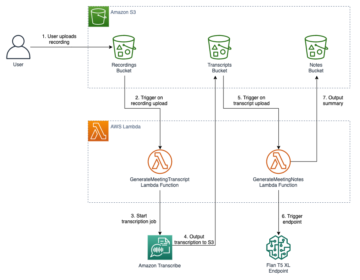
I datorseende är semantisk segmentering uppgiften att klassificera varje pixel i en bild med en klass från en känd uppsättning etiketter så att pixlar med samma etikett delar vissa egenskaper. Den genererar en segmenteringsmask av ingångsbilderna. Till exempel visar följande bilder en segmenteringsmask av cat märka.
 |
 |
I november 2018, Amazon SageMaker tillkännagav lanseringen av SageMakers semantiska segmenteringsalgoritm. Med den här algoritmen kan du träna dina modeller med en offentlig datauppsättning eller din egen datauppsättning. Populära datauppsättningar för bildsegmentering inkluderar datauppsättningen Common Objects in Context (COCO) och PASCAL Visual Object Classes (PASCAL VOC), men klasserna för deras etiketter är begränsade och du kanske vill träna en modell på målobjekt som inte ingår i offentliga datauppsättningar. I det här fallet kan du använda Amazon SageMaker Ground Sannhet för att märka din egen datauppsättning.
I det här inlägget visar jag följande lösningar:
- Använder Ground Truth för att märka en semantisk segmenteringsdatauppsättning
- Omvandla resultaten från Ground Truth till det erforderliga inmatningsformatet för SageMaker inbyggda semantiska segmenteringsalgoritm
- Använda den semantiska segmenteringsalgoritmen för att träna en modell och utföra slutledning
Semantisk segmenteringsdatamärkning
För att bygga en maskininlärningsmodell för semantisk segmentering måste vi märka en datauppsättning på pixelnivå. Ground Truth ger dig möjligheten att använda mänskliga annotatorer igenom Amazon Mekanisk Turk, tredjepartsleverantörer eller din egen privata arbetsstyrka. För att lära dig mer om arbetskraft, se Skapa och hantera arbetskraft. Om du inte vill hantera märkningspersonalen på egen hand, Amazon SageMaker Ground Truth Plus är ett annat bra alternativ som en ny nyckelfärdig datamärkningstjänst som gör att du snabbt kan skapa högkvalitativa utbildningsdatauppsättningar och minskar kostnaderna med upp till 40 %. För det här inlägget visar jag dig hur du manuellt märker datamängden med Ground Truths autosegmenteringsfunktion och crowdsource-märkning med en Mechanical Turk-arbetsstyrka.
Manuell märkning med Ground Truth
I december 2019 lade Ground Truth till en automatisk segmenteringsfunktion till användargränssnittet för semantisk segmentering av etiketter för att öka etikettgenomströmningen och förbättra noggrannheten. För mer information, se Automatisk segmentering av objekt när du utför semantisk segmenteringsmärkning med Amazon SageMaker Ground Truth. Med den här nya funktionen kan du påskynda din märkningsprocess för segmenteringsuppgifter. Istället för att rita en tättslutande polygon eller använda penselverktyget för att fånga ett objekt i en bild, ritar du bara fyra punkter: längst upp, längst ner, längst till vänster och längst till höger på objektet. Ground Truth tar dessa fyra punkter som indata och använder algoritmen Deep Extreme Cut (DEXTR) för att skapa en tättslutande mask runt objektet. För en handledning som använder Ground Truth för märkning av semantisk bildsegmentering, se Bild semantisk segmentering. Följande är ett exempel på hur autosegmenteringsverktyget genererar en segmenteringsmask automatiskt efter att du valt de fyra ytterpunkterna för ett objekt.


Crowdsourcing-märkning med en Mechanical Turk-arbetsstyrka
Om du har en stor datamängd och du inte vill märka hundratals eller tusentals bilder manuellt själv, kan du använda Mechanical Turk, som tillhandahåller en skalbar, mänsklig arbetsstyrka på begäran för att utföra jobb som människor kan göra bättre än datorer. Mechanical Turk-mjukvaran formaliserar jobberbjudanden till de tusentals arbetare som är villiga att utföra styckarbete när det passar dem. Mjukvaran hämtar också det utförda arbetet och sammanställer det åt dig, den som begär det, som betalar arbetarna för tillfredsställande arbete (endast). För att komma igång med Mechanical Turk, se Introduktion till Amazon Mechanical Turk.
Skapa ett märkningsjobb
Följande är ett exempel på ett Mechanical Turk-märkningsjobb för en havssköldpaddas dataset. Havssköldpaddans dataset är från Kaggle-tävlingen Ansiktsavkänning av havssköldpaddor, och jag valde ut 300 bilder av datasetet för demonstrationsändamål. Havssköldpaddor är inte en vanlig klass i offentliga datauppsättningar så den kan representera en situation som kräver märkning av en massiv datauppsättning.
- Välj på SageMaker-konsolen Märkning jobb i navigeringsfönstret.
- Välja Skapa märkningsjobb.
- Ange ett namn för ditt jobb.
- För Indatainställning, Välj Automatiserad datainställning.
Detta genererar ett manifest av indata. - För S3-plats för indatauppsättningar, ange sökvägen för datamängden.

- För Uppgiftskategoriväljer Bild.
- För Uppgiftsval, Välj Semantisk segmentering.

- För Arbetartyper, Välj Amazon Mekanisk Turk.
- Konfigurera dina inställningar för uppgiftens timeout, uppgiftens utgångstid och pris per uppgift.

- Lägg till en etikett (för det här inlägget,
sea turtle), och tillhandahåll märkningsinstruktioner. - Välja Skapa.

När du har ställt in etikettjobbet kan du kontrollera etikettförloppet på SageMaker-konsolen. När det är markerat som klart kan du välja jobbet för att kontrollera resultaten och använda dem för nästa steg.

Datauppsättning transformation
När du har fått utdata från Ground Truth kan du använda SageMaker inbyggda algoritmer för att träna en modell på denna datauppsättning. Först måste du förbereda den märkta datamängden som det begärda inmatningsgränssnittet för SageMakers semantiska segmenteringsalgoritm.
Begärda indatakanaler
SageMaker semantisk segmentering förväntar sig att din träningsdatauppsättning lagras på Amazon enkel lagringstjänst (Amazon S3). Datauppsättningen i Amazon S3 förväntas presenteras i två kanaler, en för train och en för validation, med fyra kataloger, två för bilder och två för kommentarer. Anteckningar förväntas vara okomprimerade PNG-bilder. Datauppsättningen kan också ha en etikettkarta som beskriver hur anteckningsmappningarna upprättas. Om inte, använder algoritmen en standard. För slutledning accepterar en slutpunkt bilder med en image/jpeg innehållstyp. Följande är den nödvändiga strukturen för datakanalerna:
Varje JPG-bild i tåg- och valideringskatalogen har en motsvarande PNG-etikettbild med samma namn i train_annotation och validation_annotation kataloger. Denna namnkonvention hjälper algoritmen att associera en etikett med dess motsvarande bild under träning. Tåget, train_annotation, validering och validation_annotation kanaler är obligatoriska. Anteckningarna är enkanaliga PNG-bilder. Formatet fungerar så länge som metadata (lägen) i bilden hjälper algoritmen att läsa annoteringsbilderna till ett enkanaligt 8-bitars osignerat heltal.
Utdata från märkningsjobbet Ground Truth
Utdata som genereras från märkningsjobbet Ground Truth har följande mappstruktur:
Segmenteringsmaskerna sparas i s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Varje anteckningsbild är en .png-fil som är uppkallad efter källbildens index och tidpunkten då denna bildmärkning slutfördes. Till exempel, följande är källbilden (Image_1.jpg) och dess segmenteringsmask genererad av Mechanical Turk-arbetsstyrkan (0_2022-02-10T17:41:04.724225.png). Lägg märke till att maskens index är annorlunda än numret i källbildens namn.
 |
 |
Utdatamanifestet från märkningsjobbet finns i /manifests/output/output.manifest fil. Det är en JSON-fil och varje rad registrerar en mappning mellan källbilden och dess etikett och annan metadata. Följande JSON-rad registrerar en mappning mellan den visade källbilden och dess anteckning:
Källbilden heter Image_1.jpg, och anteckningens namn är 0_2022-02-10T17:41: 04.724225.png. För att förbereda data som de erforderliga datakanalformaten för SageMakers semantiska segmenteringsalgoritm, måste vi ändra annoteringsnamnet så att det har samma namn som käll-JPG-bilderna. Och vi måste också dela upp datasetet i train och validation kataloger för källbilder och kommentarer.
Förvandla utdata från ett Ground Truth-märkningsjobb till det begärda inmatningsformatet
För att transformera utdata, utför följande steg:
- Ladda ner alla filer från etikettjobbet från Amazon S3 till en lokal katalog:
- Läs manifestfilen och ändra namnen på annoteringen till samma namn som källbilderna:
- Dela upp tåg- och valideringsdatauppsättningarna:
- Skapa en katalog i det format som krävs för de semantiska segmenteringsalgoritmens datakanaler:
- Flytta tåg- och valideringsbilderna och deras kommentarer till de skapade katalogerna.
- För bilder, använd följande kod:
- För kommentarer, använd följande kod:
- Ladda upp tåg- och valideringsdatauppsättningarna och deras annoteringsdatauppsättningar till Amazon S3:
SageMaker utbildning i semantisk segmenteringsmodell
I det här avsnittet går vi igenom stegen för att träna din semantiska segmenteringsmodell.
Följ exempel på anteckningsboken och ställ in datakanaler
Du kan följa instruktionerna i Semantisk segmenteringsalgoritm är nu tillgänglig i Amazon SageMaker för att implementera den semantiska segmenteringsalgoritmen till din märkta datamängd. Detta prov anteckningsbok visar ett heltäckande exempel som introducerar algoritmen. I anteckningsboken lär du dig hur du tränar och är värd för en semantisk segmenteringsmodell med hjälp av det helt konvolutionerande nätverket (FCN) algoritm som använder Pascal VOC-dataset för träning. Eftersom jag inte planerar att träna en modell från Pascal VOC-dataset hoppade jag över steg 3 (dataförberedelse) i den här anteckningsboken. Istället skapade jag direkt train_channel, train_annotation_channe, validation_channeloch validation_annotation_channel med S3-platserna där jag lagrade mina bilder och kommentarer:
Justera hyperparametrar för din egen datauppsättning i SageMaker estimator
Jag följde anteckningsboken och skapade ett SageMaker estimatorobjekt (ss_estimator) för att träna min segmenteringsalgoritm. En sak som vi måste anpassa för den nya datamängden finns i ss_estimator.set_hyperparameters: vi måste ändra num_classes=21 till num_classes=2 (turtle och background), och jag ändrade mig också epochs=10 till epochs=30 eftersom 10 endast är för demoändamål. Sedan använde jag p3.2xlarge-instansen för modellträning genom inställning instance_type="ml.p3.2xlarge". Träningen avslutades på 8 minuter. Det bästa MIoU (Mean Intersection over Union) på 0.846 uppnås vid epok 11 med en pix_acc (procentandelen pixlar i din bild som klassificeras korrekt) på 0.925, vilket är ett ganska bra resultat för denna lilla datauppsättning.
Modell slutledningsresultat
Jag var värd för modellen på en billig ml.c5.xlarge-instans:
Slutligen förberedde jag en testuppsättning med 10 sköldpaddsbilder för att se slutledningsresultatet av den tränade segmenteringsmodellen:
Följande bilder visar resultatet.

Segmenteringsmaskerna för havssköldpaddorna ser exakta ut och jag är nöjd med detta resultat som tränats på en datauppsättning på 300 bilder märkt av Mechanical Turk-arbetare. Du kan även utforska andra tillgängliga nätverk som t.ex pyramid-scene-parsing nätverk (PSP) or DeepLab-V3 i exempelanteckningsboken med din datauppsättning.
Städa upp
Ta bort slutpunkten när du är klar med den för att undvika fortsatta kostnader:
Slutsats
I det här inlägget visade jag hur man anpassar semantisk segmenteringsdatamärkning och modellträning med SageMaker. Först kan du ställa in ett märkningsjobb med verktyget för automatisk segmentering eller använda en Mechanical Turk-arbetsstyrka (liksom andra alternativ). Om du har fler än 5,000 2 objekt kan du även använda automatiserad datamärkning. Sedan förvandlar du utdata från ditt Ground Truth-märkningsjobb till de nödvändiga indataformaten för SageMaker inbyggda semantisk segmenteringsträning. Efter det kan du använda en accelererad beräkningsinstans (som p3 eller pXNUMX) för att träna en semantisk segmenteringsmodell med följande anteckningsbok och distribuera modellen till en mer kostnadseffektiv instans (som ml.c5.xlarge). Slutligen kan du granska slutledningsresultaten på din testdatauppsättning med några rader kod.
Kom igång med SageMaker semantisk segmentering datamärkning och modellutbildning med din favoritdatauppsättning!
Om författaren
 Kara Yang är datavetare inom AWS Professional Services. Hon brinner för att hjälpa kunder att nå sina affärsmål med AWS molntjänster. Hon har hjälpt organisationer att bygga ML-lösningar inom flera branscher som tillverkning, fordonsindustri, miljömässig hållbarhet och flyg.
Kara Yang är datavetare inom AWS Professional Services. Hon brinner för att hjälpa kunder att nå sina affärsmål med AWS molntjänster. Hon har hjälpt organisationer att bygga ML-lösningar inom flera branscher som tillverkning, fordonsindustri, miljömässig hållbarhet och flyg.
- Myntsmart. Europas bästa bitcoin- och kryptobörs.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. FRI TILLGÅNG.
- CryptoHawk. Altcoin radar. Gratis provperiod.
- Källa: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- Om oss
- accelerera
- accelererad
- exakt
- Uppnå
- uppnås
- tvärs
- lagt till
- Aerospace
- algoritm
- algoritmer
- Alla
- amason
- meddelade
- Annan
- runt
- Associate
- Automatiserad
- automatiskt
- fordonsindustrin
- tillgänglig
- AWS
- bakgrund
- därför att
- BÄST
- Bättre
- mellan
- SLUTRESULTAT
- inbyggd
- företag
- fånga
- Vid
- vissa
- byta
- kanaler
- Välja
- klass
- klasser
- klassificerad
- cloud
- molntjänster
- koda
- Gemensam
- konkurrens
- fullborda
- dator
- datorer
- databehandling
- förtroende
- Konsol
- innehåll
- bekvämlighet
- Motsvarande
- kostnadseffektiv
- Kostar
- skapa
- skapas
- Kunder
- skräddarsy
- datum
- datavetare
- djup
- demonstrera
- distribuera
- olika
- direkt
- ritning
- under
- varje
- möjliggör
- början till slut
- Slutpunkt
- ange
- miljömässigt
- etablerade
- exempel
- Utom
- förväntat
- förväntar
- utforska
- extrem
- Ansikte
- Leverans
- Förnamn
- följer
- efter
- format
- från
- genereras
- Mål
- god
- grå
- stor
- lyckligt
- hjälpte
- hjälpa
- hjälper
- hög kvalitet
- värd
- Hur ser din drömresa ut
- How To
- HTTPS
- humant
- Människa
- Hundratals
- bild
- bilder
- genomföra
- förbättra
- innefattar
- ingår
- Öka
- index
- industrier
- informationen
- ingång
- exempel
- Gränssnitt
- skärning
- införa
- IT
- Jobb
- Lediga jobb
- känd
- etikett
- märkning
- Etiketter
- Large
- lansera
- LÄRA SIG
- inlärning
- Nivå
- Begränsad
- linje
- rader
- Lista
- lokal
- läge
- platser
- Lång
- se
- Maskinen
- maskininlärning
- hantera
- obligatoriskt
- manuellt
- Produktion
- karta
- kartläggning
- mask
- Masker
- massiv
- mekanisk
- kanske
- ML
- modell
- modeller
- mer
- multipel
- namn
- namngivning
- Navigering
- nät
- nätverk
- Nästa
- anteckningsbok
- antal
- Erbjudanden
- Alternativet
- Tillbehör
- organisationer
- Övriga
- egen
- brinner
- procent
- utför
- poäng
- Polygon
- Populära
- Förbered
- pretty
- pris
- privat
- process
- producera
- professionell
- ge
- ger
- allmän
- syfte
- snabbt
- RE
- register
- representerar
- Obligatorisk
- Kräver
- Resultat
- översyn
- Samma
- skalbar
- Forskare
- HAV
- segmentering
- vald
- service
- Tjänster
- in
- inställning
- Dela
- show
- visas
- Enkelt
- Situationen
- Small
- So
- Mjukvara
- Lösningar
- delas
- igång
- förvaring
- Hållbarhet
- Målet
- uppgifter
- grupp
- testa
- Smakämnen
- källan
- sak
- tredje part
- tusentals
- Genom
- genomströmning
- tid
- verktyg
- Tåg
- Utbildning
- Förvandla
- fackliga
- användning
- godkännande
- försäljare
- syn
- VEM
- Arbete
- arbetare
- arbetskraft
- fungerar
- Din