Likhetsbaserad bildsökning, även känd som innehållsbaserad bildhämtning, har historiskt sett varit en utmanande uppgift med datorseende. Detta problem är särskilt svårt för bildkonst, eftersom det är mindre uppenbart vad ett mått på "likhet" ska definieras som och vem som ska sätta den standarden för konst.
Till exempel, när jag laddar upp ett foto av en väggmålning med ett ansikte bland färgglada rektanglar och djärva linjer (se bilder nedan) till Google för att hitta liknande bilder, ger Google mig en rad alternativ under avsnittet "Visuellt liknande bilder". De flesta bilder var väggmålningar med ett framträdande ansikte avbildat i väggmålningen; andra var rena målningar med ett ansikte i. Alla bilderna sträckte sig över en mängd olika färgscheman och stilistiska strukturer.

Höger: Skärmdump från Google av vad Google anser vara liknande bilder som detta foto.
En 2018 papper från Geirhos et al. [1] avslöjade att konvolutionella neurala nätverk (CNN) som tränas på ImageNet är partiska mot bildens stilistiska struktur. För att tvinga en CNN att istället lära sig en formbaserad representation, tillämpade forskarna stilöverföring på ImageNet för att istället skapa en "Stylized-ImageNet"-datauppsättning.
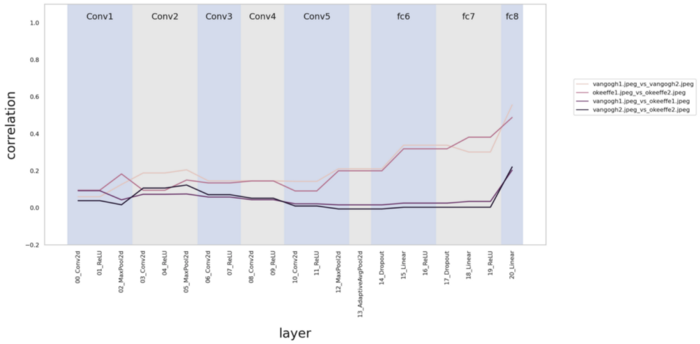
Jag bestämde mig för att bygga vidare på deras rön för att undersöka effekten av att träna par av konstverk från samma konstnärliga stilar på en struktur-biased kontra form-biased modell. När jag jämförde par av målningar från Vincent van Gogh vs. Georgia O'Keeffe, båda konstnärer med mycket distinkta konststilar, fann jag att den texturorienterade ImageNet-utbildade AlexNet-modellen gjorde ett mycket bättre jobb med att korrelera bitarna från samma konstnärer (Figur 1) jämfört med den formförsedda Stylized-ImageNet-tränade AlexNet-modellen (Figur 2).
Min huvudsakliga slutsats från detta experiment var att i att utvärdera likheten mellan bildkonst, om vi betraktade konstverk från samma konstnär som ett kriterium för likhet, då var den stilistiska strukturen mycket viktigare att leta efter och jämföra än formrepresentationerna. Men utvärderingen av "stil" verkar vara en mycket subjektiv och mänsklig perceptuell process. Detta fynd gjorde mig ännu mer nyfiken på vilka tekniska metoder som kunde kombinera både mänskligt och kvantitativt omdöme för att fastställa konstnärlig likhet.

En 2011 papper från Hughes et al. [2] kombinerade kvantitativ och psykologisk forskning för att dra slutsatsen att att kombinera mänsklig perceptuell information med högre ordnings statistiska representationer av konst var extremt effektivt för att lösa det likhetsbaserade sökproblemet för konst. Människans uppfattning om konstnärlig stil är generellt grundad i kvaliteten på element som linjer, skuggning och färg, som är svåra att fånga med hjälp av låg ordningsstatistik. Således utnyttjade dessa forskare rumslig statistik av högre ordning och använde sina resultat för att jämföra bildkonst. Sedan genomförde de psykofysiska experiment som bad deltagarna att bedöma likheten mellan par av konstverk och använde dessa resultat tillsammans med deras prediktiva modeller.
Om detta fördjupade utbildningsinnehåll är användbart för dig, prenumerera på vår AI-e-postlista att bli varnade när vi släpper nytt material.
Kvantitativ process och resultat
Hughes et al. utförde sin forskning på en datauppsättning med 308 högupplösta bilder av konstverk som spänner över en mängd olika konstnärer. De använde två bildnedbrytningsmetoder för att extrahera funktioner från bilder:
- Gabor filter, som är känslig för linjer och kanter vid specifika orienteringar och spatiala frekvenser
- Sparsam kodningsmodell, som lär sig en uppsättning basfunktioner associerade med högre ordnings statistiska egenskaper hos en bild
Efter att ha extraherat funktionerna jämförde och utvärderade de sedan dessa konstnärliga bilder med följande fyra mått:
- Topporientering, som tittar på vilken orientering toppamplituden inträffar i 2D Fourier-transformen av basfunktionen lärd från den sparsamma kodningsmodellen
- Högsta rumsfrekvens, som tittar på vilken spatial frekvens toppamplituden inträffar vid
- Orienteringsbandbredd, som mäter hur selektiv en basfunktion är för den föredragna orienteringen
- Spatial frekvensbandbredd, som mäter hur selektiv en basfunktion är för den föredragna spatiala frekvensen
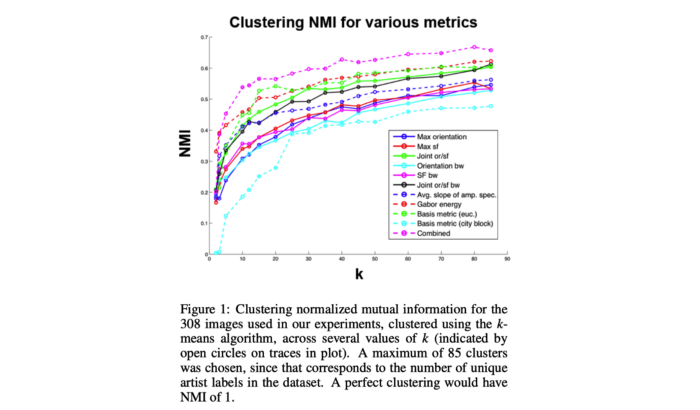
Sedan undersökte forskarna olika avståndsmått (t.ex. KL-divergens) för att jämföra fördelningarna av de fyra mätvärdena ovan för att härleda avståndsmatriser. Det är viktigt att notera att eftersom det inte finns någon grundsanning om stilistisk likhet, jämförde forskarna konstverk med märkning av äkta konstnär, dvs alla målningar av Picasso har samma märkning, så avståndsmatriserna konstruerades med hänsyn till märkningen äkta konstnär. . Att utföra k-betyder klustring med hjälp av olika avståndsmått avslöjade övergripande framgång med att använda dessa statistiska representationer av högre ordning för bildkonstbilder (se grafen nedan).
Psykofysiska perceptuella likhetsexperiment
Förutom att utveckla en metod för att kvantitativt karakterisera stilen av visuell konstverk genomförde forskarna två psykofysiska experiment för att dra fördel av mänsklig perceptuell information. De bad deltagarna att bedöma likheten mellan par av konstbilder i abstrakt konst, landskap och porträtt, och aggregerade deras svar för att skapa en likhetsmatris för var och en av de tre kategorierna.
Experiment 1 försökte jämföra effektiviteten av perceptuella bedömningar för att förutsäga det stilistiska förhållandet mellan konstverk. Forskarna höll fram två bilder per bildkategori; sedan tränade de en regressionsmodell med hjälp av funktionsbaserade avstånd för att förutsäga avståndet mellan två bilder enligt deras upplevda likhet. Med de inlärda modellerna förutspådde de avstånden mellan de uthållna bilderna och träningsbilderna. Slutligen jämförde de det förutsagda avståndet med det verkliga perceptuella avståndet mellan bilderna.
Forskarna fann att den perceptuella informationen från abstrakta och landskapskonstverk möjliggjorde statistiskt signifikanta förutsägelser, vilket säger oss att användbar statistisk information finns inte bara i perceptuell likhetsdata utan kan också användas för att modellera skillnaderna mellan visuella konstverk.
Experiment 2 mätte i vilken utsträckning begränsad perceptuell information av de tre kategorierna av bilder kunde förutsäga stilistiska distinktioner och relationer i större uppsättningar bilder, som är direkt relevant för problemet med likhetsbaserad bildsökning. Processen liknade Experiment 1, bara att den här gången höll de fram 51 bilder över de tre kategorierna och använde de återstående bilderna för att skapa en perceptuell distansmatris. Deras förutspådda avståndsmatris antydde att även med begränsad perceptuell information är sådan information till hjälp "att vägleda sätten på vilka vi kombinerar statistiska egenskaper för att förstå stiluppfattning."
Avslutande tankar
Sammanfattningsvis visade Hughes et al.s artikel "Comparing Higher-Order Spatial Statistics and Perceptual Judgments in the Stylometric Analysis of Art" oss vikten och behovet av att kombinera både mänsklig perceptuell information med högre ordnings statistisk information för att utvärdera likheten mellan visuell konst.
Mer psykologisk forskning behöver fortfarande göras för att utvärdera hur konstnärlig stil uppfattas, definieras och utvärderas med avseende på likhet. I sin uppsats nämner de hur "[inte närvarande ... det finns bara en handfull kvantitativa studier av de faktorer som styr mänsklig stiluppfattning."
Med hänsyn till datorseendets bredare sammanhang är det också intressant att tänka på behovet av högre ordnings statistiska representationer av konstnärlig stil i analogi med behovet av djupare faltningslager i CNN.
Allt som allt, Att rota bedömningarna i mänsklig perception samtidigt som man optimerar och drar fördel av all tillgänglig kvantitativ information är nyckeln för att överväga hur man kan utveckla ett bättre likhetsbaserat bildsökningssystem för visuella konstverk.
Referensprojekt
[1] Geirhos, R., Rubisch, P., Michaelis, C., Bethge, M., Wichmann, FA och Brendel, W. "ImageNet-tränade CNN:er är partiska mot textur; ökad formbias förbättrar noggrannheten och robustheten." ICLR 2019. arXiV förtryck: https://arxiv.org/abs/1811.12231.
[2] Hughes, JM, Graham, DJ, Jacobsen, CR och Rockmore, DN "Jämföra rumslig statistik av högre ordning och perceptuella bedömningar i stilometrisk analys av konst." 2011:s 19:e europeiska signalbehandlingskonferens. https://ieeexplore.ieee.org/abstract/document/7073967.
Catherine Yeo är en kandidatexamen vid Harvard och studerar datavetenskap. Du hittar henne på Twitter @catherinehyeo.
Den här artikeln är inspirerad av Harvards PSYCH 1406, "Biologiska och artificiella visuella system: hur människor och maskiner representerar den visuella världen." Tack till professor George Alvarez för hans feedback och vägledning.
Den här artikeln publicerades ursprungligen den Mot datavetenskap och publiceras på nytt till TOPBOTS med tillstånd från författaren.
Tycker du om den här artikeln? Registrera dig för fler AI-uppdateringar.
Vi meddelar dig när vi släpper mer teknisk utbildning.
Posten Likhetsbaserad bildsökning för bildkonst visades först på TOPPBOTS.
- '
- "
- 10
- 11
- 2019
- 2D
- 7
- 9
- a
- Om oss
- SAMMANDRAG
- Enligt
- tvärs
- Dessutom
- administrering
- Fördel
- AI
- Alla
- bland
- analys
- analytics
- tillämpas
- Tillämpa
- Konst
- Artikeln
- konstgjord
- konstnär
- konstnärliga
- Artister
- konstverk
- associerad
- tillgänglig
- grund
- Där vi får lov att vara utan att konstant prestera,
- nedan
- mellan
- störst
- SLUTRESULTAT
- företag
- fånga
- fall
- Kategori
- utmanar
- utmanande
- CNN
- Kodning
- färgstarka
- kombinerad
- jämfört
- dator
- Datavetenskap
- Konferens
- övervägande
- anser
- innehåll
- kunde
- skapa
- kund
- Helpdesk
- datum
- beslutade
- djupare
- beskriva
- bestämmande
- utveckla
- utveckla
- DID
- olika
- svårt
- direkt
- avstånd
- Distributioner
- Utbildning
- pedagogiska
- effekt
- Effektiv
- element
- Giltigt körkort
- utvärdering
- händelse
- exempel
- experimentera
- Ansikte
- faktorer
- Funktioner
- Med
- återkoppling
- Figur
- Slutligen
- finansiering
- finna
- Förnamn
- efter
- hittade
- från
- fungera
- funktioner
- allmänhet
- George
- georgien
- beviljats
- Harvard
- hjälp
- högre
- Hur ser din drömresa ut
- How To
- Men
- hr
- HTTPS
- humant
- Människa
- bild
- bilder
- vikt
- med Esport
- ökande
- informationen
- inspirerat
- undersöka
- IT
- Jobb
- Domaren
- domar
- Nyckel
- Vet
- känd
- etikett
- märkning
- liggande
- större
- LÄRA SIG
- lärt
- Adress
- Begränsad
- rader
- se
- Maskiner
- Marknadsföring
- Materialet
- Matris
- åtgärder
- Medium
- metoder
- Metrics
- modell
- modeller
- mer
- mest
- behov
- nätverk
- Uppenbara
- Verksamhet
- optimera
- Tillbehör
- Övriga
- övergripande
- Papper
- deltagare
- utför
- bitar
- förutse
- förutsägelse
- presentera
- Problem
- process
- bearbetning
- Produkt
- Professor
- kvalitet
- kvantitativ
- relation
- Förhållanden
- frigöra
- relevanta
- Återstående
- representerar
- representation
- forskning
- forskare
- Resultat
- avslöjade
- robusthet
- försäljning
- Samma
- system
- Vetenskap
- Sök
- selektiv
- in
- Forma
- signera
- signifikant
- liknande
- eftersom
- So
- specifik
- standard
- statistisk
- statistik
- Fortfarande
- studier
- stil
- framgång
- stödja
- system
- System
- tar
- Teknisk
- berättar
- Smakämnen
- tre
- tid
- mot
- Utbildning
- överföring
- Förvandla
- under
- förstå
- Unsplash
- Uppdateringar
- us
- användning
- mängd
- syn
- W
- sätt
- Vad
- medan
- VEM
- världen
- Din