Den inbyggda Amazon SageMaker XGBoost-algoritmen tillhandahåller en hanterad behållare för att köra den populära XGBoost ramverk för maskininlärning (ML), med extra bekvämlighet att stödja avancerad utbildning eller slutledningsfunktioner som distribuerad utbildning, datafördelning för storskaliga datauppsättningar, A/B-modelltestning, eller slutledning av flera modeller slutpunkter. Du kan också utöka denna kraftfulla algoritm för att tillgodose olika krav.
Att packa koden och beroenden i en enda behållare är ett bekvämt och robust tillvägagångssätt för långsiktigt kodunderhåll, reproducerbarhet och revisionsändamål. Att modifiera behållaren följer basbehållaren direkt och undviker att duplicera befintliga funktioner som redan stöds av basbehållaren. I det här inlägget granskar vi de inre funktionerna i SageMaker XGBoost-algoritmbehållaren och tillhandahåller pragmatiska skript för att direkt anpassa behållaren.
SageMaker XGBoost containerstruktur
SageMakers inbyggda XGBoost-algoritm är förpackad som en fristående behållare, tillgänglig på GitHub, och kan utökas under den utvecklarvänliga Apache 2.0-licensen med öppen källkod. Behållaren förpackar öppen källkod XGBoost-algoritm och tillhörande verktyg för att köra algoritmen i SageMaker-miljön integrerad med andra AWS-molntjänster. Detta gör att du kan träna XGBoost-modeller på en mängd olika datakällor, göra batch-förutsägelser på offlinedata, eller värd för en slutpunkt i realtid rörledning.
Containern stöder utbildning och slutledningsoperationer med olika ingångspunkter. För inferensläge kan posten hittas i huvudfunktionen i serving.py-skript. För visning av slutledningar i realtid kör behållaren en Flask-Baserade webbserver det när åberopas, tar emot en HTTP-kodad begäran som innehåller data, avkodar data till XGBoosts DMatrix formatera, laddar modellen, och returnerar en HTTP-kodat svar tillbaka. Dessa metoder är inkapslade under Poängtjänst klass, som också kan anpassas genom skriptläget i stor utsträckning (se bilagan nedan).
Ingångspunkten för träningsläge (algoritmläge) är huvudfunktionen i utbildning.py. Huvudfunktionen ställer upp träningsmiljön och anropar träningsjobbfunktionen. Det är tillräckligt flexibelt för att möjliggöra distribuerad utbildning eller utbildning med en nod, eller verktyg som korsvalidering. Hjärtat i utbildningsprocessen finns i träna_jobb funktion.
Docker-filer som förpackar behållaren finns i GitHub repo. Observera att behållaren är byggd i två steg: a bas container byggs först, följt av slutlig behållare på toppen.
Lösningsöversikt
Du kan ändra och bygga om behållaren genom källkoden. Detta innebär dock att man samlar in och bygger om alla beroenden och paket från grunden. I det här inlägget diskuterar vi ett mer okomplicerat tillvägagångssätt som modifierar behållaren ovanpå den redan byggda och offentligt tillgängliga SageMaker XGBoost-algoritmens containerbild direkt.
I detta tillvägagångssätt, vi dra en kopia av den offentliga SageMaker XGBoost-bilden, modifiera skripten eller lägg till paket och bygg om behållaren ovanpå. Den modifierade behållaren kan lagras i ett privat förråd. På så sätt undviker vi att bygga om mellanliggande beroenden och bygger istället direkt ovanpå de redan byggda biblioteken paketerade i den officiella behållaren.
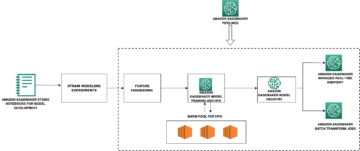
Följande figur visar en översikt över skriptet som används för att dra den offentliga basbilden, ändra och bygga om bilden och ladda upp den till en privat Amazon Elastic Container Registry (Amazon ECR) arkiv. De bash script i den medföljande koden i det här inlägget utför alla arbetsflödessteg som visas i diagrammet. Den medföljande anteckningsbok visar ett exempel där URI:n för en specifik version av SageMaker XGBoost-algoritmen först hämtas och skickas till bash script, som ersätter två av Python-skripten i bilden, bygger om den och skickar den modifierade bilden till ett privat Amazon ECR-förråd. Du kan ändra den medföljande koden för att passa dina behov.

Förutsättningar
Smakämnen GitHub repository innehåller koden som medföljer detta inlägg. Du kan köra prov anteckningsbok i ditt AWS-konto, eller använd det medföljande AWS molnformation stack för att distribuera anteckningsboken med en SageMaker-anteckningsbok. Du behöver följande förutsättningar:
- Ett AWS-konto.
- Nödvändiga behörigheter för att köra SageMaker batchtransformerings- och utbildningsjobb, och Amazon ECR-privilegier. CloudFormation-mallen skapar ett exempel AWS identitets- och åtkomsthantering (IAM) roller.
Distribuera lösningen
För att skapa dina lösningsresurser med AWS CloudFormation, välj Starta stack:
![]()
Stacken distribuerar en SageMaker-anteckningsbok som är förkonfigurerad för att klona GitHub-förvaret. Genomgången anteckningsbok innehåller stegen för att dra den offentliga SageMaker XGBoost-bilden för en given version, ändra den och skicka den anpassade behållaren till ett privat Amazon ECR-förråd. Anteckningsboken använder allmänheten Abalone dataset som ett exempel, tränar en modell med hjälp av SageMaker XGBoost inbyggda träningsläge och återanvänder denna modell i den anpassade bilden för att utföra batchtransformeringsjobb som ger slutsatser tillsammans med SHAP-värden.
Slutsats
SageMaker inbyggda algoritmer ger en mängd olika funktioner och funktioner och kan utökas ytterligare under Apache 2.0 öppen källkodslicens. I det här inlägget granskade vi hur man utökar den inbyggda produktionsbehållaren för SageMaker XGBoost-algoritmen för att möta produktionskrav som bakåtkod och API-kompatibilitet.
Exempel på anteckningsbok och hjälpreda skript ger en bekväm utgångspunkt för att anpassa SageMaker XGBoost-containerbilden så som du vill ha den. Ge det ett försök!
Bilaga: Skriptläge
Skriptläge ger ett sätt att modifiera många SageMaker inbyggda algoritmer genom att tillhandahålla ett gränssnitt för att ersätta de funktioner som är ansvariga för att transformera ingångarna och ladda modellen. Skriptläget är inte lika flexibelt som att direkt modifiera behållaren, men det ger en helt Python-baserad väg för att anpassa den inbyggda algoritmen utan att behöva arbeta direkt med Hamnarbetare.
I skriptläge, a user-module tillhandahålls för att anpassa dataavkodning, laddning av modellen och göra förutsägelser. Användarmodulen kan definiera en transformer_fn som hanterar alla aspekter av behandlingen av begäran till att förbereda svaret. Eller istället för att definiera transformer_fn, kan du tillhandahålla anpassade metoder model_fn, input_fn, predict_fnoch output_fn individuellt för att anpassa laddning av modellen och avkodning och förbereda indata för förutsägelse. För en mer grundlig översikt av skriptläge, se Ta med din egen modell med SageMaker Script Mode.
Om författarna
 Peyman Razaghi är Data Scientist på AWS. Han har en doktorsexamen i informationsteori från University of Toronto och var en postdoktorand forskare vid University of Southern California (USC), Los Angeles. Innan han började på AWS var Peyman en personalsystemingenjör på Qualcomm och bidrog till ett antal anmärkningsvärda internationella telekommunikationsstandarder. Han har skrivit flera vetenskapliga forskningsartiklar som har granskats inom statistik och systemteknik, och tycker om föräldraskap och landsvägscykling utanför jobbet.
Peyman Razaghi är Data Scientist på AWS. Han har en doktorsexamen i informationsteori från University of Toronto och var en postdoktorand forskare vid University of Southern California (USC), Los Angeles. Innan han började på AWS var Peyman en personalsystemingenjör på Qualcomm och bidrog till ett antal anmärkningsvärda internationella telekommunikationsstandarder. Han har skrivit flera vetenskapliga forskningsartiklar som har granskats inom statistik och systemteknik, och tycker om föräldraskap och landsvägscykling utanför jobbet.
- "
- 100
- tillgång
- rymma
- Konto
- avancerat
- algoritm
- algoritmer
- Alla
- redan
- amason
- api
- tillvägagångssätt
- OMRÅDE
- artiklar
- AWS
- SLUTRESULTAT
- inbyggd
- kalifornien
- Välja
- klass
- cloud
- molntjänster
- koda
- Samla
- fullständigt
- Behållare
- innehåller
- bekvämlighet
- Bekväm
- skapar
- beställnings
- datum
- datavetare
- distribuera
- vecklas ut
- olika
- direkt
- diskutera
- distribueras
- Hamnarbetare
- ingenjör
- Miljö
- exempel
- förlänga
- Funktioner
- Figur
- Förnamn
- flexibel
- efter
- format
- hittade
- Ramverk
- fungera
- ytterligare
- GitHub
- stor
- innehar
- Hur ser din drömresa ut
- How To
- HTTPS
- Identitet
- bild
- informationen
- ingång
- integrerade
- Gränssnitt
- Internationell
- IT
- Jobb
- Lediga jobb
- inlärning
- Licens
- lång sikt
- Los Angeles
- Maskinen
- maskininlärning
- GÖR
- Framställning
- förvaltade
- ML
- modell
- modeller
- mer
- anteckningsbok
- antal
- tjänsteman
- offline
- Verksamhet
- Övriga
- egen
- Punkt
- Populära
- den mäktigaste
- förutsägelse
- Förutsägelser
- privat
- process
- producera
- Produktion
- ge
- ger
- tillhandahålla
- allmän
- syfte
- realtid
- Repository
- begära
- Krav
- forskning
- Resurser
- respons
- ansvarig
- återgår
- översyn
- Rutt
- Körning
- Forskare
- Tjänster
- portion
- sharding
- Mjukvara
- lösning
- källkod
- Sydlig
- stapel
- standarder
- statistik
- Som stöds
- Stödjande
- Stöder
- System
- källan
- Genom
- tillsammans
- verktyg
- topp
- toronto
- Utbildning
- tåg
- Förvandla
- omvandla
- universitet
- användning
- mängd
- wikipedia
- Arbete
- skulle