Apache isberg är ett öppet tabellformat för mycket stora analytiska datauppsättningar, som fångar metadatainformation om datauppsättningarnas tillstånd när de utvecklas och förändras över tiden. Den lägger till tabeller till beräkningsmotorer inklusive Spark, Trino, PrestoDB, Flink och Hive med hjälp av ett högpresterande tabellformat som fungerar precis som en SQL-tabell. Iceberg har blivit mycket populärt för sitt stöd för ACID-transaktioner i datasjöar och funktioner som schema- och partitionsutveckling, tidsresor och återställning.
Apache Iceberg-integration stöds av AWS-analystjänster inklusive Amazon EMR, Amazonas Athenaoch AWS-lim. Amazon EMR kan tillhandahålla kluster med Spark, Hive, Trino och Flink som kan köra Iceberg. Från och med Amazon EMR version 6.5.0 kan du använd Iceberg med ditt EMR-kluster utan att kräva en bootstrap-åtgärd. I början av 2022 tillkännagav AWS allmän tillgänglighet av Athena ACID-transaktioner, drivna av Apache Iceberg. Den nyligen släppta Athena frågemotor version 3 ger bättre integration med Iceberg-tabellformatet. AWS Glue 3.0 och senare stöder Apache Iceberg-ramverket för datasjöar.
I det här inlägget diskuterar vi vad kunderna vill ha i moderna datasjöar och hur Apache Iceberg hjälper till att tillgodose kundernas behov. Sedan går vi igenom en lösning för att bygga en högpresterande och utvecklande isbergsdatasjö på Amazon enkel lagringstjänst (Amazon S3) och bearbeta inkrementella data genom att köra infoga, uppdatera och ta bort SQL-satser. Slutligen visar vi dig hur du prestandajusterar processen för att förbättra läs- och skrivprestandan.
Hur Apache Iceberg adresserar vad kunderna vill ha i moderna datasjöar
Fler och fler kunder bygger datasjöar, med strukturerad och ostrukturerad data, för att stödja många användare, applikationer och analysverktyg. Det finns ett ökat behov av datasjöar för att stödja databaser som funktioner som ACID-transaktioner, uppdateringar och raderingar på rekordnivå, tidsresor och återställning. Apache Iceberg är designad för att stödja dessa funktioner på kostnadseffektiva petabyte-skala datasjöar på Amazon S3.
Apache Iceberg tillgodoser kundernas behov genom att fånga rik metadatainformation om datasetet vid den tidpunkt då de enskilda datafilerna skapas. Det finns tre lager i arkitekturen för en isbergstabell: isbergskatalogen, metadatalagret och datalagret, som avbildas i följande figur (källa).

Iceberg-katalogen lagrar metadatapekaren till den aktuella tabellmetadatafilen. När en utvald fråga läser en Iceberg-tabell, går frågemotorn först till Iceberg-katalogen och hämtar sedan platsen för den aktuella metadatafilen. När det sker en uppdatering av Iceberg-tabellen skapas en ny ögonblicksbild av tabellen och metadatapekaren pekar på den aktuella tabellens metadatafil.
Följande är ett exempel på en isbergskatalog med implementering av AWS Glue. Du kan se databasnamnet, platsen (S3-sökväg) för Iceberg-tabellen och metadataplatsen.

Metadatalagret har tre typer av filer: metadatafilen, manifestlistan och manifestfilen i en hierarki. Överst i hierarkin finns metadatafilen, som lagrar information om tabellens schema, partitionsinformation och ögonblicksbilder. Ögonblicksbilden pekar på manifestlistan. Manifestlistan har informationen om varje manifestfil som utgör ögonblicksbilden, såsom placeringen av manifestfilen, partitionerna den tillhör och de nedre och övre gränserna för partitionskolumner för datafilerna som den spårar. Manifestfilen spårar datafiler såväl som ytterligare detaljer om varje fil, till exempel filformatet. Alla tre filerna arbetar i en hierarki för att spåra ögonblicksbilder, schema, partitionering, egenskaper och datafiler i en isbergstabell.
Datalagret har de individuella datafilerna i Iceberg-tabellen. Iceberg stöder ett brett utbud av filformat inklusive Parquet, ORC och Avro. Eftersom Iceberg-tabellen spårar de enskilda datafilerna istället för att bara peka på partitionsplatsen med datafiler, isolerar den skrivoperationerna från läsoperationer. Du kan skriva datafilerna när som helst, men gör bara ändringen explicit, vilket skapar en ny version av ögonblicksbilden och metadatafilerna.
Lösningsöversikt
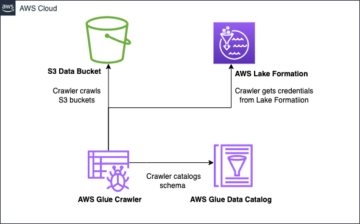
I det här inlägget går vi igenom en lösning för att bygga en högpresterande Apache Iceberg-datasjö på Amazon S3; bearbeta inkrementella data med infoga, uppdatera och ta bort SQL-satser; och justera Iceberg-tabellen för att förbättra läs- och skrivprestandan. Följande diagram illustrerar lösningsarkitekturen.

För att demonstrera denna lösning använder vi Amazon kundrecensioner dataset i en S3-hink (s3://amazon-reviews-pds/parquet/). I verkliga fall skulle det vara rådata som lagras i din S3-hink. Vi kan kontrollera datastorleken med följande kod i AWS-kommandoradsgränssnitt (AWS CLI):
Det totala antalet objekt är 430 och den totala storleken är 47.4 GiB.
För att konfigurera och testa den här lösningen genomför vi följande steg på hög nivå:
- Sätt upp en S3-hink i den kurerade zonen för att lagra konverterade data i Iceberg-tabellformat.
- Starta ett EMR-kluster med lämpliga konfigurationer för Apache Iceberg.
- Skapa en anteckningsbok i EMR Studio.
- Konfigurera Spark-sessionen för Apache Iceberg.
- Konvertera data till Iceberg-tabellformat och flytta data till den kurerade zonen.
- Kör infoga, uppdatera och ta bort frågor i Athena för att bearbeta inkrementell data.
- Utför prestandajustering.
Förutsättningar
För att följa med i denna genomgång måste du ha en AWS-konto med en AWS identitets- och åtkomsthantering (IAM) roll som har tillräcklig tillgång för att tillhandahålla de nödvändiga resurserna.
Ställ in S3-hinken för Iceberg-data i den kurerade zonen i din datasjö
Välj den region där du vill skapa S3-skopan och ange ett unikt namn:
Starta ett EMR-kluster för att köra Iceberg-jobb med Spark
Du kan skapa ett EMR-kluster från AWS Management Console, Amazon EMR CLI, eller AWS Cloud Development Kit (AWS CDK). För det här inlägget går vi igenom hur du skapar ett EMR-kluster från konsolen.
- Välj på Amazon EMR -konsol Skapa kluster.
- Välja Avancerade alternativ.
- För Programvarukonfiguration, välj den senaste Amazon EMR-versionen. Från och med januari 2023 är den senaste versionen 6.9.0. Iceberg kräver release 6.5.0 och högre.
- Välja JupyterEnterpriseGateway och Gnista som programvaran att installera.
- För Redigera programinställningar, Välj Ange konfiguration och skriv in
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - Lämna andra inställningar på standardinställningarna och välj Nästa.

- För hårdvara, använd standardinställningen.
- Välja Nästa.
- För Klusternamn, ange ett namn. Vi använder
iceberg-blog-cluster. - Lämna de återstående inställningarna oförändrade och välj Nästa.
- Välja Skapa kluster.
Skapa en anteckningsbok i EMR Studio
Vi går nu igenom hur du skapar en anteckningsbok i EMR Studio från konsolen.
- På IAM-konsolen, skapa en EMR Studio-tjänstroll.
- Välj på Amazon EMR -konsol EMR Studio.
- Välja KOM IGÅNG.
Smakämnen KOM IGÅNG sidan visas på en ny flik.
- Välja Skapa Studio i den nya fliken.
- Ange ett namn. Vi använder isbergsstudio.
- Välj samma VPC och subnät som de för EMR-klustret och standardsäkerhetsgruppen.
- Välja AWS Identity and Access Management (IAM) för autentisering och välj tjänsten EMR Studio-rollen du just skapade.
- Välj en S3-väg för Säkerhetskopiering av arbetsytor.
- Välja Skapa Studio.
- När Studio har skapats väljer du Studio-åtkomst-URL.
- Välj på EMR Studios instrumentpanel Skapa arbetsyta.
- Ange ett namn för din arbetsyta. Vi använder
iceberg-workspace. - Bygga ut Avancerad konfiguration Och välj Anslut Workspace till ett EMR-kluster.
- Välj det EMR-kluster som du skapade tidigare.
- Välja Skapa arbetsyta.
- Välj namnet på arbetsytan för att öppna en ny flik.
I navigeringsfönstret finns en anteckningsbok som har samma namn som arbetsytan. I vårt fall är det isberg-arbetsyta.
- Öppna anteckningsboken.
- När du uppmanas att välja en kärna, välj Gnista.
Konfigurera en Spark-session för Apache Iceberg
Använd följande kod och ange ditt eget S3-hinknamn:
Detta ställer in följande Spark-sessionskonfigurationer:
- spark.sql.catalog.demo – Registrerar en Spark-katalog med namnet demo, som använder Iceberg Spark-katalogplugin.
- spark.sql.catalog.demo.catalog-impl – Demo Spark-katalogen använder AWS Glue som den fysiska katalogen för att lagra Iceberg-databas och tabellinformation.
- spark.sql.catalog.demo.warehouse – Demo Spark-katalogen lagrar alla Iceberg-metadata och datafiler under rotsökvägen som definieras av den här egenskapen:
s3://iceberg-curated-blog-data. - spark.sql.extensions – Lägger till stöd för Iceberg Spark SQL-tillägg, vilket gör att du kan köra Iceberg Spark-procedurer och vissa SQL-kommandon endast för Iceberg (du använder detta i ett senare steg).
- spark.sql.catalog.demo.io-impl – Iceberg tillåter användare att skriva data till Amazon S3 genom S3FileIO. AWS Glue Data Catalog använder som standard denna FileIO, och andra kataloger kan ladda denna FileIO med hjälp av io-impl katalogegenskapen.
Konvertera data till Iceberg-tabellformat
Du kan använda antingen Spark på Amazon EMR eller Athena för att ladda Iceberg-bordet. I EMR Studio Workspace Notebook Spark-sessionen kör du följande kommandon för att ladda data:
När du har kört koden bör du hitta två prefix som skapats i ditt datalager S3-sökväg (s3://iceberg-curated-blog-data/reviews.db/all_reviews): data och metadata.
Bearbeta inkrementella data med hjälp av infoga, uppdatera och ta bort SQL-satser i Athena
Athena är en serverlös frågemotor som du kan använda för att utföra läs-, skriv-, uppdaterings- och optimeringsuppgifter mot Iceberg-tabeller. För att visa hur Apache Iceberg-datasjöformatet stöder inkrementell datainmatning, kör vi infoga, uppdatera och ta bort SQL-satser på datasjön.
Navigera till Athena-konsolen och välj Frågeredigerare. Om det här är första gången du använder Athena-frågeredigeraren måste du göra det konfigurera sökresultatets plats att vara S3-skopan du skapade tidigare. Du bör kunna se att tabellen reviews.all_reviews är tillgänglig för sökning. Kör följande fråga för att verifiera att du har laddat Iceberg-tabellen framgångsrikt:
Bearbeta inkrementella data genom att köra infoga, uppdatera och ta bort SQL-satser:
Prestandajustering
I det här avsnittet går vi igenom olika sätt att förbättra Apache Icebergs läs- och skrivprestanda.
Konfigurera Apache Iceberg-tabellegenskaper
Apache Iceberg är ett tabellformat och det stöder tabellegenskaper för att konfigurera tabellbeteende som läsning, skrivning och katalog. Du kan förbättra läs- och skrivprestandan på Iceberg-tabeller genom att justera tabellegenskaperna.
Om du till exempel märker att du skriver för många små filer för en Iceberg-tabell kan du konfigurera skrivfilstorleken för att skriva färre men större filer för att förbättra frågeprestanda.
| Fast egendom | Standard | Beskrivning |
| write.target-file-size-bytes | 536870912 (512 MB) | Styr storleken på filer som genereras för att rikta in sig på så många byte |
Använd följande kod för att ändra tabellformatet:
Avdelning och sortering
För att få en fråga att köras snabbt, ju mindre data som läses desto bättre. Iceberg drar fördel av den rika metadata som den fångar in vid skrivtid och underlättar tekniker som skanningsplanering, partitionering, beskärning och statistik på kolumnnivå som min/max-värden för att hoppa över datafiler som inte har matchningsposter. Vi guidar dig genom hur frågesökningsplanering och partitionering fungerar i Iceberg och hur vi använder dem för att förbättra frågeprestanda.
Planering av sökfrågor
För en given fråga är det första steget i en frågemotor skanningsplanering, vilket är processen för att hitta filerna i en tabell som behövs för en fråga. Planering i en Iceberg-tabell är mycket effektiv, eftersom Icebergs rika metadata kan användas för att beskära metadatafiler som inte behövs, förutom att filtrera datafiler som inte innehåller matchande data. I våra tester observerade vi att Athena skannade 50 % eller mindre data för en given fråga på en Iceberg-tabell jämfört med originaldata före konvertering till Iceberg-format.
Det finns två typer av filtrering:
- Metadatafiltrering – Iceberg använder två nivåer av metadata för att spåra filerna i en ögonblicksbild: manifestlistan och manifestfilerna. Den använder först manifestlistan, som fungerar som ett index över manifestfilerna. Under planeringen filtrerar Iceberg manifest med hjälp av partitionsvärdeintervallet i manifestlistan utan att läsa alla manifestfiler. Sedan använder den utvalda manifestfiler för att hämta datafiler.
- Datafiltrering – Efter att ha valt listan med manifestfiler, använder Iceberg partitionsdata och statistik på kolumnnivå för varje datafil som lagras i manifestfiler för att filtrera datafiler. Under planeringen konverteras frågepredikat till predikat på partitionsdata och tillämpas först för att filtrera datafiler. Sedan används kolumnstatistik som antal värden på kolumnnivå, nolltal, nedre gränser och övre gränser för att filtrera bort datafiler som inte kan matcha frågepredikatet. Genom att använda övre och nedre gränser för att filtrera datafiler vid planeringstillfället, förbättrar Iceberg avsevärt frågeprestanda.
Avdelning och sortering
Partitionering är ett sätt att gruppera poster med samma nyckelkolumnvärden skriftligt. Fördelen med partitionering är snabbare frågor som bara kommer åt en del av data, som förklarats tidigare i sökningsplanering: datafiltrering. Iceberg gör partitionering enkel genom att stödja dold partitionering, på det sätt som Iceberg producerar partitionsvärden genom att ta ett kolumnvärde och eventuellt transformera det.
I vårt användningsfall kör vi först följande fråga på Iceberg-tabellen som inte är partitionerad. Sedan partitionerar vi Iceberg-tabellen efter kategorin för recensionerna, som kommer att användas i frågan WHERE-villkor för att filtrera bort poster. Med partitionering kunde frågan skanna mycket mindre data. Se följande kod:
Kör följande select-sats på den icke-partitionerade all_reviews-tabellen kontra den partitionerade tabellen för att se prestandaskillnaden:
Följande tabell visar prestandaförbättringen för datapartitionering, med cirka 50 % prestandaförbättring och 70 % mindre skannade data.
| Dataset Namn | Icke-partitionerad datamängd | Partitionerad datamängd |
| Körtid (sekunder) | 8.20 | 4.25 |
| Data skannad (MB) | 131.55 | 33.79 |
Observera att körtiden är den genomsnittliga körtiden med flera körningar i vårt test.
Vi såg bra prestandaförbättringar efter partitionering. Detta kan dock förbättras ytterligare genom att använda statistik på kolumnnivå från Iceberg-manifestfiler. För att kunna använda statistiken på kolumnnivå effektivt vill du sortera dina poster ytterligare baserat på frågemönster. Att sortera hela datamängden med hjälp av de kolumner som ofta används i frågor kommer att ordna om data på ett sådant sätt att varje datafil slutar med ett unikt värdeintervall för de specifika kolumnerna. Om dessa kolumner används i frågevillkoret tillåter det frågemotorer att hoppa över datafiler ytterligare, vilket möjliggör ännu snabbare frågor.
Kopiera-på-skriv kontra läs-vid-sammanfogning
När du implementerar uppdatering och radering på Iceberg-tabeller i datasjön, finns det två metoder som definieras av Iceberg-tabellens egenskaper:
- Kopiera-på-skriva – Med detta tillvägagångssätt, när det finns ändringar i Iceberg-tabellen, antingen uppdateringar eller borttagningar, kommer datafilerna som är associerade med de påverkade posterna att dupliceras och uppdateras. Posterna kommer antingen att uppdateras eller raderas från de duplicerade datafilerna. En ny ögonblicksbild av Iceberg-tabellen kommer att skapas och pekar på den nyare versionen av datafiler. Detta gör att det övergripande skrivandet blir långsammare. Det kan finnas situationer där samtidiga skrivningar behövs med konflikter, så ett nytt försök måste ske, vilket ökar skrivtiden ännu mer. Å andra sidan, när du läser data, behövs ingen extra process. Frågan kommer att hämta data från den senaste versionen av datafiler.
- Merge-on-read – Med detta tillvägagångssätt, när det finns uppdateringar eller raderingar på Iceberg-tabellen, kommer de befintliga datafilerna inte att skrivas om; istället skapas nya raderingsfiler för att spåra ändringarna. För borttagningar skapas en ny raderingsfil med de raderade posterna. När du läser Iceberg-tabellen kommer raderingsfilen att tillämpas på den hämtade datan för att filtrera bort raderingsposterna. För uppdateringar skapas en ny raderingsfil för att markera de uppdaterade posterna som borttagna. Sedan kommer en ny fil att skapas för dessa poster men med uppdaterade värden. När du läser Iceberg-tabellen kommer både raderings- och nya filer att tillämpas på den hämtade informationen för att återspegla de senaste ändringarna och ge korrekta resultat. Så för alla efterföljande frågor kommer ett extra steg att slå samman datafilerna med raderingen och nya filer, vilket vanligtvis ökar frågetiden. Å andra sidan kan skrivningarna vara snabbare eftersom det inte finns något behov av att skriva om de befintliga datafilerna.
För att testa effekten av de två metoderna kan du köra följande kod för att ställa in Iceberg-tabellens egenskaper:
Kör uppdateringen, ta bort och välj SQL-satser i Athena för att visa körtidsskillnaden för kopiera-på-skriv vs. sammanfoga-på-läs:
Följande tabell sammanfattar frågekörningstiderna.
| Fråga | Copy-on-Write | Merge-on-Read | ||||
| UPPDATERING | RADERA | VÄLJA | UPPDATERING | RADERA | VÄLJA | |
| Körtid (sekunder) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| Data skannade (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
Observera att körtiden är den genomsnittliga körtiden med flera körningar i vårt test.
Som våra testresultat visar finns det alltid avvägningar i de två tillvägagångssätten. Vilken metod du ska använda beror på dina användningsfall. Sammanfattningsvis handlar övervägandena om latens vid läsning och skrivning. Du kan referera till följande tabell och göra rätt val.
| . | Copy-on-Write | Merge-on-Read |
| Fördelar | Snabbare läsning | Snabbare skriver |
| Nackdelar | Dyra skriver | Högre latens vid läsningar |
| När du ska använda den | Bra för frekventa läsningar, sällsynta uppdateringar och raderingar eller stora batchuppdateringar | Bra för tabeller med frekventa uppdateringar och raderingar |
Datakomprimering
Om din datafilstorlek är liten kan du sluta med tusentals eller miljontals filer i en isbergstabell. Detta ökar I/O-driften dramatiskt och saktar ner frågorna. Dessutom spårar Iceberg varje datafil i en datauppsättning. Fler datafiler leder till mer metadata. Detta ökar i sin tur overhead- och I/O-operationen vid läsning av metadatafiler. För att förbättra frågeprestandan rekommenderas det att komprimera små datafiler till större datafiler.
När du uppdaterar och tar bort poster i Iceberg-tabellen, om läs-på-sammanslagning-metoden används, kan du få många små raderingar eller nya datafiler. Att köra komprimering kommer att kombinera alla dessa filer och skapa en nyare version av datafilen. Detta eliminerar behovet av att stämma av dem under läsningar. Det rekommenderas att ha regelbundna komprimeringsjobb för att påverka läsningen så lite som möjligt samtidigt som man bibehåller snabbare skrivhastighet.
Kör följande datakomprimeringskommando och kör sedan urvalsfrågan från Athena:
Följande tabell jämför körtiden före och efter datakomprimering. Du kan se cirka 40 % prestandaförbättring.
| Fråga | Före datakomprimering | Efter datakomprimering |
| Körtid (sekunder) | 97.75 | 32.676 sekunder |
| Data skannade (MB) | 137.16 M | 189.19 M |
Observera att urvalsfrågorna kördes på all_reviews tabell efter uppdatering och radering, före och efter datakomprimering. Körtiden är den genomsnittliga körtiden med flera körningar i vårt test.
Städa upp
När du har följt lösningsgenomgången för att utföra användningsfallen, slutför du följande steg för att rensa upp dina resurser och undvika ytterligare kostnader:
- Släpp AWS Glue-tabellerna och databasen från Athena eller kör följande kod i din anteckningsbok:
- Välj på EMR Studio-konsolen arbetsytor i navigeringsfönstret.
- Välj den arbetsyta du skapade och välj Radera.
- På EMR-konsolen, navigera till Studios sida.
- Välj den studio du skapade och välj Radera.
- Välj på EMR-konsolen kluster i navigeringsfönstret.
- Välj klustret och välj Avsluta.
- Ta bort S3-hinken och alla andra resurser som du skapat som en del av förutsättningarna för det här inlägget.
Slutsats
I det här inlägget introducerade vi Apache Iceberg-ramverket och hur det hjälper till att lösa några av de utmaningar vi har i en modern datasjö. Sedan gick vi igenom en lösning för att bearbeta inkrementell data i en datasjö med hjälp av Apache Iceberg. Slutligen gjorde vi en djupdykning i prestandajustering för att förbättra läs- och skrivprestandan för våra användningsfall.
Vi hoppas att det här inlägget ger lite användbar information för att du ska kunna bestämma dig för om du vill använda Apache Iceberg i din datasjölösning.
Om författarna
 Flora Wu är Sr. Resident Architect vid AWS Data Lab. Hon hjälper företagskunder att skapa dataanalysstrategier och bygga lösningar för att påskynda deras affärsresultat. På fritiden tycker hon om att spela tennis, dansa salsa och att resa.
Flora Wu är Sr. Resident Architect vid AWS Data Lab. Hon hjälper företagskunder att skapa dataanalysstrategier och bygga lösningar för att påskynda deras affärsresultat. På fritiden tycker hon om att spela tennis, dansa salsa och att resa.
 Daniel Li är Sr. Solutions Architect på Amazon Web Services. Han fokuserar på att hjälpa kunder att utveckla, anta och implementera molntjänster och strategi. När han inte jobbar gillar han att vara utomhus med sin familj.
Daniel Li är Sr. Solutions Architect på Amazon Web Services. Han fokuserar på att hjälpa kunder att utveckla, anta och implementera molntjänster och strategi. När han inte jobbar gillar han att vara utomhus med sin familj.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- Able
- Om oss
- ovan
- accelerera
- tillgång
- Behörighets förvaltning
- Handling
- handlingar
- Dessutom
- Annat
- adress
- adresser
- Lägger
- anta
- Fördel
- Efter
- mot
- Alla
- tillåter
- alltid
- amason
- Amazon EMR
- Amazon Web Services
- Analytisk
- analytics
- och
- meddelade
- Apache
- tillämpningar
- tillämpas
- tillvägagångssätt
- tillvägagångssätt
- lämpligt
- arkitektur
- associerad
- Autentisering
- tillgänglighet
- tillgänglig
- genomsnitt
- undvika
- AWS
- AWS-lim
- baserat
- därför att
- blir
- innan
- fördel
- Bättre
- mellan
- större
- Bootstrap
- SLUTRESULTAT
- Byggnad
- företag
- fångar
- Fångande
- Vid
- fall
- katalog
- kataloger
- Kategori
- utmaningar
- byta
- Förändringar
- ta
- val
- Välja
- klassificering
- cloud
- molntjänster
- kluster
- koda
- Kolumn
- Kolonner
- kombinera
- komma
- förbinda
- jämfört
- fullborda
- Compute
- konkurrent
- tillstånd
- konfigurationer
- överväganden
- Konsol
- Konvertering
- konverterad
- kostnadseffektiv
- Kostar
- kunde
- skapa
- skapas
- skapar
- kurerad
- Aktuella
- kund
- Kunder
- Dans
- instrumentbräda
- datum
- Data Analytics
- datasjö
- databehandling
- datalagret
- Databas
- datauppsättningar
- djup
- djupdykning
- Standard
- definierade
- demo
- demonstrera
- beror
- utformade
- detaljer
- utveckla
- Utveckling
- Skillnaden
- olika
- diskutera
- inte
- ner
- dramatiskt
- Drop
- under
- varje
- Tidigare
- Tidig
- redaktör
- effektivt
- effektiv
- antingen
- eliminerar
- aktiverad
- möjliggör
- slutar
- Motor
- Motorer
- ange
- Företag
- företagskunder
- Eter (ETH)
- Även
- Utvecklingen
- utvecklas
- utvecklas
- exempel
- befintliga
- finns
- förklarade
- förlängningar
- extra
- underlättar
- familj
- SNABB
- snabbare
- Funktioner
- Figur
- Fil
- Filer
- filtrera
- filtrering
- filter
- Slutligen
- hitta
- Förnamn
- första gången
- fokuserar
- följer
- efter
- format
- Ramverk
- frekvent
- från
- ytterligare
- Vidare
- Allmänt
- genereras
- skaffa sig
- ges
- Går
- god
- kraftigt
- Grupp
- sidan
- hända
- hjälpa
- hjälpa
- hjälper
- dold
- hierarkin
- högnivå
- högpresterande
- högpresterande
- Bikupa
- hoppas
- Hur ser din drömresa ut
- How To
- Men
- html
- HTTPS
- IAM
- Identitet
- identitets- och åtkomsthantering
- Inverkan
- påverkade
- genomföra
- genomförande
- genomföra
- förbättra
- förbättras
- förbättring
- förbättrar
- in
- Inklusive
- Öka
- ökat
- Ökar
- index
- individuellt
- informationen
- installera
- istället
- integrering
- introducerade
- isolat
- IT
- Januari
- Lediga jobb
- Nyckel
- lab
- sjö
- Large
- större
- Latens
- senaste
- senaste släppningen
- lager
- skikt
- leda
- nivåer
- BEGRÄNSA
- linje
- Lista
- liten
- läsa in
- läge
- göra
- GÖR
- ledning
- många
- markera
- marknadsplats
- Match
- matchande
- Sammanfoga
- metadata
- kanske
- miljoner
- Modern Konst
- mer
- flytta
- multipel
- namn
- Som heter
- Navigera
- Navigering
- Behöver
- behövs
- behov
- Nya
- anteckningsbok
- objektet
- öppet
- drift
- Verksamhet
- optimering
- Optimera
- beställa
- ursprungliga
- Övriga
- utomhus
- övergripande
- egen
- panelen
- del
- bana
- mönster
- utföra
- prestanda
- fysisk
- planering
- plato
- Platon Data Intelligence
- PlatonData
- i
- plugin
- poäng
- Populära
- möjlig
- Inlägg
- drivs
- förutsättningar
- förfaranden
- process
- bearbetning
- producera
- egenskaper
- egenskapen
- ge
- ger
- tillhandahålla
- tillhandahållande
- område
- Raw
- rådata
- Läsa
- Läsning
- verklig
- nyligen
- rekommenderas
- register
- reflektera
- region
- register
- regelbunden
- frigöra
- frigörs
- Återstående
- Obligatorisk
- Kräver
- Resurser
- resultera
- Resultat
- Omdömen
- Rik
- Roll
- rot
- Körning
- rinnande
- Samma
- scanna
- sekunder
- §
- säkerhet
- vald
- väljer
- Server
- service
- Tjänster
- session
- in
- uppsättningar
- inställning
- inställningar
- skall
- show
- Visar
- Enkelt
- situationer
- Storlek
- saktar
- Small
- Snapshot
- So
- Mjukvara
- lösning
- Lösningar
- några
- Gnista
- specifik
- fart
- Spendera
- SQL
- Starta
- Ange
- .
- uttalanden
- statistik
- Steg
- Steg
- Fortfarande
- förvaring
- lagra
- lagras
- lagrar
- strategier
- Strategi
- strukturerade
- strukturerade och ostrukturerade data
- studio
- undernät
- senare
- Framgångsrikt
- sådana
- tillräcklig
- SAMMANFATTNING
- stödja
- Som stöds
- Stödjande
- Stöder
- bord
- tar
- tar
- Målet
- uppgifter
- tekniker
- tennis
- testa
- Testning
- tester
- Smakämnen
- den information
- Staten
- deras
- vari
- tusentals
- tre
- Genom
- tid
- tidsresor
- till
- tillsammans
- alltför
- verktyg
- topp
- Totalt
- spår
- Transaktioner
- omvandla
- färdas
- Traveling
- SVÄNG
- typer
- under
- unika
- Uppdatering
- uppdaterad
- Uppdateringar
- uppdatering
- URL
- användning
- användningsfall
- användare
- vanligen
- VAL
- värde
- Värden
- verifiera
- version
- promenerade
- genomgång
- Warehouse
- klockor
- sätt
- webb
- webbservice
- Vad
- om
- som
- medan
- bred
- Brett utbud
- kommer
- utan
- Arbete
- arbetssätt
- fungerar
- skulle
- skriva
- skrivning
- Din
- zephyrnet