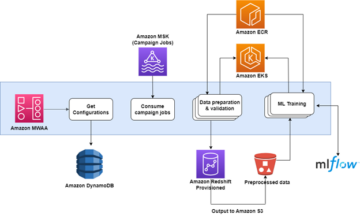
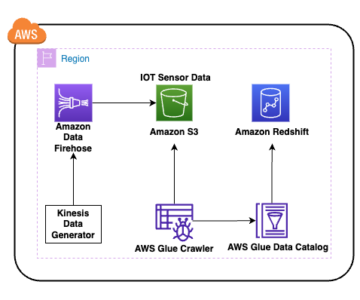
Organisationer har valt att bygga datasjöar ovanpå Amazon enkel lagringstjänst (Amazon S3) i många år. En datasjö är det populäraste valet för organisationer att lagra all organisationsdata som genererats av olika team, över affärsdomäner, från alla olika format och till och med över historien. Enligt en studie, det genomsnittliga företaget ser volymen av deras data växa i en takt som överstiger 50 % per år, vanligtvis hanterar det i genomsnitt 33 unika datakällor för analys.
Team försöker ofta replikera tusentals jobb från relationsdatabaser med samma extrahera, transformera och ladda (ETL) mönster. Det är mycket ansträngning att upprätthålla jobbtillstånden och schemalägga dessa enskilda jobb. Detta tillvägagångssätt hjälper teamen att lägga till tabeller med få ändringar och bibehåller även jobbstatusen med minimal ansträngning. Detta kan leda till en enorm förbättring av utvecklingstidslinjen och spåra jobben med lätthet.
I det här inlägget visar vi dig hur du enkelt replikerar alla dina relationsdatalager till en transaktionsdatasjö på ett automatiserat sätt med ett enda ETL-jobb med Apache Iceberg och AWS-lim.
Lösningsarkitektur
Datasjöar är vanligtvis organiserade använda separata S3-hinkar för tre lager av data: rålagret som innehåller data i sin ursprungliga form, steglagret som innehåller mellanliggande bearbetade data optimerade för konsumtion och analyslagret som innehåller aggregerade data för specifika användningsfall. I rålagret är tabeller vanligtvis organiserade utifrån deras datakällor, medan tabeller i steglagret är organiserade utifrån de affärsdomäner de tillhör.
Detta inlägg ger en AWS molnformation mall som distribuerar ett AWS Glue-jobb som läser en Amazon S3-sökväg för en datakälla för datasjöns rålager och matar in data i Apache Iceberg-tabeller på scenen lagret med AWS Glue-stöd för datasjö-ramverk. Jobbet förväntar sig att tabeller i rålagret är strukturerade på sättet AWS Database Migration Service (AWS DMS) matar in dem: schema, sedan tabell och sedan datafiler.
Denna lösning använder AWS Systems Manager Parameter Store för tabellkonfiguration. Du bör ändra denna parameter och specificera de tabeller du vill bearbeta och hur, inklusive information som primärnyckel, partitioner och den associerade affärsdomänen. Jobbet använder denna information för att automatiskt skapa en databas (om den inte redan finns) för varje affärsdomän, skapa Iceberg-tabellerna och utföra dataladdningen.
Slutligen kan vi använda Amazonas Athena för att fråga efter data i Iceberg-tabellerna.
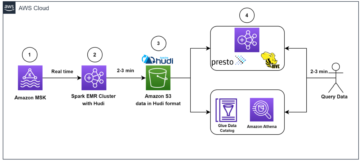
Följande diagram illustrerar denna arkitektur.

Denna implementering har följande överväganden:
- Alla tabeller från datakällan måste ha en primärnyckel för att kunna replikeras med den här lösningen. Den primära nyckeln kan vara en enstaka kolumn eller en sammansatt nyckel med mer än en kolumn.
- Om datasjön innehåller tabeller som inte behöver upserts eller inte har en primärnyckel, kan du utesluta dem från parameterkonfigurationen och implementera traditionella ETL-processer för att mata in dem i datasjön. Det ligger utanför ramen för detta inlägg.
- Om det finns ytterligare datakällor som behöver tas in kan du distribuera flera CloudFormation-stackar, en för att hantera varje datakälla.
- AWS Glue-jobbet är utformat för att bearbeta data i två faser: den initiala laddningen som körs efter att AWS DMS har slutfört den fullständiga laddningsuppgiften, och den inkrementella belastningen som körs enligt ett schema som tillämpar CDC-filer (change data capture) som fångas av AWS DMS. Inkrementell bearbetning utförs med hjälp av en AWS Lim jobb bokmärke.
Det finns nio steg för att slutföra denna handledning:
- Konfigurera en källändpunkt för AWS DMS.
- Distribuera lösningen med AWS CloudFormation.
- Granska AWS DMS-replikeringsuppgiften.
- Lägg eventuellt till behörigheter för kryptering och dekryptering eller AWS Lake Formation.
- Granska tabellkonfigurationen i Parameter Store.
- Utför inledande dataladdning.
- Utför inkrementell dataladdning.
- Övervaka bordsintag.
- Schemalägg inkrementell batchdataladdning.
Förutsättningar
Innan du börjar med den här handledningen bör du redan vara bekant med Iceberg. Om du inte är det kan du komma igång genom att replikera en enda tabell genom att följa instruktionerna i Implementera en CDC-baserad UPSERT i en datasjö med hjälp av Apache Iceberg och AWS Glue. Ställ dessutom in följande:
Ställ in en källslutpunkt för AWS DMS
Innan vi skapar vår AWS DMS-uppgift måste vi ställa in en källslutpunkt för att ansluta till källdatabasen:
- På AWS DMS-konsolen väljer du endpoints i navigeringsfönstret.
- Välja Skapa slutpunkt.
- Om din databas körs på Amazon RDS, välj Välj RDS DB-instans, välj sedan instansen från listan. Annars väljer du källmotorn och tillhandahåller anslutningsinformationen antingen genom AWS Secrets Manager eller manuellt.
- För Slutpunktsidentifierare, ange ett namn för slutpunkten; till exempel source-postgresql.
- Välja Skapa slutpunkt.
Distribuera lösningen med AWS CloudFormation
Skapa en CloudFormation-stack med den medföljande mallen. Slutför följande steg:
- Välja Starta Stack:

- Välja Nästa.
- Ange ett stacknamn, t.ex
transactionaldl-postgresql. - Ange de nödvändiga parametrarna:
- DMSS3EndpointIAMRoleARN – IAM-rollen ARN för AWS DMS att skriva data till Amazon S3.
- ReplicationInstanceArn – AWS DMS-replikeringsinstansen ARN.
- S3BucketStage – Namnet på den befintliga hinken som används för datasjöns scenlager.
- S3BucketLim – Namnet på den befintliga S3-hinken för lagring av AWS Glue-skript.
- S3BucketRaw – Namnet på den befintliga hinken som används för datasjöns råa lager.
- SourceEndpointArn – AWS DMS-ändpunkten ARN som du skapade tidigare.
- KÄLLNAMN – Den godtyckliga identifieraren för datakällan som ska replikeras (t.ex.
postgres). Detta används för att definiera S3-vägen för datasjön (rålager) där data kommer att lagras.
- Ändra inte följande parametrar:
- SourceS3BucketBlog – Hinknamnet där det medföljande AWS Glue-skriptet lagras.
- SourceS3BucketPrefix – Buckets prefixnamn där det medföljande AWS Glue-skriptet lagras.
- Välja Nästa dubbelt.
- Välja Jag erkänner att AWS CloudFormation kan skapa IAM-resurser med anpassade namn.
- Välja Skapa stack.
Efter cirka 5 minuter distribueras CloudFormation-stacken.
Granska AWS DMS-replikeringsuppgiften
AWS CloudFormation-distributionen skapade en AWS DMS-målslutpunkt åt dig. På grund av två specifika slutpunktsinställningar kommer data att tas in när vi behöver dem på Amazon S3.
- På AWS DMS-konsolen väljer du endpoints i navigeringsfönstret.
- Sök efter och välj den slutpunkt som börjar med
dmsIcebergs3endpoint. - Granska slutpunktsinställningarna:
DataFormatanges somparquet.TimestampColumnNamekommer att lägga till kolumnenlast_update_timemed datumet för skapandet av posterna på Amazon S3.

Implementeringen skapar också en AWS DMS-replikeringsuppgift som börjar med dmsicebergtask.
- Välja Replikeringsuppgifter i navigeringsfönstret och sök efter uppgiften.
Du kommer att se att Uppgiftstyp är markerad som Full belastning, pågående replikering. AWS DMS kommer att utföra en initial full laddning av befintliga data och sedan skapa inkrementella filer med ändringar utförda i källdatabasen.
På Kartläggningsregler fliken finns det två typer av regler:
- En urvalsregel med namnet på källschemat och tabeller som kommer att tas in från källdatabasen. Som standard använder den exempeldatabasen som anges i förutsättningarna,
dms_sample, och alla tabeller med sökordet %. - Två transformationsregler som inkluderar i målfilerna på Amazon S3 schemanamnet och tabellnamnet som kolumner. Detta används av vårt AWS Glue-jobb för att veta vilka tabeller filerna i datasjön motsvarar.
För att lära dig mer om hur du anpassar detta för dina egna datakällor, se Urvalsregler och åtgärder.

Låt oss ändra några konfigurationer för att avsluta vår uppgiftsförberedelse.
- På Handlingar meny, välj Ändra.
- I Uppgiftsinställningar avsnitt, under Stoppa uppgiften efter full laddningväljer Stoppa efter att ha tillämpat cachade ändringar.
På så sätt kan vi styra den initiala laddningen och den inkrementella filgenereringen som två olika steg. Vi använder denna tvåstegsmetod för att köra AWS Glue-jobbet en gång per steg.
- Enligt Uppgiftsloggarväljer Aktivera CloudWatch-loggar.
- Välja Save.
- Vänta cirka 1 minut tills databasmigreringsuppgiftens status visas som Klar.
Lägg till behörigheter för kryptering och dekryptering eller Lake Formation
Alternativt kan du lägga till behörigheter för kryptering och dekryptering eller Lake Formation.
Lägg till kryptering och dekrypteringsbehörigheter
Om dina S3-hinkar som används för rå- och steglagren är krypterade med AWS nyckelhanteringstjänst (AWS KMS) kundhanterade nycklar måste du lägga till behörigheter för att tillåta AWS Glue-jobbet att komma åt data:
Lägg till Lake Formation-behörigheter
Om du hanterar behörigheter med Lake Formation måste du tillåta ditt AWS Glue-jobb att skapa din domäns databaser och tabeller genom IAM-rollen GlueJobRole.
- Bevilja behörighet att skapa databaser (för instruktioner, se Skapa en databas).
- Ge SUPER-behörigheter till
defaultdatabas. - Ge dataplatsbehörigheter.
- Om du skapar databaser manuellt, ge alla databaser behörighet att skapa tabeller. Hänvisa till Bevilja tabellbehörigheter med hjälp av Lake Formation-konsolen och den namngivna resursmetoden or Bevilja Data Catalog-behörigheter med LF-TBAC-metoden enligt ditt användningsfall.
När du har slutfört det senare steget med att utföra den första dataladdningen, se till att även lägga till behörigheter för konsumenter att fråga efter tabellerna. Jobbrollen kommer att bli ägare till alla skapade tabeller, och datasjöadministratören kan sedan utföra anslag till ytterligare användare.
Granska tabellkonfigurationen i Parameter Store
AWS Glue-jobbet som utför datainmatningen i Iceberg-tabeller använder tabellspecifikationen som tillhandahålls i Parameter Store. Utför följande steg för att granska parameterlagret som konfigurerades automatiskt åt dig. Om det behövs, modifiera efter dina egna behov.
- På Parameter Store-konsolen väljer du Mina parametrar i navigeringsfönstret.
CloudFormation-stacken skapade två parametrar:
iceberg-configför jobbkonfigurationericeberg-tablesför tabellkonfiguration
- Välj parametern isbergsbord.
JSON-strukturen innehåller information som AWS Glue använder för att läsa data och skriva Iceberg-tabellerna på måldomänen:
- Ett objekt per bord – Namnet på objektet skapas med hjälp av schemanamnet, en punkt och tabellnamnet; till exempel,
schema.table. - primärnyckel – Detta bör anges för varje källtabell. Du kan tillhandahålla en enskild kolumn eller en kommaseparerad lista med kolumner (utan mellanslag).
- partitionCols – Detta partitionerar valfritt kolumner för måltabeller. Om du inte vill skapa partitionerade tabeller, ange en tom sträng. Ange annars en enstaka kolumn eller en kommaseparerad lista över kolumner som ska användas (utan mellanslag).
- Om du vill använda din egen datakälla, använd följande JSON-kod och ersätt texten i CAPS från den medföljande mallen. Om du använder den medföljande exempeldatakällan, behåll standardinställningarna:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Välja Spara ändringar.
Utför inledande dataladdning
Nu när den erforderliga konfigurationen är klar, matar vi in den första datan. Det här steget innehåller tre delar: inmatning av data från källrelationsdatabasen till datasjöns råa lager, skapande av Iceberg-tabellerna på datasjöns scenlager och verifiering av resultat med Athena.
Mata in data i det råa lagret av datasjön
För att få in data från den relationella datakällan (PostgreSQL om du använder provet som tillhandahålls) till vår transaktionsdatasjö med Iceberg, slutför du följande steg:
- På AWS DMS-konsolen väljer du Databasmigreringsuppgifter i navigeringsfönstret.
- Välj replikeringsuppgiften du skapade och på Handlingar meny, välj Starta om/återuppta.
- Vänta cirka 5 minuter tills replikeringsuppgiften är klar. Du kan övervaka tabellerna som intas på Statistik fliken för replikeringsuppgiften.

Efter några minuter avslutas uppgiften med meddelandet Full laddning klar.
- På Amazon S3-konsolen väljer du den hink du definierade som rålagret.
Under S3-prefixet som definieras på AWS DMS (till exempel, postgres), bör du se en hierarki av mappar med följande struktur:
- Schema
- Tabellnamn
LOAD00000001.parquetLOAD0000000N.parquet
- Tabellnamn

Om din S3-hink är tom, se över Felsökning av migreringsuppgifter i AWS Database Migration Service innan du kör AWS-limjobbet.
Skapa och mata in data i Iceberg-tabeller
Innan vi kör jobbet, låt oss navigera i skriptet för AWS Glue-jobbet som tillhandahålls som en del av CloudFormation-stacken för att förstå dess beteende.
- Välj på AWS Glue Studio-konsolen Lediga jobb i navigeringsfönstret.
- Sök efter jobbet som börjar med
IcebergJob-och ett suffix av ditt CloudFormation-stacknamn (till exempel,IcebergJob-transactionaldl-postgresql). - Välj jobbet.

Jobbskriptet får den konfiguration det behöver från Parameter Store. Funktionen getConfigFromSSM() returnerar jobbrelaterade konfigurationer som käll- och målsegment varifrån data behöver läsas och skrivas. Variabeln ssmparam_table_values innehålla tabellrelaterad information som datadomän, tabellnamn, partitionskolumner och primärnyckel för de tabeller som måste matas in. Se följande Python-kod:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']Skriptet använder ett godtyckligt katalognamn för Iceberg som definieras som my_catalog. Detta är implementerat på AWS Glue Data Catalog med hjälp av Spark-konfigurationer, så en SQL-operation som pekar på my_catalog kommer att tillämpas på Data Catalog. Se följande kod:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
Skriptet itererar över tabellerna som definieras i Parameter Store och utför logiken för att upptäcka om tabellen existerar och om inkommande data är en initial laddning eller en upsert:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')Smakämnen initialLoadRecordsSparkSQL() funktionen laddar inledande data när ingen operationskolumn finns i S3-filerna. AWS DMS lägger endast till denna kolumn till Parquet-datafiler som produceras av den kontinuerliga replikeringen (CDC). Dataladdningen utförs med kommandot INSERT INTO med SparkSQL. Se följande kod:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Nu kör vi AWS Glue-jobbet för att mata in den första datan i Iceberg-tabellerna. CloudFormation-stacken lägger till --datalake-formats parameter, lägga till de nödvändiga Iceberg-biblioteken till jobbet.
- Välja Kör jobb.
- Välja Job Runs för att övervaka status. Vänta tills statusen är Körningen lyckades.
Verifiera den laddade datan
För att bekräfta att jobbet bearbetade data som förväntat, utför följande steg:
- Välj på Athena-konsolen Query Editor i navigeringsfönstret.
- Verifiera
AwsDataCatalogväljs som datakälla. - Enligt Databas, välj den datadomän som du vill utforska, baserat på den konfiguration du definierade i parameterlagret. Om du använder den medföljande exempeldatabasen, använd
sports.
Enligt Tabeller och vyer, kan vi se listan över tabeller som skapades av AWS Glue-jobbet.
- Välj alternativmenyn (tre punkter) bredvid det första tabellnamnet och välj sedan Förhandsgranska data.
Du kan se data laddade i Iceberg-tabeller. 
Utför inkrementell dataladdning
Nu börjar vi fånga ändringar från vår relationsdatabas och tillämpa dem på transaktionsdatasjön. Detta steg är också uppdelat i tre delar: fånga ändringarna, tillämpa dem på Iceberg-tabellerna och verifiera resultaten.
Fånga ändringar från relationsdatabasen
På grund av den konfiguration vi angav, stoppades replikeringsuppgiften efter att ha kört hela laddningsfasen. Nu startar vi om uppgiften för att lägga till inkrementella filer med ändringar i det råa lagret av datasjön.
- På AWS DMS-konsolen väljer du uppgiften vi skapade och körde tidigare.
- På Handlingar meny, välj CV.
- Välja Starta uppgiften för att börja fånga ändringar.
- För att utlösa skapande av nya filer på datasjön, utför infogning, uppdatering eller borttagning av tabellerna i din källdatabas med ditt föredragna databasadministrationsverktyg. Om du använder den medföljande exempeldatabasen kan du köra följande SQL-kommandon:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- På sidan AWS DMS uppgiftsinformation väljer du Tabellstatistik fliken för att se ändringarna som registrerats.

- Öppna det råa lagret av datasjön för att hitta en ny fil som innehåller de inkrementella ändringarna i varje tabells prefix, till exempel under
sporting_eventprefix.
Rekordet med ändringar för sporting_event tabellen ser ut som följande skärmdump.

Lägg märke till Op kolumn i början identifierad med en uppdatering (U). Det andra datum-/tidsvärdet är också kontrollkolumnen som lagts till av AWS DMS med den tidpunkt då ändringen registrerades.

Tillämpa ändringar på Iceberg-borden med AWS Glue
Nu kör vi AWS Glue-jobbet igen, och det kommer automatiskt att bearbeta endast de nya inkrementella filerna eftersom jobbbokmärket är aktiverat. Låt oss se över hur det fungerar.
Smakämnen dedupCDCRecords() funktionen utför deduplicering av data eftersom flera ändringar av ett enda post-ID kan fångas in i samma datafil på Amazon S3. Deduplicering utförs baserat på last_update_time kolumn tillagd av AWS DMS som anger tidsstämpeln för när ändringen registrerades. Se följande Python-kod:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFPå rad 99, upsertRecordsSparkSQL() funktionen utför upsert på ett liknande sätt som den initiala laddningen, men den här gången med ett SQL MERGE-kommando.
Granska de tillämpade ändringarna
Öppna Athena-konsolen och kör en fråga som väljer de ändrade posterna i källdatabasen. Om du använder den medföljande exempeldatabasen, använd en av följande SQL-frågor:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Övervaka bordsintag
AWS Glue-jobbskriptet är enkelt kodat Python undantagshantering för att fånga fel under bearbetning av en specifik tabell. Jobbbokmärket sparas efter att varje tabell har slutförts framgångsrikt, för att undvika omarbetning av tabeller om jobbkörningen görs om för tabellerna med fel.
Smakämnen AWS-kommandoradsgränssnitt (AWS CLI) ger en get-job-bookmark kommando för AWS Glue som ger insikt i statusen för bokmärket för varje bearbetad tabell.
- På AWS Glue Studio-konsolen väljer du ETL-jobbet.
- Välj Job Runs fliken och kopiera jobbkörnings-ID.
- Kör följande kommando på en terminal som är autentiserad för AWS CLI, ersätt
<GLUE_JOB_RUN_ID>på rad 1 med värdet du kopierade. Om din CloudFormation-stack inte är namngiventransactionaldl-postgresql, ange namnet på ditt jobb på rad 2 i skriptet:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunI den här lösningen, när en tabellbearbetning orsakar ett undantag, kommer AWS Glue-jobbet inte att misslyckas enligt denna logik. Istället kommer tabellen att läggas till i en array som skrivs ut efter att jobbet är klart. I ett sådant scenario kommer jobbet att markeras som misslyckat efter att det försöker bearbeta resten av tabellerna som upptäckts i rådatakällan. På så sätt behöver tabeller utan fel inte vänta tills användaren identifierar och löser problemet på de motstridiga tabellerna. Användaren kan snabbt upptäcka jobbkörningar som hade problem med AWS Glue-jobbkörningsstatus och identifiera vilka specifika tabeller som orsakar problemet med hjälp av CloudWatch-loggarna för jobbkörningen.
- Jobbskriptet implementerar den här funktionen med följande Python-kod:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')Följande skärmdump visar hur CloudWatch-loggarna ser ut efter tabeller som orsakar fel vid bearbetning.

I linje med AWS välarkiterade ramdataanalysobjektiv praxis kan du anpassa mer sofistikerade kontrollmekanismer för att identifiera och meddela intressenter när fel uppstår på datapipelines. Du kan till exempel använda en Amazon DynamoDB kontrolltabell för att lagra alla tabeller och jobbkörningar med fel, eller använda Amazon enkel meddelandetjänst (Amazon SNS) till skicka varningar till operatörer när vissa kriterier är uppfyllda.
Schemalägg inkrementell batchdataladdning
CloudFormation-stacken distribuerar en Amazon EventBridge regel (inaktiverad som standard) som kan utlösa AWS Glue-jobbet att köras enligt ett schema. För att tillhandahålla ditt eget schema och aktivera regeln, utför följande steg:
- Välj på EventBridge-konsolen regler i navigeringsfönstret.
- Sök efter regeln med prefixet namnet på din CloudFormation-stack följt av
JobTrigger(till exempel,transactionaldl-postgresql-JobTrigger-randomvalue). - Välj regeln.
- Enligt Händelseplanväljer Redigera.
Standardschemat är konfigurerat att utlösas varje timme.
- Ange det schema du vill köra jobbet.
- Dessutom kan du använda en EventBridge cron uttryck genom att välja Ett fint schema.

- När du är klar med att ställa in cron-uttrycket, välj Nästa tre gånger, och slutligen välja Uppdatera regel för att spara ändringar.
Regeln skapas inaktiverad som standard så att du kan köra den initiala dataladdningen först.
- Aktivera regeln genom att välja aktivera.
Du kan använda Övervakning fliken för att se regelanrop, eller direkt på AWS-limmet Job Run detaljer.
Slutsats
Efter att ha implementerat den här lösningen har du automatiserat inmatningen av dina tabeller på en enda relationsdatakälla. Organisationer som använder en datasjö som sin centrala dataplattform behöver vanligtvis hantera flera, ibland till och med tiotals datakällor. Fler och fler användningsfall kräver också att organisationer implementerar transaktionsmöjligheter till datasjön. Du kan använda den här lösningen för att påskynda införandet av sådana funktioner i alla dina relationsdatakällor för att möjliggöra nya affärsanvändningsfall, automatisera implementeringsprocessen för att få mer värde från din data.
Om författarna
 Luis Gerardo Baeza är en Big Data Architect i Amazon Web Services (AWS) Data Lab. Han har 12 års erfarenhet av att hjälpa organisationer inom hälso- och sjukvården, finanssektorerna och utbildningssektorerna att anta program för företagsarkitektur, molnberäkning och dataanalysfunktioner. Luis hjälper för närvarande organisationer över hela Latinamerika att påskynda strategiska datainitiativ.
Luis Gerardo Baeza är en Big Data Architect i Amazon Web Services (AWS) Data Lab. Han har 12 års erfarenhet av att hjälpa organisationer inom hälso- och sjukvården, finanssektorerna och utbildningssektorerna att anta program för företagsarkitektur, molnberäkning och dataanalysfunktioner. Luis hjälper för närvarande organisationer över hela Latinamerika att påskynda strategiska datainitiativ.
 SaiKiran Reddy Aenugu är en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 10 års erfarenhet av att implementera dataladdnings-, transformations- och visualiseringsprocesser. SaiKiran hjälper för närvarande organisationer i Nordamerika att anta moderna dataarkitekturer som datasjöar och datanät. Han har erfarenhet från detaljhandeln, flygbolagen och finanssektorerna.
SaiKiran Reddy Aenugu är en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 10 års erfarenhet av att implementera dataladdnings-, transformations- och visualiseringsprocesser. SaiKiran hjälper för närvarande organisationer i Nordamerika att anta moderna dataarkitekturer som datasjöar och datanät. Han har erfarenhet från detaljhandeln, flygbolagen och finanssektorerna.
 Narendra Merla är en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 12 års erfarenhet av att designa och produktionsalisera både realtids- och batchorienterade datapipelines och bygga datasjöar i både moln- och lokalmiljöer. Narendra hjälper för närvarande organisationer i Nordamerika att bygga och designa robusta dataarkitekturer och har erfarenhet inom telekom- och finanssektorerna.
Narendra Merla är en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 12 års erfarenhet av att designa och produktionsalisera både realtids- och batchorienterade datapipelines och bygga datasjöar i både moln- och lokalmiljöer. Narendra hjälper för närvarande organisationer i Nordamerika att bygga och designa robusta dataarkitekturer och har erfarenhet inom telekom- och finanssektorerna.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Om oss
- accelerera
- tillgång
- Enligt
- bekräfta
- tvärs
- anpassa
- lagt till
- Annat
- Dessutom
- Lägger
- administration
- administrering
- anta
- Antagande
- Efter
- flygbolaget
- Alla
- redan
- amason
- Amazonas Athena
- Amazon RDS
- Amazon Web Services
- Amazon Web Services (AWS)
- amerika
- analys
- analytics
- och
- Angeles
- Apache
- visas
- Ansökan
- tillämpas
- Tillämpa
- tillvägagångssätt
- cirka
- arkitektur
- array
- associerad
- authenticated
- automatisera
- Automatiserad
- automatiskt
- automatisera
- genomsnitt
- undvika
- AWS
- AWS molnformation
- AWS-lim
- baserat
- fladdermöss
- därför att
- blir
- innan
- Börjar
- Stor
- Stora data
- SLUTRESULTAT
- byggare
- Byggnad
- företag
- Kan få
- kapacitet
- lock
- fånga
- Fångande
- Vid
- fall
- katalog
- brottning
- Orsak
- Orsakerna
- orsakar
- CDC
- centrala
- vissa
- byta
- Förändringar
- val
- Välja
- välja
- valda
- cloud
- cloud computing
- koda
- Kolumn
- Kolonner
- företag
- fullborda
- databehandling
- konfiguration
- konfigurationer
- Bekräfta
- Motstridig
- Kontakta
- anslutning
- överväganden
- Konsol
- konsumenter
- konsumtion
- innehåller
- fortsätta
- kontinuerlig
- kontroll
- kunde
- skapa
- skapas
- skapar
- Skapa
- skapande
- kriterier
- För närvarande
- beställnings
- kund
- skräddarsy
- datum
- Data Analytics
- datasjö
- Dataplattform
- Databas
- databaser
- Datum
- Standard
- definierade
- distribuera
- utplacerade
- utplacera
- utplacering
- vecklas ut
- Designa
- utformade
- design
- detaljer
- detekterad
- Utveckling
- olika
- direkt
- inaktiverad
- dividerat
- inte
- domän
- domäner
- inte
- under
- varje
- Tidigare
- lätt
- Utbildning
- ansträngning
- antingen
- möjliggöra
- aktiverad
- krypterad
- kryptering
- Slutpunkt
- Motor
- ange
- Företag
- miljöer
- fel
- Eter (ETH)
- Även
- Varje
- exempel
- överstiger
- Utom
- undantag
- befintliga
- finns
- förväntat
- förväntar
- erfarenhet
- utforska
- förlängningar
- extrahera
- Misslyckades
- bekant
- Mode
- Leverans
- få
- Fil
- Filer
- Slutligen
- finansiering
- finansiella
- hitta
- slut
- Förnamn
- följt
- efter
- För konsumenterna
- formen
- bildning
- Ramverk
- från
- full
- fungera
- genereras
- generering
- skaffa sig
- bevilja
- bidrag
- Odling
- hantera
- hälso-och sjukvård
- hjälpa
- hjälper
- hierarkin
- historia
- innehav
- Hur ser din drömresa ut
- How To
- html
- HTTPS
- stor
- IAM
- identifierade
- identifierare
- identifierar
- identifiera
- genomföra
- genomförande
- genomföras
- genomföra
- redskap
- förbättring
- in
- innefattar
- innefattar
- Inklusive
- Inkommande
- pekar på
- individuellt
- informationen
- inledande
- initiativ
- Insert
- insikt
- exempel
- istället
- instruktioner
- Mellanliggande
- fråga
- problem
- IT
- iteration
- Jobb
- Lediga jobb
- json
- Ha kvar
- Nyckel
- nycklar
- Vet
- lab
- sjö
- latin
- latinamerika
- lager
- skikt
- leda
- LÄRA SIG
- bibliotek
- BEGRÄNSA
- linje
- Lista
- läsa in
- läser in
- laster
- läge
- se
- UTSEENDE
- den
- Los Angeles
- Lot
- Huvudsida
- upprätthåller
- göra
- förvaltade
- ledning
- chef
- hantera
- manuellt
- många
- kartläggning
- markant
- Meny
- Sammanfoga
- meddelande
- kanske
- migration
- minsta
- minut
- minuter
- Modern Konst
- modifiera
- Övervaka
- övervakning
- mer
- mest
- Mest populär
- multipel
- namn
- Som heter
- namn
- Navigera
- Navigering
- Behöver
- behövs
- behov
- Nya
- Nästa
- Nord
- nordamerika
- anmälan
- antal
- objektet
- objekt
- ONE
- pågående
- OP
- drift
- optimerad
- Tillbehör
- organisatoriska
- organisationer
- Organiserad
- ursprungliga
- annat
- utanför
- egen
- ägaren
- panelen
- parameter
- parametrar
- del
- reservdelar till din klassiker
- bana
- Mönster
- utföra
- utför
- utför
- perioden
- behörigheter
- fas
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Populära
- Inlägg
- PostgreSQL
- praxis
- föredragen
- förutsättningar
- presentera
- primär
- Problem
- process
- processer
- bearbetning
- producerad
- Program
- ge
- förutsatt
- ger
- Python
- snabbt
- höja
- Betygsätta
- Raw
- rådata
- Läsa
- realtid
- post
- register
- ersätta
- replikeras
- replikation
- kräver
- Obligatorisk
- resurs
- Resurser
- REST
- Resultat
- detaljhandeln
- avkastning
- återgår
- översyn
- robusta
- Roll
- Regel
- regler
- Körning
- rinnande
- Samma
- Save
- scenario
- tidtabellen
- omfattning
- skript
- Sök
- Andra
- Sektorer
- se
- vald
- väljer
- Val
- separat
- Tjänster
- in
- inställning
- inställningar
- skall
- show
- Visar
- liknande
- Enkelt
- eftersom
- enda
- So
- lösning
- Löser
- några
- sofistikerade
- Källa
- Källor
- utrymmen
- Gnista
- specifik
- specifikation
- specificerade
- Sporter
- SQL
- stapel
- Stacks
- Etapp
- intressenter
- starta
- igång
- Starta
- startar
- Stater
- statistik
- status
- Steg
- Steg
- slutade
- förvaring
- lagra
- lagras
- lagrar
- Strategisk
- struktur
- strukturerade
- studio
- Framgångsrikt
- sådana
- super
- stödja
- System
- bord
- Målet
- uppgift
- uppgifter
- grupp
- lag
- telecom
- mall
- terminal
- Smakämnen
- källan
- deras
- tusentals
- tre
- Genom
- tid
- tidslinje
- gånger
- tidsstämpel
- till
- verktyg
- topp
- Totalt
- Spårning
- traditionell
- transaktion
- Förvandla
- Transformation
- utlösa
- handledning
- typer
- under
- förstå
- unika
- Uppdatering
- Uppdateringar
- användning
- användningsfall
- Användare
- användare
- vanligen
- värde
- verifiera
- utsikt
- visualisering
- volym
- vänta
- Warehouse
- webb
- webbservice
- som
- kommer
- inom
- utan
- fungerar
- skriva
- skriven
- jaml
- år
- år
- Din
- zephyrnet