Beskrivning
Att identifiera följande ord är uppgiften att förutsäga nästa ord, även känd som språkmodellering. En av NLPs referensuppgifter är språkmodellering. I sin mest grundläggande form innebär det att välja det ord som följer efter en sträng av ord baserat på dem som är mest sannolikt att förekomma. Inom många olika områden har språkmodellering en mängd olika tillämpningar.
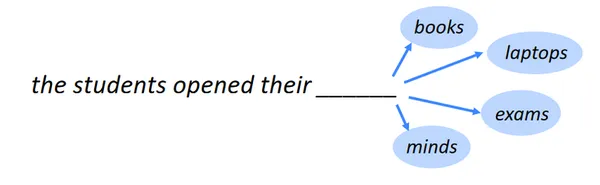
Lärande mål
- Erkänn de underliggande idéerna och principerna bakom de många modellerna som används inom statistisk analys, maskininlärning och datavetenskap.
- Lär dig hur du skapar prediktiva modeller, inklusive regression, klassificering, klustring, etc., för att generera exakta förutsägelser och typer baserat på data.
- Förstå principerna för över- och underanpassning, och lär dig hur du utvärderar modellprestanda med hjälp av mått som noggrannhet, precision, återkallelse, etc.
- Lär dig hur du förbearbetar data och identifierar relevanta egenskaper för modellering.
- Lär dig hur du justerar hyperparametrar och optimerar modeller med hjälp av rutnätssökning och korsvalidering.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Tillämpningar av språkmodellering
Här är några anmärkningsvärda tillämpningar av språkmodellering:
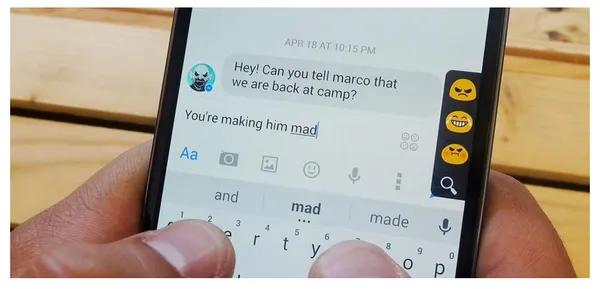
Mobilt tangentbord Textrekommendation
En funktion på smartphonetangentbord som kallas textrekommendation för mobiltangentbord, eller prediktiv text eller automatiska förslag, föreslår ord eller fraser medan du skriver. Det strävar efter att göra skrivning snabbare och mindre felbenägen och att erbjuda mer exakta och kontextuellt lämpliga rekommendationer.
Läs också: Bygga ett innehållsbaserat rekommendationssystem
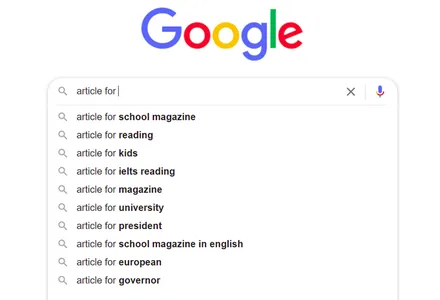
Automatisk komplettering av Google Sök
Varje gång vi använder en sökmotor som Google för att leta efter något får vi många idéer, och när vi fortsätter att lägga till fraser blir rekommendationerna bättre och mer relevanta för vår nuvarande sökning. Hur kommer det att hända då?
Natural Language Processing (NLP)-teknik gör det möjligt. Här kommer vi att använda naturlig språkbehandling (NLP) för att skapa en prediktionsmodell som använder en dubbelriktad LSTM-modell (Long short-term memory) för att förutsäga meningens återstående ord.
Läs mer: Vad är LSTM? Introduktion till långtidsminne
Importera nödvändiga bibliotek och paket
Att importera de nödvändiga biblioteken och paketen för att konstruera en prediktionsmodell för nästa ord med en dubbelriktad LSTM skulle vara bäst. Ett exempel på de bibliotek du vanligtvis behöver visas nedan:
import pandas as pd
import os
import numpy as np import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import AdamDatauppsättningsinformation
Att förstå funktionerna och attributen för datamängden du har att göra med kräver kunskap. Följande sju publikationers mediumartiklar, valda slumpmässigt och publicerade 2019, ingår i denna datauppsättning:
- Mot datavetenskap
- UX-kollektiv
- Uppstarten
- Författarkooperativet
- Datadriven investerare
- Bättre människor
- Bättre marknadsföring
Datasetlänk: https://www.kaggle.com/code/ysthehurricane/next-word-prediction-bi-lstm-tutorial-easy-way/input
medium_data = pd.read_csv('../input/medium-articles-dataset/medium_data.csv')
medium_data.head()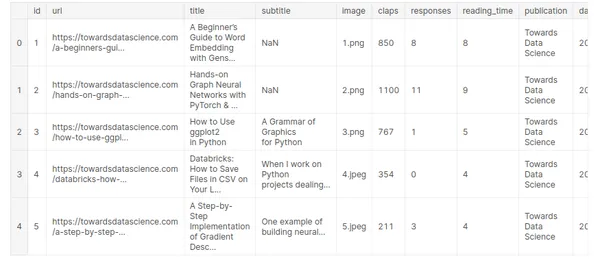
Här har vi tio olika fält och 6508 poster men vi kommer bara att använda titelfältet för att förutsäga nästa ord.
print("Number of records: ", medium_data.shape[0])
print("Number of fields: ", medium_data.shape[1])
Genom att titta igenom och förstå datauppsättningsinformationen kan du välja förbearbetningsprocedurer, modell och utvärderingsmått för din nästa ordförutsägelseutmaning.
Visa titlar på olika artiklar och förbearbeta dem
Låt oss ta en titt på några exempeltitlar för att illustrera beredningen av artikeltitlar:
medium_data['title']
Ta bort oönskade tecken och ord i titlar
Förbearbetning av textdata för prediktionsuppgifter inkluderar ibland att ta bort oönskade bokstäver och fraser från titlar. Oönskade bokstäver och ord kan förorena data med brus och lägga till onödig komplexitet, och därigenom sänka modellens prestanda och noggrannhet.
- Oönskade karaktärer:
- Skiljetecken: Du bör ta bort utropstecken, frågetecken, kommatecken och andra skiljetecken. Vanligtvis kan du säkert kassera dem eftersom de vanligtvis inte hjälper till med förutsägelseuppgiften
- Speciella karaktärer: Ta bort icke-alfanumeriska symboler, såsom dollartecken, @-symboler, hashtags och andra specialtecken, som är onödiga för prediktionsjobbet.
- HTML-taggar: Om titlarna har HTML-markeringar eller taggar, ta bort dem med hjälp av rätt verktyg eller bibliotek för att extrahera texten.
- Oönskade ord:
- Stoppord: Ta bort vanliga stoppord som "ett", "ett", "det", "är", "i" och andra ofta förekommande ord som inte har någon betydande betydelse eller prediktiv kraft.
- Irrelevanta ord: Identifiera och ta bort specifika ord som inte är relevanta för prediktionsuppgiften eller domänen. Om du till exempel förutsäger filmgenrer kanske ord som "film" eller "film" inte ger användbar information.
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace(u'xa0',u' '))
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace('u200a',' '))
tokenization
tokenization delar upp texten i tokens, ord, underord eller tecken och tilldelar sedan ett unikt ID eller index till varje token, vilket skapar ett ordindex eller ordförråd.
Tokeniseringsprocessen innefattar följande steg:
Textförbehandling: Förbearbeta texten genom att eliminera skiljetecken, ändra den till gemener och ta hand om särskilda uppgifts- eller domänspecifika behov.
tokenization: Dela upp den förbearbetade texten i separata tokens med förutbestämda regler eller metoder. Reguljära uttryck, separering med blanksteg och användning av specialiserade tokenizers är alla vanliga tokeniseringstekniker.
Öka ordförrådet Du kan skapa en ordbok, även kallad ett ordindex, genom att tilldela varje token ett unikt ID eller index. I denna process mappas varje biljett till det relevanta indexvärdet.
tokenizer = Tokenizer(oov_token='<oov>') # For those words which are not found in word_index
tokenizer.fit_on_texts(medium_data['title'])
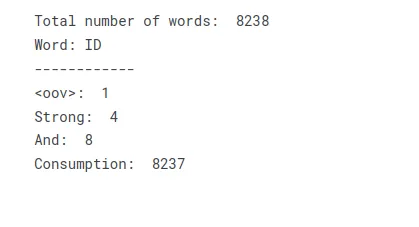
total_words = len(tokenizer.word_index) + 1 print("Total number of words: ", total_words)
print("Word: ID")
print("------------")
print("<oov>: ", tokenizer.word_index['<oov>'])
print("Strong: ", tokenizer.word_index['strong'])
print("And: ", tokenizer.word_index['and'])
print("Consumption: ", tokenizer.word_index['consumption'])Genom att omvandla text till ett ordförråd eller ordindex kan du skapa en uppslagstabell som representerar texten som en samling numeriska index. Varje unikt ord i texten får ett motsvarande indexvärde, vilket möjliggör ytterligare bearbetning eller modelleringsoperationer som kräver numerisk inmatning.
Titlar text i sekvenser och gör N_gram-modell.
Dessa steg kan användas för att bygga en n-gram-modell för exakt förutsägelse baserat på titelsekvenser:
- Konvertera titlar till sekvenser: Använd en tokenizer för att förvandla varje titel till en sträng av tokens eller manuellt separera varje slip i dess beståndsdelar. Tilldela varje ord i lexikonet ett distinkt nummerindex.
- Generera n-gram: Gör n-gram från sekvenserna. En kontinuerlig körning av n-titel-tokens kallas ett n-gram.
- Räkna frekvensen: Bestäm frekvensen med vilken varje n-gram visas i datamängden.
- Bygg n-gram-modellen: Skapa n-gram-modellen med hjälp av n-gram-frekvenserna. Modellen håller reda på varje tokens sannolikhet givet de tidigare n-1 tokens. Detta kan visas som en uppslagstabell eller en ordbok.
- Förutsäg nästa ord: Den förväntade nästa token i en n-1-token-sekvens kan identifieras med hjälp av n-gram-modellen. För att göra detta är det nödvändigt att hitta sannolikheten i algoritmen och välja en token med störst sannolikhet.
Läs mer: Vad är N-gram och hur man implementerar dem i Python?
Du kan använda dessa steg för att bygga en n-gram-modell som använder titlarnas sekvenser för att förutsäga nästa ord eller token. Baserat på träningsdata kan denna metod producera korrekta förutsägelser eftersom den fångar de statistiska sambanden och trenderna i titlarnas språkanvändning.

input_sequences = []
for line in medium_data['title']: token_list = tokenizer.texts_to_sequences([line])[0] #print(token_list) for i in range(1, len(token_list)): n_gram_sequence = token_list[:i+1] input_sequences.append(n_gram_sequence) # print(input_sequences)
print("Total input sequences: ", len(input_sequences))
Gör alla titlar till samma längd genom att använda stoppning
Du kan använda utfyllnad för att säkerställa att varje titel har samma storlek genom att följa dessa steg:
- Hitta den längsta titeln i din datauppsättning genom att jämföra alla andra titlar.
- Upprepa denna process för varje titel och jämför var och ens längd med den totala gränsen.
- När en titel är för kort bör den utökas med en specifik utfyllnadstoken eller tecken.
- Utför utfyllnadsproceduren igen för varje titel i din datauppsättning.
Utfyllnad säkerställer att alla titlar är lika långa och ger konsistens för efterbearbetning eller modellutbildning.
# pad sequences max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
input_sequences[1]
Förbered funktioner och etiketter
I det givna scenariot, om vi betraktar det sista elementet i varje ingångssekvens som etiketten, kan vi utföra en-hot-kodning på titlarna för att representera dem som vektorer som motsvarar det totala antalet unika ord.
# create features and label
xs, labels = input_sequences[:,:-1],input_sequences[:,-1]
ys = tf.keras.utils.to_categorical(labels, num_classes=total_words) print(xs[5])
print(labels[5])
print(ys[5][14])
Arkitekturen för dubbelriktat LSTM neurala nätverk
Återkommande neurala nätverk (RNN) med Long Short-Term Memory (LSTM) kan samla in och hålla information över omfattande sekvenser. LSTM-nätverk använder specialiserade minnesceller och grindtekniker för att övervinna begränsningarna hos vanliga RNN, som ofta kämpar med problemet med försvinnande gradienter och har problem med att upprätthålla ett långsiktigt beroende.
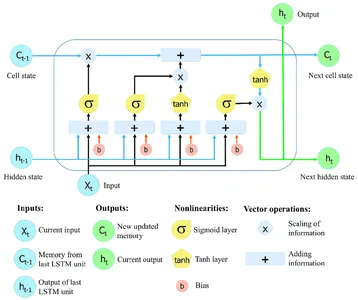
Den kritiska egenskapen hos LSTM-nätverk är celltillståndet, som fungerar som en minnesenhet som kan lagra information över tid. Celltillståndet skyddas och styrs av tre huvudgrindar: glömgrinden, ingångsgrinden och utgångsgrinden. Dessa grindar reglerar flödet av information in i, ut ur och inom LSTM-cellen, vilket gör att nätverket kan komma ihåg eller glömma information vid olika tidssteg selektivt.
Läs mer: Långt korttidsminne | Arkitektur av LSTM
Dubbelriktad LSTM
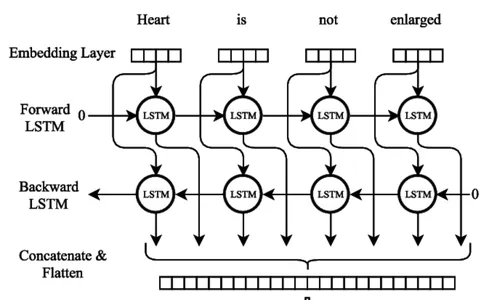
Bi-LSTM Neural Network Model utbildning
Många viktiga procedurer måste följas när du tränar en dubbelriktad LSTM (Bi-LSTM) neural nätverksmodell. Det första steget är att sammanställa en träningsdatauppsättning med in- och utdatasekvenser som motsvarar dem, vilket indikerar nästa ord. Textdata måste förbehandlas genom att delas upp i separata rader, ta bort skiljetecken och ändra skiftläge till gemener.
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(150)))
model.add(Dense(total_words, activation='softmax'))
adam = Adam(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
history = model.fit(xs, ys, epochs=50, verbose=1)
#print model.summary()
print(model)
Genom att anropa metoden fit() tränas modellen. Träningsdatan består av ingångssekvenserna (xs) och matchande utgångssekvenser (ys). Modellen fortsätter genom 50 iterationer och går igenom hela träningsuppsättningen. Under träningsprocessen visas träningsförloppet (verbose=1).
Plotta modell noggrannhet och förlust
Att plotta en modells noggrannhet och förlust under träning ger insiktsfull information om hur bra den presterar och hur träningen går. Felet eller skillnaden mellan de förväntade och faktiska värdena kallas förlust. Medan andelen exakta förutsägelser som genereras av modellen är känd som noggrannhet.
import matplotlib.pyplot as plt def plot_graphs(history, string): plt.plot(history.history[string]) plt.xlabel("Epochs") plt.ylabel(string) plt.show() plot_graphs(history, 'accuracy')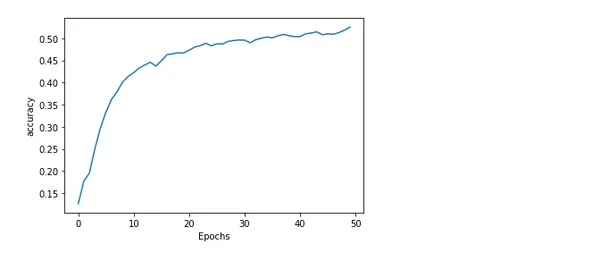
plot_graphs(history, 'loss')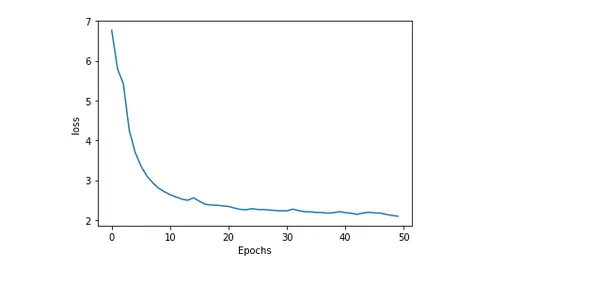
Förutsäga nästa ord i titeln
En fascinerande utmaning i naturlig språkbehandling är att gissa följande ord i en titel. Modeller kan föreslå det mest sannolika samtalet genom att leta efter mönster och samband i textdata. Denna prediktiva kraft gör applikationer som textförslagssystem och autoslutförande möjliga. Sofistikerade tillvägagångssätt som RNN:er och transformatorbaserade arkitekturer ökar noggrannheten och fångar kontextuella relationer.
seed_text = "implementation of"
next_words = 2 for _ in range(next_words): token_list = tokenizer.texts_to_sequences([seed_text])[0] token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre') predicted = model.predict_classes(token_list, verbose=0) output_word = "" for word, index in tokenizer.word_index.items(): if index == predicted: output_word = word break seed_text += " " + output_word
print(seed_text)
Slutsats
Sammanfattningsvis, att träna en modell för att förutsäga det efterföljande ordet i en sträng av ord är den spännande utmaningen med naturlig språkbehandling som kallas nästa ords förutsägelse med hjälp av en dubbelriktad LSTM. Här är slutsatsen sammanfattad i punktlistor:
- Den potenta djupinlärningsarkitekturen BI-LSTM för sekventiell databehandling kan fånga långdistansrelationer och fraskontext.
- För att förbereda råtextdata för BI-LSTM-utbildning är dataförberedelse väsentligt. Detta inkluderar tokenisering, vokabulärgenerering och textvektorisering.
- Att skapa en förlustfunktion, bygga modellen med en optimerare, anpassa den till förbehandlade data och bedöma dess prestanda på valideringsuppsättningar är stegen i träningen av BI-LSTM-modellen.
- BI-LSTM nästa ord förutsägelse kräver en kombination av teoretisk kunskap och praktiska experiment för att bemästra.
- Algoritmer för automatisk komplettering, skapande av språk och textförslag är exempel på tillämpningar för nästa ords prediktionsmodell.
Applikationer för nästa ords förutsägelse inkluderar chatbots, maskinöversättning och textkomplettering. Du kan skapa mer exakta och sammanhangsmedvetna modeller för nästa ords förutsägelse med mer forskning och förbättringar.
Vanliga frågor
S. Förutsägelse av nästa ord är en NLP-uppgift där en modell förutsäger det mest sannolika ordet att följa en given sekvens av ord eller sammanhang. Det syftar till att generera sammanhängande och kontextuellt relevanta förslag för nästa ord baserat på de mönster och relationer som lärts från träningsdata.
S. Förutsägelse av nästa ord använder vanligtvis återkommande neurala nätverk (RNN) och deras varianter, såsom Long Short-Term Memory (LSTM) och Gated Recurrent Unit (GRU). Dessutom har modeller som transformatorbaserade arkitekturer, såsom GPT-modellerna (Generative Pre-trained Transformer) också visat betydande framsteg i denna uppgift.
S. Vanligtvis, när du förbereder träningsdata för nästa ords förutsägelse, delar du upp text i ordsekvenser och skapar input-out-par. Motsvarande utdata representerar följande ord i texten för varje inmatningssekvens. Förbearbetning av texten innebär att ta bort skiljetecken, konvertera ord till gemener och tokenisera texten till enskilda ord.
S. Du kan utvärdera prestandan för en nästa ords prediktionsmodell med hjälp av utvärderingsmått som förvirring, noggrannhet eller top-k-noggrannhet. Förvirring mäter hur väl modellen förutsäger nästa ord givet sammanhanget. Noggrannhetsmätningar jämför det förutsagda ordet med grundsanningen, medan top-k-noggrannheten tar hänsyn till modellens förutsägelse inom de top-k mest sannolika kommentarerna.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Fordon / elbilar, Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- BlockOffsets. Modernisera miljökompensation ägande. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/07/next-word-prediction-with-bidirectional-lstm/
- : har
- :är
- :inte
- :var
- 1
- 100
- 13
- 14
- 20
- 2019
- 50
- 9
- a
- Om Oss
- noggrannhet
- exakt
- tvärs
- faktiska
- Adam
- lägga till
- tillsats
- Dessutom
- framsteg
- igen
- Syftet
- algoritm
- algoritmer
- Alla
- tillåta
- också
- an
- analys
- analytics
- Analys Vidhya
- och
- förväntad
- vilken som helst
- något
- tillämpningar
- tillvägagångssätt
- lämpligt
- arkitektur
- ÄR
- Artikeln
- artiklar
- AS
- frågade
- bedöma
- At
- attribut
- automatisk komplettering
- baserat
- grundläggande
- BE
- därför att
- bakom
- Där vi får lov att vara utan att konstant prestera,
- nedan
- riktmärke
- BÄST
- Bättre
- mellan
- bloggaton
- Ha sönder
- SLUTRESULTAT
- Byggnad
- men
- by
- kallas
- anropande
- KAN
- fånga
- fångar
- vilken
- bära
- Vid
- cellen
- Celler
- utmanar
- byte
- karaktär
- egenskaper
- tecken
- chatbots
- Välja
- klassificering
- klustring
- SAMMANHÄNGANDE
- samla
- samling
- kombination
- kommentarer
- Gemensam
- vanligen
- jämföra
- jämförande
- fullbordan
- Komplexiteten
- omfattande
- slutsats
- Tänk
- anser
- består
- beståndsdel
- begränsningar
- konstruera
- konsumtion
- sammanhang
- kontextuella
- kontinuerlig
- kontrolleras
- omvandling
- korrelationer
- Motsvarande
- skapa
- Skapa
- skapande
- kritisk
- avgörande
- Aktuella
- datum
- Förberedelse av data
- databehandling
- datavetenskap
- som handlar om
- djup
- djupt lärande
- tät
- beroende
- Bestämma
- olika
- diskretion
- Visa
- visas
- distinkt
- dividerat
- delar upp
- do
- Dollar
- domän
- inte
- driven
- under
- varje
- elementet
- eliminera
- inbäddning
- Motor
- säkerställa
- epoker
- väsentlig
- etc
- Eter (ETH)
- utvärdera
- utvärderade
- utvärdering
- exempel
- exempel
- spännande
- förväntat
- uttryck
- omfattande
- extrahera
- fascinerande
- snabbare
- möjlig
- Leverans
- Funktioner
- få
- fält
- Fält
- hitta
- Förnamn
- montering
- flöda
- följer
- följt
- efter
- följer
- För
- formen
- hittade
- Frekvens
- ofta
- från
- fungera
- ytterligare
- gated
- grindar
- allmänhet
- generera
- genereras
- generering
- generativ
- ges
- kommer
- Google Sök
- störst
- Rutnät
- Marken
- Väx
- styra
- praktisk
- hända
- Har
- hjälpa
- hjälp
- här.
- historia
- hålla
- Hur ser din drömresa ut
- How To
- html
- HTTPS
- i
- ID
- idéer
- identifierade
- identifiera
- if
- genomföra
- genomförande
- importera
- förbättring
- in
- innefattar
- ingår
- innefattar
- Inklusive
- Öka
- index
- index
- indikerar
- individuellt
- informationen
- ingång
- insiktsfull
- in
- Beskrivning
- innebär
- IT
- iterationer
- DESS
- Jobb
- Ha kvar
- Keras
- kunskap
- känd
- etikett
- Etiketter
- språk
- Efternamn
- skikt
- LÄRA SIG
- lärt
- inlärning
- Längd
- mindre
- bibliotek
- tycka om
- sannolikhet
- sannolikt
- BEGRÄNSA
- linje
- rader
- LINK
- Lång
- lång sikt
- se
- du letar
- slå upp
- förlust
- sänkning
- Maskinen
- maskininlärning
- maskinöversättning
- Huvudsida
- upprätthålla
- göra
- GÖR
- manuellt
- många
- Master
- Mastering
- matchande
- matplotlib
- Maj..
- betyder
- åtgärder
- Media
- Medium
- Minne
- metod
- metoder
- Metrics
- kanske
- misstag
- Mobil
- modell
- modellering
- modeller
- mer
- mest
- film
- måste
- Natural
- Naturligt språk
- Naturlig språkbehandling
- nödvändigt för
- onödigt
- behov
- nät
- nätverk
- neural
- neurala nätverk
- neurala nätverk
- Nästa
- nlp
- Brus
- anmärkningsvärd
- antal
- talrik
- numpy
- inträffa
- förekommande
- of
- erbjudanden
- Erbjudanden
- on
- ONE
- endast
- Verksamhet
- Optimera
- or
- OS
- Övriga
- vår
- ut
- produktion
- över
- övergripande
- Övervinna
- ägd
- paket
- vaddera
- par
- pandor
- del
- särskilt
- mönster
- procentuell
- utföra
- prestanda
- utför
- fraser
- plato
- Platon Data Intelligence
- PlatonData
- poäng
- möjlig
- kraft
- pre
- exakt
- Precision
- förutse
- förutsagda
- förutsäga
- förutsägelse
- Förutsägelser
- Förutspår
- beredning
- Förbered
- beredd
- förbereda
- föregående
- Principerna
- Sannolikheten
- Problem
- förfaranden
- förfaranden
- vinning
- process
- bearbetning
- producera
- Framsteg
- rätt
- föreslå
- skyddad
- ge
- publikationer
- publicerade
- Python
- fråga
- slumpmässig
- Raw
- Läsa
- motta
- erhåller
- Rekommendation
- rekommendationer
- register
- regression
- regelbunden
- Reglera
- Förhållanden
- relevanta
- Återstående
- ihåg
- ta bort
- bort
- representerar
- representerar
- representerar
- kräver
- Kräver
- forskning
- regler
- Körning
- på ett säkert sätt
- Samma
- scenario
- Vetenskap
- Sök
- sökmotor
- Söker
- vald
- separat
- separerande
- Sekvens
- serverar
- in
- uppsättningar
- sju
- Kort
- kortsiktigt
- skall
- visas
- signifikant
- Tecken
- eftersom
- Storlek
- smartphone
- några
- sofistikerade
- speciell
- specialiserad
- specifik
- delas
- stadier
- Ange
- statistisk
- Steg
- Steg
- Sluta
- lagra
- Sträng
- stark
- Kamp
- senare
- sådana
- Föreslår
- System
- bord
- tar
- tar
- Diskussion
- uppgift
- uppgifter
- tekniker
- Teknologi
- tio
- tensorflow
- termin
- den där
- Smakämnen
- deras
- Dem
- sedan
- teoretiska
- vari
- Dessa
- de
- detta
- de
- tre
- Genom
- hela
- biljett
- tid
- Titel
- titlar
- till
- token
- tokenization
- tokenizing
- tokens
- alltför
- verktyg
- Totalt
- spår
- tränad
- Utbildning
- transformator
- omvandla
- Översättning
- Trender
- problem
- sanningen
- SVÄNG
- typer
- typiskt
- underliggande
- unika
- enhet
- onödig
- oönskade
- Användning
- användning
- Begagnade
- användningar
- med hjälp av
- vanligen
- Återvinnare
- Använda
- godkännande
- värde
- Värden
- mängd
- olika
- var
- we
- webp
- VÄL
- Vad
- Vad är
- när
- medan
- som
- medan
- Hela
- bred
- kommer
- med
- inom
- ord
- ord
- skulle
- skriva
- skrivning
- X
- dig
- Din
- zephyrnet