Denna tredelade serie visar hur man använder grafiska neurala nätverk (GNN) och Amazon Neptunus för att generera filmrekommendationer med hjälp av IMDb och Box Office Mojo Movies/TV/OTT licenserbart datapaket, som tillhandahåller ett brett utbud av underhållningsmetadata, inklusive över 1 miljard användarbetyg; krediter för mer än 11 miljoner skådespelare och besättningsmedlemmar; 9 miljoner film-, TV- och underhållningstitlar; och globala kassarapportdata från mer än 60 länder. Många AWS media- och underhållningskunder licensierar IMDb-data genom AWS datautbyte för att förbättra innehållsupptäckten och öka kundernas engagemang och retention.
In del 1, diskuterade vi tillämpningarna av GNN:er och hur man transformerar och förbereder våra IMDb-data för sökning. I det här inlägget diskuterar vi processen att använda Neptune för att generera inbäddningar som används för att utföra vår sökning utanför katalogen i del 3. Vi går också över Amazon Neptune ML, maskininlärningsfunktionen (ML) i Neptune och koden vi använder i vår utvecklingsprocess. I del 3 går vi igenom hur vi tillämpar våra kunskapsdiagraminbäddningar på ett användningsfall utanför katalogen.
Lösningsöversikt
Stora uppkopplade datauppsättningar innehåller ofta värdefull information som kan vara svår att extrahera med hjälp av frågor baserade enbart på mänsklig intuition. ML-tekniker kan hjälpa till att hitta dolda korrelationer i grafer med miljarder relationer. Dessa korrelationer kan vara till hjälp för att rekommendera produkter, förutsäga kreditvärdighet, identifiera bedrägerier och många andra användningsfall.
Neptune ML gör det möjligt att bygga och träna användbara ML-modeller på stora grafer i timmar istället för veckor. För att åstadkomma detta använder Neptune ML GNN-teknik som drivs av Amazon SageMaker och Deep Graph Library (DGL) (vilket är öppen källkod). GNN är ett framväxande fält inom artificiell intelligens (se till exempel En omfattande undersökning om grafiska neurala nätverk). För en praktisk handledning om att använda GNN med DGL, se Lär dig grafiska neurala nätverk med Deep Graph Library.
I det här inlägget visar vi hur man använder Neptune i vår pipeline för att generera inbäddningar.
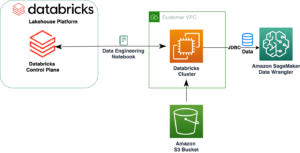
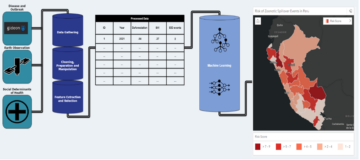
Följande diagram visar det övergripande flödet av IMDb-data från nedladdning till inbäddningsgenerering.
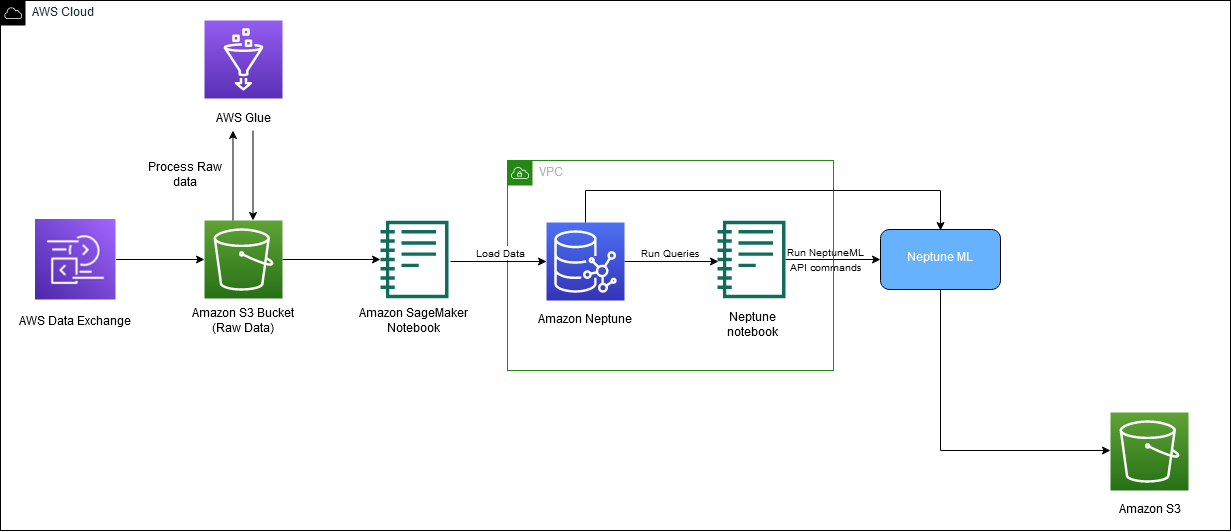
Vi använder följande AWS-tjänster för att implementera lösningen:
I det här inlägget går vi igenom följande steg på hög nivå:
- Ställ in miljövariabler
- Skapa ett exportjobb.
- Skapa ett databearbetningsjobb.
- Skicka in ett utbildningsjobb.
- Ladda ner inbäddningar.
Kod för Neptune ML-kommandon
Vi använder följande kommandon som en del av implementeringen av denna lösning:
Vi använder neptune_ml export för att kontrollera status eller starta en Neptune ML-exportprocess, och neptune_ml training för att starta och kontrollera statusen för ett Neptune ML-modellutbildningsjobb.
För mer information om dessa och andra kommandon, se Använd Neptunus arbetsbänksmagi i dina anteckningsböcker.
Förutsättningar
För att följa detta inlägg bör du ha följande:
- An AWS-konto
- Bekantskap med SageMaker, Amazon S3 och AWS CloudFormation
- Grafdata som laddas in i Neptunusklustret (se del 1 för mer information)
Ställ in miljövariabler
Innan vi börjar måste du ställa in din miljö genom att ställa in följande variabler: s3_bucket_uri och processed_folder. s3_bucket_uri är namnet på hinken som används i del 1 och processed_folder är Amazon S3-platsen för utdata från exportjobbet.
Skapa ett exportjobb
I del 1 skapade vi en SageMaker-anteckningsbok och exporttjänst för att exportera våra data från Neptune DB-klustret till Amazon S3 i det format som krävs.
Nu när vår data har laddats och exporttjänsten skapats måste vi skapa ett exportjobb och starta det. För att göra detta använder vi NeptuneExportApiUri och skapa parametrar för exportjobbet. I följande kod använder vi variablerna expo och export_params. Uppsättning expo till din NeptuneExportApiUri värde, som du kan hitta på Utgångarna fliken i din CloudFormation-stack. För export_params, använder vi ändpunkten för ditt Neptune-kluster och tillhandahåller värdet för outputS3path, som är Amazon S3-platsen för utdata från exportjobbet.
För att skicka exportjobbet använd följande kommando:
För att kontrollera statusen för exportjobbet använd följande kommando:
När ditt jobb är klart, ställ in processed_folder variabel för att ge Amazon S3-platsen för de bearbetade resultaten:
Skapa ett databearbetningsjobb
Nu när exporten är klar skapar vi ett databearbetningsjobb för att förbereda data för Neptune ML-utbildningsprocessen. Detta kan göras på några olika sätt. För detta steg kan du ändra job_name och modelType variabler, men alla andra parametrar måste förbli desamma. Huvuddelen av denna kod är modelType parameter, som antingen kan vara heterogena grafmodeller (heterogeneous) eller kunskapsdiagram (kge).
I exportjobbet ingår även training-data-configuration.json. Använd den här filen för att lägga till eller ta bort eventuella noder eller kanter som du inte vill tillhandahålla för träning (om du till exempel vill förutsäga länken mellan två noder kan du ta bort den länken i den här konfigurationsfilen). För detta blogginlägg använder vi den ursprungliga konfigurationsfilen. För ytterligare information, se Redigera en träningskonfigurationsfil.
Skapa ditt databearbetningsjobb med följande kod:
För att kontrollera statusen för exportjobbet använd följande kommando:
Skicka in ett utbildningsjobb
Efter att bearbetningsjobbet är klart kan vi börja vårt träningsjobb, det är där vi skapar våra inbäddningar. Vi rekommenderar en instanstyp av ml.m5.24xlarge, men du kan ändra detta för att passa dina datorbehov. Se följande kod:
Vi skriver ut variabeln training_results för att få ID för utbildningsjobbet. Använd följande kommando för att kontrollera statusen för ditt jobb:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Ladda ner inbäddningar
När ditt träningsjobb är klart är det sista steget att ladda ner dina råa inbäddningar. Följande steg visar hur du laddar ner inbäddningar skapade med KGE (du kan använda samma process för RGCN).
I följande kod använder vi neptune_ml.get_mapping() och get_embeddings() för att ladda ner mappningsfilen (mapping.info) och den råa inbäddningsfilen (entity.npy). Sedan måste vi mappa lämpliga inbäddningar till deras motsvarande ID.
För att ladda ner RGCN:er, följ samma process med ett nytt utbildningsjobbnamn genom att bearbeta data med parametern modelType inställd på heterogeneous, och träna sedan din modell med parametern modelName inställd på rgcn se här. för mer detaljer. När det är klart ringer du get_mapping och get_embeddings funktioner för att ladda ner din nya mapping.info och entity.npy filer. När du har entitets- och mappningsfilerna är processen för att skapa CSV-filen identisk.
Slutligen, ladda upp dina inbäddningar till din önskade Amazon S3-plats:
Se till att du kommer ihåg den här S3-platsen, du måste använda den i del 3.
Städa upp
När du är klar med att använda lösningen, se till att rensa alla resurser för att undvika pågående avgifter.
Slutsats
I det här inlägget diskuterade vi hur man använder Neptune ML för att träna GNN-inbäddningar från IMDb-data.
Vissa relaterade tillämpningar av inbäddningar av kunskapsdiagram är begrepp som sökning utanför katalogen, innehållsrekommendationer, riktad annonsering, förutsägelse av saknade länkar, allmän sökning och kohortanalys. Sökning utanför katalogen är processen att söka efter innehåll som du inte äger, och hitta eller rekommendera innehåll som finns i din katalog som är så nära det som användaren sökte efter som möjligt. Vi dyker djupare in i sökning utanför katalogen i del 3.
Om författarna
 Matthew Rhodes är en dataforskare och jag arbetar i Amazon ML Solutions Lab. Han är specialiserad på att bygga pipelines för maskininlärning som involverar begrepp som Natural Language Processing och Computer Vision.
Matthew Rhodes är en dataforskare och jag arbetar i Amazon ML Solutions Lab. Han är specialiserad på att bygga pipelines för maskininlärning som involverar begrepp som Natural Language Processing och Computer Vision.
 Divya Bhargavi är datavetare och vertikal ledare för media och underhållning vid Amazon ML Solutions Lab, där hon löser affärsproblem med högt värde för AWS-kunder med hjälp av maskininlärning. Hon arbetar med bild-/videoförståelse, rekommendationssystem för kunskapsdiagram, användningsfall för prediktiv reklam.
Divya Bhargavi är datavetare och vertikal ledare för media och underhållning vid Amazon ML Solutions Lab, där hon löser affärsproblem med högt värde för AWS-kunder med hjälp av maskininlärning. Hon arbetar med bild-/videoförståelse, rekommendationssystem för kunskapsdiagram, användningsfall för prediktiv reklam.
 Gaurav Rele är datavetare vid Amazon ML Solution Lab, där han arbetar med AWS-kunder över olika vertikaler för att påskynda deras användning av maskininlärning och AWS Cloud-tjänster för att lösa deras affärsutmaningar.
Gaurav Rele är datavetare vid Amazon ML Solution Lab, där han arbetar med AWS-kunder över olika vertikaler för att påskynda deras användning av maskininlärning och AWS Cloud-tjänster för att lösa deras affärsutmaningar.
 Karan Sindwani är en dataforskare på Amazon ML Solutions Lab, där han bygger och distribuerar modeller för djupinlärning. Han är specialiserad inom området datorseende. På fritiden tycker han om att vandra.
Karan Sindwani är en dataforskare på Amazon ML Solutions Lab, där han bygger och distribuerar modeller för djupinlärning. Han är specialiserad inom området datorseende. På fritiden tycker han om att vandra.
 Soji Adeshina är en tillämpad vetenskapsman på AWS där han utvecklar grafiska neurala nätverksbaserade modeller för maskininlärning på grafuppgifter med applikationer för bedrägeri och missbruk, kunskapsdiagram, rekommendatorsystem och biovetenskap. På fritiden tycker han om att läsa och laga mat.
Soji Adeshina är en tillämpad vetenskapsman på AWS där han utvecklar grafiska neurala nätverksbaserade modeller för maskininlärning på grafuppgifter med applikationer för bedrägeri och missbruk, kunskapsdiagram, rekommendatorsystem och biovetenskap. På fritiden tycker han om att läsa och laga mat.
 Vidya Sagar Ravipati är chef på Amazon ML Solutions Lab, där han drar nytta av sin stora erfarenhet av distribuerade system i stor skala och sin passion för maskininlärning för att hjälpa AWS-kunder i olika branschvertikaler att påskynda deras AI- och molnintroduktion.
Vidya Sagar Ravipati är chef på Amazon ML Solutions Lab, där han drar nytta av sin stora erfarenhet av distribuerade system i stor skala och sin passion för maskininlärning för att hjälpa AWS-kunder i olika branschvertikaler att påskynda deras AI- och molnintroduktion.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Om oss
- missbruk
- accelerera
- tvärs
- Annat
- ytterligare information
- Antagande
- reklam
- Efter
- AI
- Alla
- ensam
- amason
- Amazon ML Solutions Lab
- analys
- och
- tillämpningar
- tillämpas
- Ansök
- lämpligt
- OMRÅDE
- konstgjord
- artificiell intelligens
- AWS
- baserat
- mellan
- Miljarder
- miljarder
- Blogg
- Box
- box office
- SLUTRESULTAT
- Byggnad
- bygger
- företag
- Ring
- Vid
- fall
- katalog
- utmaningar
- byta
- avgifter
- ta
- Stänga
- cloud
- moln adoption
- molntjänster
- kluster
- koda
- Kohort
- fullborda
- omfattande
- dator
- Datorsyn
- databehandling
- Begreppen
- Genomför
- konfiguration
- anslutna
- innehåll
- Motsvarande
- länder
- skapa
- skapas
- kredit
- krediter
- kund
- Kundförlovning
- Kunder
- datum
- databehandling
- datavetare
- datauppsättningar
- djup
- djupt lärande
- djupare
- vecklas ut
- detaljer
- Utveckling
- utvecklar
- dgl
- olika
- Upptäckten
- diskutera
- diskuteras
- distribueras
- distribuerade system
- inte
- ladda ner
- antingen
- smärgel
- Slutpunkt
- ingrepp
- Underhållning
- enhet
- Miljö
- Eter (ETH)
- exempel
- erfarenhet
- export
- extrahera
- Leverans
- få
- fält
- Fil
- Filer
- hitta
- finna
- flöda
- följer
- efter
- format
- bedrägeri
- från
- full
- funktioner
- Allmänt
- generera
- generering
- skaffa sig
- Välgörenhet
- Go
- diagram
- grafer
- praktisk
- Hård
- hjälpa
- hjälp
- dold
- högnivå
- ÖPPETTIDER
- Hur ser din drömresa ut
- How To
- html
- HTTPS
- humant
- identiska
- identifiera
- genomföra
- genomföra
- förbättra
- in
- innefattar
- Inklusive
- Öka
- index
- industrin
- info
- informationen
- exempel
- istället
- Intelligens
- engagera
- IT
- Jobb
- json
- Nyckel
- kunskap
- lab
- språk
- Large
- storskalig
- Efternamn
- leda
- inlärning
- hävstångs
- Bibliotek
- Licens
- livet
- Life Sciences
- LINK
- länkar
- läge
- Maskinen
- maskininlärning
- Huvudsida
- GÖR
- chef
- många
- karta
- kartläggning
- Media
- Medium
- Medlemmar
- metadata
- miljon
- saknas
- ML
- modell
- modeller
- mer
- film
- namn
- Natural
- Naturlig språkbehandling
- Behöver
- behov
- Neptune
- nätverksbaserade
- nätverk
- neurala nätverk
- Nya
- noder
- anteckningsbok
- Office
- pågående
- ursprungliga
- Övriga
- övergripande
- egen
- paket
- parameter
- parametrar
- del
- brinner
- rörledning
- plato
- Platon Data Intelligence
- PlatonData
- möjlig
- Inlägg
- kraft
- drivs
- förutse
- förutsäga
- Förbered
- Skriva ut
- problem
- process
- bearbetning
- Produkter
- Profil
- ge
- ger
- område
- betyg
- Raw
- Läsning
- rekommenderar
- Rekommendation
- rekommendationer
- rekommendera
- relaterad
- Förhållanden
- förblir
- ihåg
- ta bort
- Rapportering
- Obligatorisk
- Resurser
- Resultat
- retentionstid
- sagemaker
- Samma
- VETENSKAPER
- Forskare
- Sök
- söka
- Serier
- service
- Tjänster
- in
- inställning
- skall
- show
- lösning
- Lösningar
- LÖSA
- Löser
- specialiserat
- stapel
- starta
- status
- Steg
- Steg
- lagra
- skicka
- sådana
- följer
- Undersökning
- System
- riktade
- uppgifter
- tekniker
- Teknologi
- Smakämnen
- Området
- deras
- Genom
- tid
- titlar
- till
- Tåg
- Utbildning
- Förvandla
- sann
- handledning
- tv
- förståelse
- användning
- användningsfall
- Användare
- Värdefulla
- värde
- Omfattande
- version
- vertikaler
- syn
- sätt
- veckor
- Vad
- som
- bred
- Brett utbud
- kommer
- arbetssätt
- fungerar
- Din
- zephyrnet