Ibland kan det vara mycket fördelaktigt att använda verktyg som kompilatorer som kan modifiera och kompilera dina modeller för optimal slutledningsprestanda. I det här inlägget utforskar vi TensorRT och hur man använder det med Amazon SageMaker slutsats använda NVIDIA Triton Inference Server. Vi utforskar hur TensorRT fungerar och hur man hostar och optimerar dessa modeller för prestanda och kostnadseffektivitet på SageMaker. SageMaker tillhandahåller enda modellslutpunkter (SMEs), som låter dig distribuera en enda ML-modell, eller flermodell slutpunkter (MME), som låter dig specificera flera modeller som ska vara värd bakom en logisk slutpunkt för högre resursutnyttjande.
För att betjäna modeller stöder Triton olika backends som motorer för att stödja körning och servering av olika ML-modeller för slutledning. För varje Triton-distribution är det avgörande att veta hur backend-beteendet påverkar dina arbetsbelastningar och vad du kan förvänta dig så att du kan bli framgångsrik. I det här inlägget hjälper vi dig att förstå TensorRT backend som stöds av Triton på SageMaker så att du kan fatta ett välgrundat beslut för dina arbetsbelastningar och få fantastiska resultat.
Djupdyk in i TensorRT-backend
TensorRT gör det möjligt för dig att optimera slutledningar med hjälp av tekniker som kvantisering, lager- och tensorfusion, kärnjustering och annat på NVIDIA GPU:er. Genom att anta och kompilera modeller för att använda TensorRT kan du optimera prestanda och användning för dina slutledningsarbetsbelastningar. I vissa fall finns det avvägningar, vilket är typiskt för tekniker som kvantisering, men resultaten kan vara dramatiska när det gäller att gynna prestanda, adressera latens och antalet transaktioner som kan bearbetas.
TensorRT-backend används för att köra TensorRT-modeller. TensorRT är en SDK utvecklad av NVIDIA som tillhandahåller ett högpresterande djupinlärningsinferensbibliotek. Den är optimerad för NVIDIA GPU:er och ger ett sätt att påskynda djupinlärning i produktionsmiljöer. TensorRT stöder stora ramverk för djupinlärning och inkluderar en högpresterande slutledningsoptimerare för djupinlärning och körtid som ger låg latens, hög genomströmning slutledning för AI-applikationer.
TensorRT kan accelerera modellens prestanda genom att använda en teknik som kallas grafoptimering för att optimera beräkningsdiagrammet som genereras av en djupinlärningsmodell. Den optimerar grafen för att minimera minnesavtrycket genom att frigöra onödigt minne och effektivt återanvända det. TensorRT-kompileringen smälter samman de glesa operationerna inuti modelldiagrammet för att bilda en större kärna för att undvika overhead av flera små kärnlanseringar. Med kärnans auto-tuning väljer motorn den bästa algoritmen för mål-GPU, vilket maximerar hårdvaruanvändningen. Dessutom använder TensorRT CUDA-strömmar för att möjliggöra parallell bearbetning av modeller, vilket ytterligare förbättrar GPU-användning och prestanda. Slutligen, genom kvantisering, kan TensorRT använda blandad precisionsacceleration av Tensor-kärnor, vilket gör att modellen kan köras i FP32, TF32, FP16 och INT8 precision för bästa slutledningsprestanda. Men även om den minskade precisionen generellt sett kan förbättra latensprestandan, kan den komma med möjlig instabilitet och försämring av modellens noggrannhet. Sammantaget resulterar TensorRTs kombination av tekniker i snabbare slutledning och lägre latens jämfört med andra inferensmotorer.
TensorRT-backend för Triton Inference Server är designad för att dra fördel av de kraftfulla slutledningsmöjligheterna hos NVIDIA GPU:er. För att använda TensorRT som en backend för Triton Inference Server måste du skapa en TensorRT-motor från din utbildade modell med TensorRT API. Denna motor laddas sedan in i Triton Inference Server och används för att utföra slutledning på inkommande förfrågningar. Följande är de grundläggande stegen för att använda TensorRT som en backend för Triton Inference Server:
- Konvertera din utbildade modell till ONNX formatera. Triton Inference Server stöder ONNX som modellformat. ONNX är en standard för att representera modeller för djupinlärning, vilket gör att de kan överföras mellan ramverk. Om din modell inte redan är i ONNX-formatet måste du konvertera den med det lämpliga ramspecifika verktyget. Till exempel, i PyTorch, kan detta göras med hjälp av
torch.onnx.exportmetod. - Importera ONNX-modellen till TensorRT och generera TensorRT-motorn. För TensorRT finns det flera sätt att bygga en TensorRT från din ONNX-modell. För det här inlägget använder vi
trtexecCLI-verktyg.trtexecär ett verktyg för att snabbt använda TensorRT utan att behöva utveckla din egen applikation. DetrtexecVerktyget har tre huvudsakliga syften:- Benchmarking nätverk på slumpmässiga eller användartillhandahållna indata.
- Genererar serialiserade motorer från modeller.
- Genererar en serialiserad tidscache från byggaren.
- Ladda TensorRT-motorn i Triton Inference Server. Efter att TensorRT-motorn har genererats kan den laddas in i Triton Inference Server genom att skapa en modellkonfiguration fil. Modellkonfigurationen (
config.pbtxt)-filen bör inkludera sökvägen till TensorRT-motorfilen och modellens in- och utdataformer.
Varje modell i en modellförråd måste inkludera en modellkonfiguration som ger obligatorisk och valfri information om modellen. Vanligtvis tillhandahålls denna konfiguration i en config.pbtxt fil specificerad som ModelConfig protobuf. Det finns flera viktiga punkter att notera i den här konfigurationsfilen:
- namn – Det här fältet definierar modellens namn och måste vara unikt inom modellförrådet.
- plattform – Det här fältet definierar typen av modell: TensorRT-motor, PyTorch eller något annat.
- max_batch_size – Detta anger den maximala batchstorleken som kan skickas till denna modell. Om modellens batchdimension är den första dimensionen och alla in- och utdata till modellen har denna batchdimension, kan Triton använda dess dynamisk batcher or sekvensbatcher för att automatiskt använda batchning med modellen. I detta fall,
max_batch_sizebör ställas in på ett värde större än eller lika med 1, vilket anger den maximala batchstorleken som Triton ska använda med modellen. För modeller som inte stöder batchning, eller som inte stöder batchning på de specifika sätt vi har beskrivit,max_batch_sizemåste ställas in på 0. - In-och utgång – Dessa fält är obligatoriska eftersom NVIDIA Triton behöver metadata om modellen. I huvudsak kräver det namnen på ditt nätverks in- och utdatalager och formen på nämnda in- och utgångar.
- instansgrupp – Detta avgör hur många instanser av den här modellen som kommer att skapas och om de kommer att använda GPU eller CPU.
- dynamic_batching - Dynamisk batchning är en funktion hos Triton som gör att slutledningsbegäranden kan kombineras av servern, så att en batch skapas dynamiskt. De
preferred_batch_sizeegenskapen anger batchstorlekarna som den dynamiska batchern ska försöka skapa. För de flesta modeller,preferred_batch_sizebör inte specificeras, som beskrivs i Rekommenderad konfigurationsprocess. Ett undantag är TensorRT-modeller som specificerar flera optimeringsprofiler för olika batchstorlekar. I det här fallet, eftersom vissa optimeringsprofiler kan ge betydande prestandaförbättringar jämfört med andra, kan det vara vettigt att användapreferred_batch_sizeför batchstorlekar som stöds av dessa optimeringsprofiler med högre prestanda. Du kan också referera till batchstorleken som tidigare användes vid körningtrtexec. Du kan också konfigurera fördröjningstiden för att tillåta att förfrågningar försenas under en begränsad tid i schemaläggaren för att tillåta andra förfrågningar att gå med i den dynamiska batchen.
TensorRT backend är förbättrad för att ha betydligt bättre prestanda. Förbättringar inkluderar att minska trådkonflikter, använda fast minne för snabbare överföringar mellan CPU och GPU, och öka beräknings- och minneskopieringsöverlappningen på GPU:er. Det minskar också minnesanvändningen av TensorRT-modeller i många fall genom att dela vikter över flera modellinstanser. Sammantaget ger TensorRT-backend för Triton Inference Server ett kraftfullt och flexibelt sätt att tjäna modeller för djupinlärning med optimerad TensorRT-inferens. Genom att justera konfigurationsalternativen kan du optimera prestanda och kontrollbeteende för att passa ditt specifika användningsfall.
SageMaker tillhandahåller Triton via små och medelstora företag och MME
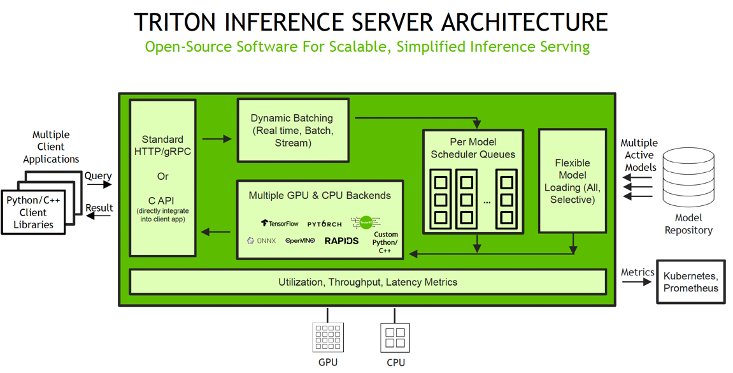
SageMaker låter dig distribuera båda enda och multimodell slutpunkter med Triton Inference Server. Triton stöder ett heterogent kluster med både GPU:er och processorer, vilket hjälper till att standardisera slutsatser över plattformar och dynamiskt skalas ut till valfri CPU eller GPU för att hantera toppbelastningar. Följande diagram illustrerar Triton Inference Server-arkitekturen. Slutledningsbegäranden anländer till servern via antingen HTTP/REST eller av C API, och dirigeras sedan till lämplig schemaläggare per modell. Triton redskap flera schemaläggnings- och batchalgoritmer som kan konfigureras på modell för modell. Varje modells schemaläggare utför valfritt batchning av slutledningsförfrågningar och skickar sedan förfrågningarna till backend motsvarande modelltypen. Ramverkets backend utför slutledning med hjälp av de indata som tillhandahålls i de batchade förfrågningarna för att producera de begärda utgångarna. Utgångarna formateras sedan och returneras i svaret. De modellförråd är ett filsystembaserat arkiv av modellerna som Triton kommer att göra tillgängliga för slutledning.
SageMaker tar hand om trafikformningen till MME-slutpunkten och upprätthåller optimala modellkopior på GPU-instanser för bästa prisprestanda. Den fortsätter att dirigera trafik till den instans där modellen laddas. Om instansresurserna når kapacitet på grund av högt utnyttjande, lossar SageMaker de minst använda modellerna från behållaren för att frigöra resurser för att ladda mer frekvent använda modeller. SageMaker MME erbjuder möjligheter för att köra flera djupinlärnings- eller ML-modeller på GPU samtidigt, med Triton Inference Server, som har utökats för att implementera MME API-kontrakt. MME:er gör det möjligt att dela GPU-instanser bakom en slutpunkt över flera modeller och dynamiskt ladda och ta bort modeller baserat på den inkommande trafiken. Med detta kan du enkelt uppnå optimal prisprestanda.
När en SageMaker MME tar emot en HTTP-anropsbegäran för en viss modell som använder TargetModel i begäran tillsammans med nyttolasten dirigerar den trafik till rätt instans bakom slutpunkten där målmodellen laddas. SageMaker tar hand om modellhanteringen bakom endpointen. Den laddar dynamiskt ner modeller från Amazon enkel lagringstjänst (Amazon S3) till instansens lagringsvolym om den anropade modellen inte är tillgänglig på instanslagringsvolymen. Sedan laddar SageMaker modellen till NVIDIA Triton-behållarens minne på en GPU-accelererad instans och betjänar slutledningsbegäran. GPU-kärnan delas av alla modeller i en instans. För mer information om SageMaker MME på GPU, se Kör flera djupinlärningsmodeller på GPU med Amazon SageMaker multi-model endpoints.
SageMaker MME:er kan skala horisontellt med hjälp av en automatisk skalningspolicy och tillhandahålla ytterligare GPU-beräkningsinstanser baserat på specificerade mätvärden. När du konfigurerar dina automatiska skalningsgrupper för SageMaker-slutpunkter, kanske du vill överväga SageMakerVariantInvocationsPerInstance som det primära kriteriet för att bestämma skalningsegenskaperna för dina automatiska skalningsgrupper. Dessutom, baserat på om dina modeller körs på GPU eller CPU, kan du också överväga att använda CPUUtilization or GPUUtilization som ytterligare kriterier. För slutpunkter för enstaka modeller är det ganska enkelt att ställa in korrekta policyer för att uppfylla dina SLA:er, eftersom alla modeller som används är desamma. För flermodellslutpunkter rekommenderar vi att du använder liknande modeller bakom en given slutpunkt för att få mer stabil, förutsägbar prestanda. I användningsfall där modeller av olika storlekar och krav används, kanske du vill separera dessa arbetsbelastningar över flera flermodellslutpunkter eller ägna lite tid åt att finjustera din grupppolicy för automatisk skalning för att få bästa balans mellan kostnad och prestanda.
Lösningsöversikt
Med NVIDIA Triton containerbild på SageMaker, kan du nu använda Tritons TensorRT-backend, som låter dig distribuera TensorRT-modeller. De TensorRT_backend repo innehåller dokumentationen och källan för backend. I följande avsnitt leder vi dig genom exempel anteckningsbok som visar hur man använder NVIDIA Triton Inference Server på SageMaker MME med GPU-funktionen för att distribuera en BERT-modell för naturlig språkbehandling (NLP).
Ställ in miljön
Vi börjar med att sätta upp den miljö som krävs. Vi installerar de beroenden som krävs för att paketera vår modellpipeline och köra inferenser med hjälp av Triton Inference Server. Vi definierar också AWS identitets- och åtkomsthantering (IAM) roll som ger SageMaker tillgång till modellartefakterna och NVIDIA Triton Amazon Elastic Container Registry (Amazon ECR) bild. Du kan använda följande kodexempel för att hämta den förbyggda Triton ECR-bilden:
Lägg till verktygsmetoder för att förbereda nyttolasten för begäran
Vi skapar funktionerna för att omvandla exempeltexten som vi använder för slutledning till nyttolasten som kan skickas för slutledning till Triton Inference Server. De tritonclient paketet, som installerades i början, tillhandahåller verktygsmetoder för att generera nyttolasten utan att behöva känna till detaljerna i specifikationen. Vi använder de skapade metoderna för att konvertera vår slutledningsbegäran till ett binärt format, vilket ger lägre latenser för slutledning. Dessa funktioner används under slutledningssteget.
Förbered TensorRT-modellen
I det här steget laddar vi förutbildad BERT-modell och konvertera till ONNX-representation med ficklampans ONNX-exportör och onnx_exporter.py manus. Efter att ONNX-modellen har skapats använder vi TensorRT trtexec kommando för att skapa modellplanen som ska vara värd för Triton. Detta drivs som en del av generate_model.sh skript från följande cell. Observera att cellen tar cirka 30 minuter att slutföra.
Medan du väntar på att kommandot ska slutföras kan du kontrollera skripten som används i det här steget. I den onnx_exporter.py skriptet använder vi torch.onnx.export funktion för att skapa ONNX-modeller:
Kommandoraden i filen gener_model.sh skapar TensorRT-modellplanen. För mer information, se trtexec kommandoradsverktyg.
Bygg ett TensorRT NLP BERT-modellförråd
Att använda Triton på SageMaker kräver att vi först ställer in en modellförråd mapp som innehåller de modeller vi vill servera. För varje modell måste vi skapa en modellkatalog som består av modellartefakten och definiera config.pbtxt fil för att ange modellkonfigurationen som Triton använder för att ladda och betjäna modellen. För att lära dig mer om konfigurationsinställningarna, se Modellkonfiguration. Modellförvarets struktur för BERT-modellen är som följer:
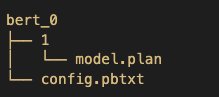
Observera att Triton har specifika krav för modellförvarslayout. Inom katalogen över modellförrådet på toppnivå har varje modell sin egen underkatalog som innehåller informationen för motsvarande modell. Varje modellkatalog i Triton måste ha minst en numerisk underkatalog som representerar en version av modellen. Här representerar mappen 1 version 1 av BERT-modellen. Varje modell körs av en specifik backend, så inom varje versionsunderkatalog måste det finnas de modellartefakter som krävs av den backend. Här använder vi TensorRT-backend, som kräver TensorRT-planfilen som används för servering (för detta exempel, model.plan). Om vi använde en PyTorch-backend, en model.pt fil skulle krävas. För mer information om namnkonventioner för modellfiler, se Modellfiler.
Varje TensorRT-modell måste tillhandahålla en config.pbtxt fil som beskriver modellkonfigurationen. För att kunna använda denna backend måste du ställa in backend fältet för din modell config.pbtxt fil till tensorrt_plan. Följande kodavsnitt visar ett exempel på hur man definierar konfigurationsfilen för BERT-modellen som serveras genom Tritons TensorRT-backend:
SageMaker förväntar sig att en .tar.gz-fil som innehåller varje Triton-modellförråd ska finnas på flermodellslutpunkten. För att simulera flera liknande modeller som är värd, kanske du tror att allt som krävs är att tjära modellförrådet vi redan har byggt och sedan kopiera det med olika filnamn. Triton kräver dock unika modellnamn. Därför kopierar vi först modellrepo N gånger, och ändrar modellkatalognamnen och deras motsvarande config.pbtxt filer. Du kan ändra antalet N för att få fler kopior av modellen som dynamiskt kan laddas till värdslutpunkten för att simulera modellens laddnings-/avlastningsåtgärd som hanteras av SageMaker. Se följande kod:
Skapa en SageMaker-slutpunkt
Nu när vi har laddat upp modellartefakterna till Amazon S3 kan vi skapa SageMaker-modellobjektet, slutpunktskonfigurationen och slutpunkten.
Först måste vi definiera serveringsbehållaren. I behållardefinitionen definierar du ModelDataUrl för att ange S3-katalogen som innehåller alla modeller som SageMaker multi-model endpoint kommer att använda för att ladda och visa förutsägelser. Uppsättning Mode till MultiModel för att indikera att SageMaker kommer att skapa slutpunkten med MME-behållarespecifikationer. Se följande kod:
Sedan skapar vi SageMaker-modellobjektet med hjälp av create_model boto3 API genom att ange ModelName och behållardefinition:
Vi använder denna modell för att skapa en slutpunktskonfiguration där vi kan ange vilken typ och antal instanser vi vill ha i slutpunkten. Här distribuerar vi till en g5.xlarge NVIDIA GPU-instans:
Med denna slutpunktskonfiguration skapar vi en ny SageMaker-slutpunkt och väntar på att distributionen ska slutföras. Status kommer att ändras till InService när distributionen är framgångsrik.
Anropa din modell på SageMaker-slutpunkten
När slutpunkten körs kan vi använda några exempel på rådata för att utföra slutledning med antingen JSON eller binär+JSON som nyttolastformat. För formatet för inferensbegäran använder Triton gemenskapsstandarden KFServing slutledningsprotokoll. Vi kan skicka slutledningsbegäran till flermodellslutpunkten med hjälp av invoke_enpoint API. Vi specificerar TargetModel i anropsanropet och skicka in nyttolasten för varje modelltyp. Här anropar vi slutpunkten i en for-loop för att begära slutpunkten till dynamiskt ladda eller lossa modeller baserat på förfrågningarna:
Du kan övervaka modellens lastnings- och lossningsstatus med hjälp av amazoncloudwatch mätvärden och loggar. SageMaker multi-model endpoints tillhandahåller mätvärden på instansnivå att övervaka; för mer information, se Övervaka Amazon SageMaker med Amazon CloudWatch. De LoadedModelCount metrisk visar antalet modeller som är lastade i containrarna. De ModelCacheHit mått visar antalet anrop till modellering som redan är inlästa i behållaren för att hjälpa dig få insikter på modellinbjudningsnivå. För att kontrollera om modeller har laddats ur från minnet kan du leta efter de lyckade avlastade loggposterna i slutpunktens CloudWatch-loggar.
Anteckningsboken finns i GitHub repository.
Bästa praxis
Innan du påbörjar någon optimeringsinsats med TensorRT är det viktigt att bestämma vad som ska mätas. Utan mätningar är det omöjligt att göra tillförlitliga framsteg eller mäta om framgång har uppnåtts. Här är några bästa praxis att tänka på när du använder TensorRT-backend för Triton Inference Server:
- Optimera din TensorRT-modell – Innan du distribuerar en modell på Triton med TensorRT-backend, se till att optimera modellen efter TensorRT bästa praxis guide. Detta hjälper dig att uppnå bättre prestanda genom att minska slutledningstid och minnesförbrukning.
- Använd TensorRT istället för andra Triton-backends när det är möjligt – TensorRT är designat för att optimera djupinlärningsmodeller för distribution på NVIDIA GPU:er, så att använda den kan avsevärt förbättra slutledningsprestanda jämfört med andra stödda Triton-backends.
- Använd rätt precision – TensorRT stöder flera precisioner (FP32, FP16, INT8), och att välja rätt precision för din modell kan ha en betydande inverkan på prestandan. Överväg att använda lägre precision när det är möjligt.
- Använd batchstorlekar som passar din hårdvara – Se till att välja batchstorlekar som passar din GPU:s minne och beräkningskapacitet. Att använda batchstorlekar som är för stora eller för små kan påverka prestandan negativt.
Slutsats
I det här inlägget dyker vi djupt in i TensorRT-backend som Triton Inference Server stöder på SageMaker. Denna backend tillhandahåller både CPU- och GPU-acceleration av dina TensorRT-modeller. Det finns många alternativ att överväga för att få bästa möjliga prestanda för slutledning, såsom batchstorlekar, datainmatningsformat och andra faktorer som kan anpassas för att möta dina behov. SageMaker låter dig dra fördel av denna möjlighet genom att använda enstaka modellslutpunkter för garanterad prestanda och flermodellslutpunkter för att få en bättre balans mellan prestanda och kostnadsbesparingar. För att komma igång med MME-stöd för GPU, se Algoritmer, ramverk och instanser som stöds.
Vi inbjuder dig att prova Triton Inference Server-behållare i SageMaker och dela din feedback och frågor i kommentarerna.
Om författarna
 Melanie Li är en Senior AI/ML Specialist TAM på AWS baserad i Sydney, Australien. Hon hjälper företagskunder att bygga lösningar som utnyttjar de senaste AI/ML-verktygen på AWS och ger vägledning om arkitektur och implementering av maskininlärningslösningar med bästa praxis. På fritiden älskar hon att utforska naturen utomhus och umgås med familj och vänner.
Melanie Li är en Senior AI/ML Specialist TAM på AWS baserad i Sydney, Australien. Hon hjälper företagskunder att bygga lösningar som utnyttjar de senaste AI/ML-verktygen på AWS och ger vägledning om arkitektur och implementering av maskininlärningslösningar med bästa praxis. På fritiden älskar hon att utforska naturen utomhus och umgås med familj och vänner.
 James Park är en lösningsarkitekt på Amazon Web Services. Han arbetar med Amazon för att designa, bygga och distribuera tekniklösningar på AWS och har ett särskilt intresse för AI och maskininlärning. På fritiden tycker han om att söka nya kulturer, nya upplevelser och att hålla sig uppdaterad med de senaste tekniktrenderna.
James Park är en lösningsarkitekt på Amazon Web Services. Han arbetar med Amazon för att designa, bygga och distribuera tekniklösningar på AWS och har ett särskilt intresse för AI och maskininlärning. På fritiden tycker han om att söka nya kulturer, nya upplevelser och att hålla sig uppdaterad med de senaste tekniktrenderna.
 Jiahong Liu är en lösningsarkitekt på Cloud Service Provider-teamet på NVIDIA. Han hjälper kunder att ta till sig maskininlärning och AI-lösningar som utnyttjar NVIDIAs accelererade datoranvändning för att hantera deras utbildnings- och slutledningsutmaningar. På sin fritid tycker han om origami, gör-det-själv-projekt och att spela basket.
Jiahong Liu är en lösningsarkitekt på Cloud Service Provider-teamet på NVIDIA. Han hjälper kunder att ta till sig maskininlärning och AI-lösningar som utnyttjar NVIDIAs accelererade datoranvändning för att hantera deras utbildnings- och slutledningsutmaningar. På sin fritid tycker han om origami, gör-det-själv-projekt och att spela basket.
 Kshitiz Gupta är lösningsarkitekt på NVIDIA. Han tycker om att utbilda molnkunder om GPU AI-teknikerna NVIDIA har att erbjuda och hjälpa dem med att accelerera deras maskininlärning och djupinlärning. Utanför jobbet tycker han om att springa, vandra och titta på vilda djur.
Kshitiz Gupta är lösningsarkitekt på NVIDIA. Han tycker om att utbilda molnkunder om GPU AI-teknikerna NVIDIA har att erbjuda och hjälpa dem med att accelerera deras maskininlärning och djupinlärning. Utanför jobbet tycker han om att springa, vandra och titta på vilda djur.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/host-ml-models-on-amazon-sagemaker-using-triton-tensorrt-models/
- : har
- :är
- :inte
- :var
- $UPP
- 1
- 10
- 100
- 11
- 12
- 13
- 23
- 30
- 8
- a
- Able
- Om oss
- accelerera
- accelererad
- accelererande
- acceleration
- tillgång
- noggrannhet
- Uppnå
- uppnås
- tvärs
- Handling
- Dessutom
- Annat
- Dessutom
- adress
- adresse
- Anta
- Fördel
- Efter
- AI
- AI / ML
- algoritm
- algoritmer
- Alla
- tillåter
- tillåter
- längs
- redan
- också
- Även
- amason
- Amazon SageMaker
- Amazon Web Services
- an
- och
- vilken som helst
- api
- Ansökan
- tillämpningar
- lämpligt
- arkitektur
- ÄR
- runt
- AS
- assist
- At
- Australien
- bil
- automatiskt
- tillgänglig
- undvika
- AWS
- backend
- Balansera
- bas
- baserat
- grundläggande
- grund
- Basketboll
- BE
- därför att
- varit
- innan
- börja
- Börjar
- bakom
- Där vi får lov att vara utan att konstant prestera,
- fördelaktigt
- gynnar
- BÄST
- bästa praxis
- Bättre
- mellan
- kropp
- båda
- SLUTRESULTAT
- byggare
- byggt
- men
- by
- cache
- Ring
- kallas
- KAN
- kapacitet
- Kapacitet
- vilken
- Vid
- fall
- utmaningar
- byta
- byte
- egenskaper
- ta
- Välja
- klient
- klienter
- cloud
- kluster
- koda
- COM
- kombination
- kombinerad
- komma
- kommentarer
- samfundet
- jämfört
- fullborda
- beräkning
- Compute
- databehandling
- konfiguration
- Tänk
- Bestående
- konsumtion
- Behållare
- Behållare
- innehåller
- fortsätter
- kontroll
- Konventioner
- konvertera
- Kärna
- Motsvarande
- Pris
- kostnadsbesparingar
- CPU
- skapa
- skapas
- skapar
- Skapa
- skapande
- kriterier
- avgörande
- Kunder
- datum
- Datum
- Beslutet
- djup
- djupt lärande
- definierar
- fördröja
- Försenad
- levererar
- demonstrerar
- distribuera
- utplacerade
- utplacera
- utplacering
- beskriven
- Designa
- utformade
- detaljer
- Bestämma
- bestämd
- utveckla
- utvecklade
- olika
- Dimensionera
- diy
- dokumentation
- gjort
- inte
- duva
- Nedladdningar
- dramatiskt
- grund
- under
- dynamisk
- dynamiskt
- varje
- lätt
- kant
- utbilda
- effektivitet
- effektivt
- ansträngning
- antingen
- sysselsätter
- möjliggöra
- möjliggör
- möjliggör
- Slutpunkt
- Motor
- Motorer
- Företag
- företagskunder
- Miljö
- miljöer
- lika
- väsentlig
- väsentligen
- Eter (ETH)
- exempel
- undantag
- förvänta
- förväntar
- Erfarenheter
- utforska
- faktorer
- ganska
- familj
- snabbare
- Leverans
- återkoppling
- fält
- Fält
- Fil
- Filer
- FIN
- Slutligen
- slut
- Förnamn
- passa
- flexibel
- efter
- följer
- Fotavtryck
- För
- formen
- format
- hittade
- Ramverk
- ramar
- Fri
- ofta
- vänner
- från
- fungera
- funktioner
- ytterligare
- sammansmältning
- allmänhet
- generera
- genereras
- skaffa sig
- Ge
- ges
- ger
- GPU
- GPUs
- diagram
- stor
- större
- Grupp
- Gruppens
- garanterat
- vägleda
- styra
- hantera
- hårdvara
- Har
- har
- he
- hjälpa
- hjälper
- här
- här.
- Hög
- högpresterande
- högre
- vandring
- hans
- värd
- värd
- värd
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- i
- IAM
- ID
- Identitet
- if
- illustrerar
- bild
- Inverkan
- Konsekvenser
- genomföra
- genomföra
- redskap
- importera
- omöjligt
- förbättra
- förbättras
- förbättring
- förbättringar
- förbättra
- in
- innefattar
- innefattar
- Inkommande
- ökande
- ökning
- indikerar
- pekar på
- informationen
- informeras
- ingång
- ingångar
- insikter
- instabilitet
- installera
- installerad
- exempel
- istället
- intresse
- in
- bjuda in
- åberopas
- IT
- DESS
- delta
- jpg
- json
- Nyckel
- Snäll
- Vet
- språk
- Large
- större
- Latens
- senaste
- lanserar
- lager
- skikt
- Layout
- LÄRA SIG
- inlärning
- t minst
- Hävstång
- hävstångs
- Bibliotek
- Begränsad
- linje
- läsa in
- läser in
- laster
- log
- logisk
- se
- Låg
- Maskinen
- maskininlärning
- Huvudsida
- upprätthåller
- större
- göra
- förvaltade
- ledning
- många
- Match
- maximera
- maximal
- Maj..
- mäta
- mätningar
- Möt
- Minne
- metadata
- metod
- metoder
- metriska
- Metrics
- kanske
- minimera
- minuter
- ML
- Mode
- modell
- modeller
- modifiera
- Övervaka
- mer
- mest
- Multi-Model Endpoint
- multipel
- måste
- namn
- namn
- namngivning
- Natural
- Naturligt språk
- Naturlig språkbehandling
- Natur
- Behöver
- behov
- negativt
- nätverk
- Nya
- nlp
- Notera
- anteckningsbok
- nu
- antal
- Nvidia
- objektet
- få
- of
- erbjudanden
- on
- ONE
- öppet
- Verksamhet
- optimala
- optimering
- Optimera
- optimerad
- optimerar
- Tillbehör
- or
- beställa
- OS
- Övriga
- Övrigt
- vår
- ut
- utomhus
- produktion
- utanför
- övergripande
- egen
- paket
- Parallell
- del
- särskilt
- passera
- Godkänd
- passerar
- bana
- Topp
- utföra
- prestanda
- utför
- rörledning
- Planen
- plattform
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- i
- poäng
- Strategier
- policy
- möjlig
- Inlägg
- den mäktigaste
- praxis
- Precision
- Förutsägbar
- Förutsägelser
- förbereda
- föregående
- tidigare
- pris
- primär
- bearbetning
- producera
- Produktion
- Profiler
- Framsteg
- projekt
- rätt
- egenskapen
- proto
- ge
- förutsatt
- leverantör
- ger
- tillhandahållande
- syfte
- pytorch
- frågor
- snabbt
- höja
- slumpmässig
- Raw
- rådata
- nå
- erhåller
- rekommenderar
- Minskad
- minskar
- reducerande
- region
- pålitlig
- Repository
- representation
- representerar
- representerar
- begära
- begärda
- förfrågningar
- Obligatorisk
- Krav
- Kräver
- resurs
- Resurser
- respons
- Resultat
- höger
- Roll
- Rutt
- rutter
- rt
- Körning
- rinnande
- s
- sagemaker
- Nämnda
- Samma
- Save
- Besparingar
- Skala
- skalor
- skalning
- schemaläggning
- skript
- sDK
- §
- sektioner
- se
- söker
- väljer
- sända
- senior
- känsla
- separat
- tjänar
- serverar
- service
- Leverantör
- Tjänster
- portion
- in
- inställning
- inställningar
- flera
- Forma
- former
- formning
- Dela
- delas
- delning
- hon
- skall
- Visar
- signifikant
- signifikant
- liknande
- Enkelt
- enda
- Storlek
- storlekar
- Small
- SMF
- So
- lösning
- Lösningar
- några
- något
- Källa
- specialist
- specifik
- specifikation
- specifikationer
- specificerade
- spendera
- standard
- igång
- Starta
- state-of-the-art
- status
- stadig
- Steg
- Steg
- förvaring
- okomplicerad
- strömmar
- struktur
- framgång
- framgångsrik
- sådana
- följer
- stödja
- Som stöds
- Stöder
- säker
- sydney
- Ta
- tar
- TAM
- Målet
- grupp
- tekniker
- Tekniken
- Teknologi
- än
- den där
- Smakämnen
- Grafen
- den information
- deras
- Dem
- sedan
- Där.
- därför
- Dessa
- de
- Tänk
- detta
- de
- tre
- Genom
- tid
- gånger
- Tidpunkten
- till
- alltför
- verktyg
- verktyg
- toppnivå
- brännaren
- trafik
- tränad
- Utbildning
- Transaktioner
- överförd
- överföringar
- Förvandla
- transformatorer
- Trender
- Triton
- Typ
- typisk
- typiskt
- förstå
- unika
- uppladdad
- us
- Användning
- användning
- användningsfall
- Begagnade
- med hjälp av
- verktyg
- utnyttja
- värde
- olika
- version
- mycket
- via
- volym
- vänta
- väntar
- vill
- var
- tittar
- Sätt..
- sätt
- we
- webb
- webbservice
- były
- Vad
- när
- om
- som
- Djurliv
- kommer
- med
- inom
- utan
- Arbete
- fungerar
- skulle
- dig
- Din
- zephyrnet