Dataanalys med Scala
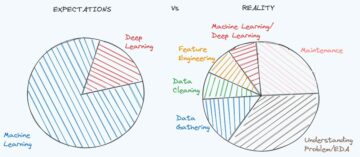
Det är mycket viktigt att välja rätt verktyg för dataanalys. På Kaggle -forumen, där internationella Data Science -tävlingar hålls, frågar folk ofta vilket verktyg som är bättre. R och Python är högst upp på listan. I den här artikeln kommer vi att berätta om en alternativ stapel dataanalysteknik, baserad på Scala.
By Roman Zykov, Grundare/Data Scientist @ TopDataLab

Det är mycket viktigt att välja rätt verktyg för dataanalys. På Kaggle.com forum, där internationella Data Science -tävlingar hålls, frågar folk ofta vilket verktyg som är bättre. R och Python är högst upp på listan. I den här artikeln kommer vi att berätta om en alternativ stack av dataanalystekniker, baserat på Scala programmeringsspråk och Gnista distribuerad datorplattform.
Hur kom vi på det? På Retail Rocket gör vi mycket maskininlärning på mycket stora datamängder. Vi brukade använda ett gäng IPython + Pyhs2 (bikupa -drivrutin för Python) + Pandas + Sklearn för att utveckla prototyper. I slutet av sommaren 2014 tog vi ett grundläggande beslut att byta till Spark, eftersom experiment har visat att vi kommer att få 3-4 gånger bättre prestanda på samma park av servrar.
En annan fördel är att vi kan använda ett programmeringsspråk för modellering och kod som körs på produktionsservrar. Detta var en stor fördel för oss, eftersom vi tidigare använde 4 språk samtidigt: Hive, Pig, Java, Python. Det är ett problem för ett litet team av ingenjörer.
Spark stöder att arbeta med Python/Scala/Java väl via API: er. Vi bestämde oss för att välja Scala eftersom det är språket Spark är skrivet på, vilket innebär att vi kan analysera dess källkod och åtgärda buggar om det behövs. Det är också JVM som Hadoop körs på.
Jag måste säga att valet inte var lätt, eftersom ingen i laget kände Scala vid den tiden.
Det är ett välkänt faktum att för att lära sig att kommunicera bra på ett språk måste du fördjupa dig i språket och använda det så mycket som möjligt. Så vi övergav Python -stacken till förmån för Scala för modellering och snabb dataanalys.
Det första steget var att hitta en ersättare för IPython -bärbara datorer. Alternativen var följande:
- Zeppelin -en IPython-liknande anteckningsbok för Spark;
- ISpark;
- Spark Anteckningsbok;
- IBMs Spark IPython -anteckningsbok.
- Apache Tmalm
Hittills har valet varit ISpark eftersom det är enkelt - det är IPython för Scala/Spark. Det har varit relativt enkelt att bulta på HighCharts och R -grafik. Och vi hade inga problem att ansluta den till garnklustret.
uppgift
Låt oss försöka svara på frågan: beror det genomsnittliga inköpsbeloppet (AOV) i din webbutik på statiska kundparametrar, som inkluderar avveckling, webbläsartyp (mobil/skrivbord), operativsystem och webbläsarversion? Du kan göra detta med Ömsesidig information.
Vi använder entropi mycket för våra rekommendationsalgoritmer och analyser: den klassiska Shannon-formeln, Kullback-Leibler-divergensen, ömsesidig information. Vi skickade till och med ett papper om detta ämne. Det finns en separat, om än liten, sektion som ägnas åt dessa åtgärder i Murphys berömda lärobok om maskininlärning.
Låt oss analysera det på riktiga Retail Rocket -data. På förhand kopierade jag provet från vårt kluster till min dator som en csv -fil.
Data
Här använder vi ISpark och Spark som körs i lokalt läge, vilket innebär att alla beräkningar utförs lokalt och fördelas mellan processorkärnorna. Allt beskrivs i kommentarerna till koden. Det viktigaste är att vi i utdata får RDD (Spark datastruktur), som är en samling fallsklasser av typen Row, som definieras i koden. Detta gör att du kan hänvisa till fält via “.”, Till exempel _.categoryId.


Raden ovan använder den nya DataFrame -datatypen som läggs till i Spark i version 1.3.0, den liknar mycket den liknande strukturen i pandas -biblioteket i Python. toDf plockar upp vår radklass, så att vi kan referera till fältet med namn.
För ytterligare analys måste vi välja en enda kategori, helst med mycket data. För att göra detta måste vi få en lista över de mest populära kategorierna.


Teoretiskt kan du använda alla HighCharts -grafer så länge de stöds i Wisp. Alla diagram är interaktiva.
Låt oss försöka göra samma sak, men med R.
Kör R -klienten och rita en char:


Ömsesidig information
Graferna visar att det finns ett samband, men kommer mätvärdena att bekräfta denna slutsats för oss? Det finns många sätt att göra detta. I vårt fall använder vi ömsesidig information mellan värdena i tabellen. Den mäter det ömsesidiga beroendet mellan fördelningar av två slumpmässiga (diskreta) variabler.
För diskreta fördelningar beräknas det med hjälp av formeln:

Men vi är intresserade av ett mer praktiskt mått - Maximal informationskoefficient (MIC) som kräver några knepiga beräkningar för kontinuerliga variabler. Så här låter definitionen av denna parameter.
Låt D = (x, y) vara en uppsättning n ordnade par element av slumpmässiga variabler X och Y. Detta tvådimensionella utrymme delas upp av X- och Y-rutnät, som grupperar x- och y-värden i X respektive Y-partitioner ( kom ihåg histogram!).

där B (n) är maskstorleken, är I ∗ (D, X, Y) den ömsesidiga informationen för X- och Y -partitionerna. Nämnaren anger logaritmen, som tjänar till att normalisera MIC till värdena för segmentet [0, 1]. MIC tar kontinuerliga värden i intervallet [0,1]: för extrema värden är det 1 om det finns ett beroende, 0 om det inte finns det. Vad som annars kan läsas om detta ämne listas i slutet av artikeln, i referenslistan.
Smakämnen boken (Machine Learning: a Probabilistic Perspective) kallar MIC (ömsesidig information) ett samband från 21 -talet. Och här är varför! Grafen nedan visar 6 beroenden (C till H -grafer). Pearsons korrelation och MIC har beräknats för dem, och de är markerade med motsvarande bokstäver på diagrammet till vänster. Som vi kan se är Pearson -korrelationen nästan noll, medan MIC visar en korrelation (diagram F, G, E).
 Källa: Reshef, DN, YA Reshef, HK Finucane, SR Grossman, G. McVean, PJ Turnbaugh, ES Lander, M. Mitzenmacher och PC Sabeti. "Upptäcka nya föreningar i stora datamängder."
Källa: Reshef, DN, YA Reshef, HK Finucane, SR Grossman, G. McVean, PJ Turnbaugh, ES Lander, M. Mitzenmacher och PC Sabeti. "Upptäcka nya föreningar i stora datamängder."Tabellen nedan visar ett antal mätvärden som har beräknats på olika beroenden: slumpmässiga, linjära, kubiska, etc. Tabellen visar att MIC uppträder mycket bra och upptäcker olinjära beroenden.
 Källa: Reshef, DN, YA Reshef, HK Finucane, SR Grossman, G. McVean, PJ Turnbaugh, ES Lander, M. Mitzenmacher och PC Sabeti. "Upptäcka nya föreningar i stora datamängder."
Källa: Reshef, DN, YA Reshef, HK Finucane, SR Grossman, G. McVean, PJ Turnbaugh, ES Lander, M. Mitzenmacher och PC Sabeti. "Upptäcka nya föreningar i stora datamängder."I vårt fall har vi att göra med en MIC -beräkning där vi har en kontinuerlig variabel Aov och alla andra är diskreta med oordnade värden, till exempel webbläsartyp. För att beräkna MIC korrekt måste vi diskretisera Aov -variabeln. Vi kommer att använda en färdig lösning från exploredata.net. Det finns ett problem med denna lösning: den förutsätter att båda variablerna är kontinuerliga och uttrycks i Float -värden. Så vi måste lura koden genom att koda värdena för de diskreta variablerna i Float och slumpmässigt ändra ordningen på dessa variabler. För att göra detta måste vi göra många iterationer med slumpmässig ordning (100), och vi tar det maximala MIC -värdet som resultatet.



För experimentet lade jag till en slumpmässig variabel med en enhetlig fördelning och själva AOV (genomsnittligt inköpsvärde). Som vi kan se var nästan alla MIC under slumpmässiga MIC, vilket kan betraktas som ett "villkorat" beslutströskelvärde. Aov MIC är nästan enhet, vilket är naturligt, eftersom korrelationen till sig själv är 1.
En intressant fråga uppstår: varför ser vi en korrelation på graferna, men MIC är noll? Vi kan komma med många hypoteser, men för OS Family är det troligtvis ganska enkelt - antalet Windows -maskiner är mycket högre än antalet andra:

Slutsats
Jag hoppas att Scala kommer att få sin popularitet bland dataanalytiker (Data Scientists). Det är mycket bekvämt eftersom det är möjligt att arbeta med en vanlig IPython -bärbar dator + få alla funktioner i Spark. Denna kod kan säkert fungera med terabyte med data, du behöver bara ändra konfigurationsraden i ISpark och ange URI för ditt kluster.
Referensprojekt
[1] Reshef, DN, YA Reshef, HK Finucane, SR Grossman, G. McVean, PJ Turnbaugh, ES Lander, M. Mitzenmacher och PC Sabeti. "Upptäcka nya föreningar i stora datamängder."
[2] MINE: Maximal information Icke -parametrisk utforskningsprogramvara med MIC
[3] Minepy-Maximal informationsbaserad Nonparam (Python, C ++, MATLAB, Octave)) etrisk utforskning.
[4] Java -bibliotek med datamängder för MIC
[5] "Machine Learning: a Probabilistic Perspective" Kevin Patrick Murphy
[6] Listan över koden ovan
Bio: Roman Zykov är grundare och datavetenskapare på TopDataLab, och har 20 års erfarenhet av dataanalys, med en magisterexamen i tillämpad matematik och fysik. Roman skrev också boken "Roman's Data Science: How to monetize your data", tillgänglig på Amazon.
Ursprungliga. Skickas om med tillstånd.
Relaterat:
Källa: https://www.kdnuggets.com/2021/09/data-analysis-scala.html
- "
- &
- 100
- Fördel
- algoritmer
- Alla
- amason
- bland
- analys
- Apache
- API: er
- appar
- Artikeln
- Bult
- webbläsare
- fel
- SLUTRESULTAT
- Bunch
- byta
- Diagram
- koda
- kommentarer
- Tävlingar
- databehandling
- datum
- dataanalys
- datavetenskap
- datavetare
- som handlar om
- djupt lärande
- utveckla
- DID
- distribuerad databehandling
- chaufför
- Teknik
- Ingenjörer
- etc
- excel
- erfarenhet
- experimentera
- utforskning
- Ansikte
- familj
- SNABB
- Funktioner
- Fält
- Förnamn
- Fast
- grundare
- Ramverk
- GitHub
- Hadoop
- här.
- Bikupa
- Hur ser din drömresa ut
- How To
- HTTPS
- stor
- informationen
- interaktiva
- Internationell
- IT
- java
- språk
- Språk
- Large
- LÄRA SIG
- inlärning
- Bibliotek
- linje
- Lista
- lokal
- lokalt
- Lång
- maskininlärning
- Maskiner
- matematik
- Metrics
- Microsoft
- modellering
- Mest populär
- bärbara datorer
- nätet
- Online Store
- öppet
- öppen källkod
- drift
- operativsystem
- Tillbehör
- beställa
- Övrigt
- Papper
- Personer
- prestanda
- perspektiv
- Fysik
- plattform
- Populära
- portfölj
- Produktion
- Programmering
- projektet
- inköp
- Python
- detaljhandeln
- Körning
- rinnande
- Skala
- Vetenskap
- vetenskapsmän
- in
- lösning
- Enkelt
- Storlek
- färdigheter
- Small
- So
- Mjukvara
- Utrymme
- lagra
- Upplevelser för livet
- lämnats
- sommar
- Som stöds
- Stöder
- Växla
- system
- Tekniken
- Testning
- Grafen
- tid
- topp
- enhet
- URI
- us
- värde
- webb
- wikipedia
- fönster
- Arbete
- X
- år
- noll-