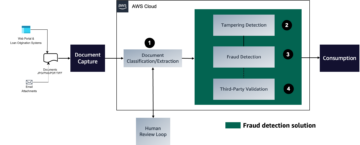
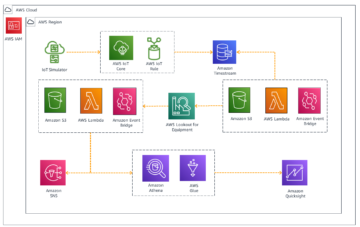
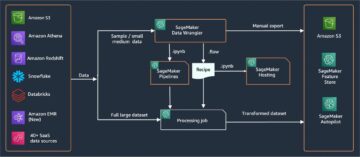
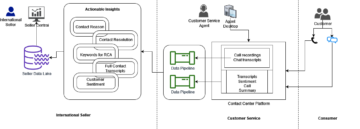
Amazon SageMaker ger en svit av inbyggda algoritmer, förutbildade modelleroch färdigbyggda lösningsmallar för att hjälpa datavetare och utövare av maskininlärning (ML) komma igång med utbildning och implementering av ML-modeller snabbt. Du kan använda dessa algoritmer och modeller för både övervakat och oövervakat lärande. De kan bearbeta olika typer av indata, inklusive tabell, bild och text.
Från och med idag tillhandahåller SageMaker fyra nya inbyggda algoritmer för tabelldatamodellering: LightGBM, CatBoost, AutoGluon-Tabular och TabTransformer. Du kan använda dessa populära, toppmoderna algoritmer för både tabellklassificering och regressionsuppgifter. De är tillgängliga via inbyggda algoritmer på SageMaker-konsolen såväl som via Amazon SageMaker JumpStart UI inuti Amazon SageMaker Studio.
Följande är listan över de fyra nya inbyggda algoritmerna, med länkar till deras dokumentation, exempel på anteckningsböcker och källa.
| Dokumentation | Exempel på anteckningsböcker | Källa |
| LightGBM-algoritm | Regression, Klassificering | LightGBM |
| CatBoost-algoritm | Regression, Klassificering | CatBoost |
| AutoGluon-tabellalgoritm | Regression, Klassificering | AutoGluon-tabell |
| TabTransformer-algoritm | Regression, Klassificering | TabTransformer |
I följande avsnitt ger vi en kort teknisk beskrivning av varje algoritm, och exempel på hur man tränar en modell via SageMaker SDK eller SageMaker Jumpstart.
LightGBM
LightGBM är en populär och effektiv implementering med öppen källkod av algoritmen Gradient Boosting Decision Tree (GBDT). GBDT är en övervakad inlärningsalgoritm som försöker att exakt förutsäga en målvariabel genom att kombinera en ensemble av uppskattningar från en uppsättning enklare och svagare modeller. LightGBM använder ytterligare tekniker för att avsevärt förbättra effektiviteten och skalbarheten hos konventionell GBDT.
CatBoost
CatBoost är en populär och högpresterande öppen källkodsimplementering av GBDT-algoritmen. Två kritiska algoritmiska framsteg introduceras i CatBoost: implementeringen av ordnad boosting, ett permutationsdrivet alternativ till den klassiska algoritmen och en innovativ algoritm för bearbetning av kategoriska funktioner. Båda teknikerna skapades för att bekämpa en förutsägelseförskjutning orsakad av en speciell typ av målläckage som finns i alla för närvarande existerande implementeringar av gradientförstärkningsalgoritmer.
AutoGluon-tabell
AutoGluon-tabell är ett AutoML-projekt med öppen källkod utvecklat och underhållet av Amazon som utför avancerad databearbetning, djupinlärning och stackensembling i flera lager. Den känner automatiskt igen datatypen i varje kolumn för robust dataförbehandling, inklusive speciell hantering av textfält. AutoGluon passar olika modeller, allt från träd som är förstärkta från hyllan till anpassade neurala nätverksmodeller. Dessa modeller är sammansatta på ett nytt sätt: modeller staplas i flera lager och tränas på ett lagervis sätt som garanterar att rådata kan översättas till högkvalitativa förutsägelser inom en given tidsbegränsning. Överanpassning mildras under hela denna process genom att dela upp data på olika sätt med noggrann spårning av exemplen utanför vikningen. AutoGluon är optimerat för prestanda, och dess out-of-the-box användning har uppnått flera topp-3 och topp-10 positioner i datavetenskapstävlingar.
TabTransformer
TabTransformer är en ny djup tabellformad datamodelleringsarkitektur för övervakat lärande. TabTransformer är byggd på självuppmärksamhetsbaserade transformatorer. Transformatorlagren omvandlar inbäddningar av kategoriska egenskaper till robusta kontextuella inbäddningar för att uppnå högre förutsägningsnoggrannhet. Dessutom är de kontextuella inbäddningar som lärts av TabTransformer mycket robusta mot både saknade och brusiga datafunktioner och ger bättre tolkningsmöjligheter. Denna modell är en produkt från senaste tiden Amazon Science forskning (papper och officiell blogginlägg här) och har antagits allmänt av ML-gemenskapen, med olika implementeringar från tredje part (Keras, AutoGluon,) och funktioner för sociala medier som t.ex tweets, mot datavetenskap, medium och Kaggle.
Fördelar med SageMaker inbyggda algoritmer
När du väljer en algoritm för din speciella typ av problem och data är det enklaste alternativet att använda en SageMaker inbyggd algoritm, eftersom att göra det kommer med följande stora fördelar:
- De inbyggda algoritmerna kräver ingen kodning för att starta experiment. De enda indata du behöver tillhandahålla är data, hyperparametrar och beräkningsresurser. Detta gör att du kan köra experiment snabbare, med mindre omkostnader för att spåra resultat och kodändringar.
- De inbyggda algoritmerna kommer med parallellisering över flera beräkningsinstanser och GPU-stöd direkt från lådan för alla tillämpliga algoritmer (vissa algoritmer kanske inte ingår på grund av inneboende begränsningar). Om du har mycket data att träna din modell med kan de flesta inbyggda algoritmer enkelt skalas för att möta efterfrågan. Även om du redan har en förtränad modell kan det fortfarande vara lättare att använda dess följd i SageMaker och mata in de hyperparametrar du redan känner till istället för att överföra den och skriva ett träningsskript själv.
- Du är ägaren till de resulterande modellartefakterna. Du kan ta den modellen och distribuera den på SageMaker för flera olika slutledningsmönster (kolla in alla tillgängliga distributionstyper) och enkel slutpunktsskalning och hantering, eller så kan du distribuera den var du än behöver den.
Låt oss nu se hur man tränar en av dessa inbyggda algoritmer.
Träna en inbyggd algoritm med SageMaker SDK
För att träna en utvald modell måste vi få den modellens URI, såväl som för träningsskriptet och behållarbilden som används för träning. Tack och lov beror dessa tre ingångar enbart på modellnamnet, versionen (för en lista över tillgängliga modeller, se JumpStart Tillgänglig modelltabell), och vilken typ av instans du vill träna på. Detta visas i följande kodavsnitt:
Smakämnen train_model_id ändras till lightgbm-regression-model om vi har att göra med ett regressionsproblem. ID:n för alla andra modeller som introduceras i det här inlägget listas i följande tabell.
| Modell | Problemtyp | Modell-ID |
| LightGBM | Klassificering | lightgbm-classification-model |
| . | Regression | lightgbm-regression-model |
| CatBoost | Klassificering | catboost-classification-model |
| . | Regression | catboost-regression-model |
| AutoGluon-tabell | Klassificering | autogluon-classification-ensemble |
| . | Regression | autogluon-regression-ensemble |
| TabTransformer | Klassificering | pytorch-tabtransformerclassification-model |
| . | Regression | pytorch-tabtransformerregression-model |
Vi definierar sedan var vår input är på Amazon enkel lagringstjänst (Amazon S3). Vi använder en offentlig exempeldatauppsättning för det här exemplet. Vi definierar också vart vi vill att vår utdata ska gå och hämtar standardlistan med hyperparametrar som behövs för att träna den valda modellen. Du kan ändra deras värde efter eget tycke.
Slutligen instansierar vi en SageMaker Estimator med alla hämtade ingångar och lansera träningsjobbet med .fit, skickar det vår träningsdatauppsättning URI. De entry_point skriptet som tillhandahålls heter transfer_learning.py (samma för andra uppgifter och algoritmer), och indatakanalen skickas till .fit måste namnges training.
Observera att du kan träna inbyggda algoritmer med SageMaker automatisk modelljustering för att välja de optimala hyperparametrarna och ytterligare förbättra modellens prestanda.
Träna en inbyggd algoritm med SageMaker JumpStart
Du kan också träna alla dessa inbyggda algoritmer med några få klick via SageMaker JumpStart UI. JumpStart är en SageMaker-funktion som låter dig träna och distribuera inbyggda algoritmer och förtränade modeller från olika ML-ramverk och modellhubbar genom ett grafiskt gränssnitt. Det låter dig också distribuera fullfjädrade ML-lösningar som sammanfogar ML-modeller och olika andra AWS-tjänster för att lösa ett målinriktat användningsfall.
Mer information finns i Kör textklassificering med Amazon SageMaker JumpStart med TensorFlow Hub och Hugging Face-modeller.
Slutsats
I det här inlägget tillkännagav vi lanseringen av fyra kraftfulla nya inbyggda algoritmer för ML på tabelluppsättningar som nu är tillgängliga på SageMaker. Vi gav en teknisk beskrivning av vad dessa algoritmer är, samt ett exempel på utbildningsjobb för LightGBM med SageMaker SDK.
Ta med din egen datauppsättning och prova dessa nya algoritmer på SageMaker, och kolla in exempel på anteckningsböcker för att använda inbyggda algoritmer tillgängliga på GitHub.
Om författarna
![]() Dr Xin Huang är en tillämpad forskare för Amazon SageMaker JumpStart och Amazon SageMaker inbyggda algoritmer. Han fokuserar på att utveckla skalbara maskininlärningsalgoritmer. Hans forskningsintressen är inom området naturlig språkbehandling, förklarlig djupinlärning på tabelldata och robust analys av icke-parametrisk rum-tid-klustring. Han har publicerat många artiklar i ACL, ICDM, KDD-konferenser och Royal Statistical Society: Series A journal.
Dr Xin Huang är en tillämpad forskare för Amazon SageMaker JumpStart och Amazon SageMaker inbyggda algoritmer. Han fokuserar på att utveckla skalbara maskininlärningsalgoritmer. Hans forskningsintressen är inom området naturlig språkbehandling, förklarlig djupinlärning på tabelldata och robust analys av icke-parametrisk rum-tid-klustring. Han har publicerat många artiklar i ACL, ICDM, KDD-konferenser och Royal Statistical Society: Series A journal.
![]() Dr Ashish Khetan är en Senior Applied Scientist med Amazon SageMaker JumpStart och Amazon SageMaker inbyggda algoritmer och hjälper till att utveckla maskininlärningsalgoritmer. Han är en aktiv forskare inom maskininlärning och statistisk slutledning och har publicerat många artiklar i NeurIPS, ICML, ICLR, JMLR, ACL och EMNLP-konferenser.
Dr Ashish Khetan är en Senior Applied Scientist med Amazon SageMaker JumpStart och Amazon SageMaker inbyggda algoritmer och hjälper till att utveckla maskininlärningsalgoritmer. Han är en aktiv forskare inom maskininlärning och statistisk slutledning och har publicerat många artiklar i NeurIPS, ICML, ICLR, JMLR, ACL och EMNLP-konferenser.
 João Moura är en AI/ML Specialist Solutions Architect på Amazon Web Services. Han är mest fokuserad på NLP-användningsfall och att hjälpa kunder att optimera utbildning och implementering av Deep Learning-modeller. Han är också en aktiv förespråkare för ML-lösningar med låg kod och ML-specialiserad hårdvara.
João Moura är en AI/ML Specialist Solutions Architect på Amazon Web Services. Han är mest fokuserad på NLP-användningsfall och att hjälpa kunder att optimera utbildning och implementering av Deep Learning-modeller. Han är också en aktiv förespråkare för ML-lösningar med låg kod och ML-specialiserad hårdvara.
- Myntsmart. Europas bästa bitcoin- och kryptobörs.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. FRI TILLGÅNG.
- CryptoHawk. Altcoin radar. Gratis provperiod.
- Källa: https://aws.amazon.com/blogs/machine-learning/new-built-in-amazon-sagemaker-algorithms-for-tabular-data-modeling-lightgbm-catboost-autogluon-tabular-and-tabtransformer/
- "
- 100
- a
- Uppnå
- uppnås
- tvärs
- aktiv
- Annat
- avancerat
- framsteg
- mot
- algoritm
- algoritmisk
- algoritmer
- Alla
- tillåter
- redan
- alternativ
- amason
- Amazon Web Services
- analys
- meddelade
- tillämplig
- tillämpas
- arkitektur
- OMRÅDE
- Automat
- automatiskt
- tillgänglig
- AWS
- därför att
- Fördelarna
- Bättre
- ökat
- öka
- Box
- inbyggd
- noggrann
- Vid
- orsakas
- byta
- klassiska
- klassificering
- koda
- Kodning
- Kolumn
- komma
- samfundet
- Tävlingar
- Compute
- konferenser
- Konsol
- Behållare
- skapa
- skapas
- kritisk
- För närvarande
- beställnings
- Kunder
- datum
- databehandling
- datavetenskap
- som handlar om
- Beslutet
- djup
- Efterfrågan
- demonstreras
- distribuera
- utplacera
- utplacering
- beskrivning
- utveckla
- utvecklade
- utveckla
- olika
- Hamnarbetare
- varje
- lätt
- effektivitet
- effektiv
- Slutpunkt
- uppskattningar
- exempel
- exempel
- befintliga
- Ansikte
- Leverans
- Funktioner
- Fält
- fokuserade
- fokuserar
- efter
- ramar
- från
- ytterligare
- Vidare
- GPU
- Arbetsmiljö
- hårdvara
- höjd
- hjälpa
- hjälpa
- hjälper
- här.
- hög kvalitet
- högre
- höggradigt
- Hur ser din drömresa ut
- How To
- HTTPS
- Nav
- bild
- genomförande
- förbättra
- ingår
- Inklusive
- informationen
- inneboende
- innovativa
- ingång
- exempel
- intressen
- Gränssnitt
- IT
- Jobb
- tidskriften
- Vet
- språk
- lansera
- lärt
- inlärning
- länkar
- Lista
- Noterade
- Maskinen
- maskininlärning
- större
- ledning
- sätt
- Media
- Medium
- ML
- modell
- modeller
- mer
- mest
- multipel
- Natural
- nät
- Optimera
- optimerad
- Alternativet
- Övriga
- egen
- ägaren
- särskilt
- Förbi
- prestanda
- Populära
- den mäktigaste
- förutse
- förutsägelse
- Förutsägelser
- presentera
- Problem
- process
- bearbetning
- Produkt
- projektet
- ge
- förutsatt
- ger
- allmän
- publicerade
- snabbt
- som sträcker sig
- Raw
- erkänner
- region
- kräver
- forskning
- Resurser
- resulterande
- Resultat
- Körning
- rinnande
- Samma
- skalbarhet
- skalbar
- Skala
- skalning
- Vetenskap
- Forskare
- vetenskapsmän
- sDK
- vald
- Serier
- Serie A
- Tjänster
- in
- flera
- skifta
- Enkelt
- So
- Social hållbarhet
- sociala medier
- Samhället
- lösning
- Lösningar
- LÖSA
- några
- speciell
- specialist
- stapel
- starta
- igång
- state-of-the-art
- statistisk
- Fortfarande
- förvaring
- stödja
- Målet
- riktade
- uppgifter
- Teknisk
- tekniker
- Smakämnen
- tredje part
- tre
- Genom
- hela
- tid
- i dag
- tillsammans
- Spårning
- Tåg
- Utbildning
- Förvandla
- typer
- ui
- unika
- användning
- användarfall
- värde
- olika
- version
- sätt
- webb
- webbservice
- Vad
- inom
- Din