Under de senaste åren har företag samlat på sig enorma mängder data. Datavolymerna har ökat i en aldrig tidigare skådad hastighet, och exploderat från terabyte till petabyte och ibland exabyte data. I allt högre grad bygger många företag mycket skalbara, tillgängliga, säkra och flexibla datasjöar på AWS som kan hantera extremt stora datamängder. Efter att datasjöar har producerats, för att mäta datasjöns effektivitet och kommunicera luckorna eller prestationerna till affärsgrupperna, behöver företagsdatateam verktyg för att extrahera operativa insikter från datasjön. Dessa insikter hjälper till att svara på nyckelfrågor som:
- Senast en tabell uppdaterades
- Det totala antalet tabeller i varje databas
- Den förväntade tillväxten för en given tabell
- Den vanligast efterfrågade tabellen kontra de minst efterfrågade tabellerna
I det här inlägget går jag igenom en lösning för att bygga en instrumentpanel för operationsmått (som följande skärmdump) för ditt företag AWS-lim Datakatalog på AWS.

Lösningsöversikt
Det här inlägget visar dig hur du samlar in metadatainformation från din datasjös AWS Glue Data Catalog-resurser (databaser och tabeller) och bygger en operativ instrumentpanel på denna data.
Följande diagram illustrerar den övergripande lösningsarkitekturen och stegen.

Stegen är som följer:
- Ett Python-program för datainsamlare körs enligt ett schema och samlar in metadatadetaljer om databaser och tabeller från företagsdatakatalogen.
- Följande nyckeldataattribut samlas in för varje tabell och databas i din AWS Glue Data Catalog.
| Tabelldata | Databasdata |
| Tabellnamn | Databas namn |
| Databas namn | Skapa tid |
| Ägare | SharedResource |
| Skapa tid | SharedResourceOwner |
| Uppdaterings tid | SharedResourceDatabaseName |
| Last AccessTime | Plats |
| Tabelltyp | Beskrivning |
| Retentionstid | |
| Skapad av | |
| Är Registrerad MedLakeFormation | |
| Plats | |
| SizeInMBOnS3 | |
| TotalFilesonS3 |
- Programmet läser varje tabells filplats och beräknar antalet filer på Amazon enkel lagringstjänst (Amazon S3) och storleken i MB.
- All data för tabellerna och databaserna lagras i en S3-hink för nedströmsanalys. Programmet körs varje dag och skapar nya filer uppdelade efter år, månad och dag på Amazon S3.
- Vi genomsöker data som skapades i steg 4 med en AWS Glue-crawler.
- Sökroboten skapar en extern databas och tabeller för vår genererade datauppsättning för nedströmsanalys.
- Vi kan fråga de extraherade uppgifterna med Amazonas Athena.
- Vi använder Amazon QuickSight att bygga vår instrumentpanel för operativa mätvärden och få insikter i vårt datasjöinnehåll och vår användning.
För enkelhetens skull genomsöker och samlar detta program in data från datakatalogen endast för us-east-1-regionen.
Walkthrough-översikt
Genomgång innehåller följande steg:
- Konfigurera din datauppsättning.
- Distribuera kärnlösningens resurser med en AWS molnformation mall och konfigurera och utlösa AWS-limjobbet.
- Genomsök metadatauppsättningen och skapa externa tabeller i datakatalogen.
- Bygg en vy och fråga efter data genom Athena.
- Ställ in och importera data till QuickSight för att skapa en instrumentpanel för operationsmått för datakatalogen.
Konfigurera din datauppsättning
Vi använder AWS COVID-19-datasjön för analys. Denna datasjö består av data i en offentligt läsbar S3-skopa.
För att göra data från AWS COVID-19-datasjön tillgänglig i ditt AWS-konto, skapa en CloudFormation-stack med följande mall. Om du är inloggad på ditt AWS-konto, följande länk fyller i det mesta av formuläret för att skapa stacken åt dig. Se till att ändra region till us-east-1. För instruktioner om hur du skapar en CloudFormation-stack, se KOM IGÅNG.
Den här mallen skapar en COVID-19-databas i din datakatalog och tabeller som pekar på den offentliga AWS COVID-19-datasjön. Du behöver inte vara värd för data på ditt konto, och du kan lita på att AWS uppdaterar data när datauppsättningar uppdateras via AWS datautbyte.
För mer information om datauppsättningen COVID-19, se En offentlig datasjö för analys av covid-19-data.
Din miljö kanske redan har befintliga datauppsättningar i datakatalogen. Programmet samlar också in de ovannämnda attributen för dessa datauppsättningar, som kan användas för analys.
Distribuera dina resurser
För att göra det enklare att komma igång skapade vi en CloudFormation-mall som automatiskt ställer in några nyckelkomponenter i lösningen:
- Ett AWS Glue-jobb (Python-program) som utlöses baserat på ett schema
- Smakämnen AWS identitets- och åtkomsthantering (IAM) roll som krävs av AWS Glue-jobbet så att jobbet kan samla in och lagra detaljer om databaser och tabeller i datakatalogen
- En ny S3-hink för AWS Glue-jobbet för att lagra datafilerna
- En ny databas i datakatalogen för lagring av våra mätdatatabeller
Källkoden för AWS Glue-jobbet och CloudFormation-mallen är tillgängliga i GitHub repo.
Du måste först ladda ner AWS Glue Python-koden från GitHub och ladda upp den till en befintlig S3-hink. Sökvägen till denna fil måste anges när CloudFormation-stacken körs.
- Starta stacken:

- Ange värden för dina parametrar som visas i följande skärmdump.

Efter att stacken har distribuerats framgångsrikt kan du kontrollera resurserna som skapats på stacken Resurser fliken.

Du kan verifiera och kontrollera AWS Glue-jobbinställningen och triggern, som är schemalagd enligt din angivna tid.
Nu när vi har verifierat att stacken har konfigurerats framgångsrikt kan vi köra vårt AWS Glue-jobb manuellt och samla in nyckelattribut för vår analys.
- På AWS Glue-konsolen väljer du AWS Glue Studio i navigeringsfönstret.

- I AWS Glue Studio Console klickar du på Jobs och väljer
DataCollectorjobb och kör jobbet.
AWS Glue-jobbet samlar in data och lagrar det i S3-hinken som skapats för oss genom AWS CloudFormation. Jobbet skapar separata mappar för databas- och tabelldata, som visas i följande skärmdump.

Genomsök och ställ in externa tabeller för mätdata
Följ dessa steg för att skapa tabeller i databasen med AWS Glue Crawlers på data som lagras på Amazon S3. Observera att databasen har skapats åt oss med hjälp av CloudFormation-stacken.
- På AWS Lim-konsolen, under Databaser välj i navigeringsfönstret Bord.
- Välja Lägg till tabeller.
- Välja Lägg till tabeller med en sökrobot.
- Ange ett namn för sökroboten och välj Nästa.
- För Lägg till sökrobotväljer Skapa källtyp.
- Ange sökrobotens källtyp genom att välja Datalager Och välj Nästa.
- I Lägg till ett datalager avsnitt, för Välj ett datalagerväljer S3.
- För Genomsök data i, Välj Angiven sökväg.
- För Inkludera sökväg, ange sökvägen till
tablesmapp genererad av AWS Glue-jobbet:s3://<data bucket created using CFN>/datalake/tables/.
- När du tillfrågas om du vill skapa ett annat datalager väljer du Nej och välj sedan Nästa.
- På Välj en IAM-roll sida, välj Välj en befintlig IAM-roll.
- För IAM-roll, välj IAM-rollen som skapats genom CloudFormation-stacken.
- Välja Nästa.
- På Produktion sida, för Databas, välj AWS Glue-databasen som du skapade tidigare.
- Välja Nästa.
- Granska dina val och välj Finish.
- Välj sökroboten du just skapade och välj Kör sökrobot.
Sökroboten bör bara ta några minuter att slutföra. Medan den körs kan statusmeddelanden visas som informerar dig om att systemet försöker köra sökroboten och sedan faktiskt kör sökroboten. Du kan välja uppdateringsikonen för att kontrollera sökrobotens aktuella status.
- Välj i navigeringsfönstret Bord.
Bordet ringde tables, som skapades av sökroboten, bör listas.

Fråga data med Athena
Det här avsnittet visar hur man frågar dessa tabeller med Athena. Athena är en serverlös, interaktiv frågetjänst som gör det enkelt att analysera data i AWS COVID-19-datasjön. Athena stöder SQL, ett vanligt språk som dataanalytiker använder för att analysera strukturerad data. Utför följande steg för att fråga efter data:
- Logga in på Athena-konsolen.
- Om det här är första gången du använder Athena måste du ange en sökresultatplats på Amazon S3.
- På rullgardinsmenyn väljer du
datalake360dbdatabas. - Ange dina frågor och utforska datamängderna.
Konfigurera och importera data till QuickSight och skapa en instrumentpanel för operationella mätvärden
Ställ in QuickSight innan du importerar datamängden och se till att du har minst 512 MB SPICE-kapacitet. För mer information, se Hantera SPICE-kapacitet.
Innan du fortsätter, se till att ditt QuickSight-konto har IAM-behörighet för åtkomst till Athena (se Auktorisera anslutningar till Amazon Athena) och Amazon S3.
Låt oss först skapa våra datauppsättningar.
- Välj på QuickSight-konsolen dataset i navigeringsfönstret.
- Välja Nytt datasätt.
- Välj Athena från listan över datakällor.
- För Datakällans namn, ange ett namn.

- För Databas, välj den databas som du konfigurerade i föregående steg (
datalake360db). - För Bord, Välj databaser.

- Slutför skapa din datauppsättning..
- Upprepa samma steg för att skapa en
tablesdatasätt.
Nu redigerar du databasens dataset.
- Från datauppsättningslistan väljer du
databasesdatasätt. - Välja Redigera dataset.

- Ändra
createtimefälttyp från sträng till datum.
- Ange datumformat som
yy/MM/dd HH:mm:ss. - Välja Uppdatering.

- Ändra tabelldatafälten på samma sätt
createtime,updatetimeochlastaccessedtimetill datumtypen. - Välja Spara och publicera för att spara ändringarna i datamängden.
Därefter lägger vi till beräknade fält för räkningen av databases och tables.
- För
tablesdataset, välj Lägg till beräkning.
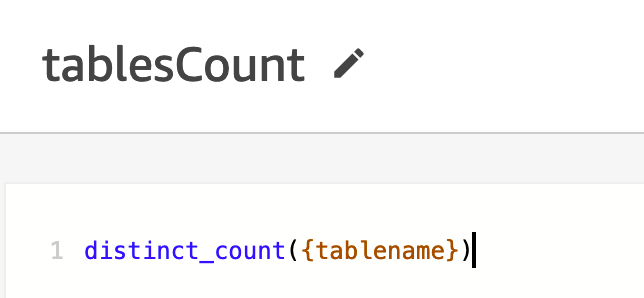
- Lägg till det beräknade fältet
tablesCountasdistinct_count({tablename}.
- Lägg på samma sätt till ett nytt beräknat fält
databasesCountasdistinct_count({databasename}.
Låt oss nu skapa en ny analys.
- Välj i navigeringsfönstret Analys.
- Välj
tablesdatasätt. - Välja Skapa analys.

Låt oss skapa vår första visual för räkningen av antalet databaser och tabeller i vår datasjö Data Catalog.
- Skapa en ny bild och lägg till
databasesCountfrån fältlistan.
Detta ger oss ett antal databaser i vår datakatalog.
- På samma sätt, lägg till en visual för att visa det totala antalet tabeller med hjälp av
tablesCountfält.
Låt oss skapa en andra bild för det totala antalet filer på Amazon S3 och den totala lagringsstorleken på Amazon S3.
- I likhet med föregående steg lägger vi till en ny bild och väljer
totalfilesons3ochsizeinmbons3fält för att visa Amazon S3-relaterad lagringsinformation.
Låt oss skapa en annan bild för att kontrollera vilka som är de minst använda datamängderna.
- Lägg till en bild med hjälp av
LastAccessTimedataelement.
Slutligen, låt oss skapa en bild till för att kontrollera om databaser är det delade resurser från olika konton.
- Välj
databasesdatasätt. - Vi skapar en tabell visuell typ och lägger till
databasename,sharedresourceochdescriptionfält.
Nu har du en uppfattning om vilka typer av bilder som är möjliga med denna data. Följande skärmdump är ett exempel på en färdig instrumentpanel.

Städa upp
För att undvika pågående avgifter, ta bort CloudFormation-stackarna och utdatafilerna i Amazon S3 som du skapade under distributionen. Du måste radera data i S3-hinkarna innan du kan radera hinkarna.
Slutsats
I det här inlägget visade vi hur du kan ställa in en instrumentpanel för operationella mätvärden för din datakatalog. Vi satte upp vårt program för att samla in viktiga dataelement om våra tabeller och databaser från AWS Glue Data Catalog. Vi använde sedan denna datauppsättning för att bygga vår instrumentpanel för operationsmått och fick insikter om vår datasjö.
Om författarna
 Sachin Thakkar är Senior Solutions Architect på Amazon Web Services och arbetar med en ledande Global System Integrator (GSI). Han har över 22 års erfarenhet som IT-arkitekt och teknikkonsult för stora institutioner. Hans fokusområde ligger på Data & Analytics. Sachin tillhandahåller arkitektonisk vägledning och stödjer GSI-partnern i att bygga strategiska industrilösningar på AWS
Sachin Thakkar är Senior Solutions Architect på Amazon Web Services och arbetar med en ledande Global System Integrator (GSI). Han har över 22 års erfarenhet som IT-arkitekt och teknikkonsult för stora institutioner. Hans fokusområde ligger på Data & Analytics. Sachin tillhandahåller arkitektonisk vägledning och stödjer GSI-partnern i att bygga strategiska industrilösningar på AWS
- '
- &
- 100
- 107
- 9
- tillgång
- Konto
- amason
- Amazon Web Services
- analys
- analytics
- arkitektur
- OMRÅDE
- AWS
- SLUTRESULTAT
- Byggnad
- företag
- Kapacitet
- byta
- avgifter
- koda
- Gemensam
- Anslutningar
- konsult
- innehåll
- Covid-19
- Skapa
- Aktuella
- instrumentbräda
- datum
- datasjö
- Databas
- databaser
- dag
- Företag
- Miljö
- erfarenhet
- Fält
- Förnamn
- första gången
- Fokus
- formen
- format
- Välgörenhet
- Tillväxt
- Hur ser din drömresa ut
- How To
- HTTPS
- IAM
- IKON
- Tanken
- Identitet
- industrin
- informationen
- insikter
- institutioner
- interaktiva
- IT
- Jobb
- Lediga jobb
- Nyckel
- språk
- Large
- ledande
- Lista
- läge
- mäta
- Metrics
- Navigering
- partnern
- Program
- allmän
- Python
- Resurser
- Körning
- rinnande
- Skala
- Server
- Tjänster
- in
- Enkelt
- Storlek
- So
- Lösningar
- SQL
- igång
- status
- förvaring
- lagra
- lagrar
- Strategisk
- Stöder
- system
- Teknologi
- tid
- us
- utsikt
- webb
- webbservice
- år
- år
