Det här inlägget är skrivet tillsammans med Mahima Agarwal, Machine Learning Engineer, och Deepak Mettem, Senior Engineering Manager, på VMware Carbon Black
VMware kolsvart är en välkänd säkerhetslösning som erbjuder skydd mot hela spektrumet av moderna cyberattacker. Med terabyte data som genereras av produkten fokuserar säkerhetsanalysteamet på att bygga lösningar för maskininlärning (ML) för att yttra kritiska attacker och belysa nya hot från buller.
Det är avgörande för VMware Carbon Black-teamet att designa och bygga en anpassad end-to-end MLOps-pipeline som orkestrerar och automatiserar arbetsflöden i ML-livscykeln och möjliggör modellutbildning, utvärderingar och implementeringar.
Det finns två huvudsakliga syften med att bygga denna pipeline: stödja dataforskarna för modellutveckling i sena stadier, och ytmodellförutsägelser i produkten genom att betjäna modeller i hög volym och i realtidsproduktionstrafik. Därför valde VMware Carbon Black och AWS att bygga en anpassad MLOps-pipeline med hjälp av Amazon SageMaker för dess användarvänlighet, mångsidighet och fullt hanterade infrastruktur. Vi orkestrerar våra ML-utbildnings- och distributionspipelines med hjälp av Amazon Managed Workflows för Apache Airflow (Amazon MWAA), vilket gör att vi kan fokusera mer på att programmera skapa arbetsflöden och pipelines utan att behöva oroa oss för automatisk skalning eller underhåll av infrastruktur.
Med denna pipeline är det som en gång var Jupyter notebook-driven ML-forskning nu en automatiserad process som distribuerar modeller till produktion med få manuella ingrepp från dataforskare. Tidigare kunde processen att träna, utvärdera och implementera en modell ta över en dag; med denna implementering är allt bara en trigger bort och har minskat den totala tiden till några minuter.
I det här inlägget diskuterar VMware Carbon Black och AWS-arkitekter hur vi byggde och hanterade anpassade ML-arbetsflöden med gitlab, Amazon MWAA och SageMaker. Vi diskuterar vad vi har uppnått hittills, ytterligare förbättringar av pipelinen och lärdomar på vägen.
Lösningsöversikt
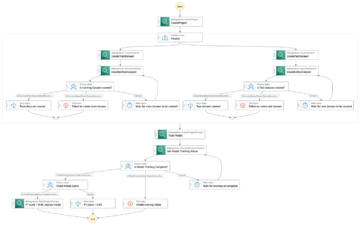
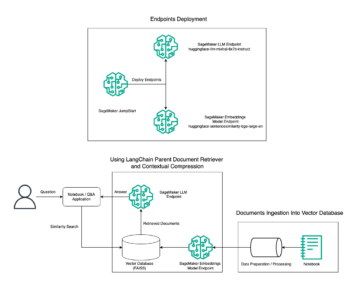
Följande diagram illustrerar ML-plattformsarkitekturen.

Lösningsdesign på hög nivå
Denna ML-plattform var tänkt och designad för att kunna användas av olika modeller över olika kodlager. Vårt team använder GitLab som ett källkodshanteringsverktyg för att underhålla alla kodförråd. Alla ändringar i modellförvarets källkod integreras kontinuerligt med hjälp av Gitlab CI, som anropar de efterföljande arbetsflödena i pipelinen (modellutbildning, utvärdering och implementering).
Följande arkitekturdiagram illustrerar end-to-end-arbetsflödet och de komponenter som ingår i vår MLOps-pipeline.

End-to-end arbetsflöde
ML-modellens utbildnings-, utvärderings- och distributionspipelines är orkestrerade med hjälp av Amazon MWAA, kallad en Regisserad acyklisk graf (DAG). En DAG är en samling uppgifter tillsammans, organiserade med beroenden och relationer för att säga hur de ska köras.
På hög nivå innehåller lösningsarkitekturen tre huvudkomponenter:
- ML pipeline kodlager
- ML modell utbildning och utvärdering pipeline
- ML-modellimplementeringspipeline
Låt oss diskutera hur dessa olika komponenter hanteras och hur de interagerar med varandra.
ML pipeline kodlager
Efter att modellrepo har integrerat MLOps-repo som deras nedströms pipeline, och en dataforskare begår kod i sin modellrepo, gör en GitLab-runner standardkodvalidering och -testning som definieras i det repet och triggar MLOps-pipeline baserat på kodändringarna. Vi använder Gitlabs flerprojektspipeline för att aktivera denna trigger över olika repor.
MLOps GitLab pipeline kör en viss uppsättning steg. Den utför grundläggande kodvalidering med pylint, paketerar modellens tränings- och slutledningskod i Docker-bilden och publicerar behållarbilden till Amazon Elastic Container Registry (Amazon ECR). Amazon ECR är ett fullständigt hanterat containerregister som erbjuder högpresterande hosting, så att du på ett tillförlitligt sätt kan distribuera applikationsbilder och artefakter var som helst.
ML modell utbildning och utvärdering pipeline
Efter att bilden publicerats utlöser den utbildningen och utvärderingen Apache luftflöde rörledningen genom AWS Lambda fungera. Lambda är en serverlös, händelsedriven beräkningstjänst som låter dig köra kod för praktiskt taget alla typer av applikationer eller backend-tjänster utan att tillhandahålla eller hantera servrar.
Efter att pipelinen har triggats framgångsrikt, kör den Training and Evaluation DAG, som i sin tur startar modellutbildningen i SageMaker. I slutet av denna utbildningspipeline får den identifierade användargruppen ett meddelande med tränings- och modellutvärderingsresultaten via e-post via Amazon enkel meddelandetjänst (Amazon SNS) och Slack. Amazon SNS är en fullständigt hanterad pub/undertjänst för A2A- och A2P-meddelanden.
Efter noggrann analys av utvärderingsresultaten kan datavetaren eller ML-ingenjören implementera den nya modellen om prestandan hos den nyutbildade modellen är bättre jämfört med den tidigare versionen. Modellernas prestanda utvärderas baserat på modellspecifika mätvärden (som F1-poäng, MSE eller förvirringsmatris).
ML-modellimplementeringspipeline
För att starta implementeringen startar användaren GitLab-jobbet som utlöser Deployment DAG genom samma Lambda-funktion. När pipelinen har körts framgångsrikt skapar eller uppdaterar den SageMaker-slutpunkten med den nya modellen. Detta skickar också ett meddelande med slutpunktsdetaljerna via e-post med Amazon SNS och Slack.
I händelse av fel i någon av rörledningarna meddelas användarna via samma kommunikationskanaler.
SageMaker erbjuder inferens i realtid som är idealisk för slutledningsarbetsbelastningar med låg latens och höga genomströmningskrav. Dessa slutpunkter är helt hanterade, lastbalanserade och automatiskt skalade och kan distribueras över flera tillgänglighetszoner för hög tillgänglighet. Vår pipeline skapar en sådan slutpunkt för en modell efter att den körts framgångsrikt.
I de följande avsnitten utökar vi de olika komponenterna och dyker in i detaljerna.
GitLab: Paketera modeller och utlösa pipelines
Vi använder GitLab som vårt kodlager och för pipeline för att paketera modellkoden och trigga nedströms Airflow DAGs.
Flerprojektspipeline
GitLab-pipelinefunktionen för flera projekt används där den överordnade pipelinen (uppströms) är en modellrepo och den underordnade pipelinen (nedströms) är MLOps-repo. Varje repo har en .gitlab-ci.yml, och följande kodblock aktiverat i uppströmspipelinen triggar nedströms MLOps-pipeline.
Uppströmspipelinen skickar över modellkoden till nedströmspipelinen där paketerings- och publicerings-CI-jobben utlöses. Koden för att behålla modellkoden och publicera den till Amazon ECR underhålls och hanteras av MLOps pipeline. Den skickar variabler som ACCESS_TOKEN (kan skapas under Inställningar, Tillgång), JOB_ID (för att komma åt artefakter uppströms) och $CI_PROJECT_ID (projekt-ID för modellrepo) variabler, så att MLOps-pipeline kan komma åt modellkodfilerna. Med jobbartefakter funktionen från Gitlab, nedströms repet kommer åt fjärrartefakterna med följande kommando:
Modellrepo kan konsumera nedströms pipelines för flera modeller från samma repo genom att förlänga steget som utlöser det med hjälp av sträcker nyckelord från GitLab, som låter dig återanvända samma konfiguration över olika steg.
Efter att ha publicerat modellbilden till Amazon ECR, utlöser MLOps-pipelinen Amazons MWAA-utbildningspipeline med hjälp av Lambda. Efter användarens godkännande utlöser den även Amazon MWAA-pipeline för modelldistribution med samma Lambda-funktion.
Semantisk versionering och överföring av versioner nedströms
Vi utvecklade anpassad kod till version ECR-bilder och SageMaker-modeller. MLOps-pipelinen hanterar den semantiska versionslogiken för bilder och modeller som en del av det stadium där modellkoden blir containeriserad, och skickar versionerna vidare till senare stadier som artefakter.
Omskolning
Eftersom omskolning är en avgörande aspekt av en ML-livscykel har vi implementerat omskolningsmöjligheter som en del av vår pipeline. Vi använder SageMaker list-models API för att identifiera om det är omskolning baserat på modellens versionsnummer och tidsstämpel.
Vi hanterar det dagliga schemat för omskolningspipeline med hjälp av GitLabs schemapipelines.
Terraform: Infrastrukturinstallation
Förutom ett Amazon MWAA-kluster, ECR-förråd, Lambda-funktioner och SNS-ämne, använder denna lösning också AWS identitets- och åtkomsthantering (IAM) roller, användare och policyer; Amazon enkel lagringstjänst (Amazon S3) hinkar och en amazoncloudwatch stock speditör.
För att effektivisera installationen och underhållet av infrastrukturen för de tjänster som är involverade i hela vår pipeline använder vi Terraform att implementera infrastrukturen som kod. Närhelst infrauppdateringar krävs utlöser kodändringarna en GitLab CI-pipeline som vi sätter upp, som validerar och distribuerar ändringarna i olika miljöer (till exempel lägga till en behörighet till en IAM-policy i dev-, stage- och prod-konton).
Amazon ECR, Amazon S3 och Lambda: Pipeline facilitation
Vi använder följande nyckeltjänster för att underlätta vår pipeline:
- Amazon ECR – För att upprätthålla och tillåta bekväma hämtningar av modellbehållarbilderna taggar vi dem med semantiska versioner och laddar upp dem till ECR-arkiv som ställts in pr.
${project_name}/${model_name}genom Terraform. Detta möjliggör ett bra lager av isolering mellan olika modeller och tillåter oss att använda anpassade algoritmer och formatera slutledningsbegäranden och svar för att inkludera önskad modellmanifestinformation (modellnamn, version, träningsdataväg, och så vidare). - Amazon S3 – Vi använder S3-hinkar för att bevara modellträningsdata, tränade modellartefakter per modell, Airflow DAGs och annan ytterligare information som krävs av pipelines.
- Lambda – Eftersom vårt Airflow-kluster är utplacerat i en separat VPC av säkerhetsskäl, kan DAG:erna inte nås direkt. Därför använder vi en Lambda-funktion, som också underhålls med Terraform, för att trigga eventuella DAGs som anges av DAG-namnet. Med korrekt IAM-inställning utlöser GitLab CI-jobbet Lambda-funktionen, som passerar genom konfigurationerna ner till de begärda utbildnings- eller distributions-DAG:erna.
Amazon MWAA: Utbildnings- och distributionspipelines
Som nämnts tidigare använder vi Amazon MWAA för att orkestrera utbildnings- och distributionspipelines. Vi använder SageMaker-operatörer som finns tillgängliga i Amazon-leverantörspaket för Airflow att integrera med SageMaker (för att undvika jinja-mall).
Vi använder följande operatörer i denna utbildningspipeline (visas i följande arbetsflödesdiagram):

MWAA Training Pipeline
Vi använder följande operatörer i distributionspipelinen (visas i följande arbetsflödesdiagram):

Modellinstallationspipeline
Vi använder Slack och Amazon SNS för att publicera fel-/framgångsmeddelanden och utvärderingsresultat i båda pipelines. Slack erbjuder ett brett utbud av alternativ för att anpassa meddelanden, inklusive följande:
- SnsPublishOperator - Vi använder SnsPublishOperator för att skicka meddelanden om framgång/misslyckande till användarnas e-post
- Slack API – Vi skapade inkommande webhook-URL för att få pipeline-meddelanden till önskad kanal
CloudWatch och VMware Wavefront: Övervakning och loggning
Vi använder en CloudWatch-instrumentpanel för att konfigurera slutpunktsövervakning och loggning. Det hjälper till att visualisera och hålla reda på olika drifts- och modellprestandamått som är specifika för varje projekt. Utöver policyerna för automatisk skalning som ställts in för att spåra några av dem, övervakar vi kontinuerligt förändringarna i CPU- och minnesanvändning, förfrågningar per sekund, svarsfördröjningar och modellmått.
CloudWatch är till och med integrerat med en VMware Tanzu Wavefront dashboard så att den kan visualisera mätvärdena för modellslutpunkter såväl som andra tjänster på projektnivå.
Affärsfördelar och vad som händer härnäst
ML pipelines är mycket avgörande för ML-tjänster och funktioner. I det här inlägget diskuterade vi ett end-to-end ML-användningsfall med funktioner från AWS. Vi byggde en anpassad pipeline med SageMaker och Amazon MWAA, som vi kan återanvända över projekt och modeller, och automatiserade ML-livscykeln, vilket minskade tiden från modellutbildning till produktionsinstallation till så lite som 10 minuter.
I och med att ML-livscykelbördan flyttades till SageMaker, tillhandahöll det en optimerad och skalbar infrastruktur för modellträning och implementering. Modellservering med SageMaker hjälpte oss att göra förutsägelser i realtid med millisekunders latenser och övervakningsmöjligheter. Vi använde Terraform för att underlätta installationen och för att hantera infrastruktur.
Nästa steg för denna pipeline skulle vara att förbättra modellträningspipelinen med omträningsmöjligheter, oavsett om den är schemalagd eller baserad på modelldriftdetektering, stöd för skuggutbyggnad eller A/B-testning för snabbare och kvalificerad modellinstallation, och ML-linjespårning. Vi planerar också att utvärdera Amazon SageMaker-rörledningar eftersom GitLab-integration nu stöds.
Lärdomar
Som en del av att bygga den här lösningen lärde vi oss att du bör generalisera tidigt, men inte övergeneralisera. När vi först avslutade arkitekturdesignen försökte vi skapa och genomdriva kodmall för modellkoden som en bästa praxis. Det var dock så tidigt i utvecklingsprocessen att mallarna antingen var för generaliserade eller för detaljerade för att kunna återanvändas för framtida modeller.
Efter att ha levererat den första modellen genom pipeline, kom mallarna ut naturligt baserat på insikterna från vårt tidigare arbete. En pipeline kan inte göra allt från dag ett.
Modellexperimentering och produktion har ofta mycket olika (eller ibland till och med motstridiga) krav. Det är avgörande att balansera dessa krav från början som ett team och prioritera därefter.
Dessutom kanske du inte behöver alla funktioner i en tjänst. Att använda väsentliga funktioner från en tjänst och ha en modulariserad design är nyckeln till en effektivare utveckling och en flexibel pipeline.
Slutsats
I det här inlägget visade vi hur vi byggde en MLOps-lösning med SageMaker och Amazon MWAA som automatiserade processen att distribuera modeller till produktion, med få manuella ingrepp från dataforskare. Vi uppmuntrar dig att utvärdera olika AWS-tjänster som SageMaker, Amazon MWAA, Amazon S3 och Amazon ECR för att bygga en komplett MLOps-lösning.
*Apache, Apache Airflow och Airflow är antingen registrerade varumärken eller varumärken som tillhör Apache Software Foundation i USA och / eller andra länder.
Om författarna
 Deepak Mettem är Senior Engineering Manager i VMware, Carbon Black Unit. Han och hans team arbetar med att bygga streamingbaserade applikationer och tjänster som är högst tillgängliga, skalbara och motståndskraftiga för att ge kunderna maskininlärningsbaserade lösningar i realtid. Han och hans team är också ansvariga för att skapa verktyg som behövs för datavetare för att bygga, träna, distribuera och validera sina ML-modeller i produktion.
Deepak Mettem är Senior Engineering Manager i VMware, Carbon Black Unit. Han och hans team arbetar med att bygga streamingbaserade applikationer och tjänster som är högst tillgängliga, skalbara och motståndskraftiga för att ge kunderna maskininlärningsbaserade lösningar i realtid. Han och hans team är också ansvariga för att skapa verktyg som behövs för datavetare för att bygga, träna, distribuera och validera sina ML-modeller i produktion.
 Mahima Agarwal är en maskininlärningsingenjör i VMware, Carbon Black Unit.
Mahima Agarwal är en maskininlärningsingenjör i VMware, Carbon Black Unit.
Hon arbetar med att designa, bygga och utveckla kärnkomponenterna och arkitekturen för maskininlärningsplattformen för VMware CB SBU.
 Vamshi Krishna Enabothala är en Sr. Applied AI Specialist Architect på AWS. Han arbetar med kunder från olika sektorer för att påskynda högeffektiva data-, analys- och maskininlärningsinitiativ. Han brinner för rekommendationssystem, NLP och datorseende områden inom AI och ML. Utanför jobbet är Vamshi en RC-entusiast som bygger RC-utrustning (flygplan, bilar och drönare) och tycker också om trädgårdsarbete.
Vamshi Krishna Enabothala är en Sr. Applied AI Specialist Architect på AWS. Han arbetar med kunder från olika sektorer för att påskynda högeffektiva data-, analys- och maskininlärningsinitiativ. Han brinner för rekommendationssystem, NLP och datorseende områden inom AI och ML. Utanför jobbet är Vamshi en RC-entusiast som bygger RC-utrustning (flygplan, bilar och drönare) och tycker också om trädgårdsarbete.
 Sahil Thapar är en Enterprise Solutions Architect. Han arbetar med kunder för att hjälpa dem att bygga högt tillgängliga, skalbara och motståndskraftiga applikationer på AWS-molnet. Han är för närvarande fokuserad på containrar och maskininlärningslösningar.
Sahil Thapar är en Enterprise Solutions Architect. Han arbetar med kunder för att hjälpa dem att bygga högt tillgängliga, skalbara och motståndskraftiga applikationer på AWS-molnet. Han är för närvarande fokuserad på containrar och maskininlärningslösningar.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :är
- $UPP
- 1
- 10
- 100
- 7
- 8
- a
- Om oss
- accelerera
- tillgång
- Accessed
- i enlighet med detta
- konton
- uppnås
- tvärs
- acyklisk
- Dessutom
- Annat
- ytterligare information
- Efter
- mot
- AI
- algoritmer
- Alla
- tillåter
- amason
- Amazon SageMaker
- analys
- analytics
- och
- var som helst
- Apache
- api
- Ansökan
- tillämpningar
- tillämpas
- Tillämpad AI
- godkännande
- arkitektur
- ÄR
- områden
- AS
- aspekt
- At
- Attacker
- författarskap
- bil
- Automatiserad
- automatiserar
- tillgänglighet
- tillgänglig
- undvika
- AWS
- backend
- Balansera
- baserat
- grundläggande
- BE
- därför att
- Börjar
- Fördelarna
- BÄST
- Bättre
- mellan
- Svart
- Blockera
- Branch
- föra
- SLUTRESULTAT
- Byggnad
- byggt
- belastning
- by
- KAN
- kan inte
- kapacitet
- kol
- bilar
- Vid
- CB
- vissa
- Förändringar
- kanaler
- barn
- valde
- cloud
- kluster
- koda
- samling
- Kommunikation
- jämfört
- fullborda
- komponenter
- Compute
- dator
- Datorsyn
- beteenden
- konfiguration
- konfigurationer
- Motstridig
- förvirring
- överväganden
- konsumera
- konsumeras
- Behållare
- Behållare
- kontinuerligt
- Bekväm
- Kärna
- kunde
- länder
- CPU
- skapa
- skapas
- skapar
- Skapa
- kritisk
- avgörande
- För närvarande
- beställnings
- Kunder
- skräddarsy
- cyberattack
- DAG
- dagligen
- instrumentbräda
- datum
- datavetare
- dag
- definierade
- leverera
- distribuera
- utplacerade
- utplacera
- utplacering
- distributioner
- vecklas ut
- Designa
- utformade
- design
- detaljerad
- detaljer
- Detektering
- dev
- utvecklade
- utveckla
- Utveckling
- olika
- direkt
- diskutera
- diskuteras
- Hamnarbetare
- inte
- ner
- Drönare
- varje
- Tidigare
- Tidig
- enkel användning
- effektiv
- antingen
- smärgel
- möjliggöra
- aktiverad
- möjliggör
- uppmuntra
- början till slut
- Slutpunkt
- ingenjör
- Teknik
- Företag
- Enterprise Solutions
- entusiast
- miljöer
- Utrustning
- väsentlig
- Eter (ETH)
- utvärdera
- utvärderade
- utvärdering
- utvärdering
- utvärderingar
- Även
- händelse
- Varje
- allt
- exempel
- Bygga ut
- sträcker
- f1
- främja
- Misslyckande
- långt
- snabbare
- Leverans
- Funktioner
- få
- Filer
- Förnamn
- flexibel
- Fokus
- fokuserade
- fokuserar
- efter
- För
- format
- från
- full
- fullt spektrum
- fullständigt
- fungera
- funktioner
- ytterligare
- framtida
- genereras
- skaffa sig
- god
- Grupp
- Har
- har
- hjälpa
- hjälpte
- hjälper
- Hög
- högpresterande
- höggradigt
- värd
- Hur ser din drömresa ut
- Men
- html
- http
- HTTPS
- IAM
- ID
- idealisk
- identifierade
- identifiera
- Identitet
- bild
- bilder
- genomföra
- genomförande
- genomföras
- in
- innefattar
- innefattar
- Inklusive
- informationen
- Infrastruktur
- initiativ
- insikter
- integrera
- integrerade
- integrerar
- integrering
- interagera
- ingripande
- anropar
- involverade
- isolering
- IT
- DESS
- Jobb
- Lediga jobb
- jpg
- Ha kvar
- Nyckel
- nycklar
- Latens
- lager
- lärt
- inlärning
- Lärdomar
- Lärdomar
- Lets
- Nivå
- livscykel
- tycka om
- liten
- läsa in
- Låg
- Maskinen
- maskininlärning
- Huvudsida
- bibehålla
- upprätthåller
- underhåll
- göra
- hantera
- förvaltade
- ledning
- chef
- förvaltar
- hantera
- manuell
- Matris
- Minne
- nämnts
- meddelanden
- meddelandehantering
- Metrics
- kanske
- millisekund
- minuter
- ML
- MLOps
- modell
- modeller
- Modern Konst
- Övervaka
- övervakning
- mer
- mer effektiv
- multipel
- namn
- naturligt
- nödvändigt för
- Behöver
- Nya
- Nästa
- nlp
- Brus
- anmälan
- anmälningar
- antal
- of
- erbjuda
- Erbjudanden
- on
- ONE
- operativa
- operatörer
- optimerad
- Tillbehör
- iscensatt
- Organiserad
- Övriga
- utanför
- övergripande
- paket
- paket
- förpackning
- del
- passerar
- Förbi
- brinner
- bana
- prestanda
- tillstånd
- rörledning
- Planen
- Planes
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Strategier
- policy
- Inlägg
- praktiken
- Förutsägelser
- föregående
- Prioritera
- process
- Produkt
- Produktion
- projektet
- projekt
- rätt
- skydd
- förutsatt
- leverantör
- ger
- publicera
- publicerade
- publicerar
- publicering
- syfte
- kvalificerad
- område
- realtid
- Rekommendation
- Minskad
- avses
- registrerat
- register
- Förhållanden
- avlägsen
- känd
- Repository
- begärda
- förfrågningar
- Obligatorisk
- Krav
- forskning
- elastisk
- respons
- ansvarig
- Resultat
- omskolning
- återanvändbar
- roller
- Körning
- runner
- sagemaker
- Samma
- skalbar
- skalning
- tidtabellen
- planerad
- Forskare
- vetenskapsmän
- Andra
- sektioner
- Sektorer
- säkerhet
- senior
- separat
- Server
- Servrar
- service
- Tjänster
- portion
- in
- inställning
- skugga
- SKIFTANDE
- skall
- visas
- Enkelt
- slak
- So
- än så länge
- Mjukvara
- lösning
- Lösningar
- några
- Källa
- källkod
- specialist
- specifik
- specificerade
- Spektrum
- Spotlight
- Etapp
- stadier
- standard
- starta
- startar
- Stater
- Steg
- förvaring
- Strategi
- streaming
- effektivisera
- senare
- Framgångsrikt
- sådana
- stödja
- Som stöds
- yta
- System
- MÄRKA
- Ta
- uppgifter
- grupp
- mallar
- Terraform
- Testning
- den där
- Smakämnen
- deras
- Dem
- därför
- Dessa
- hot
- tre
- Genom
- hela
- genomströmning
- tid
- tidsstämpel
- till
- tillsammans
- alltför
- verktyg
- verktyg
- topp
- ämne
- spår
- Spårning
- varumärken
- trafik
- Tåg
- tränad
- Utbildning
- utlösa
- triggas
- SVÄNG
- under
- enhet
- United
- USA
- Uppdateringar
- us
- Användning
- användning
- användningsfall
- Användare
- användare
- BEKRÄFTA
- godkännande
- variabler
- olika
- version
- praktiskt taget
- syn
- visualisera
- vmware
- volym
- Sätt..
- VÄL
- Vad
- om
- som
- bred
- Brett utbud
- med
- inom
- utan
- Arbete
- arbetsflöde
- arbetsflöden
- fungerar
- skulle
- zephyrnet
- Postnummer
- zoner