Dataförberedelse är en huvudkomponent i pipelines för maskininlärning (ML). Faktum är att det uppskattas att dataproffs lägger cirka 80 procent av sin tid på dataförberedelser. På denna intensiva konkurrensutsatta marknad vill team analysera data och snabbt få ut mer meningsfulla insikter. Kunder antar mer effektiva och visuella sätt att bygga databehandlingssystem.
Amazon SageMaker Data Wrangler förenklar dataförberedelsen och funktionsutvecklingsprocessen, vilket minskar tiden det tar från veckor till minuter genom att tillhandahålla ett enda visuellt gränssnitt för datavetare att välja, rensa data, skapa funktioner och automatisera dataförberedelse i ML-arbetsflöden utan att skriva någon kod. Du kan importera data från flera datakällor, som t.ex Amazon Simple Storage Service (Amazon S3), Amazonas Athena, Amazon RedShift, och Snowflake. Du kan nu också använda Amazon EMR som en datakälla i Data Wrangler för att enkelt förbereda data för ML.
Att analysera, transformera och förbereda stora mängder data är ett grundläggande steg i alla datavetenskapliga och ML-arbetsflöden. Dataproffs som datavetare vill utnyttja kraften i Apache Spark, Bikupaoch Presto körs på Amazon EMR för snabb dataförberedelse, men inlärningskurvan är brant. Våra kunder ville ha möjligheten att ansluta till Amazon EMR för att köra ad hoc SQL-frågor på Hive eller Presto för att söka efter data i den interna metastore eller extern metastore (t.ex. AWS Glue Data Catalog), och förbereda data inom några få klick.
Den här bloggartikeln kommer att diskutera hur kunder nu kan hitta och ansluta till befintliga Amazon EMR-kluster med hjälp av en visuell upplevelse i SageMaker Data Wrangler. De kan visuellt inspektera databasen, tabellerna, schemat och Presto-frågorna för att förbereda sig för modellering eller rapportering. De kan sedan snabbt profilera data med hjälp av ett visuellt gränssnitt för att bedöma datakvaliteten, identifiera avvikelser eller saknade eller felaktiga data och ta emot information och rekommendationer om hur man åtgärdar dessa problem. Dessutom kan de analysera, rengöra och konstruera funktioner med hjälp av mer än ett dussin extra inbyggda analyser och 300+ extra inbyggda transformationer som backas upp av Spark utan att skriva en enda rad kod.
Lösningsöversikt
Dataproffs kan snabbt hitta och ansluta till befintliga EMR-kluster med SageMaker Studio-konfigurationer. Dessutom kan dataproffs avsluta EMR-kluster med bara några få klick från SageMaker Studio använder fördefinierade mallar och on-demand-skapande av EMR-kluster. Med hjälp av dessa verktyg kan kunder hoppa direkt in i SageMaker Studios universella anteckningsbok och skriva kod i Apache Spark, Hive, Presto eller PySpark för att utföra dataförberedelser i stor skala. På grund av en brant inlärningskurva för att skapa Spark-kod för att förbereda data, är inte alla dataproffs bekväma med denna procedur. Med Amazon EMR som datakälla för Amazon SageMaker Data Wrangler kan du nu snabbt och enkelt ansluta till Amazon EMR utan att skriva en enda rad kod.
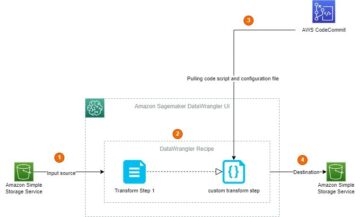
Följande diagram representerar de olika komponenterna som används i denna lösning.
Vi visar två autentiseringsalternativ som kan användas för att upprätta en anslutning till EMR-klustret. För varje alternativ distribuerar vi en unik stack med AWS molnformation mallar.
CloudFormation-mallen utför följande åtgärder när varje alternativ är valt:
- Skapar en Studiodomän i endast VPC-läge, tillsammans med en namngiven användarprofil
studio-user. - Skapar byggstenar, inklusive VPC, slutpunkter, undernät, säkerhetsgrupper, EMR-kluster och andra nödvändiga resurser för att framgångsrikt köra exemplen.
- För EMR-klustret, ansluter AWS Glue Data Catalog som metastore för EMR Hive och Presto, skapar en Hive-tabell i EMR och fyller den med data från en amerikansk flygplatsdatauppsättning.
- För LDAP CloudFormation-mallen, skapar en Amazon Elastic Compute Cloud (Amazon EC2) instans för att vara värd för LDAP-servern för att autentisera Hive och Presto LDAP-användare.
Alternativ 1: Lightweight Access Directory Protocol
För LDAP-autentiseringsmallen CloudFormation tillhandahåller vi en Amazon EC2-instans med en LDAP-server och konfigurerar EMR-klustret för att använda denna server för autentisering. Detta är TLS-aktiverat.
Alternativ 2: No-Auth
I mallen för No-Auth-autentisering CloudFormation använder vi ett standard EMR-kluster utan autentisering aktiverad.
Distribuera resurserna med AWS CloudFormation
Slutför följande steg för att distribuera miljön:
- Logga in på AWS Management Console som en AWS Identity and Access Management (IAM) användare, helst en administratörsanvändare.
- Välja Starta stack för att starta CloudFormation-mallen för lämpligt autentiseringsscenario. Se till att regionen som används för att distribuera CloudFormation-stacken inte har någon befintlig Studio-domän. Om du redan har en Studiodomän i en region kan du välja en annan region.
- LDAP-startstack

- Ingen Auth Launch Stack

- LDAP-startstack
- Välja Nästa.
- För Stapla namn, ange ett namn för stacken (till exempel
dw-emr-blog). - Lämna de andra värdena som standard.
- För att fortsätta, välj Nästa från sidan med stackdetaljer och stackalternativ. LDAP-stacken använder följande autentiseringsuppgifter:
- användarnamn:
david - Lösenord:
welcome123
- användarnamn:
- Markera kryssrutan på granskningssidan för att bekräfta att AWS CloudFormation kan skapa resurser.
- Välja Skapa stack. Vänta tills stackens status ändras från
CREATE_IN_PROGRESStillCREATE_COMPLETE. Processen tar vanligtvis 10–15 minuter.

Obs: Om du vill prova flera stackar, följ stegen i avsnittet Rensa upp. Kom ihåg att du måste ta bort SageMaker Studio-domänen innan nästa stack framgångsrikt kan lanseras.
Ställ in Amazon EMR som en datakälla i Data Wrangler
I det här avsnittet täcker vi anslutning till det befintliga Amazon EMR-klustret som skapats genom CloudFormation-mallen som en datakälla i Data Wrangler.
Skapa ett nytt dataflöde
Så här skapar du ditt dataflöde:
- Välj på SageMaker-konsolen Amazon SageMaker Studio i navigeringsfönstret.
- Välja Öppen studio.
- Välj i startprogrammet Nytt dataflöde. Alternativt på Fil rullgardinsmenyn, välj Nytt och välj sedan Data Wrangler-flöde.
- Att skapa ett nytt flöde kan ta några minuter. Efter att flödet har skapats ser du Importera datum sida.

Lägg till Amazon EMR som en datakälla i Data Wrangler
Välj på menyn Lägg till datakälla Amazon EMR.

Du kan bläddra bland alla EMR-kluster som din Studio-exekveringsroll har behörighet att se. Du har två alternativ för att ansluta till ett kluster; den ena är genom interaktivt användargränssnitt, och den andra är först skapa en hemlighet med AWS Secrets Manager med JDBC URL, inklusive EMR-klusterinformation, och tillhandahåll sedan den lagrade AWS-hemligheten ARN i användargränssnittet för att ansluta till Presto. I den här bloggen följer vi det första alternativet. Välj ett av följande kluster som du vill använda. Klicka på Nästa, och välj endpoints.

Välja Presto, koppla till amason EMR, skapa ett namn för att identifiera din anslutning och klicka Nästa.

Välja Autentisering skriv, antingen LDAP eller Ingen autentisering, och klicka Kontakta.
- För Lightweight Directory Access Protocol (LDAP), ange användarnamn och lösenord som ska autentiseras.


- För ingen autentisering kommer du att vara ansluten till EMR Presto utan att tillhandahålla användaruppgifter inom VPC. Gå in på Data Wranglers SQL explorer-sida för EMR.

När du väl är ansluten kan du interaktivt se ett databasträd och en förhandsgranskning av en tabell eller ett schema. Du kan också fråga, utforska och visualisera data från EMR. För förhandsgranskning ser du en gräns på 100 poster som standard. För anpassad fråga kan du tillhandahålla SQL-satser i frågeredigeringsrutan och när du klickar på Körning knappen, kommer frågan att köras på EMR:s Presto-motor.

Smakämnen Avbryt fråga knappen gör att pågående frågor kan avbrytas om de tar ovanligt lång tid.
Det sista steget är att importera. När du är redo med den efterfrågade informationen har du alternativ att uppdatera samplingsinställningarna för dataurvalet enligt samplingstyp (FirstK, Random eller Stratified) och samplingsstorlek för att importera data till Data Wrangler.
Klicka Importera. Förberedelsesidan kommer att laddas, så att du kan lägga till olika transformationer och viktig analys till datasetet.

Navigera till DataFlow från den övre skärmen och lägg till fler steg i flödet efter behov för transformationer och analys. Du kan köra en datainsiktsrapport för att identifiera datakvalitetsproblem och få rekommendationer för att åtgärda dessa problem. Låt oss titta på några exempel på transformationer.
Gå till ditt dataflöde och det här är skärmen som du bör se. Det visar oss att vi använder EMR som en datakälla med Presto-kontakten.

Låt oss klicka på +-knappen till höger om Datatyper och välj Lägg till transform. När du gör det bör följande skärm dyka upp:

Låt oss utforska data. Vi ser att den har flera funktioner som t.ex iata_code, flygplats, stad, tillstånd, land, latitudoch longitud. Vi kan se att hela datasetet är baserat i ett land, vilket är USA, och det saknas värden i latitud och longitud. Saknade data kan orsaka bias i skattningen av parametrar, och det kan minska representativiteten för proverna, så vi måste utföra några imputering och hantera saknade värden i vår datauppsättning.

Låt oss klicka på Lägg till steg knappen i navigeringsfältet till höger. Välj Handtag saknas. Konfigurationerna kan ses i följande skärmdumpar. Under Omvandla, välj Tillräkna. Välj kolumntyp som Numerisk och kolumnnamn Latitud och Longitud. Vi kommer att tillräkna de saknade värdena med hjälp av ett ungefärligt medianvärde. Förhandsgranska och lägg till transformationen.


Låt oss nu titta på ett annat exempel på transformation. När du bygger en maskininlärningsmodell tas kolumner bort om de är överflödiga eller inte hjälper din modell. Det vanligaste sättet att ta bort en kolumn är att släppa den. I vår datauppsättning, funktionen land kan tas bort eftersom datasetet är specifikt för amerikanska flygplatsdata. Låt oss se hur vi kan hantera kolumner. Låt oss klicka på Lägg till steg knappen i navigeringsfältet till höger. Välj Hantera kolumner. Konfigurationerna kan ses i följande skärmdumpar. Under Förvandla, Välj Släpp kolumn, och under Kolumner att släppa, Välj Land.


Du kan fortsätta lägga till steg baserat på de olika transformationer som krävs för din datauppsättning. Låt oss gå tillbaka till vårt dataflöde. Du kommer nu att se ytterligare två block som visar transformationerna som vi utförde. I vårt scenario kan du se Tillräkna och Släpp kolumn.

ML-utövare spenderar mycket tid på att skapa funktionsteknikkod, applicera den på sina initiala datauppsättningar, träna modeller på de konstruerade datauppsättningarna och utvärdera modellens noggrannhet. Med tanke på den experimentella karaktären av detta arbete kommer även det minsta projektet att leda till flera iterationer. Samma funktionskod körs ofta om och om igen, vilket slösar tid och beräkningsresurser på att upprepa samma operationer. I stora organisationer kan detta orsaka en ännu större produktivitetsförlust eftersom olika team ofta kör identiska jobb eller till och med skriver duplicerad funktionskod eftersom de inte har någon kunskap om tidigare arbete. För att undvika omarbetning av funktioner kommer vi nu att exportera våra transformerade funktioner till Amazon Feature Store. Låt oss klicka på + knappen till höger om Släpp kolumn. Välj Exportera till Och välj Sagemaker Feature Store (via Jupyter notebook).

Du kan enkelt exportera dina genererade funktioner till SageMaker Feature Store genom att välja den som destination. Du kan spara funktionerna i en befintlig funktionsgrupp eller skapa en ny.


Vi har nu skapat funktioner med Data Wrangler och enkelt lagrat dessa funktioner i Feature Store. Vi visade ett exempel på arbetsflöde för funktionsteknik i Data Wrangler UI. Sedan sparade vi dessa funktioner i Feature Store direkt från Data Wrangler genom att skapa en ny funktionsgrupp. Slutligen körde vi ett bearbetningsjobb för att få in dessa funktioner i Feature Store. Data Wrangler och Feature Store hjälpte oss tillsammans bygga automatiska och repeterbara processer för att effektivisera våra dataförberedande uppgifter med ett minimum av kodning. Data Wrangler ger oss också flexibilitet att automatisera samma databeredningsflöde med hjälp av schemalagda jobb. Vi kan också automatisera utbildning eller funktionsteknik med SageMaker Pipelines (via Jupyter Notebook) och distribuera till Inference endpoint med SageMaker inference pipeline (via Jupyter Notebook).

Städa upp
Om ditt arbete med Data Wrangler är klart, välj stacken som skapats från CloudFormation-sidan och radera den för att undvika extra avgifter.
Slutsats
I det här inlägget gick vi över hur man ställer in Amazon EMR som en datakälla i Data Wrangler, hur man transformerar och analyserar en datauppsättning och hur man exporterar resultaten till ett dataflöde för användning i en Jupyter-anteckningsbok. Efter att ha visualiserat vår datauppsättning med Data Wranglers inbyggda analytiska funktioner förbättrade vi vårt dataflöde ytterligare. Det faktum att vi skapade en databeredningspipeline utan att skriva en enda kodrad är betydande.
För att komma igång med Data Wrangler, se Förbered ML-data med Amazon SageMaker Data Wrangler, och se den senaste informationen om Data Wrangler produktsida.
Om författarna
 Ajjay Govindaram är Senior Solutions Architect på AWS. Han arbetar med strategiska kunder som använder AI/ML för att lösa komplexa affärsproblem. Hans erfarenhet ligger i att tillhandahålla teknisk ledning samt designhjälp för blygsamma till storskaliga AI/ML-applikationer. Hans kunskap sträcker sig från applikationsarkitektur till big data, analys och maskininlärning. Han tycker om att lyssna på musik medan han vilar, uppleva utomhus och umgås med sina nära och kära.
Ajjay Govindaram är Senior Solutions Architect på AWS. Han arbetar med strategiska kunder som använder AI/ML för att lösa komplexa affärsproblem. Hans erfarenhet ligger i att tillhandahålla teknisk ledning samt designhjälp för blygsamma till storskaliga AI/ML-applikationer. Hans kunskap sträcker sig från applikationsarkitektur till big data, analys och maskininlärning. Han tycker om att lyssna på musik medan han vilar, uppleva utomhus och umgås med sina nära och kära.
 Isha Dua är en senior lösningsarkitekt baserad i San Francisco Bay Area. Hon hjälper AWS företagskunder att växa genom att förstå deras mål och utmaningar, och guidar dem om hur de kan utforma sina applikationer på ett molnbaserat sätt samtidigt som de ser till att de är motståndskraftiga och skalbara. Hon brinner för maskininlärningsteknik och miljömässig hållbarhet.
Isha Dua är en senior lösningsarkitekt baserad i San Francisco Bay Area. Hon hjälper AWS företagskunder att växa genom att förstå deras mål och utmaningar, och guidar dem om hur de kan utforma sina applikationer på ett molnbaserat sätt samtidigt som de ser till att de är motståndskraftiga och skalbara. Hon brinner för maskininlärningsteknik och miljömässig hållbarhet.
 Rui Jiang är en mjukvaruutvecklingsingenjör på AWS baserad i New York City-området. Hon är medlem i SageMaker Data Wrangler-teamet som hjälper till att utveckla tekniska lösningar för AWS-företagskunder för att uppnå deras affärsbehov. Utanför jobbet tycker hon om att utforska nya livsmedel, fitness, utomhusaktiviteter och att resa.
Rui Jiang är en mjukvaruutvecklingsingenjör på AWS baserad i New York City-området. Hon är medlem i SageMaker Data Wrangler-teamet som hjälper till att utveckla tekniska lösningar för AWS-företagskunder för att uppnå deras affärsbehov. Utanför jobbet tycker hon om att utforska nya livsmedel, fitness, utomhusaktiviteter och att resa.
- AI
- ai konst
- ai art generator
- har robot
- Amazon EMR
- Amazon SageMaker
- Amazon SageMaker Data Wrangler
- analytics
- artificiell intelligens
- artificiell intelligenscertifiering
- artificiell intelligens inom bankväsendet
- artificiell intelligens robot
- robotar med artificiell intelligens
- programvara för artificiell intelligens
- AWS maskininlärning
- blockchain
- blockchain konferens ai
- coingenius
- konversationskonstnärlig intelligens
- kryptokonferens ai
- dalls
- djupt lärande
- du har google
- maskininlärning
- plato
- plato ai
- Platon Data Intelligence
- Platon spel
- PlatonData
- platogaming
- skala ai
- syntax
- zephyrnet