Amazon RedShift är ett snabbt, skalbart, säkert och fullt hanterat datalager som gör att du enkelt och kostnadseffektivt kan analysera all din data med standard SQL. Amazon Redshift Datadelning tillåter kunder att säkert dela live, transaktionsmässigt konsekvent data i ett Amazon Redshift-kluster med ett annat Amazon Redshift-kluster över konton och regioner utan att behöva kopiera eller flytta data från ett kluster till ett annat.
Amazon Redshift Data Sharing lanserades ursprungligen i mars 2021, och ytterligare stöd för datadelning över flera konton lades till augusti 2021. Det tvärregionala stödet blev allmänt tillgängligt i februari 2022. Detta ger full flexibilitet och smidighet för att dela data över Redshift-kluster i samma AWS-konto, olika konton eller olika regioner.
Amazon Redshift Data Sharing används för att i grunden omdefiniera Amazon Redshift-implementeringsarkitekturer till en nav-eker, datamesh-modell för att bättre möta prestanda-SLA:er, ge arbetsbelastningsisolering, utföra tvärgruppsanalyser, enkelt ta med nya användningsfall och viktigast av allt göra allt detta utan komplexiteten med dataförflyttning och datakopior. Några av de vanligaste frågorna som ställs under implementeringen av datadelning är "Hur stora ska mina konsumentkluster och producentkluster vara?" och "Hur får jag bästa prisprestanda för isolering av arbetsbelastning?". Eftersom arbetsbelastningsegenskaper som datastorlek, inmatningshastighet, frågemönster och underhållsaktiviteter kan påverka datadelningsprestanda, bör en kontinuerlig strategi för att dimensionera både konsument- och producentkluster för att maximera prestandan och minimera kostnaderna implementeras. I det här inlägget tillhandahåller vi ett steg-för-steg tillvägagångssätt för att hjälpa dig att bestämma dina producent- och konsumentklusterstorlekar för bästa prisprestanda baserat på din specifika arbetsbelastning.
Generisk vägledning för konsumentstorlekar
Följande steg visar den generiska strategin för att dimensionera dina producent- och konsumentkluster. Du kan använda den som utgångspunkt och modifiera den för att passa ditt specifika användningsfall.
Storlek på ditt producentkluster
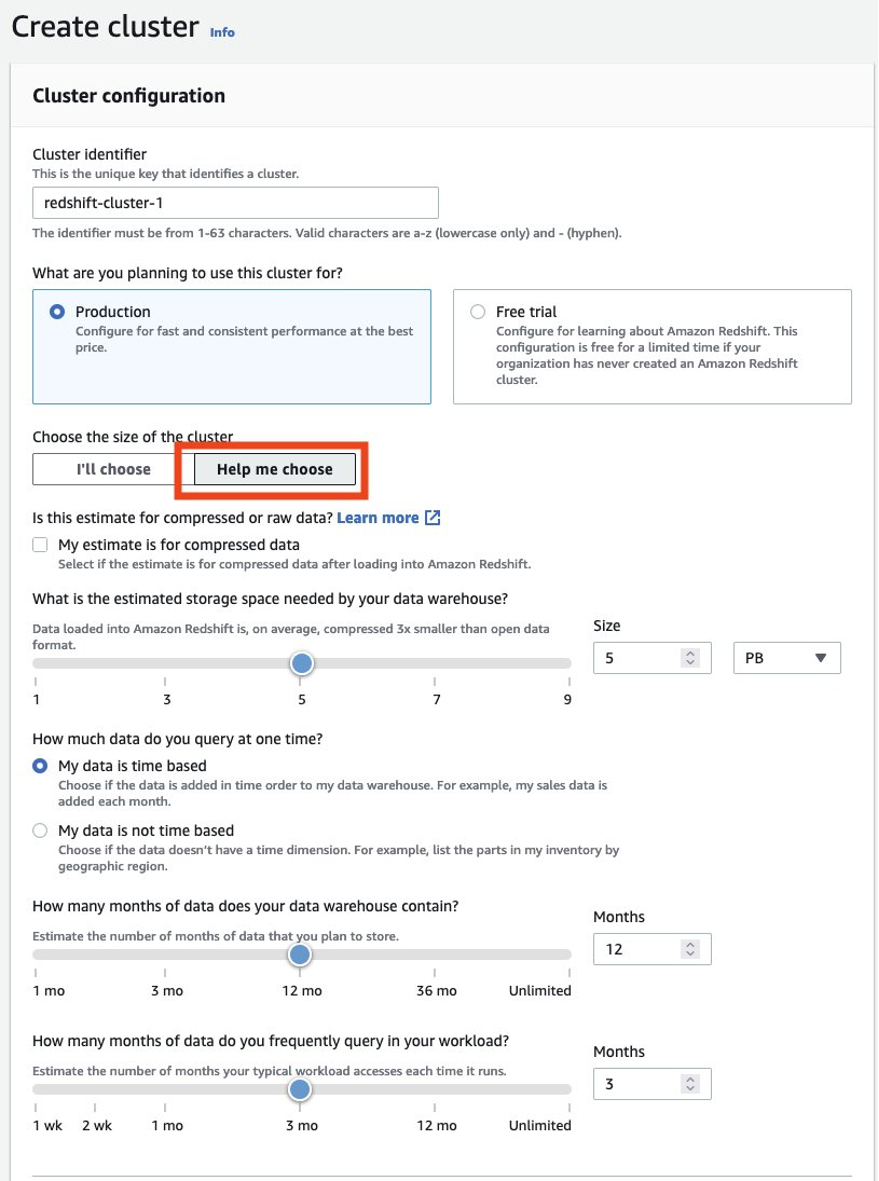
Du bör alltid se till att du har rätt storlek på ditt producentkluster för att få den prestanda du behöver för att uppfylla din SLA. Du kan använda storlekskalkylatorn från Amazon Redshift-konsolen för att få en rekommendation för producentklustret baserat på storleken på dina data och frågeegenskaper. Leta efter Hjälp mig att välja på konsolen i AWS-regioner som stöder RA3-nodtyper för att använda den här storlekskalkylatorn. Observera att detta bara är en första rekommendation för att komma igång, och du bör testa att köra hela din arbetsbelastning på det ursprungliga storleksklustret och elastiskt ändra storleken på klustret upp och ner i enlighet med detta för att få bästa prisprestanda.
Storlek och inställning av initialt konsumentkluster
Du bör alltid dimensionera ditt konsumentkluster baserat på dina datorbehov. Ett sätt att komma igång är att följa den allmänna klusterstorleksguiden som liknar producentklustret ovan.
Ställ in Amazon Redshift-datadelning
Ställ in datadelning från producent till konsument när du har konfigurerat både producent- och konsumentkluster. Hänvisa till detta inlägg för vägledning om hur du ställer in datadelning.
Testa arbetsbelastningen endast för konsumenter på det ursprungliga konsumentklustret
Testa arbetsbelastningen endast för konsumenter på det nya initiala konsumentklustret. Detta kan göras genom att peka konsumentapplikationer, till exempel ETL-verktyg, BI-applikationer och SQL-klienter, till det nya konsumentklustret och köra om arbetsbelastningen för att utvärdera prestandan mot dina krav.
Testa endast arbetsbelastning för konsumenter på olika konsumentklusterkonfigurationer
Om konsumentklustret i den ursprungliga storleken uppfyller eller överstiger dina prestandakrav för arbetsbelastning, kan du antingen fortsätta att använda den här klusterkonfigurationen eller så kan du testa på mindre konfigurationer för att se om du kan minska kostnaderna ytterligare och ändå få den prestanda du behöver.
Å andra sidan, om konsumentklustret i den ursprungliga storleken inte uppfyller dina krav på prestanda för arbetsbelastning, kan du testa större konfigurationer ytterligare för att få den konfiguration som uppfyller din SLA.
Som en tumregel, storleksanpassa konsumentklustret med 2x den ursprungliga klusterkonfigurationen stegvis tills det uppfyller dina arbetsbelastningskrav.
När du har planerat vilken konfiguration du vill testa, använd elastisk storleksändring för att ändra storlek på det ursprungliga klustret till målklusterkonfigurationen. När den elastiska storleksändringen är klar, utför samma arbetsbelastningstest och utvärdera prestandan mot din SLA. Välj den konfiguration som uppfyller ditt prisprestandamål.
Testa endast arbetsbelastning för producent på olika producentklusterkonfigurationer
När du väl flyttar din arbetsbörda för konsumenter till konsumentklustret med optimal prisprestanda, kan det finnas en möjlighet att minska beräkningsresursen hos producenten för att spara på kostnaderna.
För att uppnå detta kan du köra endast producentens arbetsbelastning igen på 1/2x av den ursprungliga producentens storlek och utvärdera arbetsbelastningens prestanda. Ändra storlek på klustret upp och ner beroende på resultatet, och sedan väljer du den lägsta producentkonfigurationen som uppfyller dina krav på prestanda för arbetsbelastning.
Omvärdera efter en full arbetsbelastning över tid
Allt eftersom Amazon Redshift fortsätter att utvecklas, och det finns ständiga förbättringar av prestanda och skalbarhet, kommer prestanda för datadelning att fortsätta att förbättras. Dessutom kan många variabler påverka prestandan för datadelningsfrågor. Följande är bara några exempel:
- Intagshastighet och mängd data ändras
- Frågemönster och egenskap
- Arbetsbelastningen förändras
- samtidighet
- Underhållsaktiviteter, till exempel vakuum, analys och ATO
Det är därför du ibland måste omvärdera storleken på producent- och konsumentklustret med hjälp av strategin ovan, särskilt efter en full implementering av arbetsbelastningen, för att få den nya bästa prisprestandan från klustrets konfiguration.
Automatiserade dimensioneringslösningar
Om din miljö involverade mer komplex arkitektur, till exempel med flera verktyg eller applikationer (BI, intag eller streaming, ETL, datavetenskap), kanske det inte är möjligt att använda den manuella metoden från den allmänna vägledningen ovan. Istället kan du använda lösningarna i det här avsnittet för att automatiskt spela upp arbetsbelastningen från ditt produktionskluster på testkonsument- och producentklustren för att utvärdera prestandan.
Enkelt Replay-verktyg kommer att utnyttjas som den automatiserade lösningen för att vägleda dig genom processen för att få rätt producent- och konsumentklusterstorlek för bästa prisprestanda.
Simple Replay är ett verktyg för att genomföra en vad-om-analys och utvärdera hur din arbetsbelastning presterar i olika scenarier. Du kan till exempel använda verktyget för att jämföra din faktiska arbetsbelastning på en ny instanstyp som RA3, utvärdera en ny funktion eller utvärdera olika klusterkonfigurationer. Det inkluderar också förbättrat stöd för att spela upp dataintag och exportpipelines med COPY- och UNLOAD-satser. För att komma igång och spela om dina arbetsbelastningar, ladda ner verktyget från Amazon Redshift GitHub-förvar.
Här går vi igenom stegen för att extrahera dina arbetsbelastningsloggar från källproduktionsklustret och spela upp dem i en isolerad miljö. Detta låter dig utföra en direkt jämförelse mellan dessa Amazon Redshift-kluster sömlöst och välja den klusterkonfiguration som bäst uppfyller ditt prisprestandamål.
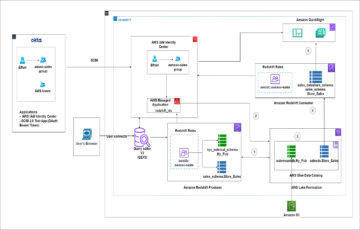
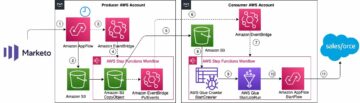
Följande diagram visar lösningsarkitekturen.
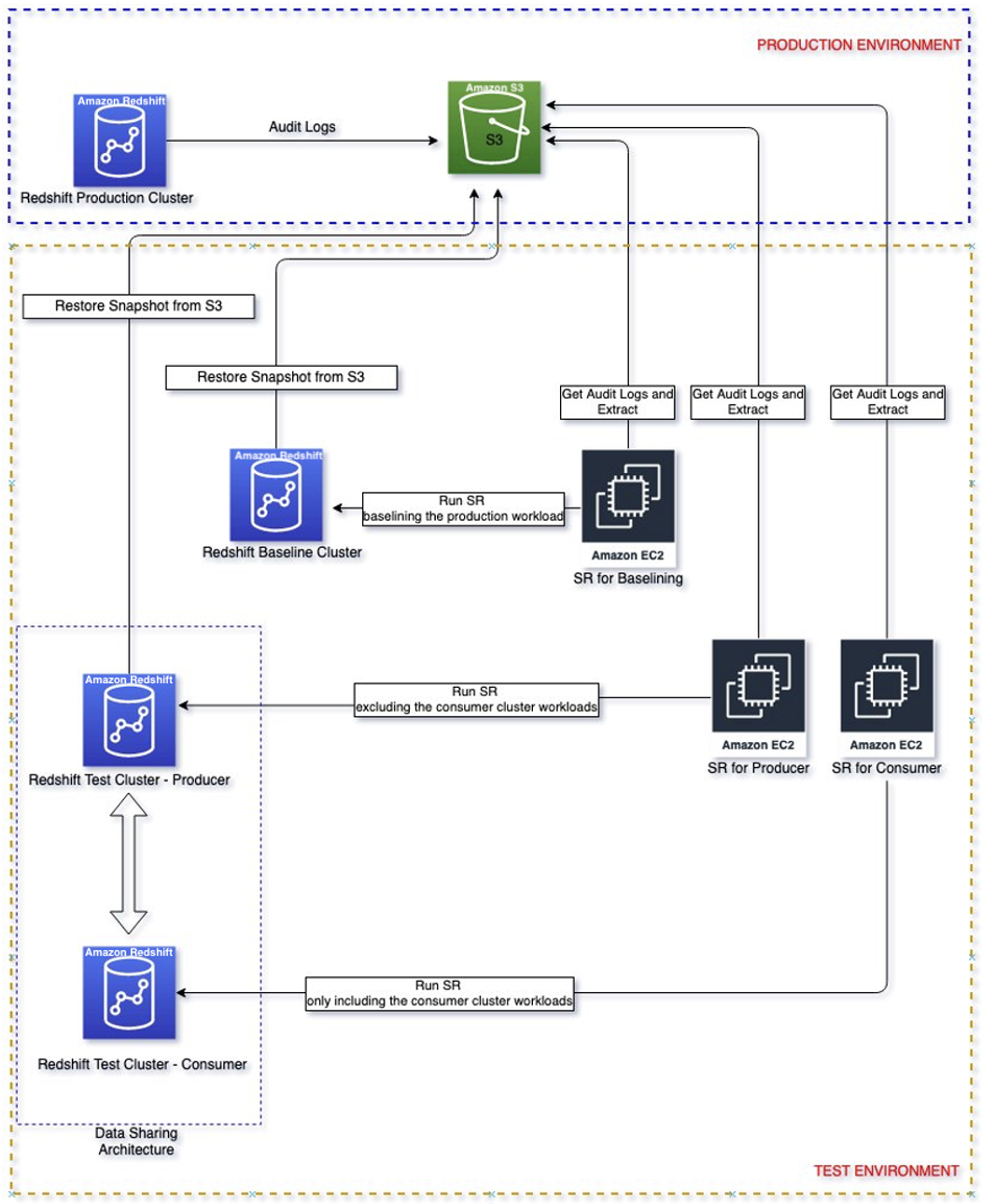
Lösning genomgång
Följ dessa steg för att gå igenom lösningen för att dimensionera dina konsument- och producentkluster.
Storlek på ditt produktionskluster
Du bör alltid se till att dimensionera ditt befintliga produktionskluster korrekt för att få den prestanda du behöver för att möta dina arbetsbelastningskrav. Du kan använda storlekskalkylatorn från Amazon Redshift-konsolen för att få en rekommendation om produktionsklustret baserat på storleken på dina data och frågeegenskaper. Leta efter Hjälp mig att välja på konsolen i AWS-regioner som stöder RA3-nodtyper för att använda den här storlekskalkylatorn. Observera att detta bara är en första rekommendation för att komma igång. Du bör testa att köra hela din arbetsbelastning på det ursprungliga storleksklustret och elastiskt ändra storleken på klustret upp och ner i enlighet med detta för att få bästa prisprestanda.
Identifiera arbetsbelastningen som ska isoleras
Du kan ha olika arbetsbelastningar på ditt ursprungliga kluster, men det första steget är att identifiera den mest kritiska arbetsbelastningen för verksamheten som vi vill isolera. Detta för att vi vill försäkra oss om att den nya arkitekturen kan uppfylla dina krav på arbetsbelastning. Detta inlägg är en bra referens till ett användningsfall för isolering av arbetsbelastning för datadelning som kan hjälpa dig att bestämma vilken arbetsbelastning som kan isoleras.
Ställ in enkel repris
När du väl känner till din kritiska arbetsbelastning måste du aktivera revisionsloggning i ditt produktionskluster där den kritiska arbetsbelastningen som identifierats ovan körs för att fånga frågeaktiviteter och lagra i Amazon Simple Storage Service (Amazon S3). Observera att det kan ta upp till tre timmar för granskningsloggarna att levereras till Amazon S3. När granskningsloggen är tillgänglig, fortsätt till ställ in Enkel Replay och då extrahera den kritiska arbetsbelastningen från revisionsloggen. Observera att start_time och end_time kan användas som parametrar för att filtrera bort den kritiska arbetsbelastningen om dessa arbetsbelastningar körs under vissa tidsperioder, till exempel 9:11 till XNUMX:XNUMX. Annars kommer det att extrahera alla loggade aktiviteter.
Baslinje arbetsbelastning
Skapa ett baslinjekluster med samma konfiguration som producentklustret genom att återställa från produktionsögonblicksbilden. Syftet med att börja med samma konfiguration är att basera prestandan med en isolerad miljö.
När baslinjeklustret är tillgängligt, spela den extraherade arbetsbelastningen i baslinjeklustret. Utdata från denna repris kommer att vara baslinjen som används för att jämföra med efterföljande repriser på olika konsumentkonfigurationer.
Ställ in första producent- och konsumenttestkluster
Skapa ett producentkluster med samma produktionsklusterkonfiguration genom att återställa från produktionsögonblicksbilden. Skapa ett konsumentkluster med den rekommenderade initiala konsumentstorleken från den tidigare vägledningen. Dessutom ställ in datadelning mellan producent och konsument.
Spela om arbetsbelastningen på den ursprungliga producenten och konsumenten
Spela endast producentens arbetsbelastning på det ursprungliga producentklustret. Detta kan uppnås med filterparametern "Uteslut" för att utesluta konsumentfrågor, till exempel användaren som kör konsumentfrågor.
Spela arbetsbelastningen endast för konsumenten på konsumentklustret i den ursprungliga storleken. Detta kan uppnås med filterparametern "Inkludera" för att utesluta konsumentfrågor, till exempel användaren som kör konsumentfrågor.
Utvärdera prestandan för dessa repriser mot prestandakraven för baslinjen och arbetsbelastningen.
Spela om konsumentens arbetsbelastning på olika konfigurationer
Om konsumentklustret i den ursprungliga storleken uppfyller eller överträffar prestandakraven för din arbetsbelastning kan du antingen använda den här klusterkonfigurationen eller så kan du följa dessa steg för att testa på mindre konfigurationer för att se om du kan minska kostnaderna ytterligare och ändå få den prestanda du behöver.
Jämför de första resultaten för konsumenternas prestanda mot dina krav på arbetsbelastning:
- Om resultatet överstiger prestandakraven för din arbetsbelastning kan du minska storleken på konsumentklustret stegvis, börja med 1/2x, prova omspelningen igen och utvärdera prestandan och sedan ändra storleken uppåt eller nedåt baserat på resultatet tills det uppfyller din arbetsbelastning krav. Syftet är att få en sweet spot där du är bekväm med prestandakraven och får lägsta möjliga pris.
- Om resultatet inte uppfyller dina krav på prestanda för arbetsbelastning kan du öka storleken på klustret stegvis, börja med 2x den ursprungliga storleken, prova omspelningen igen och utvärdera prestandan tills den uppfyller dina krav på prestanda för arbetsbelastningen.
Spela upp producentens arbetsbelastning på olika konfigurationer
När du delar upp dina arbetsbelastningar till konsumentkluster bör belastningen på producentklustret minskas och du bör utvärdera ditt producentklusters arbetsbelastningsprestanda för att söka möjligheten att minska för att spara på kostnaderna.
Stegen liknar konsumentreplay. Elastiskt ändra storlek på producentklustret stegvis med början med 1/2x den ursprungliga storleken, spela upp endast producentens arbetsbelastning och utvärdera prestandan, och ändra sedan storleken ytterligare upp eller ner tills det uppfyller dina krav för arbetsbelastning. Syftet är att få en sweet spot där du är bekväm med arbetsbelastningens prestandakrav och får lägsta möjliga pris. När du har den önskade producentklusterkonfigurationen, försök igen att spela upp konsumentarbetsbelastningar på konsumentklustret för att se till att prestandan inte påverkades av ändringar i producentklusterkonfigurationen. Slutligen bör du spela upp både producent- och konsumentarbetsbelastningar samtidigt för att säkerställa att prestandan uppnås i ett scenario med full arbetsbelastning.
Omvärdera efter en full arbetsbelastning över tid
I likhet med den allmänna vägledningen bör du vid enstaka tillfällen omvärdera storleken på producent- och konsumentklustren med hjälp av den tidigare strategin, särskilt efter full arbetsbelastning för att få den nya bästa prisprestandan från ditt klusters konfiguration.
Städa upp
Att köra dessa storlekstester i ditt AWS-konto kan ha vissa kostnadskonsekvenser eftersom det tillhandahåller nya Amazon Redshift-kluster, som kan debiteras som on-demand-instanser om du inte har reserverade instanser. När du slutför dina utvärderingar rekommenderar vi att du tar bort Amazon Redshift-klustren för att spara på kostnaderna. Vi rekommenderar också att du pausar dina kluster när de inte används.
Tillämpa Amazon Redshift och bästa praxis för datadelning
Korrekt storlek på både dina producent- och konsumentkluster kommer att ge dig en bra start för att få bästa prisprestanda från din Amazon Redshift-distribution. Men storleken är inte den enda faktorn som kan maximera din prestation. I det här fallet är det lika viktigt att förstå och följa bästa praxis.
Allmänt Amazon Redshifts bästa praxis för prestandajustering är tillämpliga på distribution av datadelning. Se till att din distribution följer dessa bästa praxis.
Det finns många specifika bästa praxis för datadelning som du bör följa för att se till att du maximerar prestandan. Hänvisa till detta inlägg för mer detaljer.
Sammanfattning
Det finns ingen rekommendation som passar alla för producent- och konsumentklusterstorlekar. Det varierar beroende på arbetsbelastning och din prestations-SLA. Syftet med det här inlägget är att ge dig vägledning för hur du kan utvärdera din specifika arbetsbelastningsprestanda för datadelning för att bestämma både konsument- och producentklusterstorlekar för att få bästa prisprestanda. Överväg att testa dina arbetsbelastningar på producent och konsument med enkel uppspelning innan du använder den i produktionen för att få bästa prisprestanda.
Om författarna
 BP Yau är Sr Product Manager på AWS. Han brinner för att hjälpa kunder att utforma big data-lösningar för att bearbeta data i stor skala. Innan AWS hjälpte han Amazon.com Supply Chain Optimization Technologies att migrera sitt Oracle-datalager till Amazon Redshift och bygga sin nästa generations stora dataanalysplattform med hjälp av AWS-teknik.
BP Yau är Sr Product Manager på AWS. Han brinner för att hjälpa kunder att utforma big data-lösningar för att bearbeta data i stor skala. Innan AWS hjälpte han Amazon.com Supply Chain Optimization Technologies att migrera sitt Oracle-datalager till Amazon Redshift och bygga sin nästa generations stora dataanalysplattform med hjälp av AWS-teknik.
 Sidhanth Muralidhar är en Principal Technical Account Manager på AWS. Han arbetar med stora företagskunder som kör sina arbetsuppgifter på AWS. Han brinner för att arbeta med kunder och hjälpa dem att utforma arbetsbelastningar för kostnader, tillförlitlighet, prestanda och operativ excellens i stor skala i deras molnresa. Han har också ett stort intresse för Data Analytics.
Sidhanth Muralidhar är en Principal Technical Account Manager på AWS. Han arbetar med stora företagskunder som kör sina arbetsuppgifter på AWS. Han brinner för att arbeta med kunder och hjälpa dem att utforma arbetsbelastningar för kostnader, tillförlitlighet, prestanda och operativ excellens i stor skala i deras molnresa. Han har också ett stort intresse för Data Analytics.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/how-to-get-best-price-performance-from-your-amazon-redshift-data-sharing-deployment/
- 100
- a
- Om oss
- ovan
- i enlighet med detta
- Konto
- konton
- Uppnå
- uppnås
- tvärs
- aktiviteter
- lagt till
- Anta
- Efter
- mot
- Alla
- tillåter
- alltid
- amason
- Amazon.com
- mängd
- analys
- analytics
- analysera
- och
- Annan
- tillämplig
- tillämpningar
- tillvägagångssätt
- arkitektur
- revision
- Automatiserad
- automatiskt
- tillgänglig
- AWS
- baserat
- Baslinje
- därför att
- innan
- riktmärke
- BÄST
- bästa praxis
- Bättre
- mellan
- Stor
- Stora data
- SLUTRESULTAT
- företag
- fånga
- Vid
- fall
- vissa
- kedja
- Förändringar
- karakteristiska
- egenskaper
- laddad
- klienter
- cloud
- kluster
- COM
- bekväm
- Gemensam
- jämföra
- jämförelse
- fullborda
- Avslutade
- komplex
- Komplexiteten
- Compute
- ledande
- konfiguration
- Tänk
- konsekvent
- Konsol
- Konsumenten
- fortsätta
- fortsätter
- kontinuerlig
- Pris
- Kostar
- kunde
- skapa
- kritisk
- Kunder
- datum
- Data Analytics
- datavetenskap
- datadeling
- levereras
- beror
- utplacering
- detaljer
- Bestämma
- olika
- rikta
- inte
- ner
- ladda ner
- under
- lätt
- antingen
- möjliggör
- förbättrad
- Företag
- Miljö
- lika
- speciellt
- Eter (ETH)
- utvärdera
- utvärderingar
- utvecklas
- exempel
- exempel
- överstiger
- Excellence
- befintliga
- export
- extrahera
- misslyckas
- SNABB
- möjlig
- Leverans
- filtrera
- Slutligen
- Förnamn
- Flexibilitet
- följer
- efter
- följer
- från
- full
- fundamentalt
- ytterligare
- Vidare
- Få
- allmänhet
- generering
- skaffa sig
- få
- GitHub
- Ge
- Go
- god
- styra
- hjälpa
- hjälpte
- hjälpa
- ÖPPETTIDER
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- identifierade
- identifiera
- Inverkan
- påverkade
- genomföras
- implikationer
- med Esport
- förbättring
- förbättra
- in
- innefattar
- Öka
- inledande
- initialt
- exempel
- istället
- intresse
- involverade
- isolerat
- isolering
- IT
- resa
- Angelägen
- Vet
- Large
- större
- lanserades
- Lets
- Hävstång
- lever
- läsa in
- se
- underhåll
- göra
- chef
- manuell
- Maximera
- Möt
- möter
- metod
- kanske
- migrera
- minsta
- modell
- mer
- mest
- flytta
- rörelse
- multipel
- Behöver
- behöver
- behov
- Nya
- Nästa
- nod
- talrik
- tillfälle
- Ombord
- ONE
- operativa
- Möjlighet
- optimering
- optimal
- orakel
- ursprungliga
- Övriga
- annat
- parameter
- parametrar
- brinner
- Mönster
- utföra
- prestanda
- utför
- perioder
- Planen
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- möjlig
- Inlägg
- praxis
- föregående
- pris
- Principal
- process
- producent
- Produkt
- produktchef
- Produktion
- ordentligt
- ge
- ger
- Syftet
- frågor
- Betygsätta
- rekommenderar
- Rekommendation
- rekommenderas
- minska
- Minskad
- regioner
- meddelanden
- tillförlitlighet
- Krav
- reserverad
- resurs
- återställa
- resultera
- Resultat
- Regel
- Körning
- rinnande
- Samma
- Save
- skalbarhet
- skalbar
- Skala
- scenarier
- Vetenskap
- sömlöst
- §
- säkra
- säkert
- Seek
- service
- inställning
- Dela
- delning
- skall
- show
- Visar
- liknande
- Enkelt
- Storlek
- storlekar
- mindre
- Snapshot
- lösning
- Lösningar
- några
- Källa
- specifik
- delas
- Spot
- standard
- starta
- igång
- Starta
- uttalanden
- Steg
- Steg
- Fortfarande
- förvaring
- lagra
- Strategi
- streaming
- senare
- leverera
- leveranskedjan
- Supply Chain Optimering
- stödja
- söt
- Ta
- Målet
- Teknisk
- Tekniken
- testa
- Testning
- tester
- Smakämnen
- källan
- deras
- tre
- Genom
- tid
- till
- verktyg
- verktyg
- typer
- förståelse
- användning
- användningsfall
- Användare
- Vakuum
- Vad
- som
- VEM
- kommer
- utan
- arbetssätt
- fungerar
- Din
- zephyrnet