Detta är ett gästinlägg skrivet tillsammans med Raghu Boppanna från Vanguard.
At Förtrupp, Enterprise Advice förbättrar investerarnas resultat genom digital tillgång till överlägsen, personlig och prisvärd finansiell rådgivning. De gjorde det möjligt, delvis, genom att driva stordriftsfördelar över hela världen för investerare med en mycket motståndskraftig och effektiv teknisk plattform. Vanguard valde en arkitektur för flera regioner för denna arbetsbelastning för att skydda mot försämringar av regionala tjänster. För hög tillgänglighetssyften finns det ett behov av att göra de data som används av arbetsbelastningen tillgängliga inte bara i den primära regionen, utan även i den sekundära regionen med minimal replikeringsfördröjning. I händelse av en funktionsnedsättning i den primära regionen bör lösningen kunna misslyckas till den sekundära regionen med så lite dataförlust som möjligt och möjligheten att återuppta dataintag.
Vanguard Cloud Technology Office och AWS samarbetade för att bygga en infrastrukturlösning på AWS som uppfyllde deras resilienskrav. Multi-Region-lösningen möjliggör en robust fail-over-mekanism, med inbyggd observerbarhet och återställning. Lösningen stöder även streaming av data från flera källor till olika Kinesis-dataströmmar. Lösningen rullas för närvarande ut till de olika företagsgrupperna för att förbättra motståndskraften för deras arbetsbelastningar.
Användningsfallet som diskuteras här kräver Change Data Capture (CDC) för att strömma data från en fjärrdatakälla (stordator DB2) till Amazon Kinesis dataströmmar, eftersom affärskapaciteten beror på dessa data. Kinesis Data Streams är en fullt hanterad, massivt skalbar, hållbar och lågkostnadsstreamingtjänst som kontinuerligt kan fånga och strömma stora mängder data från flera källor och gör data tillgänglig för konsumtion inom millisekunder. Tjänsten är byggd för att vara mycket motståndskraftig och använder flera tillgänglighetszoner för att bearbeta och lagra data.
Lösningen som diskuteras i det här inlägget förklarar hur AWS och Vanguard innoverade för att bygga en motståndskraftig arkitektur för att möta sina höga tillgänglighetsmål.
Lösningsöversikt
Lösningen använder AWS Lambda att replikera data från Kinesis dataströmmar i den primära regionen till en sekundär region. I händelse av en funktionsnedsättning som påverkar CDC-pipelinen, främjar failover-processen den sekundära regionen till primär för producenter och konsumenter. Vi använder Amazon DynamoDB globala tabeller för replikeringskontrollpunkter som gör det möjligt att återuppta dataströmning från kontrollpunkten och även upprätthåller en primär regionkonfigurationsflagga som förhindrar en oändlig replikeringsslinga av samma data fram och tillbaka.
Lösningen ger också flexibiliteten för Kinesis Data Streams-konsumenter att använda den primära eller andra sekundära regionen inom samma AWS-konto.
Följande diagram illustrerar referensarkitekturen.
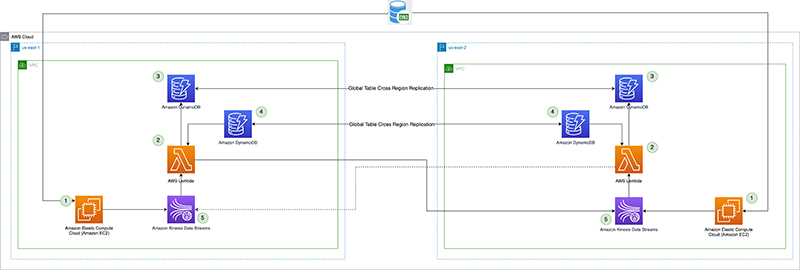
Låt oss titta på varje komponent i detalj:
- CDC-processor (producent) – I denna referensarkitektur är producenten utplacerad på Amazon Elastic Compute Cloud (Amazon EC2) i både den primära och sekundära regionen, och är aktiv i den primära regionen och i standby-läge i den sekundära regionen. Den fångar upp CDC-data från den externa datakällan (som en DB2-databas som visas i arkitekturen ovan) och strömmar till Kinesis-dataströmmar i den primära regionen. Vanguard använder en 3:ard partyverktyget Qlik Replicate som deras CDC-processor. Den producerar en välformad nyttolast inklusive DB2-bekräftelsetidsstämpeln till Kinesis-dataströmmen, förutom de faktiska raddata från fjärrdatakällan. (
example-stream-1i det här exemplet). Följande kod är ett exempel på nyttolast som endast innehåller primärnyckeln för posten som ändrades och commit-tidsstämpeln (för enkelhetens skull visas inte resten av tabellraddata nedan):{ "eventSource": "aws:kinesis", "kinesis": { "ApproximateArrivalTimestamp": "Mon July 18 20:00:00 UTC 2022", "SequenceNumber": "49544985256907370027570885864065577703022652638596431874", "PartitionKey": "12349999", "KinesisSchemaVersion": "1.0", "Data": "eyJLZXkiOiAxMjM0OTk5OSwiQ29tbWl0VGltZXN0YW1wIjogIjIwMjItMDctMThUMjA6MDA6MDAifQ==" }, "eventId": "shardId-000000000000:49629136582982516722891309362785181370337771525377097730", "invokeIdentityArn": "arn:aws:iam::6243876582:role/kds-crr-LambdaRole-1GZWP67437SD", "eventName": "aws:kinesis:record", "eventVersion": "1.0", "eventSourceARN": "arn:aws:kinesis:us-east-1:6243876582:stream/kds-stream-1/consumer/kds-crr:6243876582", "awsRegion": "us-east-1" }Det Base64-avkodade värdet på
Dataenligt följande. Den faktiska Kinesis-posten skulle innehålla hela raddata för tabellraden som ändrades, förutom primärnyckeln och commit-tidsstämpeln.{"Key": 12349999,"CommitTimestamp": "2022-07-18T20:00:00"}Smakämnen
CommitTimestampiDatafältet används i replikeringskontrollpunkten och är avgörande för att korrekt spåra hur mycket av strömdata som har replikerats till den sekundära regionen. Kontrollpunkten kan sedan användas för att underlätta en CDC-processor (producent) failover och korrekt återuppta produktion av data från replikeringskontrollpunktens tidsstämpel och framåt.Alternativet till att använda en fjärrdatakälla
CommitTimestamp(om den inte är tillgänglig) är att användaApproximateArrivalTimestamp(vilket är tidsstämpeln när posten faktiskt skrivs till dataströmmen). - Cross-Region replikering Lambda funktion – Funktionen är utplacerad till både primära och sekundära regioner. Den är konfigurerad med en händelsekälla som är mappad till dataströmmen som innehåller CDC-data. Samma funktion kan användas för att replikera data från flera strömmar. Den anropas med en grupp poster från Kinesis Data Streams och replikerar batchen till en målreplikeringsregion (som tillhandahålls via Lambda-konfigurationsmiljön). Av kostnadsskäl, om CDC-data aktivt produceras endast i den primära regionen, kan den reserverade samtidigheten för funktionen i den sekundära regionen sättas till noll och modifieras under regional failover. Funktionen har AWS identitets- och åtkomsthantering (IAM) rollbehörigheter för att göra följande:
- Läs och skriv till DynamoDB globala tabeller som används i den här lösningen, inom samma konto.
- Läs och skriv till Kinesis Dataströmmar i båda regionerna inom samma konto.
- Publicera anpassade mätvärden till amazoncloudwatch i båda regionerna inom samma konto.
- Replikeringskontrollpunkt – Replikeringskontrollpunkten använder DynamoDB globala tabellen i både den primära och sekundära regionen. Den används av Lambda-funktionen för replikering över regioner för att bevara tidsstämpeln för den senaste replikeringsposten som replikeringskontrollpunkt för varje ström som är konfigurerad för replikering. För det här inlägget skapar vi och använder en global tabell som heter
kdsReplicationCheckpoint. - Active Region config – Den aktiva regionen använder DynamoDB globala tabellen i både primära och sekundära regioner. Den använder den inbyggda replikeringsförmågan över regioner i den globala tabellen för att replikera konfigurationen. Den är förfylld med data om vilken som är den primära regionen för en ström, för att förhindra replikering tillbaka till den primära regionen av Lambda-funktionen i standbyregionen. Denna konfiguration kanske inte krävs om lambdafunktionen i standbyregionen har en reserverad samtidighet inställd på noll, men kan fungera som en säkerhetskontroll för att undvika oändlig replikeringsloop av data. För det här inlägget skapar vi en global tabell som heter
kdsActiveRegionConfigoch lägg ett objekt med följande data:{ "stream-name": "example-stream-1", "active-region" : "us-east-1" } - Kinesis dataströmmar – Strömmen till vilken CDC-processorn producerar data. För det här inlägget använder vi en ström som heter
example-stream-1i båda regionerna, med samma fragmentkonfiguration och åtkomstpolicyer.
Sekvens av steg i replikering mellan regioner
Låt oss kort titta på hur arkitekturen utövas med hjälp av följande sekvensdiagram.
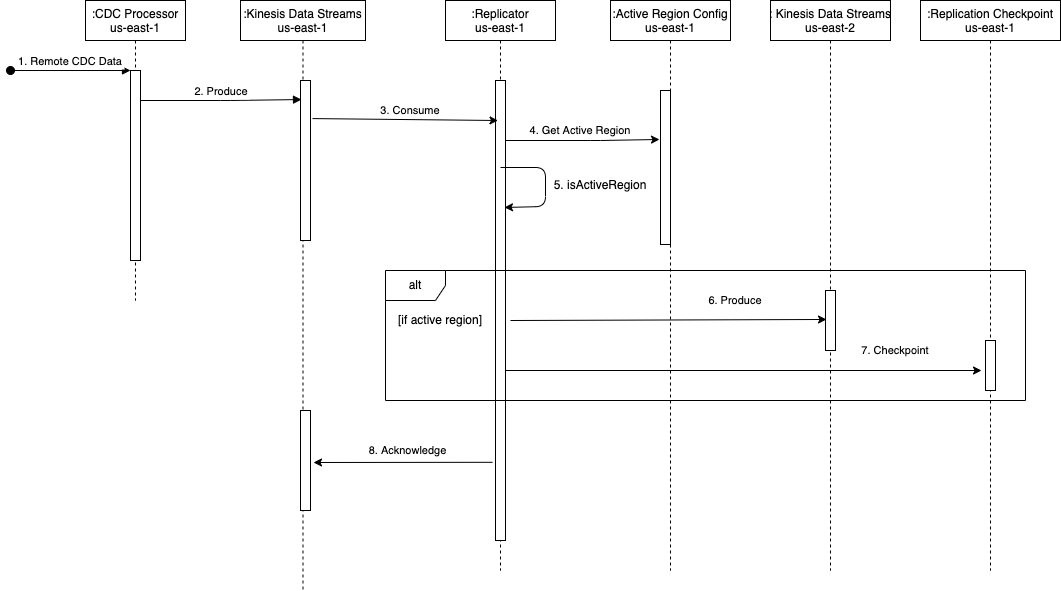
Sekvensen består av följande steg:
- CDC-processorn (in
us-east-1) läser CDC-data från fjärrdatakällan. - CDC-processorn (in
us-east-1) strömmar CDC-data till Kinesis Data Streams (inus-east-1). - Lambdafunktionen för replikering mellan regioner (i us-east-1) förbrukar data från dataströmmen (i
us-east-1). Det förbättrade fan-out-mönstret rekommenderas för dedikerad och ökad genomströmning för replikering över regioner. - Replikatorns Lambda-funktion (in
us-east-1) validerar sin nuvarande region med den aktiva regionkonfigurationen för strömmen som konsumeras, med hjälp avkdsActiveRegionConfigDynamoDB global tabell Följande exempelkod (i Java) kan hjälpa till att illustrera tillståndet som utvärderas:// Fetch the current AWS Region from the Lambda function’s environment String currentAWSRegion = System.getenv(“AWS_REGION”); // Read the stream name from the first Kinesis Record once for the entire batch being processed. This is done because we are reusing the same Lambda function for replicating multiple streams. String currentStreamNameConsumed = kinesisRecord.getEventSourceARN().split(“:”)[5].split(“/”)[1]; // Build the DynamoDB query condition using the stream name Map<String, Condition> keyConditions = singletonMap(“streamName”, Condition.builder().comparisonOperator(EQ).attributeValueList(AttributeValue.builder().s(currentStreamNameConsumed).build()).build()); // Query the DynamoDB Global Table QueryResponse queryResponse = ddbClient.query(QueryRequest.builder().tableName("kdsActiveRegionConfig").keyConditions(keyConditions).attributesToGet(“ActiveRegion”).build()); - Funktionen utvärderar svaret från DynamoDB med följande kod:
// Evaluate the response if (queryResponse.hasItems()) { AttributeValue activeRegionForStream = queryResponse.items().get(0).get(“ActiveRegion”); return currentAWSRegion.equalsIgnoreCase(activeRegionForStream.s()); } - Beroende på svaret utför funktionen följande åtgärder:
- Om svaret är
true, producerar replikatorfunktionen posterna till Kinesis Data Streams ius-east-2på ett sekventiellt sätt.- Om det uppstår ett fel spåras postens sekvensnummer och iterationen bryts. Funktionen returnerar listan över misslyckade sekvensnummer. Genom att returnera det misslyckade sekvensnumret använder lösningen funktionen av Lambdakontroll för att kunna återuppta bearbetningen av ett parti av poster med partiella fel. Detta är användbart vid hantering av eventuella funktionsnedsättningar, där funktionen försöker replikera data över regioner för att säkerställa strömparitet och ingen dataförlust.
- Om det inte finns några fel returneras en tom lista, vilket indikerar att batchen lyckades.
- Om svaret är
false, returnerar replikatorfunktionen utan att utföra någon replikering. För att minska kostnaden för Lambda-anrop kan du ställa in den reserverade samtidigheten för funktionen i DR-regionen (us-east-2) till noll. Detta kommer att förhindra att funktionen anropas. När du failover kan du uppdatera detta värde till ett lämpligt antal baserat på CDC-genomströmningen och ställa in den reserverade samtidigheten för funktionen ius-east-1till noll för att förhindra att den körs i onödan.
- Om svaret är
- Efter att alla poster produceras till Kinesis Data Streams in
us-east-2, kontrollerar replikatorfunktionen tillkdsReplicationCheckpointDynamoDB global tabell (inus-east-1) med följande data:{ "streamName": "example-stream-1", "lastReplicatedTimestamp": "2022-07-18T20:00:00" } - Funktionen återkommer efter framgångsrik bearbetning av partiet med poster.
Prestationsöverväganden
Lösningens prestandaförväntningar bör förstås med hänsyn till följande faktorer:
- Regionval – Replikeringslatensen är direkt proportionell mot avståndet som tillryggaläggs av data, så förstå ditt val av region
- Hastighet – Datans inkommande hastighet eller mängden data som replikeras
- Nyttolaststorlek – Storleken på nyttolasten som replikeras
Övervaka replikeringen mellan regioner
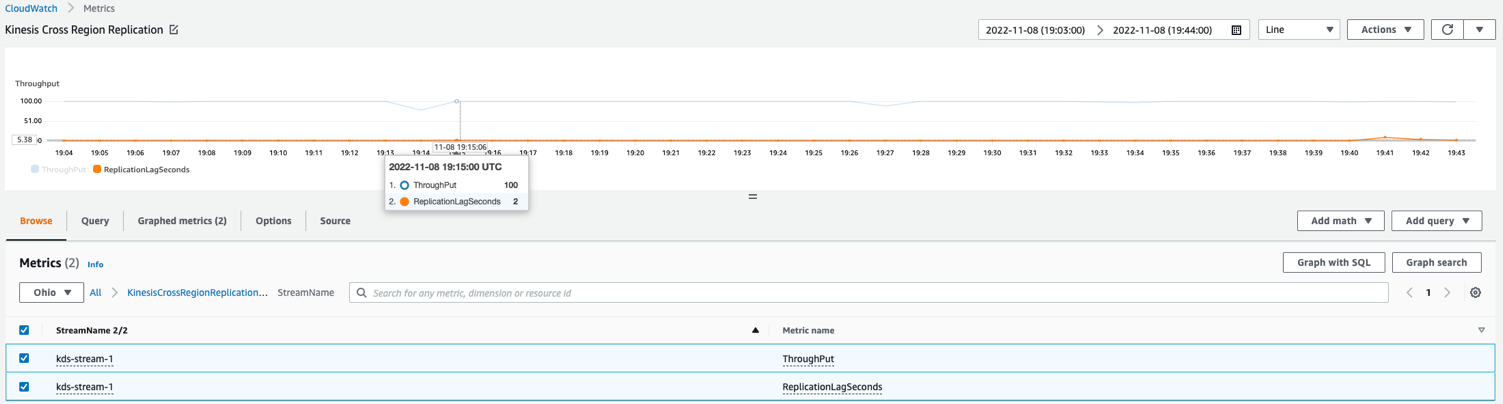
Det rekommenderas att spåra och observera replikeringen när den sker. Du kan skräddarsy Lambda-funktionen för att publicera anpassade mätvärden till CloudWatch med följande mätvärden i slutet av varje anrop. Genom att publicera dessa mätvärden till både den primära och sekundära regionen hjälper du dig att skydda dig från försämringar som påverkar observerbarheten i den primära regionen.
- genomströmning – Den nuvarande lambdaanropsbatchstorleken
- ReplicationLagSeconds – Skillnaden mellan den aktuella tidsstämpeln (efter bearbetning av alla poster) och
ApproximateArrivalTimestampav den senaste skivan som replikerades
Följande exempel CloudWatch-statistikdiagram visar att den genomsnittliga replikeringsfördröjningen var 2 sekunder med en genomströmning av 100 poster replikerade från us-east-1 till us-east-2.
Gemensam failover-strategi
Under eventuella nedskrivningar som påverkar CDC-pipelinen i den primära regionen, kan behov av affärskontinuitet eller katastrofåterställning diktera en pipeline-failover till den sekundära (standby-) regionen. Detta innebär att ett par saker måste göras som en del av denna failover-process:
- Om möjligt, stoppa alla CDC-uppgifter i CDC-processorverktyget i
us-east-1. - CDC-processorn måste misslyckas över till den sekundära regionen, så att den kan läsa CDC-data från fjärrdatakällan medan den arbetar utanför standby-regionen.
- Smakämnen
kdsActiveRegionConfigDynamoDB globala tabell måste uppdateras. Till exempel för strömmenexample-stream-1används i vårt exempel ändras den aktiva regionen tillus-east-2:
{ "stream-name": "example-stream-1", "active-Region" : "us-east-2"
}- Alla strömkontrollpunkter måste läsas från
kdsReplicationCheckpointDynamoDB global tabell (inus-east-2), och tidsstämplarna från var och en av kontrollpunkterna används för att starta CDC-uppgifterna i producentverktyget ius-east-2Område. Detta minimerar risken för dataförlust och återupptar korrekt strömning av CDC-data från fjärrdatakällan från kontrollpunktens tidsstämpel och framåt. - Om du använder reserverad samtidighet för att kontrollera Lambda-anrop, ställ in värdet till noll i den primära regionen(
us-east-1) och till ett lämpligt värde som inte är noll i den sekundära regionen(us-east-2).
Vanguards flerstegs failover-strategi
Några av tredjepartsverktygen som Vanguard använder har en CDC-process i två steg för att strömma data från en fjärrdatakälla till en destination. Vanguards val av verktyg för deras CDC-processor följer denna tvåstegsmetod:
- Det första steget involverar att ställa in en loggströmuppgift som läser data från fjärrdatakällan och kvarstår på en iscensättningsplats.
- Det andra steget innebär att ställa in individuella konsumentuppgifter som läser data från uppställningsplatsen – som kan vara på Amazon Elastic File System (Amazon EFS) eller Amazon FSx, till exempel — och streama den till destinationen. Flexibiliteten här är att var och en av dessa konsumentuppgifter kan utlösas för att strömma från olika tidsstämplar för commit. Loggströmsuppgiften börjar vanligtvis läsa data från det minsta av alla tidsstämplar som används av konsumentuppgifterna.
Låt oss titta på ett exempel för att förklara scenariot:
- Konsumentuppgift A strömmar data från en commit-tidsstämpel 2022-07-19T20:00:00 och framåt till
example-stream-1. - Konsumentuppgift B strömmar data från en commit-tidsstämpel 2022-07-19T21:00:00 och framåt till
example-stream-2. - I den här situationen bör loggströmmen läsa data från fjärrdatakällan från det minsta av de tidsstämplar som används av konsumentuppgifterna, vilket är 2022-07-19T20:00:00.
Följande sekvensdiagram visar de exakta stegen att köra under en failover till us-east-2 (beredskapsregionen).
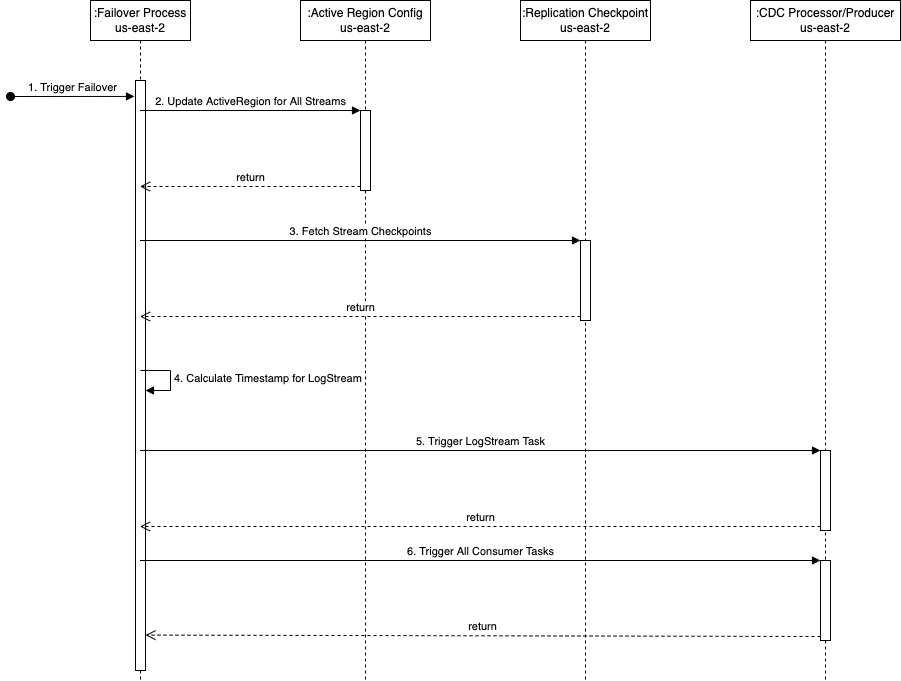
Stegen är som följer:
- failover-processen utlöses i standby-regionen (
us-east-2i det här exemplet) när det behövs. Observera att utlösaren kan automatiseras med hjälp av omfattande hälsokontroller av pipelinen i den primära regionen. - failover-processen uppdaterar kdsActiveRegionConfig DynamoDB globala tabellen med det nya värdet för regionen som
us-east-2för alla strömnamn. - Nästa steg är att hämta alla strömkontrollpunkter från
kdsReplicationCheckpointDynamoDB global tabell (inus-east-2). - Efter att kontrollpunktsinformationen har lästs, hittar failover-processen minimum av alla
lastReplicatedTimestamp. - Loggströmningsuppgiften i CDC-processorverktyget startas i
us-east-2med tidsstämpeln som finns i steg 4. Den börjar läsa CDC-data från fjärrdatakällan från denna tidsstämpel och framåt och behåller dem på iscensättningsplatsen på AWS. - Nästa steg är att starta alla konsumentuppgifter för att läsa data från mellanstationsplatsen och strömma till destinationsdataströmmen. Det är här varje konsumentuppgift förses med lämplig tidsstämpel från
kdsReplicationCheckpointtabell enligtstreamNamesom uppgiften strömmar data till.
Efter att alla konsumentuppgifter har startat produceras data till Kinesis dataströmmar i us-east-2. Därefter är processen för replikering mellan regioner densamma som beskrivits tidigare - lambda-replikeringsfunktionen i us-east-2 börjar replikera data till dataströmmen in us-east-1.
Konsumentapplikationerna som läser data från strömmarna förväntas vara idempotenta för att kunna hantera dubbletter. Dubletter kan införas i strömmen på grund av många orsaker, av vilka några nämns nedan.
- Producenten eller CDC-processorn inför dubbletter i strömmen samtidigt som CDC-data spelas upp under en failover
- DynamoDB Global Table använder asynkron replikering av data över regioner och om
kdsReplicationCheckpointtabelldata har en replikeringsfördröjning, kan failover-processen potentiellt använda en äldre kontrollpunktstidstämpel för att spela upp CDC-data.
Konsumentapplikationer bör också kontrollera CommitTimestamp för den senaste posten som konsumerades. Detta för att underlätta bättre övervakning och återhämtning.
Vägen till mognad: Automatiserad återhämtning
Det idealiska tillståndet är att fullständigt automatisera failover-processen, vilket minskar tiden för återhämtning och möter resilience Service Level Objective (SLO). Men i de flesta organisationer kräver beslutet att misslyckas, misslyckas och utlösa failover manuellt ingripande för att bedöma situationen och besluta om resultatet. Att skapa skriptautomation för att utföra failover som kan köras av en människa är ett bra ställe att börja.
Vanguard har automatiserat alla steg i failover, men har fortfarande människor att fatta beslut om när de ska anropa det. Du kan anpassa lösningen för att möta dina behov och beroende på vilket CDC-processorverktyg du använder i din miljö.
Slutsats
I det här inlägget beskrev vi hur Vanguard förnyade och byggde en lösning för att replikera data över regioner i Kinesis Dataströmmar för att göra data mycket tillgänglig. Vi visade också en robust kontrollpunktsstrategi för att underlätta en regional failover av replikeringsprocessen vid behov. Lösningen illustrerade också hur man använder DynamoDB globala tabeller för att spåra replikeringskontrollpunkter och konfiguration. Med den här arkitekturen kunde Vanguard distribuera arbetsbelastningar beroende på CDC-data till flera regioner för att möta affärsbehov av hög tillgänglighet inför funktionsnedsättningar som påverkar CDC-pipelines i den primära regionen.
Om du har någon feedback vänligen lämna en kommentar i kommentarsektionen nedan.
Om författarna
 Raghu Boppanna arbetar som Enterprise Architect på Vanguards Chief Technology Office. Raghu är specialiserad på dataanalys, datamigrering/replikering inklusive CDC Pipelines, Disaster Recovery och databaser. Han har tjänat flera AWS-certifieringar inklusive AWS Certified Security – Specialty & AWS Certified Data Analytics – Specialty.
Raghu Boppanna arbetar som Enterprise Architect på Vanguards Chief Technology Office. Raghu är specialiserad på dataanalys, datamigrering/replikering inklusive CDC Pipelines, Disaster Recovery och databaser. Han har tjänat flera AWS-certifieringar inklusive AWS Certified Security – Specialty & AWS Certified Data Analytics – Specialty.
 Parameswaran V Vaidyanathan är en Senior Cloud Resilience Architect med Amazon Web Services. Han hjälper stora företag att uppnå affärsmålen genom att utforma och bygga skalbara och motståndskraftiga lösningar på AWS-molnet.
Parameswaran V Vaidyanathan är en Senior Cloud Resilience Architect med Amazon Web Services. Han hjälper stora företag att uppnå affärsmålen genom att utforma och bygga skalbara och motståndskraftiga lösningar på AWS-molnet.
 Richa Kaul är en senior ledare inom kundlösningar som betjänar kunder med finansiella tjänster. Hon är baserad i New York. Hon har lång erfarenhet av storskalig molntransformation, medarbetarexcellens och nästa generations digitala lösningar. Hon och hennes team fokuserar på att optimera värdet av molnet genom att bygga prestanda, motståndskraftiga och smidiga lösningar. Richa tycker om multisporter som triathlon, musik och att lära sig om ny teknik.
Richa Kaul är en senior ledare inom kundlösningar som betjänar kunder med finansiella tjänster. Hon är baserad i New York. Hon har lång erfarenhet av storskalig molntransformation, medarbetarexcellens och nästa generations digitala lösningar. Hon och hennes team fokuserar på att optimera värdet av molnet genom att bygga prestanda, motståndskraftiga och smidiga lösningar. Richa tycker om multisporter som triathlon, musik och att lära sig om ny teknik.
 Mithil Prasad är en huvudansvarig för kundlösningar med Amazon Web Services. I sin roll arbetar Mithil med kunder för att driva molnvärdeförverkligande, tillhandahålla tankeledarskap för att hjälpa företag att uppnå snabbhet, smidighet och innovation.
Mithil Prasad är en huvudansvarig för kundlösningar med Amazon Web Services. I sin roll arbetar Mithil med kunder för att driva molnvärdeförverkligande, tillhandahålla tankeledarskap för att hjälpa företag att uppnå snabbhet, smidighet och innovation.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/how-vanguard-made-their-technology-platform-resilient-and-efficient-by-building-cross-region-replication-for-amazon-kinesis-data-streams/
- 1
- 100
- 2022
- 28
- a
- förmåga
- Able
- Om oss
- ovan
- tillgång
- Enligt
- Konto
- exakt
- Uppnå
- tvärs
- åtgärder
- aktiv
- aktivt
- faktiskt
- Dessutom
- rådgivning
- påverkar
- prisvärd
- Efter
- mot
- smidig
- Alla
- tillåter
- alternativ
- amason
- Amazon EC2
- Amazon Kinesis
- Amazon Web Services
- mängder
- analytics
- och
- tillämpningar
- tillvägagångssätt
- lämpligt
- arkitektur
- automatisera
- Automatiserad
- Automation
- tillgänglighet
- tillgänglig
- genomsnitt
- undvika
- AWS
- AWS-certifierad
- tillbaka
- baserat
- därför att
- Där vi får lov att vara utan att konstant prestera,
- nedan
- Bättre
- mellan
- i korthet
- Brutet
- SLUTRESULTAT
- Byggnad
- byggt
- inbyggd
- företag
- kontinuitet i verksamheten
- företag
- kallas
- fånga
- fångar
- Vid
- CDC
- certifieringar
- Certifierad
- chanser
- byta
- ta
- Kontroller
- chef
- val
- cloud
- MOLNTEKNIK
- koda
- kommentar
- kommentarer
- förbinda
- komponent
- omfattande
- Compute
- tillstånd
- konfiguration
- överväganden
- konsumeras
- Konsumenten
- konsumenter
- konsumtion
- kontinuerligt
- kontroll
- Pris
- kunde
- Par
- skapa
- Skapa
- kritisk
- Aktuella
- För närvarande
- beställnings
- kund
- Kundlösningar
- Kunder
- skräddarsy
- datum
- Data Analytics
- dataförlust
- Databas
- databaser
- Avgörande
- Beslutet
- dedicerad
- demonstreras
- demonstrerar
- beroende
- beror
- distribuera
- utplacerade
- beskriven
- destination
- detalj
- Skillnaden
- olika
- digital
- direkt
- katastrof
- diskuteras
- avstånd
- driv
- drivande
- dubbletter
- under
- varje
- Tidigare
- intjänade
- ekonomier
- Stordriftsfördelar
- effektiv
- Anställd
- möjliggör
- förbättrad
- säkerställa
- Företag
- företag
- Hela
- Miljö
- Eter (ETH)
- utvärdera
- utvärderade
- händelse
- Varje
- exempel
- Excellence
- exekvera
- förväntningar
- förväntat
- erfarenhet
- Förklara
- Förklarar
- omfattande
- extern
- Ansikte
- främja
- faktorer
- MISSLYCKAS
- Misslyckades
- Misslyckande
- Leverans
- återkoppling
- fält
- Fil
- finansiella
- finansiella tjänster
- fynd
- Förnamn
- Flexibilitet
- Fokus
- efter
- följer
- För investerare
- hittade
- från
- fullständigt
- fungera
- generering
- Välgörenhet
- globen
- Mål
- god
- diagram
- Gäst
- gäst inlägg
- hantera
- Arbetsmiljö
- händer
- Hälsa
- hjälpa
- hjälper
- här.
- Hög
- höggradigt
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- humant
- Människa
- IAM
- idealisk
- Identitet
- nedsättning
- förbättra
- förbättrar
- in
- Inklusive
- Inkommande
- ökat
- pekar på
- individuellt
- informationen
- Infrastruktur
- Innovation
- exempel
- ingripande
- introducerade
- Introducerar
- investerare
- För Investerare
- innebär
- IT
- iteration
- java
- Juli
- Nyckel
- Kinesis dataströmmar
- Large
- Efternamn
- Latens
- ledare
- Ledarskap
- inlärning
- Lämna
- Nivå
- linje
- rader
- Lista
- liten
- läge
- se
- förlust
- gjord
- upprätthåller
- göra
- GÖR
- förvaltade
- chef
- sätt
- manuell
- många
- kartläggning
- massivt
- förfall
- betyder
- mekanism
- Möt
- möte
- metriska
- Metrics
- minimum
- minsta
- Mode
- modifierad
- övervakning
- mest
- flera
- multipel
- Musik
- namn
- namn
- nativ
- Behöver
- behövs
- behov
- Nya
- Ny teknik
- New York
- Nästa
- antal
- nummer
- mål
- observera
- Office
- drift
- optimera
- organisationer
- Resultat
- paritet
- del
- samarbetar
- parti
- Mönster
- utföra
- prestanda
- utför
- behörigheter
- kvarstår
- personlig
- rörledning
- Plats
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- snälla du
- Strategier
- möjlig
- Inlägg
- potentiellt
- förhindra
- primär
- Principal
- process
- bearbetning
- Processorn
- producerad
- producent
- producenter
- främjar
- skydda
- ge
- förutsatt
- ger
- publicera
- publicering
- syfte
- sätta
- Läsa
- Läsning
- insikt
- skäl
- rekommenderas
- post
- register
- Recover
- återvinning
- minska
- reducerande
- region
- regionala
- regioner
- avlägsen
- replikeras
- replikerar
- replikation
- Obligatorisk
- Krav
- Kräver
- reserverad
- motståndskraft
- elastisk
- respons
- REST
- Fortsätt
- avkastning
- tillbaka
- återgår
- robusta
- Roll
- Rullad
- RAD
- Körning
- Säkerhet
- Samma
- skalbar
- Skala
- scenario
- Andra
- sekundär
- sekunder
- §
- säkerhet
- senior
- Sekvens
- tjänar
- service
- Tjänster
- portion
- in
- inställning
- flera
- skall
- visas
- Visar
- enkelhet
- Situationen
- Storlek
- So
- lösning
- Lösningar
- några
- Källa
- Källor
- specialiserat
- Specialitet
- fart
- Sporter
- staging
- starta
- igång
- startar
- Ange
- Steg
- Steg
- Fortfarande
- Sluta
- lagra
- Strategi
- ström
- streaming
- streaming service
- strömmar
- framgångsrik
- Framgångsrikt
- lämplig
- överlägsen
- levereras
- Stöder
- system
- bord
- tar
- Målet
- uppgift
- uppgifter
- grupp
- lag
- Teknisk
- Tekniken
- Teknologi
- Smakämnen
- deras
- saker
- tredje part
- trodde
- tanke ledarskap
- Genom
- genomströmning
- tid
- tidsstämpel
- till
- verktyg
- verktyg
- spår
- Spårning
- Transformation
- rest
- utlösa
- triggas
- förstå
- förstått
- onödigt
- Uppdatering
- uppdaterad
- Uppdateringar
- användning
- användningsfall
- vanligen
- UTC
- värde
- Förtrupp
- Hastighet
- via
- volym
- webb
- webbservice
- som
- medan
- kommer
- inom
- utan
- fungerar
- skulle
- skriva
- skriven
- Din
- själv
- zephyrnet
- noll-
- zoner