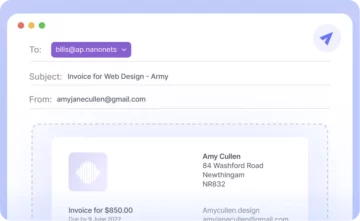
I den här artikeln får du reda på olika metoder för att konvertera PDF till Google Sheets.
Du kommer också att lära dig hur Nanonets kan automatisera hela arbetsflödet för att konvertera PDF till Google Sheets uppkopplad.
Innan vi tittar på hur man konverterar PDF till Google Sheets, låt oss ta en titt på varför det är viktigt att göra detta.
Varför konvertera PDF-filer till Google Sheets?
Enligt det här Google blogg från Googles officiella bloggsida använder mer än 5 miljoner företag sin G Suite-lösning. Samtidigt har ett stort antal företag också börjat använda Google Sheets-integrationer för att automatisera uppgifter.
Låt oss överväga ett typiskt användningsfall. Ditt leverantörsreskontrateam får en faktura i standard PDF-format. Någon går manuellt igenom fakturan och knappar in den nödvändiga informationen i ett Google Sheets-dokument innan han vidarebefordrar det till sektionen Ekonomi. Ekonomisektionen betalar din leverantör och gör en anteckning i företagets reskontra.
Förutom att det är en långdragen process är detta felbenäget och det skulle vara mycket mer meningsfullt att helt enkelt automatisera den.
Nu när behovet av att konvertera PDF-filer till ett Google-arkformulär är klart, låt oss ta en titt på hur PDF-dokument är uppbyggda och vilka utmaningarna är att analysera dem.
Vill konvertera PDF filer till Google Sheets ? Kolla upp Nanonets kostnadsfria PDF till CSV-konverterare. Eller ta reda på hur automatisera hela din PDF till Google Sheets arbetsflöde med Nanonets.
Utmaningar med att analysera ett PDF-dokument
Det bärbara dokumentformatet var ett filformat som ursprungligen utvecklades av Adobe och släpptes senare som en öppen standard. Det har sedan dess antagits allmänt eftersom det är agnostiskt för det underliggande operativsystemet.
Så varför är det så utmanande att analysera en PDF och konvertera dess innehåll till ett annat format? Följande bilder säger mer än tusen ord och kommer att driva poängen hem.
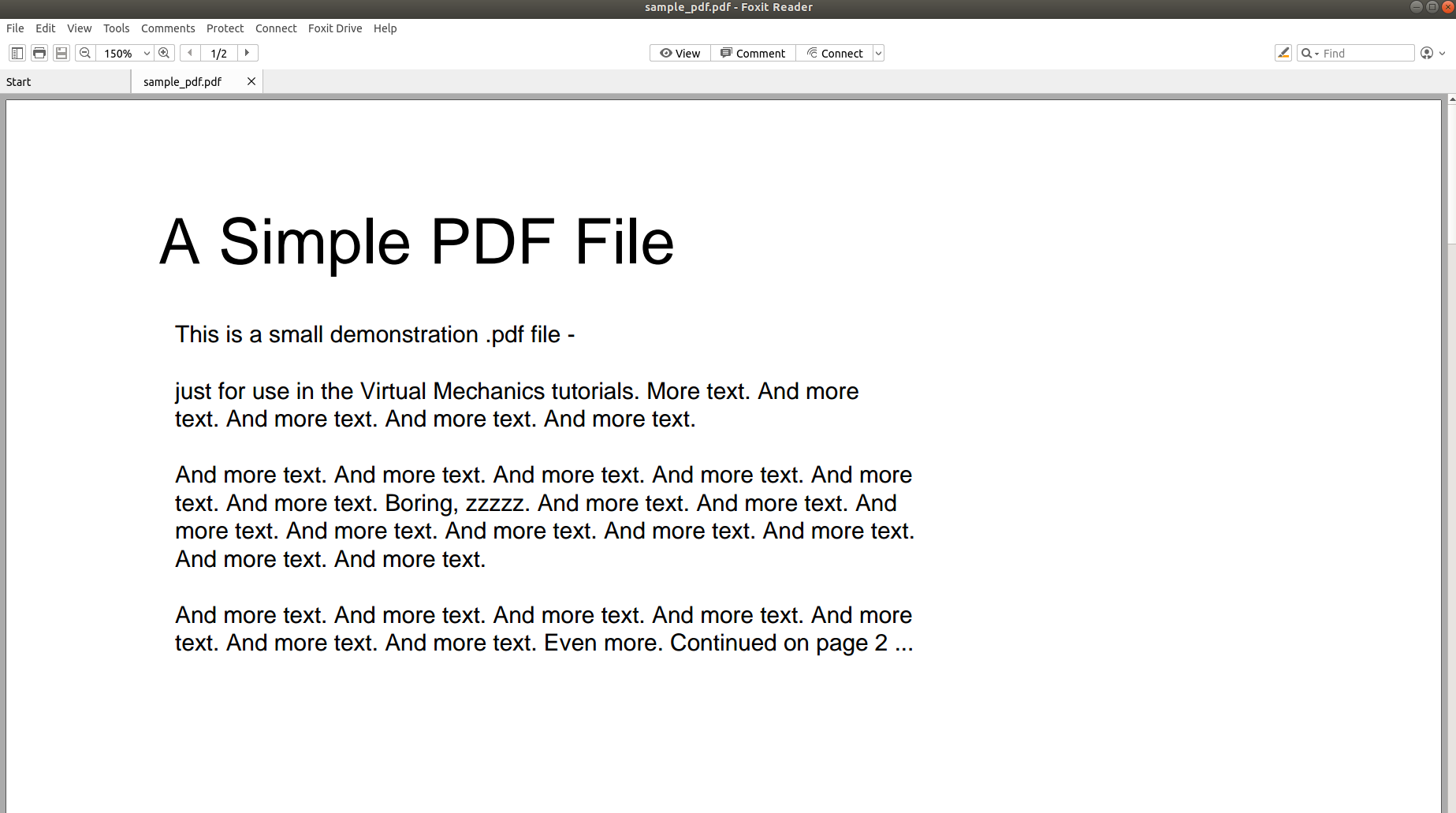
Bilden ovan visar skärmdumpen av ett PDF-dokument som öppnas med en PDF-läsare. Låt oss försöka öppna samma PDF-dokument med en textredigerare.
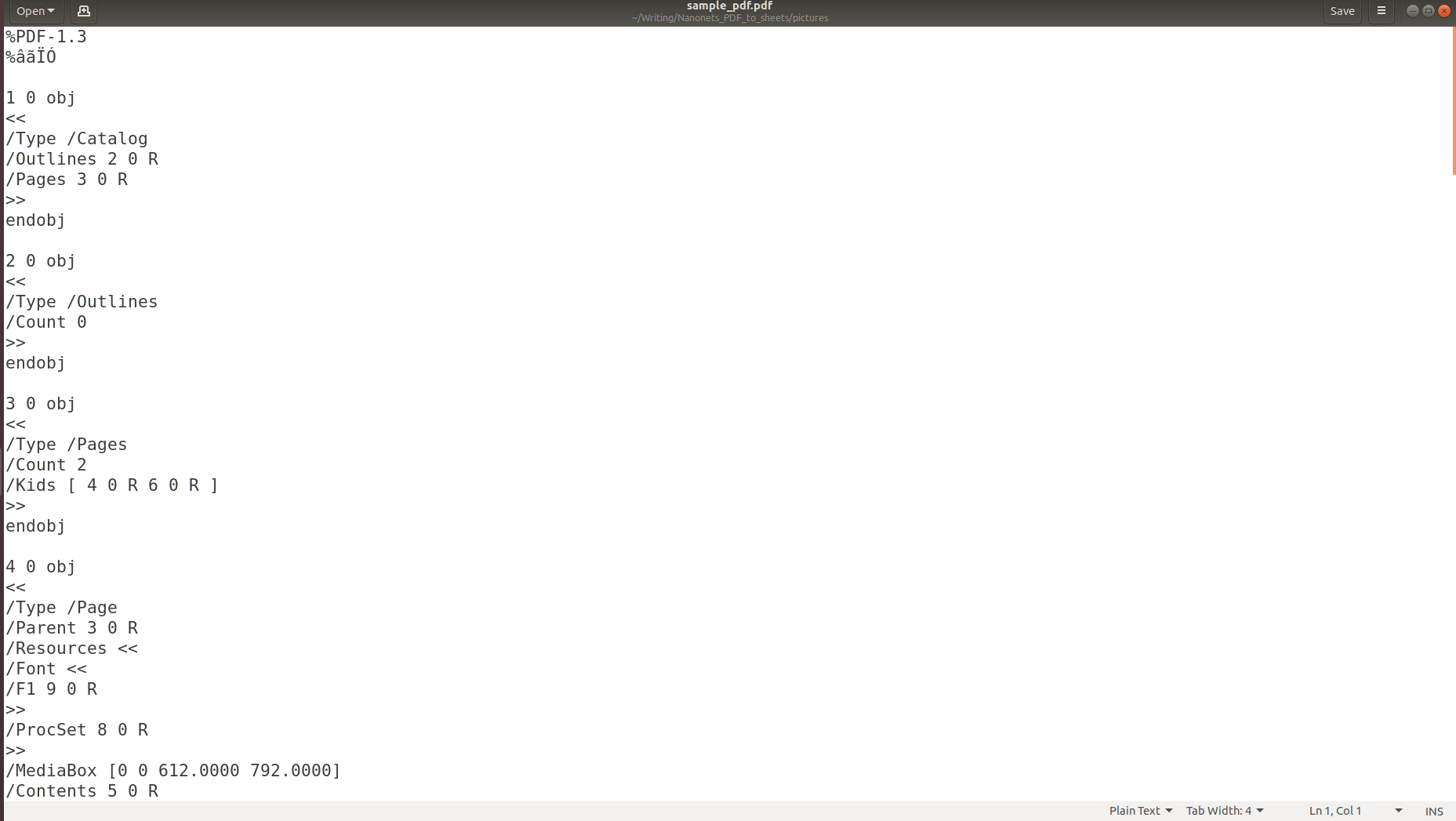
Ovanstående bilder gör det tydligt att när information lagras i en PDF, förloras dess ursprungliga struktur helt. Det beror på att PDF-formatet helt enkelt består av instruktioner om hur man skriver ut/ritar en sekvens av tecken på en sida.
Om du tycker att textextraktion är svårt är det ännu mer utmanande att extrahera data i tabeller på grund av de mycket varierande tabellformaten som används.
Förhoppningsvis är du övertygad om att konvertera ett PDF-dokument till ett Google Sheets-formulär är ingen promenad i parken. Nästa avsnitt talar om det tillvägagångssätt som de flesta moderna PDF-tolkare använder för att känna igen/tolka information från ett PDF-dokument.
Den moderna metoden för att analysera PDF-dokument
De flesta moderna PDF-tolkare använder flödet som beskrivs nedan för att analysera ostrukturerad data från PDF-dokument.
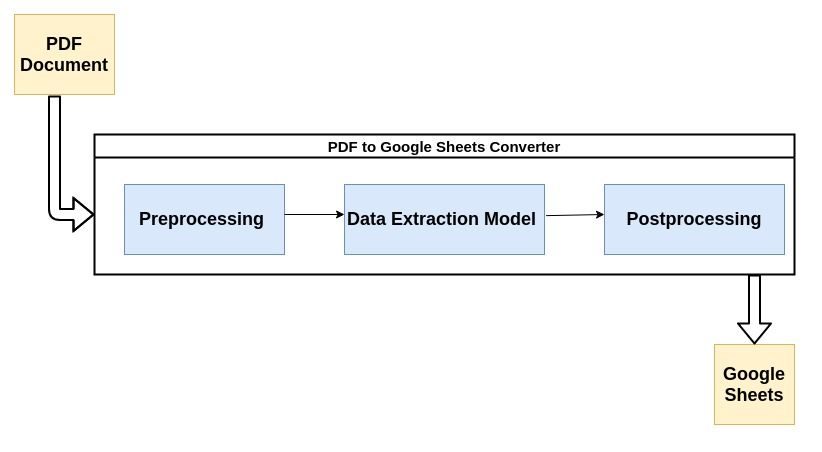
Låt oss kort ta en titt på varje steg i processen:
1. Förbearbetning eller datarensning:
Ju bättre din PDF ser ut, desto lättare blir det för din maskininlärningsmodell att extrahera eller fånga upp data från det. Till exempel, om PDF-dokumentet har skannats, är det skyldigt att innehålla några skanningsartefakter som kan påverka konverterarens prestanda.
Brusborttagning genom att använda lämpliga filter, binarisering, skevningskorrigering etc är några av de vanligaste förbearbetningsstegen. Följande Nanonets-inlägg Nanonets Tesseract Post innehåller några bra exempel på hur dokument kan förbehandlas innan Optical Character Recognition(OCR) körs på dem.
Det är här det mesta av magin händer. Dataextraktion utförs vanligtvis av en maskininlärningsmodell (ML). De flesta ML-modeller som används för dataextraktion från PDF-filer innehåller en kombination av optiska teckenigenkänningsverktyg, text- och mönsterigenkänningsverktyg etc.
I detta inläggs syfte kan vi behandla modellen som en svart låda som tar ditt PDF-dokument som indata och spottar ut den analyserade informationen. Dessutom, eftersom den använder ML i sin kärna, kan den omskolas med anpassade data för att passa ditt företags användningsfall.
3. Efterbearbetning:
I det här steget konverteras den extraherade datan till önskat format som CSV, XML, JSON etc. Dessutom läggs ytterligare användardefinierade regler till ovanpå de förutsägelser som AI gör. Detta kan inkludera regler för formatering av utdata, ytterligare begränsningar för information som extraheras etc.
Följande avsnitt tittar på några mätvärden som vi kan använda för att mäta prestandan för en PDF-tolkare.
Vill konvertera PDF filer till Google Sheets ? Kolla upp Nanonets kostnadsfria PDF till CSV-konverterare. Ta reda på hur du automatiserar hela din PDF-fil till Google Sheets-arbetsflödet med Nanonets.

Mätvärden för att mäta prestandan hos en PDF-konverterare
Eftersom de flesta PDF-konverterare kommer att användas för fakturahantering eller relaterade uppgifter, är noggrannheten och hastigheten för tabellextraktion från ett PDF-dokument en avgörande faktor för att bedöma PDF-konverterarens prestanda.
2. Flerspråkig förmåga:
De flesta stora företag är bundna att ta emot fakturor på ett antal olika språk. PDF-tolkaren bör antingen stödja flerspråkig analys direkt eller så bör den tillhandahålla ett alternativ där användare kan träna modellen med hjälp av anpassade data.
3. Integration med bokföringsprogramvara:
Den idealiska PDF-konverteraren bör vara en plug and play-modul som enkelt kan läggas till i din befintliga dokument arbetsflöde. Det bör stödja integration med populära bokföringsprogram som QuickBooks, Xero, Wave etc.
4. Enkelt och intuitivt:
Verktyget kommer troligen att användas av icke-tekniska användare. Det skulle vara fördelaktigt om den kan drivas med minimal teknisk kunskap.
Olika metoder för att konvertera PDF-filer till Google Sheets
1.Använda Google Dokument för att konvertera PDF till Google Sheets
Google Drive har inbyggd förmåga att känna igen tabeller och text i enkla PDF-dokument. Du behöver bara:
-
Ladda upp din PDF-fil till Google Drive
-
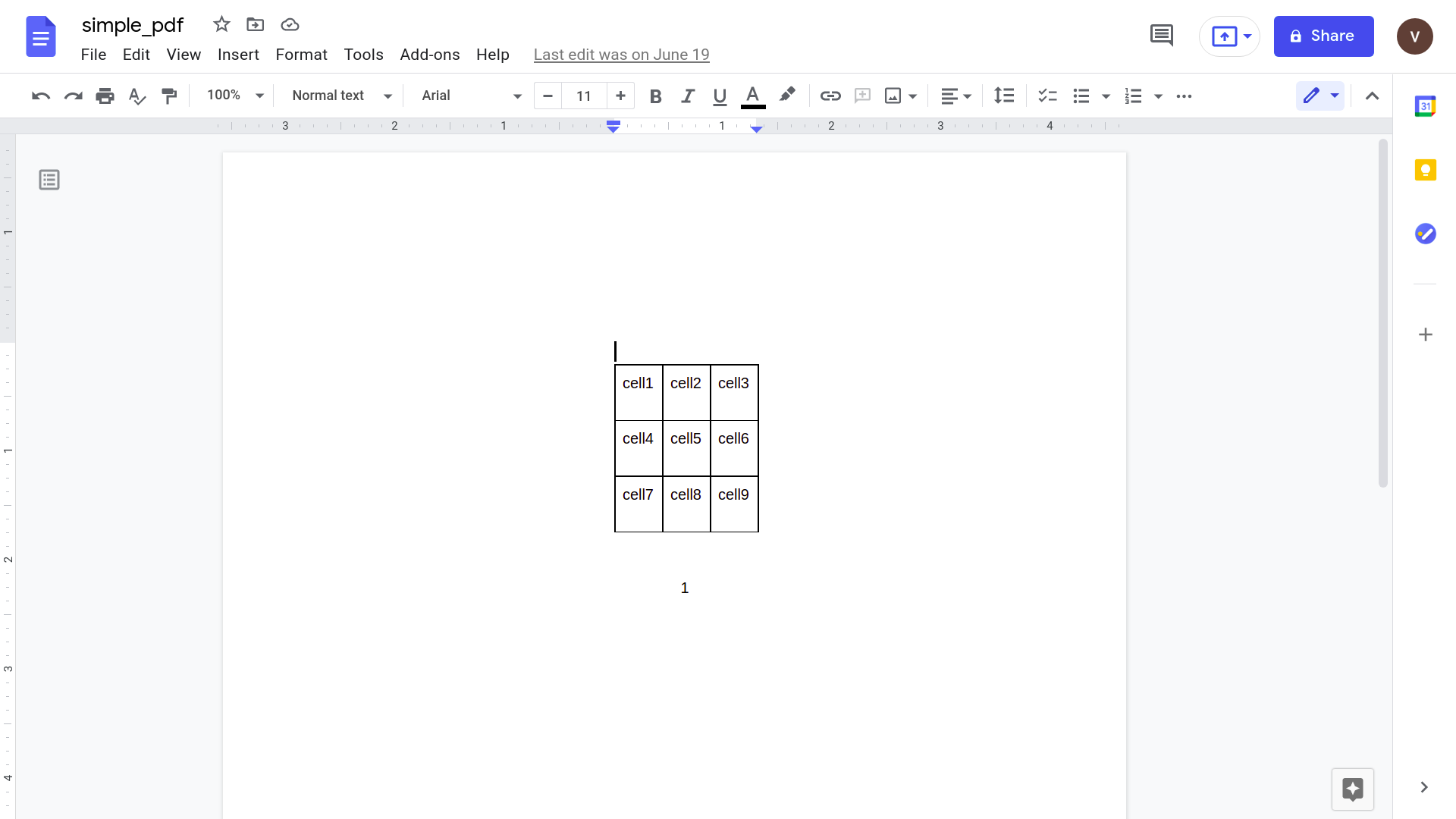
Klicka på "Öppna med Google Dokument"
-
Kopiera data du vill ha och klistra in i Google Kalkylark
Även om det verkar fungera bra, låt oss prova något lite mer praktiskt. Tänk på denna enkla faktura.
Om du öppnar detta med Google docs-applikationen får du följande resultat.
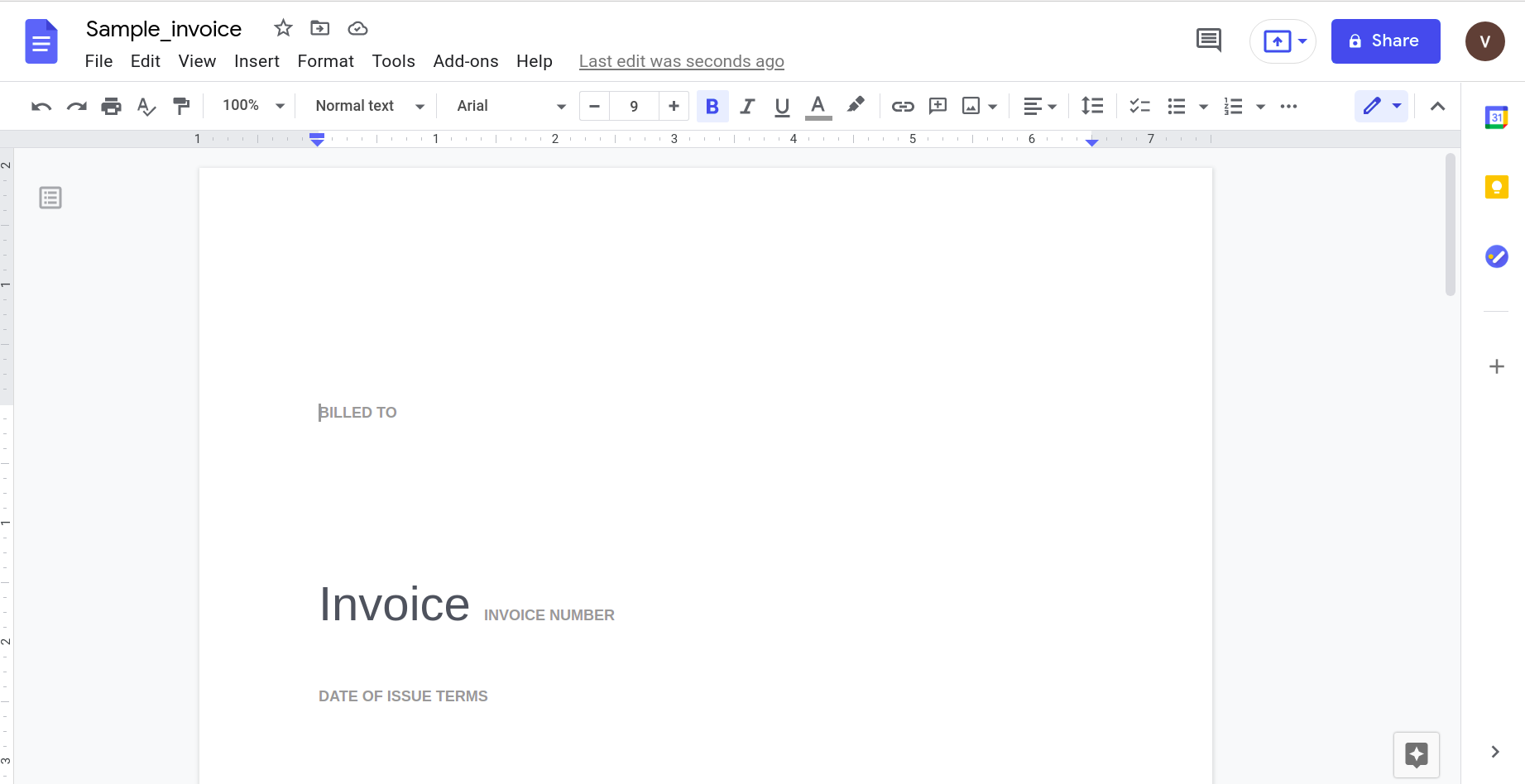
När dokumentets komplexitet ökar måste vi helt klart förlita oss på mer sofistikerade verktyg för att känna igen data.
2. Använda onlineverktyg:
Flera onlineverktyg som PDF-tabellextraktor, Online2PDF etc, integreras direkt med Google Drive och ger möjlighet att direkt konvertera PDF-dokument till Google Sheets.
Men när dessa verktyg testades med hjälp av provfaktura PDF-filen som visas ovan, upptäcktes inte tabellerna i de flesta fall.
Vill konvertera PDF filer till Google Sheets ? Kolla upp Nanonets kostnadsfria PDF till CSV-konverterare. Ta reda på hur du automatiserar hela din PDF-fil till Google Sheets-arbetsflödet med Nanonets som visas nedan.
Automatisera konverteringsprocessen för PDF till Google Sheets
Vi kan helt automatisera processen att tolka PDF:en och extrahera data till ett Google Sheets-formulär med hjälp av följande verktyg.
1. Använda Webhooks:
Webhooks är anpassade HTTP-förfrågningar. De utlöses vanligtvis på en händelse, dvs när en händelse inträffar skickar applikationen information till en fördefinierad URL.
Hur kan du använda detta för att automatisera ditt arbetsflöde? Låt oss överväga det typiska användningsfallet för fakturahantering. Du får ett antal fakturor från dina leverantörer och matar in dem i din PDF till Google Sheets-konverterare som finns i molnet. Hur vet man när modellen har bearbetat dokumenten?
Istället för att manuellt kontrollera om konverteringen har slutförts kan du helt enkelt använda en webhook som meddelar dig när data i PDF-filen har extraherats till ett Google Sheets-dokument.
2. Använda API:er
API står för Application Programming Interface. Genom att använda lämpliga API-anrop kan det visa sig vara lika enkelt att konvertera PDF-dokument till Google Sheets som att skriva följande kodrader:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Om ditt företag redan har konfigurerat integrationen med Webhooks kommer du att få ett meddelande när dina PDF-dokument har konverterats. Du kan sedan ladda ner Google Sheets-formuläret med hjälp av API:et som visas nedan.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF till Google Sheets med nanonnät
Nanonets PDF-parser gör analys och konvertering enkel och korrekt. PDF-tolken användes för att analysera en provfaktura. Det här avsnittet visar verktygets enkla användning och noggrannhet. Istället för att tala om hur bra det är, illustrerar följande bilder på ett träffande sätt poängen.
Bilden nedan är en skärmdump av provfakturan som matades till Nanonets PDF-parser.
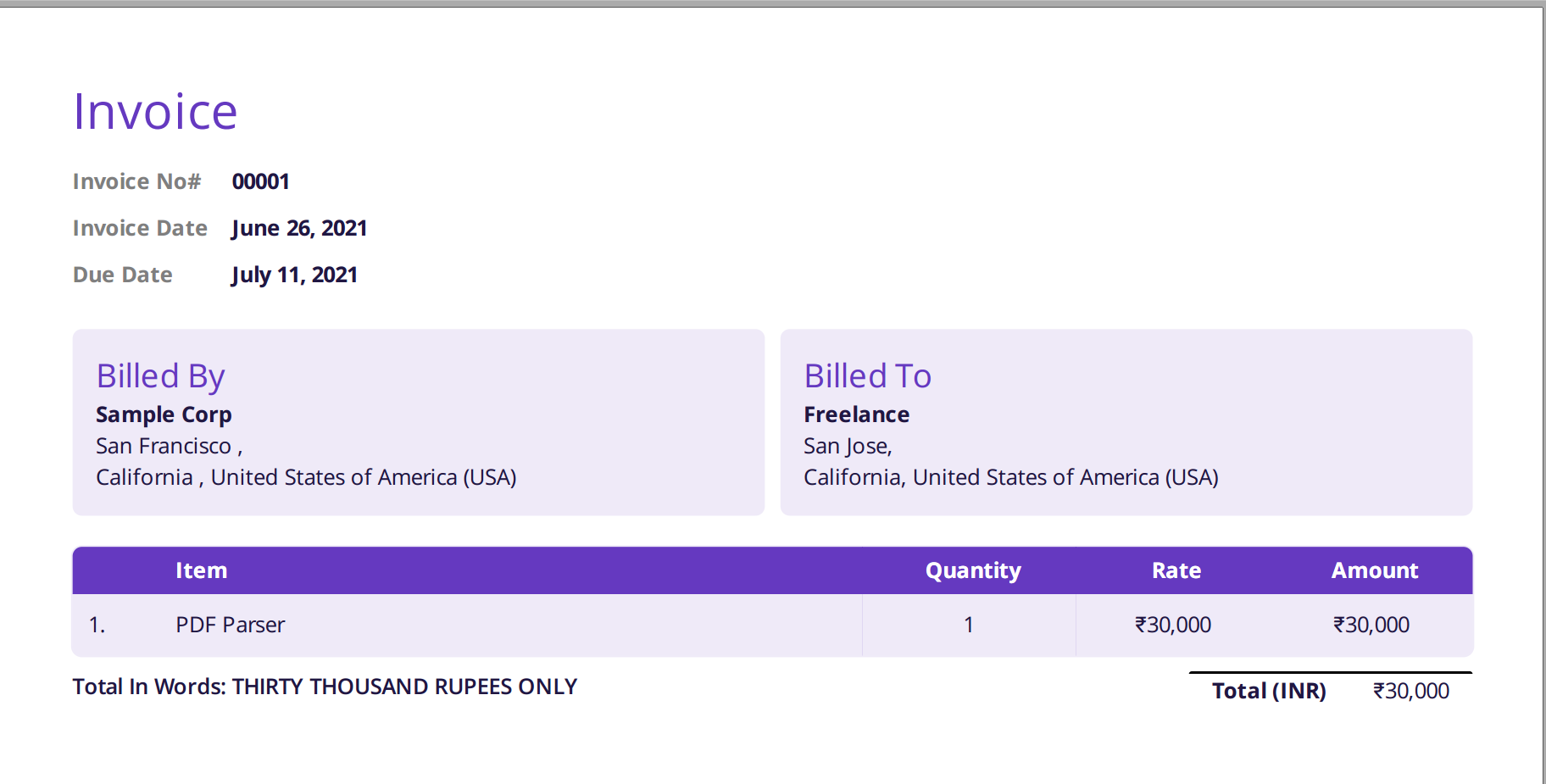
Navigera helt enkelt till Nanonets webbplats och ladda upp fakturan. Konverteringen tar bara några sekunder varefter den analyserade datan kan laddas ner i en mängd olika format som t.ex CSV, XLSX etc. (kolla in Nanonets' PDF till CSV-konverterare)
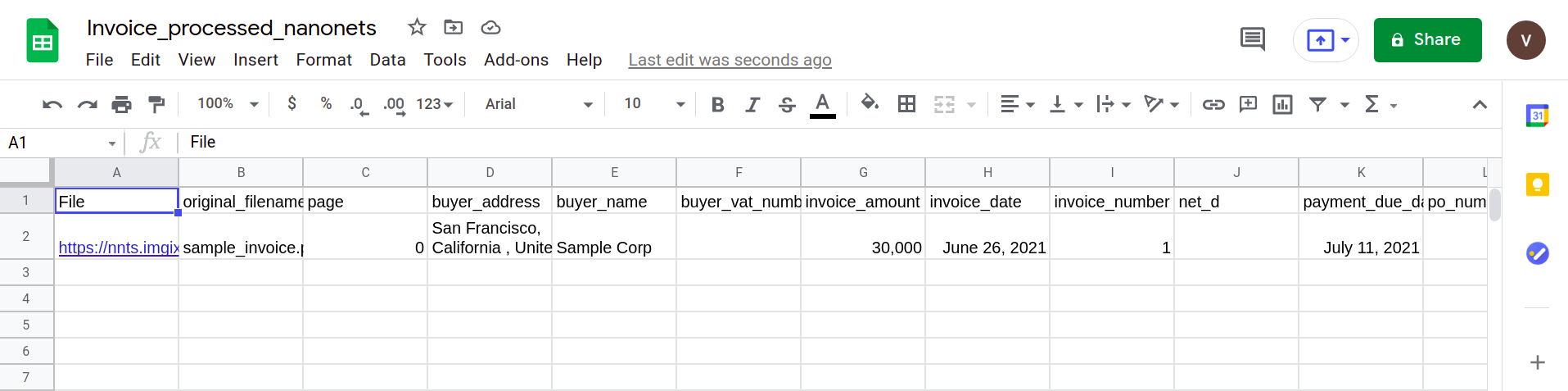
Nästa bild visar en skärmdump av CSV-filen som innehåller analyserad data från PDF-dokumentet.

Slutligen, för att konvertera CSV-filen till ett google sheets-formulär, är det bara en fråga om att ladda upp XLSX/CSV-filen till din Google Drive. Detta steg kan automatiseras genom att använda Google Drive API:er.
Följande avsnitt visar hur en enkel pipeline kan skapas genom att använda Nanonets PDF-parser.
Vill du extrahera information från PDF-dokument och konvertera/lägga till dem till ett Google Sheets-dokument? Kolla in Nanonets™ för att automatisera export av all information från alla PDF-dokument till Google Sheets!
Skapa en enkel pipeline
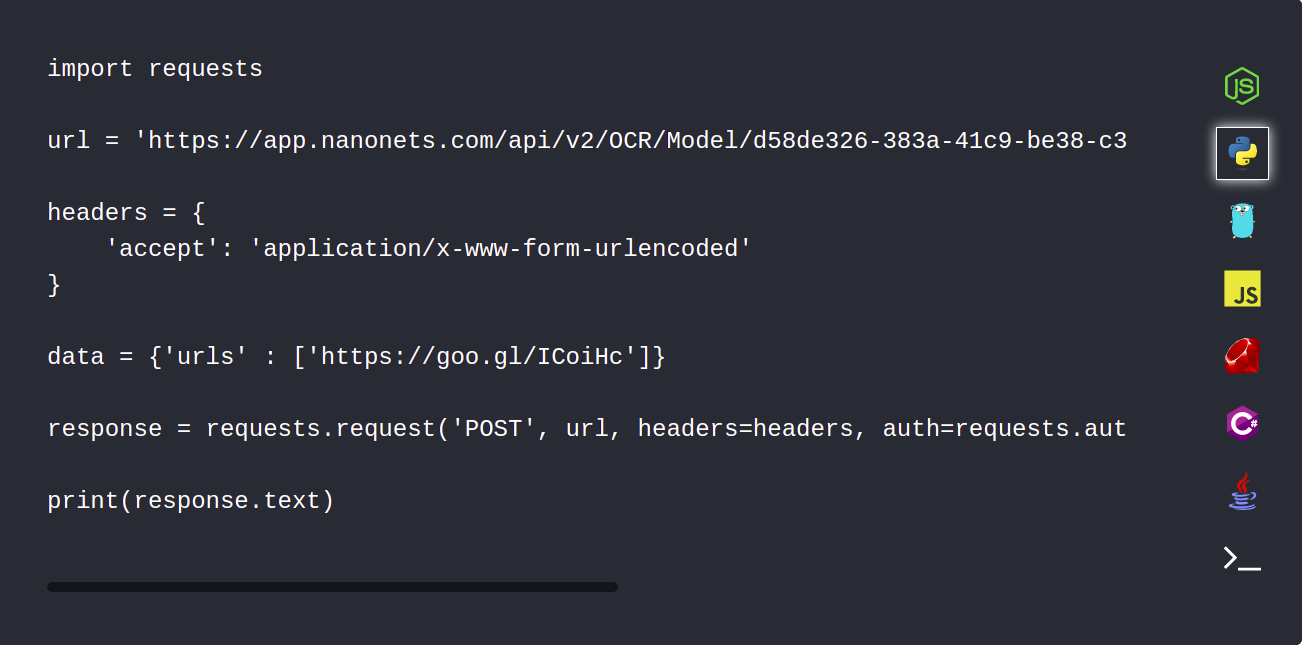
1. Ladda automatiskt upp dina PDF-dokument med hjälp av Nanonets API
Nanonets API låter dig automatiskt ladda upp dina dokument som måste tolkas. Följande kodsnutt visar hur detta kan göras med python.
2. Använd webhooks-integration för att få ett meddelande när analysen är klar
Webhooks kan konfigureras för att automatiskt meddela dig när dokumenten har analyserats.
3. Granska och ladda upp till Google Kalkylark
Ladda ner och granska CSV-filerna för att se till att allt är i sin ordning och ladda upp data till Google Sheets med Google Drive API.
The Nanonets Edge
Här är några funktioner i Nanonets PDF Parser som gör den till det perfekta verktyget för ditt företag.
1. Externa integrationer:
Nanonetsmodellen kan enkelt integreras med MySql, Quickbooks, Salesforce etc. Detta innebär att ditt nuvarande arbetsflöde förblir ostört och nanonetsomvandlaren kan enkelt kopplas in som en extra modul.
2. Hög noggrannhet och låga behandlingstider:
Nanonets PDF-parserverktyg har en noggrannhet på över 95%+ vilket är mycket högre jämfört med sina konkurrenter.
3. Coola efterbehandlingsfunktioner:
Antag att din databas har integrerats med nanonetsmodellen. Modellen fyller automatiskt i vissa fält (med data från din databas) baserat på data som extraherats från dokumentet. Till exempel:
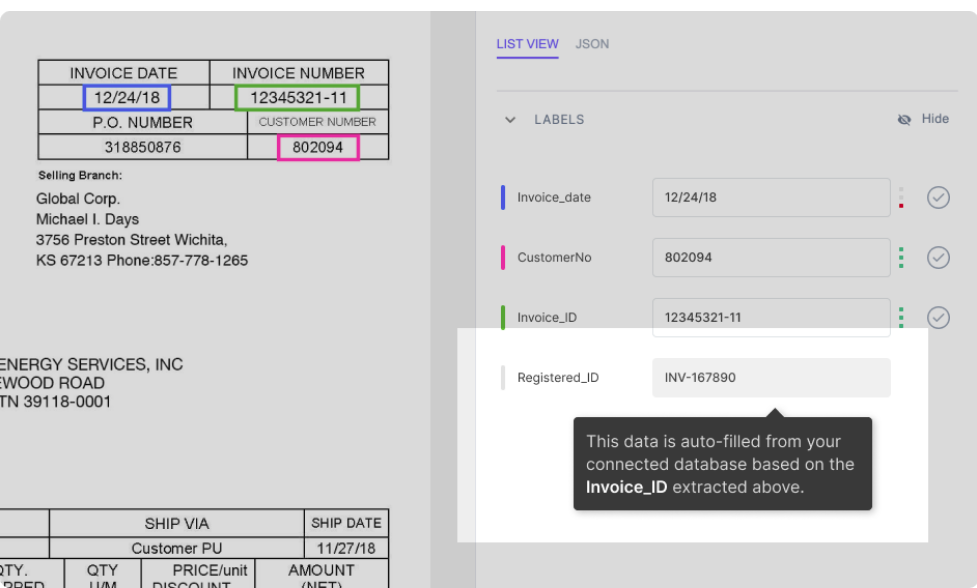
Som visas i figuren fylls fältet Registered_ID i automatiskt (genom en databassökning) baserat på Faktura_ID som extraheras från PDF:en.
4. Enkelt och intuitivt gränssnitt
Även om den här funktionen är underskattad, tyckte jag att UI och UX var perfekt. Hela processen med att registrera dig, ladda upp dokumentet och analysera data tog mindre än 5 minuter. Det är nästan lika med den tid det tar för min bärbara dator att starta upp!
5. Enorma kundbas
Om du fortfarande har reservationer för att använda Nanonets för att automatisera ditt arbetsflöde, ta bara en titt på några av företagen som använder deras tjänster.
- Deloitte
- Sherwin-Williams
- DoorDash
- P&G
Vill du extrahera information från PDF-dokument och konvertera/lägga till dem till ett Google Sheets-dokument? Kolla in Nanonets™ för att automatisera export av all information från alla PDF-dokument till Google Sheets!
Slutsats
I det här inlägget tog vi en titt på hur du kan automatisera ditt arbetsflöde genom att använda en PDF till Google Sheets-konverterare. Inledningsvis lärde vi oss om behovet av att konvertera PDF-dokument till Google Sheets, följt av utmaningarna under denna process. Vi dök sedan ner i metoderna som används av moderna tolkare för att analysera PDF-dokument och implementerade också några av de vanliga metoderna. Vi lärde oss också hur vi helt kan automatisera konverteringen med hjälp av externa integrationer som webhooks och API:er. Slutligen använde vi Nanonets-verktyget för att analysera en provfaktura, extrahera data till ett Google Sheets-formulär och även utforskade några av dess coola efterbearbetningsfunktioner.
Har du gett Nanonets-modellen ett försök? Om så är fallet, vänligen lämna en kommentar nedan angående din erfarenhet av verktyget. Om inte, fortsätt och prova det. Det kanske bara gör din dag!
- AI
- AI och maskininlärning
- ai konst
- ai art generator
- har robot
- artificiell intelligens
- artificiell intelligenscertifiering
- artificiell intelligens inom bankväsendet
- artificiell intelligens robot
- robotar med artificiell intelligens
- programvara för artificiell intelligens
- blockchain
- blockchain konferens ai
- coingenius
- konversationskonstnärlig intelligens
- kryptokonferens ai
- dalls
- djupt lärande
- du har google
- maskininlärning
- pdf till google sheets
- plato
- plato ai
- Platon Data Intelligence
- Platon spel
- PlatonData
- platogaming
- skala ai
- syntax
- zephyrnet