Idag använder hundratusentals kunder datasjöar för analys och maskininlärning. Dataingenjörer måste dock rensa och förbereda denna data innan den kan användas. Den underliggande informationen måste vara korrekt och aktuell för att kunden ska kunna fatta säkra affärsbeslut. Annars förlorar datakonsumenter förtroendet för datan och fattar suboptimala eller felaktiga beslut. Det är en vanlig uppgift för dataingenjörer att utvärdera om uppgifterna är korrekta och aktuella eller inte. Idag finns det olika verktyg för datakvalitet. Vanliga datakvalitetsverktyg kräver dock vanligtvis manuella processer för att övervaka datakvaliteten.
AWS Glue Data Quality är en förhandsgranskningsfunktion för AWS-lim som mäter och övervakar datakvaliteten på Amazon enkel lagringstjänst (Amazon S3) datasjöar och i AWS Glue extrahera, transformera och ladda (ETL) jobb. Detta är en öppen förhandsgranskningsfunktion så den är redan aktiverad i ditt konto i tillgängliga regioner. Du kan enkelt definiera och mäta datakvalitetskontrollerna i AWS Glue Studio-konsolen utan att skriva koder. Det förenklar din upplevelse av att hantera datakvalitet.
Det här inlägget är del 2 i en serie med fyra inlägg för att förklara hur AWS Glue Data Quality fungerar. Kolla in det tidigare inlägget i den här serien:
I det här inlägget visar vi hur man skapar ett AWS Glue-jobb som mäter och övervakar datakvaliteten i en datapipeline. Vi visar också hur man vidtar åtgärder baserat på datakvalitetsresultaten.
Lösningsöversikt
Låt oss överväga ett exempel på användningsfall där en dataingenjör behöver bygga en datapipeline för att få in data från en råzon till en kurerad zon i en datasjö. Som dataingenjör är ett av dina huvudansvar – tillsammans med att extrahera, transformera och ladda data – att validera datakvaliteten. Genom att identifiera datakvalitetsproblem i förväg hjälper dig att förhindra att dålig data placeras i den kurerade zonen och undvika svåra incidenter med datakorruption.
I det här inlägget får du lära dig hur du enkelt ställer in inbyggd och beställnings datavalideringskontroller i ditt AWS Glue-jobb för att förhindra att dålig data förstör nedströms högkvalitetsdata.
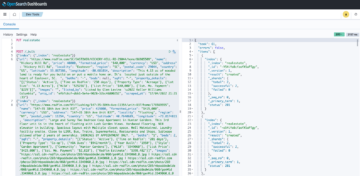
Datauppsättningen som används för detta inlägg är syntetiskt genererad; följande skärmdump visar ett exempel på data.

Konfigurera resurser med AWS CloudFormation
Detta inlägg innehåller en AWS molnformation mall för snabb installation. Du kan granska och anpassa den för att passa dina behov.
CloudFormation-mallen genererar följande resurser:
- En Amazon Simple Storage Service (Amazon S3) hink (
gluedataqualitystudio-*). - Följande prefix och objekt i S3-skopan:
datalake/raw/customer/customer.csvdatalake/curated/customer/scripts/sparkHistoryLogs/temporary/
- AWS identitets- och åtkomsthantering (IAM) användare, roller och policyer. IAM-rollen (
GlueDataQualityStudio-*) har behörighet att läsa och skriva från S3-hinken. - AWS Lambda funktioner och IAM-policyer som krävs av dessa funktioner för att skapa och ta bort denna stack.
Så här skapar du dina resurser:
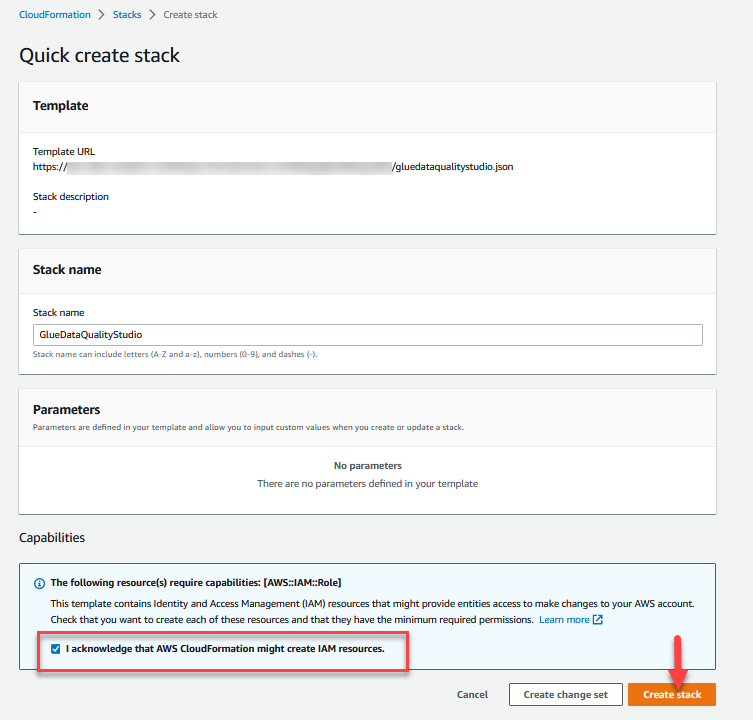
- Logga in på AWS CloudFormation-konsol i
us-east-1Område. - Välja Starta stack:

- Välja Jag erkänner att AWS CloudFormation kan skapa IAM-resurser.
- Välja Skapa stack och vänta på att steget att skapa stack ska slutföras.
Implementera lösningen
Utför följande steg för att börja konfigurera din lösning:
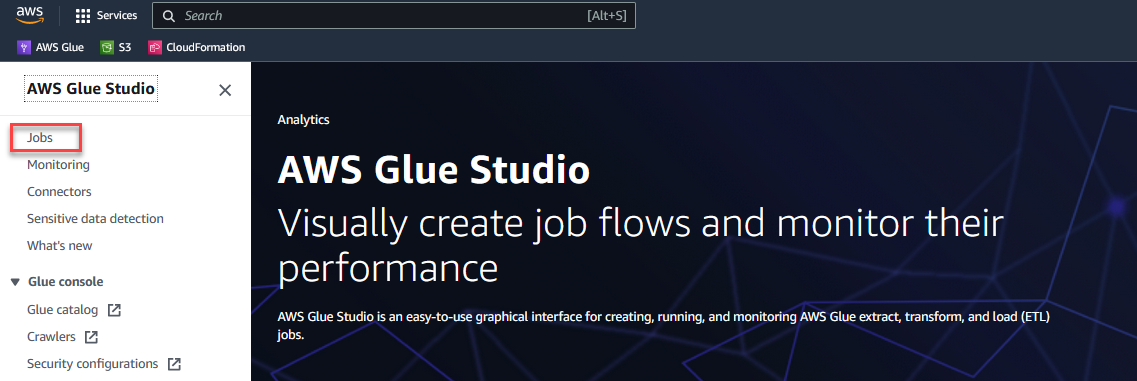
- På AWS Glue Studio-konsolväljer Lediga jobb i navigeringsfönstret.
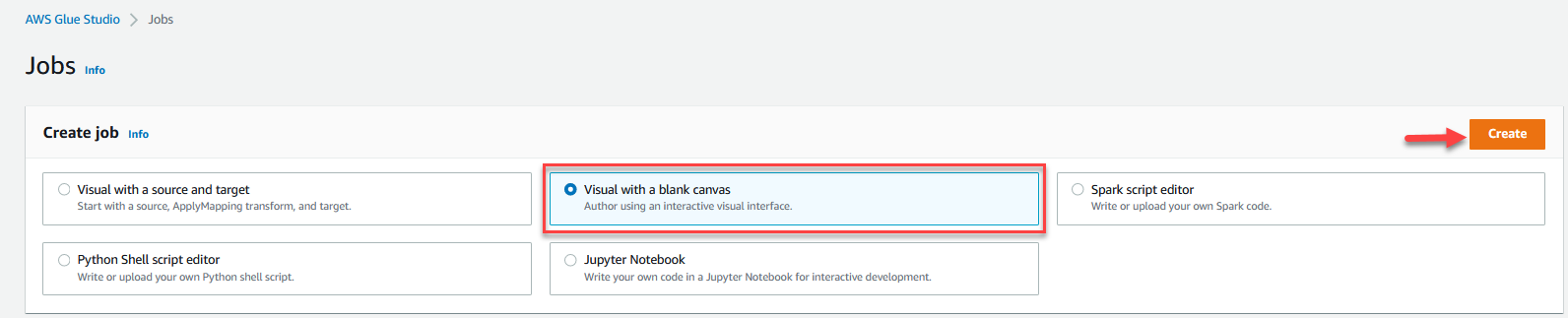
- Välja Visual med en tom duk Och välj Skapa.
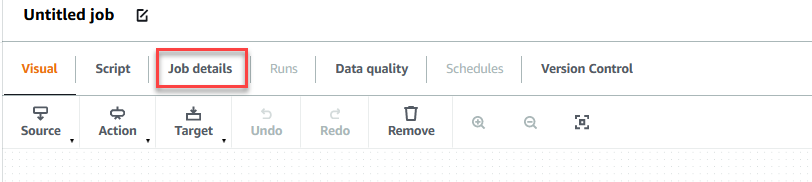
- Välj jobb~~POS=TRUNC Detaljer fliken för att konfigurera jobbet.
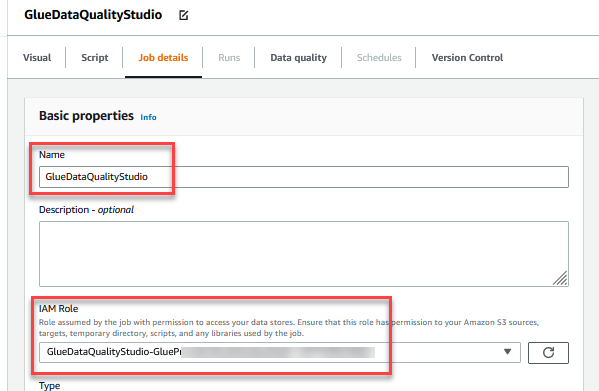
- För Namn , stiga på
GlueDataQualityStudio. - För IAM-roll, välj rollen som börjar med
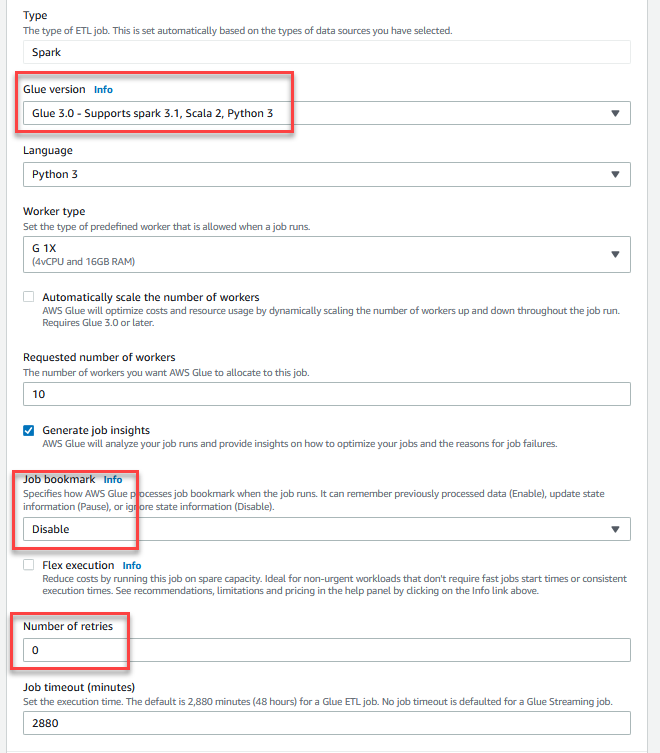
GlueDataQualityStudio-*. - För Limversionväljer Lim 3.0.
- För Jobbmärkeväljer inaktivera. Detta gör att du kan köra det här jobbet flera gånger med samma indatauppsättning.
- För Antal återförsök, stiga på
0.
- I Avancerade egenskaper sektionen tillhandahåller S3-hinken som skapats av CloudFormation-mallen (som börjar med
gluedataqualitystudio-*).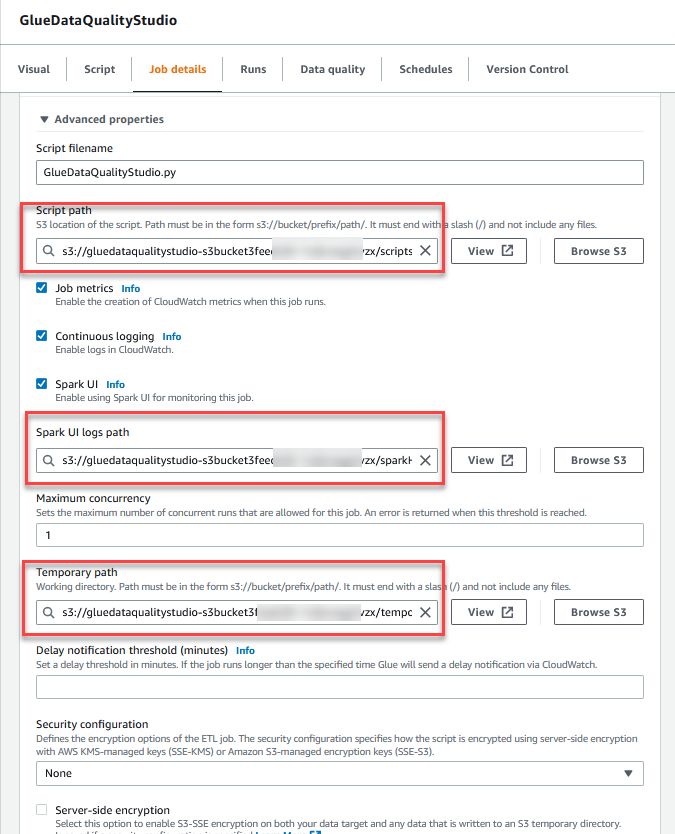
- Välja Save.
- När jobbet har sparats väljer du Visuell fliken och på Källa meny, välj Amazon S3.
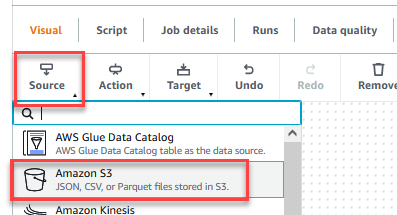
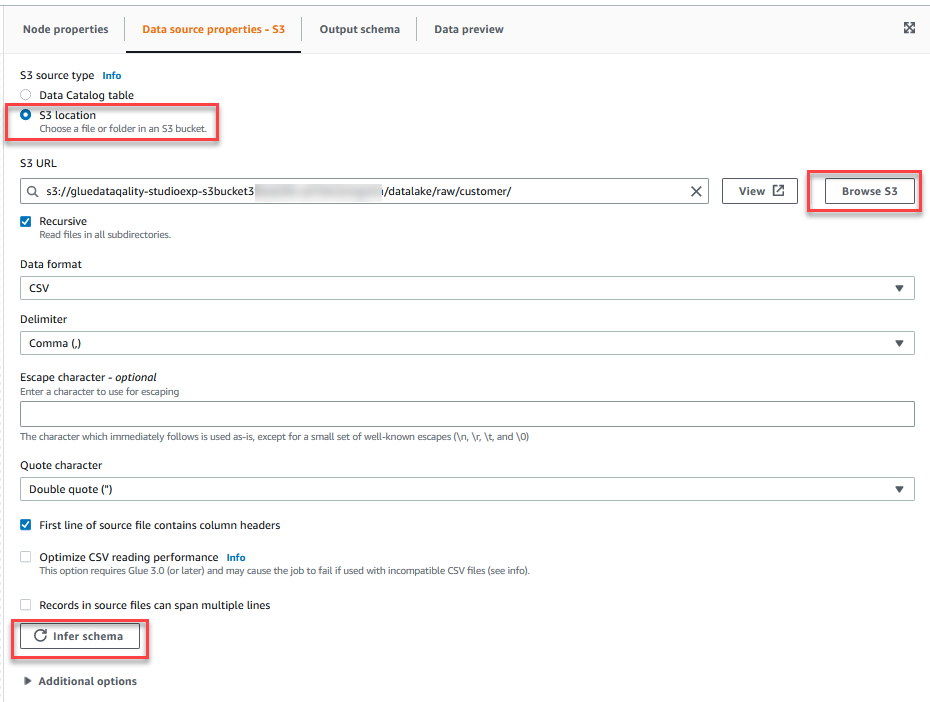
- På Datakällegenskaper - S3 flik, för S3 källtyp, Välj S3-plats.
- Välja Bläddra i S3 och navigera till prefix
/datalake/raw/customer/i S3-skopan som börjar medgluedataqualitystudio-*. - Välja Härleda schema.
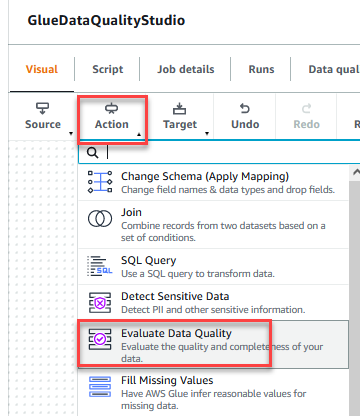
- På Handling meny, välj Utvärdera datakvalitet.
- Välj Utvärdera datakvalitet nod.
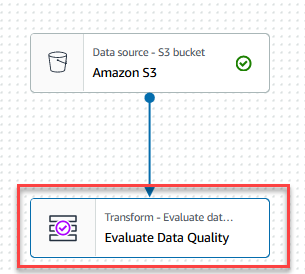
På Förvandla fliken kan du nu börja bygga datakvalitetsregler. Den första regeln du skapar är att kontrollera omCustomer_IDär unik och inte null med hjälp avisPrimaryKeyregel. - På Regeltyper fliken på DQDL-regelbyggare, söka efter
isprimarykeyoch välj plustecknet.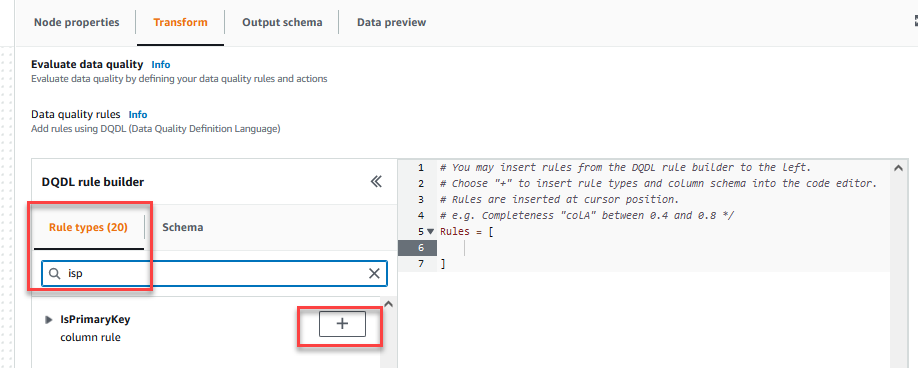
- På Schema fliken på DQDL-regelbyggare, välj plustecknet bredvid
Customer_ID. - Ta bort i regelredigeraren
id.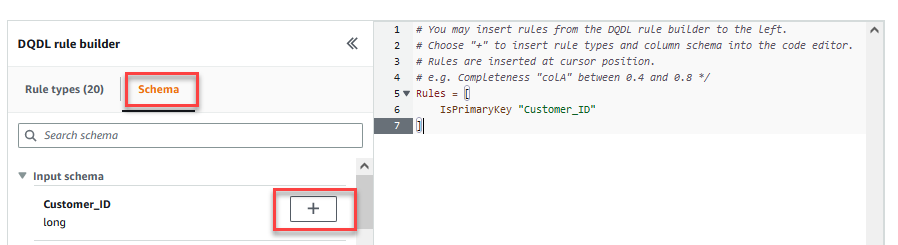
Nästa regel vi lägger till kontrollerar attFirst_Namekolumnvärdet finns för alla rader. - Du kan också ange datakvalitetsreglerna direkt i regelredigeraren. Lägg till ett kommatecken (,) och skriv in
IsComplete "First_Name",efter den första regeln.
Därefter lägger du till en anpassad regel för att verifiera att ingen rad existerar utanTelephoneorEmail. - Ange följande anpassade regel i regelredigeraren:

Funktionen Utvärdera datakvalitet tillhandahåller åtgärder för att hantera resultatet av ett jobb baserat på resultaten av jobbkvaliteten. - Välj det här inlägget Misslyckas jobb när datakvaliteten sviker Och välj Misslyckad jobb utan att ladda mål datum insatser. I den Utdatainställning för datakvalitet avsnitt väljer Bläddra i S3 och navigera till prefix
dqresultsi S3-skopan som börjar medgluedataqualitystudio-*.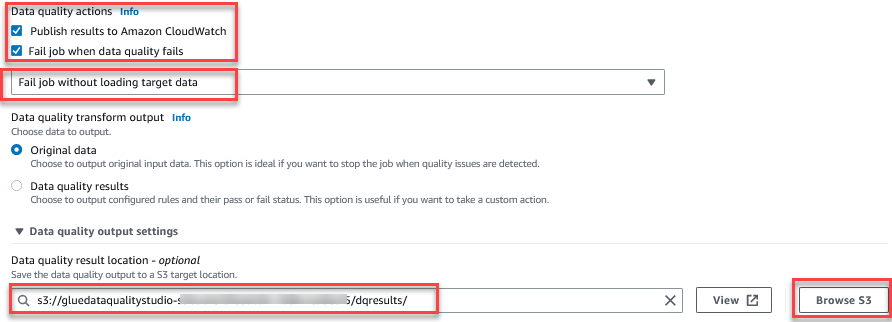
- På Målet meny, välj Amazon S3.
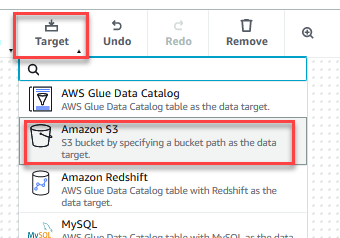
- Välj Datamål – S3-hink nod.
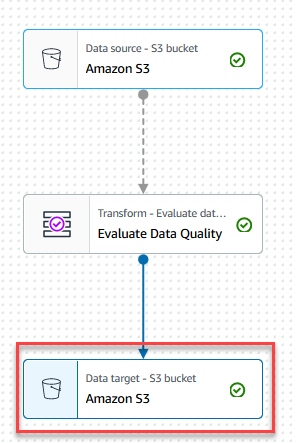
- På Egenskaper för datamål - S3 flik, för bildadväljer ParkettOch för Komprimeringstypväljer Snappy.
- För S3 Målplatsväljer Bläddra i S3 och navigera till prefixet
/datalake/curated/customer/i S3-skopan som börjar medgluedataqualitystudio-*.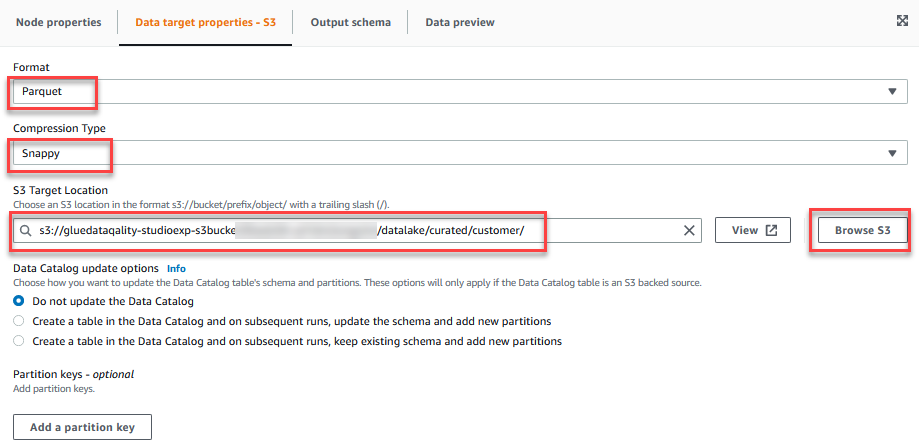
- Välja SaveOch välj sedan Körning.
 Du kan se uppgifter om jobbkörningen på fliken Körningar. I vårt exempel misslyckas jobbet med felmeddelandet "AssertionError: Jobbet misslyckades på grund av felaktiga DQ-regler för nod: .”
Du kan se uppgifter om jobbkörningen på fliken Körningar. I vårt exempel misslyckas jobbet med felmeddelandet "AssertionError: Jobbet misslyckades på grund av felaktiga DQ-regler för nod: .”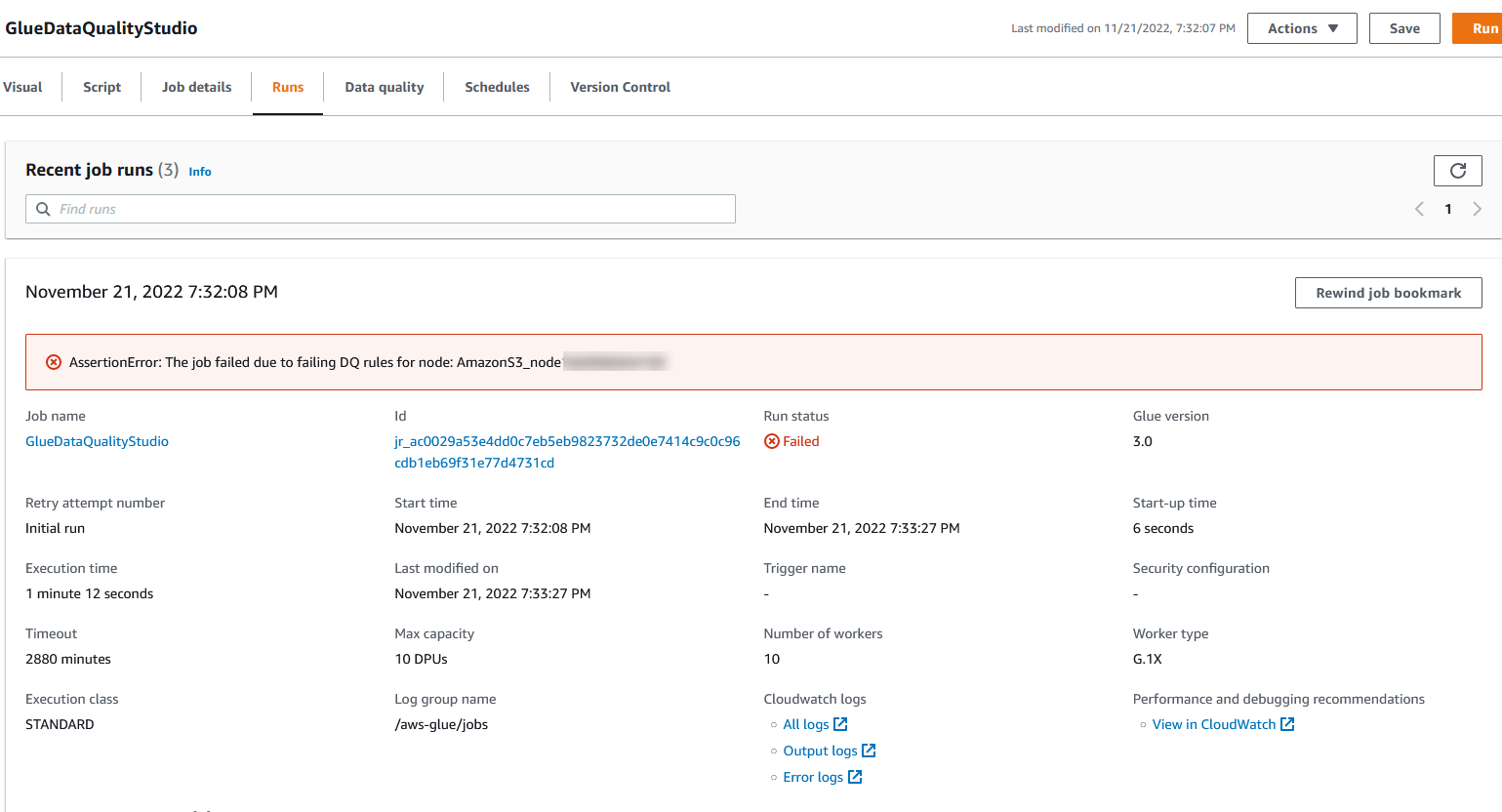 Du kan granska datakvalitetsresultatet på fliken Datakvalitet. I vårt exempel misslyckades valideringen av anpassad datakvalitet eftersom en av raderna i datamängden hade nr
Du kan granska datakvalitetsresultatet på fliken Datakvalitet. I vårt exempel misslyckades valideringen av anpassad datakvalitet eftersom en av raderna i datamängden hade nr TelephoneorEmailvärde. Evaluate Data Quality-resultat skrivs också till S3-bucket i JSON-format baserat på datakvalitetsresultatets platsparameter för noden.
Evaluate Data Quality-resultat skrivs också till S3-bucket i JSON-format baserat på datakvalitetsresultatets platsparameter för noden. - Navigera till
dqresultsprefix under S3-skopan som startargluedataqualitystudio-*. Du kommer att se att datakvalitetsresultatet är uppdelat efter datum.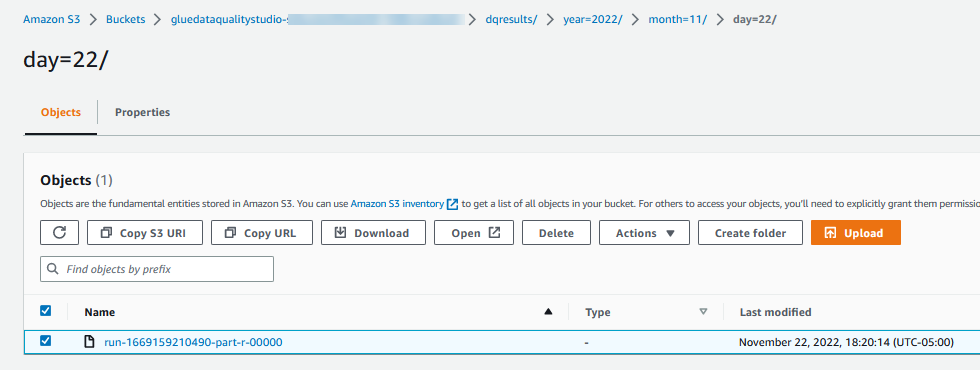
Följande är resultatet av JSON-filen. Du kan använda den här filutgången för att skapa anpassade instrumentpaneler för visualisering av datakvalitet.

Du kan också övervaka Utvärdera datakvalitet nod igenom amazoncloudwatch mätvärden och ställ in larm för att skicka meddelanden om datakvalitetsresultat. För att lära dig mer om hur du ställer in CloudWatch-larm, se Använder Amazon CloudWatch-larm.
Städa upp
För att undvika framtida avgifter och för att rensa outnyttjade roller och policyer, radera resurserna du skapade:
- Radera
GlueDataQualityStudiojobb du skapade som en del av det här inlägget. - På AWS CloudFormation-konsolen, ta bort
GlueDataQualityStudiostack.
Slutsats
AWS Glue Data Quality erbjuder ett enkelt sätt att mäta och övervaka datakvaliteten för din ETL-pipeline. I det här inlägget lärde du dig hur du vidtar nödvändiga åtgärder baserat på datakvalitetsresultaten, vilket hjälper dig att upprätthålla höga datastandarder och fatta säkra affärsbeslut.
För att lära dig mer om AWS Glue Data Quality, kolla in dokumentationen:
Om författarna
 Deenbandhu Prasad är Senior Analytics Specialist på AWS, specialiserad på big data-tjänster. Han brinner för att hjälpa kunder att bygga modern dataarkitektur på AWS-molnet. Han har hjälpt kunder av alla storlekar att implementera datahantering, datalager och datasjölösningar.
Deenbandhu Prasad är Senior Analytics Specialist på AWS, specialiserad på big data-tjänster. Han brinner för att hjälpa kunder att bygga modern dataarkitektur på AWS-molnet. Han har hjälpt kunder av alla storlekar att implementera datahantering, datalager och datasjölösningar.
 Yannis Mentekidis är Senior Software Development Engineer i AWS Glue-teamet.
Yannis Mentekidis är Senior Software Development Engineer i AWS Glue-teamet.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/getting-started-with-aws-glue-data-quality-for-etl-pipelines/
- 1
- 100
- 7
- a
- Om oss
- tillgång
- Konto
- exakt
- bekräfta
- Handling
- åtgärder
- Efter
- Alla
- tillåter
- redan
- amason
- analytics
- och
- arkitektur
- AWS
- AWS molnformation
- AWS-lim
- Badrum
- dålig data
- baserat
- därför att
- innan
- Stor
- Stora data
- SLUTRESULTAT
- Byggnad
- företag
- Vid
- avgifter
- ta
- Kontroller
- Välja
- cloud
- Kolumn
- Gemensam
- fullborda
- säker
- Tänk
- Konsol
- konsumenter
- Korruption
- skapa
- skapas
- skapande
- kurerad
- beställnings
- kund
- Kunder
- skräddarsy
- datum
- datasjö
- datahantering
- Datum
- beslut
- detaljer
- Utveckling
- direkt
- dokumentation
- lätt
- redaktör
- ingenjör
- Ingenjörer
- ange
- fel
- Eter (ETH)
- utvärdera
- exempel
- finns
- erfarenhet
- Förklara
- extrahera
- Misslyckades
- misslyckas
- Leverans
- Fil
- Förnamn
- efter
- format
- från
- funktioner
- framtida
- genereras
- genererar
- få
- hjälpte
- hjälpa
- hjälper
- Hög
- hög kvalitet
- Hur ser din drömresa ut
- How To
- Men
- html
- HTTPS
- Hundratals
- identifiera
- Identitet
- genomföra
- in
- innefattar
- ingång
- problem
- IT
- Jobb
- Lediga jobb
- json
- Nyckel
- sjö
- LÄRA SIG
- lärt
- inlärning
- läsa in
- läser in
- läge
- förlorar
- Maskinen
- maskininlärning
- bibehålla
- göra
- hantera
- ledning
- hantera
- manuell
- mäta
- åtgärder
- Meny
- meddelande
- Metrics
- kanske
- Modern Konst
- Övervaka
- monitorer
- mer
- multipel
- Navigera
- Navigering
- nödvändigt för
- behov
- Nästa
- nod
- anmälningar
- objekt
- Erbjudanden
- ONE
- öppet
- annat
- panelen
- parameter
- del
- brinner
- tillstånd
- rörledning
- placering
- plato
- Platon Data Intelligence
- PlatonData
- plus
- Strategier
- Inlägg
- Förbered
- presentera
- förhindra
- Förhandsvisning
- föregående
- primär
- processer
- egenskaper
- ge
- ger
- kvalitet
- Snabbt
- Raw
- Läsa
- senaste
- region
- kräver
- Obligatorisk
- Resurser
- resultera
- Resultat
- översyn
- Roll
- roller
- RAD
- Regel
- regler
- Körning
- Samma
- Sök
- §
- Serier
- service
- Tjänster
- in
- inställning
- inställning
- show
- Visar
- signera
- Enkelt
- storlekar
- So
- Mjukvara
- mjukvaruutveckling
- lösning
- Lösningar
- Källa
- specialist
- specialiserat
- stapel
- standarder
- starta
- igång
- Starta
- Steg
- Steg
- förvaring
- studio
- följer
- syntetiskt
- Ta
- Målet
- uppgift
- grupp
- mall
- Smakämnen
- tusentals
- Genom
- gånger
- till
- i dag
- verktyg
- Förvandla
- omvandla
- Litar
- under
- underliggande
- unika
- oanvänd
- användning
- användningsfall
- användare
- vanligen
- BEKRÄFTA
- godkännande
- värde
- olika
- utsikt
- visualisering
- vänta
- om
- som
- kommer
- utan
- fungerar
- skriva
- skrivning
- skriven
- Din
- zephyrnet