Idag bygger, utbildar och implementerar tiotusentals kunder maskininlärningsmodeller (ML) med hjälp av Amazon SageMaker för att driva applikationer som har potential att återuppfinna deras verksamheter och kundupplevelser. Dessa ML-modeller har ökat i storlek och komplexitet under de senaste åren, vilket har lett till toppmoderna noggrannheter över en rad uppgifter och även förskjutit tiden att träna från dagar till veckor. Som ett resultat måste kunder skala sina modeller över hundratals till tusentals acceleratorer, vilket gör dem dyrare att träna.
SageMaker är en helt hanterad ML-tjänst som hjälper utvecklare och datavetare att enkelt bygga, träna och distribuera ML-modeller. SageMaker tillhandahåller redan det bredaste och djupaste urvalet av datorerbjudanden med hårdvaruacceleratorer för ML-träning, inklusive G5 (Nvidia A10G) instanser och P4d (Nvidia A100) instanser.
Ökande beräkningskrav kräver snabbare och mer kostnadseffektiv processorkraft. För att ytterligare minska modellutbildningstider och göra det möjligt för ML-utövare att iterera snabbare, har AWS förnyat sig över chips, servrar och datacenteranslutningar. De nya Trn1-instanserna drivs av AWS Trainium Chips erbjuder den bästa pris-prestanda och den snabbaste ML-modellutbildningen på AWS, vilket ger upp till 50 % lägre kostnad för att träna modeller för djupinlärning jämfört med jämförbara GPU-baserade instanser utan något fall i noggrannhet.
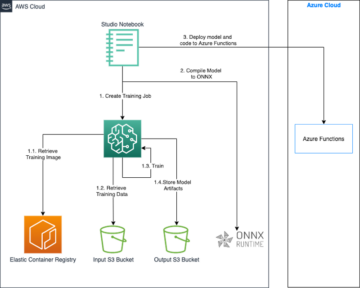
I det här inlägget visar vi hur du kan maximera din prestanda och minska kostnaderna med hjälp av Trn1-instanser med SageMaker.
Lösningsöversikt
SageMaker utbildningsjobb stödjer ml.trn1-instanser, drivna av Trainium-chips, som är specialbyggda för högpresterande ML-träningsapplikationer i molnet. Du kan använda ml.trn1-instanser på SageMaker för att träna naturlig språkbehandling (NLP), datorseende och rekommendationsmodeller över en bred uppsättning applikationer, såsom taligenkänning, rekommendation, bedrägeriupptäckt, bild- och videoklassificering och prognos. ml.trn1-instanserna har upp till 16 Trainium-chips, vilket är ett andra generationens ML-chip byggt av AWS efter AWS slutledning. ml.trn1-instanserna är de första Amazon Elastic Compute Cloud (Amazon EC2)-instanser med upp till 800 Gbps nätverksbandbredd för Elastic Fabric Adapter (EFA). För effektiv data- och modellparallellism har varje ml.trn1.32xl-instans 512 GB högbandbreddsminne, levererar upp till 3.4 petaflops FP16/BF16-beräkningskraft och har NeuronLink, en intra-instans, högbandbredd, icke-blockerande sammankoppling .
Trainium finns i två konfigurationer och kan användas i USA:s östra (N. Virginia) och USA:s västra (Oregon) regioner.
Följande tabell sammanfattar funktionerna i Trn1-instanserna.
| Förekomststorlek | trainium acceleratorer |
Accelerator Minne (GB) |
vCPU: er | Exempel Minne (GiB) |
nätverks Bandbredd (Gbps) |
EFA och RDMA Support |
| trn1.2xlarge | 1 | 32 | 8 | 32 | Upp till 12.5 | Nej |
| trn1.32xlarge | 16 | 512 | 128 | 512 | 800 | Ja |
| trn1n.32xlarge (kommer snart) | 16 | 512 | 128 | 512 | 1600 | Ja |
Låt oss förstå hur man använder Trainium med SageMaker med ett enkelt exempel. Vi kommer att träna en textklassificeringsmodell med SageMaker-träning och PyTorch med hjälp av Hugging Face Transformers Library.
Vi använder datasetet Amazon Recensioner, som består av recensioner från amazon.com. Uppgifterna sträcker sig över en period på 18 år och omfattar cirka 35 miljoner recensioner fram till mars 2013. Recensioner inkluderar produkt- och användarinformation, betyg och en recension i klartext. Följande kod är ett exempel från AmazonPolarity testset:
För det här inlägget använder vi bara innehålls- och etikettfälten. Innehållsfältet är en fritextrecension, och etikettfältet är ett binärt värde som innehåller 1 eller 0 för positiva respektive negativa recensioner.
För vår algoritm använder vi BERT, en transformatormodell förutbildad på en stor korpus av engelska data på ett självövervakat sätt. Denna modell är främst inriktad på att vara finjusterad på uppgifter som använder hela meningen (potentiellt maskerad) för att fatta beslut, såsom sekvensklassificering, tokenklassificering eller frågesvar.
Implementeringsdetaljer
Låt oss börja med att titta närmare på de olika komponenterna som är involverade i att träna modellen:
- AWS Trainium – I sin kärna, var och en Trainium exempel har Trainium-enheter inbyggda. Trn1.2xlarge har 1 Trainium-enhet och Trn1.32xlarge har 16 Trainium-enheter. Varje Trainium-enhet består av dator (2 NeuronCore-v2), 32 GB HBM-enhetsminne och NeuronLink för snabb kommunikation mellan enheter. Varje NeuronCore-v2 består av en helt oberoende heterogen beräkningsenhet med separata motorer (Tensor/Vector/Scalar/GPSIMD). GPSIMD är helt programmerbara generella processorer som du kan använda för att implementera anpassade operatörer och köra dem direkt på NeuronCore-motorerna.
- Amazon SageMaker utbildning – SageMaker ger en helt hanterad träningsupplevelse för att enkelt träna modeller utan att behöva oroa sig för infrastruktur. När du använder SageMaker Training kör den allt som behövs för ett träningsjobb, såsom kod, behållare och data, i en beräkningsinfrastruktur skild från anropsmiljön. Detta gör att vi kan köra experiment parallellt och iterera snabbt. SageMaker tillhandahåller en Python SDK att lansera utbildningsjobb. Exemplet i det här inlägget använder SageMaker Python SDK för att trigga träningsjobbet med Trainium.
- AWS Neuron – Eftersom Trainium NeuronCore har sin egen beräkningsmotor behöver vi en mekanism för att kompilera vår träningskod. De AWS Neuron kompilatorn tar koden skriven i Pytorch/XLA och optimerar den för att köras på Neuron-enheter. Neuron-kompilatorn är integrerad som en del av Deep Learning Container vi kommer att använda för att träna vår modell.
- PyTorch/XLA - Det här Python-paket använder XLA deep learning-kompilatorn för att koppla ihop PyTorchs djupinlärningsramverk och molnacceleratorer som Trainium. Att bygga ett nytt PyTorch-nätverk eller konvertera ett befintligt till att köras på XLA-enheter kräver bara några rader med XLA-specifik kod. Vi kommer att se för vårt användningsfall vilka ändringar vi behöver göra.
- Distribuerad utbildning – För att köra utbildningen effektivt på flera NeuronCores behöver vi en mekanism för att distribuera utbildningen till tillgängliga NeuronCores. SageMaker stöder torchrun med Trainium-instanser, som kan användas för att köra flera processer motsvarande antalet NeuronCores i klustret. Detta görs genom att skicka distributionsparametern till SageMaker-estimatorn enligt följande, vilket startar en dataparallellt distribuerad träning där samma modell laddas in i olika NeuronCores som bearbetar separata databatcher:
Skriptändringar behövs för att köras på Trainium
Låt oss titta på kodändringarna som behövs för att använda ett vanligt GPU-baserat PyTorch-skript för att köras på Trainium. På en hög nivå måste vi göra följande förändringar:
- Byt ut GPU-enheter med Pytorch/XLA-enheter. Eftersom vi använder ficklampsdistribution måste vi initiera träningen med XLA som enheten enligt följande:
- Vi använder PyTorch/XLA distribuerade backend för att överbrygga PyTorch distribuerade API:er till XLA kommunikationssemantik.
- Vi använder PyTorch/XLA MpDeviceLoader för pipelines för dataintag. MpDeviceLoader hjälper till att förbättra prestandan genom att överlappa tre steg: spårning, kompilering och databatchladdning till enheten. Vi måste linda PyTorch dataloader med MpDeviceDataLoader enligt följande:
- Kör optimeringssteget med hjälp av XLA-tillhandahållet API som visas i följande kod. Detta konsoliderar gradienterna mellan kärnor och utfärdar XLA-enhetens stegberäkning.
- Mappa CUDA API:er (om några) till generiska PyTorch API:er.
- Ersätt CUDA fused optimizers (om några) med generiska PyTorch-alternativ.
Hela exemplet, som tränar en textklassificeringsmodell med SageMaker och Trainium, finns i det följande GitHub repo. Anteckningsboken Finjustera transformatorer för att bygga klassificeringsmodeller med SageMaker och Trainium.ipynb är startpunkten och innehåller steg-för-steg-instruktioner för att genomföra utbildningen.
Benchmark-tester
I testet körde vi två träningsjobb: ett på ml.trn1.32xlarge och ett på ml.p4d.24xlarge med samma batchstorlek, träningsdata och andra hyperparametrar. Under utbildningsjobben mätte vi den fakturerbara tiden för SageMaker-utbildningsjobben och beräknade pris-prestanda genom att multiplicera tiden som krävs för att köra utbildningsjobb i timmar med priset per timme för instanstypen. Vi valde det bästa resultatet för varje instanstyp bland flera jobbkörningar.
Följande tabell sammanfattar våra benchmarkresultat.
| Modell | Typ av instans | Pris (per nod * timme) | Genomströmning (iterationer/sek) | Valideringsnoggrannhet | Fakturerbar tid (sek) | Utbildningskostnad i $ |
| BERT-basklassificering | ml.trn1.32xlarge | 24.725 | 6.64 | 0.984 | 6033 | 41.47 |
| BERT-basklassificering | ml.p4d.24xlarge | 37.69 | 5.44 | 0.984 | 6553 | 68.6 |
Resultaten visade att Trainium-instansen kostar mindre än P4d-instansen, vilket ger liknande genomströmning och precision när man tränar samma modell med samma indata och träningsparametrar. Detta innebär att Trainium-instansen levererar bättre pris-prestanda än GPU-baserade P4D-instanser. Med ett enkelt exempel som detta kan vi se att Trainium erbjuder cirka 22 % snabbare tid att träna och upp till 50 % lägre kostnad jämfört med P4d-instanser.
Distribuera den utbildade modellen
Efter att vi har tränat modellen kan vi distribuera den till olika instanstyper som CPU, GPU eller AWS Inferentia. Den viktigaste punkten att notera är att den tränade modellen inte är beroende av specialiserad hårdvara för att distribuera och dra slutsatser. SageMaker tillhandahåller mekanismer för att distribuera en tränad modell med både realtids- eller batchmekanismer. Notebook-exemplet i GitHub-repo innehåller kod för att distribuera den tränade modellen som en realtidsslutpunkt med hjälp av en ml.c5.xlarge (CPU-baserad) instans.
Slutsats
I det här inlägget tittade vi på hur man använder Trainium och SageMaker för att snabbt sätta upp och träna en klassificeringsmodell som ger upp till 50% kostnadsbesparingar utan att kompromissa med noggrannheten. Du kan använda Trainium för ett brett utbud av användningsfall som involverar förträning eller finjustering av transformatorbaserade modeller. För mer information om stöd för olika modellarkitekturer, se Riktlinjer för passning av modellarkitektur.
Om författarna
 Arun Kumar Lokanatha är senior ML Solutions Architect med Amazon SageMaker Service-teamet. Han fokuserar på att hjälpa kunder att bygga, träna och migrera ML-produktionsarbetsbelastningar till SageMaker i stor skala. Han är specialiserad på Deep Learning, särskilt inom området NLP och CV. Utanför jobbet tycker han om att springa och vandra.
Arun Kumar Lokanatha är senior ML Solutions Architect med Amazon SageMaker Service-teamet. Han fokuserar på att hjälpa kunder att bygga, träna och migrera ML-produktionsarbetsbelastningar till SageMaker i stor skala. Han är specialiserad på Deep Learning, särskilt inom området NLP och CV. Utanför jobbet tycker han om att springa och vandra.
 Mark Yu är mjukvaruingenjör i AWS SageMaker. Han fokuserar på att bygga distribuerade träningssystem i stor skala, optimera träningsprestanda och utveckla högpresterande ml-träningshårdvara, inklusive SageMaker trainium. Mark har också djupgående kunskaper om optimering av infrastruktur för maskininlärning. På fritiden tycker han om att vandra och springa.
Mark Yu är mjukvaruingenjör i AWS SageMaker. Han fokuserar på att bygga distribuerade träningssystem i stor skala, optimera träningsprestanda och utveckla högpresterande ml-träningshårdvara, inklusive SageMaker trainium. Mark har också djupgående kunskaper om optimering av infrastruktur för maskininlärning. På fritiden tycker han om att vandra och springa.
 Omri Fuchs är mjukvaruutvecklingschef på AWS SageMaker. Han är den tekniska ledaren som ansvarar för SageMakers utbildningsjobbplattform, med fokus på att optimera SageMakers träningsprestanda och förbättra träningsupplevelsen. Han har en passion för banbrytande ML- och AI-teknik. På fritiden gillar han att cykla och vandra.
Omri Fuchs är mjukvaruutvecklingschef på AWS SageMaker. Han är den tekniska ledaren som ansvarar för SageMakers utbildningsjobbplattform, med fokus på att optimera SageMakers träningsprestanda och förbättra träningsupplevelsen. Han har en passion för banbrytande ML- och AI-teknik. På fritiden gillar han att cykla och vandra.
 Gal Oshri är Senior Product Manager på Amazon SageMaker-teamet. Han har 7 års erfarenhet av att arbeta med maskininlärningsverktyg, ramverk och tjänster.
Gal Oshri är Senior Product Manager på Amazon SageMaker-teamet. Han har 7 års erfarenhet av att arbeta med maskininlärningsverktyg, ramverk och tjänster.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/maximize-performance-and-reduce-your-deep-learning-training-cost-with-aws-trainium-and-amazon-sagemaker/
- :är
- $UPP
- 1
- 100
- 7
- 8
- a
- A100
- Om oss
- acceleratorer
- noggrannhet
- tvärs
- anta
- Efter
- AI
- algoritm
- tillåter
- redan
- alternativ
- amason
- Amazon EC2
- Amazon SageMaker
- Amazon.com
- och
- api
- API: er
- tillämpningar
- cirka
- arkitektur
- ÄR
- OMRÅDE
- AS
- At
- tillgänglig
- AWS
- AWS slutledning
- backend
- Badrum
- Bandbredd
- bas
- BE
- därför att
- börja
- Där vi får lov att vara utan att konstant prestera,
- riktmärke
- BÄST
- Bättre
- mellan
- Bortom
- Stor
- Svart
- boken
- BRO
- SLUTRESULTAT
- Byggnad
- byggt
- företag
- by
- beräknat
- Samtal
- KAN
- Vid
- fall
- CD
- Centrum
- Förändringar
- chip
- Pommes frites
- val
- klassificering
- närmare
- cloud
- kluster
- koda
- COM
- kommande
- Coming Soon....
- Kommunikation
- jämförbar
- Komplexiteten
- komponenter
- komprometterande
- beräkning
- Compute
- dator
- Datorsyn
- konfigurationer
- Kontakta
- Anslutningar
- konsoliderar
- Behållare
- innehåller
- innehåll
- Kärna
- Pris
- kostnadsbesparingar
- kostnadseffektiv
- Kostar
- CPU
- beställnings
- kund
- Kunder
- allra senaste
- datum
- Data Center
- Dagar
- beslut
- djup
- djupt lärande
- djupaste
- levererar
- beroende
- distribuera
- utplacera
- ÖKEN
- Detektering
- utvecklare
- utveckla
- Utveckling
- anordning
- enheter
- olika
- direkt
- distribuera
- distribueras
- distribuerad utbildning
- fördelning
- Drop
- under
- varje
- lätt
- öster
- effektiv
- effektivt
- möjliggöra
- aktiverad
- Slutpunkt
- Motor
- ingenjör
- Motorer
- Engelska
- Hela
- Miljö
- Motsvarande
- speciellt
- Eter (ETH)
- allt
- exempel
- befintliga
- dyra
- erfarenhet
- Erfarenheter
- tyg
- Ansikte
- Mode
- SNABB
- snabbare
- snabbast
- Leverans
- Funktioner
- Med
- kvinna
- få
- fält
- Fält
- Fil
- Förnamn
- passa
- fokuserar
- fokusering
- efter
- följer
- För
- Ramverk
- ramar
- bedrägeri
- spårning av bedrägerier
- Fri
- från
- fullständigt
- ytterligare
- generell mening
- generering
- GitHub
- ger
- god
- GPU
- gradienter
- stor
- hårdvara
- Har
- har
- hjälpa
- hjälper
- dold
- Hög
- högpresterande
- vandring
- ÖPPETTIDER
- Hur ser din drömresa ut
- How To
- html
- http
- HTTPS
- Hundratals
- i
- bild
- genomföra
- förbättra
- förbättra
- in
- djupgående
- innefattar
- Inklusive
- ökande
- oberoende
- informationen
- Infrastruktur
- nyskapande
- ingång
- exempel
- instruktioner
- integrerade
- engagera
- involverade
- problem
- IT
- DESS
- Jobb
- Lediga jobb
- jpg
- Nyckel
- Döda
- kunskap
- etikett
- språk
- Large
- storskalig
- Efternamn
- lansera
- ledare
- inlärning
- Led
- Nivå
- Bibliotek
- livet
- tycka om
- rader
- läser in
- se
- såg
- älskar
- Maskinen
- maskininlärning
- gjord
- göra
- GÖR
- förvaltade
- chef
- Mars
- markera
- Materia
- Maximera
- betyder
- mekanism
- Minne
- migrera
- miljon
- ML
- modell
- modeller
- humör
- mer
- multipel
- multiplicerande
- Natural
- Naturligt språk
- Naturlig språkbehandling
- Behöver
- behövs
- negativ
- nät
- Nya
- nlp
- nod
- anteckningsbok
- antal
- Nvidia
- of
- erbjudanden
- offer~~POS=TRUNC
- Erbjudanden
- Gamla
- on
- ONE
- operatörer
- optimering
- optimerar
- optimera
- Oregon
- Övriga
- utanför
- egen
- Parallell
- parameter
- parametrar
- del
- Förbi
- brinner
- prestanda
- perioden
- Oformatterad text
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Spela
- Punkt
- positiv
- Inlägg
- potentiell
- potentiellt
- kraft
- drivs
- pris
- primärt
- process
- processer
- bearbetning
- Process kraft
- processorer
- Produkt
- produktchef
- Produktion
- ger
- tillhandahålla
- Syftet
- Tryckande
- Python
- pytorch
- fråga
- snabbt
- REGN
- område
- betyg
- realtid
- erkännande
- Rekommendation
- minska
- regioner
- regelbunden
- Obligatorisk
- Krav
- Kräver
- ansvarig
- resultera
- Resultat
- översyn
- Omdömen
- Körning
- rinnande
- s
- sagemaker
- Samma
- Besparingar
- säger
- Skala
- vetenskapsmän
- sDK
- SEC
- vald
- semantik
- senior
- mening
- separat
- Sekvens
- Servrar
- service
- Tjänster
- in
- show
- visas
- liknande
- Enkelt
- Storlek
- Mjukvara
- mjukvaruutveckling
- Programvara ingenjör
- Lösningar
- Alldeles strax
- spann
- specialiserad
- specialiserat
- tal
- Taligenkänning
- startar
- state-of-the-art
- Steg
- Steg
- Fortfarande
- sådana
- stödja
- Stöder
- System
- bord
- tar
- tar
- uppgifter
- grupp
- Teknisk
- Teknologi
- testa
- Textklassificering
- den där
- Smakämnen
- Området
- deras
- Dem
- Dessa
- sak
- tusentals
- tre
- genomströmning
- tid
- gånger
- Titel
- till
- token
- verktyg
- brännaren
- spåra
- Tåg
- tränad
- Utbildning
- tåg
- transformatorer
- utlösa
- typer
- förstå
- enhet
- us
- användning
- användningsfall
- Användare
- värde
- olika
- Video
- Virginia
- syn
- RÖSTER
- veckor
- väster
- Vad
- som
- vit
- VEM
- bred
- Brett utbud
- kommer
- med
- utan
- Arbete
- arbetssätt
- linda
- skriven
- år
- ung
- Din
- zephyrnet