Har du någonsin väntat på det där dyra paketet som visar "levererat", men du har ingen aning om var det är? Spårningshistoriken slutade uppdateras för fem dagar sedan, och du har nästan tappat hoppet. Men vänta, 11 dagar senare har du den vid din dörr. Du önskade att spårbarheten kunde ha varit bättre för att befria dig från all orolig väntan. Det är här "observerbarhet" kommer in i bilden.
I ett tekniskt landskap skulle du vilja undvika att detta händer med din programvara eller datasystem. Och därmed använder du övervakningsverktyg som samlar in loggar och mätvärden för dina system och informerar dig om deras interna tillstånd. Övervakning fungerar bäst när du vill att dina system ska informera dig om vad felet är, var och när det hände, men den säger inte hur du ska lösa felet.
För mer än ett decennium sedan saknade övervakningsverktyg sammanhanget och förutseendet för underliggande systemproblem och team skulle vara begränsade till att felsöka dagliga operativa fel. Idag arbetar och lever vi i en distribuerad värld av mikrotjänster och datapipelines; ens att använda flera övervakningsverktyg hjälper dig inte svara på dina affärsfrågor som "Varför är min ansökan alltid långsam?" eller "I vilket skede uppstod problemet och hur djupt ligger det i högen?" eller "Hur kan jag förbättra miljöns övergripande prestanda?" Det blir nödvändigt att vara proaktiv i att fatta dessa beslut och ha en övergripande synlighet av dina system, applikationer och data.
Denna blogginlägg av Etsy publicerades för ett decennium sedan, och den anger själva faktum i andra stycket:
"Applikationsmått är vanligtvis det svåraste, men ändå viktigaste, av de tre. De är mycket specifika för din verksamhet och de förändras när dina applikationer förändras (och Etsy förändras mycket)."
Så, hur mäter vi allt och vad som helst? Vi börjar med observerbarhet.
Vad är observerbarhet?
Termen "observerbarhet" var myntade av Rudolf Emil Kálmán 1960 i hans ingenjörsuppsats för att beskriva matematiska styrsystem. Han definierade det som ett mått på hur väl interna tillstånd i ett system kan härledas från kunskap om dess externa utdata. Men låter det inte som övervakning? I grund och botten, ja, det är övervakning.
Dessa dagar har observerbarhet blivit ett ganska hett ämne. Enligt flera marknadsundersökningar är det en miljardplattform. Många organisationer har anammat konceptet och använt det som ett ramverk för synlighet från slut till ände av sina distribuerade system och pipelines. Observerbarhet förväxlas dock med övervakning. För nu kan jag säga att övervakning är en delmängd av observerbarhet, där observerbarhet är ett enda stort paraplybegrepp.
Observerbarhet möjliggör distribuerad spårning genom att samla in och aggregera spår, loggar och mätvärden. Låt oss se vad dessa drar slutsatsen:
- Spår: När ett system tar emot en förfrågan berättar spåren hur den förfrågan flyter, under hela dess livscykel, från källan till destinationen. Spår representeras av "spann". Ett spår är ett träd av spann, och ett span är en enda operation inom ett spår. De hjälper dig att hitta fel, latens eller flaskhalsar i systemet.
- loggar: Dessa är maskingenererade tidsstämplade händelser som berättar om operationerna eller förändringarna som hände i systemet. Loggar används ofta för att söka efter dessa fel eller ändringar i systemet.
- Metrik: Dessa ger kvantitativa insikter om CPU, minne, diskanvändning och hur systemet presterar över en tidsperiod.
Dessa attribut förbättrar övervakningsramen med spårbarhet. Spårbarhet ger dig linserna för att spåra en begäran som gör ett anrop till ditt system, hur lång tid det tar att gå från en komponent till en annan, vilka andra tjänster den anropar, ger den något fel, vilka loggar den producerar, vilket tillstånd det är i, när började det och slutade det, vilken tidslinje den stannade i ditt system, etc. När du samlar in, aggregerar och analyserar dessa spår kan du fatta värdefulla välgrundade beslut som kundens tidslinje på en e-handelswebbplats , hur lång tid det tog dem att söka efter en produkt, hur lång tid de tittade på produkten, laddade HTML-sidan in alla detaljer som bilder eller inbäddade videor, hur lång tid det tog för systemet att autentisera och behandla betalningen, etc.
Vad uppnår vi med observerbarhet i en distribuerad miljö?
Utvecklingen av distribuerade system började när organisationer började gå bort från sin centraliserade monolitarkitektur till en distribuerad och decentraliserad mikrotjänstarkitektur. Och detta är fortfarande ett pågående arbete där många organisationer omfamnar mikroservicekaraktären hos system och applikationer. Och allt detta kan tillskrivas stora uppgifter och skalning. Att hantera en distribuerad miljö kräver kontinuerligt lärande, ytterligare arbetskraft, förändringar i ramverk och policyer, IT-hantering och så vidare. Det är verkligen en stor förändring.
Tidigare, i den begränsade monolitiska miljön, levde hårdvara, mjukvara, data och databaser alla under ett enda tak. Med tillkomsten av big data på 2000-talet började övervaknings- och skalsystem att bli ett stort problem. Ofta använde organisationer olika övervakningsverktyg för att tillgodose behoven för deras olika applikationer. Som ett resultat blev det snart en operativ overhead med dålig spänst, synlighet och tillförlitlighet.
Alla dessa frågor gav upphov till antagandet av observerbarhet. Idag finns det flera observerbarhetsverktyg för säkerhet, nätverk, applikationer och datapipelines för distribuerad spårning i en komplex miljö. De samexisterar med sin kusin, övervakningsverktygen, och tar hävstången genom att samla in informationen från sin kusin och aggregera med ytterligare information från sin egen spårningsdata.
Det finns många rörliga komponenter i alla dessa system, vars spår när de fångas kan illustrera historien om de 5 Ws: när, var, varför, vad och hur. Du går till exempel in på DATAVERSITYs hemsida klockan 1:43 för att läsa några blogginlägg. När du träffar dataversity.net loggas HTTP-förfrågan in i systemet. Du börjar söka efter ett blogginlägg och går till ett Data Governance-inlägg, där du spenderar 17 minuter på att läsa det inlägget och sedan stänger du din flik klockan 2:00
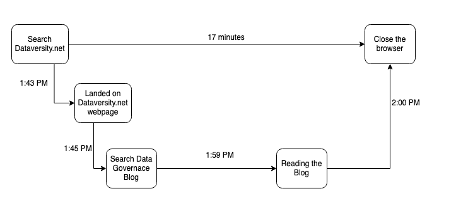
Det kommer också att göras andra anrop till nätverkssystemet för nätverkspaketfångning också. Observerbarhetsverktyg samlar alla spann och förenar dem i ett spår eller spår, vilket gör att du kan se vägen den bildade under sin livscykel. Om du har ett problem som nätverkslatens eller ett systemfel är det nu lättare att dissekera (skala löken) och felsöka problemet (fel i vilket lager).
Nu i en stor distribuerad miljö, när dina applikationer får miljontals förfrågningar, växer spårningsdata i enorma volymer. Att samla in och analysera dessa spår är dyrt för lagringsförbrukning och dataöverföring. Så, för att spara kostnader, samplas spårningsdata, eftersom ingenjörsteam i de flesta fall behöver bara några av delarna för att undersöka vad som gick fel eller vad som är felmönstret.
Med det lilla exemplet förstår vi att vi får mycket djupare insikter i våra system. Så, med tanke på en större skala av system, kan ingenjörsteam fånga in och arbeta med samplade data för att förbättra systemets nuvarande struktur, tillämpa eller ta bort nya komponenter, lägga till ytterligare ett säkerhetslager, ta bort flaskhalsar och så vidare.
Bör organisationer välja observerbarhet?
Vi borde alla förstå att slutmålen är bättre användarupplevelse och större användarnöjdhet. Och vägen till att uppnå dessa mål kan göras enklare med ett automatiserat och proaktivt observerbarhetsramverk. Att etablera en kultur av ständig förbättring och optimering anses vara den optimala affärs- och ledarskapsstrategin.
I denna tid av digital transformation har observerbarhet blivit ett måste för att ett företag ska bli framgångsrikt i sin digitala resa. Genom att ge dig insiktsfulla spår, manövrerar observerbarhet dig också till att vara datainformerad snarare än bara datadriven.
Slutsats
Även om vi har använt termerna övervakning och observerbarhet omväxlande, har vi sett att även om övervakning hjälper dig med information om systemets tillstånd och händelser som händer på det, underlättar observerbarhet dig att dra slutsatser baserade på bevis som samlats in från djupare lager av ett slut- to-end miljö.
Observerbarhet är och kan också uppfattas som en komponent i Data Governance-ramverket. I den här generationen, där den ständigt ökande datavolymen finns i ett nätverk av råvaruhårdvara, är det viktigt att hålla arkitekturerna så enkla som möjligt. Och uppenbarligen blir det en omöjlig uppgift att hantera miljön längs linjen. Genom att implementera lämpliga och automatiserade förvaltningspolicyer och regler för att hålla ditt stora nätverk av system, pipelines och data renad kräver åtgärder förr än senare.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.dataversity.net/observability-traceability-for-distributed-systems/
- 1
- 11
- a
- Able
- Om oss
- Enligt
- Uppnå
- uppnå
- Handling
- Annat
- ytterligare information
- anta
- antagen
- Antagande
- första advent
- Alla
- tillåter
- alltid
- analysera
- analys
- och
- Annan
- svara
- Ansökan
- tillämpningar
- Ansök
- tillvägagångssätt
- lämpligt
- arkitektur
- attribut
- autentisera
- Automatiserad
- undvika
- baserat
- I grund och botten
- därför att
- blir
- blir
- började
- BÄST
- Bättre
- Stor
- Stora data
- Blogg
- Blogginlägg
- flaskhals
- företag
- Ring
- Samtal
- fånga
- fall
- centraliserad
- byta
- Förändringar
- Välja
- Stänga
- samla
- Samla
- råvara
- fullborda
- komplex
- komponent
- komponenter
- begrepp
- Oro
- förväxlas
- anses
- med tanke på
- konsumtion
- sammanhang
- kontinuerlig
- kontroll
- Kostar
- kunde
- CPU
- kultur
- Aktuella
- kund
- datum
- data driven
- databaser
- DATAVERSITET
- dag för dag
- Dagar
- årtionde
- decentraliserad
- beslut
- djup
- djupare
- definierade
- beskriva
- destination
- detaljer
- DID
- olika
- digital
- digital Transformation
- distribueras
- distribuerade system
- inte
- ner
- under
- e-handel
- lättare
- inbäddade
- fattande
- möjliggör
- början till slut
- Teknik
- Miljö
- fel
- fel
- upprättandet
- etc
- Även
- händelser
- NÅGONSIN
- ständigt ökande
- allt
- bevis
- Utvecklingen
- exempel
- dyra
- erfarenhet
- extern
- underlättar
- flöden
- bildad
- Ramverk
- ramar
- från
- generering
- skaffa sig
- Go
- Mål
- styrning
- större
- Växer
- hänt
- Happening
- hårdvara
- Hälsa
- hjälpa
- hjälper
- historia
- Träffa
- hoppas
- HET
- Hur ser din drömresa ut
- How To
- Men
- html
- HTTPS
- stor
- bilder
- genomföra
- med Esport
- omöjligt
- förbättra
- förbättring
- in
- informationen
- informeras
- insikter
- inre
- undersöka
- anropar
- fråga
- problem
- IT
- IT-hantering
- resa
- Ha kvar
- kunskap
- liggande
- Large
- större
- Latens
- lager
- skikt
- Ledarskap
- inlärning
- linser
- Hävstång
- livscykel
- Begränsad
- linje
- lever
- läsa in
- Lång
- Lot
- gjord
- göra
- GÖR
- Framställning
- hantera
- ledning
- hantera
- många
- marknad
- matematisk
- max-bredd
- mäta
- Minne
- Metrics
- microservices
- miljoner
- minuter
- övervakning
- Monolitisk
- mest
- flytta
- rörliga
- multipel
- Måste-ha
- Natur
- nödvändigt för
- Behöver
- behov
- netto
- nät
- nätverkssystem
- Nya
- ONE
- drift
- operativa
- Verksamhet
- optimala
- optimering
- organisationer
- Övriga
- övergripande
- egen
- Papper
- bana
- Mönster
- betalning
- uppfattas
- prestanda
- utför
- perioden
- bitar
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Spela
- Strategier
- dålig
- möjlig
- Inlägg
- inlägg
- Proaktiv
- Problem
- process
- Produkt
- Framsteg
- ge
- ger
- tillhandahålla
- publicerade
- kvantitativ
- frågor
- snarare
- Läsa
- Läsning
- motta
- erhåller
- tillförlitlighet
- ta bort
- representerade
- begära
- förfrågningar
- Kräver
- motståndskraft
- begränsad
- resultera
- Rise
- Taket
- regler
- tillfredsställande
- Save
- Skala
- skalning
- Sök
- söka
- Andra
- säkerhet
- Tjänster
- flera
- skall
- Visar
- Enkelt
- enda
- långsam
- Small
- So
- Mjukvara
- LÖSA
- några
- Alldeles strax
- ljud
- Källa
- spann
- specifik
- spendera
- stapel
- Etapp
- starta
- igång
- Ange
- Stater
- stannade
- Fortfarande
- slutade
- förvaring
- Historia
- struktur
- framgångsrik
- system
- System
- Ta
- tar
- uppgift
- lag
- Teknisk
- villkor
- Smakämnen
- den information
- källan
- deras
- vari
- tre
- Genom
- hela
- tid
- tidslinje
- till
- i dag
- verktyg
- ämne
- spåra
- Spårbarhet
- spåra
- Spårning
- överföring
- Transformation
- paraply
- under
- underliggande
- förstå
- uppdatering
- Användning
- Användare
- Användarupplevelse
- vanligen
- Värdefulla
- olika
- Video
- synlighet
- avgörande
- volym
- vänta
- väntar
- Webbplats
- Vad
- Vad är
- som
- medan
- kommer
- inom
- Arbete
- arbetskraft
- fungerar
- världen
- skulle
- Fel
- Din
- zephyrnet











