocken eller byte som hämtas, kan du köra om din applikation med större arbetare (med 8 eller 16 vCPU:er eller spark.executor.cores) och granska dessa utbytesmått i en DAG för att se om det blir någon förbättring.

- Använd Gnistmått verktyg med din Spark-fråga för att få shuffle-statistiken i Spark-förarens
stdoutloggar, som visas i följande logg för ett Spark-jobb. Granska tiden det tar för att blanda läsningar (shuffleFetchWaitTime) och blanda skriver (shuffleWriteTime), och förhållandet mellan de lokala byten som hämtas och de fjärrbyte som hämtas. Om blandningsoperationen tar mer än 2 minuter, kör din applikation igen med större arbetare (med 8 eller 16 vCPUs ellerspark.executor.cores) med Spark Measure för att spåra förbättringen av shuffle-prestanda och den totala jobbets körtid.
Fördelar med att använda stora arbetare för minnesintensiva arbetsbelastningar
Vissa typer av arbetsbelastningar är minneskrävande och kan dra nytta av mer minne som konfigureras per arbetare. I det här avsnittet diskuterar vi vanliga scenarier där stora arbetare kan vara fördelaktiga för att köra minnesintensiva arbetsbelastningar.
Data skev
Dataskevningar förekommer vanligtvis i flera typer av datamängder. Några vanliga exempel är bedrägeriupptäckt, befolkningsanalys och inkomstfördelning. Till exempel, när du vill upptäcka avvikelser i dina data, förväntas det att endast mindre än 1 % av data är onormala. Om du vill utföra en viss aggregering utöver normala kontra onormala poster, kommer 99 % av data att behandlas av en enskild arbetare, vilket kan leda till att den arbetaren får slut på minne. Dataskevheter kan observeras för minnesintensiva transformationer som groupBy, orderBy, join, fönsterfunktioner, collect_list, collect_set, och så vidare. Gå med typer som t.ex BroadcastNestedLoopJoin och Cartesan-produkter är också i sig minnesintensiva och känsliga för dataskevheter. På samma sätt, om din indata är Gzip-komprimerad, kan en enda Gzip-fil inte läsas av mer än en uppgift eftersom Gzip-komprimeringstypen är ofördelbar. När det finns några mycket stora Gzip-filer i inmatningen, kan ditt jobb ta slut på minne eftersom en enda uppgift kan behöva läsa en enorm Gzip-fil som inte får plats i exekveringsminnet.
Misslyckanden på grund av dataskev kan mildras genom att tillämpa strategier som saltning. Detta kräver dock ofta omfattande ändringar av koden, vilket kanske inte är genomförbart för en produktionsbelastning som misslyckades på grund av en aldrig tidigare skådad dataskevning orsakad av en plötslig ökning av inkommande datavolym. För en enklare lösning kanske du bara vill öka arbetarminnet. Använder större arbetare med fler spark.executor.memory låter dig hantera dataskev utan att göra några ändringar i din applikationskod.
caching
För att förbättra prestandan låter Spark dig cachelagra dataramar, datauppsättningar och RDD:er i minnet. Detta gör att du kan återanvända en dataram flera gånger i din applikation utan att behöva beräkna den igen. Som standard används upp till 50 % av din exekutors JVM för att cache dataramarna baserat på property spark.memory.storageFraction. Till exempel om din spark.executor.memory är inställd på 30 GB, sedan används 15 GB för cachelagring som är immun mot vräkning.
Standardlagringsnivån för cacheoperation är DISK_AND_MEMORY. Om storleken på dataramen du försöker cache inte får plats i executorns minne, spills en del av cachen till disken. Om det inte finns tillräckligt med utrymme för att skriva cachad data på disken, vräkas blocken och du får inte fördelarna med cachning. Genom att använda större arbetare kan du cachelagra mer data i minnet, vilket ökar jobbprestanda genom att hämta cachade block från minnet snarare än den underliggande lagringen.
Experiment
Till exempel följande PySpark jobb leder till en skevhet, med en exekutor som bearbetar 99.95 % av data med minnesintensiva aggregat som collect_list. Jobbet cachar också en mycket stor dataram (2.2 TB). Låt oss köra två iterationer av samma jobb på EMR Serverless med följande vCPU- och minneskonfigurationer.
Låt oss köra Test 3 med de tidigare största möjliga arbetarkonfigurationerna:
- Storlek på exekutor som ställs in vid skapandet av EMR-serverlös applikation = 4 vCPU:er, 30 GB minne, 200 GB disk
- Spark job-konfiguration:
spark.executor.cores= 4spark.executor.memory= 27 G
Låt oss köra Test 4 med de nyligen släppta stora arbetarkonfigurationerna:
- Storlek på executor som ställdes in när EMR Serverless-applikation skapades = 8 vCPU:er, 60 GB minne, 200 GB disk
- Spark job-konfiguration:
spark.executor.cores= 8spark.executor.memory= 54 G
Test 3 misslyckades med FetchFailedException, vilket resulterade på grund av att exekveringsminnet inte var tillräckligt för jobbet.

Dessutom, från Spark UI i Test 3, ser vi att det reserverade lagringsminnet för exekverarna utnyttjades fullt ut för att cache dataramarna.

De återstående blocken som skulle cachelagrades spilldes till disk, som ses i exekutörens stderr loggar:
Ungefär 33 % av den kvarstående dataramen cachelagrades på disken, som ses på lagring fliken i Spark UI.

Test 4 med större exekutorer och vCores kördes framgångsrikt utan att kasta några minnesrelaterade fel. Dessutom cachades endast cirka 2.2 % av dataramen till disken. Därför kommer cachade block av en dataram att hämtas från minnet snarare än från disk, vilket ger bättre prestanda.

Rekommendationer
För att avgöra om de stora arbetarna kommer att gynna dina minnesintensiva Spark-applikationer, överväg följande:
- Ta reda på om din Spark-applikation har några dataskevheter genom att titta på Spark-gränssnittet. Följande skärmdump av Spark-gränssnittet visar ett exempel på dataskevscenario där en uppgift bearbetar det mesta av data (145.2 GB) och tittar på Blanda Läs storlek. Om en eller färre uppgifter bearbetar betydligt mer data än andra uppgifter, kör din applikation igen med större arbetare med 60–120 G minne (
spark.executor.memoryinställd på allt från 54–109 GB med 10 % avspark.executor.memoryOverhead).

- Kontrollera lagring fliken i Spark History Server för att granska förhållandet mellan data cachad i minnet och disk från Storlek i minnet och Storlek i disk kolumner. Om mer än 10 % av din data är cachad till disk, kör du om programmet med större arbetare för att öka mängden data som cachelagras i minnet.
- Ett annat sätt att förebyggande avgöra om ditt jobb behöver mer minne är genom att övervaka Peak JVM-minne på Spark UI testamentsexekutorer flik. Om peak JVM-minnet som används ligger nära executor- eller drivrutinminnet kan du skapa en applikation med en större arbetare och konfigurera ett högre värde för
spark.executor.memoryorspark.driver.memory. Till exempel, i följande skärmdump, är det maximala värdet för maximal JVM-minneanvändning 26 GB ochspark.executor.memoryär inställd på 27 G. I det här fallet kan det vara fördelaktigt att använda större arbetare med 60 GB minne ochspark.executor.memoryinställd på 54 G.

Överväganden
Även om stora vCPU:er hjälper till att öka lokaliteten för shuffle-blocken, finns det andra faktorer inblandade, såsom diskgenomströmning, disk IOPS (input/output operations per second) och nätverksbandbredd. I vissa fall kan fler små arbetare med fler diskar erbjuda högre disk IOPS, genomströmning och nätverksbandbredd totalt sett jämfört med färre stora arbetare. Vi uppmuntrar dig att jämföra dina arbetsbelastningar mot lämpliga vCPU-konfigurationer för att välja den bästa konfigurationen för din arbetsbelastning.
För blandningstunga jobb rekommenderas det att använda stora diskar. Du kan bifoga upp till 200 GB disk till varje arbetare när du skapar din applikation. Använda stora vCPU:er (spark.executor.cores) per executor kan öka diskanvändningen på varje arbetare. Om din applikation misslyckas med "Inget utrymme kvar på enheten" på grund av oförmågan att passa shuffle-data på disken, använd fler mindre arbetare med 200 GB disk.
Slutsats
I det här inlägget lärde du dig om fördelarna med att använda stora exekutörer för dina EMR-serverlösa jobb. För mer information om olika arbetarkonfigurationer, se Arbetarkonfigurationer. Stora arbetarkonfigurationer är tillgängliga i alla regioner där EMR Serverless finns tillgänglig.
Om författaren
 Veena Vasudevan är Senior Partner Solutions Architect och Amazon EMR-specialist på AWS med fokus på big data och analys. Hon hjälper kunder och partners att bygga mycket optimerade, skalbara och säkra lösningar; modernisera sina arkitekturer; och migrera deras big data-arbetsbelastningar till AWS.
Veena Vasudevan är Senior Partner Solutions Architect och Amazon EMR-specialist på AWS med fokus på big data och analys. Hon hjälper kunder och partners att bygga mycket optimerade, skalbara och säkra lösningar; modernisera sina arkitekturer; och migrera deras big data-arbetsbelastningar till AWS.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/amazon-emr-serverless-supports-larger-worker-sizes-to-run-more-compute-and-memory-intensive-workloads/
- 1
- 10
- 100
- 11
- 2%
- 7
- 70
- 9
- 95%
- a
- Om oss
- tvärs
- Handling
- mot
- aggregation
- Alla
- allokeras
- fördelning
- tillåta
- tillåter
- amason
- Amazon EMR
- mängd
- analys
- analytics
- och
- Meddela
- var som helst
- Apache
- Apache Spark
- API: er
- Ansökan
- tillämpningar
- Tillämpa
- bifoga
- Automat
- automatiskt
- tillgänglig
- undvika
- AWS
- Bandbredd
- baserat
- därför att
- Där vi får lov att vara utan att konstant prestera,
- riktmärke
- fördelaktigt
- fördel
- Fördelarna
- BÄST
- Bättre
- Stor
- Stora data
- Blockera
- Block
- öka
- flaskhals
- SLUTRESULTAT
- cache
- Kapacitet
- Vid
- fall
- orsakas
- Förändringar
- byte
- Välja
- Stänga
- kluster
- koda
- samla
- samling
- Kolonner
- Gemensam
- vanligen
- jämfört
- komprometterande
- beräkning
- Compute
- konfiguration
- konfigurationer
- Tänk
- konsekvent
- sammanhang
- motsvarar
- Pris
- kunde
- skapa
- Skapa
- Kunder
- DAG
- datum
- datauppsättningar
- Standard
- definierade
- Examen
- demonstrera
- Detektering
- Bestämma
- Skillnaden
- olika
- diskutera
- fördelning
- inte
- inte
- ner
- chaufför
- under
- dynamisk
- varje
- möjliggör
- uppmuntra
- tillräckligt
- fel
- speciellt
- Eter (ETH)
- Även
- Varje
- exempel
- exempel
- utbyta
- Utbyten
- exciterade
- exekvera
- förväntat
- dyra
- omfattande
- faktorer
- Misslyckades
- misslyckas
- långt
- snabbare
- möjlig
- Hämtas
- få
- Fil
- Filer
- passa
- fixerad
- fokusering
- efter
- följer
- RAM
- ramar
- bedrägeri
- spårning av bedrägerier
- från
- fullständigt
- funktioner
- skaffa sig
- Hälften
- hantera
- har
- hjälpa
- hjälper
- högre
- höggradigt
- historia
- Bikupa
- Men
- html
- HTTPS
- stor
- Inverkan
- förbättra
- förbättras
- förbättring
- förbättringar
- in
- Oförmågan
- Inkomst
- Inkommande
- Öka
- ökat
- info
- informationen
- ingång
- istället
- involverade
- IT
- iterationer
- Jobb
- Lediga jobb
- delta
- Ha kvar
- Large
- större
- största
- lansera
- leda
- Leads
- lärt
- Nivå
- BEGRÄNSA
- lokal
- lokalt
- se
- du letar
- Framställning
- hantera
- maximal
- mäta
- Möt
- Minne
- Metrics
- migrera
- minuter
- Mode
- modernisera
- övervakning
- mer
- mest
- MS
- multipel
- Behöver
- behov
- nät
- Brus
- normala
- antal
- få
- erbjudanden
- erbjuda
- Erbjudanden
- ONE
- öppen källkod
- drift
- Verksamhet
- optimerad
- optimera
- beställa
- Övriga
- övergripande
- partnern
- partner
- Topp
- utföra
- prestanda
- utför
- plato
- Platon Data Intelligence
- PlatonData
- befolkning
- möjlig
- Inlägg
- potentiell
- potentiellt
- tidigare
- process
- processer
- bearbetning
- Produkt
- Produktion
- ge
- ratio
- Läsa
- rekommenderas
- register
- minska
- regioner
- frigörs
- Återstående
- avlägsen
- begärda
- Krav
- Kräver
- reserverad
- resurs
- Resurser
- översyn
- Körning
- rinnande
- Samma
- Save
- skalbar
- Skala
- skalor
- skalning
- scenario
- scenarier
- Andra
- sekunder
- §
- säkra
- senior
- Server
- Servrar
- in
- inställning
- flera
- delas
- visas
- Visar
- blanda
- signifikant
- signifikant
- liknande
- Liknande
- enda
- Storlek
- storlekar
- skev
- Small
- mindre
- So
- än så länge
- Lösningar
- några
- Utrymme
- Gnista
- specialist
- SQL
- Etapp
- stadier
- förvaring
- lagra
- strategier
- Framgångsrikt
- sådana
- plötslig
- tillräcklig
- lämplig
- Stöder
- uppstår
- apt
- bord
- Ta
- tar
- tar
- uppgift
- uppgifter
- villkor
- testa
- tester
- Smakämnen
- deras
- därför
- genomströmning
- Kasta
- tid
- gånger
- till
- verktyg
- topp
- Totalt
- spår
- Transformation
- transformationer
- SVÄNG
- typer
- typiskt
- ui
- underliggande
- utan motstycke
- Användning
- användning
- utnyttjas
- värde
- volym
- volymer
- som
- medan
- bred
- kommer
- utan
- arbetstagaren
- arbetare
- skriva
- Din
- zephyrnet